[인공지능사관학교: 자연어분석A반] 기업연계 프로젝트 12일차
AICE BASIC 특강
- 시험 개요
- 탐색적 데이터분석과 시각화
- 데이터 전처리와 데이터 가공
- 머신러닝의 이해와 구현
- 딥러닝의 이해와 구현
- 문제 풀이
시험 개요
- 노코딩, 15문제
- POINT
- 데이터를 잘 해석하고 데이터 사이 관계 파악
- 데이터에 대한 이해
- 인공지능 활용
- 현실의 문제를 해결
- 주의 사항
- 회귀/분류 중 어느 유형의 문제인지 먼저 파악
- 모델, 평가지표가 달라짐
- 요구하는 답안의 형식 잘 지키기
- 천 단위의 k 표기
- 반올림하여 정수 또는 소수점 둘째자리까지 표시 등
- 수행해야 할 작업의 상세를 꼼꼼히 읽고 실행
- 결측치 대체 방법 및 학습 파라미터 변경 방법
- 시험 결과는 분야별 점수와 합격 여부만 알 수 있음
- 회귀/분류 중 어느 유형의 문제인지 먼저 파악
- 문제 풀이 팁
- 개념 정확히 알기
- 용어의 개념, 의미, 사용처를 정확히 알아야 변형 문제 해결 가능
- 지시문에서 용어를 사용하지 않고 의미를 사용하는 경우가 늘고 있음
(예: Epochs를 10으로 하시오 → "전체 데이터가 학습에 사용되는 횟수"를 10으로 하시오)
- 문제 꼼꼼히 읽기 ★★★
- 컬럼(변수) 이해: 데이터의 각 컬럼이 무엇에 대한 컬럼인지 알기
- 데이터 분석/AI 모델링에 일반적으로 사용하는 용어를 '영어'로 알야 함
- 개념 정확히 알기
출제 범위 및 구성
- 데이터 분석 (4문항, 20점)
- 문제 이해
- 데이터 유형 확인
- 데이터 파악, 기술통계 확인
- 전처리 & 시각화 (6문항, 40점)
- 데이터 시각화
- 히트맵
- 박스차드
- 분포차트 등
- 데이터 전처리
- 결측치 처리
- 스케일링
- 데이터 시각화
- 모델링 (5문항, 40점)
- 머신러닝 모델 학습
- 다중선형회귀
- 로지스틱회귀
- KNN
- 의사결정나무
- 랜덤 포레스트
- 부스팅 등
- 딥러닝 모델 학습
- 모델 성능 평가 및 시뮬레이션
- 회귀: MSE, MAE
- 분류: 정확도, 재현율, 정밀도
- 모델 성능 개선
- 머신러닝 모델 학습
모델링 순서: AIDU ex 3.0
- 데이터 가져오기
- basic은 해당없음
- 데이터 분석
- basic은 기초정보분석, 시각화 분석만
- 기초정보분석
- 기초통계량
- 컬럼 개수
- 총 데이터 개수
- 속성들의 자료형
- 최빈값, 분포 등 표시
- 데이터 시각화
- 데이터 분석 > 시각화 분석 (4가지)
- 히트맵
- 데이터 분석 > 시각화 분석 (4가지)
- 데이터 전처리
- 데이터 가공
- basic에서는 결측치 처리만
- 스케일링 나올 수도 있음
- 데이터 가공
- 머신러닝 학습
- AI모델 학습 > 머신러닝 학습
- 딥러닝 학습
- AI모델 학습 > 딥러닝 학습
- 모델 활용
- AI모델 활용
- 가장 영향을 미치는 컬럼 확인
- 새로운 값 예측
- AI모델 활용
- 딥러닝 고도화 작업
- AI모델 학습 > 딥러닝 학습
가공이 끝난 데이터는 반드시 저장 버튼 누르기
→ 데이터 전처리 후 기초 정보 분석이나 시각화 분석으로 다시 돌아와 값을 보는 문제도 있음
화면 예시 & 팁
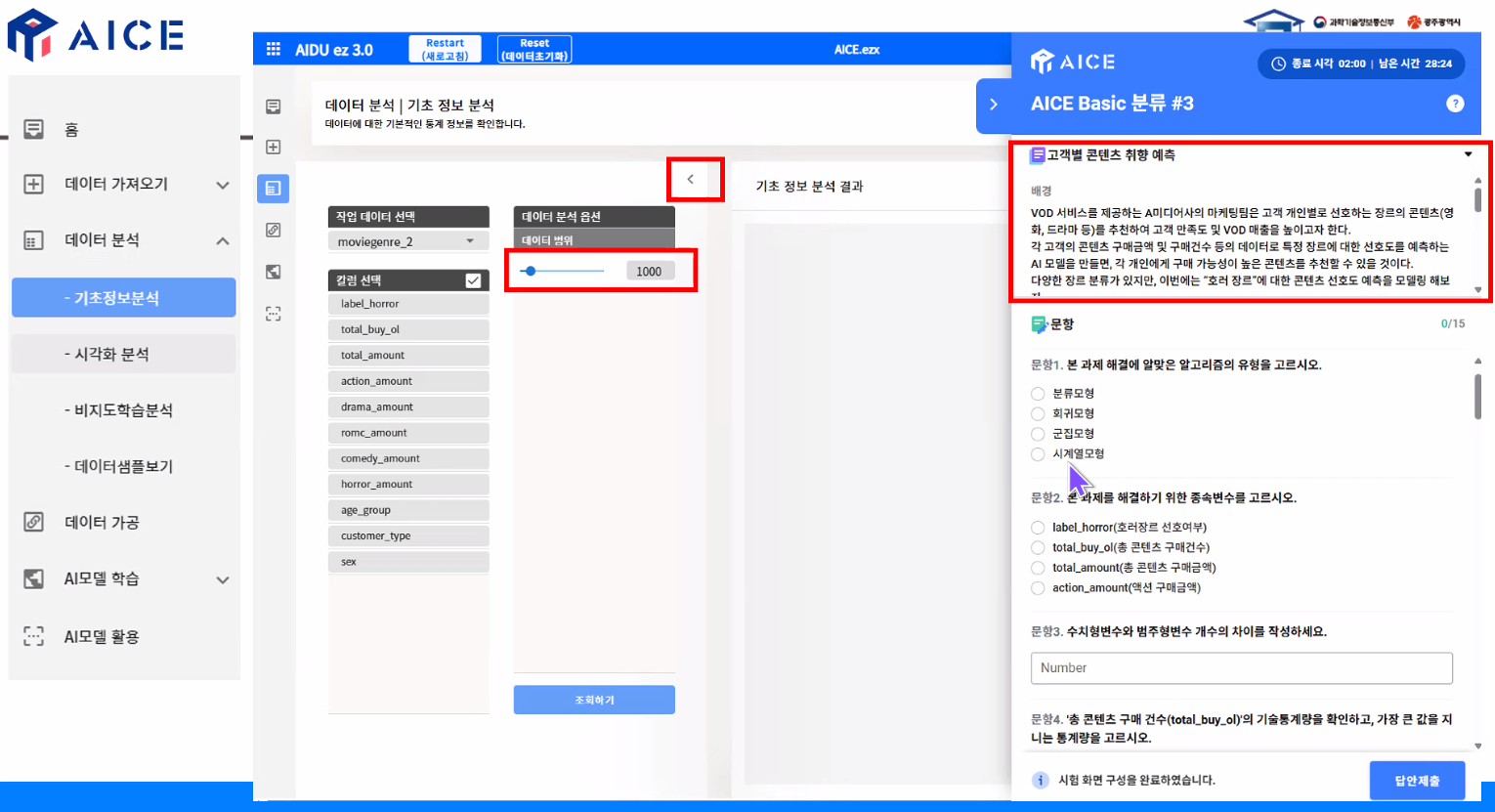
- 기초 정보 분석할 때 데이터 범위 반드시 "전체"로 하기
- 문제에서 데이터 범위 설정하라고 하면(예: 데이터 범위가 2000일 때) 거기에 맞추기
데이터 탐색 및 분석
AI 구현 프로세스
- 문제 정의 및 데이터 수집
- 분류
- 회귀
- 데이터 분석 및 시각화
- 기초 통계량 분석
- 시각화
- 데이터 전처리
- 결측치, 이상치 처리
- 범주형 데이터를 수치 데이터로 변환하기
- 모델 생성 및 튜닝
- 머신러닝
- 딥러닝
- 평가 및 활용
- 변수 영향 확인
- 예측
- 고도화
머신러닝의 종류
Machine Learning
├→ Supervised Learning
│ ├→ Regression
│ └→ Classification
├→ Unsupervised Learning
│ └→ Clustering
└→ Reinforcement Learning- basic에서는 회귀, 분류만 나옴
- 예시
- 회귀: 주가 예측
- 분류: 손글씨 인식, 스팸 메일 분류
- 군집화: 마케팅 고객 그룹화, 추천 시스템
- 강화 학습: 게임 또는 행동 교정
데이터의 종류
- Data
- Structured Data
- excel
- Unstructured Data
- Social Media
- Youtube
- X-ray
- Semi-Structured Data
- JSON
- Structured Data
회귀와 분류에 사용하는 데이터
- 회귀(Regression) 문제에서 Target(==종속변수 ==output)은 수치형(Numerical) 데이터
- 분류(Classification) 문제에서 Target은 범주형(Categorical) 데이터
table에서 row의 수(튜플 수) == 데이터 개수
독립변수와 종속변수
독립변수==feature==input
종속변수==target==output
데이터 분석
- EDA(Exploratory Data Analysis)
- 수집한 데이터의 중요한 특성 발견
- 데이터에 대한 귀중한 통찰력 제공 → 의사결정 및 비즈니스 성공의 중요 요소
- 확인해야 하는 것
- 데이터 구성
- 자료의 양
- 데이터 속성들의 자료 타입
- 기술통계량 확인
- 자료 기초 통계값 및 전반적인 흐름 이해
- 데이터 시각화
- 데이터 분포, 속성의 상관 관계, 데이터 집계를 활용한 도수 분포 이해
기초 정보 분석
object → bar chart / 기술통계에 size, distinct만 있음
vs.
numeric → histogram / 기술통계에 mean, median 등 다양하게 표시
- 데이터 정보
- 총 레코드 개수
- 속성(변수) 개수
- 결측치
- 중복값
- 데이터 유형
- Numeric(수치형): 숫자로만 구성
- 연속형: 연속적인 값
- 이산형: 비연속적인 값
- Object(문자형): 문자 또는 문자와 숫자로 구성
- Category(범주형): 수치형 또는 문자형 데이터 중 범주로 나눌 수 있는 데이터
- 순서형: 순서 있음(
[1,2,3,4,5],[상,중,하]등) - 명목형: 순서 없음(
[영업부,개발부,총무부]등)
- 순서형: 순서 있음(
- Numeric(수치형): 숫자로만 구성
- Datetime: 날짜 시간
- Timedeltas: 시간 간격
- Boolean: 참/거짓
basic 시험에는 Numeric이랑 Object 두 개만 나온다고 함
object → 메타데이터(이름 같은 고유값) 나올 수도 있음
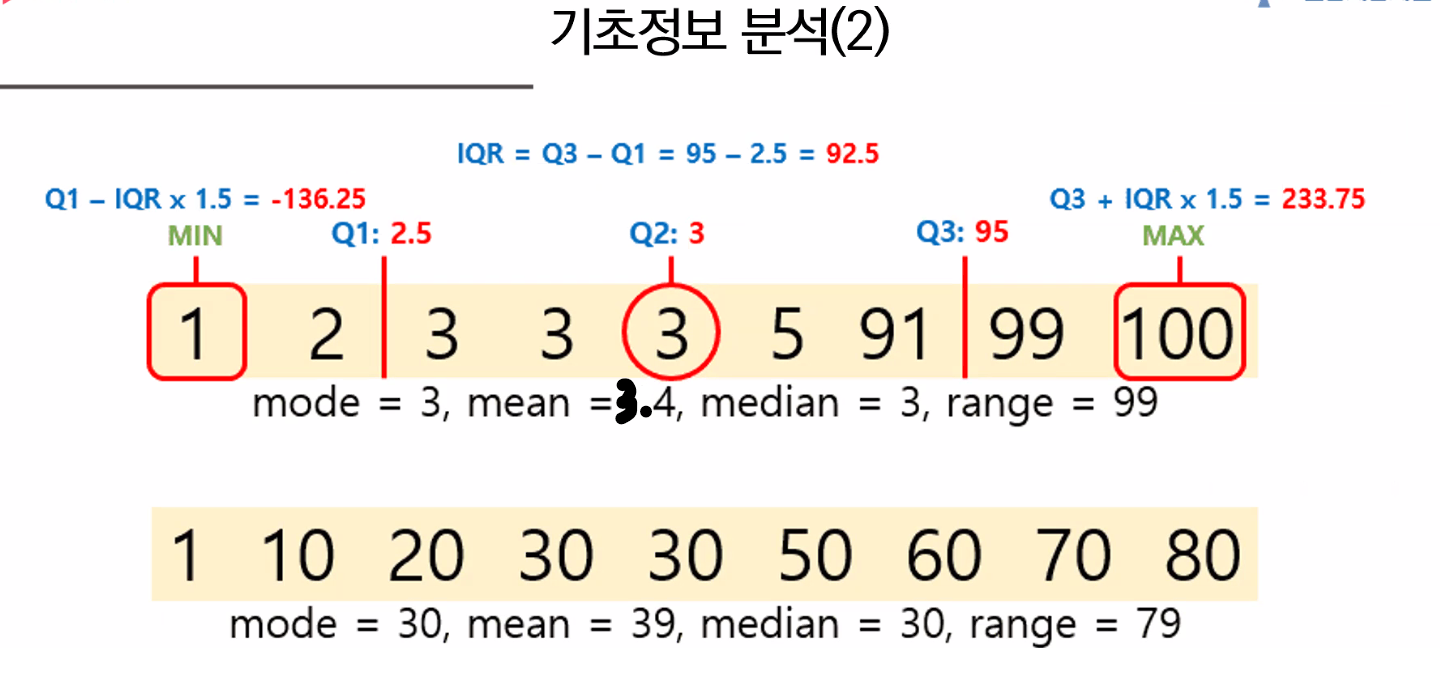
- 기술통계값 확인하기
- 대표값
- 평균 (mean): 각 데이터를 모두 더한 후 데이터의 개수로 나누 값
- 중앙값 (mean): 데이터를 크기 순서대로 나열했을 때 가장 중앙에 위치하는 값 (짝수 데이터의 경우 가운데 두 값의 평균)
- 최빈값 (mode): 출현 빈도수가 가장 큰 값
- 예시:
[1,1,1,1,2,2,3,3,6,10]- 평균:
- 중앙값:
- 최빈값: 1 (4회)
- 대표값
더 알아보기: 평균의 함정 - 사람이 만든 통계의 함정에 빠지지 않으려면

- 기술통계값 더 알아보기
- 최솟값(minimum)
- 데이터 중 가장 작은 값
- 최댓값(maximum)
- 데이터 중 가장 큰 값
- 분산(variation)
- 각 데이터에서 평균을 뺀 값의 제곱의 평균
- 표준편차(standard deviation)
- 분산의 제곱근
- 사분위수(quantile)
- 모든 데이터를 순서대로 4등분 했을 때 경계에 있는 값
- 첨도(kurtosis)
- 데이터의 분포가 정규분포 대비 뾰족한 정도를 나타내는 값
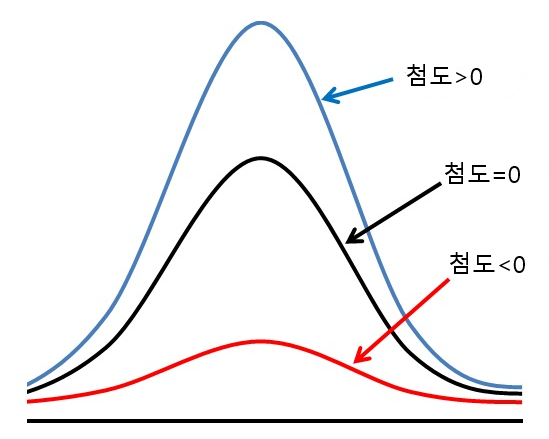
- 데이터의 분포가 정규분포 대비 뾰족한 정도를 나타내는 값
- 왜도(skewness)
- 데이터의 분포가 정규분포 대비 기울어진 정도를 나타내는 값
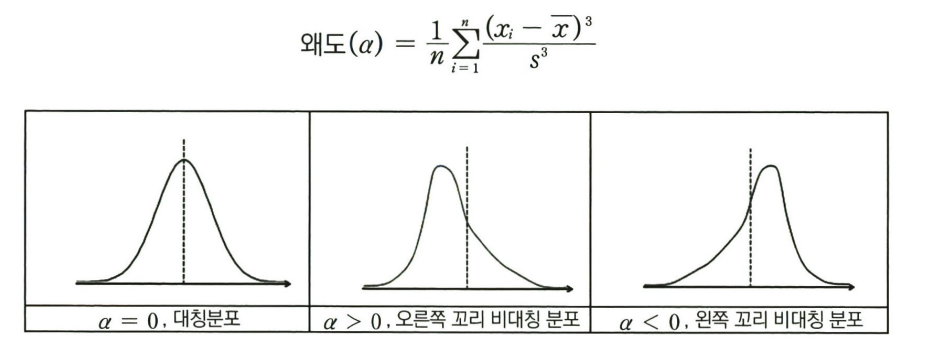
- 데이터의 분포가 정규분포 대비 기울어진 정도를 나타내는 값
- 최솟값(minimum)
분산과 표준편차는 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타냄
첨도는 AICE basic 기초정보분석에서는 안 나온다고 함
- numeric의 기초정보 분석에서 확인할 수 있는 값
- 기술통계
- size: 전체 데이터의 개수
- distinct: 서로 다른 값의 개수
- missing: 결측치
- minimum: 최솟값
- maximum: 최댓값
- zeros
- mean: 평균
- median: 중앙값(중위값) == Q2
- sum
- sd: 표준편차
- skewness: 왜도
- 분위수
- min
- 5-th per.: 전체 5% 위치
- Q1
- median
- Q3
- 95-th per.: 전체 95% 위치
- max
- 최빈값
- 히스토그램
- 기술통계
95th Percentile과 정규분포의 관계
95th Percentile은 정규분포 상에서 특정 의미를 가짐
(단순 '상위 5%'라는 통계적 비율이 아니라 정규분포에서는 그 위치와 확률적 의미가 수식으로 명확히 결정됨)
데이터가 정규분포를 따른다면 평균을 기준으로 약 +1.645 표준편차(σ) 떨어진 값이 95th Percentile임 → 표준편차 단위(z-score)로 명확히 값이 정해짐
즉, 정규분포를 가정할 때만 '평균+1.645σ'가 95번째 백분위수라는 의미가 성립
- object or category의 기초정보 분석에서 확인할 수 있는 값
- 기술통계
- size
- distinct
- missing
- 최빈값
- Bar 차트
- 기술통계
데이터 시각화
- 두 변수 간의 관계를 이해하기 위한 시각화 방법
- 산점도(scatter plot)
- 두 수치형 데이터 사이의 분포를 보여주는 시각화 방법
- 히트맵(heatmap)
- 두 수치형 또는 범주형 데이터 간의 상관관계를 색상으로 표현
- 산점도(scatter plot)
- cf. 두 변수 간 관계를 이해하기 위한 비시각화 방법
- 상관계수(Correlation Coefficient)
- 두 변수 간의 관계의 강도와 방향을 숫자로 나타내는 지표
- 값의 범위: -1 - +1
- +1에 가까울수록 강한 양의 상관 관계
- -1에 가까울수록 강한 음의 상관 관계
- 0에 가까울수록 두 변수는 상관 관계가 없다는 것을 의미
- 주의: 상관관계 ≠ 인과관계
- 상관계수(Correlation Coefficient)
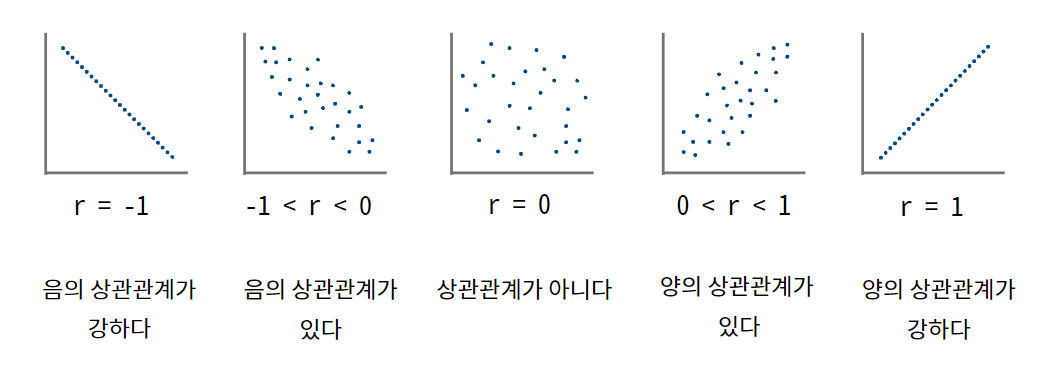
- 상관관계
- 양의 상관 관계
- x가 증가하면 y도 증가
- 점들이 양의 기울기를 갖는 직선에 가까울수록 강한 양의 상관 관계
- 상관 관계 없음
- x와 y는 서로 관계가 없음
- 점들 사이에 패턴이 없음
- 음의 상관 관계
- x가 증가하면 y는 감소
- 점들이 음의 기울기를 갖는 직선에 가까울수록 강한 음의 상관 관계
- 양의 상관 관계
- 한 개의 변수를 분석하기 위한 시각화 방법
- Bar Plot(막대 그래프)
- 범주 데이터의 도수를 계산
- Count Plot(카운트 플롯)
- 범주 데이터의 도수를 다른 변수의 특성에 따라 나누어 계산
- Histogram(히스토그램)
- 수치 데이터의 범주에 따른 도수를 계산
- Box Plot(상자 그래프, 박스 플롯)
- 수치 데이터의 분포를 사분위 값을 활용하여 시각화
- 다른 범주형 데이터의 특성에 따라 분리 가능
- Bar Plot(막대 그래프)
시험 환경에서는 막대 그래프, 카운트 플롯, 히스토그램을 합쳐 분포 차트 / 박스 플롯 있음
- Density Plot(분포 차트)
- 어떤 속성에 대하여 그 속성의 빈도수 또는 다른 속성 범주에 대한 빈도수를 표현하는 시각화 방법
- Box Plot(박스 플롯)
- 수치형 데이터의 통계 정보를 박스 모양으로 시각화하는 그래프
- 5가지 통계 정보를 한눈에 볼 수 있도록 시각화
- 상단 경계
- 제 1사분위 값
- 중앙값
- 제 3사분위 값
- 하단 경계
- 데이터의 특성을 쉽게 파악할 수 있음
- 데이터의 분포
- 이상치(Outlier) 등
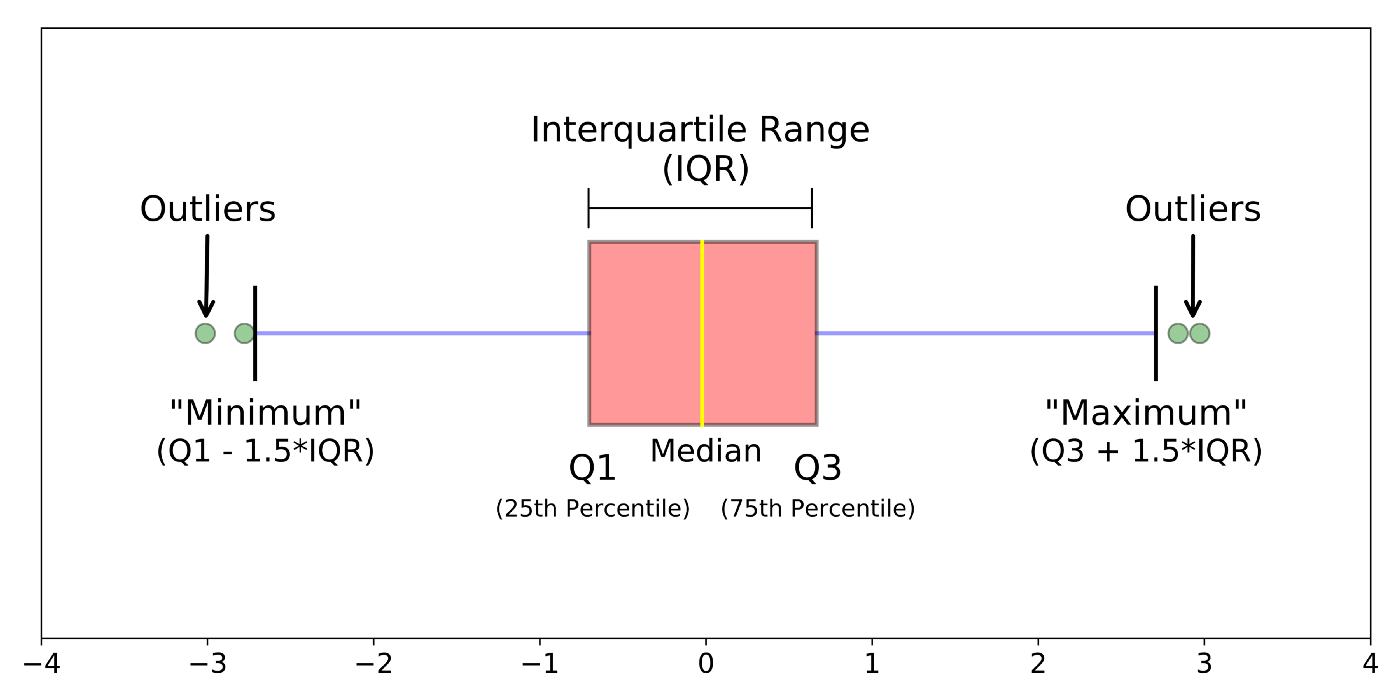
- Outlier
- 일반적으로 정상 데이터가 분포한다고 여겨지는 범위(상단 경계/하단 경계)를 벗어난 값을 갖는 값
- IQR(Interquartile range)
- Q3-Q1
- 데이터 분석 > 시각화 분석 > 시각화 선택
- 산점도
- 히트맵
- 박스차트
- 분포차트
- 워드클라우드
basic에서는 워드클라우드 X (워드클라우드: 문서 내 단어의 출현 빈도에 따른 시각화 방법)
1,2 → 두 개 이사으이 변수의 분포 및 상관관계
3,4 → 하나의 변수(또는 하나의 변수가 다른 범주구분 내)에서 분포를 표시
데이터 가공
데이터 전처리
결측치와 이상치 처리
- 결측치(Missing Value)
- 수집되지 않은 데이터 값
- 0이 아님!
- 결측치 처리 방법: 제거(drop) 또는 대체(fill)
- 데이터의 개수, 결측치의 비율, 중요도에 따라 결정
- 수집되지 않은 데이터 값
- 이상치(Outlier)
- 전체 데이터의 추세를 벗어나는 값을 가진 데이터 값
- 이상치 탐지(Outlier Detection) 및 이상치 처리 과정 필요
인코딩과 스케일링
- 인코딩(Encoding)
- Object 타입의 데이터를 수치형 데이터로 변환
- Label Encoding → 순서가 있는 데이터의 인코딩
- One-hot Encoding → 순서가 없는 데이터의 인코딩
- Object 타입의 데이터를 수치형 데이터로 변환
- 스케일링(Scaling)
- 변수간 학습 반영 비율이 수치 데이터의 범위에 영향을 받지 않도록 수치의 크기를 변환하는 과정
- Min-Max Scaler
- Standard Scaler
- Robust Scaler
- 변수간 학습 반영 비율이 수치 데이터의 범위에 영향을 받지 않도록 수치의 크기를 변환하는 과정
결측치 처리
- numeric
- most_frequent
- median
- mean
- constant
- category/object
- most_frequent
- constant
이상치 처리
- 전체 데이터의 패턴에서 벗어난 이상 값을 가진 데이터인 이상치(Outlier)는 분석 결과를 왜곡시킬 수 있으므로 제거하는 것이 좋음
basic에서는 안 나옴
스케일링
- 데이터셋을 구성하고 있는 특성(Feature)들이 서로 단위나 범위, 분포가 다르면 직접 비교하기 힘들고 모델 학습에 잘못된 영향을 줄 수 있으므로 스케일링(Scaling) 과정 필요
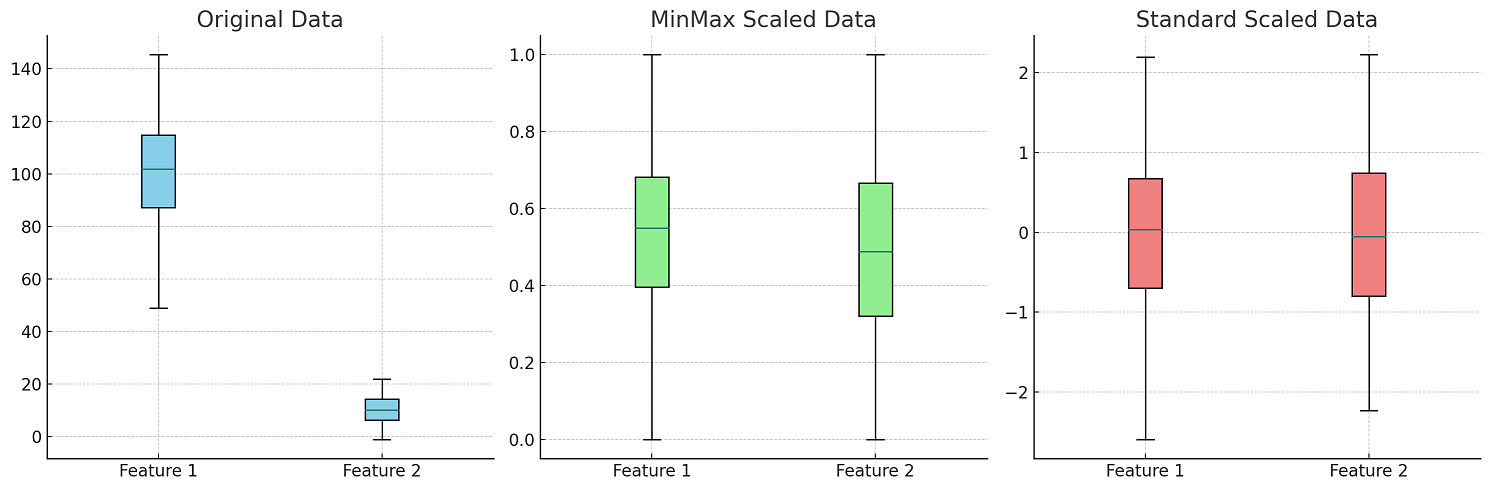
★
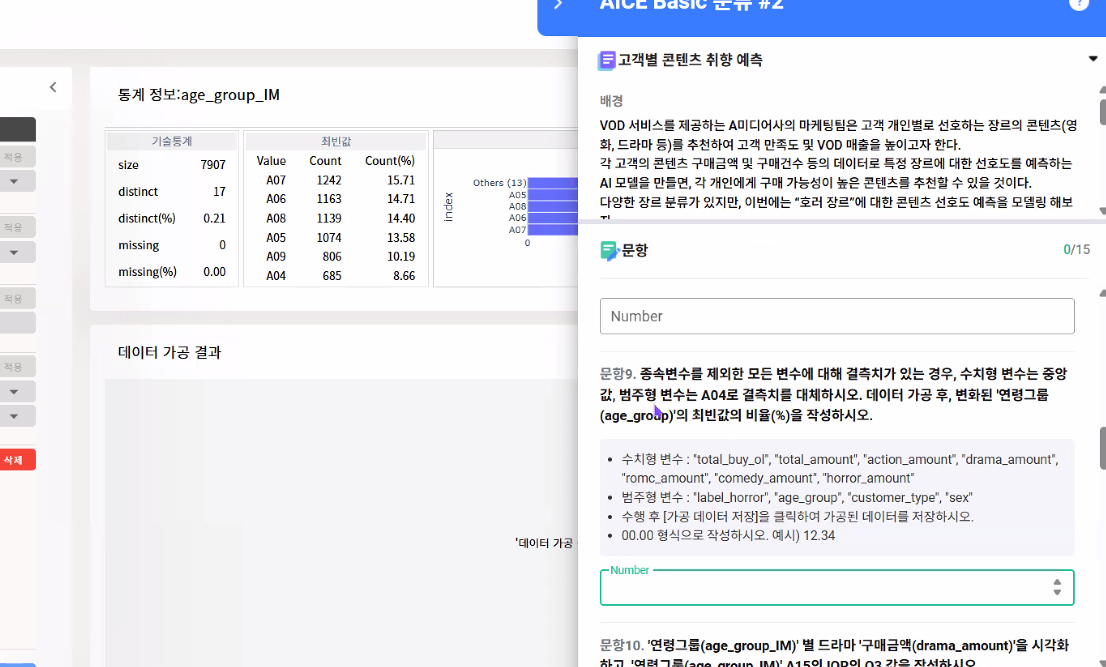
문항 9 답: 15.71
(해설지에는 8.66으로 잘못 나와 있음)
데이터 가공 후 반드시 가공 데이터 저장하기!
AI 모델링
AI 모델학습
- 정의된 문제에 대해 알고리즘 선택 → 학습 → 모델 저장 & 평가 → 개선
- 알고리즘 선택
- 해결하고자 하는 문제(회귀/분류)에 적합한 알고리즘
- 머신러닝/딥러닝
- 모델 학습
- 학습을 위한 데이터 선정 및 분할
- 파라미터 설정
- 모델 성능 평가
- 알고리즘 선택
알고리즘 선택
- 데이터 형태에 적합한 모델 선택
- 이미지
- 텍스트
- 테이블 등
- 예측하려는 결과가 수치 데이터/범주 값: 회귀/분류
- 목적이 '데이터에 대한 이해'인지 '결과 예측'인지
- 예측이 목적
- 날씨에 따른 아이스크림 판매량 예측
- 기상 데이터에 따른 강수 여부 예측
- 설명이 목적
- 백화점 고개의 매출에 따른 고객의 특성 이해 및 영향을 주는 요소 분석
- 예측이 목적
- 알고리즘 선택
- 머신 러닝 알고리즘
- Linear Regressio
- Decision Tree
- SVM
- KNN
- RandomForest
- LSM
- XGBoost
- DNN 등
- 머신 러닝 알고리즘
머신러닝 학습 시 알아야 할 내용: 분류
- 데이터 유형, Output 컬럼, 학습 유형 일치
- 학습 유형이 'Classification'인지 확인
- Category - object - Classification
- Numeric - int64 - Regression
- Output 컬럼에 Target이 들어가 있는지 확인
- 학습 유형이 'Classification'인지 확인
- 학습 데이터 비율 (데이터 분할)
- 교차 검증 방법 (Cross Validation)
- 교차 검증 fold 수 (k-fold에서 k값)
- 타겟 데이터 불균형 처리 (stratify)
- ML 모델 종류
분류모델의 평가지표
- 혼동행렬(confusion matrix)
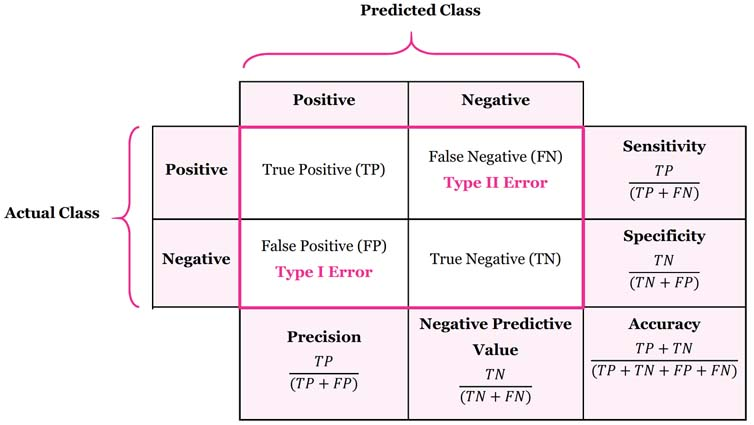
- 성능지표
- Accuracy(정확도)
- Recall(재현율)
- Precision(정밀도)
- F1 Score
- ROC 곡선과 AUC(Area Under Curve)
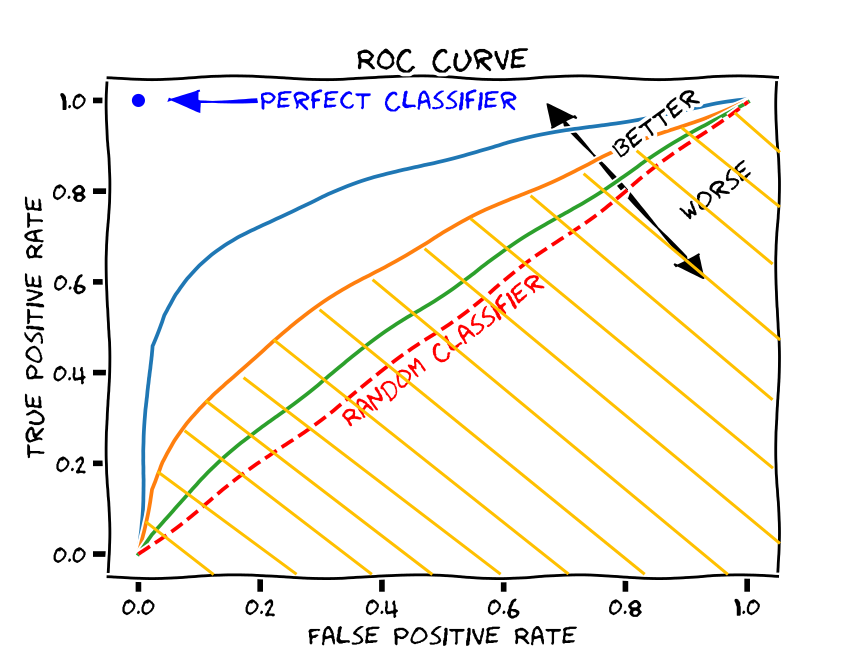
회귀모델의 평가지표
- 0에 가까울수록 성능 우수
- MAE(Mean Absolute Error; 평균절대오차)
- MSE(Mean Squared Error; 평균제곱오차)
- RMSE(Root Mean Squared Error; 평균 제곱근 오차)
- 1에 가까울수록 성능 우수
- Score 결정계수
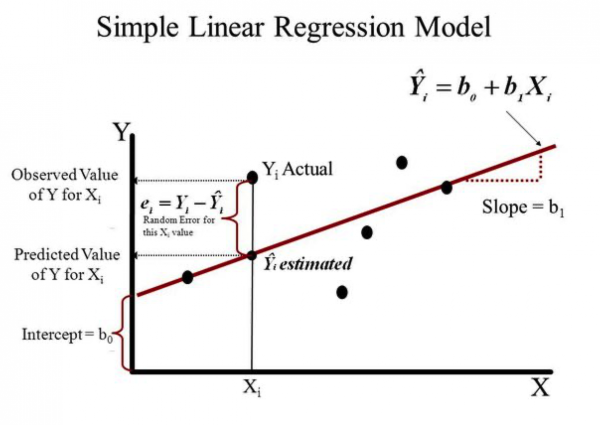
오차: 실제 값과 예측 값과의 차이()
→ 오차가 가장 적은 것이 좋은 모델
- 회귀 모델
- MAE, MSE는 작을수록 성능이 좋은 모델
- 는 1에 가까울수록 좋은 모델
- 분류 모델
- Accuracy는 1에 가까울수록 좋은 모델
딥러닝
활성화 함수(Activation Function)
- 학습에 '비선형성' 부여
- 생물의 신경 세포에서 신호가 전달되기 위한 역치를 넘는 값일 경우에만 다른 세포로 신호를 전달하는 것에 착안하여 도입
- 종류
- ReLU → 회귀모델
- Sigmoid → 이진분류
- tanh
- Softmax → 다중분류
핵심 구성요소
- 에포크(epoch)
- 전체 데이터를 한 번 훑어서 지나가는 것
- 배치(batch)
- 한 번의 파라미터 계산에 사용하는 데이터 개수
- 학습률(learning rate)
- 모델이 얼마나 빠르게 학습할지를 조절하는 파라미터
- 최적화기(optimizer)
- 손실 값을 줄이기 위한 가중치를 업데이트하는 방법을 기술하는 알고리즘
- 경사하강법을 기반으로 함
- adam, sdg, momentum, RMSProp 등
모델 성능 최적화
- 은닉층의 깊이를 더 깊게
- 과적합 주의
- 하이퍼파라미터 튜닝
- epoch, batch_size 등
- 성능 고도화 문제 나오면 대부분 epoch만 증가시켜도 성능 좋아짐
- epoch, batch_size 등
- 성능 향상과 함께 과적합을 방지하는 방법
- Drop-out(드롭아웃)
- 학습 단계에서 각 뉴런의 출력값(activation)을 임의로 0으로 만드는 방식으로 작동
- 특정 확률로 각 뉴런의 출력을 해당 미니배치 동안 0으로 만들어 신호 전파와 가중치 업데이트에서 제외시킴 → 활성화가 0이 되어 정보 전달 경로가 일시적으로 막힘
- 출력값을 0으로 만드는 행위를 비유적으로 '뉴런을 끈다', 'edge를 제거한다' 등으로 표현
- Early Stopping
- 검증 손실(validation loss)이 일정 횟수 동안 개선되지 않으면 학습을 조기에 중단하는 기법
- Drop-out(드롭아웃)
딥러닝 학습 시 알아야 할 내용
- 데이터 유형과 Output 컬럼 일치
- 분류
- Output 컬럼: object - 데이터 유형: category - 모델 유형: classifier
- 회귀
- Output 컬럼: int64 - 데이터 유형: numerical - 모델 유형: regressor
- 분류
- 활성 함수
- FC 레이어 수, FC 레이어 크기
- 드롭 아웃
- Epochs
- Batch Size
- Early Stop
- Optimizer
- Learning Rate
- 교차 검증 fold 수
https://huggingface.co/blog/manu/colpali
기업연계 프로젝트
DB 문서 작성
① 회원(테이블)은 회원ID, 비밀번호, 이름, 이메일, 역할(컬럼) 등의 정보를 입력하고 가입한다.
② 회원은 여러 제품(테이블)을 소유하거나 등록할 수 있다.
③ 회원은 여러 설치 공간(InstallationSpace) 정보를 등록할 수 있다.
④ 전자제품(제품)은 제조사, 모델명 등으로 구분된다.
⑤ 회원은 제품을 선택 후 질의응답(질문/답변 기록)을 남길 수 있다.
⑥ 관리자 및 기업 회원은 PDF 매뉴얼, FAQ, Q&A 데이터를 업로드·수정할 수 있다.
⑦ 회원은 자신의 활동 로그를 확인할 수 있다.
⑧ 각각의 PDF는 여러 버전과 언어로 관리된다.
⑨ 일반 고객은 제품별 부착된 QR 코드를 스마트폰으로 스캔하여 서비스를 이용한다.
⑩ QR 코드를 통해 제품 ID를 조회하며, 제품은 product_id로 식별(PK 제약조건)한다.
⑪ 일반 고객은 특정 제품에 대해 챗봇에 자연어 질문을 할 수 있으며, 챗봇은 사용자의 질문을 chat_message 테이블의 content 컬럼에 저장한다.
⑫ 하나의 챗봇 세션(chatbot_session)에는 여러 chat_message가 포함될 수 있다(1:N 관계).
⑬ 챗봇 답변은 chat_message 테이블에서 sender_type이 'bot'으로 구분되며, 답변에 대한 사용자의 평가(bot_feedback)는 메시지별로 하나 이상 저장될 수 있다(1:N 관계).
⑭ 제품과 연결된 manual 테이블에는 해당 제품 설명서 이력이 저장되며, manual_id가 PK다.
⑮ 일반 고객은 FAQ 테이블에서 자주 묻는 질문과 답변을 먼저 참조하며, FAQ는 제품별로 다대일(N:1) 관계를 가진다.
⑯ 일반 고객이 설치 공간 정보를 등록할 수 있으며, installation_space 테이블에 저장된다.
⑰ 설치 공간과 제품별로 시뮬레이션 결과(simulation_result)가 다대일(N:1) 관계로 기록된다.
⑱ 제품 상세 스펙은 product_specification 테이블에서 key, value 컬럼으로 관리되며, product_id와 연결된다.
⑲ 기업 고객과 관리자(user.role이 company 또는 admin)는 manual 업로드 및 문서 갱신(document_update_log)를 관리한다.
⑳ 질문 개선 또는 피드백은 query_feedback에 저장되며, 이는 원본 chat_message(query_id 참조)와 사용자를 FK로 연결하여 관리한다.
① 피드백 변경 이력은 feedback_history 회테이블에 기록되어, feedback_id와 변경자(changed_by)를 FK로 참조한다.
② 모든 테이블은 PK를 통해 고유 식별되며, 외래키(FK)를 통해 서로 논리적으로 연결되어 있다.
유형별 분기
사용자 입력에 따라 유형별 분기를 정확히 판별하기 위해서는 질문 분석 로직(클래스/모델/룰 기반 시스템)이 필요합니다. 최근에는 고정 룰과 함께 자연어 처리(NLP) 모델, LLM 활용을 병행하는 것이 실전에서 빠르고 정확합니다.
1. 키워드·패턴 기반 룰(정적)
- 명확히 잡히는 패턴/키워드(예: "설치", "공간", "크기" → 설치 공간, "추천", "비교" → 추천)
- 정규표현식, 사전 정의 키워드 리스트와의 매칭
2. 머신러닝/딥러닝 기반 분류
- 사전 구축한 데이터셋으로 다중 분류기(train/test): 예를 들면 BERT, DistilBERT, KoELECTRA 등 분류 fine-tuning
- 입력 문장에 대해 다중 클래스 softmax 결과로 "faq", "installation", "recommendation", "document_search", "composite" 중 선택
3. LLM 활용 룰
- 챗봇 프롬프트로 입력 질의를 분석하게 하여,
"아래 문장의 질의 유형을 분류해줘"등의 시스템/프롬프트 설계 - 예시 프롬프트:
사용자의 입력이 어떤 질문 유형인지 'faq', 'installation', 'recommendation', 'document_search', 'composite' 중 하나 또는 다수로만 알려줘. 입력: "우리집에 맞는 냉장고 추천해 줘" 출력: ["installation", "recommendation"] - 복합 유형 여러 개가 함께 반환되는 구조도 설정 가능
4. 하이브리드
- 키워드/정적 룰 + 모델 예측 + LLM 기반 판단 결과를 앙상블해서 신뢰도·정확도 보완
판별 로직 예시(파이썬-유사)
def classify_query_type(user_input):
if keyword_match(user_input, FAQ_KEYWORDS):
return "faq"
if keyword_match(user_input, INSTALLATION_KEYWORDS):
return "installation"
if keyword_match(user_input, RECOMMENDATION_KEYWORDS):
return "recommendation"
if is_document_search_needed(user_input):
return "document_search"
# LLM or ML 기반 복합 유형 판단
return llm_based_type(user_input)요약
- 키워드/정적 룰로 빠른 분기
- ML/NLP분류기로 의미 기반 자동 분류(특히 긴 문장, 복합 질의)
- LLM 프롬프트로 애매하거나 복수 유형 분기
- 결과 앙상블로 최종 "질문 유형"을 결정, 그 결과에 따라 각각의 세부 알고리즘 모듈 호출 및 데이터 저장
이 방식이면 질의 입력 성격에 따라 자연스럽고 강건하게 분기·처리가 가능합니다.
Algorithm
(음성/오프라인까지 고려한 ver. → 앱으로 구현해야 함)
이 프로젝트(문서 업로드, 임베딩, 벡터DB 기반 챗봇, 제품 추천, 설치 공간 분석, 음성 인식 등)는 많은 핵심 기능이 클라우드나 서버 기반 리소스(LLM 엔진, 대용량 벡터DB, 음성 인식 모델, 지속적 DB 동기화 등)에 크게 의존하기 때문에 완전한 오프라인 환경에서 작동하려면 상당한 제약과 추가 엔지니어링이 필요합니다.
오프라인 지원을 위해 필요한 주요 조건 및 한계
- 경량화 LLM 및 음성인식 엔진 로컬 배포: 고성능 PC/디바이스에 Huggingface Transformers, Whisper 등 오픈소스 모델 미리 설치 및 세팅 필요(속도와 리소스 한계)
- 로컬 DB 및 벡터 인덱스화: SQLite, local FAISS DB 등으로 메타/임베딩 데이터 미리 패키징해서 배포
- 파일 시스템과 UI 통합: 서비스 패키지를 단일 바이너리 또는 앱으로 만들어 사용자가 문서 업로드/조회/질문까지 모두 로컬에서 처리되게 구현
- 업데이트/새제품/기업정보 연동: 중앙 서버 업데이트 없이 신규 데이터 반영 불가(USB, 패치파일 등 별도 배포)
현실적 제약 및 타협점
- 최신 GPT-4, 상용 음성인식 API 등은 오프라인 사용 어려움(인터넷 연결 필요)
- 오픈소스 LLM·음성모델로 기본 QA, 안내, FAQ, 제품추천, PDF 질의는 가능(성능·품질 제한 있음)
- 일반적 통계, 로그, 자동 분석 등 백엔드 연계 서비스 기능 사용 불가
요약
- 기본형 챗봇 + FAQ/매뉴얼 질의 + 로컬 문서 임베딩 질의 + 설치 가능성 간이 판정 정도는 오프라인 패키징이 가능
- 고성능 LLM·음성 QA·실시간 데이터 업데이트 등은 오프라인 환경에서 제한됨
- 완전히 오프라인 지원하려면 기능 축소와 리소스 선반영 등 설계 전략이 필요
오프라인 구현이 중요한 환경이라면, 요구 우선순위를 명확히 하고 핵심 기능 위주로 경량화, 선반영 설계가 반드시 필요합니다.
실제 현장(공장, 시골, 해외, 군부대, 동네 서비스센터 등)에서는 인터넷 연결이 어렵거나 개인정보·보안 문제로 네트워크가 제한되는 경우가 많아,
PDF 기반의 사용설명서 자동검색, FAQ 안내, 제품 스펙 조회 등 핵심 기능이 오프라인에서도 작동한다면
고객 신뢰, 활용성, 산업 표준 대응력 모두 한 단계 업그레이드되는 서비스가 됩니다.
오프라인·표준형 프로젝트 방향 제안
- 모든 코어 기능(설명서·FAQ·제품 데이터 규격화)은 설치형 패키지로 제공
- 예: 제품별 임베딩 데이터, 벡터 인덱스, FAQ, 스펙을 USB/SD카드/로컬 PC에 모두 내장
- LLM/음성인식도 open-source 소형 모델로 배포 가능(성능 타협)
- 포맷 및 데이터 구조 표준화
- 제품 설명서, 스펙, FAQ 등은 구조화된 JSON/XML 등으로 변환해 저장
- 제조사·유통사·고객사 간 데이터 호환성을 극대화
- 네트워크 연결 시 업로드·분석 로그 동기화, 분리 작동 지원
- 온라인 환경에서는 지속 업데이트/피드백,
- 오프라인 서식은 필요할 때 동기화 가능
기대 효과
- 산업 현장, 긴급지원, 유통 지원에서 신뢰성과 실전성↑
- 데이터 호환, 유지보수, 다양한 기기 지원 등 표준화 이점↑
- 차후 글로벌·공공 표준 대응 등 확장성 보장
이 방향이면 단순 챗봇이 아니라,
B2B·B2G·산업·공공 레퍼런스가 가능한 차별화 플랫폼으로 성장할 수 있습니다.
접근성을 강화하고, 기술표준 관점에서도 높은 평가를 받을 수 있습니다.
1. 데이터 저장 방식
- 제품 정보/설명서/FAQ/스펙 등은 구조화된 테이블에 저장(제품, 스펙, 메뉴얼, FAQ 등)
- 표준화된 JSON 필드, 벡터 인덱스, 메타데이터 포함
- 사용자 입력(텍스트/음성)은 ChatMessage 및 VoiceMessage에 저장
- 질문 유형(FAQ/설치 공간/추천/임베딩 검색/복합)은 ChatMessageQueryType 및 유형별 세부 테이블에 저장
2. 질의응답 및 추천 알고리즘(핵심 로직)
-
QR/제품 입력
→ 제품 정보 조회, 관련 문서/DB 로딩 -
질문 처리 (텍스트/음성)
→ 챗 메시지, 음성 변환 결과 DB 저장
→ 질문 유형 자동 분류
a. FAQ 매칭
b. 문서 임베딩 검색
c. 설치 공간 연관
d. 제품 추천
e. 복합 유형 처리 -
유형별 분기 및 결과 생성
- FAQ: DB에서 정형 질의 매칭, 즉답
- 임베딩: 벡터DB에서 관련 문서 청크 검색 후 LLM 생성 답변
- 설치 공간: 공간 정보 + 제품 스펙 조건 검색, 설치 가능여부/추천
- 추천: 사용 환경, 공간, 선호 기준에 따라 제품 목록(스펙 기반 필터링/정렬)
- 복합: 위 기능 병렬 조합, 각 결과 통합/우선순위 추천
-
로그/피드백/사용 데이터 기록
→ 모든 Q&A/추천/설치 시뮬/기업 로그 UsageAnalytics 및 FeedbackHistory에 저장
→ 추후 분석/모니터링에 활용 -
오프라인 환경 고려
- 모든 주요 인덱스, 임베딩, 메타데이터, 모델을 로컬에 패키징
- 사용자는 앱/데스크탑에서 데이터 동기화 없이 즉시 기능 이용
3. 예시 알고리즘 핵심 코드/플로우(Py-like)
def handle_query(user_input):
query_type = classify_query_type(user_input)
if query_type == "faq":
return faq_lookup(user_input)
elif query_type == "installation":
space = get_install_space(user_input, user_id)
return recommend_installable_products(space)
elif query_type == "recommendation":
prefs = extract_preferences(user_input)
return recommend_products(prefs)
elif query_type == "document_search":
docs = get_related_docs(user_input)
return summarize_and_answer(user_input, docs)
elif query_type == "composite":
results = []
for qtype in extract_multiple_types(user_input):
results.append(handle_query_type(user_input, qtype))
return integrate_results(results)4. 설계 포인트
- DB 설계는 모듈화(엔티티별 분리, 적절한 연결)
- 알고리즘은 유형 분류 후 모듈별 병렬 처리, 통합 답변
- 즉각적 결과/로그 저장으로 분석성과 지속적 개선 가능
- 오프라인/온라인 환경 모두 동일 인터페이스로 작동할 설계
