목차
Ⅰ. 오전 수업
A. 1교시: JavaScript
1. 지난 시간 복습
- 객체
- 함수
- DOM(Document Object Model)
- 실습: 요소 가져오기
2. getElementById() 실습 1
B. 2교시: JavaScript
1. getElementById() 실습 1 (cont.)
2. getElementById() 실습 2
C. 3교시: JavaScript
1. getElementById() 실습 2 (cont.)
2. 이벤트 처리
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. 실습: Gmarket best 상품
B. 5교시
1. 실습: Gmarket best 상품 (cont.)
C. 6교시
1. Gmarket 실습 내용 정리
2. 실습: 이미지 수집 (포켓몬)
Ⅲ. CARRER UP
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시: JavaScript
1. 지난 시간 복습
- 객체
- 매우 중요한 개념임: JavaScript는 객체로 시작해 객체로 끝난다!
- 큰 덩어리를 하나하나 쪼개서 관리하는 개념
- 관리가 용이, 하나하나의 명령이 가능하다는 장점
- 데이터로서의 객체
- 하나의 큰 덩어리를 각각 key라는 의미가 다른 데이터로 쪼개서 관리 → 원하는 데이터를 어떤 형태이든 관리할 수 있음
- 다른 의미의 데이터를 관리하는 공간 → 값을 쪼개서 저장 → 의미가 다르다(여러 내용이 혼재됨)
- 필연적으로 복잡한 구조를 가짐 → 반드시 첫 번째는 출발지고 마지막이 목적지라는 것만 기억하자(나머지는 다 경유지일 뿐)
- 배열은 인덱스로 조회, 객체는 키로 조회
- 함수
- 자주 쓰는 기능들을 묶어서 관리하는 방법
- 정의 방식
- 함수 선언문: 함수가 정의되기 전에 호출해도 오류가 발생하지 않고 정상적으로 동작 → 호이스팅
- 함수 표현식: 함수 표현식은 함수 호이스팅이 일어나지 않음
- Function() 생성자 함수
- arrow function: ES6(ECMAScript 2015)에서 도입된 함수 표현식의 간결한 문법.
=>기호를 사용하여 함수를 정의. 자체적인 this 바인딩을 갖지 않고, 자신이 정의된 위치의 lexical scope의 this를 그대로 사용(화살표 함수 내부에서 사용되는 this는 함수가 정의될 때 결정되며, 함수가 호출될 때 동적으로 변경되지 않음)
// 함수 선언문(function statement)
function add_statement(x,y) {
return x+y
}
// 함수 표현식(function expression)
var add_expression = function(x,y) {
return x+y
};
// 함수 생성자(arg1,arg2,..,argN,본문)
var add_construction = new Function(‘x’,’y’,’return x+y’)
console.log(add_statement(1,2))
console.log(add_expression(1,2))
console.log(add_construction(1,2))
// 화살표 함수 (Arrow Function)
const multiply = (a, b) => a * b;
console.log(multiply(4, 6)); // 출력: 24
// 화살표 함수의 this에 관하여
const obj = {
value: 10,
getValue: function() {
return this.value;
},
getValueArrow: () => {
return this.value; // obj 객체가 아닌 전역 객체의 value를 가리킴
}
};
console.log(obj.getValue()); // 출력: 10 (obj 객체의 value)
console.log(obj.getValueArrow()); // 출력: undefined 또는 전역 객체의 value (브라우저 환경에서는 window.value)더 알아보기: 자바스크립트 함수를 선언하는 여섯가지 방법
- DOM(Document Object Model)
- HTML 문서를 태그, 속성, 컨텐츠 등 하나하나 쪼개서 관리하는 모델
- html이라는 큰 데이터를 쪼개서 관리하는 객체 형태의 모델
- html 문서를 하나의 통으로 된 텍스트 형태의 문서로 읽어오는 게 아니라 한번 읽은 다음 태그 속성 컨텐츠를 각 방에다가 따로 저장
- document: 모든 정보를 담고 있는 최상위 객체
- HTML 문서를 태그, 속성, 컨텐츠 등 하나하나 쪼개서 관리하는 모델
- 실습: 문서에서 아이디가 text인 요소 가져오기
- document.getElementById("text")
- 최종적으로 값을 꺼낼 때에는 키 값으로 접근:
.innerText- 객체는 키 값으로 조회! (특정 함수가 있는 경우도 있음)
- 실습: 컨텐츠 변경
- 대입(
=)하면 됨 - 수정할 때 쓸 수 있는 키워드 두 개: innerText, innerHTML
- 태그가 없을 경우에는 똑같이 동작
- 수집하려는 대상에서 태그가 포함되어 있다면 innerText는 인식 자체를 못하지만 innerHTML은 인식할 수 있음
- 대입(
- innerText vs. innerHTML
- innerText: 글자만 가지고 오고 싶을 때
- innerHTML: 값을 넣어 뭔가를 수정하거나 안에 컨텐츠를 추가할 때
- 태그를 인식하기 때문에 주의해야 함: XSS
- 사용자가 입력을 한다면 절대 사용하지 말 것
코드 리팩토링 할 때 이런 보안 이슈 신경쓰기
→ TIP: CursorAI나 코드를 담당하는 AI에게 보안 이슈 같은 거 잡아달라고 요청하기
- 복수개의 요소 가져오기: getElementsBy…
- 여러 개를 요청했으니 리턴도 여러 개 → "배열"? HTMLCollection!(유사 배열)
- 유사 배열 vs 배열
- 배열처럼 length와 index가 존재해 반복문 등과 같은 문법들은 다 활용이 가능
- 하지만 실제 배열은 아니기 때문에 map, filter, forEach 같은 배열 함수 사용은 불가능
- 쓰고 싶으면 배열로 형변환하기
2. getElementById() 실습 1
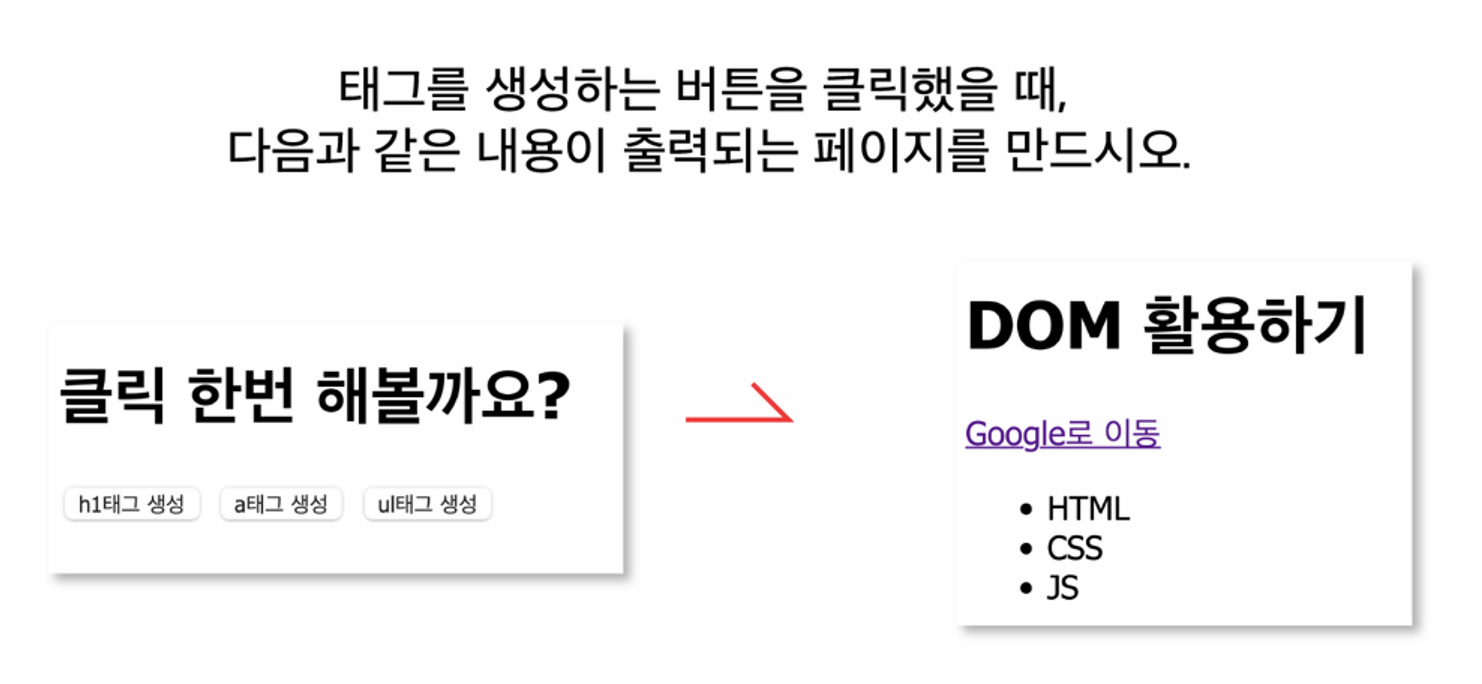
- div 한 개 만들기 (id="content")
- div 아래 버튼 3개 만들기
a. h1 태그 생성
b. a 태그 생성: 주의점 → href 속성 필수
c. ul 태그 생성: 주의점 → li 태그도 반드시 함께 써야 함 - 버튼 아래 script
- 실습 목표: 각각의 버튼을 클릭하면, 버튼에 맞는 태그를 포함한 요소를 div 태그에 넣기
- 주의점: 클릭할 때마다 사라지지 않고, 누적해서 나와야 한다.
- 필요 기능: 함수 3개 제작, 함수 연결(onclick), innerHTML, 복합대입연산자 +=
- 함수 1개로 만드는 기법도 있지만(forEach 문 응용) 복잡하니까 3개 만들기
- 현업에서는 1개로 처리함
- 핵심: 버튼을 클릭했을 때 div 안쪽의 innerHTML을 바꾸는 것
풀다가 막힌 부분 꼭 정리하기
코드 적다가 막히면 바로 생성형 AI한테 물어보지 말고 최대한 먼저 스스로 생각해보는 시간 가지기
- 풀이
- 큰 틀(버튼 3개, 함수 3개) 만들고 버튼과 함수 연결하기
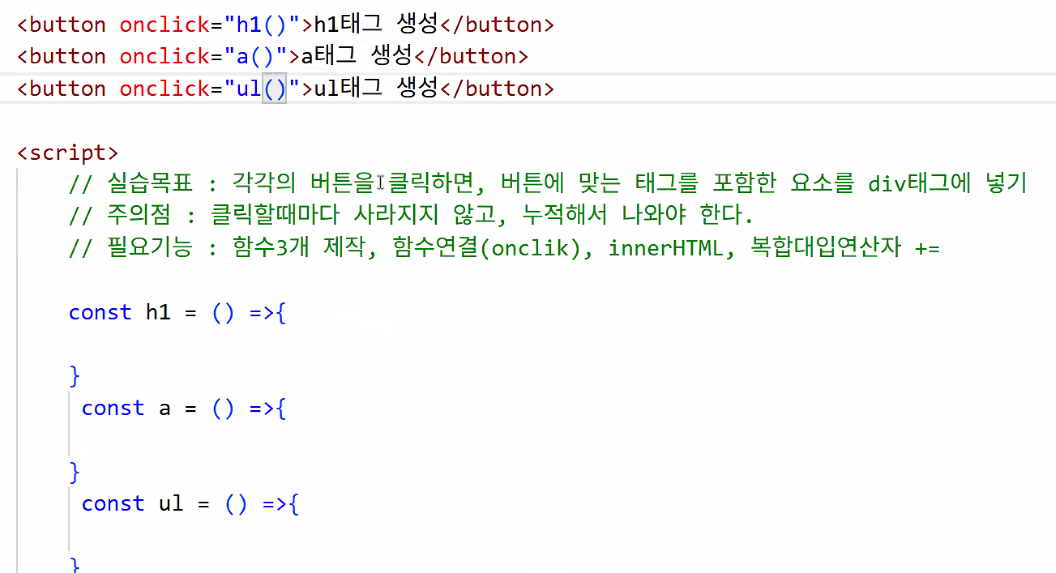
- div 안쪽 content 가지고 오기
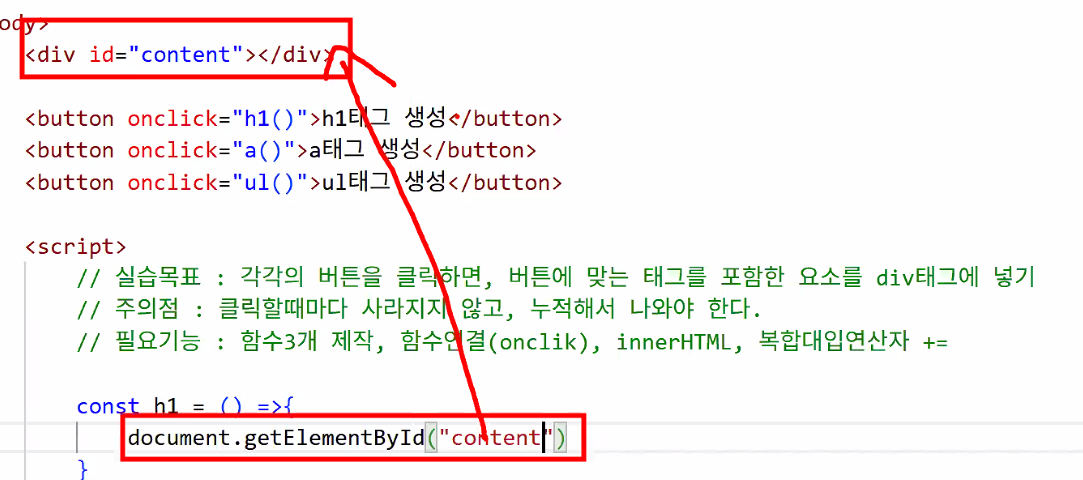
- 안의 문자열에 내용 넣기

- 내용이 쌓일 수 있게 복합 대입 연산자 사용하기

- 큰 틀(버튼 3개, 함수 3개) 만들고 버튼과 함수 연결하기
B. 2교시: JavaScript
1. getElementById() 실습 1 (cont.)
- a 태그 추가 함수 만들기
- 큰따옴표 안에 새롭게 문자열 표시하고 싶으면 작은따옴표 쓰기

- 큰따옴표 안에 새롭게 문자열 표시하고 싶으면 작은따옴표 쓰기
- ul 태그 추가 함수 만들기
- ul은 단일 태그가 아님! li와 항상 함께 써야 한다는 점을 기억하기

- ul은 단일 태그가 아님! li와 항상 함께 써야 한다는 점을 기억하기
- 개선 사항
- ul 태그 가독성이 안 좋음
- backtick(`) 사용하면 해결 가능! → 엔터로 문자 쪼갤 수 있음
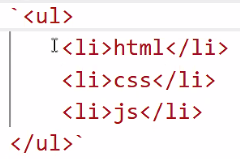
- 하지만 명령문과 넣고자 하는 내용이 분리되어 보기에 불편함 → 내용을 변수에 넣어서
document.getElementById("content").innerHTML += data;로 쓰기!

- backtick(`) 사용하면 해결 가능! → 엔터로 문자 쪼갤 수 있음
document.getElementById("content").innerHTML문장이 반복됨 → 반복되는 요소(document.getElementById("content"))를 변수에 저장하기- 영역을 나눠서 작업 → 코드의 그룹화(블록화): 변수 관리 영역, 요소 저장 영역, 실행 로직 영역 → 관리가 용이
- ul 태그 가독성이 안 좋음
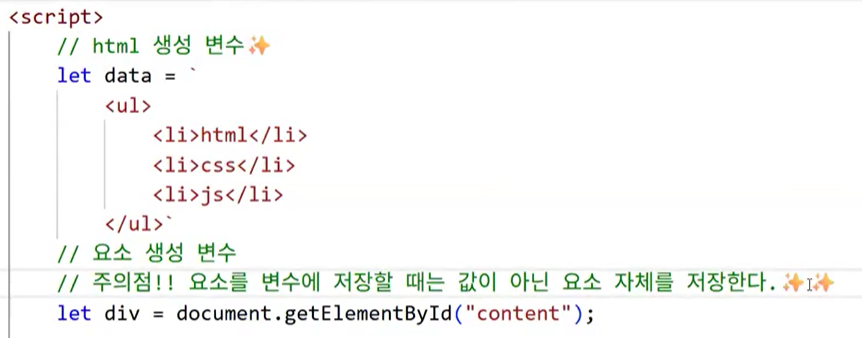
- 주의 사항 ★★★
- 요소를 변수에 저장할 때는 값이 아닌 요소 자체를 저장한다.
- 값 자체를 가져오면 로직 성립 자체가 안 됨(
"" += "<h1>h1 태그입니다.</h1>"→ 성립되지 않는 로직)- div = document.getElementById("content")
- div 요소 자체(=DOM 객체)를 변수에 저장
- 이후 div.innerHTML을 사용해서 요소의 내용을 조작할 수 있음:
div.innerHTML += h1_data;
- 기존 내용 뒤에 새 HTML 코드를 누적해서 추가할 수 있음
- div = document.getElementById("content").innerHTML
- div 영역의 "내용"(문자열)만을 변수에 저장
- 즉, 실제로는 HTML 요소가 아니라 "텍스트(문자열)"가 저장 → 이후
div += h1_data;를 하면 단지 문자열을 변수에 덧붙이는 것뿐이고, 화면에 아무런 변화가 일어나지 않음: DOM 요소에 접근한 것이 아니기 때문- 좀 더 자세한 원리
- innerHTML은 HTML 요소의 "속성(property)"으로, 해당 요소의 '내용'을 의미
- div = document.getElementById("content")
- div라는 변수가 실제 브라우저에 존재하는
<div id="content">를 가리킴- div.innerHTML을 쓰거나 += 연산을 하면 실제 화면의 내용을 바꿀 수 있음
- div = document.getElementById("content").innerHTML
- div라는 변수에는 현재 화면에 들어있는 "문자열(HTML로 되어있는 텍스트)"만 들어 있음
- div += h1_data 는 이 변수값을 단순히 이어붙이기만 하고, 실제 element에는 아무 효과가 없음
- 결론
- 화면에 변화를 주려면 '엘리먼트 객체' 자체를 변수에 담고, innerHTML을 이용해 조작해야 함
- innerHTML 속성만 변수에 담으면 그건 단순한 문자열일 뿐, 화면에 적용되지 않음
핵심 차이점 요약
| 할당 방식 | 저장되는 값 | 누적 가능? | 화면에 영향? |
|---|---|---|---|
| 요소 객체(div) | DOM Element | innerHTML += ...로 누적 출력 | O (화면 변화) |
| 내용(innerHTML) | String(내용) | 그냥 문자열 누적 | X (화면 변화X) |
나중에 이런 것까지 실습할 예정

2. getElementById() 실습 2
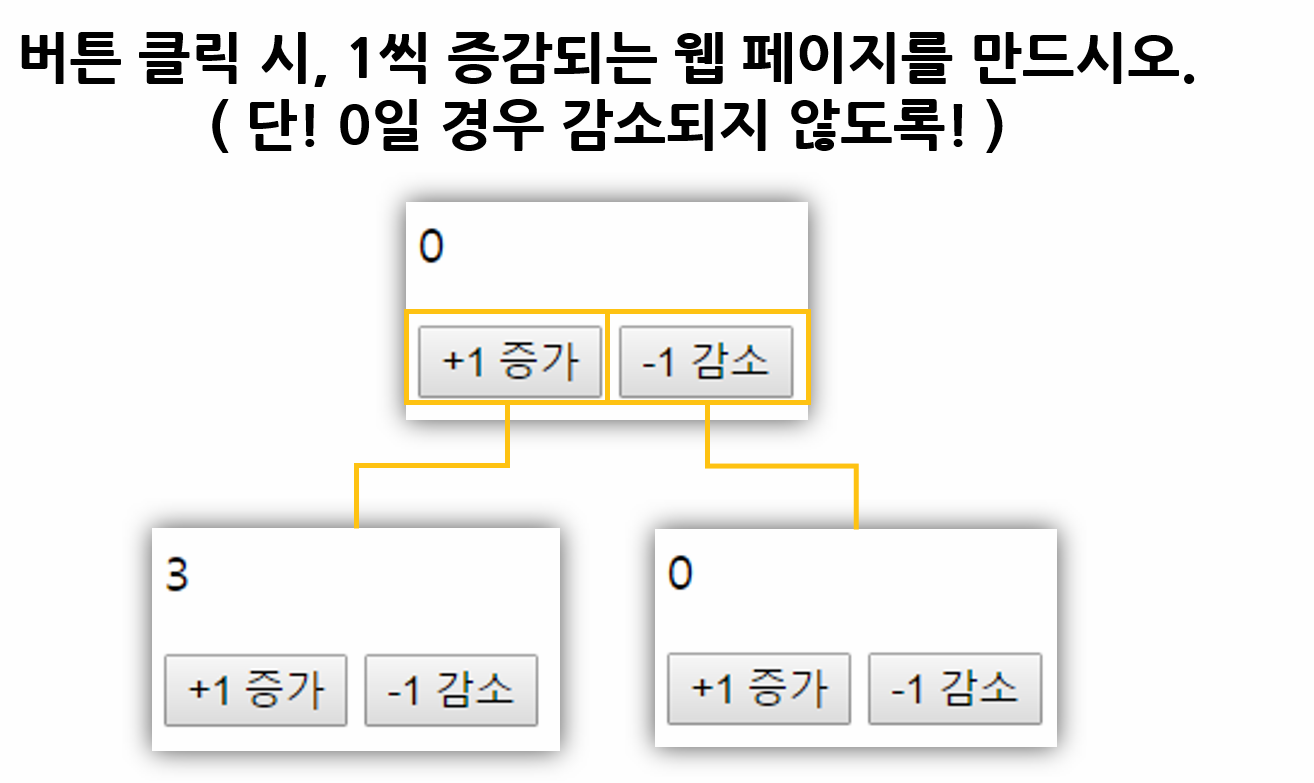
- 실습 목표: 각각 버튼을 눌렀을 때, p 태그의 값을 +1 또는 -1한 값을 반영해보자.
- 조건: 숫자는 0 이하로 내려가지 않는다(마이너스는 없다).
- 필요 기술: 함수 2개 제작, 함수 연결, innerText, Number(), 조건문
항상 껍데기 먼저 만들고(큰 틀 먼저) 그 후에 기능을 추가하기
작성한 코드가 작동이 안 되는 것 같으면 가장 먼저 개발자 도구의 "콘솔창" 확인하기
★오류를 최소화하는 코드 작성 습관을 기릅시다★
- 버튼에 함수 연결하기
- 함수 내용 작성하기
- 덧셈

- 뺄셈

- 코드 가독성을 위한 변수 할당
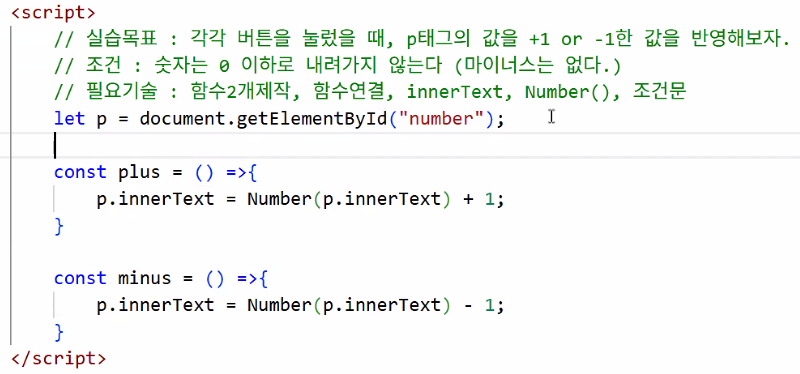
- 덧셈
C. 3교시: JavaScript
1. getElementById() 실습 2 (cont.)
- 조건 추가하기: 0일 경우 감소되지 않도록
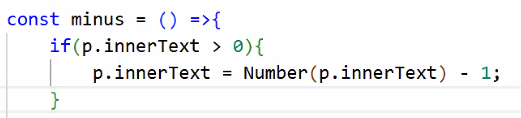
- 주의: 성립하지 않는 연산을 사용(문자열과 숫자를 비교)했을 때 자바스크립트는 자동으로 문자를 숫자로 형변환시켜 동작하기 때문에 위처럼 작성해도 작동은 됨
- 하지만 작성 시 아래처럼 의미가 명확하게 표현하는 게 권장 사항

- 하지만 작성 시 아래처럼 의미가 명확하게 표현하는 게 권장 사항
- 반드시 의미가 명확하게 코드를 짜 주기: 정확하게 표현을 하자! (권장 사항)
- 주의: 성립하지 않는 연산을 사용(문자열과 숫자를 비교)했을 때 자바스크립트는 자동으로 문자를 숫자로 형변환시켜 동작하기 때문에 위처럼 작성해도 작동은 됨
TIPS
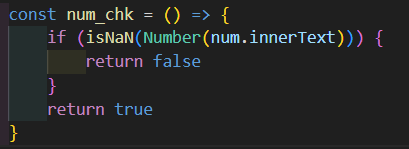
innerText 조작 예방 : 버튼 클릭 전에 값이 올바른 숫자인지 확인하고 싶을 때, 혹은 입력값 검증이 필요할 때 안전장치 역할로 활용하면 좋음
→ num이라는 변수에 들어있는 요소(num.innerText)의 값이 숫자인지 아닌지 확인
→ num.innerText는 해당 요소의 텍스트 내용을 가져옴:<p id="number">0</p>라면 "0"이라는 문자열을 가져오게 됨
→ Number() 함수는 이 문자열을 숫자로 변환: 만약 "10"이면 숫자 10, "abc"면 NaN(Not a Number)
→ isNaN()는 "파라미터가 숫자가 아닌 경우(true), 숫자인 경우(false)"를 반환
→ 만약<p id="number">이십</p>처럼 숫자가 아닌 텍스트가 들어가 있을 때 이 함수를 통해 유효성 검사를 할 수 있음
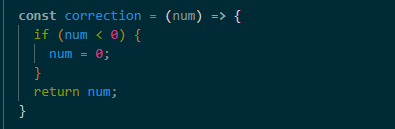
0보다 작을 경우 강제로 0으로 반환하는 보정 함수 : 받은 num 값이 음수(0보다 작을 때)면 0으로 바꾸고, 그렇지 않으면 그대로 값을 반환
→ 만약 인자인 num이 0보다 작으면, 내부에서 값을 0으로 바꾸고 그 값을 반환
→ 숫자 값이 "0 이하로 내려가면 안 된다"는 규칙을 강제하기 위해 사용합니다. 만약 실수로 -1, -10 같은 값이 되더라도 무조건 0으로 돌려주기 때문에 값이 음수가 되지 않음
→ 카운터 UI, 점수판, 재고 등 "최소값이 0"이어야 하는 기능에서 값을 보정할 때 사용
2. 이벤트 처리 ★
- 인라인 방식
- 태그 안에 직접 JS를 연결하는 방식

- 단점
- 함수명 노출: 인라인 방식 == 라인에 쓴다 → 개발자 도구에서 보인다
- 가독성이 떨어짐 (HTML 코드 안에 직접 JS가 들어감 → 역할 분리가 되지 않음 & 노출)
- 장점
- 처리가 빠름
- 사용처
- 간단한 함수 처리 (중요하지 않은 함수, 핵심 로직이 아닌 함수를 쓸 때)
- 내장 함수 활용 시 (alert 등 → 누구나 아는 코드니까 괜찮음)
- 태그 안에 직접 JS를 연결하는 방식
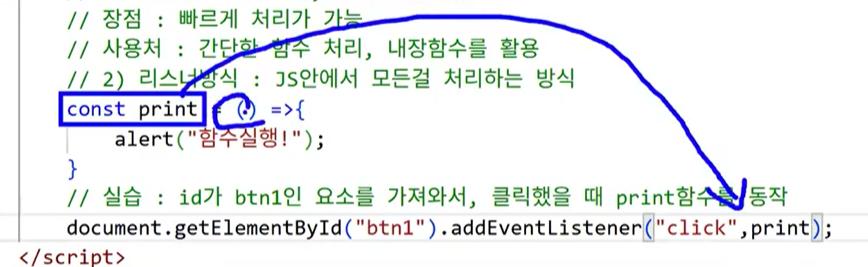
- 이벤트 리스너 방식:
addEventListener()★★★- JS 안에서(스크립트 영역에서) 모든 걸 처리하는 방식
- 가장 대중적으로 사용
- 실습: id가 btn1인 요소를 가져와서, 클릭했을 때 print 함수를 동작
- 주의점: 제작한 함수를 연결할 때는 함수의 이름만 작성 → 자바스크립트는 () 만나면 실행을 해 버린다.
- 아래와 같이 작성한 경우 함수 뒤
()가 실행하라는 의미라서 우리가 버튼을 안 눌러도 자동 실행되어버림

- 정확하게 다시 작성: 괄호 빼기

- 실행은 상수 print가 호출되면 함수가 동작함
- 아래와 같이 작성한 경우 함수 뒤
- 인라인 방식에는 소괄호가 있는데 실행이 안 되잖아요 → 거기는 HTML 영역이기 때문: HTML에는 함수 실행 개념이 없음!
- 자바스크립트는 함수 실행 베이스라서 소괄호 넣으면 자동 실행되지만 HTML은 실행 개념이 없어서 소괄호 넣어줘야 동작함
- 아니 그럼 매개 변수 전달은 어떻게 하죠? → 이 방식으로는 매개 변수를 담을 수 없음(매개변수 전달 불가)
- 위 방식은 매개 변수가 없는 함수만 사용할 수 있어요
- 매개 변수 전달하고 싶으면 익명 함수를 이용해야 함
- JS 안에서(스크립트 영역에서) 모든 걸 처리하는 방식
- 익명 함수
- 익명 함수: 함수의 이름을 정의하지 않는다 → 다른 곳에서 부를 수 없다 → 하나의 태그에게만 붙일 때 사용

- 사용처
- 특정 함수를 한 번만 연결할 때
- 매개 변수를 포함한 함수를 호출할 때: 콜백 함수(callback function)
- 함수 안에 함수를 넣는 개념
- 자바스크립트에서 매개 변수를 바로 함수로 전달해버리는 순간 함수가 실행이 되기 때문에 이 실행을 한번 막고자 껍데기를 씌우는 것
- 익명 함수: 함수의 이름을 정의하지 않는다 → 다른 곳에서 부를 수 없다 → 하나의 태그에게만 붙일 때 사용
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- Selenium 라이브러리
- 자동화 수집 도구
- requests 라이브러리(브라우저를 대신해 페이지 정보를 요청, 응답)가 가지는 한계: 페이지가 변경되면 매번 페이지 주소를 다시 줘야 함 → 정적 수집 도구(조작==동적 기능이 없음)
- Selenium은 브라우저 조작 기능을 하게 해 주는 라이브러리임
- 클릭, 입력, 스크롤, 화면 전환 등 사람이 하는 행동을 똑같이 가능하게 해 줌
webdriver: 컴퓨터용 브라우저 → 데이터 요청, 응답, 화면 조종, 관제 담당By: 선택자 구분 시 사용하는 라이브러리 (selenium.webdriver.common.by에 있음)Keys: 컴퓨터용 키보드 → ENTER, DEL, END 등 키보드 기능을 담당 (selenium.webdriver.common.keys에 있음)- 사람이 하는 행동을 코드로 작성해 주면 됨: 웹 브라우저 열기, 검색창 위치 찾기(태그 이용해 알려줘야 함), 검색창에 키워드 입력하기, 엔터 키 누르기(
search.send_keys(Keys.ENTER)), 뒤로 가기(driver.back()) 등- 주의: 뒤로 가기, 종료(창 닫기) 등 html 구조가 아닌 웹 브라우저 자체 기능은 driver에게 직접 요청
- 자동화 수집 도구
- time 라이브러리
- 쉬는 쉬간을 줘서 코드 실행이 마치 사람이 하는 것처럼 보이게 도와주는 역할
- 페이지가 열린 후 로딩 시간을 기다려 줄 때도 사용
- 이미지가 많은 페이지는 time.sleep 해 줘야 이미지까지 모두 수집 가능 (이미지 로딩 중간에 수집되면 이미지 잘려서 저장됨 → 수집 기준이 수집 당시 웹 브라우저 화면에 열려 있는 모습이기 때문)
- 더 보기 버튼 누르기: 반복문, 예외 처리 알고리즘
2. 실습: Gmarket
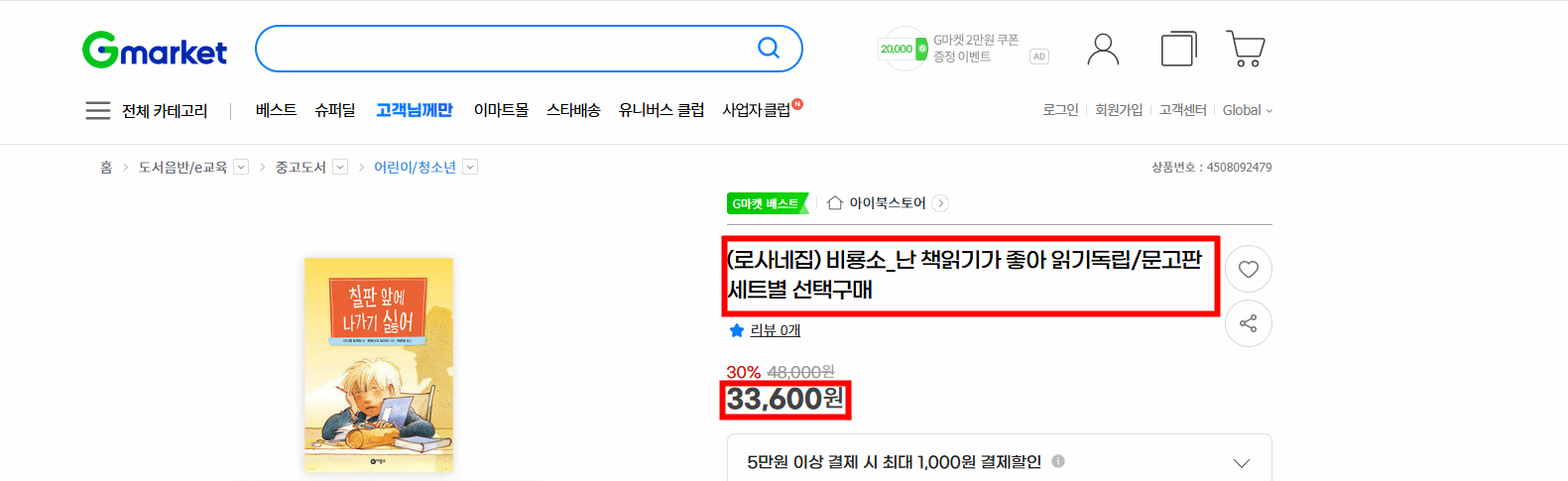
학습 목표
- Gmarket best 상품의 상품명, 가격 수집
- 1-10번의 상품을 클릭하여 들어가 수집 → 10개의 상품을 반복 작업 진행
- 1번 상품의 리뷰 데이터 수집
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
import time
import pandas as pd
# 1. 사이트 접근
url = "https://www.gmarket.co.kr/n/best"
driver = wb.Chrome()
driver.get(url)
time.sleep(1)
# 2. 첫 번째 상품 위치 전달
# 첫 번째, 두 번째, 세 번째까지도 가져올 수 있도록 작성
# 첫 번째 상품 절대 경로: #container > div.box__best-list > ul > li:nth-child(1) > a
# 두 번째 상품 절대 경로: #container > div.box__best-list > ul > li:nth-child(2) > a
item = driver.find_elements(By.CSS_SELECTOR, "#container > div.box__best-list > ul > li > a")
# 3. 첫 번째 상품 클릭
item[0].click()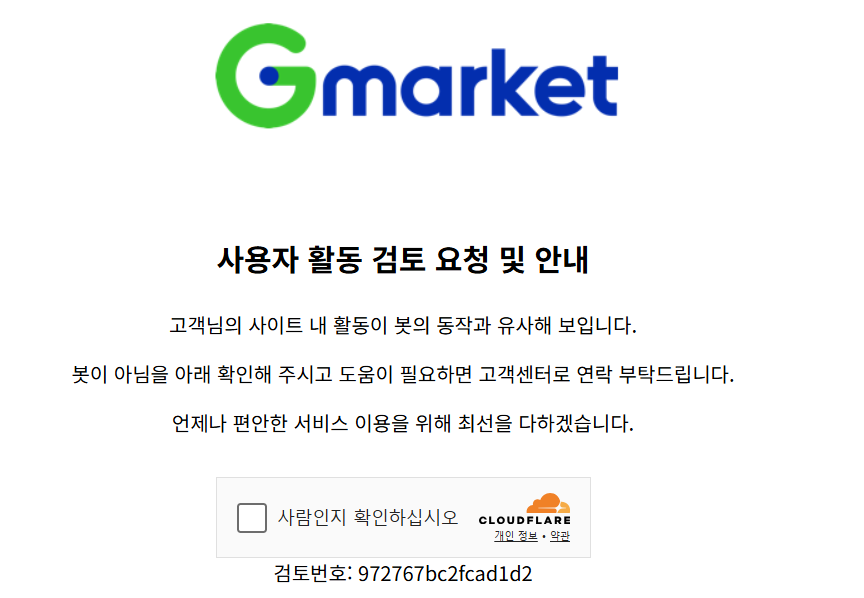
- Selenium으로 페이지 접근 시 로봇 동작으로 인식되어 제한당한 경우
- 최근 데이터의 보안이 강화 추세 → 서버 공격, 데이터 보안 등
- 로봇으로 감지되지 않는 크롬 드라이버 → undetected-chromedriver 설치 필요
%pip install -q undetected-chromedriver
import undetected_chromedriver as uc
# 사이트 접근
driver = uc.Chrome()
driver.get(url)
# 상품 위치 전달
item = driver.find_elements(By.CSS_SELECTOR,"#container>div.box__best-list>ul>li>a")
# 첫 번째 상품 클릭
item[0].click()
# 상품의 이름과 가격(할인 적용 후) 수집
title = driver.find_element(By.CSS_SELECTOR,"#itemcase_basic > div > div.box__item-info > h1")
price = driver.find_element(By.CSS_SELECTOR,"#itemcase_basic > div > div.box__price.price > span:nth-child(3) > strong")B. 5교시
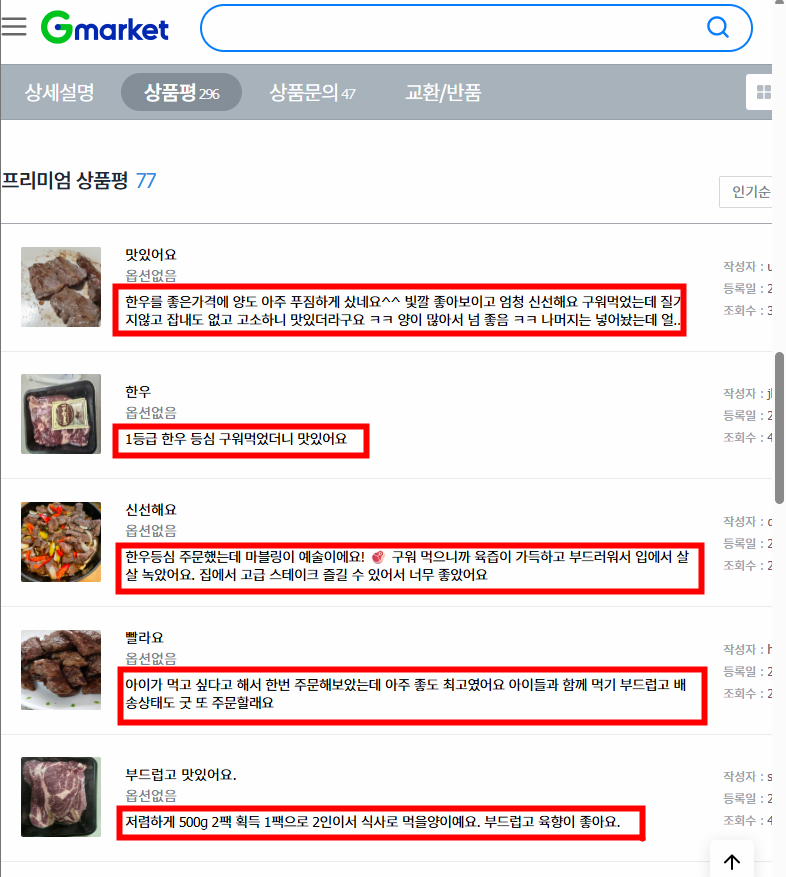
1. 실습: Gmarket (cont.)
- 10개의 상품명, 가격 수집하는 코드 작성
C. 6교시
1. Gmarket 실습 내용 정리
- Gmarket best 상품 페이지의 데이터를 가져와 상품의 상품명과 가격을 수집
- 1번부터 10번까지의 상품을 클릭해 10개의 상품명과 가격 가져오기
- 로봇 동작으로 인식되어 페이지 접근을 제한당했을 때 대처법
- selenium webdriver 대신 undetected-chromedriver 사용하기
- 1번 상품의 리뷰 데이터 수집
- 페이지를 넘겨가며 리뷰 데이터를 많이 수집하기
- 다음 페이지(11번=20번)까지 넘어가서 총 100 페이지까지 수집
- span 태그보다는 a 태그로 가져오는 게 좋다
# 다음 10개 페이지 출력하기
# #premium-pagenation-wrap > div.board_pagenation > a.next
driver.find_element(By.CSS_SELECTOR,"#premium-pagenation-wrap > div.board_pagenation > a.next").click()- 이걸 반복문으로 크게 묶어주면 됨
- 리뷰가 100페이지가 안 되는 경우도 있으니 try-except 문을 사용
- 작업이 끝나면 "모든 페이지를 수집하였습니다" 출력되도록
# 리뷰 데이터에서 다음 페이지 버튼을 눌러 많은 양의 리뷰 데이터 수집하는 코드
# 반복문 활용
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import time
import pandas as pd
# 사이트 접근
driver = uc.Chrome()
driver.get("https://www.gmarket.co.kr/n/best")
time.sleep(1)
# 상품 위치 전달
item = driver.find_elements(By.CSS_SELECTOR,"#container>div.box__best-list>ul>li>a")
# 첫 번째 상품 클릭
item[0].click()
time.sleep(1)
# 상품평 클릭
review = driver.find_element(By.CSS_SELECTOR,"#container > div.vip-tabwrap.uxetabs > div.vip-tabnavi.uxeposfix > ul > li:nth-child(2) > a")
review.click()
time.sleep(1)
review_list = []
for chunck in range(2): # 최대 세트 수
for i in range(10):
page_num = driver.find_elements(By.CSS_SELECTOR,"#premium-pagenation-wrap > div.board_pagenation > ul > li > a")
try:
page_num[i].click()
time.sleep(2)
rv = driver.find_elements(By.CSS_SELECTOR,'#premium-wrapper > table > tbody > tr > td.comment-content > a > p.con')
for j in rv:
review_list.append(j.text)
except:
# 해당 chunck의 페이지 수가 부족할 경우
print("모든 페이지를 수집하였습니다.")
break
try:
# 마지막 chunk가 아니라면 '다음' 버튼 누르기 (다음 10개 페이지 출력)
next_btn = driver.find_element(By.CSS_SELECTOR,"#premium-pagenation-wrap > div.board_pagenation > a.next")
next_btn.click()
time.sleep(2)
except:
# 다음 버튼이 없는 경우 (더 이상의 페이지 없음)
print("모든 페이지를 수집하였습니다.")
break # 반복 종료
driver.quit()
len(review_list)1002. 실습: 이미지 수집 (포켓몬)
학습 목표
- 자동화 도구 selenium 라이브러리를 통하여 포켓몬 이미지 데이터를 수집
- 많은 양의 이미지 데이터를 수집해보자!
- 이미지의 주소를 저장하여 관리하기
- '뉴스 데이터 수집' 실습 참고
- 이미지를 로컬 환경에 이미지 형태로 저장할 수 있다
- os 라이브러리를 이용한 자동 폴더 생성, 폴더명 지정
- os: 파일 관리 시스템(Operating System)의 약자
- os 라이브러리를 이용한 자동 폴더 생성, 폴더명 지정
라이브러리 불러오기
- urllib 라이브러리
- 이미지의 경로 → 이미지 파일로 변환 후 저장해 주는 라이브러리
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import os
from urllib.request import urlretrieve저장 경로 설정
- os 라이브러리를 통하여 바탕 화면에 "포켓몬" 폴더 생성:
os.mkdir("경로")- 윈도우 기준으로 문자열로 절대 경로를 작성할 때
\\두 번 작성해야 함\는 이스케이프코드이기 때문
- 두 번 적기 싫으면 /로 쓰면 됨
- 윈도우 기준으로 문자열로 절대 경로를 작성할 때
os.makedirs("C:/Users/내 PC/Desktop/Pokemon")- 위 코드의 문제점: 파일이 존재하는 상태에서 코드가 실행되면 에러 발생
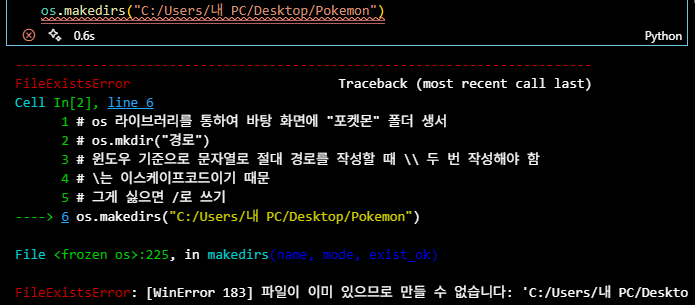
- 예외 처리하는 코드를 작성해보자
예외 처리(조건문 활용)
- 만약 현재 경로에 동일 이름 폴더가 없으면 생성하고 있으면 '폴더 존재'라고 출력
if not os.path.isdir("C:/Users/내 PC/Desktop/Pokemon"):
os.makedirs("C:/Users/내 PC/Desktop/Pokemon")
print("폴더 생성 완료")
else:
print("이미 폴더가 존재합니다!")selenium
# 브라우저 열기
driver = wb.Chrome()
url = "https://www.pokemonkorea.co.kr/pokedex#pokedex_1"
driver.get(url)
# 이미지 데이터 태그 정보 수집하기
img = driver.find_elements(By.CSS_SELECTOR, "div.img > div > img")
# 수집된 데이터 개수 확인
len(img)18- 이미지별 절대 경로 확인
- 1번 이미지:
#\#pokedex_1 > a > div.img > div > img - 2번 이미지:
#\#pokedex_2 > a > div.img > div > img - 3번 이미지:
#\#pokedex_3 > a > div.img > div > img - 굳이 전체를 가져와서 1,2,3을 반복문으로 처리할 필요 없이 뒷쪽 반복되는 부분만 가져와서
find_elements하면 모든 데이터를 가져다가 사용할 수 있음
- 1번 이미지:
- 수집된 데이터가 왜 18개뿐일까?
- 현재 데이터에 로딩된 데이터만 수집이 가능하기 때문!
- 브라우저를 제어할 때에는 내 현재 페이지에서 보이는 만큼만 가져와진다
- 포켓몬 도감 페이지는 스크롤을 내리면 데이터가 로딩된 다음 이미지가 늘어나는 구조임
- 많은 데이터를 수집하기 위해서는 스크롤을 진행해 많은 데이터를 로딩해 주어야 함
- 현재 데이터에 로딩된 데이터만 수집이 가능하기 때문!
스크롤
- 키보드로 스크롤 내리는 방법은 다양함
- 아래 화살표 키
- PgDn
- 스페이스 바
- End
- 우리는 End 사용 (가장 하단으로 많이 내려가기 때문)
- 그런데 End 키를 누구에게 보내줘야 할까?
- 강아지/고양이 검색 실습에서는 검색창의 태그 정보를 드라이버에게 알려주고 거기에 send_keys 했었음
- 화면을 내려야 하는데 누구에게 이 화면을 보내줘야 할까? → 전체 페이지를 관장하는 페이지: body 태그
# 페이지의 전체를 관장하는 Body 태그에 end 키보드 전송하자!
body = driver.find_element(By.CSS_SELECTOR,"body")
body.send_keys(Keys.END)
# end 키 입력 반복!
# 드라이버에게 body 태그 알려주기
body = driver.find_element(By.CSS_SELECTOR,"body")
# 스크롤 끝까지 내리는 코드도 있지만 실습 편의를 위해 20번만 내리기
for i in range(20):
body.send_keys(Keys.END)
time.sleep(1)
img = driver.find_elements(By.CSS_SELECTOR, "div.img > div > img")
len(img)378이미지 주소 저장
- selenium 활용한 속성명 추출 방법 →
요소.get_attribute("속성명")img[0].get_attribute("src")- 실행 결과: 'https://data1.pokemonkorea.co.kr/newdata/pokedex/mid/000101.png'
- cf. bs 파싱 후 속성명 추출 방법 →
요소["속성명"]
{kind=link}
이미지를 파일로 저장
- 이미지 경로를 활용하여 로컬 폴더에 이미지를 파일로 저장하기
urlretrive(이미지 주소, "저장 경로/파일이름.jpg")함수 사용
urlretrieve(img[0].get_attribute("src"), "C:/Users/내 PC/Desktop/Pokemon/test.jpg")('C:\\Users\\내 PC\\Desktop\\Pokemon\\test.jpg',
<http.client.HTTPMessage at 0x1beb6827290>)# 반복문 써서 수집한 이미지 데이터 전체 파일로 저장하고 드라이버 종료하기
for i in range(len(img)):
urlretrieve(img[i].get_attribute("src"), f"C:/Users/내 PC/Desktop/Pokemon/{i}.jpg")
driver.quit()Ⅲ. CARRER UP
- 수업 내용 복습 & 미니 프로젝트 진행
Ⅳ. 하루 돌아보기
👍 잘한 점
- 수업에 적극적으로 참여
- 질문 많이 했음
👎 아쉬웠던 점
- 미니 프로젝트 모델 학습 결과가 생각보다 안 나왔음
- 복습하는데 내용 정리를 좀 중구난방으로 하는 것 같음
🔬 개선점
- 효율적인 내용 정리 방안 생각해보기
