SQL CodeKata 관련
- WINDOW FUNCTION (참고 1, 참고 2)
- 기본 형태
함수(함수_적용_열) OVER ( PARTITION BY 그룹열 ORDER BY 순서열 )- 그룹 내 순위(RANK) 관련 함수
- RANK
: 중복 가능 순위
공동 순위만큼 건너뜀 - DENSE_RANK
: 중복 가능 순위
동일한 순위는 하나의 순위로 취급
공동 순위가 있더라도 1, 2, 3 순차적으로 순위를 매김 - ROWNUMBER: 중복 없는 순위. 행 번호
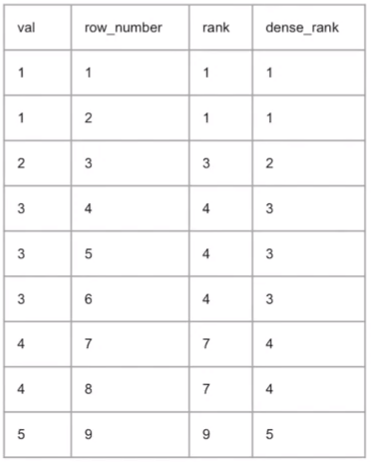
※ ORDER BY에 순위의 기준을 지정
※ `함수적용_열` 인자가 들어가지 않음
- RANK
- 그룹 내 집계(AGGREGATE) 관련 함수
- SUM: 합
- MAX: 최솟값
- MIN: 최댓값
- AVG: 평균
- COUNT: 개수
※ PARTITION BY에 그룹할 기준을 지정
※ ORDER BY에 정렬 기준을 지정
- 그룹 내 행 순서 관련 함수
- FIRST_VALUE: 파티션별 윈도우에서 가장 먼저 나온 값. 공통 등수를 인정하지 않고 처음 나온 행을 처리. MIN 함수를 이용해도 같은 결과 얻을 수 있음.
- LAST_VALUE: 파티션별 윈도우에서 가장 나중에 나오는 값 중 먼저 나온 값. 공통 등수를 인정하지 않음. MAX 함수를 이용해도 같은 결과 얻을 수 있음.
- LAG(열, n, 결측값 채울 값): n칸 미루기
- LEAD(열, n, 결측값 채울 값): n칸 당기기
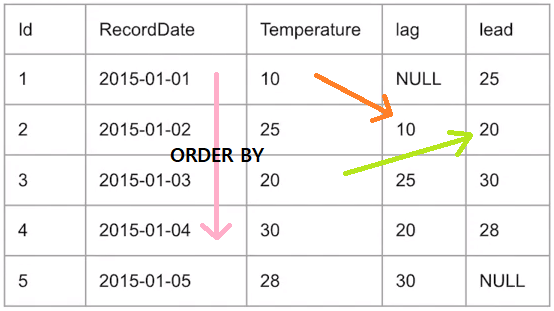
※ n은 설정 안 하면 1임
※ PARTITION BY에 그룹할 기준을 지정
※ ORDER BY에 정렬 기준을 지정
LEAD(<expression>[,offset[, default_value]]) OVER ( PARTITION BY (expr) ORDER BY (expr) ) - 그룹 내 비율 관련 함수
- CUME_DIST: 파티션별 윈도우의 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율. 0-1 사이의 값
- PERCENT_RANK: 파티션별 윈도우에서 제일 먼저 나오는 것을 0, 제일 늦게 나오는 것을 1로 하여 행의 순서별 백분율 구함
- NTILE: 파티션별 전체 건수를 ARGUMENT 값으로 N등분한 결과
- RATIO_TO_REPORT: 파티션 내 전체 SUM(컬럼) 값에 대한 행별 컬럼 값의 백분율을 소수점으로 구함. 결과값은 > 0 & <= 1 의 범위를 가지며 개별 ratio 의 합을 구하면 1이 됨
- 선형 분석을 포함한 통계 분석 함수
PERCENT_RANK
- 같은 부서 소속 사원들의 집합에서 본인의 급여가 순서상 몇 번째 위치해 있는지 0과 1 사이의 값으로 출력하는 예제
SELECT
ENAME
, SAL
, PERCENT_RANK() OVER (
PARTITION BY DEPTNO
ORDER BY SAL DESC
) P_R
FROM
EMP
;[실행 결과]
DEPTNO ENAME SAL P_R
------ ------ ---- ----
10 KING 5000 0
10 CLARK 2450 0.5
10 MILLER 1300 1
20 SCOTT 3000 0
20 FORD 3000 0
20 JONES 2975 0.5
20 ADAMS 1100 0.75
20 SMITH 800 1
30 BLAKE 2850 0
30 ALLEN 1600 0.2
30 TURNER 1500 0.4
30 MARTIN 1250 0.6
30 WARD 1250 0.6
30 JAMES 950 1
14개의 행이 선택되었다.- DEPTNO 10
- 3건이므로 구간은 2
- 0과 1 사이를 2개의 구간으로 나누면 0, 0.5, 1
- DEPTNO 20
- 5건, 구간은 4
- 0과 1 사이를 4개 구간으로 나누면 0, 0.25, 0.5, 0.75, 1
- DEPTNO 30
- 6건, 구간은 5
- 0과 1 사이를 5개 구간으로 나누면 0, 0.2, 0.4, 0.6, 0.8, 1
NTILE
- 전체 사원을 급여가 높은 순서로 정렬하고, 급여를 기준으로 4개 그룹으로 분류
SELECT
ENAME
, SAL
, NTILE(4) OVER (
ORDER BY SAL DESC
) QUAR_TILE
FROM
EMP
;[실행 결과]
DEPTNO ENAME SAL QUAR_TILE
------ ------- ---- --------
10 KING 5000 1
10 FORD 3000 1
10 SCOT 3000 1
20 JONES 2975 1
20 BLAKE 2850 2
20 CLARK 2450 2
20 ALLEN 1600 2
20 TURNER 1500 2
30 MILLER 1300 3
30 WARD 1250 3
30 MARTIN 1250 3
30 ADAMS 1100 4
30 JAMES 950 4
30 SMITH 800 4
14개의 행이 선택되었다.- NTILE(4) 의 의미
- 14명의 팀원을 4개 조로 나눈다!
- 14명을 4개의 집합으로 나누면 몫이 3, 나머지가 2
- 나머지 두 명의 앞의 조부터 할당
→ 4명 + 4명 + 3명 + 3명 으로 조를 나눔
Python CodeKata 관련
- 문자열 내에서 for문 돌 수 있음
str.isnumeric()- string 함수
str이 숫자인지 아닌지 판별.digit()도 동일한 기능
- 문자열 합치는 건
.append아님+쓰면 됨
join은 리스트를 문자열로 합치는 거
arr.index(i)- arr 내에서 i값의 위치 반환
dic.item()- key와 value 한번에 가져오기
for key, value in num_dic.items():
- replace 함수는 replace된 문자열을 반환할 뿐 실제 문자열을 변경하지는 않음
s = s.replace(c,str(i))이렇게 다시 넣어줘야 함- 인자는 '변환 대상', '변환할 문자', 'count'
- count 지정하면 count 개수 만큼만 replace
- enumerate 함수는 인덱스와 요소를 함께 받고 싶을 때 사용
- 리스트나 문사열에서 인덱스와 요소를 함께 받고 싶을 때 사용하면 매우 편리
파이썬의 enumberate() 내장 함수로 for 루프 돌리기
- 많은 프로그래밍 언어들에서 i, j, k와 같은 소위 인덱스(index) 변수를 증가시키면서 for 루프를 돌리지만 파이썬에서는 enumerate()라는 내장 함수를 통해 이러한 인덱스 변수를 사용하지 않고 루프를 돌리는 방식을 선호
- 이런 코딩 스타일을 소위 Pythonic, 즉 파이썬답다고 한다.
for 루프
- 파이썬에서는 기본적으로
for <원소> in <목록>:형태로 작성<목록>부분에는 리스트(list), 튜플(tuple), 문자열(string), 반복자(iterator), 제너레이터(generator) 등 순회가 가능한 왠만한 모든 데이터 타입을 사용할 수 있음<원소>부분은 흔히 순회 변수(loop variable)라고 하는데,<목록>부분에 넘긴 객체가 담고 있는 원소들이 루프가 도는 동안 하나씩 차례로 할당됨
3개의 글자를 담고 있는 리스트를 대상으로 루프를 돌면서 각 글자를 출력하기
for letter in ['A', 'B', 'C']:
print(letter)[실행 결과]
A
B
C- 여기서 원소 뿐만 아니라 인덱스(index)도 함께 출력하고 싶을 때는 어떻게 해야 할까?
- 다른 프로그래밍 언어를 사용하다가 파이썬으로 넘어온 사람은 흔히 아래와 같이 코드를 작성함
i = 0 for letter in ['A', 'B', 'C']: print(i, letter) i += 1[실행 결과] 0 A 1 B 2 C- 이 방법이 틀린 것은 아니지만, i 변수가 for 반복문이 종료된 이 후에도 네임 스페이스에 남아있기 때문에 이상적이지 않음
range()와len()내장 함수를 이용하여 만든 인덱스 목록을 대상으로 루프를 돌리는 방법도 생각해 볼 수 있음
letters = ['A', 'B', 'C'] for i in range(len(letters)): letter = letters[i] print(i, letter)[실행 결과] 0 A 1 B 2 C- 이전 방법보다는 나아보이지만 파이썬 답지(Pythonic) 않아 보임
enumerate() 함수
- 파이썬의 내장 함수인 enumerate()를 이용하면 좀 더 파이썬답게 인덱스(index)와 원소를 동시에 접근하면서 루프를 돌릴 수 있음
for entry in enumerate(['A', 'B', 'C']):
print(entry)[실행 결과]
(0, 'A')
(1, 'B')
(2, 'C')- enumerate() 함수는 기본적으로 인덱스와 원소로 이루어진 튜플(tuple)을 생성
시작 인덱스 변경
enumerate()함수를 호출할 때start인자에 시작하고 싶은 숫자를 넘기기
for i, letter in enumerate(['A', 'B', 'C'], start=1):
print(i, letter)[실행 결과]
1 A
2 B
3 Cenumerate() 작동 원리
- 파이썬에서
for문은 내부적으로in뒤에 오는 목록을 대상으로 계속해서next()함수를 호출하고 있다고 생각할 수 있음- 일반 리스트를
iter()함수에 넘겨 반복자(iterator)로 만든 후next()함수를 호출해보면 원소들이 차례로 얻어지는 것을 알 수 있음
- 일반 리스트를
>>> iter_letters = iter(['A', 'B', 'C'])
>>> next(iter_letters)
'A'
>>> next(iter_letters)
'B'
>>> next(iter_letters)
'C'enumerate()함수를 호출한 결과를 대상으로next()함수를 계속해서 호출해보면, 인덱스와 원소의 쌍이 튜플(tuple)의 형태로 차례로 얻어지는 것을 알 수 있음
>>> enumerate_letters = enumerate(['A', 'B', 'C'])
>>> next(enumerate_letters)
(0, 'A')
>>> next(enumerate_letters)
(1, 'B')
>>> next(enumerate_letters)
(2, 'C')- 결국,
enumerate()함수는 인자로 넘어온 목록을 기준으로 인덱스와 원소를 차례대로 접근하게 해주는 반복자(iterator) 객체를 반환해주는 함수라는 이야기enumerate()함수의 반환 값을 리스트로 변환해보면 좀 더 명확하게 확인할 수 있음
>>> list(enumerate(['A', 'B', 'C']))
[(0, 'A'), (1, 'B'), (2, 'C')]2차원 리스트 루프
- 응용: 2차원 리스트나 튜플이 담고 있는 데이터를 루프를 돌면서 접근해야한다고 가정
>>> matrix = [['A', 'B', 'C'], ['D', 'E', 'F'], ['G', 'H', 'I']]- 대부분 중첩 for문 내에서 행과 열의 인덱스로 데이터를 읽도록 작성하는 경우가 많음
>>> for r in range(len(matrix)):
... for c in range(len(matrix[r])):
... print(r, c, matrix[r][c])
...
0 0 A
0 1 B
0 2 C
1 0 D
1 1 E
1 2 F
2 0 G
2 1 H
2 2 I- 동일한 작업을 하는 코드를 enumerate() 함수를 이용해 재작성
>>> for r, row in enumerate(matrix):
... for c, letter in enumerate(row):
... print(r, c, letter)
...
0 0 A
0 1 B
0 2 C
1 0 D
1 1 E
1 2 F
2 0 G
2 1 H
2 2 I데이터프레임 인덱스 관련
reset_index


- 멀티인덱스에서는 level 키워드를 사용하여 멀티인덱스의 한 부분을 리셋시킬 수 있음
to_csv
df.to_csv("./result.csv", index=False)- index 키워드 False로 해야 인덱스 저장 안 됨
오류 메시지 관련
-
DataConversionWarning: A column-vector y was passed when a 1d array was expected.
DataConversionWarning: A column-vector y was passed when a 1d array was expected.
Please change the shape of y to (n_samples,), for example using ravel().-
데이터를 1차원 배열로 넣으라는 이야기
ravel(),flatten()
: 다차원 배열(array)을 1차원 배열(array)로 평평하게 펴 주는 numpy 함수
→ DataFrame(n,1)을 Series(n,)로
cf.
reshape(): 1차원 배열을 다차원 배열로 만들어주는 numpy 함수
-
-
AttributeError: 'float' object has no attribute 'round'
- float 숫자에서 함수 를 호출하려고 할 때 발생
- float를 round() 함수의 인수로 전달하면 오류 해결
example = 3.6
result = example.round() # error
result = round(example) # 4
2 B R 0 2 B