DataFrame
- 2차원의 자료 구조
- 데이터 분석의 최종 단계인 시각화 결과물을 만드는 바로 직전 단계
- 이전 단계의 다양한 작업 결과물이 하나로 모인 것
- 데이터프레임까지 올 수 있는 다양한 여러 가지 작업 경로: 빅데이터 분석 파이프라인
goog.cvs
Date Open High Low Close Volume
0 12/19/2016 790.219971 797.659973 786.270020 794.200012 1225900
1 12/20/2016 796.760010 798.650024 793.270020 796.419983 925100
2 12/21/2016 795.840027 796.676025 787.099976 794.559998 1208700
3 12/22/2016 792.359985 793.320007 788.580017 791.260010 969100
4 12/23/2016 790.900024 792.739990 787.280029 789.909973 623400
.. ... ... ... ... ... ...
56 3/13/2017 844.000000 848.684998 843.250000 845.539978 1149500
57 3/14/2017 843.640015 847.239990 840.799988 845.619995 779900
58 3/15/2017 847.590027 848.630005 840.770020 847.200012 1379600
59 3/16/2017 849.030029 850.849976 846.130005 848.780029 970400
60 3/17/2017 851.609985 853.400024 847.109985 852.119995 1712300
[61 rows x 6 columns]- df에는 모두 몇 개의 셀이 있습니까?
61*6=366개
- df에는 인덱스가 있나요?
- 네(0~60)
- 인덱스는 누가 만들었나요?
- 시스템(판다스 시스템)
- 인덱스가 존재하는 목적은 무엇인가요?
- 요소(행)를 제어하기 위해
- DateTime 타입의 인덱스를 가지고 있는 시리즈를 만드는 법?
- 날짜 문자열 리스트를 DatetimeIndex로 변환하여 시리즈 생성
- 날짜 문자열 리스트를 pd.to_datetime()으로 변환한 뒤, 이를 인덱스로 사용해 시리즈를 만들 수 있음
- date_range로 DatetimeIndex를 생성하여 시리즈 만들기
- pd.date_range() 함수를 사용해 일정 기간 또는 주기를 가진 DatetimeIndex를 생성
- 기존 DataFrame의 열을 Datetime 타입으로 변환 후 인덱스로 지정
- 기존 DataFrame의 날짜 열을 Datetime 타입으로 변환한 뒤, 그 열을 인덱스로 지정
- 시리즈로 만들고 싶다면, 해당 열을 인덱스로 지정한 후 시리즈로 추출
- 날짜 문자열 리스트를 DatetimeIndex로 변환하여 시리즈 생성
# 1번
import pandas as pd
import numpy as np
# 날짜 문자열 리스트
date_str = ["2025-06-01", "2025-06-02", "2025-06-03"]
# DatetimeIndex로 변환
idx = pd.to_datetime(date_str)
# 시리즈 생성 (랜덤 값 예시)
s = pd.Series(np.random.randn(3), index=idx)
print(s)
# 2번
import pandas as pd
import numpy as np
# 2025년 6월 1일부터 3일간의 날짜 생성
idx = pd.date_range('2025-06-01', periods=3)
# 시리즈 생성
s = pd.Series(np.random.randn(3), index=idx)
print(s)
# 3번
import pandas as pd
# 예시 DataFrame (날짜 열 포함)
df = pd.DataFrame({
'date': ['2025-06-01', '2025-06-02', '2025-06-03'],
'value': [10, 20, 30]
})
# 날짜 열을 Datetime 타입으로 변환
df['date'] = pd.to_datetime(df['date'])
# 인덱스를 날짜로 지정
df.set_index('date', inplace=True)
# 시리즈로 추출 (예: value 열)
s = df['value']
print(s)짝수의 행 중에서 High, Low 컬럼만을 출력
# 방법 1
df.iloc[list(range(0,61,2)) ,2:4]
# 방법 2
df.iloc[[i for i in range (0,61,2)], 2:4]
# 방법 3
ls = [x for x in df.index if x % 2 == 0]
df.loc[ls, ['High','Low']]
# 방법 4
df.loc[df.index % 2 == 0, ['High','Low']]
# 또 다른 방법들
df.loc[[i for i in range(len(df)) if not i%2], ['High', 'Low']]
df[df.index%2==0][['High', 'Low']]
df.iloc[[i for i in range(len(df)) if not i%2]][['High', 'Low']]df의 기본 인덱스
# df의 인덱스(정수인덱스) 확인
df.indexRangeIndex(start=0, stop=61, step=1)- 지금은 RangeIndex이지만 예전 pandas에서는 그냥 정수 인덱스였다고 함
- 이를 해결하기 위해 pd.read_csv() 함수의 index_col 파라미터를 사용해 인덱스로 쓸 컬럼을 지정하면 됨
문자열로 된 날짜 형식을 연산 가능한 날짜 형식으로 변환
- pd.read_csv() 메서드의 옵션을 이용
- 연산가능한 날짜형식으로 변환 옵션:
parse_dates=['컴럼명'] - csv파일의 특정 컬럼을 데이터 프레임의 인덱스로 지정하는 옵션:
index_col='컬럼명'
- 연산가능한 날짜형식으로 변환 옵션:
pd.read_csv('data/goog.csv', parse_dates=['Date'], index_col='Date')- df를 재활용
df32 = df # df 데이터프레임을 df32로 할당한다
df32['Date'] = pd.to_datetime(df['Date'] )
# to_datetime() 함수
# 데이터프레임의 특정 컬럼의 타입(형식)을 detetime 형식으로 변환
print(type(df32.Date[0])) # 서비스 코드
df32pandas plot
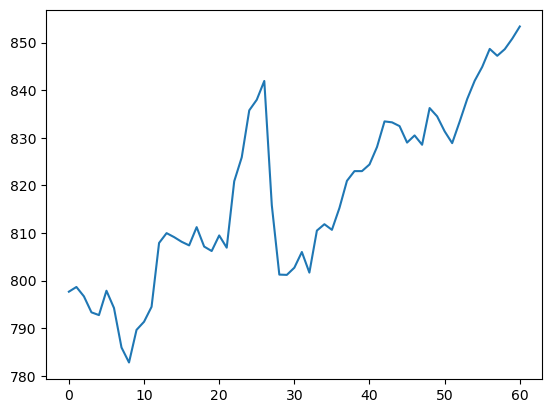
-
df.High.plot()
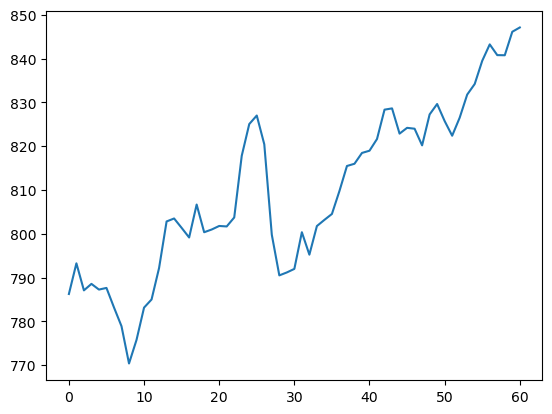
-
df.Low.plot()
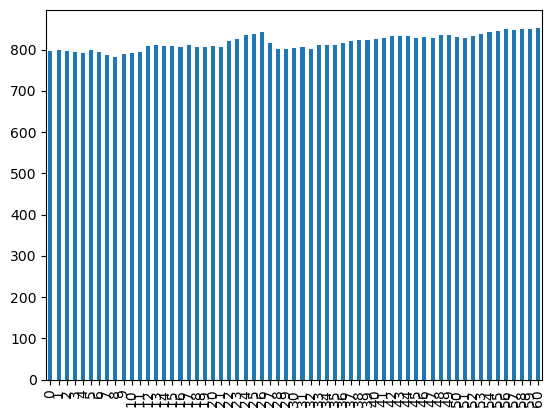
-
df.High.plot(kind='bar')
-
df.High.plot(kind='pie') # 파이
-
df.High.plot(kind='hist', y='Height') #히스토그램
pandas concat
pandas.concat(objs, *, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, sort=False, copy=True)→ concatenate Series/DataFrame: pandas.concat() 함수를 사용하여 데이터프레임들을 합치는 방법
pandas.concat()- 시리즈나 데이터프레임 등의 판다스 객체들을 특정 방향(축,axis)으로 이어붙이는 함수
- 자주 사용되는 파라미터
- objs : a sequence or mapping of Series or DataFrame objects
→ 이어붙일 시리즈/데이터프레임들을 입력
→ 데이터프레임 df1과 df1을 합치려면[df1, df2]과 같은 형태로 입력 - axis : {0/’index’, 1/’columns’}, default 0
→ 어떤 축을 기준으로 연결할지 → 0이면 행을, 1이면 열을 기준으로 연결
→ 디폴트는 0, 즉 행을 기준으로 연결 - join : {‘inner’, ‘outer’}, default ‘outer’
→ 연결할 기준 축이 아닌 다른 축의 인덱스를 처리하는 방법
→ inner, outer 방식이 있으며, 디폴트는 outer - ignore_index : bool, default False
→ 연결할 때 기존의 인덱스를 사용할지 여부
→ 디폴트는 False
→ 만약 ignore_index=True 라면 기존의 인덱스가 아닌 새로 부여한 인덱스(0, 1, 2, ... , n-1)로 인덱스를 다시 세팅하게 됩니다.
- objs : a sequence or mapping of Series or DataFrame objects
예제
- 먼저 데이터프레임 2개를 생성
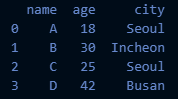
- df1
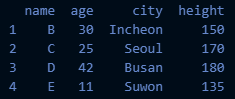
- df2
- df1
import pandas as pd
df1 = pd.DataFrame({'name':['A','B','C','D'],
'age':[18,30,25,42],
'city':['Seoul','Incheon','Seoul','Busan']}, index=[0,1,2,3])
df2 = pd.DataFrame({'name':['B','C','D','E'],
'age':[30,25,42,11],
'city':['Incheon','Seoul','Busan','Suwon'],
'height':[150, 170, 180, 135]}, index=[1,2,3,4])- 다른 파라미터 추가 없이 두 데이터프레임을 합치기
concat1 = pd.concat([df1, df2])- 데이터프레임
concat1은 다음과 같음- axis 값을 설정하지 않았기 때문에 디폴트값인 0이 사용됨
- axis=0 은 행을 기준으로, 즉 위아래로 두 데이터프레임을 이어붙이게 되므로 다음과 같은 결과가 나옴
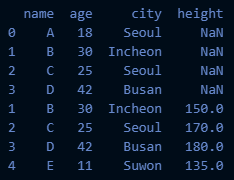
- axis=0 은 행을 기준으로, 즉 위아래로 두 데이터프레임을 이어붙이게 되므로 다음과 같은 결과가 나옴
- df1 에는 'height' 컬럼이 없으므로 NaN 값이 채워진 것을 확인할 수 있음
- concat1의 인덱스 번호는 0,1,2,3,1,2,3,4 로 df1과 df2의 인덱스 번호가 그대로 사용됨
- 만약 새로운 인덱스 번호를 부여하고 싶다면 ignore_index=True 파라미터를 입력하면 됨
- axis 값을 설정하지 않았기 때문에 디폴트값인 0이 사용됨
concat2 = pd.concat([df1, df2], ignore_index=True)-
concat2는 다음과 같이 새롭게 인덱스 번호가 설정되었음을 확인할 수 있음
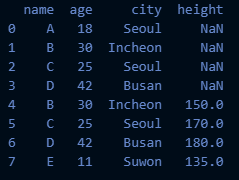
-
axis=1 값을 통해 열방향(좌우)으로 합치기
concat3 = pd.concat([df1, df2], axis=1)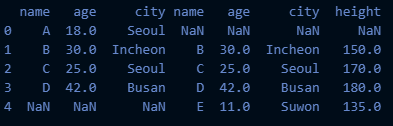
- df1의 인덱스는 0,1,2,3이고, df2의 인덱스는 1,2,3,4이므로 그에 맞게 이어짐
- df1에는 4행이 없고, df2에는 0행이 없으므로 해당 데이터는 NaN 값으로 채워진 것을 확인할 수 있음
- join 옵션을 따로 설정하지 않았기 때문에 디폴트 값인 'outer'로 설정되어서 위와 같은 결과가 나옴
- 만약
join='inner'로 설정을 하면 교집합에 해당하는 부분만 이어붙이게 됨
- 만약
concat4 = pd.concat([df1, df2], axis=1, join='inner')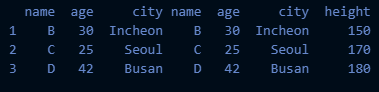
- df1, df2에 모두 존재하는 행 인덱스는 1, 2, 3이기 때문에 concat4 는 위와 같이 합쳐진 것을 확인할 수 있음

2 B R 0 2 B