SQL
여러 행의 컬럼을 합치는 방법: GROUP_CONCAT
- n개의 row 로 결과가 출력되는 쿼리를 한 줄의 row에 표현하고 싶은 경우, GROUP_CONCAT을 사용
- 오라클의 경우
- 오라클 10G : WM_CONCAT()
- 오라클 11G : LISTAGG()
SELECT
GROUP_CONCAT('컬럼명' SEPARATOR '구분문자')
FROM
테이블명
예시
| type | name |
|---|
| fruit | 수박 |
| fruit | 사과 |
| fruit | 바나나 |
| fruit | 사과 |
SELECT
type
, group_concat(name)
FROM
test
GROUP BY
type
;
| type | name |
|---|
| fruit | 수박,사과,바나나,사과 |
- GROUP_CONCAT을 기본적인 형태로 사용하면 문자열 사이에 쉼표(,)가 붙음
- 구분자를 변경하고 싶을 때
SEPARATOR '구분자' 추가
SELECT
type
, group_concat(name SEPARATOR '|')
FROM
test
GROUP BY
type
;
| type | name |
|---|
| fruit | 수박|사과|바나나|사과 |
- 합쳐지는 문자열에 중복되는 문자열을 제거할 때는
DISTINCT 사용
SELECT
type
, group_concat(DISTINCT name)
FROM
test
GROUP BY
type
;
SELECT
type
, group_concat(DISTINCT name ORDER BY name)
FROM
test
GROUP BY
type
;
정리
- group_concat: MySQL에서 group by로 문자열을 합칠 때
- 기본형 : group_concat(필드명)
- 구분자 변경 : group_concat(필드명 separator '구분자')
- 중복제거 : group_concat(distinct 필드명)
- 문자열 정렬 : group_concat(필드명 order by 필드명)
참고: MySQL Aggregate function
더 알아보기
| Name | Description |
|---|
| AVG() | Return the average value of the argument |
| BIT_AND() | Return bitwise AND |
| BIT_OR() | Return bitwise OR |
| BIT_XOR() | Return bitwise XOR |
| COUNT() | Return a count of the number of rows returned |
| COUNT(DISTINCT) | Return the count of a number of different values |
| GROUP_CONCAT() | Return a concatenated string |
| JSON_ARRAYAGG() | Return result set as a single JSON array |
| JSON_OBJECTAGG() | Return result set as a single JSON object |
| MAX() | Return the maximum value |
| MIN() | Return the minimum value |
| STD() | Return the population standard deviation |
| STDDEV() | Return the population standard deviation |
| STDDEV_POP() | Return the population standard deviation |
| STDDEV_SAMP() | Return the sample standard deviation |
| SUM() | Return the sum |
| VAR_POP() | Return the population standard variance |
| VAR_SAMP() | Return the sample variance |
| VARIANCE() | Return the population standard variance |
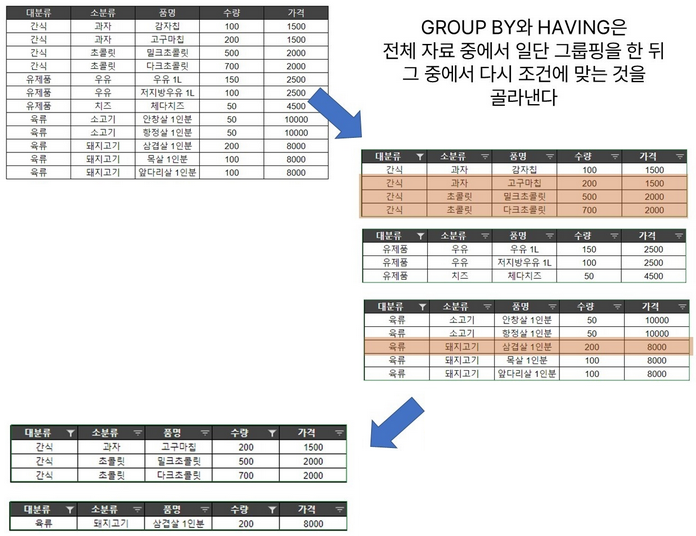
WHERE와 HAVING

- WHERE는 GROUP BY보다 먼저 실행되고, HAVING은 GROUP BY 뒤에 실행됨
- WHERE를 통해 조건을 적용한다면, FROM으로 참고한 원본 데이터를 우선 모두 골라낸 뒤에 남은 데이터만으로 GROUP BY
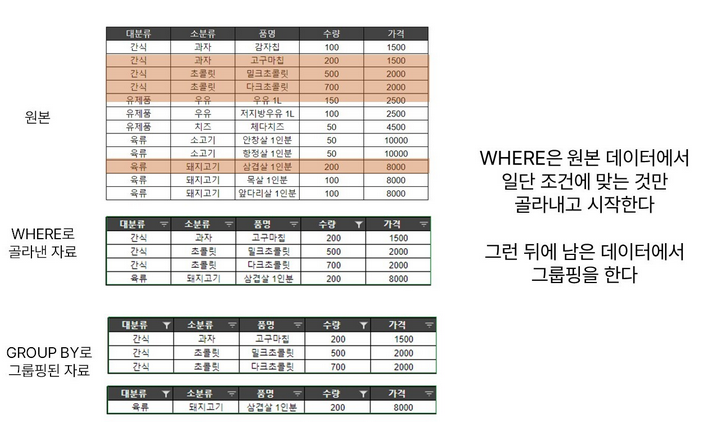
- HAVING을 통해 조건을 적용하면 모든 데이터를 이용해 일단 그룹핑을 하고 그 뒤에 조건을 적용