groupby 함수와 멀티인덱스
-
두 가지 이상의 범주로 groupby를 실행한 경우, 자동으로 멀티인덱스가 적용
- 뭉쳐있는 데이터 프레임의 형태 출력
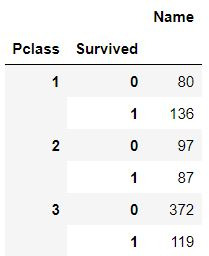
- 뭉쳐있는 데이터 프레임의 형태 출력
-
각 행이 나누어져 있고, 인덱스가 초기화된 결과를 얻으려면 어떻게 해야 할까?
- 이후 인덱싱이나 다른 작업을 할 때 일반 데이터프레임처럼 간주할 수 있게 만드는 것!
reset_index() 함수
- groupby된 데이터 프레임에서 인덱스를 재정렬하여 나누어진 행을 만드는 것은 다음 코드 한 줄이면 해결됨
df = df.reset_index() 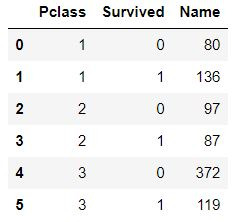
-
판다스 내 reset_index() 함수를 사용하면 행이 분리된 데이터프레임의 결과를 살펴볼 수 있음
- level 인자를 사용하면 다른 column을 index로 가질 수 있음
df = df.reset_index(level = 'Survived')
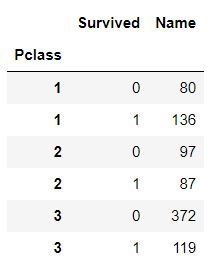
- level 인자를 사용하면 다른 column을 index로 가질 수 있음
-
level 인자로 지정한 반대의 column이 index로 지정된 것에 주의할 것
- Pclass와 Survived 중 Pclass를 index로 취급하고 싶다면 Survived를 level 인자로 지정해주어야 함
-
- reset_index 함수에는 더 다양한 기능이 있고, 이보다 더 복잡한 상황에서도 사용이 가능
- 사용하려는 경우의 상황이 3중 인덱스 이상
- level을 더 디테일하게 적용
df = df.reset_index()처럼이 아니라 inplace = True 기능을 이용해df.reset_index(inplace = True)처럼 변수 재선언 과정 없이 결과 반영이 가능하게 만들 수도 있음
- reset_index 함수에는 더 다양한 기능이 있고, 이보다 더 복잡한 상황에서도 사용이 가능
pivot_table
- pandas 모듈의 pd.pivot_table 함수로 피벗테이블을 원하는대로 생성
- values, index, columns, fill_value 및 aggfunc 인자를 기준으로 사용법 익히기
- values : 피벗테이블에서 각 그룹 별로 조회할 값의 기존 데이터프레임의 열 이름(들)
- index : 테이블의 행으로 들어갈 기존 데이터프레임의 열 이름(들)
- columns : 테이블의 열로 들어갈 기존 데이터프레임의 열 이름(들)
- fill_value : 값이 존재하지 않는 그룹에 채울 값 지정(기본 값 : np.NaN)
- aggfunc : 각 그룹 별로 값들을 조회할 함수(들)
- values, index, columns, fill_value 및 aggfunc 인자를 기준으로 사용법 익히기
index는 기준점이 되는 변수를 의미하며, 보통 문자열 변수를 작성한다.
values는 계산하려는 변수를 의미하며, 보통 숫자열 변수를 작성한다.
예제
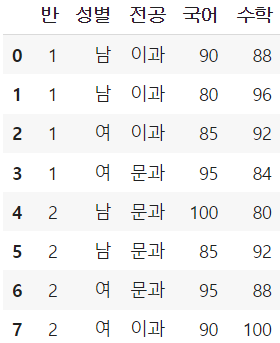
- 반과 전공을 기준으로 그룹을 나누어 각 그룹의 국어 성적 평균을 조회
- 반 → index, 전공 → columns, 국어 → values, 평균 → aggfunc
- index로 지정한 반은 왼쪽에, columns로 지정한 전공은 위쪽에 들어감
table1 = pd.pivot_table(df, values='국어', index=['반'],
columns=['전공'], aggfunc=np.mean)
table1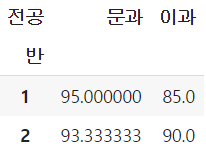
- 국어 성적뿐 아니라 수학 성적의 평균도 같이 조회하고 싶을 때 → values 인자를 리스트로 묶어서 지정
table2 = pd.pivot_table(df, values=['국어', '수학'], index=['반'],
columns=['전공'], aggfunc=np.mean)
table2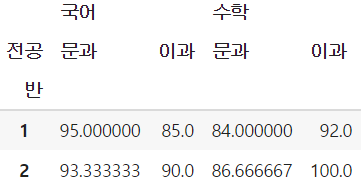
- 반과 전공뿐 아니라 성별 정보도 그룹의 기준에 추가하되, 성별 정보는 반 정보와 함께 왼쪽 row에 위치하게 하고 싶을 때 → 왼쪽 row에 위치할 index 인자를 리스트로 묶어서 지정
- 해당 그룹에 속하는 학생 정보가 없는 경우 NaN으로 표시
table3 = pd.pivot_table(df, values=['국어', '수학'], index=['반', '성별'],
columns=['전공'], aggfunc=np.mean)
table3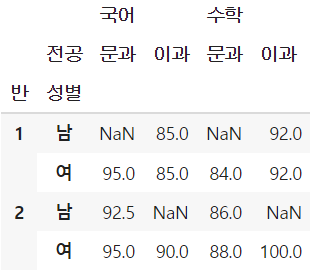
- 성별 정보를 왼쪽 row 대신 위쪽 column 위치에 추가하고 싶다면 → columns 인자에 해당 정보를 포함하여 피벗테이블을 생성
table4 = pd.pivot_table(df, values=['국어', '수학'], index=['반'],
columns=['전공', '성별'], aggfunc=np.mean)
table4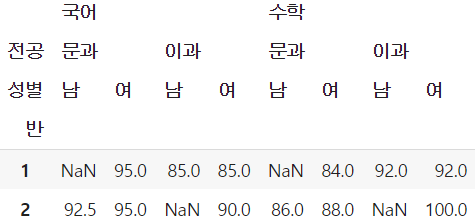
fill_value인자- 학생 정보가 없는 그룹의 데이터를 NaN이 아닌 다른 값으로 채우고 싶다면 fill_value 인자에 대치를 원하는 값을 지정
table5 = pd.pivot_table(df, values=['국어', '수학'], index=['반'],
columns=['전공', '성별'], aggfunc=np.mean, fill_value = 0)
table5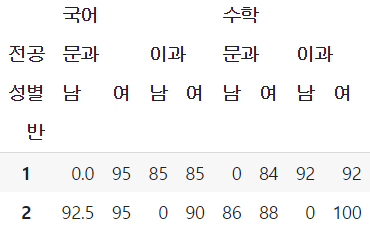
aggfunc인자 여러 개 지정- 각 그룹에서 조회하고 싶은 값 연산의 종류가 여러개인 경우 → aggfunc 인자에 원하는 연산 함수들을 리스트로 모아서 지정
table6 = pd.pivot_table(df, values=['국어', '수학'], index=['반', '성별'],
columns=['전공'], aggfunc=[np.mean, np.std])
table6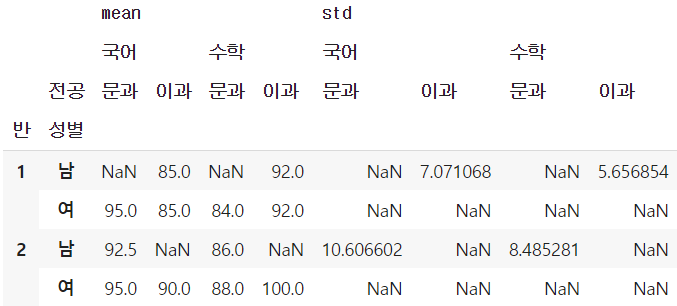
피벗테이블 필터링
- table
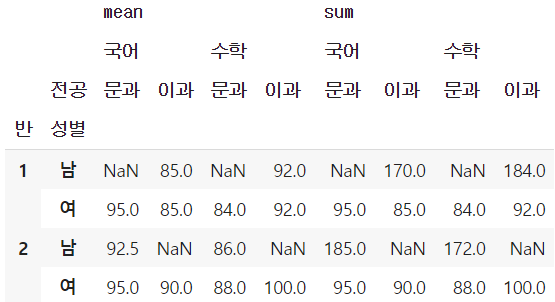
값 1개만 가져오고 싶다면?
- 인덱스 및 열이 MultiIndex 형태로 저장된 점에 유의하여 아래와 같이 loc 함수에서 튜플로 행, 열 이름을 지정한 필터링 가능
table.loc[(2, '남'), ('mean', '국어', '문과')] # 92.5- 가장 바깥쪽 index 및 column 이름을 기준으로 부분 테이블을 필터링하는 것도 가능
- 최외곽 index인 반 정보와 가장 위쪽 column인 mean/sum 중 2반과 mean 정보만을 골라 추출한 부분 테이블
table.loc[2, 'mean']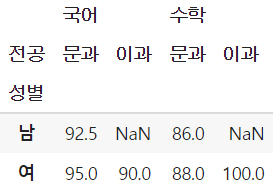
- 부분 테이블 내에서 다시 부분 테이블을 필터링하거나 부분 테이블 내 값 추출도 가능
# 부분 테이블 내 부분 테이블 필터링
table.loc[2, 'mean'].loc['남', '국어'] # 성별, 전공 정보 모두 지정
'''
전공
문과 92.5
이과 NaN
Name: 남, dtype: float64'''
table.loc[2, 'mean'].loc[:, '국어'] # 전공 정보만 지정
'''
전공 문과 이과
성별
남 92.5 NaN
여 95.0 90.0'''
table.loc[2, 'mean'].loc['여'] # 성별 정보만 지정
'''
전공
국어 문과 95.0
이과 90.0
수학 문과 88.0
이과 100.0
Name: 여, dtype: float64'''
# 부분 테이블 내 값 추출
table.loc[2, 'mean'].loc['여', ('국어', '문과')] # 95.0피벗테이블 정렬
- 데이터프레임과 마찬가지로 sort_values 함수로 가능
- 열 이름이 MultiIndex 형태임에 유의하여 튜플로 열 이름 정보를 바깥쪽부터 순서대로 묶어서 원하는 열을 정확하게 지정해주어야 함
예시
- mean, 수학, 문과 정보에 해당하는 열의 점수를 기준으로 오름차순 정렬
table.sort_values(('mean', '수학', '문과'))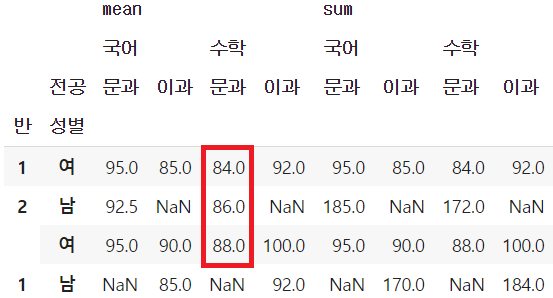
- 같은 기준으로 내림차순 정렬
- ascending 인자를 False로 지정
table.sort_values(('mean', '수학', '문과'), ascending = False)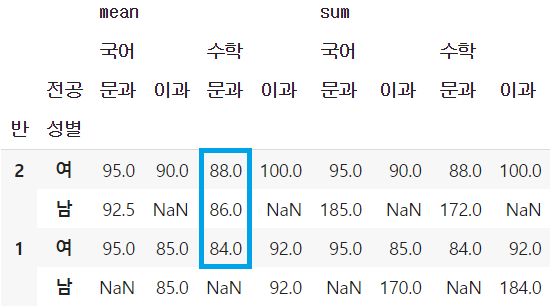
피벗테이블 데이터프레임 변환
- 조회된 피벗테이블을 일반적인 데이터프레임 형태로 바꾸기 위해서는 열과 행에 지정된 MultiIndex를 순서대로 풀어주어야 함
(1) 열에 지정된 멀티인덱스를 각각의 단일인덱스로 변경
- 열 이름을 관리하는 columns 속성을 변경하는 원리
- / 대신 다른 구분자를 넣어도 됨
table.columns = ['/'.join(col) for col in table.columns]
table
(2) reset_index 함수로 행의 멀티인덱스까지 풀면 데이터프레임 변경 완료
table = table.reset_index()
table
추가로 읽어보면 좋을 글
pandas pivot table

2 B R 0 2 B