데이터 필터링하기
행 단위 데이터 추출
-
프레임 속에 있는 수많은 데이터 중에, 내가 원하는 대상의 데이터만 골라 새로운 프레임으로 만들기
- SQL에서 where절을 지정해 쿼리를 날리는 것과 유사
-
판다스에서는 loc 프로퍼티로 수행 가능
예시
| id | name | |
|---|---|---|
| 0 | 0 | a |
| 1 | 1 | b |
| 2 | 2 | c |
| 3 | 3 | a |
| 4 | 4 | a |
| 5 | 5 | b |
| 6 | 6 | c |
- 'name'이 'a'인 라인들만 모아 새로운 리스트를 만드로 싶어요
df2 = df.loc[df['name'] == 'a']
df2.head()| id | name | |
|---|---|---|
| 0 | 0 | a |
| 3 | 3 | a |
| 4 | 4 | a |
- 특별 관리 대상을 담은 target 리스트
targets = ['a', 'c']
- name이 targets 리스트에 포함된 라인만 모아서 새로운 데이터프레임으로 옮기고 싶어요
targets = ['a', 'c']
df3 = df.loc[df['name'].isin(targets)]
df3.head()| id | name | |
|---|---|---|
| 0 | 0 | a |
| 2 | 2 | c |
| 3 | 3 | a |
| 4 | 4 | a |
| 6 | 6 | c |
- 여러 개의 조건을 조합하려면?
- &나 | 사용
# isin(targets) 와 동일한 결과
df3 = df.loc[(df['name'] == 'a') | (df['name'] == 'c')]
df3.head()
# isin(targets) 이고, id가 4보다 작은 데이터들
df4 = df.loc[(df['name'].isin(targets)) & (df['id'] < 4)]
df4.head()| id | name | |
|---|---|---|
| 0 | 0 | a |
| 2 | 2 | c |
| 3 | 3 | a |
| 4 | 4 | a |
| 6 | 6 | c |
| id | name | |
|---|---|---|
| 0 | 0 | a |
| 2 | 2 | c |
| 3 | 3 | a |
- isin이 아니라 'is not in'이 필요한 경우(여집합)
- 조건식 앞에 ~ 붙이기
df5 = df.loc[~df['name'].isin(targets)]
df5.head()| id | name | |
|---|---|---|
| 1 | 1 | b |
| 5 | 5 | b |
열 단위 데이터 추출
- 데이터프레임에서 특정 열만 골라 새로운 프레임으로 만들고 싶을 땐 대괄호 사용
예시
| id | name | location | |
|---|---|---|---|
| 0 | 0 | a | 서울 |
| 1 | 1 | b | 부산 |
| 2 | 2 | c | 대구 |
| 3 | 3 | a | 서울 |
| 4 | 4 | a | 인천 |
| 5 | 5 | b | 여수 |
| 6 | 6 | c | 대전 |
- 한 개의 열 추출
- 시리즈가 리턴됨
series = df["location"]
series.head()0 서울
1 부산
2 대구
3 서울
4 인천
Name: location, dtype: object- 두 개 이상의 열을 추출하려면 대괄호 안데 리스트를 전달
- 리턴 타입은 프레임
frame = df[["id", "location"]]
frame.head()| id | location | ||
|---|---|---|---|
| 0 | 0 | 서울 | |
| 1 | 1 | 부산 | |
| 2 | 2 | 대구 | |
| 3 | 3 | 서울 | |
| 4 | 4 | 인천 |
- loc 프로퍼티와 조합
- 일부 행, 일부 열 데이터만 별도의 프레임으로 구성 가능
- df.loc[ 행, 열 ] 의 형태로 필터링할 내용을 입력
- e.g. name이 "a"인 행의 id, location 만 얻어오기
- 일부 행, 일부 열 데이터만 별도의 프레임으로 구성 가능
frame = df.loc[df["name"]=="a", ["id", "location"]]
frame.head()| id | location | ||
|---|---|---|---|
| 0 | 0 | 서울 | |
| 3 | 3 | 서울 | |
| 4 | 4 | 인천 |
groupby를 이용한 조건부 통계
- groupby
- 조건부 통계량을 계산하기 위한 방법
- 사용 방법
df.groupby(분할 기준 컬럼)[적용 기준 칼럼].집계함수
- 주요 입력
by: 분할 기준 컬럼(목록)as_index: 분할 기준 컬럼들을 인덱스로 사용할 것인지 여부- default값은 True
- 여러 개의 집계 함수나 사용자 정의 함수를 쓰고 싶다면
agg함수를 사용해야 함
pivot_table과 groupby의 차이점
- pivot_table과 groupby는 결과값은 동일하지만 출력 값의 형태에 차이가 있으므로 상황에 맞게 구별해 사용해야 함
- pivot_table은 출력 결과 자체가 결과물인 경우
- groupby는 중간 산출물로써 사용
- pivot_table은 heatmap과 같은 시각화에 더 유리한 데이터 구조
예시
- 쇼핑몰 유형에 따른 수량의 평균
df.groupby(['쇼핑몰 유형'])['수량'].mean()- as_index를 False로 지정하지 않으면 '쇼핑몰 유형'은 인덱스로, 평균값은 시리즈 형태의 값으로 출력됨

- as_index를 False로 지정하지 않으면 '쇼핑몰 유형'은 인덱스로, 평균값은 시리즈 형태의 값으로 출력됨
-
쇼핑몰 유형에 따른 수량의 평균
df.groupby(['쇼핑몰 유형'], as_index=False)['수량'].mean()
- as_index=False로 하면 인덱스는 숫자로 들어감

-
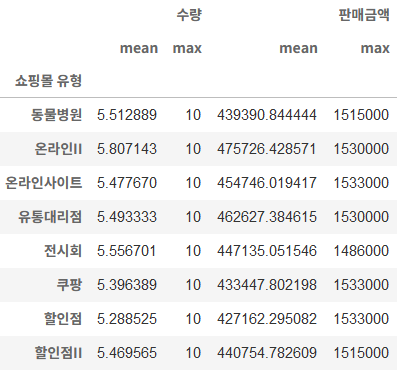
쇼핑몰 유형에 따른 수량의 평균, 최대값
df.groupby(['쇼핑몰 유형'])[['수량','판매금액']].agg(['mean','max'])
- mean과 max 두 개의 연산 함수를 사용하므로 agg를 써야 함
-
쇼핑몰 유형과 제품에 따른 수량, 판매금액의 최대값-최소값: 사용자 함수 적용
def my_func(value):
return max(value) - min(value)
df.groupby(['쇼핑몰 유형', '제품'])[['수량','판매금액']].agg(my_func)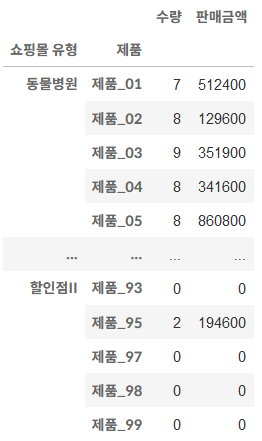
- as_index=False로 해서 인덱스를 숫자로 만들 수도 있음
def my_func(value):
return max(value) - min(value)
df.groupby(['쇼핑몰 유형', '제품'], as_index=False)[['수량','판매금액']].agg(my_func)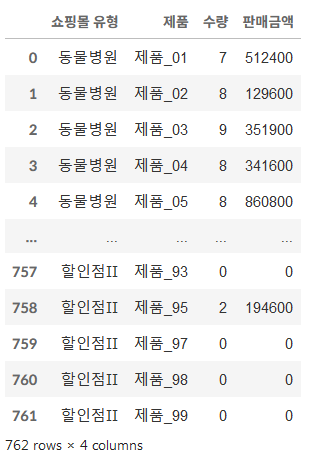
groupby에 복잡한 집계(조건부 집계 등) 함수 적용
- 복잡한 집계를 어떻게 해야 할까?
groupby 원리
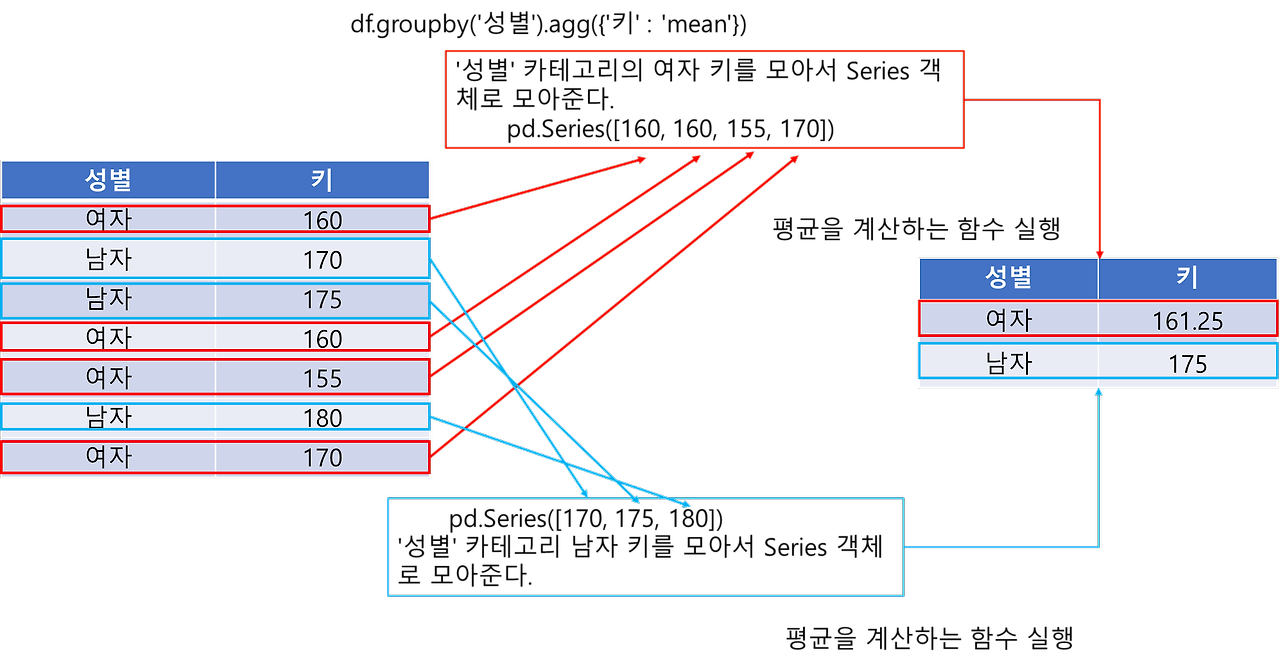
- groupby를 통한 집계 과정
- 그룹화 변수('성별')에 대하여 각 카테고리별로 집계할 컬럼('키')의 값을 Series 객체로 모아줌
- 각 Series 객체에 집계함수를 적용하여 하나의 데이터프레임(DataFrame) 객체로 모아줌
- 카테고리별로 Series 객체가 완성되면 이를 인자로 하여 집계 함수가 적용된 뒤 각 성별에 대응하여 평균이 적용된 결과가 하나의 DataFrame으로 모아지게 됨
※ Pandas에서 집계함수는 Series 객체를 인자로 받는다는 점이 포인트!
함수를 적용하여 복잡한 집계 처리하기
- 집계함수는 그룹 카테고리별로 Series 객체를 인자로 받는다는 것이 핵심!
- Series 객체의 인덱스 중 아무 값과 원 데이터를 이용하면 특정 정보를 가져올 수 있음
import pandas as pd
df_dict = {
'성별':['남자', '여자', '남자', '여자', '여자', '남자', '남자', '여자'],
'이름':['박영진', '김지혜', '김철수', '박유니', '김민혜', '김민철', '구태원', '김민주'],
'키':[170, 150, 188, 160, 160, 176, 181, 155]
}
df = pd.DataFrame(df_dict)
# 1. 성별로 '김'씨가 몇 명인지 집계
def get_lastname_count(series):
res = len([ _ for x in series if x[0]=='김'])
return res
# 언더바(_)는 명시적으로 뭔가를 받아야 하지만 그 값이 필요 없을 때 임시로 사용하는 것
df.groupby('성별').agg({'이름':get_lastname_count}).reset_index()
# 2. groupby를 이용하여 남자는 키가 180 이상인 사람, 여자는 키 160 이상인 사람의 수를 계산
def get_count_by_height(series):
if df.iloc[series.index[0], :]['성별'] == '남자':
res = len([_ for x in series if x>=180])
else:
res = len([_ for x in series if x>=160])
return res
df.groupby('성별').agg({'키':get_count_by_height}).reset_index()to_datetime
- Date 형식의 자료형을 datetime 오브젝트로 변환
import pandas as pd
df = pd.DataFrame({'date': ['29/10/24', '30/10/24', '31/10/24']})
print(df.dtypes_
dfdate object
dtype: object| date | |
|---|---|
| 0 | 29/10/24 |
| 1 | 30/10/24 |
| 2 | 31/10/24 |
- date 컬럼의 자료형은 object
- 이 문자열 날짜를 datetime 자료형으로 변환하기 위해 pd.to_datetime을 이용
infer_datetime)_format = True- 여러 datetime 유명한 포맷 중에서 datetime이 어떤 형식으로 이루어졌는지 확인 후 자동 변환
- 참고: 삭제 예정임
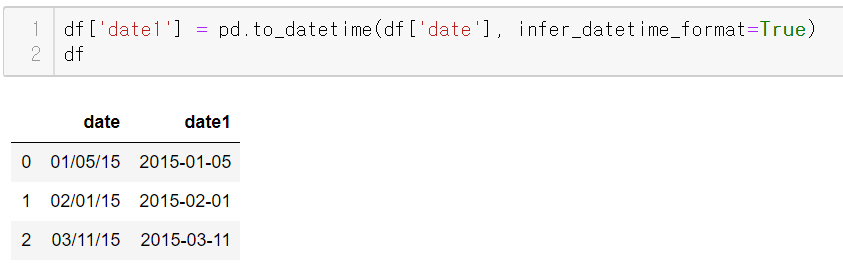
- format 지정
- 첫 번째를 일, 중간을 월, 마지막을 연도로 지정
df['date1'] = pd.to_datetime(df['date']. format = '%d/%m/%y')
df| date | date1 | |
|---|---|---|
| 0 | 29/10/24 | 2024-10-29 |
| 1 | 30/10/24 | 2024-10-30 |
| 2 | 31/10/24 | 2024-10-31 |
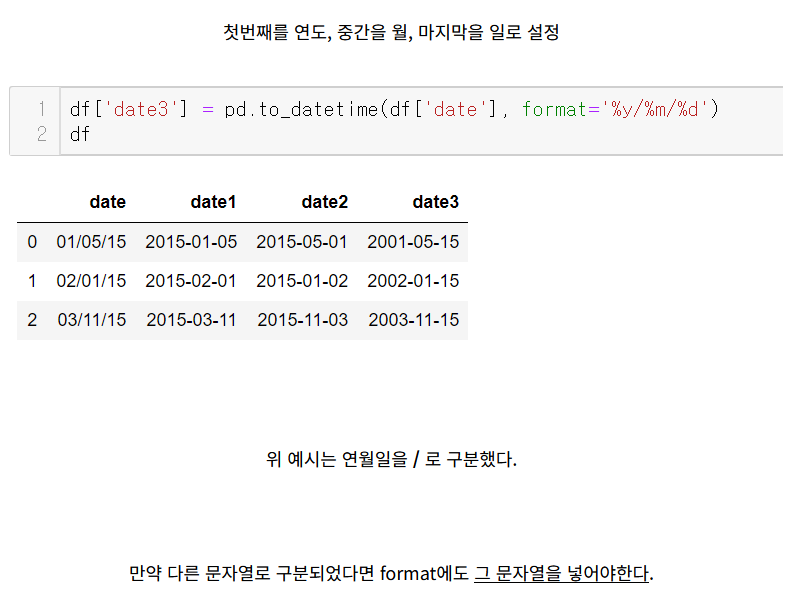
연, 월, 일 뽑아내기
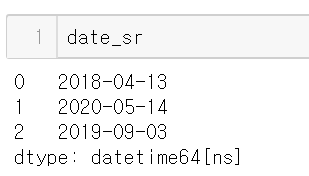
- 0번 행의 연, 월, 일을 뽑으려면 0번 행을 가져와서 year, month, day 속성을 이용
- dayofweek 속성은 요일을 숫자로 출력
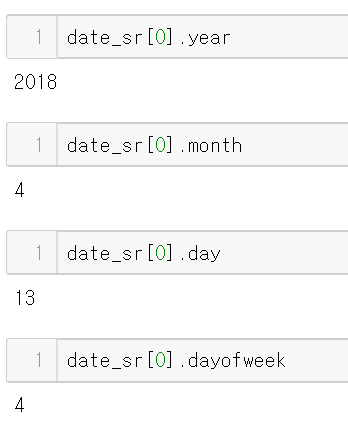
- dayofweek 속성은 요일을 숫자로 출력
컬럼(시리즈) 통째로 뽑기
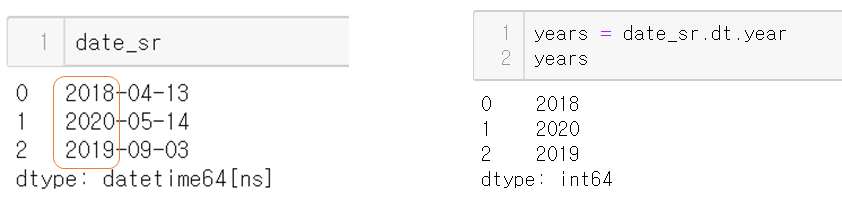
-
한 컬럼씩 뽑기 위해서는
dt연산자를 반드시 붙여야 함- 없으면 에러 발생
-
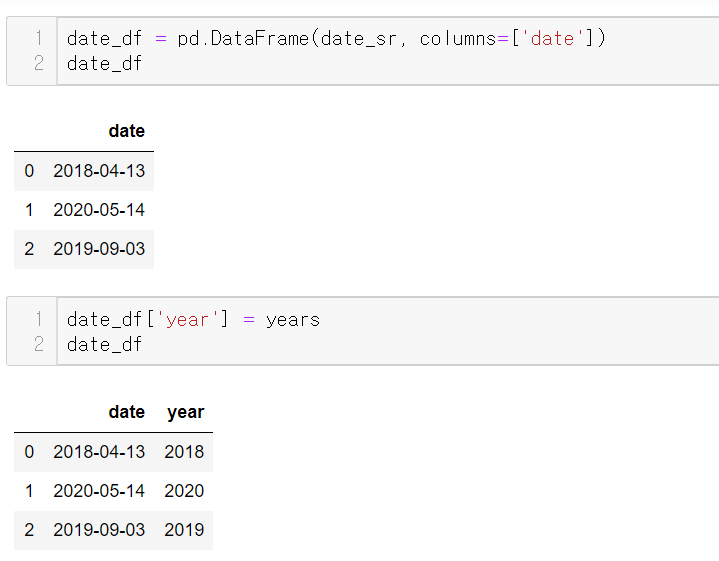
통째로 뽑은 연도를 컬럼으로 추가하기
데이터프레임 요일 구하기
- 파이썬 판다스 모듈로 데이터프레임 내의 날짜 정보를 다룰 때 요일 정보를 추출하는 방법
dt.weekday
- datetime 자료형에서 dt.weekday 속성을 홍해 요일 정보를 숫자로 추출 가능
- 0은 월요일, 1은 화요일, …, 6은 일요일
dt.day_name()
- datetime 자료형에서 제공하는 day_name() 메서드로 각 요일의 영어 이름 추출
- 주의: 속성이 아닌 메서드이기 때문에 dt.day_name이 아닌
dt.day_name()으로 사용
- 주의: 속성이 아닌 메서드이기 때문에 dt.day_name이 아닌
요일의 한글 이름 추출
- apply 메서드 등의 기능을 활용해 weekday의 정보를 월~일의 이름으로 변환
- 요일 이름이 담긴 리스트를 선언하고 0~6번째 인덱스의 값에 매칭되는 이름으로 한글 요일 이름을 추출할 수 있음
# 0~6번 인덱스 위치에 각 한글 요일 이름이 담긴 리스트
weekday_list = ['월', '화', '수', '목', '금', '토', '일']
# apply 함수로 숫자 -> 요일 이름으로 변환
df['요일'] = df.apply(lambda x : weekday_list[x['weekday']], axis = 1)
dfapply(lambda if) 함수
-
def를 이용해 함수로 나타낸 코드의 return 값을 모든 데이터프레임에 적용할 수 있음 → apply 함수 이용
- 리스트에서 map 함수가 있다면, 데이터프레임에는 apply 함수가 있다.
-
전체 데이터프레임이나 특정 칼럼 값을 일괄적으로 가공하는 게 더 빠르겠지만, 특정 조건을 걸어서 조금 더 복잡하게 데이터를 가공해야 할 때 lambda식과 결합하여 apply lambda를 이용함
파이썬 Python list map lambda x y 함수
- lambda 함수는 함수명을 프로그래밍할 때, 사용자 정의 함수를 문법에 맞춰 작성하는 것보다 간단하게 해결할 수 있도록 만듦
:를 기준으로 왼쪽에는 입력 인자들을, 오른쪽에는 계산식(반환되는 return값)을 입력
# a와 b의 값을 더하는 get_sum(a,b) 함수
def get_sum(a,b):
return a+b
print(get_sum(10,20))
# 위 식을 lambda식으로 쓰면 한 줄로 작성 가능
get_sum_lambda = lambda x,y : x+y
print(get_sum_lambda(10,20))- 만약 여러 개의 입력 인자들이 리스트 형태로 있을 경우 map을 이용해 한 번에 처리 가능
a = [10,20,30]
b = [4,5,6]
sums = map(lambda x,y : x+y, a,b)
list(sums)
# 실행 결과: [14, 25, 36]→ lambda 매개변수 1, 매개변수 2 : 공식, 매개변수 1, 매개변수 2와 같이 작성
판다스 데이터프레임 Pandas apply (lambda) 활용
- 데이터프레임의 apply(lambda) 식은 파이썬 리스트 map rambda와 똑같은 원리로 작동
- 함수를 먼저 만든 다음 .apply(lambda x: 함수(변수))와 같은 식으로 적용
- lambda를 사용할 때, if나 else if, else는 이용이 불가능하지만 유일하게 이용할 수 있는 것이 if else문
반환값1 if 조건식 else 반환값2와 같은 형태로 작성해야 한다는 점만 유의해서 사용하면 됨
e.g.
18세 이하면 Child, 아니면 Adult로 값을 할당하기 위한 람다식의 작성
lambda x : 'Child' if x<=18 else 'Adult'
Pandas lambda if else
- 데이터프레임의 컬럼에 apply로 일괄 적용
데이터프레임명.apply(lambda x : x['칼럼명'] 반환값
if x['칼럼명'] 조건식
else x['칼럼명'] 반환값),
axis=1)예시
- titanic 데이터의 Age 값을 4세 이하는 Baby, 5세~18세 이하는 Child, 나머지는 Adult로 분류
#1. 바로 lambda식 이용하기. 간단하고 빠르지만, 조건을 많이 걸어야 하는 상황에는 부적합하다.
df['Age_cat1']=df['Age'].apply(lambda x:'Baby'
if x<=4
else ('Child'
if x<=18
else 'Adult'))
print(df['Age_cat1'].value_counts())
df[['Age','Age_cat1']].head()
#2. 함수 만들어서 lambda식 적용하기. 세분화된 분류가 필요한 경우 적절하다.
def Age_cat2(age):
cat2=''
if age<=4 : cat2= 'Baby'
elif age<=18 : cat2= 'Child'
else : cat2 = 'Adult'
return cat2
df['Age_cat2']=df['Age'].apply(lambda x : Age_cat2(x))
print(df['Age_cat2'].value_counts())
df[['Age','Age_cat2']].head()그룹별 구간 나누기
수치형 데이터의 구간 나누기
- qcut()과 cut() 함수
- qcut(): 절대평가
- cut(): 상대평가
pd.qcut(data['close_price'], 3).value_counts()
pd.cut(data['close_price'], 3).value_counts()나누어진 구간에 라벨링
pd.qcut(data['close_price'], 3, labels = ['L', 'M', 'H'])
pd.cut(data['close_price'], 3, labels = ['L', 'M', 'H'])라벨링한 값을 새로운 열로 추가
data['close_price_group'] = pd.qcut(data['close_price'], 3, labels = ['L', 'M', 'H'])
data[["ticker", "sector", "close_price", "sector_mean", "close_price_group"]]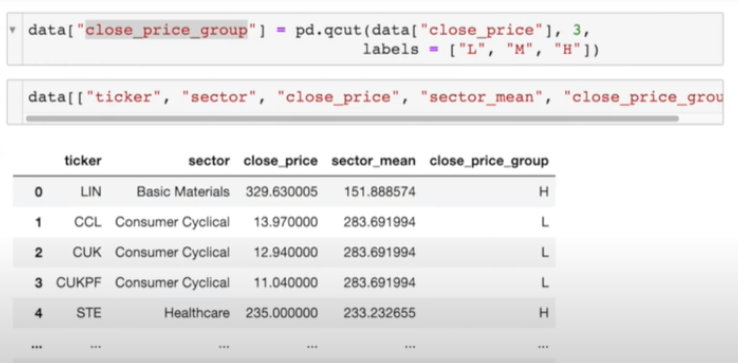
→ 라벨링한 값은 전체 close_price를 기준으로 그룹지어 라벨링한 것이기 때문에 sector를 기준으로 groupby가 한 번 더 필요
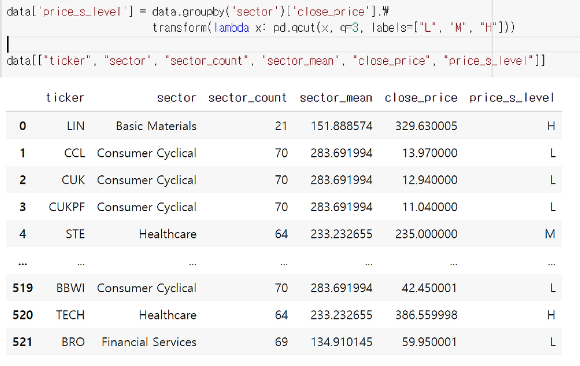
그룹별 구간 데이터 라벨링
data["price_s_level"] = data.groupby(['sector'])['close_price'].transform(lambda x: pd.qcut(x, 3, labels = ['L', 'M', 'H']))
data[["ticker", "sector", "sector_count", "sector_mean", "close_price", "price_s_level"]]- sector 열을 기준으로 groupby하고 close_price열에 대해 계산한 값을 새로운 열로 추가(
.transform())- 이때 close_price열에 대해 동일 개수로 나눠주는 계산(
pd.qcut())을 람다 함수(lambda x:)로 수행
- 이때 close_price열에 대해 동일 개수로 나눠주는 계산(
pandas.cut
- 주로 연속형 데이터를 구간(빈)으로 나누고 범주형 데이터로 변환하는 데 사용
- 데이터를 분석하고 시각화할 때 유용하며, 데이터의 구간별 요약 통계를 생성하는 데도 사용
pandas.cut(x, bins, labels=None, right=True, include_lowest=False, ...)
- x
- 나눌 연속형 시리즈나 배열
- bins
- 나눌 구간(빈)을 지정하는 값
- 리스트 또는 숫자의 시퀀스로 지정 가능
- labels
- 나눠진 구간에 대한 레이블을 지정
- 이 매개변수를 지정하지 않으면 구간의 값을 레이블로 사용
- right
- 기본값은 True
- 오른쪽 경계값을 포함하는 것을 의미 - False로 설정하면 왼쪽 경계값을 포함
- 기본값은 True
- include_lowest
- True로 설정하면 가장 낮은(최소) 구간에 속하는 값을 포함
- 기본값은 False
import pandas as pd
df = pd.DataFrame()
x = np.arange(6)+1
df["x"] = x
df["cut1"] = pd.Series(pd.cut(x, [1,3,5]))
df["cut2"] = pd.Series(pd.cut(x, [-np.inf,1,3,5,np.inf]))
df
x cut1 cut2
0 1 NaN (-inf, 1.0]
1 2 (1.0, 3.0] (1.0, 3.0]
2 3 (1.0, 3.0] (1.0, 3.0]
3 4 (3.0, 5.0] (3.0, 5.0]
4 5 (3.0, 5.0] (3.0, 5.0]
5 6 NaN (5.0, inf]→ 1과 6의 경우에는 어떤 구간에도 속하지 않으므로 NaN(결측치)으로 표시됨: cut1 열에서 NaN 값이 발생
→ 반면에 cut2 열에서는 구간 경계값을 [-inf, 1, 3, 5, inf]로 지정했으므로 1이하 5초과의 값이 각각 (-inf, 1.0], (5.0, inf]구간에 속하게 됨
