코딩테스트
알고리즘
import pandas as pd
def solution(nums):
answer = 0
nums = pd.Series(nums)
if nums.nunique() > (len(nums)/2):
answer = len(nums)/2
else:
answer = nums.nunique()
return answer- unique한 값의 개수가 필요해서 pandas의 nuique를 떠올렸는데 더 간단한 게 있었다!
- 집합(set)은 중복을 허용하지 않기 때문에 len(set(ls))는 무조건 unique한 값의 개수임
def solution(ls):
return min(len(ls)/2, len(set(ls)))SQL
WITH cte AS (
SELECT
o.sales_id
FROM
Orders as o
JOIN Company as c
USING (com_id)
WHERE
c.name = "RED"
)
SELECT
name
FROM
SalesPerson AS s
LEFT JOIN cte AS c
USING (sales_id)
WHERE
c.sales_id IS NULL
;- 다른 사람들 풀이 보니까 좀 더 간단하게 생각해도 됐었을 것 같다.
# 1
select s.name
from SalesPerson s
where s.name not in
(select s.name
from SalesPerson s
left join Orders o on s.sales_id = o.sales_id
left join Company c on o.com_id = c.com_id
where c.name = 'Red')
# 2
select s.name
from SalesPerson s
where s.name not in
(select s.name
from SalesPerson s
left join Orders o on s.sales_id = o.sales_id
left join Company c on o.com_id = c.com_id
where c.name = 'Red')
# 3
SELECT name
FROM SalesPerson
WHERE sales_id NOT IN(
SELECT sales_id
FROM Orders
WHERE com_id IN (
SELECT com_id
FROM Company
WHERE name="RED"
)
);오늘의 목표
- pandas 기본 사용법을 익히고 사용하기
- 데이터 분석 및 모델링 전처리 프로세스 이해하기
Pandas 라이브러리
- 행과 열을 가지는 구조의 데이터를 다룰 때 사용하는 라이브러리
Python == 인터프리터 언어
→ 소스코드를 한 줄 한 줄 읽어가며 명령을 바로 처리: 번역과 실행이 동시에 발생
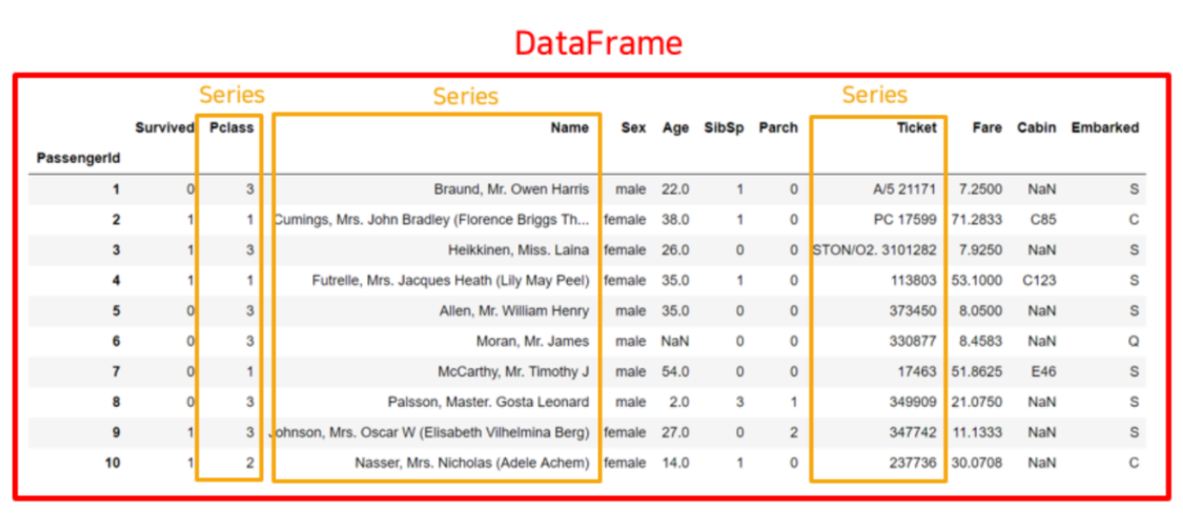
구조
- Series 자료형
- 1차원의 데이터 구조
- 인덱스 값 1:1 대응하는 데이터
- DataFrame 자료형
- 2차원 데이터 구조
- 행과 열의 값을 가짐
- 특징: 요소별 산술연상 가능
- 데이터들이 넘파이 배열 형태로 저장되어 있기 때문!
- Series가 모여 DataFrame이 됨
[]: list
{key:value}/{key:[v1, v2, …]}: dictionary
Series 데이터 생성
# 라이브러리 불러오기
import pandas as pd
pd.Series([10, 20, 30, 40, 50])DataFrame 생성
pd.DataFrame([["A", "apple"]
, ["B", "banana"]
, ["C", "cantaloupe"]
, ["D", "date"]
, ["E", "elderberry"]]
, index = [1, 2, 3, 4, 5]
, columns = ["alphabet", "fruits"])- 데이터프레임 특징
- 산술연산 가능 == 요소별 연산 가능
- 각 사람마다 12를 나누는 행위 OK
- 데이터들이 넘파이 배열 형태로 저장되어 있기 때문!
- 산술연산 가능 == 요소별 연산 가능
Dictionary를 활용한 생성
- 키값 → 컬럼명
data = {"alphabet": ["A", "B", "C", "D", "E"]
, "fruits": ["apple", "banana", "cantaloupe", "date", "elderberry"]}
df = pd.DataFrame(data, index = [1,2,3,4,5])데이터프레임 정보 확인
- 속성 잘 알아두기
- 데이터 분석 시 항상 데이터가 어떻게 생겼는지를 먼저 알아보아야 하기 때문
# 인덱스 확인
df.index
# 컬럼명 확인
df.columns
# 데이터 확인
df.values
# 데이터 크기(모양, 형태) 확인: (행, 열)
df.shape
# 데이터의 전반적인 특징, 정보 확인
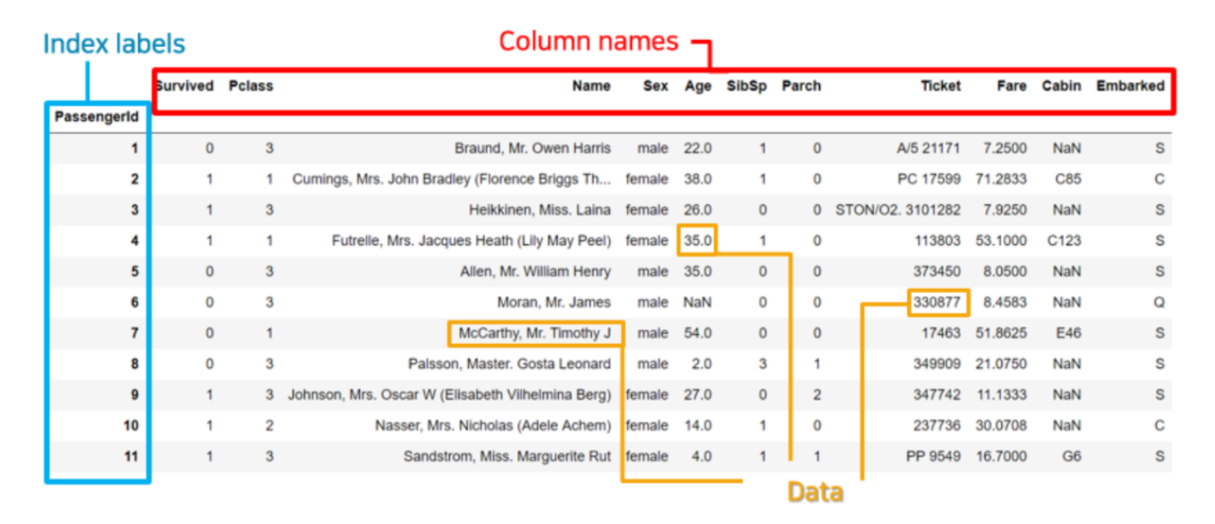
df.info() # info는 함수라서 () 필요데이터 색인: 기초
- 색인: 내가 원하는 데이터만 가져와서 확인하는 것
- 인덱싱
- 1개의 데이터를 추출
변수명[이름]
- 슬라이싱
- 범위를 주어 여러 개의 데이터를 추출
변수명[시작:끝+1]변수명["시작인덱스명":"끝인덱스명"]
- 인덱싱
- 인덱스는 인덱스 이름/숫자 모두 가능
열 색인
- 열(column) 하나 추출하기: 인덱싱
- 대괄호(
[])를 사용해 추출:DataFrame명[컬럼명]
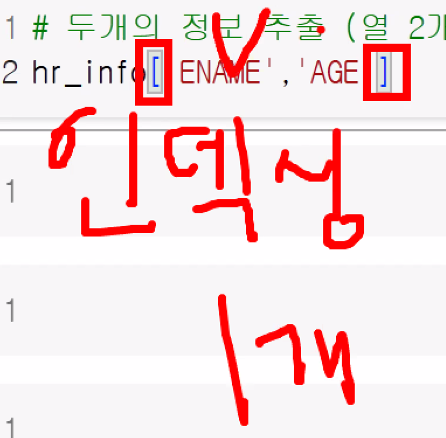
- 두 개의 정보 추출: 열 2개 추출
- list로 묶어서 하나로 보내야 인덱싱 가능(인덱싱은 '하나만' 추출)
- 대괄호(
행 색인
- 행은 슬라이싱만 가능
- 슬라이싱: 범위를 줘서 해당 범위만큼만 가져옴
- 인덱싱: 하나만 추출
디렉토리 구조 이해하기
경로(path)의 종류
| 구분 | 예시 | 설명 |
|---|---|---|
| 절대경로 | /home/jooinkim/projects/data.csv | 루트(/)부터 시작하는 전체 경로 |
| 상대경로 | ../images/logo.png | 현재 위치를 기준으로 상대적으로 지정한 경로 |
- 주의!
- 역슬래시 기호(
\)는 이스케이프 기호이기 때문에 단일 사용시 이스케이프 기호로 인지 - 역슬래시 기호로 인지시키기 위해
\\2번 작성 or/로 대체하여 사용 가능
- 역슬래시 기호(
Colab(코랩)
- 리눅스 기반의 환경이라 리눅스 명령어 사용 가능
- 맨 앞에
!: 일시 적용 - 맨 앞에
%: 영구 적용
- 맨 앞에
- 명령어 예시
!pws: 현재 내 파일의 위치 확인(Print Work Directory)%cd: change directory!ls: 현재 같은 폴더에 있는 파일 목록 확인
- 구글 마운트: 코랩과 구글 드라이브 연동
chardet 라이브러리
- 인코딩 감지 라이브러리
- 파이썬의 기본 언어는 영어이기 때문에 한글이 들어 있는 파일을 이용하려면 인코딩을 해줘야 하는 경우가 있음
import chardet
with open("./data/hr-info.csv", "rb") as f:
data = f.read() # 파일을 읽어서 변수 저장
chardet.detect(data) # 인코딩 분석- 한국어 인코딩
- EUC-KR
- UTF-8
- cp949
Career Up
- 인공지능사관학교 학습자의 취·창업 지원을 위한 프로그램
- 기초부터 심화학습 후 프로젝트 학습하는 1,300 시간의 본 교육과정을 순차적으로 진행
- Pre- 과정
- AI 빌드업: 공통
- AI 빌드업: 전공핵심
- AI 엑스퍼트: 전공심화
- AI 마스터
- AI 기술 심화 및 현장실습 경험을 진행하는 500 시간의 추가 교육으로 구성(1월 ~ 6월)
- AI+ 코스 (1월~4월): AI 심화 및 취업지원
- ESTERNSHIP (4월~6월): 현장실무 경험
- 기초부터 심화학습 후 프로젝트 학습하는 1,300 시간의 본 교육과정을 순차적으로 진행
| 주차 | 내용 |
|---|---|
| 6월 1주차 | 과정 오리엔테이션 / Goal Tracker 안내 / HR 멘토 소개 및 멘토링 |
| 6월 2주차 | 목표 설정 / 직업의 이해 / 좋은 기업 선택 방법 / 포트폴리오 구성을 위한 경험의 기준 / HR 멘토링 |
| 6월 3주차 | 노션 사용 방법 / 직무탐색 / 이력서 작성 방법 / HR 멘토링 |
| 6월 4주차 | 직무 탐색 / NCS 활용, 직무분석 / HR 멘토링 |
-
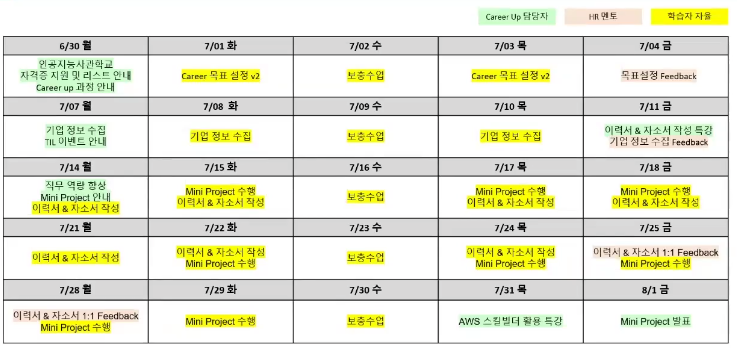
6월 공통과정 → 7월 자소서 → 8월 포트폴리오 → 9월 모의면접
-
7월 진행
목표란
- 달성하고 싶은 결과, 성과에 대해 명확히 정의한 것
- 학습에 대한 기준, 나아가야 하는 방향을 제시
동기부여
방향성
회고 기준
더 좋은 성과
좋은 목표의 특징
측정 가능성
- 목표의 달성 여부를 명확하게 확인할 수 잇음
- 진척율 관리에 용이
- 지속적으로 현황 점검 가능
- TIP
- '좋은', '우수한' 등의 추상적인 단어를 사용하기보다, 해당 형용사를 표현할 수 있는 지표를 설정
- 좋은 서비스를 만든다 → 서비스 이용자의 고객만족도는 평균 9.5 이상을 유지한다
- 달성, 미달성으로 표기되는 목표보다는 구체적 숫자로 표현(고객 n명 확보, 전환율 n% 확보)
- 고객관리 대시보드를 만든다 → 전환율 N%를 확보한다
- 전환률 N%를 확보하기 위한 세부 액션으로 '고객관리 대시보드를 만든다'를 입력
- '좋은', '우수한' 등의 추상적인 단어를 사용하기보다, 해당 형용사를 표현할 수 있는 지표를 설정
명확성
- 목표는 조직 구성원 모두가 함께 바라보는 방향
- 구성원들이 목표에 대해 동일하게 이해하려면 명확한 서술 필요
- TIP
- 하나의 해석이 가능하도록 설정
- 국내 10위 서비스가 된다 → 고객 수 측면에서 국내 10위 서비스가 된다
- 국내 10위에 대한 해석을 명확하게 제시(안 그러면 해석이 다양하게 가능하기 때문)
- 구성원들이 목표 달성을 위해 어떤 액션을 해야 하는지 이해할 때까지 목표를 잘게 쪼개기
- 매출 10억을 달성한다 → 막연함 → 달성을 위해 필요한 업무나 행동 등을 하위 목표로 서술해 구성원들의 이해를 돕기(재구매율을 20%에서 30%로 높인다 등)
- 하나의 해석이 가능하도록 설정
일관성
- 목표의 달성 여부를 명확하게 확인할 수 있음
- 진척률 관리에 용이
- 지속적인 현황 점검 가능
- TIP
- 상위 목표를 달성하기 위한 항목으로 하위 목표 구성하기
- 목표 align이 잘 되었다면 하위 목표가 달성되었을 때 상위 목표의 달성 가능성이 높아짐

내재적 동기를 위한 내재적 목표
목표 수립: SMART
- Specific(구체적)
- 명확하고 구체적으로 서술
- Measurable(측정)
- 데이터를 기반으로 성과를 측정할 수 있도록 설정
- Achievable(달성)
- 현실적으로 달성 가능한 목표
- Relevant(관련)
- 학습과 직접적 관련이 있도록
- Time-bound(시간)
- 성과 달성 시점을 명확히 설정
목표 CHECK
- 설정한 목표에 대해 기록을 남기는 것
- 목표, 측정 지표, 수행 기간을 기록하는 것이 기본
- 목표 진행 현황을 주기적으로 체크하고 기록으로 남겨야 함
- 제대로 목표를 향해 나아가고 있는지 점검 및 우선순위 재정리

2 B R 0 2 B