코딩테스트 연습
알고리즘
def solution(arr):
answer = [arr[0]]
for i in arr[1:]:
if i != answer[-1]:
answer.append(i)
return answer- 나는 arr의 첫 번째 값을 answer에 넣고 시작 & i와 answer[-1](answer 리스트의 마지막 값) 비교로 했는데, answer[-1:]로 슬라이싱을 사용하면 '리스트'가 반환되기 때문에 answer가 비어있을 때도 쓸 수 있다는 사실을 알게 되었음
- 하지만 이것은 실제 코드 효율성상 불리한데, 이는 list의 생성 과정에서 메모리 할당 과정이 추가로 붙기 때문이라고 함
def solution(arr):
answer = []
for i in arr:
if answer[-1:] == [i]:
continue
answer.append(i)
return answer- answer가 비어있을 경우를 아래와 같이 처리할 수도 있음
def solution(arr):
answer = []
for i in arr:
if len(answer) == 0 or answer[-1] != i:
answer.append(i)
return answer- 배열로 풀 수도 있음
def solution(arr):
answer = []
cnt = 0
answer.append(arr[0])
for a in arr[1:]:
if answer[cnt]==a:
continue
else:
answer.append(a)
cnt += 1
return answerSQL
SELECT
t1.id
, CASE
WHEN t1.p_id IS NULL THEN "Root"
WHEN COUNT(t2.id) > 0 THEN "Inner"
ELSE "Leaf"
END AS type
FROM
Tree AS t1
LEFT JOIN Tree AS t2
ON t1.id = t2.p_id
GROUP BY t1.id
;쿼리 비교
- 쿼리마다 접근 방식과 성능, 가독성, 사용 가능한 SQL 문법 등이 다름
1. 첫 번째 쿼리
SELECT
DISTINCT t.id
, CASE
WHEN t.p_id IS NULL THEN 'Root'
WHEN t2.id IS NULL THEN 'Leaf'
ELSE 'Inner'
END AS 'type'
FROM
Tree AS t
LEFT JOIN Tree AS t2
ON t.id = t2.p_id
;- 특징
- LEFT JOIN을 사용하여 자기 자신을 부모-자식 관계로 조인
- 부모가 없으면 'Root', 자식이 없으면 'Leaf', 둘 다 아니면 'Inner'로 분류
- DISTINCT를 사용해서 중복을 제거
- JOIN으로 인해 중복된 행이 생성될 수 있기 때문(JOIN으로 인해 부모 노드가 자식 수만큼 중복되어 나타남)
- LEFT JOIN을 사용하여 자기 자신을 부모-자식 관계로 조인
- 장점
- 직관적
- JOIN을 활용해 트리 구조를 명확히 보여줌
- SQL 표준에 가까움
- 대부분의 DBMS에서 동작함
- 단점
- 데이터가 많을 경우 JOIN으로 인해 성능이 떨어질 수 있음
- DISTINCT가 필요하므로 불필요한 연산이 추가될 수 있음
2. 두 번째 쿼리
SELECT
t1.id
, CASE
WHEN t1.p_id IS NULL THEN 'Root'
WHEN COUNT(t2.id) > 0 THEN 'Inner'
ELSE 'Leaf'
END AS type
FROM
Tree AS t1
LEFT JOIN Tree AS t2
ON t1.id = t2.p_id
GROUP BY t1.id
;- 특징
- LEFT JOIN을 사용
- GROUP BY와 COUNT를 활용
- 자식이 있으면 COUNT가 0보다 크므로 'Inner', 없으면 'Leaf'
- 장점
- 중복 행이 발생하지 않으므로 DISTINCT가 필요 없음
- GROUP BY를 통해 명확하게 각 id별로 한 줄씩 결과가 나옴
- 단점
- JOIN이므로 데이터가 많으면 느릴 수 있음
- GROUP BY가 추가되어 쿼리가 약간 더 복잡해짐
3. 세 번째 쿼리
SELECT
id
, CASE
WHEN p_id IS NULL THEN 'Root'
WHEN id IN (SELECT p\_id FROM Tree) THEN 'Inner'
ELSE 'Leaf'
END AS type
FROM Tree
;- 특징
- IN (SELECT ...) 서브쿼리를 사용하여 id가 다른 노드의 부모인지 확인
- JOIN 없이 한 번의 SELECT로 처리
- 장점
- 코드가 간결하고 읽기 쉬움
- JOIN이 없어서 작은 데이터셋에서는 빠를 수 있음
- 단점
- IN (SELECT ...) 는 데이터가 많을 때 성능 저하가 심할 수 있음
- DBMS에 따라 서브쿼리 최적화가 다르게 적용될 수 있음
4. 네 번째 쿼리
SELECT
id
, IF(ISNULL(p\_id), 'Root', IF(id IN (SELECT p\_id FROM tree), 'Inner', 'Leaf')) type
FROM tree
ORDER BY id
;- 특징
- 3번 쿼리와 거의 동일하나, MySQL의 IF 문법을 사용
- ORDER BY id로 결과 정렬 추가
- 장점
- MySQL에서 매우 간결하게 쓸 수 있음
- 가독성이 좋고, 정렬까지 포함되어 있음
- 단점
- MySQL 전용 문법
- 다른 RDBMS에서는 동작하지 않을 수 있음
- IN (SELECT ...) 의 성능 이슈
- MySQL 전용 문법
요약 표
| 쿼리 | JOIN 사용 | GROUP BY/COUNT | IN (SELECT ...) | DISTINCT 필요 | 정렬 | DBMS 호환성 | 성능(대용량) | 가독성 |
|---|---|---|---|---|---|---|---|---|
| 1 | O | X | X | O | X | 높음 | 보통 | 보통 |
| 2 | O | O | X | X | X | 높음 | 보통 | 보통 |
| 3 | X | X | O | X | X | 높음 | 낮음 | 좋음 |
| 4 | X | X | O | X | O | MySQL 전용 | 낮음 | 좋음 |
추천
- 데이터가 적고, MySQL을 쓴다면 4번 쿼리가 가장 간결
- 데이터가 많고, 범용성을 원한다면 2번 쿼리가 GROUP BY로 중복 없이 잘 처리됨
- 다른 DBMS 또는 표준 SQL을 원하면 1번이나 3번을 쓸 수 있음
(단, 3번은 데이터가 많을 때 성능이 떨어질 수 있음)
오늘의 TIP: alt+shift+위/아래 방향키 → 커서가 있는 줄 내용 바로 복사&붙여넣기(위/아래로)
지난 시간 복습
Pandas
- 두 개의 데이터 구조를 가짐: Series(1차원), DataFrame(2차원)
데이터 색인: 기초
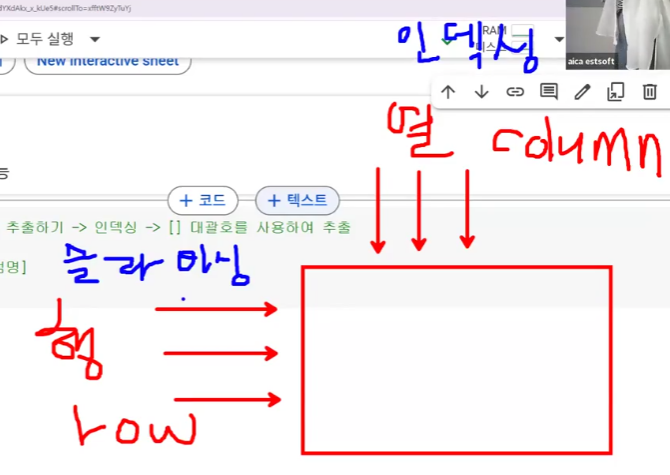
- 인덱싱
- 1개의 데이터를 추출
변수명[이름],변수명[[이름1, 이름2, …]]
- 슬라이싱
- 범위를 주어 여러 개의 데이터를 추출
변수명[시작:끝+1]
- 열(Column) 색인: 인덱싱만 가능
- 행(Row) 색인: 슬라이싱만 가능
신체정보측정데이터 처리
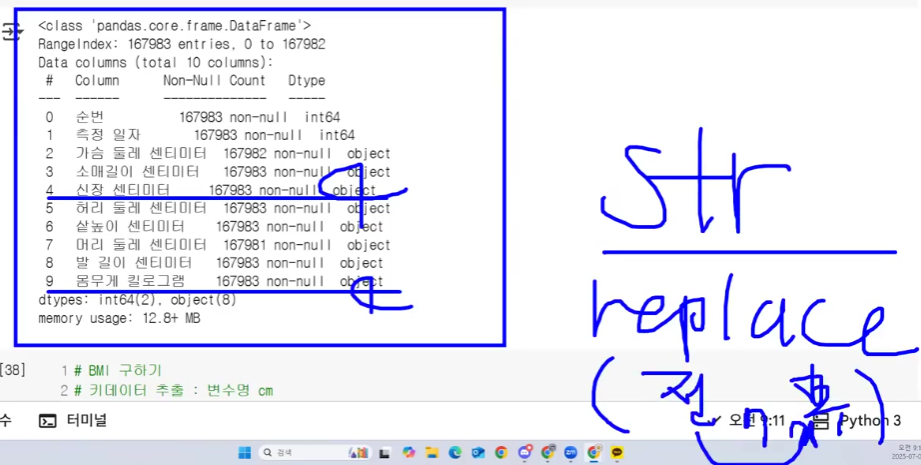
df["몸무게 킬로그램"].str.replace(" kg", '').astype("float64")- .str.replace(변경 전 데이터, 변경 후 데이터): 문자열 데이터를 대체
- BMI
- 몸무게(kg) / 키(m) ** 2
weight = df["몸무게 킬로그램"].str.replace(" kg", '').astype("float64")
height = df["신장 센티미터"].str.replace(" kg", '').astype("float64")
bmi = pd.Series(weight / (height/100) ** 2, name="BMI")
bmiBoolean Indexing
- 인덱스 번호가 아닌 '조건'을 중심으로 데이터 추출
- 조건 == 비교 연산의 결과
- 비교 연산의 결과가 참(True)인 값만 추출
- 형식:
변수명[조건]
예시
# 연봉이 5000 이상인 데이터만 추출
# DataFrame명[조건]
# 조건: hr_info['SALARY']>= 5000
hr_info[hr_info['SALARY']>= 5000]
# 성별이 여자인 사람의 이름만 추출
# 조건: 성별이 여자니?
# 1. 성별 컬럼 unique 값 확인
hr_info['GENDER'].unique()
# array(['M', 'F'], dtype=object)
# 2. 데이터에서 이름만 추출
hr_info['ENAME'][hr_info['GENDER'] == 'F']데이터 색인: 심화
데이터프레임은 열→인덱싱, 행→슬라이싱만 되는데 중간에 있는 값을 어떻게 가져올 수 있을까요?
- 인덱서(indexer)를 사용해 행과 열의 범위를 주어 데이터를 추출
.loc,.iloc, and also[]indexing can accept a callable as indexer
.loc와.iloc- 데이터프레임이나 시리즈에서 데이터 선택(접근)하는 메서드
- loc: location의 약자
- iloc: integer location의 약자
- 데이터프레임이나 시리즈에서 데이터 선택(접근)하는 메서드
- loc
- Label-based indexing
- may also be used with a boolean array
df.loc[행 범위, 열 범위]- 컬럼명, 인덱스명을 통해 추출
- Label-based indexing
- iloc
- Integer-location(integer position) based indexing
- from 0 to length-1 of the axis
- may also be used with a boolean array
df.iloc[행 범위, 열 범위]- 인덱스 번호를 통해 추출
- 끝 범위 + 1
- Integer-location(integer position) based indexing
데이터 추가(행, 열)
- 나중에 특성 공학(Feature Engineering)에서 중요하게 쓰이니 꼭 기억해주세요.
열(column) 추가
df["추가하고 싶은 컬럼명"] = 데이터- 가장 마지막 열로 추가됩니다.
열 삭제
df.drop(columns = ["삭제할 컬럼명"])- 컬럼을 삭제하는 행위는 신중해야 함!
→ 한 번 더 대입해주는 확인을 해 주거나 확인하는 코드가 필요
- 컬럼을 삭제하는 행위는 신중해야 함!
df.drop(columns = ["삭제할 컬럼"], inplace = True)- 확인하는 코드(
inplace = True)를 넣어줘야 df에서 바로 삭제됨
- 확인하는 코드(
df = df.drop(columns = ["삭제할 컬럼"])- 변수에 한 번 더 대입해줘도 삭제가 적용됨
df.drop("삭제할 컬럼명", axis=1)- drop 함수를 사용해 columns 파라미터에 값을 넣지 않고 열을 삭제하고 싶으면 축 설정 필수!
- 기본 설정은
axis=0이라 axis 입력을 안 하면 행으로 처리되므로 주의
- 기본 설정은
- drop 함수를 사용해 columns 파라미터에 값을 넣지 않고 열을 삭제하고 싶으면 축 설정 필수!
열 삽입
df.insert(loc=인덱스 번호, column="컬럼명", value=데이터)- 입력한 인덱스 번호 자리에 삽입됩니다.
- 이후 데이터는 뒤로 밀립니다.
행 추가
df.loc["추가하고 싶은 인덱스명"] = 데이터.loc- 데이터를 검색할 때 행 단위부터 시작 → 한 개만 작성해 줬을 때에는 행 인덱싱이 가능합니다.
- 주의사항
- column, 즉 특성의 개수를 맞춰서 넣어줘야 함
행 삭제
df.drop("삭제할 행 이름")
실습
- 불리언 인덱싱과 loc 활용
# 30살 미만("AGE")의 직원들의
# 연봉("SALARY")과 근속년수("SERVICE_YEAR")를 추출
# 행: 30살 미만, 열: 연봉, 근속년수
hr_info.loc[
hr_info["AGE"]<30
, ["SALARY", "SERVICE_YEAR"]
]
# 성별이 여자이면서 박사 학위를 가진 사람의 연봉 추출
# 조건 2개 -> '이면서'(and: & 기호 사용)
# 비교 연산의 우선 순위를 파악
hr_info[
(hr_info['GENDER'] == 'F') &
(hr_info['EDU_LEVEL'] == '박사 학위')
]['SALARY']
hr_info[hr_info['GENDER'] == 'F' & hr_info['EDU_LEVEL'] == '박사 학위']로 작성하면 오류 발생!
→ 비교 연산의 우선 순위로 인해'F' & hr_info['EDU\_LEVEL']가 먼저 연산: 문자열과 문자열 사이 and 연산은 불가능하기 때문에 오류가 발생합니다.
- 데이터 추가
# 연봉 정보를 활용하여 월 급여 컬럼 생성
# MONTHLY_PAY -> SALARY/12 -> 소수점 첫 번째 자리까지 출력(round 함수)
(hr_info["SALARY"]/12).round(1)
# 연봉 정보 옆에 월 급여 컬럼을 삽입
# 연봉 정보 인덱스 번호 확인: 8
hr_info.columns.get_loc("SALARY")
# 월 급여 컬럼 삽입
hr_info.insert(loc=9, column = "MONTHLY_PAY", value=(hr_info["SALARY"]/12).round(1))
# loc -> 데이터 검색 시 행 단위부터 시작
# -> 한 개만 작성해 주면 행 인덱싱이 가능
hr_info.loc["E00206"]
# 행 데이터 삭제
# 불리언 인덱싱을 통해서 '시이오' 이름을 가진 사람을 삭제
hr_info.drop(hr_info[hr_info['ENAME'] == '시이오'].index)
# 조건을 통해 데이터를 추출 후 변수명에 대입
ht_drop = hr_info[hr_info['ENAME'] == '시이오']
# drop 삭제 함수 사용 시 열 삭제는 축 설정 필수!
hr_info.drop("ENAME", axis=1)Machine Learning
학습 목표
- Machine Learning의 개념을 이해할 수 있다.
- Machine Learning의 종류 및 과정을 알 수 있다.
- 기계 학습과 관련된 기본 용어를 알 수 있다.
AI vs. ML vs. DL
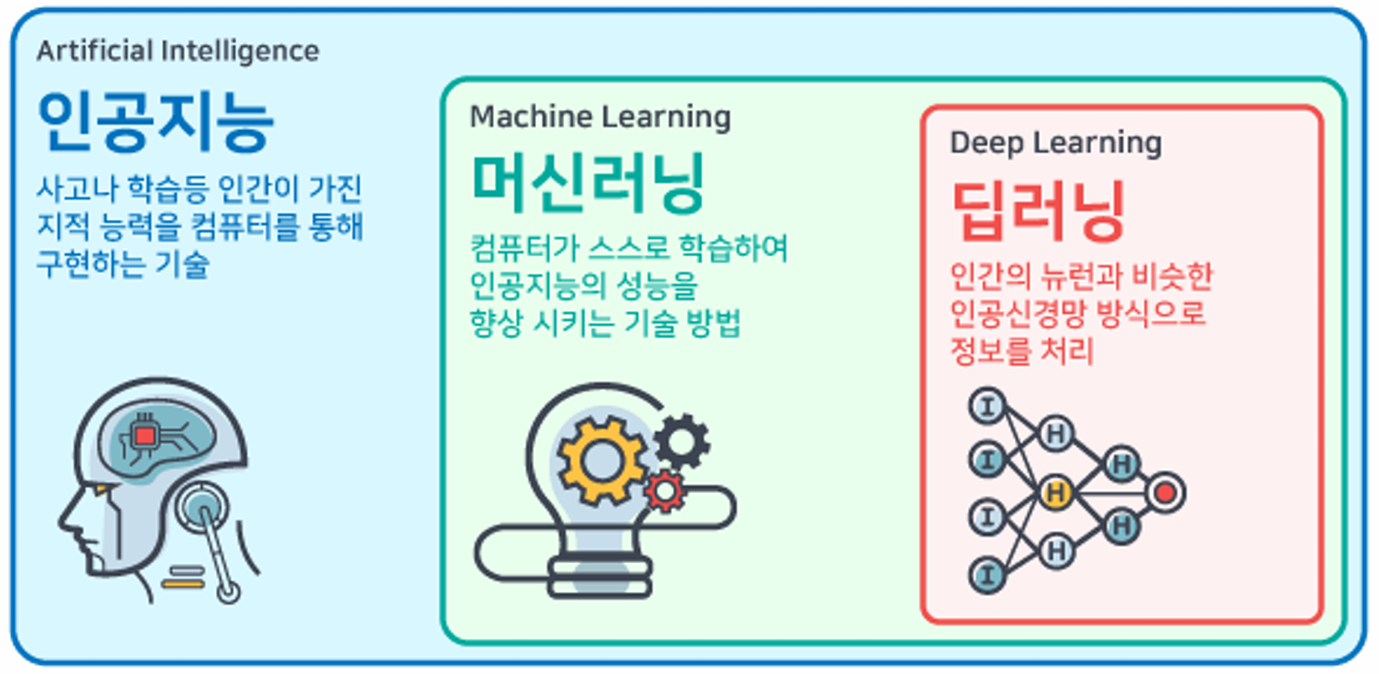
- 인간의 지적 능력을 기계가 가짐: 인공지능
- 기계로 인간이 가지고 있는 지능을 구현
- 컴퓨터가 지능을 가지고 스스로 학습: 머신러닝
- 학습 결과를 가지고 새로운 데이터 예측
- 기계를 좀 더 사람처럼: 딥러닝
- 인간의 신경망을 모방한 기술
머신러닝(Machine Learning)이란?
- 데이터를 기반으로 학습을 시켜서 예측하게 만드는 기법
- 인공지능의 한 분야
- 컴퓨터가 학습할 수 있도록 하는 알고리즘 기술을 개발하는 분야
- 통계학, 데이터 마이닝, 컴퓨터 과학이 어우러진 분야
- 데이터 마이닝: 데이터에서 유의미한 인사이트를 추출하는 것
ML의 역사

- Alan Mathison Turing(1912 - 1954)
- 1차 암흑기
- 하드웨어 issue(성능이 나쁨) 및 데이터 부족 문제(기계에 입력하는 것 자체가 어려웠음)로 인해 발생
- 규칙 기반 전문가 시스템(Rule-Based Expert System)
- if와 else로 하드 코딩된 명령을 사용하는 시스템
- 2차 암흑기
- 규칙 기반 전문가 시스템이 기계학습이 아닌 하드 코딩의 결과물임이 드러나서 발생
- AI 부활
- 스마트폰의 등장으로 데이터가 폭발적으로 증가 & 하드웨어의 발전
인공지능 종류
- 약한 인공지능(Artificial Narrow Intelligence, ANI)
- Weak AI(약인공지능)라고도 부름
- 특정 분야를 위해 제작
- 체스, 퀴즈, 자율주행, 상품추천, 번역 시스템, 알파고(특정 임무 수행) 등
- 강한 인공지능(Artificial General Intelligence, AGI)
- Strong AI(강인공지능)라고도 부름
- 모든 방면에서 인간급
- 사고, 계획, 문제 해결, 추상화, 복잡한 개념 학습
- 초인공지능(Artificial Super Intelligence, ASI)
- 과학 기술, 사회적 능력 등 모든 영역에서 인간보다 뛰어남
- "충분히 발달한 과학은 마법과 구분할 수 없다.(Any sufficiently advanced technology is indistinguishable from magic.)" - 아서 C. 클라크 (→ 2001 스페이스 오딧세이 작가)
AI를 "어떻게 활용"할 것인지가 중요함
생성형 AI를 잘 활용하는 방법을 알아야 함
- Beneficial AI 2017 컨퍼런스
- 인공지능의 위험성에 대한 우려로 제정
- 초인공지능이란 영역이 도달 가능한지, 초지능을 가진 개체가 출현 가능할지 묻자 연사 9명 모두 '그렇다'라고 답함
- 정책이 기술을 따라가지 못하는 문제
- 윤리, 도덕 관점 → 옳고 그름을 판별할 수 있는 지능을 갖춰야 함
- 인공지능의 위험성에 대한 우려로 제정
- 불쾌한 골짜기
- 인간이 인간과 유사한 로봇에 대해 호감도가 증가하다가 어느 정도에 도달하면 갑자기 강한 거부감을 느끼는 현상
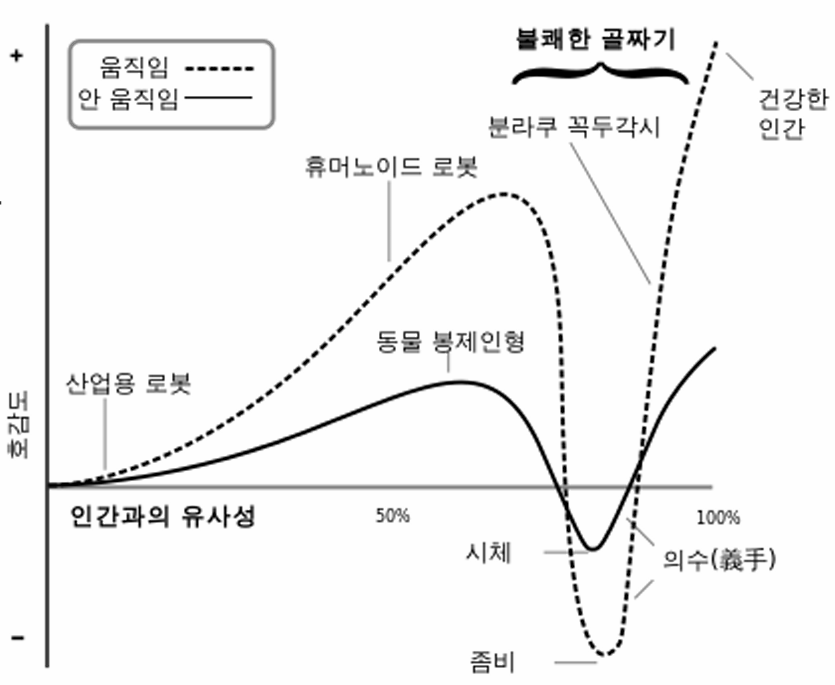
- 최근 광고에 등장하는 가상 인플루언서에 대해서도 불쾌한 골짜기를 느끼는 사람이 많음
- 인간이 인간과 유사한 로봇에 대해 호감도가 증가하다가 어느 정도에 도달하면 갑자기 강한 거부감을 느끼는 현상
- 지능, 윤리&도덕 관점
- 단순히 똑똑한 것을 넘어서서 옳고, 그름을 판별할 수 있는 지능을 가지는 것이 인공지능 목표
- 자율주행차의 윤리적 딜레마
- 트롤리 딜레마
- 단순히 똑똑한 것을 넘어서서 옳고, 그름을 판별할 수 있는 지능을 가지는 것이 인공지능 목표
ML vs. DL
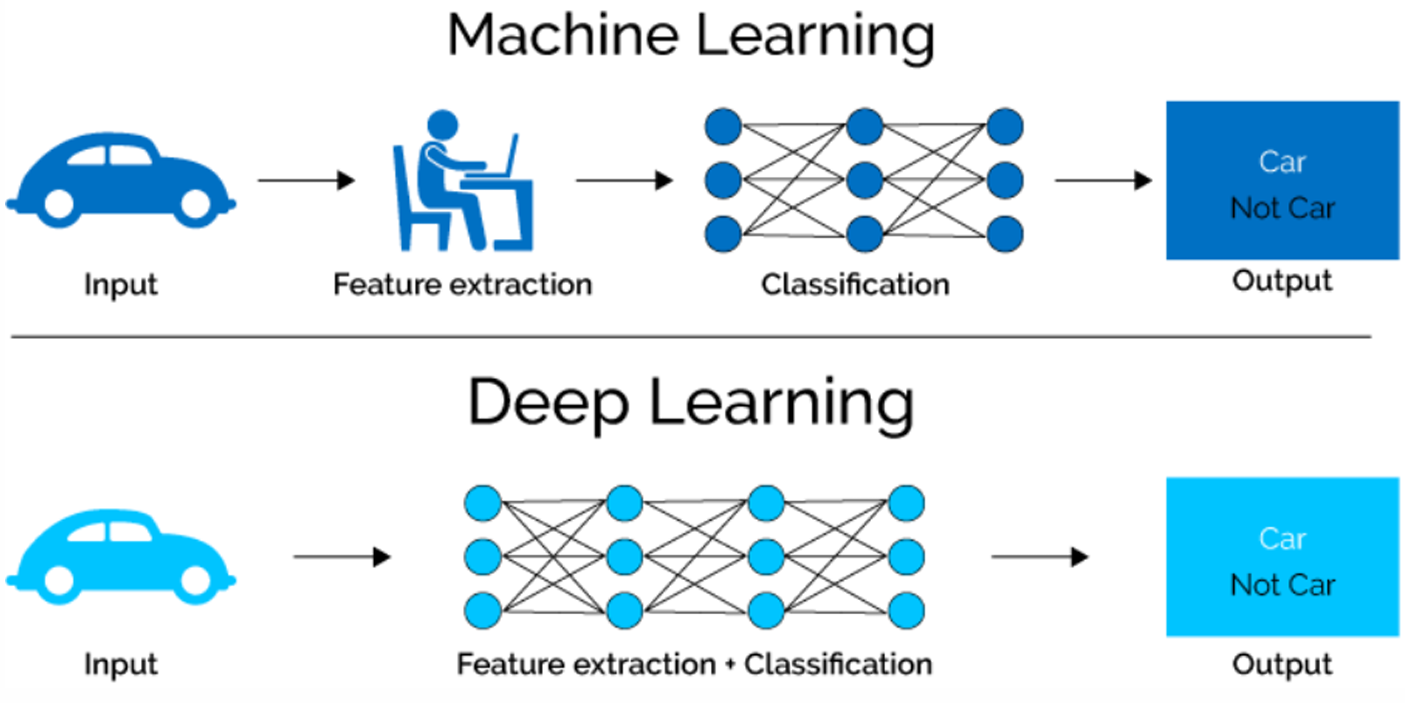
- 머신러닝과 딥러닝의 차이
- 머신러닝은 'Feature extraction'이라는 특성에 대한 추출을 사람이 진행
- 딥러닝은 특성 추출도 기계가 함
Rule-based expert system
- 규칙 기반 전문가 시스템
- "if"와 "else"로 하드 코딩된 명령을 사용하는 시스템
- 결과물을 보면 기계학습처럼 보이게끔 만들어 주지만 실제로는 기계학습이 아님
- 예: 심심이(chatting robot)
- 문제점
- 많은 상황에 대한 규칙들을 모두 만들어 낼 수 없음
- 제작한 로직이 특정 작업에만 국한됨 → 작업이 조금만 변경되어도 전체 시스템을 다시 만들어야 할 가능성 높음
- 규칙을 설계하려면 해당 분야에 대해 잘 알아야 함
- 예시
- 스팸 메일 필터: "발신자가 X이면 메일을 스팸 폴더로 이동한다" 또는 "제목에 Z가 포함되어 있으면 메일을 스팸 폴더로 이동한다" 등과 같은 if/then/else 조건문을 이용
- 자연어 처리
- 얼굴 인식 시스템
- "if"와 "else"로 하드 코딩된 명령을 사용하는 시스템
Machine Learning 등장
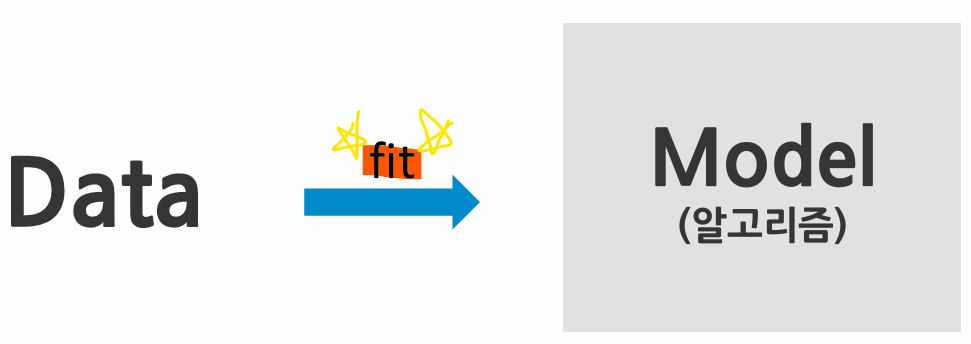
- 데이터를 이용하여 스스로 특성과 패턴을 찾아 학습하고 예측을 수행하는 것
- fit: '학습 과정'이라고 생각하면 됨
- 학습하고자 하는 데이터에 딱 맞춘다는 느낌
- 머신러닝은 학습 과정을 거쳐야 함
- 모델이라는 알고리즘을 통해 학습
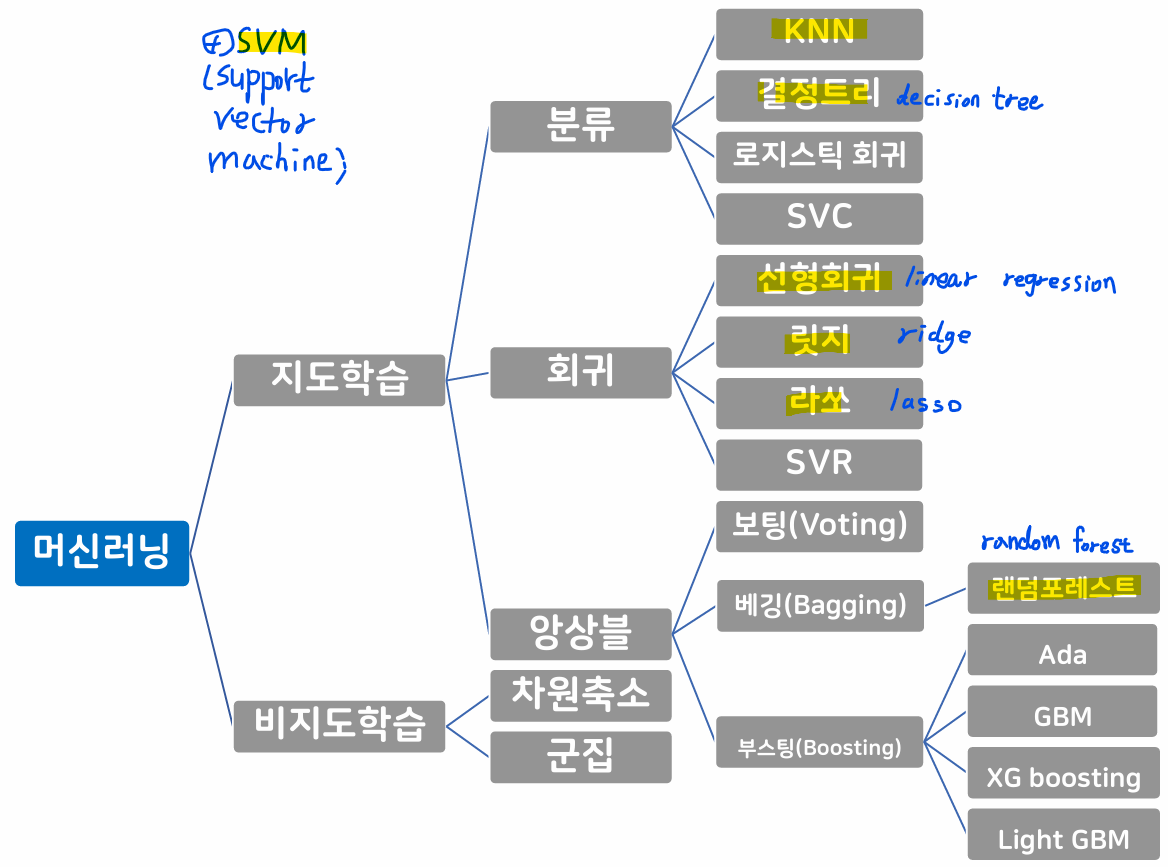
머신러닝 종류
- 지도 학습(Supervised Learning)
- 비지도 학습(Unsupervised Learning)
- 강화 학습(Reinforcement Learning)
지도 학습
- 데이터에 대한 Label(명시적인 답)이 주어진 상태에서 컴퓨터를 학습시키는 방법
- 종류: 정답 label의 형태에 따라 구분
- 분류(Classification) → Classifier
- 정답이 범주형(categorical)이면 분류 학습: 스팸 분류(이지선다→클래스 2개), 붓꽃 품종 분류 등
- 미리 정의된 여러 클래스 레이블 중 하나를 예측(클래스: 정답 데이터의 카테고리, 레이블: 정답)
- 속성 값을 입력, 클래스 값을 출력으로 하는 모델
- 이진분류(클래스 2개), 다중분류(클래스 3개 이상)
- 회귀(Regression) -> Regressor
- 정답이 연속형(숫자)이면 회귀: 연봉 예측, 집값 예측
- 연속적인 숫자 예측
- 속성 값을 입력, 연속적인 실수 값을 출력으로 하는 모델
- 예측 값의 미묘한 차이가 크게 중요하지 않음
- 분류(Classification) → Classifier
- 범주형은 error가 치명적
- A형인데 B형으로 분류해서 수혈하면 큰일남
- 연속형은 조금 차이가 있어도 괜찮음
- 수요 예측이 15만 명/15만 1명 → 작은 차이는 큰 영향 없음
성적 예측 → 학점 예측이라면 분류, 점수 예측이라면 회귀
비지도 학습
- 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법
- 데이터의 숨겨진 특징, 구조, 패턴 파악
- 종류
- 클러스터링(Clustering; 군집화)
- 차원축소(Dimensionality Reduction) 등
- 예시
- 이미지 감색 처리
- 소비자 그룹 발견을 통한 마케팅
- 마케팅에서 많이 사용
- 넷플릭스 컨텐츠 추천
- 신서유기를 좋아하는 사람에게 지구오락실 추천
- 삼시세끼를 좋아하는 사람에게 언니네 산지직송 추천
- 월마트 소비 패턴 분석
- 기저귀-맥주: 주말에 산 기저귀가 보통 수요일에 떨어짐 → 기저귀 심부름 간 김에 맥주를 삼 → 기저귀 옆에 맥주 코너 옮기니 매출 7배 상승
- 넷플릭스 컨텐츠 추천
- 비지도학습은 주로 지도학습을 위해 사용됨
- 정답을 만들어 지도학습 진행
강화 학습
- 지도학습과 비슷하지만 완전한 답(Label)을 제공하지 않음
- 기계는 더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
- 주로 게임이나 로봇을 학습시키는 데 많이 사용
- 로봇 길찾기
- 알파고

머신러닝 과정
- Problem Identification(문제정의)
- Data Collect(데이터 수집)
- Data Preprocessing(데이터 전처리)
- EDA(Exploratory Data Analysis; 탐색적 데이터 분석)
- Model 선택, Hyper Parameter 조정
- Training(학습)
- Evaluation(평가)
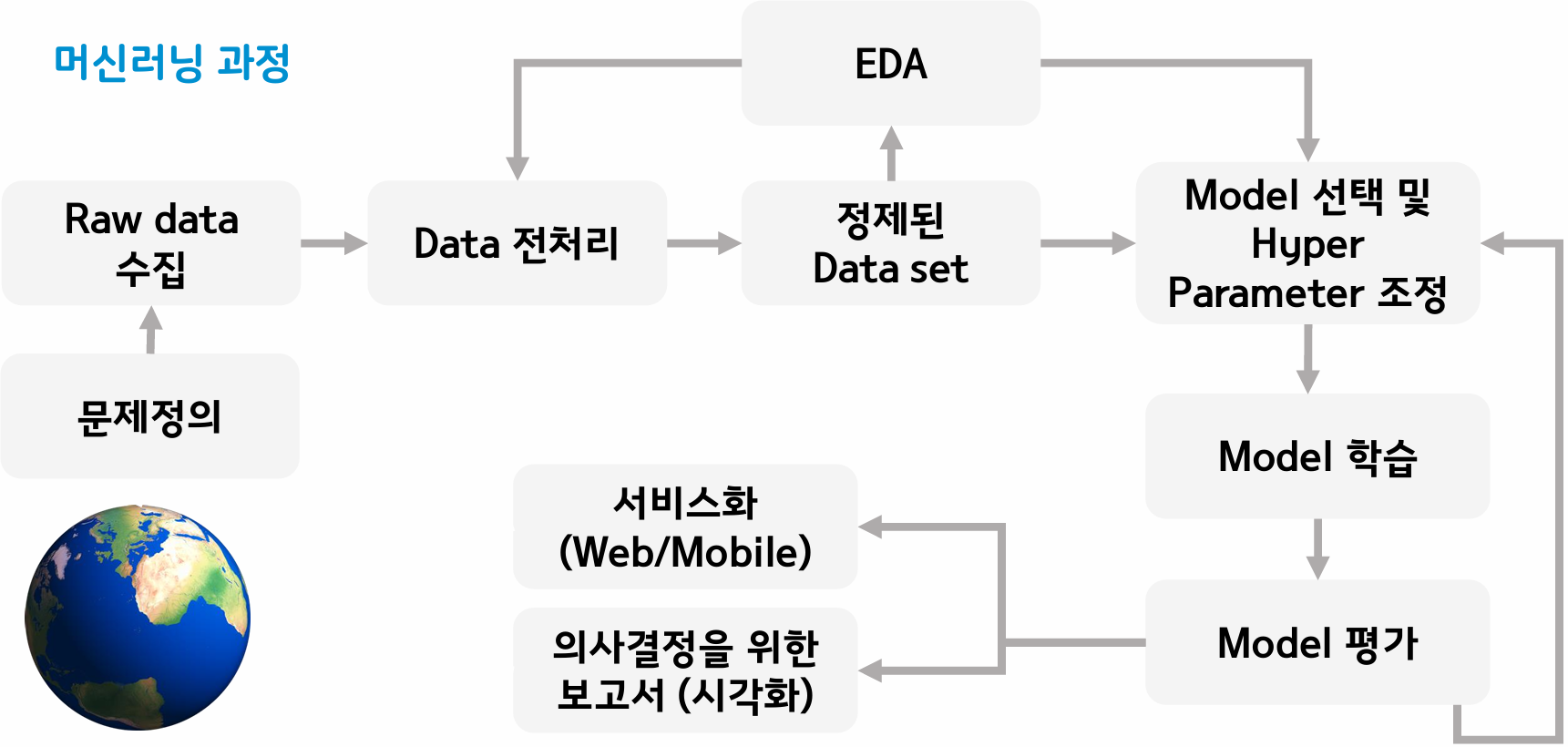
→ Data 전처리, EDA, Model 선택 및 Hyperparameter 조정은 유기적으로 움직임!
1. Problem Identification
- 비즈니스 목적 정의
- 모델을 어떻게 사용해 이익을 얻을까?
- 현재 솔루션의 구성 파악
- 지도 vs 비지도 vs 강화
- 분류 vs 회귀
- 다음 학기 성적 점수를 예측하려면 어떤 특성이 필요할까?
- 성적 점수를 예측 → 회귀
- 입력특성: 직전 학기 성적, 아르바이트 진행 여부, 수면 시간, 출석률, 학교와 집 사이 거리, 연애 여부
- 특성: 정답을 유추해내기 위해 입력받은 다양한 데이터(입력 데이터)
- 다음 학기 성적 점수를 예측하려면 어떤 특성이 필요할까?
2. Data Collect
- File(CSV, XML, JSON)
- CSV: comma separated values
- 기호로 구분이 되어 있는 데이터
- CSV: comma separated values
- Database
- Web Crawler
- 뉴스, SNS, 블로그 등
- IoT 센서를 통한 수집
- Survey
- 설문조사는 프로젝트(연구)의 당위성을 제공하는 데에도 유용하게 사용
3. Data Preprocessing
→ 매우 중요!
- 결측치, 이상치 처리
- 결측치(NaN)가 있으면 학습 불가
- 결측치: 비어 있는 값
- 결측치(NaN)가 있으면 학습 불가
- Feature Engineering(특성 공학)
- Scaling(단위 변환)
- Encoding(범주형 -> 수치형)
- 문자 데이터는 학습이 불가능하기 때문에 인코딩 진행해야 함
- Binning(수치형 -> 범주형)
- 컴퓨터는 11, 12, 13세를 각각 다른 특성으로 인식 -> 이를 청소년/10대와 같이 묶어주면 그룹의 학습을 하기 때문에 예측률이 높아짐: 일반화
- 일반화는 모델 학습 시 가장 중요! -> 누구에게 적용시켜도 항상 작동해야 하니까
- Transform(새로운 속성 추출)
4. EDA
- 기술통계
- 평균, 중앙값, 최빈값 등
- 변수간 상관관계
- 시각화
- Feature Selection(사용할 특성 선택)
- 특성 ≒ 변수
5. 모델 선택, Hyper Parameter 조정
- 목적에 맞는 적절한 모델 선택
CNN(합성곱 신경망), RNN(순환 신경망) → 딥러닝 - Hyper Parameter
- model의 성능을 개선하기 위해 사람이 직접 넣는 parameter
6. Model Training
model.fit(X_train, y_train)- train 데이터와 test 데이터를 7:3 정도로 나눔
- train 데이터의 문제와 정답으로 모델 학습
model.predict(X_test)- test 데이터의 문제를 넣고 정답을 예측
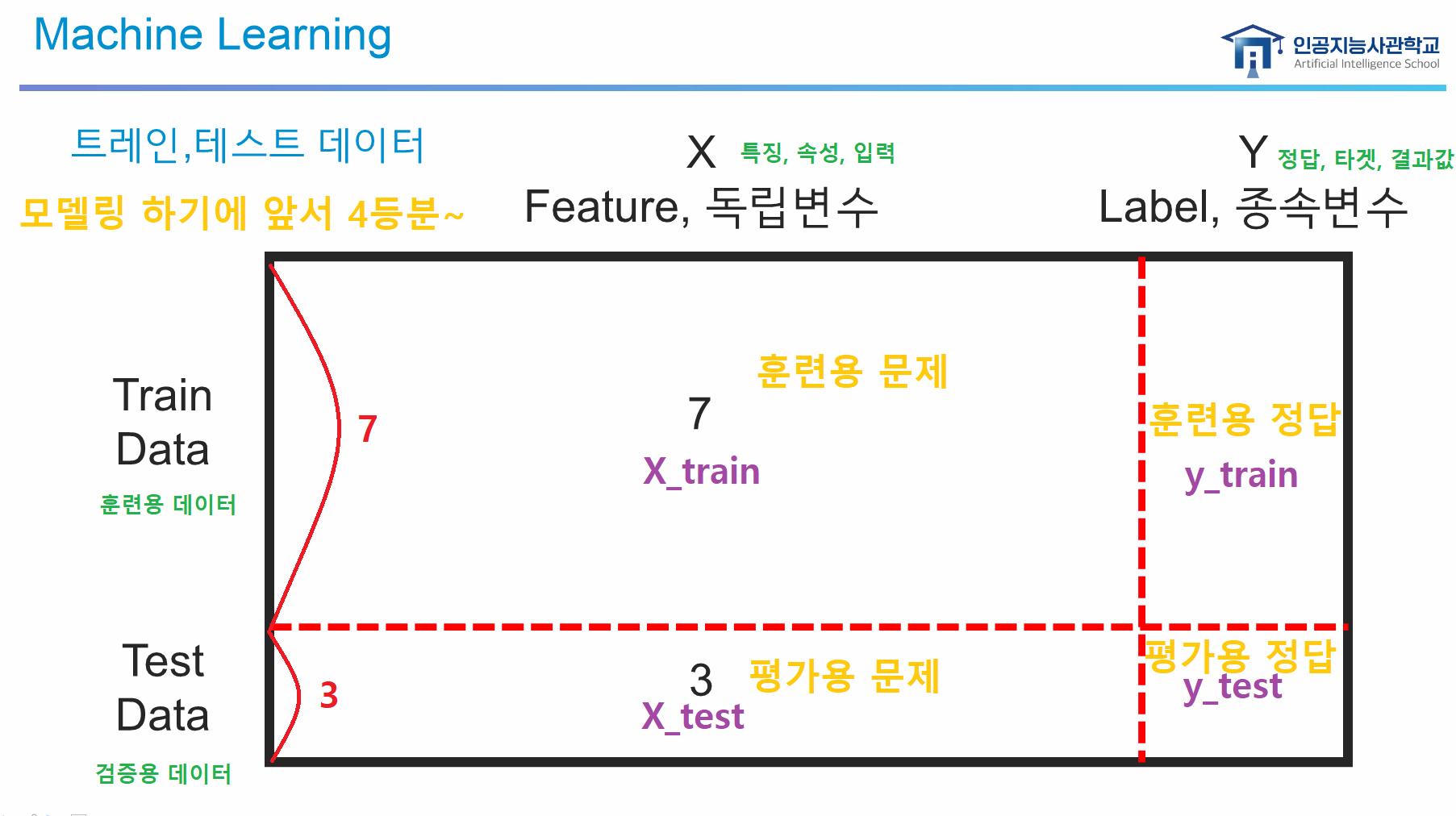
- y 데이터는 시리즈 데이터 -> 1차원 -> 소문자
- X 데이터는 데이터프레임 데이터 -> 2차원(여러 개의 특정) -> 대문자(다차원은 대문자로 표시)
- 문제 데이터는 항상 2차원이어야 함!
- 특성이 한 개라도 2차원으로 넣어줘야 함:
[[입력특성]]
- 특성이 한 개라도 2차원으로 넣어줘야 함:
- 문제 데이터는 항상 2차원이어야 함!
데이터 분리
- 문제(X), 정답(y)
- 훈련(train), 정답(test) → 7:3 정도로 나눔
→ "4등분" 변수 저장: 모델링 준비!
7. Evaluation
- 분류 분석
- accuracy(정확도)
- 모델이 얼마나 정확하게 예측했는가를 의미
- 0 ~ 1 사이의 값: 1에 가까울수록 좋음
- recall(재현율)
- precision(정밀도)
- f1 score
- roc 곡선의 auc
- accuracy(정확도)
- 회귀 분석
- MSE(Mean Squared Error)
- RMSE(Root Mean Squared Error)
- (R Square)
머신러닝 모델 학습을 위한 도구
- scikit-learn
- 파이썬에서 쉽게 사용할 수 있는 머신러닝 프레임워크, 라이브러리
- 회귀, 분류, 군집, 차원축소, 특성공학, 전처리, 교차검증, 파이프라인 등 머신러닝에 필요한 기능을 갖춤
- 학습을 위한 샘플 데이터 제공
AND 연산 학습하기
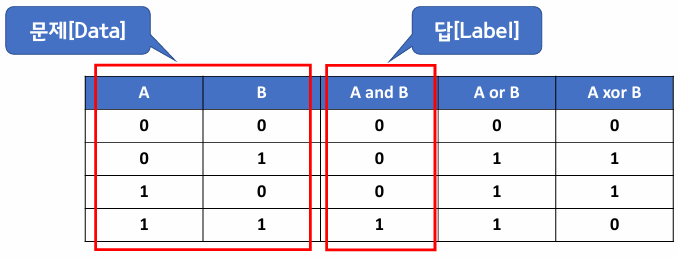
실습: 머신러닝 7단계
- 문제 정의
- 데이터 수집
- 데이터 전처리
- EDA(Exploratory Data Analysis; 탐색적 데이터 분석)
- 모델 선택 및 하이퍼 파라미터 설정
- 모델 학습 및 예측(fit, predict)
- 모델 평가
실습 목표
- 머신러닝의 7가지 과정을 이해하기
- 머신러닝의 학습 과정을 이해하고 결과를 확인하기
- 온·습도 데이터를 분석하여 결과를 예측해보기
1. 문제 정의
- Role: 서비스 기획자
- 가정 내 온·습도 측정 제품을 고객에게 제공
- 새로운 고객 가치를 발견하기 위하여 데이터 분석
- 온·습도 데이터를 수집하여 AI 제습기를 개발하고자 함 → 환기 여부를 추천해주는 AI 제습기 제작을 원함
2. 데이터 수집
온습도 관측 데이터.csv- 데이터 설명
- 3개의 센서 데이터가 수집됨(원활한 실습을 위해 label은 미리 달아둠)
- 데이터 명세
- 데이터 설명
| Column Name | 컬럼명 | 설명 |
|---|---|---|
| T(temperature) | 온도 | 주변 환경의 온도 (섭씨) |
| RH(relative humidity) | 상대습도 | 공기 중 습도의 비율 (%) |
| AH(absolute humidity) | 절대습도 | 공기 중 실제 수증기량 |
| Comfortable | 쾌적 여부 | 환경이 쾌적한지 나타내는 이진값 - 0(불쾌), 1(상쾌) |
- IoT 센서, survey, crawling, 공공데이터포털 등을 활용하여 데이터 수집도 가능
3. 데이터 전처리
- 이상치, 결측치 제거
- 결측치(missing value): 없는 값
- 데이터 분석에서 값이 비어있거나 알 수 없는 경우
- NA, null, NaN
- 결측치(missing value): 없는 값
- NA (Not Available)
- 주로 데이터가 누락되었거나 사용할 수 없을 때 사용
- R과 같은 통계 프로그래밍 언어에서 널리 사용
- NULL
- 값이 없음을 명확하게 나타냄
- 프로그래밍에서 변수가 어떤 객체도 가리키지 않거나, 데이터베이스에서 특정 필드에 값이 없는 경우 사용
- NaN (Not a Number)
- 숫자 연산 결과가 정의되지 않았을 때 사용
- 예를 들어 0으로 나누거나, 음수의 제곱근을 계산할 때 발생
- 입력변수 처리
- 특성공학 → 특성 추가, 삭제, 새로운 특성 생성 등
- 인코딩
- 문자열 데이터 → 수치형으로 처리
.info()- Not-Null Count
- 결측치 여부 확인 → 머신러닝 학습을 위해 결측치 반드시 제거 필요
- Dtype
- 데이터의 타입 확인 → 머신러닝 학습을 윟해 모두 수치형 데이터로 변경
- Not-Null Count

2 B R 0 2 B