목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. 회원 관리 구현
B. 2교시
1. 회원 관리 구현 (cont.)
C. 3교시
1. DB 연결 3가지 프로세스
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. RAG 평가 지표 알아보기
B. 5교시
1. RAGAS
2. RAG 평가용 데이터셋 비교
C. 6교시
1. Human-labeled
2. RAGAS Score 계산
Ⅲ. CAREER UP
오늘 학습한 내용 복습
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
- 라우터 역할
- 경로 관련 업무를 가져가서 처리
- app.js(서버 컴퓨터)가 가지고 있는 업무 중 경로 관련 처리만 뽑아가서 담당해주는 것
- 경로 관련 업무를 가져가서 처리
- 라우터 쪼개기 → 조건문을 주는 것과 유사!
- mainRouter: 경로 뒤에 특이사항 없을 때 (아무 조건 없을 때)
- esportsRouter: 그룹화된 특정 경로 처리 (
a href="/esports/lol")- 그룹화의 목적: 관리를 쉽고 편하게 하기 위해
- 보통 페이지 반환 라우터와 DB 연동 라우터 두 개로 쪼개는 걸 많이 함
- 무조건 쪼개기보다는 일단 만들고 관리하기 불편해 보이면 공통된 부분을 찾아 나누기
- 동일한 경로에 대해 두 가지 요청 처리도 가능함: get/post
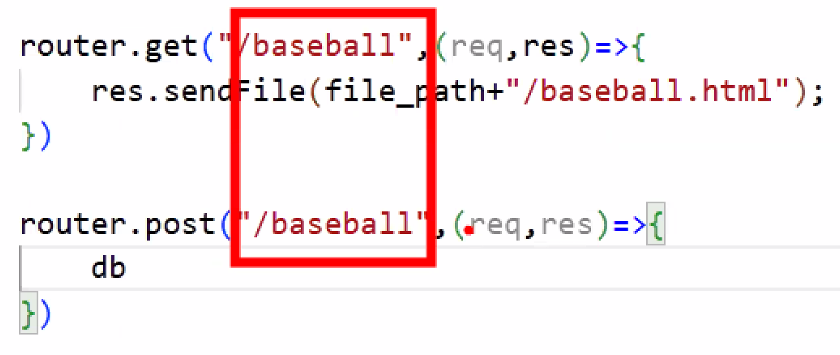
- 한 라우터에서 페이지 보여주기(get)와 DB와 소통하기(post) 모두 처리 가능 → 이건 사람마다 어떻게 처리하는지가 달라요~ (개발자 스타일 차이)
- 데이터베이스
- 아키텍처
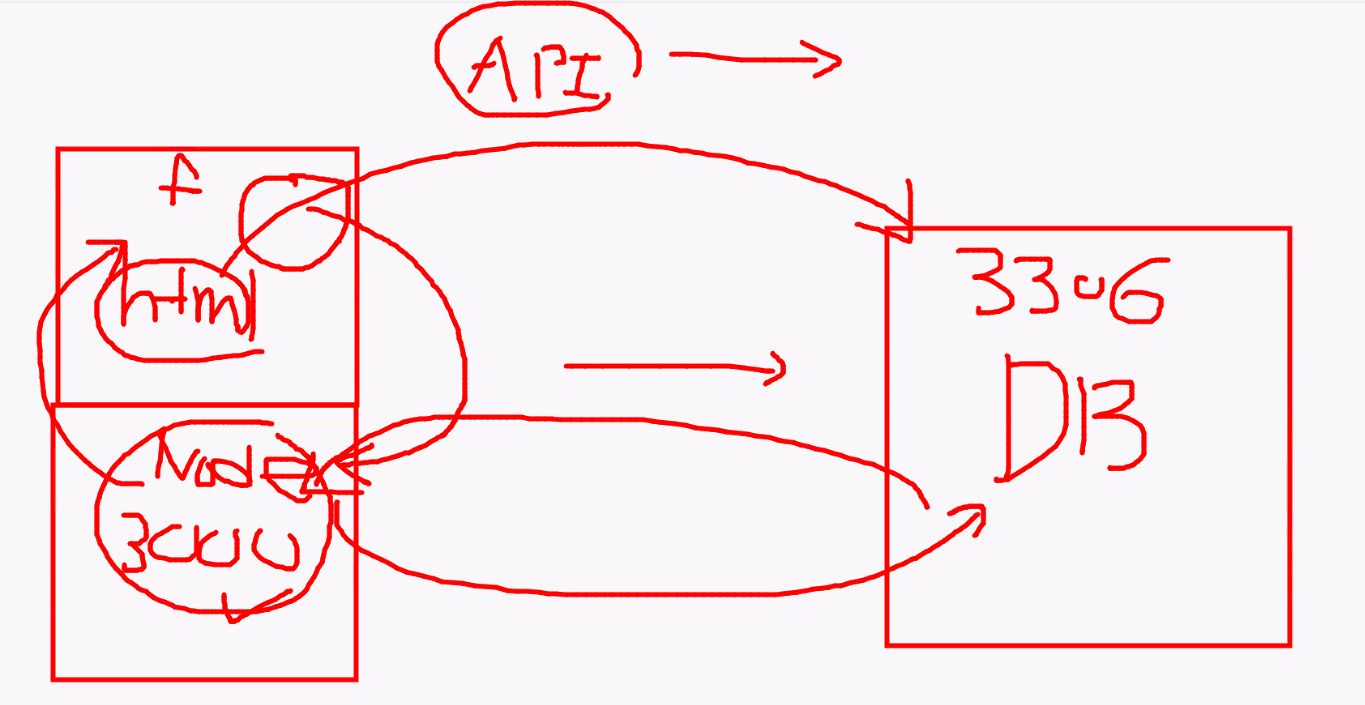
- 통신하려면 무조건 서버가 필요함
- 프론트엔드는 DB와 직접 소통 불가 (API 제외)
- 서버는 반드시 처리 결과를 frontend에 돌려줘야 함
- 예시: 게임 아이템 창고에 저장하기
- 쿼리문: select, insert, update, delete
- 아키텍처
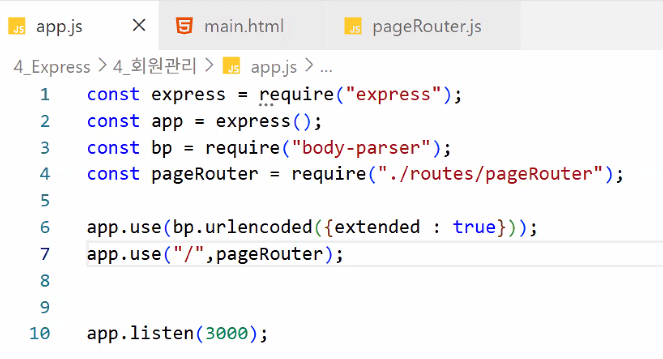
2. 회원 관리 구현
node 서버와 DB 서버 연결하기
- 프로젝트 진행할 폴더 만들기 (4_회원관리)
- express 설치
- public, routes, config 폴더 만들기
- 원래 웹 페이지는 views에 만드는데(동적 페이지) 지금은 public 사용
- DB 정보 관리할 거라 config 폴더 필요함
- app.js 생성
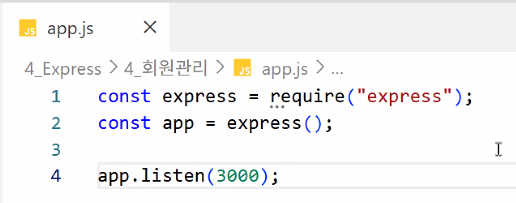
- 하나 더 설정할 수 있음: post 데이터 처리
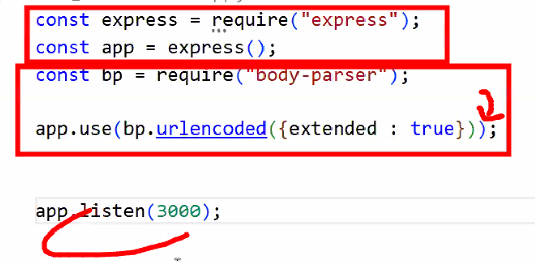
- 하나 더 설정할 수 있음: post 데이터 처리
- (frontend) public 폴더에 html 파일 만들기: main.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>회원 관리 시스템입니다!</h1>
<a href="">회원 가입 페이지</a>
</body>
</html>- routes 폴더에 js 파일 만들기: pageRouter.js
- 기본 설정
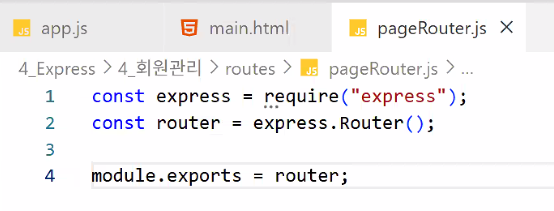
- router 만들고 바로 exports 먼저 설정해주기! (그래야 안 까먹음)
- path 모듈 추가하고 main.html 연결하기
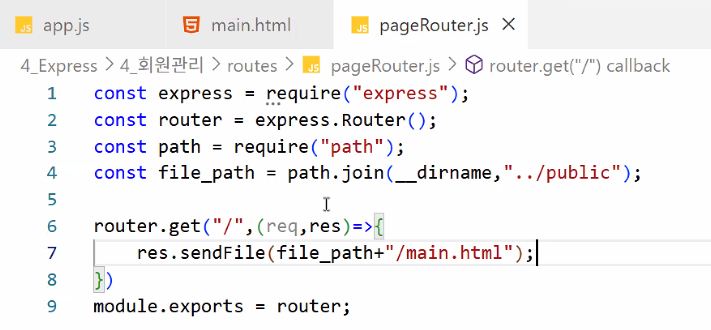
- 기본 설정
- app.js와 pageRouter.js 연결하기
B. 2교시
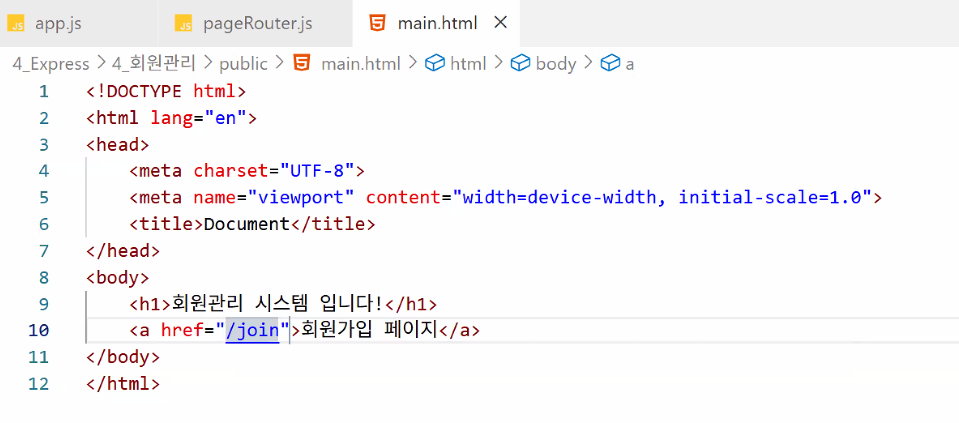
1. 회원 관리 구현 (cont.)
실제 회원 가입 페이지로 연결하기
- (frontend) main.html에서 회원 가입 경로 연결: /join
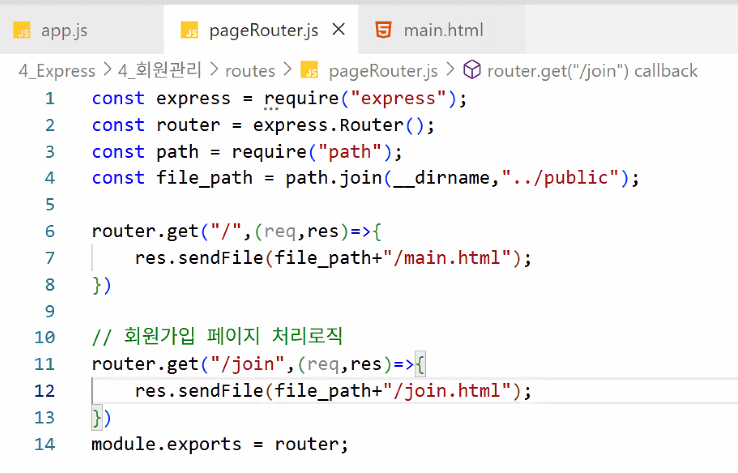
- pageRouter.js에 '/join' 업무 처리 추가 → 회원 가입 페이지 처리 로직 (회원 가입 메인 페이지 열기)
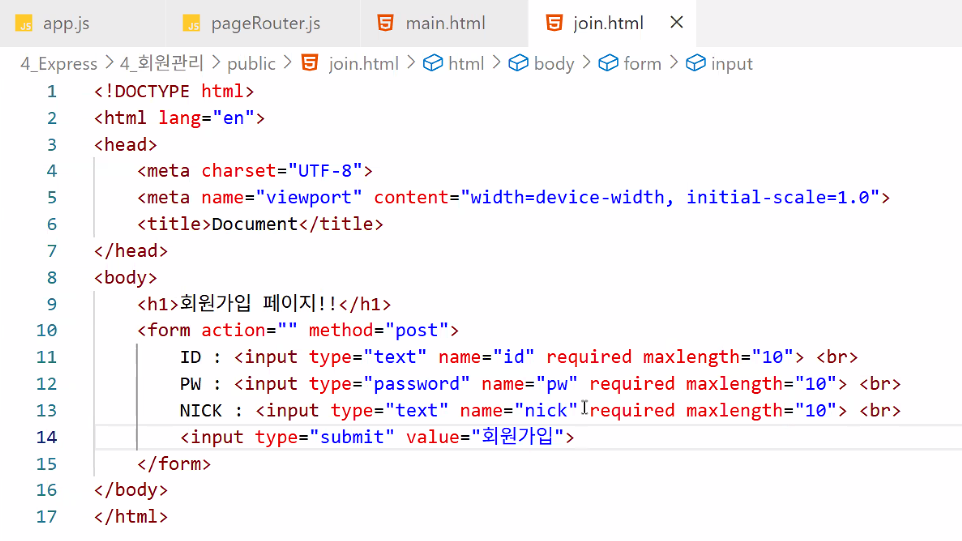
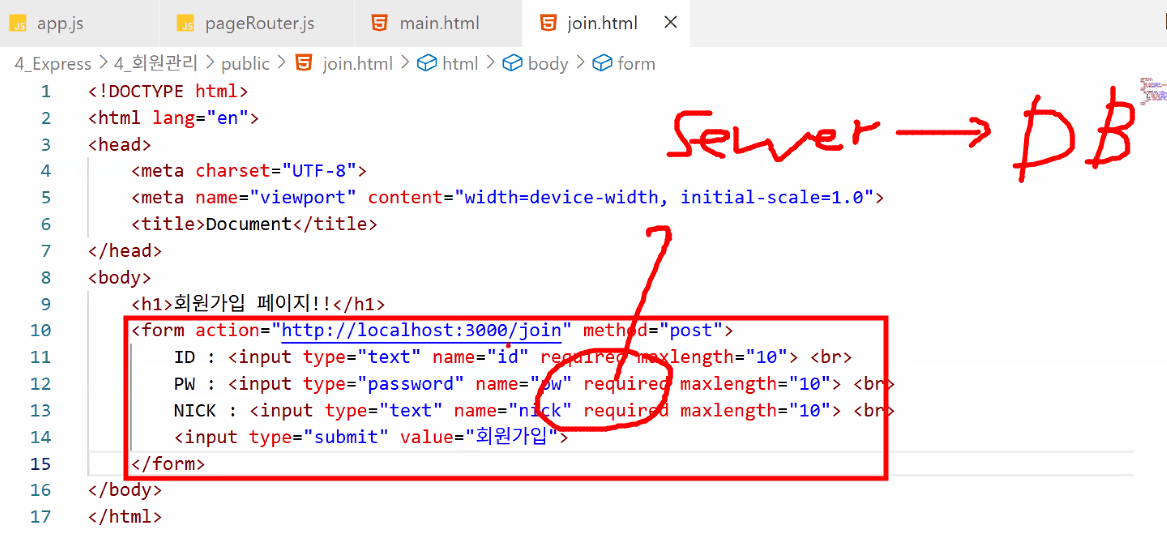
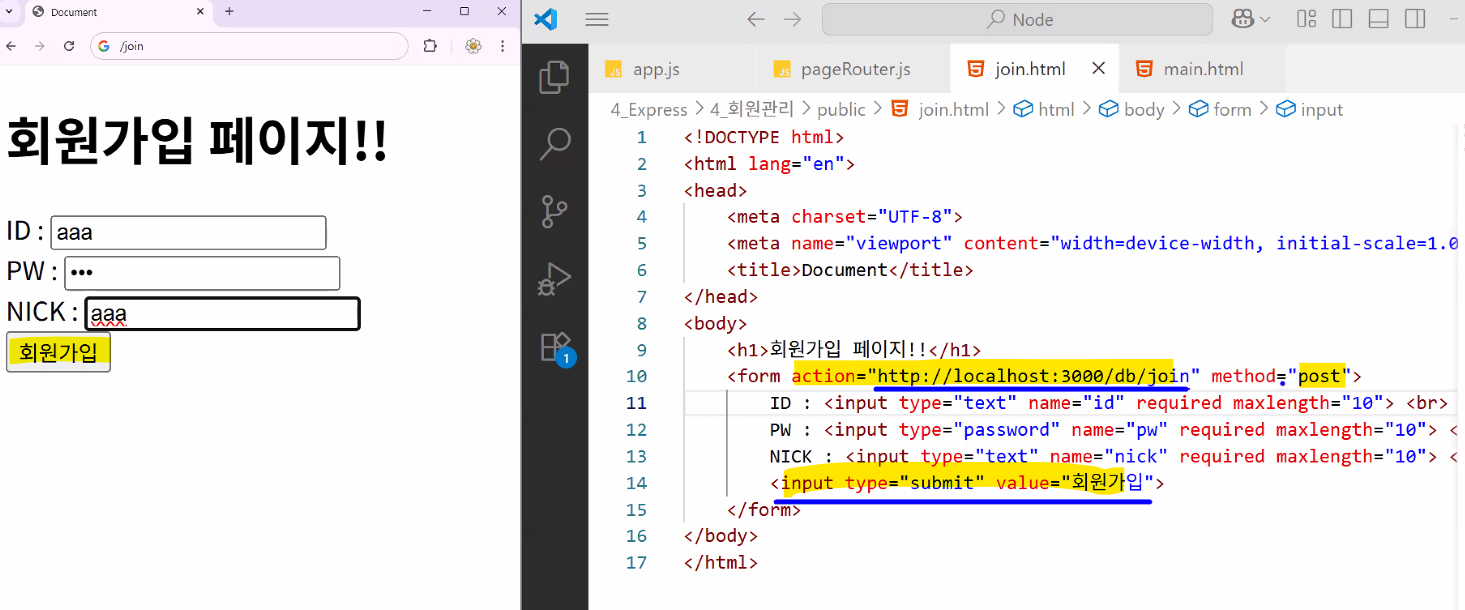
- (frontend) public 폴더에 join.html 만들기
- form 태그 사용: post 방식
action="http://localhost:3000/join"입력 → 오류 발생- 주의: 무한 루프 오류 아님! → 기존 '/join' 처리 방식은 get이고 여기서 보내는 통신은 post라 데이터 흐름이 연결되지 않고 끊어짐
- 같은 경로여도 처리 방식이 다름 → post 방식이라 기존 로직(get) 실행이 안 된다! → 그럼 어떻게 할까?
- 하나의 라우터에서 기능을 쪼개서 처리하는 것도 가능 → get/post가 다르기 때문에 경로가 중복돼도 처리 OK
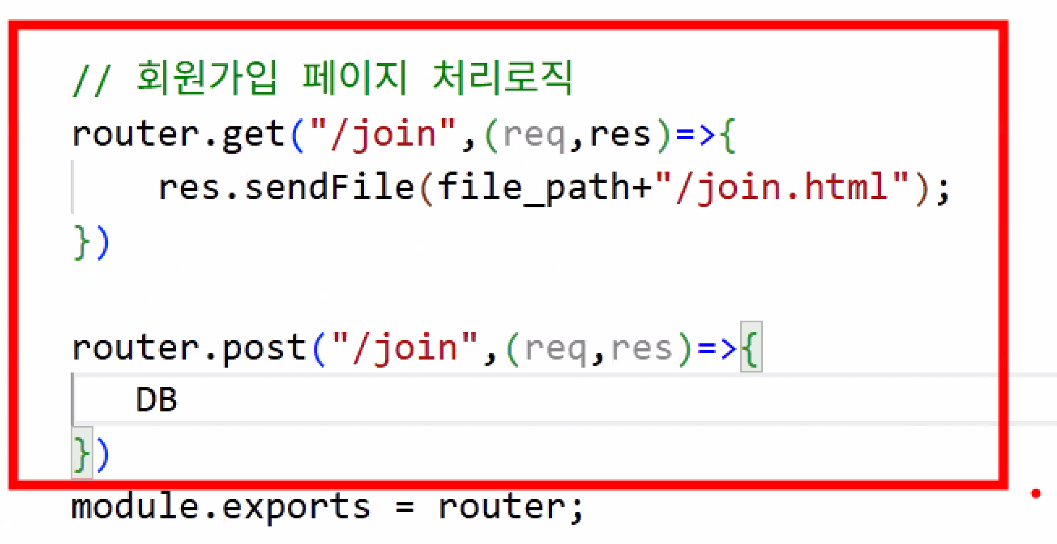
- BUT 이렇게 하면 관리가 어려움 → 쪼개서 사용하자: dbRouter 추가
- 하나의 라우터에서 기능을 쪼개서 처리하는 것도 가능 → get/post가 다르기 때문에 경로가 중복돼도 처리 OK
- 우리가 원하는 흐름
- 이렇게 하려면 경로를 약간 바꿔줘야 함:
action="http://localhost:3000/db/join"
- 이렇게 하려면 경로를 약간 바꿔줘야 함:
- form 태그 사용: post 방식
- (backend) routes 폴더에 새로운 라우터(dbRouter.js) 만들고 app.js와 연결
- dbRouter.js
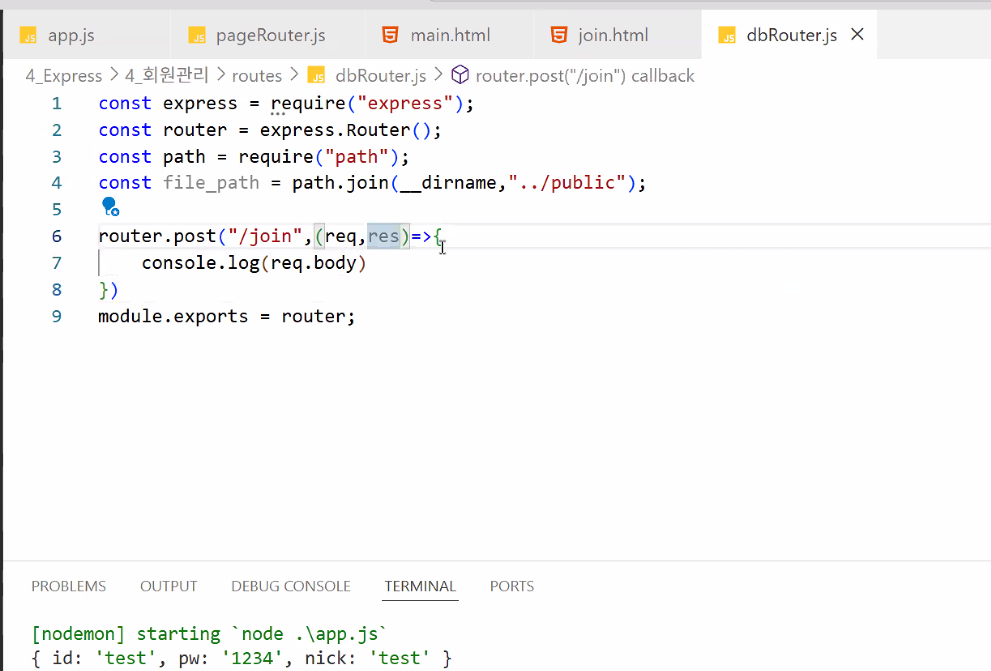
- app.js에 코드 두 줄 추가하고 실행하면 위 사진처럼 터미널에 로그 뜸
const dbRouter = require("./routes/dbRouter");app.use("/db",dbRouter);
- dbRouter.js
- DB 서버와 연결하기
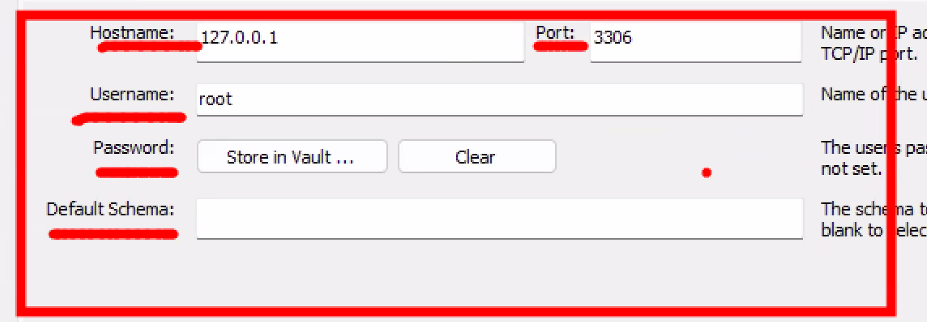
- 아래와 같은 연결 정보를 만들어야 함 → config 폴더 안에!
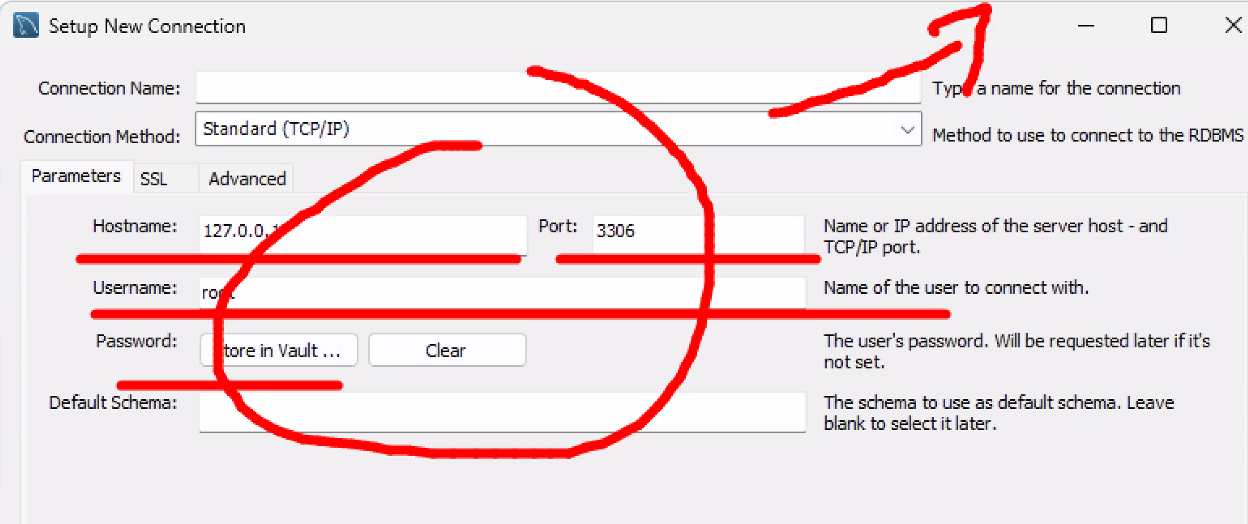
- 아래와 같은 연결 정보를 만들어야 함 → config 폴더 안에!
- config 폴더에 db.js 파일 만들기
- Express에서 DB로 연결하기 위한 연결 정보를 관리하는 파일
npm i mysql2설치
- 2버전부터 외부 통신이 가능
- db.js 파일 코드 작성
- 1) mysql2 모듈 불러오기
- Workbench 프로그램 연 것과 동일한 효과
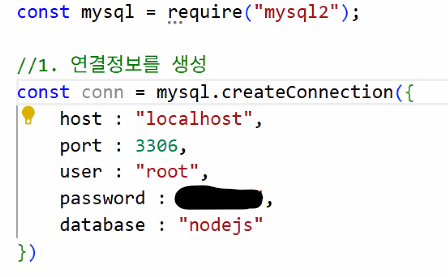
- 2) 연결 정보를 생성
- 입력해야 하는 정보
- object 형태로 동일한 내용 입력
- 입력해야 하는 정보
- 3) 생성한 연결 정보로 접속하게 만들기
conn.connect();
- 4) 다른 파일에서 사용하기 위해 exports 하기
module.exports = conn;
- 1) mysql2 모듈 불러오기
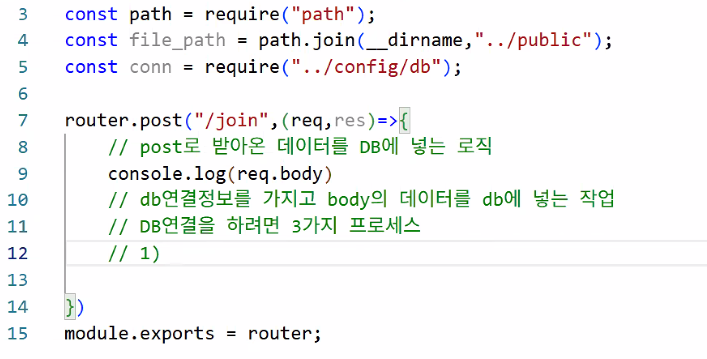
- dbRouter.js에 db.js 연결하기
C. 3교시
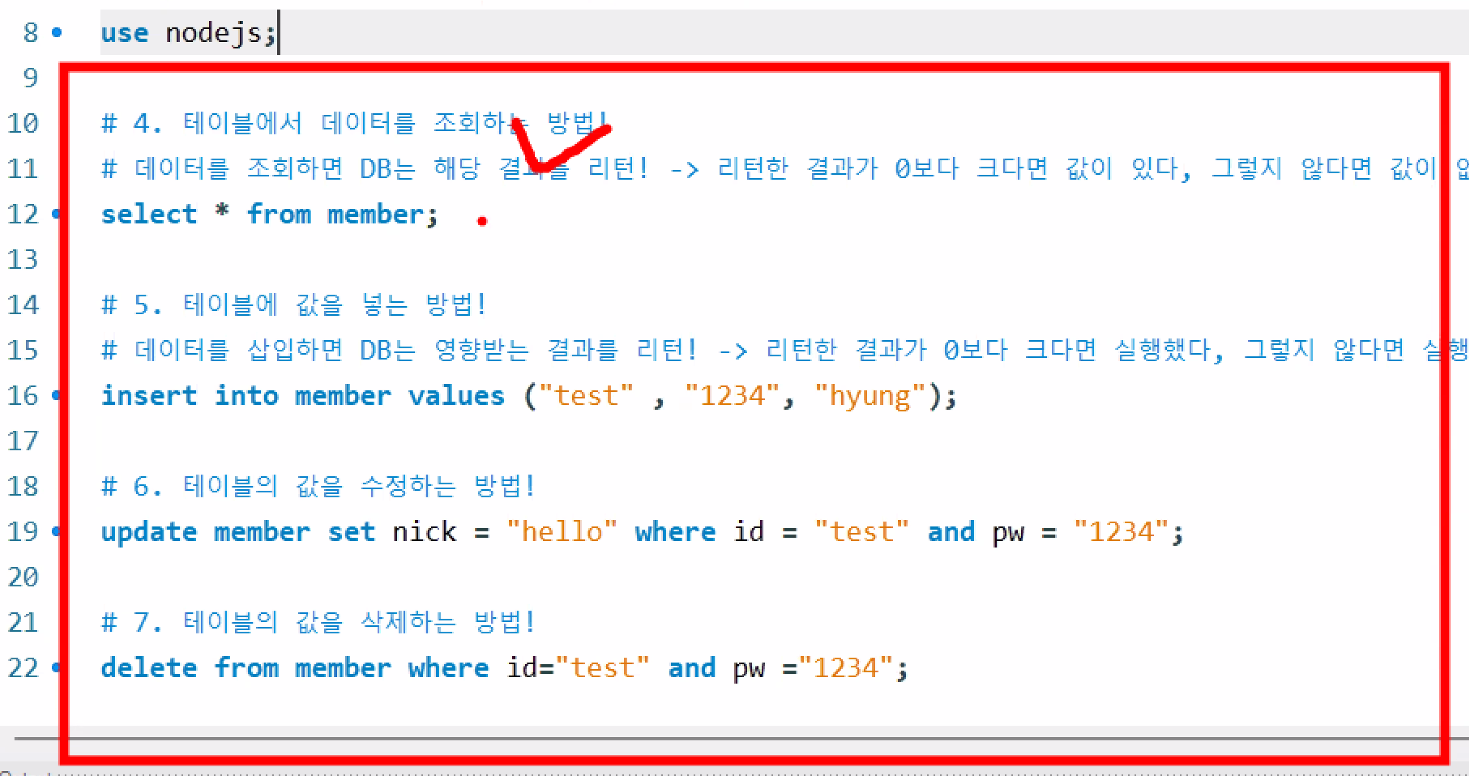
1. DB 연결 3가지 프로세스
- DB SQL문 작성
- 값이 필요한 경우 JS의 값 + SQL 합치기
- 연결 정보를 가지고 SQL문 실행
- 과거에 사용하던 방식
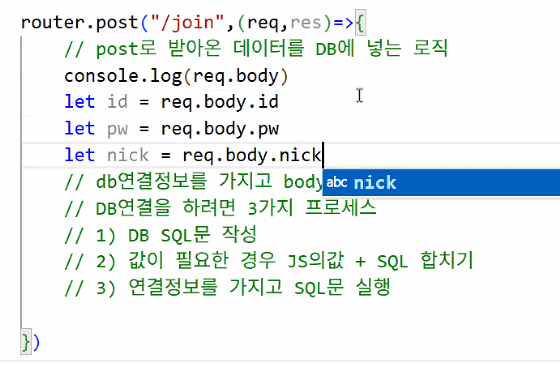
- 똑같은 이름에 똑같은 키를 가져다 쓸 건데(id-id) 매번 똑같은 변수 세 줄씩 만들어야 해서 귀찮음 → 한 번에 쉽게 받아오고 싶어요 → EC6에서 새로운 문법이 등장: 객체 비구조화 할당(destructuring assignment)
- 배열이나 객체의 속성 혹은 값을 해체하여 그 값을 변수에 각각 담아 사용하는 자바스크립트 표현식
let {id,pw,nick} = req.body;: 이름과 순서가 일치해야 함- 배열 스프레드 표기법(전개 구문)도 있음 → 스프레드 연산자(Spread Operator)
- 똑같은 이름에 똑같은 키를 가져다 쓸 건데(id-id) 매번 똑같은 변수 세 줄씩 만들어야 해서 귀찮음 → 한 번에 쉽게 받아오고 싶어요 → EC6에서 새로운 문법이 등장: 객체 비구조화 할당(destructuring assignment)
Destructuring assignment
객체 비구조화 할당(=구조 분해 할당)은 객체의 속성 값을 해체하여 원하는 변수에 할당하는 JavaScript 문법으로, 객체 리터럴 안에 {} 중괄호를 사용하고, 변수 이름은 객체의 속성 이름과 같게 작성하면 됩니다. 예를 들어, { name, age } = user와 같이 작성하여 객체 user의 name과 age 속성을 각각 name과 age 변수에 할당할 수 있습니다.
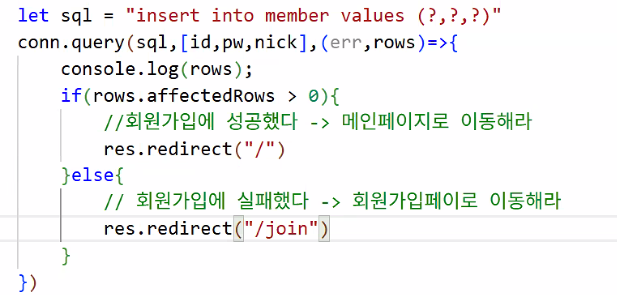
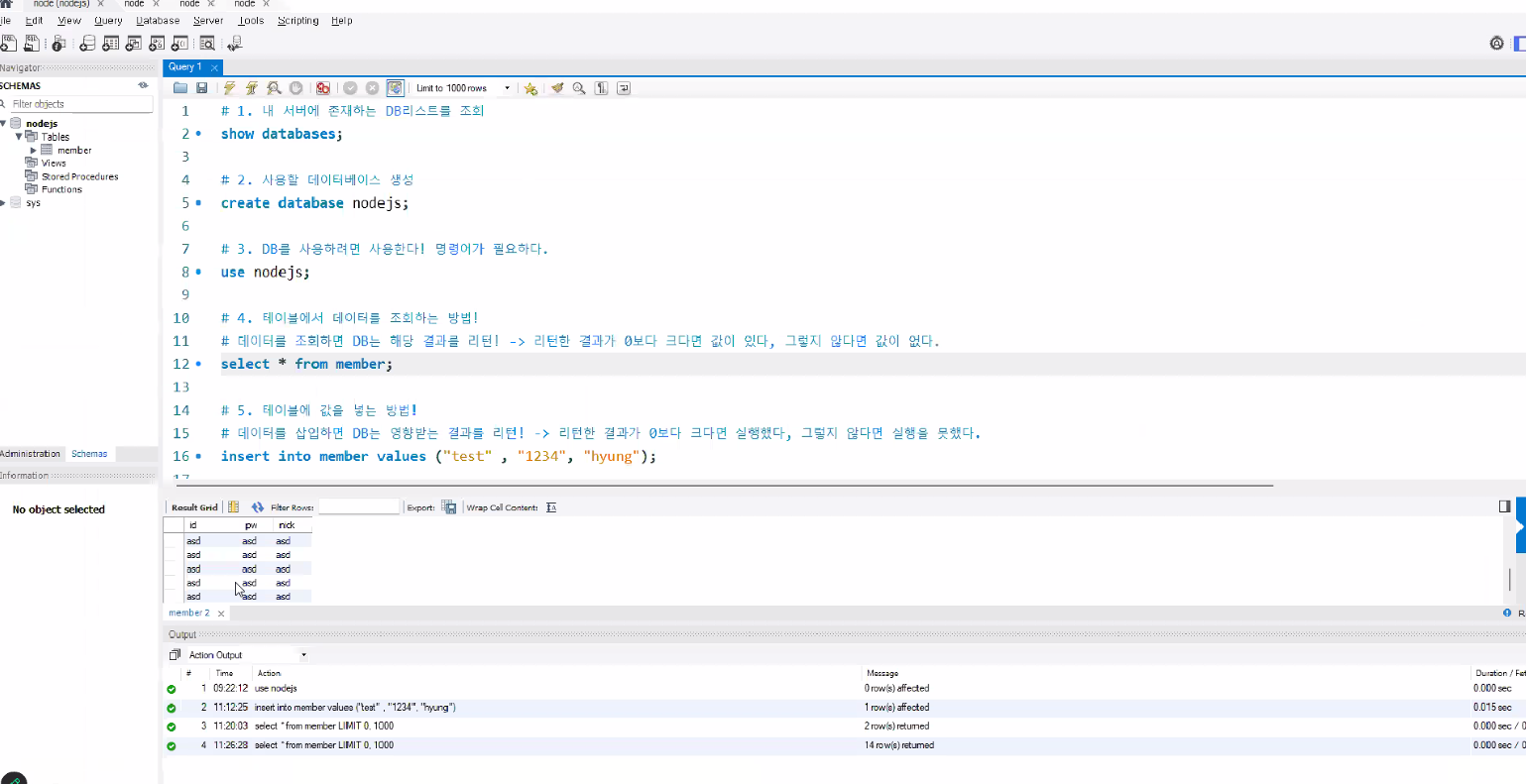
DB SQL문 작성
let sql = "insert into member values (?,?,?);";?의 의미: 아직 어떤 값을 넣을지 모른다는 의미
JS의 값 + SQL 합치기
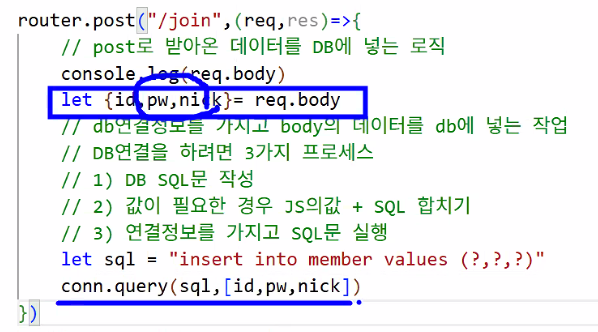
conn.query(sql,[id,pw,nick],);: sql 변수에 있는 쿼리문 쓸 건데 물음표에[]안의 변수를 넣어달라는 뜻- 반드시 순서에 맞게 넣어줘야 함!
연결 정보를 가지고 SQL문 실행 → 성공/실패 처리
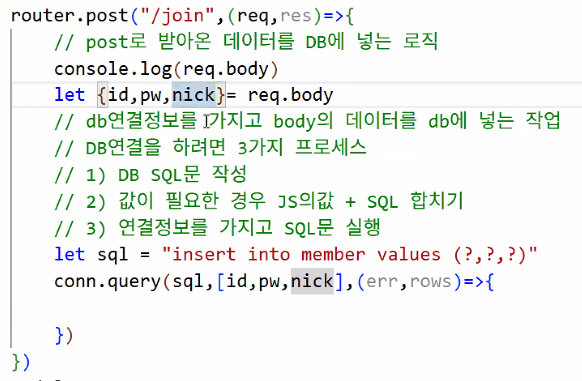
- err: 오류 발생 시, rows: 잘 처리되었을 때
- return을 DB에서 rows라 부르는 이유
- MySQL 콘솔창 message 보면 '1 row(s) affected'와 같이 어떤 줄이 영향을 받았다고 표출되기 때문
- return을 DB에서 rows라 부르는 이유
- rows가 잘 넘어오는지 결과 확인해보기
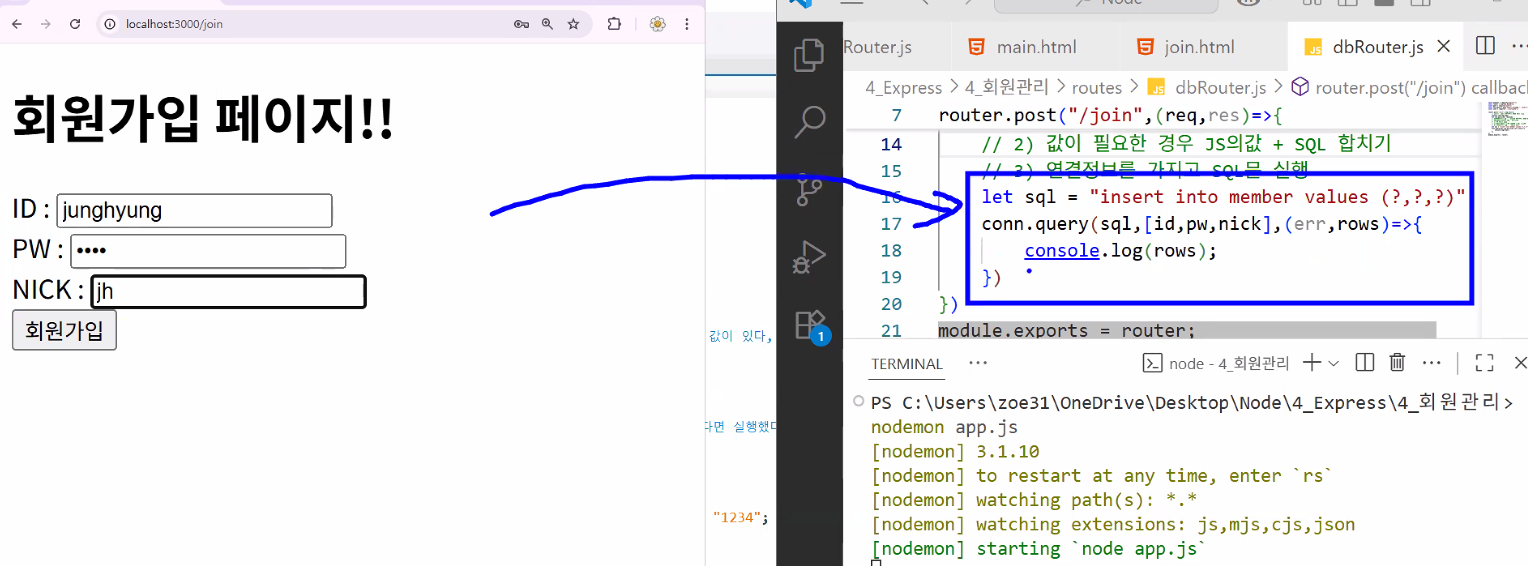
- terminal에 응답에 대한 결과 표출
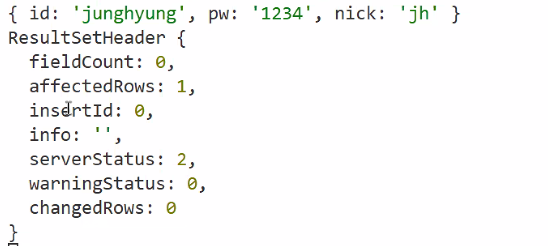
- terminal에 응답에 대한 결과 표출
- Workbench로 가서 결과 확인해보기
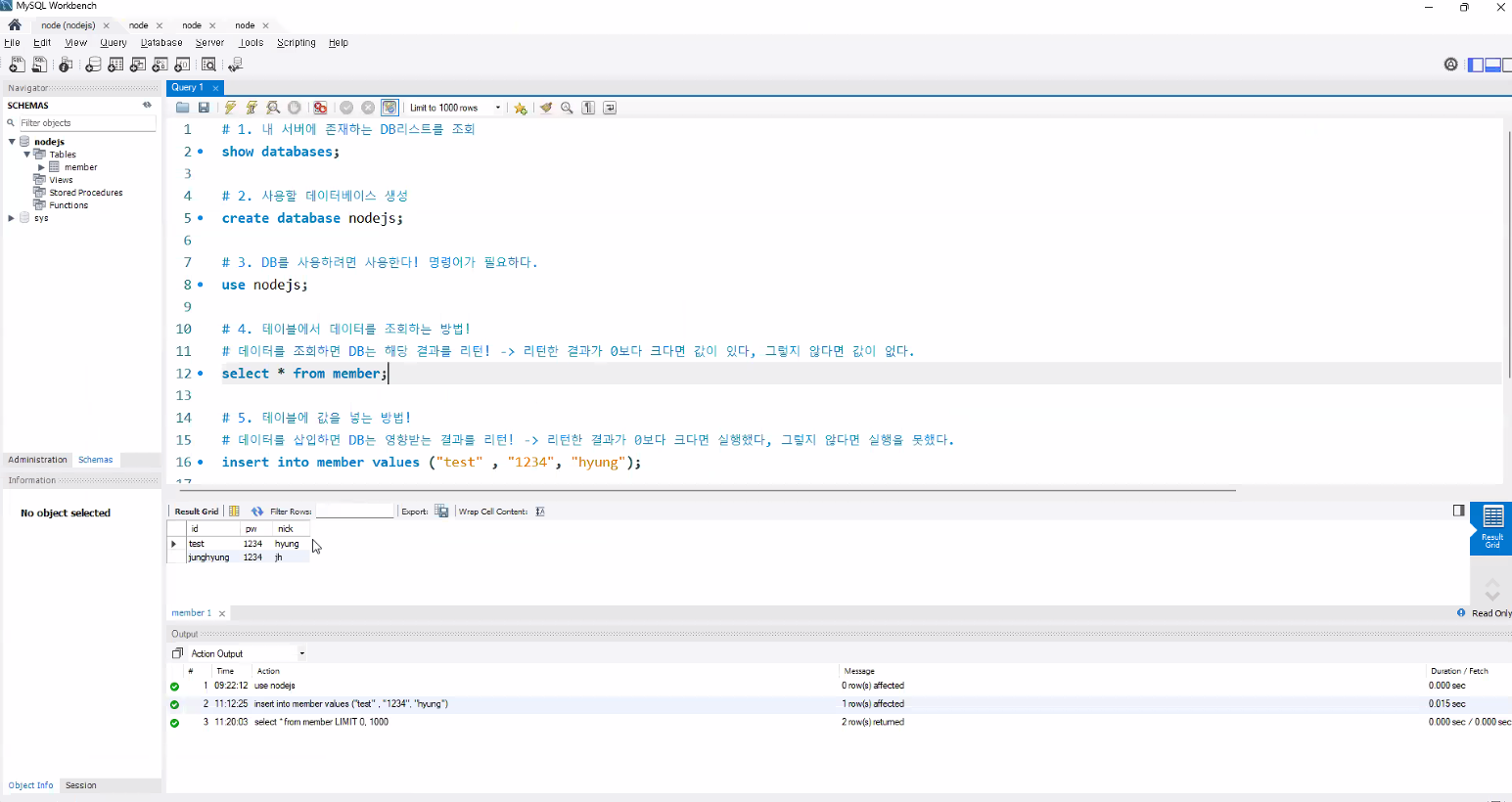
- 주의: 실제 통신은 암호화 과정이 포함되어 훨씬 복잡함!
- 우리가 한 건 원리 파악을 위한 가장 간단한 방식임
- 주의: 실제 통신은 암호화 과정이 포함되어 훨씬 복잡함!
- 사용자 페이지 무한 로딩 이유
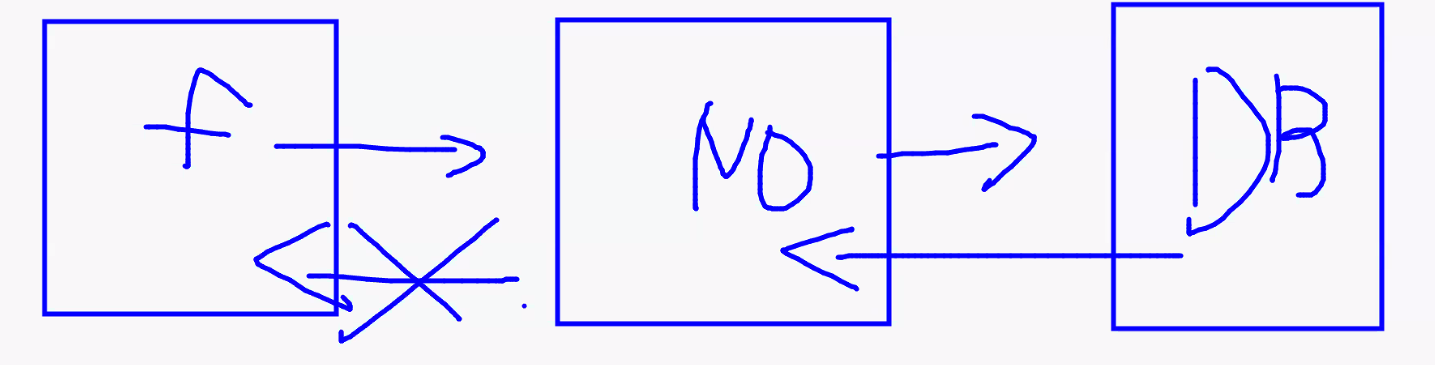
- node 서버에서 front로 응답 결과를 안 보내줬음 → redirect 사용하기!
- node 서버에서 front로 응답 결과를 안 보내줬음 → redirect 사용하기!
sendFile() 쓰면 안 되는 이유
sendFile() 쓰면 경로는 안 바뀌었는데 화면은 바뀜
문제점: 새로고침 10번 하면 10번 가입됨 → 쿼리문에 영향을 주기 때문
- 전체 프로세스 정리
- 사용자가
http://localhost:3000메인 입장- app.js 동작
- 경로에
/db있어요? → 없어요 → pageRouter.js 실행
- 경로에
- pageRouter.js 동작
:3000뒤에 뭐 있어요? → 없어요 → main.html 리턴
- app.js 동작
- 사용자가 '회원 가입 페이지'를 누름 → 새로운 페이지 요청
- app.js
- 경로에
/db있어요? → 없어요 → pageRouter.js 실행
- 경로에
- pageRouter.js
:3000뒤에 뭐 있어요? →/join있어요 → join.html 리턴
- app.js
- 사용자가 정보를 모두 입력하고 input '회원 가입' 누름 →
http://localhost:3000/db/join에 post 방식으로 값 전송
- app.js
- 경로에
/db있어요? → 네 → dbRouter.js 실행
- 경로에
- dbRouter.js
/db뒤에 뭐 있어요? → post로/join왔어요 → 로직 실행- sql문 만들어놓고 conn 호출 → db.js 실행
- db.js
- 작성된 연결 정보 가지고 db 연결 실행
- 연결 성공 → dbRouter.js에서 일할 준비 완료
- dbRouter.js
conn.query: db랑 연결되었으면 쿼리문 돌리자 → sql 변수에 들어 있는 쿼리문!(insert)- ? 값을 모르는데요 → 배열로 데이터 전송(객체 비구조화 할당으로 만든 데이터) → 내가 전달한 데이터로 쿼리문 실행 → rows로 성공 여부 받음
- rows 값에 따른 조건문: redirect → redirect 실행되면 app.js 동작
- app.js
- 총 3개의 통신이 완성되었다~
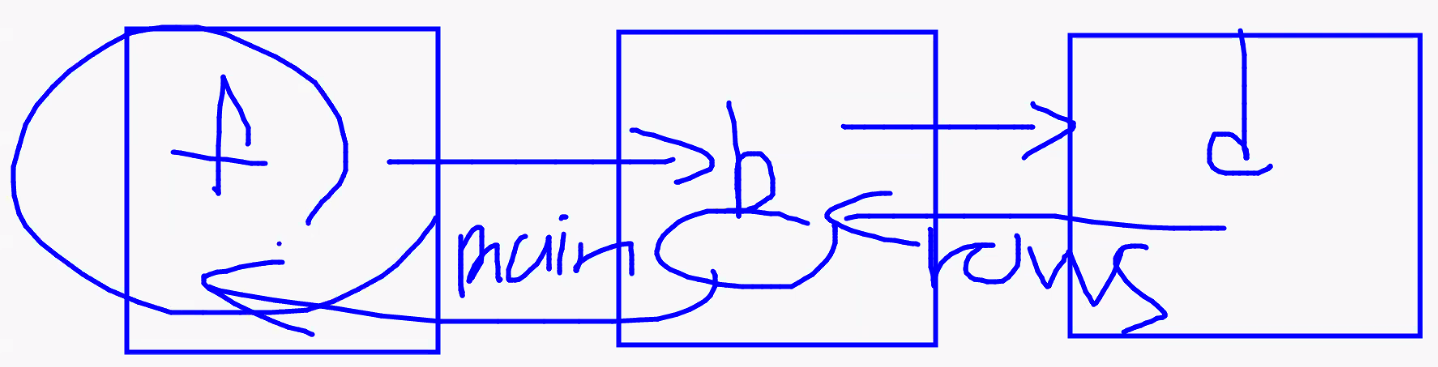
- 사용자가
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- LLM 평가: 인공지능 언어모델의 성능, 정확성, 일관성 등 중요한 측면을 측정하고 분석하는 과정
- 자동화된 메트릭
- BLEU
- ROUGE
- METEOR
- SemScore
- 인간 평가
- LLM-as-Judge
- 자동화된 메트릭
| 지표 | 특징 | 장점 | 단점 | 점수 범위 | 해석 | 좋은 점수 기준 | 주의사항 |
|---|---|---|---|---|---|---|---|
| BLEU | 기계 번역 평가용, n-그램 일치율 기반 | 계산 간단, 전통적으로 많이 사용 | 의미 같아도 표현 다르면 낮음 | 0 ~ 1 | 참조와 단어 수준 유사도 | ≥ 0.5: 꽤 유사, ≥ 0.7: 매우 유사 | 어휘 다양성 높은 경우 과소평가 가능 |
| ROUGE | 요약 평가에 특화, n-그램/구절/최장 공통 부분 수열 | 요약 핵심어 커버 잘 측정 | 단어 겹침 위주, 의미는 반영 약함 | 0 ~ 1 | 참조 요약과 단어·구절 겹침 정도 | ≥ 0.5: 주요 내용 커버, ≥ 0.7: 매우 좋음 | 의미 다르더라도 단어 겹치면 점수 높을 수 있음 |
| METEOR | BLEU 보완, 동의어·어간·형태 고려 | 인간 평가와 상관도 높음 | 계산 복잡, 언어 자원 필요 | 0 ~ 1 | 참조와 어휘적·의미적 유사도 | ≥ 0.6~0.7: 꽤 좋은 결과 | 지원 언어 한정, 속도 느릴 수 있음 |
| SemScore | 임베딩 기반 의미 유사도 | 표현 달라도 의미 같으면 높음 | 임베딩 모델 품질에 의존 | -1 ~ 1 (보통 0~1) | 의미적 유사도 (코사인 유사도) | ≥ 0.7: 유사, ≥ 0.85: 거의 동일 | 모델 성능·도메인에 따라 점수 신뢰도 달라짐 |
→ 여러 평가 지표를 확인해서 적당한 걸 선택하는 게 중요
점수가 낮게 나왔다면 낮게 나온 이유를 분석하기!
- ROUGE Score
- n-gram 중첩 기반
- rouge1, rouge2, rougeL
- 단어 겹침 위주라 의미가 달라도 점수가 높을 수 있음
- e.g., 하늘에서 내리는 '눈', 얼굴에 있는 '눈'
- BLEU
- n-gram 정밀도 기반
- 의미가 같아도 표현 방식이 다르면 낮게 나올 수 있음
- 예: “자동차” vs “승용차”
- METEOR
- BLEU와 유사하지만, 동의어·어간·형태변화까지 고려
- 계산이 느리고 언어 자원(단어사전 등)에 의존
- SemScore
- 의미적 유사도 기반
METEOR에서 사용한 wordnet에 문제가 있다는 제보가 들어왔음:
wordnet이 영어만 지원된다고 함 → 한국어 워드넷 받아서 쓰는 법 알아오기!
wordnet이란?
Wordnet with NLTK
자연어 처리 - Word Embedding(WordNet)
NLTK에서 WordNet의 다국어 확장인 omw-1.4 (Open Multilingual Wordnet) 리소스를 별도로 다운로드 (nltk.download('omw-1.4'))해 다른 언어의 레마(lemma)를 조회해 보았는데 한국어는 없음😭

추가: Wordnet 관련
한국어에 대해 NLTK WordNet은 공식적으로 지원하지 않습니다. WordNet은 주로 영어 어휘에 대해 동의어, 어간(stemming), 형태 변화를 처리하기 위한 자원으로 설계되었고, NLTK에 포함된 WordNet도 영어에 최적화되어 있습니다. 따라서 NLTK WordNet의 동의어 사전이나 어간 매칭 기능은 한국어에 적용되지 않습니다.
METEOR 평가지표 자체는 동의어, 어간 추출, 그리고 형태 변화를 반영하는 장점이 있지만, 그 기반이 되는 WordNet 등의 언어자원이 지원하는 언어에 한정됩니다. 한국어의 경우 공식적인 WordNet 지원이 없기 때문에, NLTK의 meteor_score 함수가 WordNet을 사용해 동의어, 어간, 형태 변화 매칭을 수행하지 않고 단순 토큰 매칭 위주로 평가가 진행될 가능성이 높습니다.
meteor_score 함수 내 자동 WordNet 활용은 영어 텍스트에는 동작하지만, 한국어 텍스트에서는 동의어·어간·형태소 변화를 고려하지 않고 단순 토큰 매칭만으로 평가가 이루어집니다. 한국어에 특화된 언어자원이나 형태소 분석기를 이용하거나, 한국어 WordNet(다수 비공식/개별 프로젝트 존재)을 연동해야 METEOR와 유사한 의미 기반 평가가 가능해집니다.
요약하면:
① NLTK WordNet은 영어 중심이며 한국어 지원이 없습니다.
② NLTK meteor_score 함수는 WordNet에 기반하여 동의어/어간 매칭을 수행하나, 한국어에서는 이를 활용할 수 없습니다.
③ 따라서 한국어 문장에 대해선 동의어, 어간, 형태 변화 고려 없이 단순 토큰 매칭으로 METEOR 점수가 계산됩니다.
④ 한국어 평가를 위해선 한국어 형태소 분석기 또는 별도 한국어 WordNet 자원이 필요합니다.
한국어 WordNet 자원을 별도로 사용하려면, 국내에서 개발된 한국어 WordNet 프로젝트(예: KAIST 오픈 한국어 워드넷(KWN))나 비슷한 형태의 한국어 유의어/동의어 사전을 활용해야 합니다. NLTK 기본 WordNet은 영어 전용이므로, 이와 별개로 아래와 같은 절차가 필요합니다.
- 한국어 WordNet 자원 연동 방법 개요
- 한국어 WordNet 데이터 확보
- KAIST 오픈 한국어 워드넷(KWN) 프로젝트(https://koasas.kaist.ac.kr 등)에서 데이터셋을 내려받거나 API를 연동.
- 또는 공개된 한국어 유의어/동의어 사전 파일 활용.
- 데이터 파싱 및 연동 라이브러리 준비
- JSON, XML, CSV 등 형태로 된 WordNet 데이터를 파이썬에서 파싱.
- 필요시 한국어 형태소 분석기(KoNLPy, Kkma, Komoran, Kiwi 등)를 사용해 토큰화, 어간 추출.
- 자주 쓰이는 것은 데이터 구조를 클래스/함수로 Wrapping해서 동의어 집합 추출 함수 등 개발.
- METEOR 함수 내 동의어 매칭 모듈 교체 또는 확장
- 표준
meteor_score함수는 영어 WordNet에 묶여 있으므로, 한국어 동의어 검사 로직을 별도로 구현해 평가 코드에 통합.- 예를 들어, 토큰별로 한국어 WordNet 기반 동의어 목록을 조회해 매칭 점수를 조정.
- 예시 코드 구성
- 한국어 문장을 형태소 단위로 토큰화 후, 각 토큰의 동의어를 한국어 WordNet에서 조회.
- 기존 meteor_score 내부에서 영어 WordNet을 참조하는 부분을 대체 또는 병행 적용.
- 참고할만한 라이브러리 및 도구
- KAIST Open Korean WordNet (KWN)
- KoNLPy: 한국어 형태소 분석기 (예: Komoran, Kkma, Hannanum, Kiwi)
- Soynlp: 한국어 문장 분리 및 단어 추출 도구
- 직접 구축한 유의어 사전 또는 DB와 연동
- 이 방식으로 METEOR 평가 시 동의어 매칭을 실제 한국어 WordNet 데이터 기반으로 확장할 수 있습니다. 다만 구현 난이도가 있으므로, 완전한 동의어 기반 METEOR 지원은 추가 개발이 필요하며 기존 python-nltk meteor_score 함수 대신 커스텀 구현이나 확장 패키지를 고려하는 것이 좋습니다.
2. RAG 평가 지표 알아보기
- 평가를 진행하기 위하여 RAG 기능 구현
- PDF 문서를 읽어 검색하는 모듈 정의
import os
with open('./key/.openai_api_key','r') as f:
api_key = f.read().strip()
# 환경변수 설정 (딕셔너리형태)
os.environ['OPENAI_API_KEY'] = api_key
import os
if not os.path.exists("./module"):
os.mkdir("./module")
%%writefile module/PDFRAG.py
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.prompts.chat import ChatPromptTemplate
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
def load_pdf(file_path):
""" PDF 파일 로드 및 텍스트 분할"""
loader = PyPDFLoader(file_path)
return loader.load()
def text_split(doc) :
""" 텍스트 분할 """
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50,
length_function = len)
texts = text_splitter.split_documents(doc)
return texts
def create_retriever(texts, file_name, num) :
""" 벡터 DB 저장하고 검색기 설정 """
vec_db = FAISS.from_documents(documents=texts, embedding=OpenAIEmbeddings())
vec_db.save_local("./db/" + file_name) # 만든 FAISS 벡터 DB를 ./db/faiss02 같은 폴더에 저장.
# 매번 PDF를 읽고 임베딩을 새로 만들면 시간·비용 낭비 → 한 번 만들어 저장해두면 다음에 바로 로드 가능.
# 방금 저장한 벡터 DB를 다시 불러옴
vec_db2 = FAISS.load_local("./db/" + file_name, OpenAIEmbeddings(),
allow_dangerous_deserialization=True)
#FAISS DB를 retriever(검색기) 객체로 변환.
retriever = vec_db2.as_retriever(search_kwargs={"k": num})
return retriever
def create_chain(retriever) :
""" 대화형 프롬프트 템플릿 설정 """
prompt = ChatPromptTemplate.from_messages([
('system', "{summaries}"),
("user", "{question}")
])
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever = retriever,
return_source_documents=False,
chain_type_kwargs={"prompt": prompt}
)
return chainWriting module/PDFRAG.py- 지난 시간 RAG 실습과 달라진 부분: 벡터 DB를 드라이브에 저장
- 생성한 FAISS 벡터 DB를 저장하는 로직을 추가했음
- 이유: 매번 PDF를 읽고 임베딩을 새로 만들면 시간·비용 낭비 → 한 번 만들어 저장해두면 다음에 바로 로드 가능
- 사용할 자료
- SPRiAI_Brief_8월호산업동향.pdf
- 자료 성격
- 발행 기관: 소프트웨어정책연구소(SPRI)
- 형태: 월간 브리프(월호)
- 주제: AI 산업 동향, 정책·법제 변화, 글로벌 기업 전략, 최신 연구 결과, 인력·교육 이슈 등
- 목적: 정책 담당자, 연구자, 기업 관계자들이 최근 AI 산업 트렌드와 규제/기술 동향을 한눈에 파악하도록 정리한 보고서
# 위에서 생성한 모듈 불러와 사용하기
from module.PDFRAG import load_pdf, text_split, create_retriever, create_chain
# 파일 읽기
documents = load_pdf("./data/SPRi_AI_Brief_8월호_산업동향.pdf")
# 표지, 차례, 간지 삭제
documents = documents[3:]
# 텍스트 분리
texts = text_split(documents)
# 벡터 DB 저장하고 검색기 설정
retriever = create_retriever(texts, "faiss_db_01", 2)
# 대화형 프롬프트 템플릿 설정
chain = create_chain(retriever)
# 체인 실행
result = chain.invoke("AI가 일자리를 줄이는 대신 창출하는 영역은?")
print(result){'question': 'AI가 일자리를 줄이는 대신 창출하는 영역은?', 'answer': 'AI는 여러 분야에서 새로운 일자리를 창출할 수 있는 잠재력을 가지고 있습니다. 다음은 AI가 일자리를 창출할 수 있는 몇 가지 영역입니다:\n\n1. **AI 개발 및 연구**: AI 시스템을 개발하고 개선하기 위한 연구자, 엔지니어, 데이터 과학자 등의 수요가 증가하고 있습니다.\n\n2. **데이터 분석 및 관리**: AI 시스템이 작동하기 위해서는 대량의 데이터가 필요하며, 이를 수집, 정리, 분석하는 데이터 전문가의 역할이 중요해지고 있습니다.\n\n3. **AI 유지보수 및 운영**: AI 시스템의 유지보수, 운영, 모니터링을 담당하는 직무가 필요합니다.\n\n4. **교육 및 훈련**: AI 기술을 이해하고 활용할 수 있도록 교육하고 훈련하는 직무가 증가하고 있습니다.\n\n5. **AI 윤리 및 규제**: AI의 윤리적 사용과 관련된 정책 개발 및 규제 업무를 담당하는 직무가 필요합니다.\n\n6. **고객 지원 및 서비스**: AI 기반 제품 및 서비스를 사용하는 고객을 지원하는 역할이 중요해지고 있습니다.\n\n이러한 영역들은 AI 기술의 발전과 함께 지속적으로 성장할 것으로 예상됩니다.', 'sources': ''}print(result["answer"])AI는 여러 분야에서 새로운 일자리를 창출할 수 있는 잠재력을 가지고 있습니다. 다음은 AI가 일자리를 창출할 수 있는 몇 가지 영역입니다:
1. **AI 개발 및 연구**: AI 시스템을 개발하고 개선하기 위한 연구자, 엔지니어, 데이터 과학자 등의 수요가 증가하고 있습니다.
2. **데이터 분석 및 관리**: AI 시스템이 작동하기 위해서는 대량의 데이터가 필요하며, 이를 수집, 정리, 분석하는 데이터 전문가의 역할이 중요해지고 있습니다.
3. **AI 유지보수 및 운영**: AI 시스템의 유지보수, 운영, 모니터링을 담당하는 직무가 필요합니다.
4. **교육 및 훈련**: AI 기술을 이해하고 활용할 수 있도록 교육하고 훈련하는 직무가 증가하고 있습니다.
5. **AI 윤리 및 규제**: AI의 윤리적 사용과 관련된 정책 개발 및 규제 업무를 담당하는 직무가 필요합니다.
6. **고객 지원 및 서비스**: AI 기반 제품 및 서비스를 사용하는 고객을 지원하는 역할이 중요해지고 있습니다.
이러한 영역들은 AI 기술의 발전과 함께 지속적으로 성장할 것으로 예상됩니다.# 질문에 대한 답변을 생성하는 함수 생성
def ask_question (input:dict):
return {"answer": chain.invoke(input["question"])}
# 입력값은 딕셔너리 형태로 입력받음
ask_question({"question": "AI가 일자리를 줄이는 대신 창출하는 영역은?"}){'answer': {'question': 'AI가 일자리를 줄이는 대신 창출하는 영역은?',
'answer': 'AI는 여러 분야에서 새로운 일자리를 창출할 수 있는 잠재력을 가지고 있습니다. 다음은 AI가 일자리를 창출할 수 있는 몇 가지 영역입니다:\n\n1. **AI 개발 및 연구**: AI 시스템을 개발하고 개선하기 위한 연구자, 엔지니어, 데이터 과학자 등의 수요가 증가하고 있습니다.\n\n2. **데이터 분석 및 관리**: AI 시스템이 작동하기 위해서는 대량의 데이터가 필요하며, 이를 수집, 정리, 분석하는 데이터 전문가의 역할이 중요해지고 있습니다.\n\n3. **AI 유지보수 및 운영**: AI 시스템의 유지보수, 운영, 모니터링을 담당하는 직무가 필요합니다.\n\n4. **AI 교육 및 훈련**: AI 기술을 이해하고 활용할 수 있도록 교육하는 역할이 중요해지면서 관련 교육자와 트레이너의 수요가 증가하고 있습니다.\n\n5. **윤리 및 규제 준수**: AI의 윤리적 사용과 규제 준수를 보장하기 위한 전문가들이 필요합니다.\n\n6. **AI와 인간의 협업**: AI가 인간의 업무를 보조하거나 협업하는 방식으로 사용되면서, 이를 관리하고 최적화하는 직무가 생겨나고 있습니다.\n\n이러한 영역들은 AI 기술의 발전과 함께 지속적으로 성장할 것으로 예상됩니다.',
'sources': ''}}B. 5교시
1. RAGAS
- RAG 결과를 평가하는 평가 지표
- RAGAS
[RAA-gahs]: Retrieval-Augmented Generation Assessment의 약자 - RAG 기술의 성능을 정량적으로 평가하기 위한 오픈소스 프레임워크
- 검색 품질과 응답 품질을 지표로 설정 → 설정 성능을 진단
- 일반 LLM 평가와 달리, RAG 기술에 별도의 평가 지표를 사용하는 이유
- 검색기, 생성기 모두 평가
- 단순 결과('정답을 맞췄나요?')보다 검색 품질과 생성 품질을 모두 평가해 문제의 원인을 정확하게 찾을 수 있도록 함
- RAGAS 설치
!pip install -qU ragas rapidfuzz pi-heif unstructured unstructured_inference- rapidfuzz : 한글 문자열 유사도 검사
- pi-heif : HEIF 형식의 이미지를 처리할 수 있는 기능
- unstructured : 다양한 비정형 데이터에서 정보를 추출하고 처리
- unstructured_inference : 비정형 데이터의 구조적 해석과 정보 추출을 위한 기계 학습 기반 기능
2. RAG 평가용 데이터셋 비교
| 구분 | 사람이 만든 데이터셋 (Human-labeled) | 합성 데이터셋 (Synthetic, LLM-generated) |
|---|---|---|
| 구축 방식 | 전문가/사용자가 직접 질문·정답·근거 작성 | LLM을 활용해 문서에서 자동 생성 |
| 품질 | 신뢰도 높음, 실제 도메인 반영 | 품질 편차 있음, 검수 필요 |
| 다양성 | 작성자 역량/시간에 제한 → 질문 범위 좁을 수 있음 | 대량 생성 가능, 난이도·질문 유형 다양하게 생성 가능 |
| 효율성 | 시간·비용 많이 듦 (노동 집약적) | 빠르게 수백~수천 샘플 생성 가능 |
| 활용 목적 | “골든셋”(기준 데이터셋)으로 성능 검증 | 대규모 회귀 테스트, 자동화된 품질 모니터링 |
| 한계 | 구축 규모 확장 어려움 | LLM 편향, 문체 단조화, 잘못된 Q/A 가능 |
| 권장 사용법 | 소규모지만 정확한 기준 데이터셋 | 보완재로 대량 생성 후 일부 검수 |
정리
- 사람 데이터셋: 정확도, 신뢰성 확보
- 합성 데이터셋: 속도, 확장성 확보
- 두 개의 데이터셋을 하이브리드로 사용하는 것이 가장 효과적이다~
사람이 만든 데이터셋으로 평가
# 파일 읽기
documents_2 = load_pdf("./data/인공일반지능의 이해.pdf")
# 텍스트 분리
texts_2 = text_split(documents_2)
# 벡터 DB 저장 후 검색기 설정 ("faiss_db_02", 상단 2개의 유사한 결과 사용)
retriever_2 = create_retriever(texts_2, "faiss_db_02", 2)
from langchain_openai import ChatOpenAI
from langchain.prompts.chat import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# LLM 모델, 템플릿 작성
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
template = """당신은 질의 응답 작업의 보조자입니다. context 내용을 사용하여 질문에 답하세요.
답을 모르면 모른다고 하세요. 최대 두 문장을 사용하고 답변을 간결하게 해주세요.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
# 체인 생성
chain_2 = (
{"context": retriever_2, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)C. 6교시
1. Human-labeled
questions = [
"AGI(인공일반지능)는 무엇이며 기존 AI와 어떤 점이 다른가?",
"AGI 구현을 위해 제시된 핵심 기술·아키텍처의 예는 무엇인가?",
"AGI 실현 예상 시점에 대해 문서가 제시한 전망은?"
]
ground_truths = [
# Q1
"AGI는 인간 수준의 인지 능력으로 다양한 과업에 지식을 전이해 해결하는 AI를 뜻한다. "
"기존 과업 특화형 AI와 달리 스스로 학습·적응·추론하며 다중 작업을 수행한다.",
# Q2
"인과적 세계 모델 등 새로운 알고리즘/아키텍처, 지속적 학습·메타학습, "
"양자·아날로그 컴퓨팅 결합 등 고도화된 컴퓨팅이 필요하다고 서술된다.",
# Q3
"전망은 엇갈리나, 대체로 5~10년 이상이 필요하며 2035년경 초기 징후가 보일 수 있다는 관측도 제시된다."
]
# 비교를 위한 LLM의 답변 저장해 줄 빈 리스트 생성 (생성 품질)
answers = []
# LLM 응답을 위해 사용된 RAG 에시 문장 (검색 품질)
contexts = []
# 평가 데이터셋 생성
for query in questions:
# LLM으로 질문에 대한 답변 데이터 생성 후 저장
answers.append(chain_2.invoke(query)) # 여기서는 딕셔너리로 안 넣어도 됨
# 검색기 결과를 저장
# get_relevant_documents(query): 질문(quert)과 가장 관련성이 높은 document를 검색기를 통해 가져옴 → 검색기의 출력 기준이 되는 데이터
contexts.append([docs.page_content for docs in retriever_2.get_relevant_documents(query)])
answers['AGI(인공일반지능)는 인간 수준의 인지 능력을 갖춘 AI로, 다양한 과업을 수행하고 학습하며 문제를 해결할 수 있는 능력을 의미합니다. 기존 AI는 특정 용도에 제한되어 있지만, AGI는 여러 과업을 넘나들며 지식을 전이할 수 있는 점에서 차별화됩니다.',
'AGI 구현을 위해 필요한 핵심 기술·아키텍처의 예로는 새로운 알고리즘과 엄청난 연산 성능이 요구된다고 언급됩니다. 현재의 디지털 컴퓨팅 및 GPU 기반 방식은 AGI 시대에는 부족할 것으로 보입니다.',
'레즈닉은 AGI가 2035년경부터 실질적인 돌파구가 보이기 시작할 것이라고 전망했습니다. AGI의 출현은 점진적이고 단계적으로 이루어질 것이라고 강조했습니다.']contexts[['지능 수준의 인지 유연성과 적응력을 갖추고 있어 추론과 문제 해결이 가능하다.\nAI 기술은 수십 년에 걸쳐 발전해 왔고, 최근 몇 년간 큰 진전을 이뤘다. 그러나 현재의 AI 도구는 여전히\n단일 용도에 머물고 있으며, 자기 인식, 맥락 파악, 추론 같은 인간 지능의 핵심 요소는 부족한 상태다. AI가\n자동차를 운전할 수 있다면, AGI는 운전뿐 아니라 자동차를 수리하고, 세차하고, 등록까지 할 수 있다고\nAGI 지지자들은 말한다.\n딜로이트 미국 법인의 최고 혁신 책임자 데보라 골든은 “오늘날 대부분 AI는 과업 특화형이다. 대화하거나\n이미지를 분류하거나 코드를 작성할 수 있지만, 모두 훈련받은 범위 내에서만 가능하다”라며, “AGI는\n과업을 넘나들며 학습하고 지식을 전이하며, 낯선 문제도 해결할 수 있다는 점에서 다르다”라고 강조했다.\n일부 연구자와 전문가들은 인간 인지 능력에 필적하거나 이를 초월하는 AI 시스템을 AGI로 정의하지만,',
'2년 전 AGI가 통제 불능 상태가 될 것을 우려해 1,000명의 기술 분야 책임자와 AI 연구자가 새로운 AI 모델\n출시를 중단하자는 공개서한에 서명한 바 있다. 물론 그런 중단은 실제로 이뤄지지 않았고, AGI도 아직\n등장하지 않았다.\n오픈AI의 CEO 샘 알트먼과 앤트로픽의 CEO 다리오 아모데이는 AGI가 곧 도래할 것이라고 주장했다.\n그러나 일부 AI 전문가들은 보다 보수적인 관점을 견지하고 있으며, 그 예상 시점도 “앞으로 5년에서 10년\n사이”부터 “수십 년 후”, 또는 “영원히 오지 않을 것”까지 다양하다.\n혼란스러운가? 다들 마찬가지다.\nAGI란 무엇인가?\n흥미롭게도 샘 알트먼 본인조차 최근 들어 AGI라는 표현에 회의적인 입장을 보인다. 사람마다 의미를\n다르게 사용하기 때문에 “그다지 유용한 용어가 아니다”라고 밝힌 것이다. 다만 일반적으로 AGI는 인간\n수준의 인지 능력을 갖춘 AI로 정의된다. AGI 지지자들에 따르면, 이 기술은 인간처럼 이해하고, 학습하고,'],
['실행당 전력 소모가 훨씬 적지만, 챗GPT나 제미나이 같은 서비스에서 발생하는 모든 질의마다 추론 과정이\n실행되므로, 전체 전력 소모량은 학습 못지않게 커진다.\nAGI는 이론적으로 끊임없이 학습하고 적응해야 하므로, 추론 과정에서 지금보다 훨씬 많은 자원을 소모할\n수 있다. 야밧카르는 “현실 세계 데이터를 지속적으로 수집하고 활용하는 것은 전혀 다른 차원의 연산\n성능을 요구한다”라고 지적했다.\n이는 컴퓨팅 방식의 전환이 필요하다는 의미다. 현재 AI 모델은 디지털 컴퓨팅과 GPU 기반으로 작동하고\n있지만, 지속적인 연산과 처리가 요구되는 AGI 시대에는 이 방식으로는 부족하다. 야밧카르는 “우리는\n아키텍처와 알고리즘 지식에서 새로운 돌파구가 필요하다”라며, “연구자가 지금 집중하고 있는 것도 바로\n그것”이라고 말했다. 또, “AGI에는 기존 방식이 아니라 완전히 새로운 알고리즘이 필요하며, 엄청난 연산\n성능이 전제돼야 한다”라고 덧붙였다.',
'AGI의 가능성과 위험성\nAGI 지지자들은 활용 가능성이 사실상 무한하다고 주장한다. 자주 언급되는 사례 중 하나가 자율적으로\n수행하는 과학 및 의학 연구다.\n기존 AI는 특정 과업에 맞춰 훈련되며, 인간의 주도와 개입이 필요하다. AGI 지지자는 AGI가 추상적으로\n사고하고 서로 다른 분야에서 통찰력을 도출하며, 독립적으로 과학 지식을 생성하고 검증하고 정제할 수\n있는 자율 연구원 역할을 할 수 있다고 본다.\nAGI는 방대한 기존 연구 문헌, 실험 데이터, 이론 모델 등을 분석해 현재 과학계의 이해에 존재하는 공백과\n연구 기회가 있는 영역을 식별하는 것부터 시작할 수 있다. 데이터를 분석해 패턴과 이상 징후, 공백을\n식별하고 변수 간의 관계와 상관관계를 파악하며, 가장 그럴듯한 설명을 추론하는 귀추법(Abductive\nReasoning)을 통해 새로운 가설을 제안한다.\n그 다음에는 실험 설계를 포함해 실험을 자율적으로 수행한다. 단순히 시뮬레이션을 실행하는 데 그치지'],
['레즈닉은 “AI가 지혜와 이해를 갖게 되는 순간, 그때가 AGI의 시점”이라고 말했다.\n가트너는 AGI의 초기 징후가 나타날 시점에 대한 목표 시점도 제시한다. 레즈닉은 “2035년경부터 AGI로\n가는 실질적인 돌파구가 보이기 시작할 것”이라고 전망했다. 향후 10년 동안은 획기적인 돌파보다는\n느리지만 꾸준한 진전이 이어질 것으로 보인다. 레즈닉은 “어느 날 갑자기 스위치를 켜듯 AGI가 등장하는\n일은 없을 것이다. 점진적으로, 단계적으로 이뤄질 것”이라고 강조했다.\ndl-itworldkorea@foundryco.com\n© 2025 IDG Communications, Inc. All Rights Reserved.',
'2년 전 AGI가 통제 불능 상태가 될 것을 우려해 1,000명의 기술 분야 책임자와 AI 연구자가 새로운 AI 모델\n출시를 중단하자는 공개서한에 서명한 바 있다. 물론 그런 중단은 실제로 이뤄지지 않았고, AGI도 아직\n등장하지 않았다.\n오픈AI의 CEO 샘 알트먼과 앤트로픽의 CEO 다리오 아모데이는 AGI가 곧 도래할 것이라고 주장했다.\n그러나 일부 AI 전문가들은 보다 보수적인 관점을 견지하고 있으며, 그 예상 시점도 “앞으로 5년에서 10년\n사이”부터 “수십 년 후”, 또는 “영원히 오지 않을 것”까지 다양하다.\n혼란스러운가? 다들 마찬가지다.\nAGI란 무엇인가?\n흥미롭게도 샘 알트먼 본인조차 최근 들어 AGI라는 표현에 회의적인 입장을 보인다. 사람마다 의미를\n다르게 사용하기 때문에 “그다지 유용한 용어가 아니다”라고 밝힌 것이다. 다만 일반적으로 AGI는 인간\n수준의 인지 능력을 갖춘 AI로 정의된다. AGI 지지자들에 따르면, 이 기술은 인간처럼 이해하고, 학습하고,']]# 생성한 데이터셋을 딕셔너리로 변환 후 데이터프레임으로 생성
data = {
"question": questions # 질문
, "reference": ground_truths # 사람이 만든 정답
, "answer": answers # RAG 응답
, "retrieved_contexts": contexts # RAG 응답의 근거
}
# dataset으로 만들기
from datasets import Dataset
dataset = Dataset.from_dict(data)
dataset.to_pandas()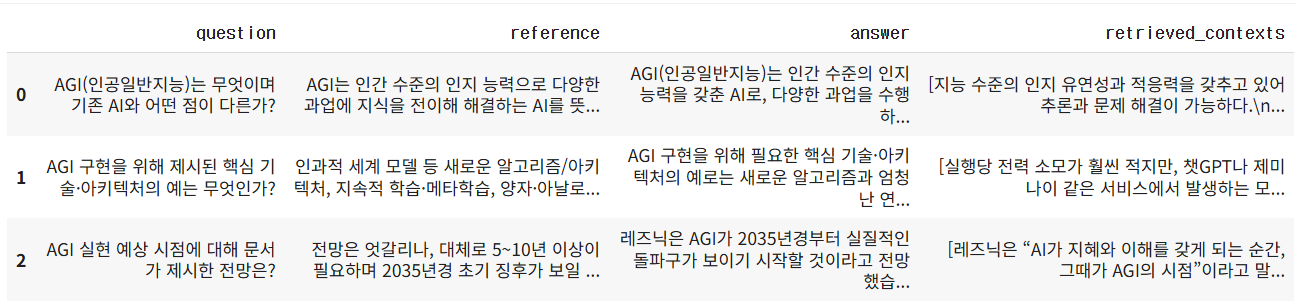
2. RAGAS Score 계산
- 평가 지표
- 정확성/신뢰성(faithfulness): 생성된 답변(answer)이 얼마나 사실(context)에 근거한 정확한 답변인지를 평가
- 응답 관련성(answer_relevancy): 생성된 답변이 질문과 얼마나 관련있는가?
- 예시 질문: "2024년 올림픽 개최지는 어디인가요?"
- 응답: "2024년 올림픽은 파리에서 열립니다." → 높음 (질문과 관련된 정확한 정보 제공)
- 응답: "올림픽은 세계적인 스포츠 행사입니다." → 낮음 (질문에 대한 핵심 답변이 누락)
- 예시 질문: "2024년 올림픽 개최지는 어디인가요?"
- 문맥 재현율(context_recall): 참조 문맥(context)의 정보가 생성된 응답에 얼마나 잘 반영되어 있는지를 평가
- 문맥 정밀도(context_precision): 생성된 응답(answer)이 참조 문맥(context)과 얼마나 일치하는지를 평가
- LLMOps, RAGAS LLM 평가지표 (Faithfulness)
- RAGAS는 LLM 평가를 위한 데이터셋을 생성하고, 이를 평가하기 위한 프레임워크입니다. 주요 성능 메트릭으로는 Retrieval(정보 검색)과 Generation(답변 생성) 두 가지가 있으며, 각각 정확성, 정밀성, 관련성 등을 평가합니다. 또한 RAGAS는 파이프라인 전체 성능을 평가하는 end-to-end 메트릭도 제공합니다.
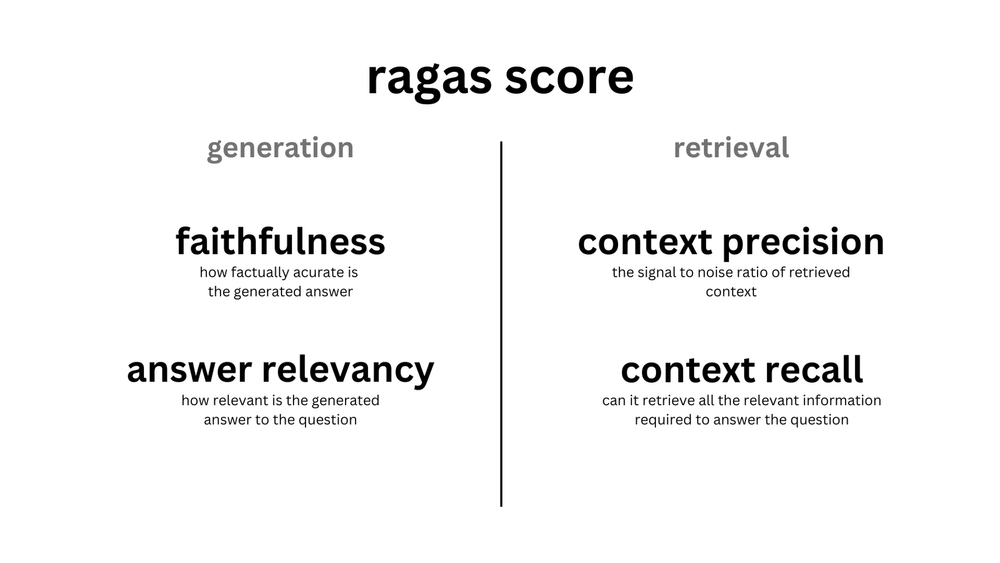
- RAGAS는 LLM 평가를 위한 데이터셋을 생성하고, 이를 평가하기 위한 프레임워크입니다. 주요 성능 메트릭으로는 Retrieval(정보 검색)과 Generation(답변 생성) 두 가지가 있으며, 각각 정확성, 정밀성, 관련성 등을 평가합니다. 또한 RAGAS는 파이프라인 전체 성능을 평가하는 end-to-end 메트릭도 제공합니다.
- RAGAS를 통한 평가
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision
result = evaluate(
dataset=dataset
, metrics=[
context_precision
, context_recall
, faithfulness
, answer_relevancy
]
)
result.to_pandas()
- Context Precision
- contexts 내의 ground-truth 관련 항목들이 상위 순위에 있는지를 평가하는 지표
- 이상적으로는 모든 관련 chunks가 상위 순위에 나타나야 함
- question, ground_truth, 그리고 contexts를 사용하여 계산
- Context Precision@K의 계산식
- K는 contexts의 총 chunk 수, 은 순위 k에서의 관련성 지표
- Precision@k는 다음과 같이 계산함
- 0에서 1 사이의 값 (높은 점수일수록 더 나은 정밀도를 나타냄)
- 정보 검색 시스템에서 검색된 컨텍스트의 품질을 평가하는 데 사용 → 관련 정보가 얼마나 정확하게 상위 순위에 배치되었는지를 측정함으로써 시스템의 성능을 판단
- Context Recall
- 검색된 context가 LLM 이 생성한 답변과 얼마나 일치하는지를 측정
- question, ground truth 및 검색된 context를 사용하여 계산
- 값은 0에서 1 사이 (높을수록 더 나은 성능을 나타냄)
- Ground truth 답변에서 context recall을 추정하기 위해, ground truth 답변의 각 주장이 검색된 context에 귀속될 수 있는지 분석
- 이상적인 시나리오에서는 ground truth 답변의 모든 주장이 검색된 context에 귀속될 수 있어야 함
- Faithfulness
- 생성된 답변의 사실적 일관성을 주어진 컨텍스트와 비교하여 측정하는 지표
- 주요 특징
- 목적: 생성된 답변의 관련성을 평가
- 점수 해석: 낮은 점수는 불완전하거나 중복 정보를 포함한 답변을, 높은 점수는 더 나은 관련성을 나타냄
- 계산에 사용되는 요소: question, context, answer
- 점수 계산 방법
- 생성된 답변에서 주장(claims)들을 식별
- 각 주장을 주어진 컨텍스트와 대조 검증하여 컨텍스트에서 추론 가능한지 확인
- 아래 수식을 사용하여 점수를 계산
- 예시
- 질문: "아인슈타인은 어디서, 언제 태어났나요?"
- 컨텍스트: "알버트 아인슈타인(1879년 3월 14일 출생)은 독일 출신의 이론 물리학자로, 역사상 가장 위대하고 영향력 있는 과학자 중 한 명으로 여겨집니다."
- 높은 충실도 답변: "아인슈타인은 1879년 3월 14일 독일에서 태어났습니다."
- 낮은 충실도 답변: "아인슈타인은 1879년 3월 20일 독일에서 태어났습니다."
- 생성된 답변이 주어진 컨텍스트에 얼마나 충실한지를 평가하는 데 유용하며, 특히 질문-답변 시스템의 정확성과 신뢰성을 측정하는 데 중요
- Answer Relevancy
- 생성된 답변이 주어진 prompt에 얼마나 적절한지를 평가하는 지표
- 주요 특징
- 목적: 생성된 답변의 관련성을 평가
- 점수 해석: 낮은 점수는 불완전하거나 중복 정보를 포함한 답변을, 높은 점수는 더 나은 관련성을 나타냄
- 계산에 사용되는 요소: question, context, answer
- 점수 계산 방법
- 원래 question과 answer를 기반으로 생성된 인공적인 질문들 간의 평균 코사인 유사도로 정의
- 아래와 같이 계산할 수도 있음
- 는 생성된 질문 의 임베딩
- 는 원래 질문의 임베딩
- 은 생성된 질문의 수 (기본값 3)
- 주의 사항
- 실제로는 점수가 대부분 0과 1 사이에 있지만, 코사인 유사도의 특성상 수학적으로 -1에서 1 사이의 값을 가질 수 있음
- 질문-답변 시스템의 성능을 평가하는 데 유용
- 특히 생성된 답변이 원래 질문의 의도를 얼마나 잘 반영하는지를 측정
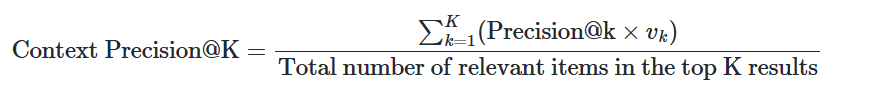
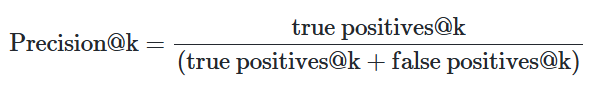
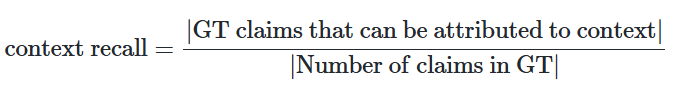
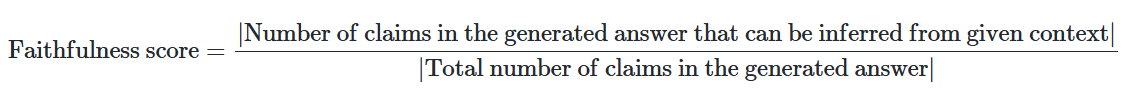
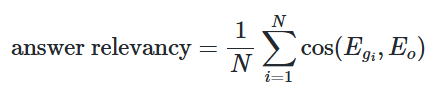
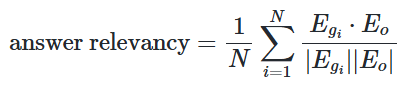
정리: 평가 결과 해석
- 검색 단계(precision, recall): 검색 품질이 매우 좋음
- 생성 단계(faithfulness): 근거에 충실, 환각 없음
- 문제점
- answer_relevancy가 답변이 질문의 의도에 맞지 않는다고 판단
- 프롬프트 등을 개선하기!
- answer_relevancy가 답변이 질문의 의도에 맞지 않는다고 판단
RAGAS 평가 지표 정리
| 지표 (EN) | 무엇을 재는가 | 필요 컬럼(최소) | 비고 |
|---|---|---|---|
| Faithfulness (정확성/신뢰성) | 응답이 retrieved context에 사실적으로 근거했는가 | user_input, response, retrieved_contexts | LLM판정 기반. 응답의 주장들을 컨텍스트로 검증. |
| Response Relevancy (aka Answer Relevancy) (응답 관련성) | 질문과의 관련도 | user_input, response | 질문과 덜 관련/장황하면 감점. |
| Context Precision (문맥 정밀도) | 가져온 컨텍스트 중 관련 조각의 비율 | (가변) WithoutReference(LLM): user_input, response, retrieved_contexts / WithReference(LLM): reference, retrieved_contexts (+옵션 user_input) / WithReference(Non-LLM): reference_contexts, retrieved_contexts | 구현에 따라 LLM·Non-LLM 버전 존재. 공통적으로 retrieved_contexts 필수. |
| Context Recall (문맥 재현율) | 놓치지 않았는가(필요 정보가 컨텍스트에 얼마나 포함) | LLM 버전: user_input, reference, retrieved_contexts / Non-LLM 버전: reference_contexts, retrieved_contexts | Recall은 기준이 필요 → 참조(reference 또는 reference_contexts)가 필수. |
| Context Entities Recall (문맥 엔터티 재현율) | 참조에 있는 엔터티가 컨텍스트에서 얼마나 회수되었는가 | reference, retrieved_contexts | 엔터티 기반 재현율. |
| Noise Sensitivity (노이즈 민감도) | 불필요/오류 문맥이 있을 때 오답을 내는 빈도 | user_input, response, reference, retrieved_contexts | 낮을수록 좋음. 노이즈 주입 평가. |
| Multimodal Faithfulness (멀티모달 신뢰성) | 응답이 텍스트+비주얼 컨텍스트에 사실적으로 일치하는가 | response + 텍스트/비주얼 컨텍스트(프로젝트 스키마에 맞게) | 멀티모달 RAG용. |
| Multimodal Relevance (멀티모달 관련성) | 질문–응답–멀티모달 컨텍스트의 관련도 | user_input, response + 텍스트/비주얼 컨텍스트 | 멀티모달 관련성 판정. |
내용 보충
# 평가용 질문
q1 = "인공일반지능은 무엇인가요?"
q2 = "기존 약한 AI와의 차이점은 무엇인가요?"
q3 = "AGI가 자율 연구원이 되어 할 수 있는 일들은 무엇일까요?"
questions = [q1, q2, q3]
# 평가용 질문에 대한 대답: ground_text(인간이 쓴 정답)
a1 = "인간처럼 이해하고 학습하고 지식을 다양한 과업에 적용할 수 있는 인간 수준의 인지 능력을 갖춘 AI이다."
a2 = "AGI는 스스로 행동을 시작하고 여러 작업을 수행하며 추론과 문제 해결이 가능하다."
a3 = "현재 과학계의 이해에 존재하는 공백과 연구 기회가 있는 영역을 식별하고 실험 설계를 포함해 실험을 자율적으로 수행한다."
ground_text = [a1, a2, a3]
# 비교를 위한 LLM의 답변 저장해 줄 빈 리스트 생성 (생성 품질)
answers = []
# LLM 응답을 위해 사용된 RAG 에시 문장 (검색 품질)
contexts = []
# 평가 데이터셋 생성
for query in questions:
# LLM으로 질문에 대한 답변 데이터 생성 후 저장
answers.append(chain_2.invoke(query)) # 여기서는 딕셔너리로 안 넣어도 됨
# 검색기 결과를 저장
# get_relevant_documents(query): 질문(quert)과 가장 관련성이 높은 document를 검색기를 통해 가져옴 → 검색기의 출력 기준이 되는 데이터
contexts.append([docs.page_content for docs in retriever_2.get_relevant_documents(query)])
# 생성한 데이터셋을 딕셔너리로 변환 후 데이터프레임으로 생성
data = {
"question": questions # 질문
, "reference": ground_text # 사람이 만든 정답
, "answer": answers # RAG 응답
, "retrieved_contexts": contexts # RAG 응답의 근거
}
# dataset으로 만들기
from datasets import Dataset
dataset = Dataset.from_dict(data)
dataset.to_pandas()
result = evaluate(
dataset=dataset
, metrics=[
context_precision
, context_recall
, faithfulness
, answer_relevancy
]
)
result.to_pandas()
추가
q3 = "AGI 구현을 위한 핵심 기술은 무엇인가요?"
a3 = "단순한 관찰, 패턴 인식, 예측을 넘어 인과 추론과 의사결정을 가능하게 하는 인과적 세계 모델과 양자 컴퓨팅과 아날로그 컴퓨팅을 결합한 새로운 형태의 컴퓨팅 기술이 필요하다."- 위 질문-답에 대한 answer_relevancy, context_recall 결과: 0점 → WHY?
- Answer Relevancy 0.0의 이유
- 생성된 답변이 질문과 의미상 맞지 않거나 관련성이 거의 없을 때
- 답변이 너무 짧거나 불완전해서 역으로 질문 생성이 제대로 이뤄지지 않은 경우
- 질문/답변 데이터 포맷 오류 또는 LLM 임베딩 생성 문제 가능성
- Context Recall 0.0의 이유
- 참조 답변 내 주장을 커버하는 검색된 문맥이 전혀 없을 때 발생
- 참조 답변과 검색 문맥간의 내용 불일치 혹은 문맥 설정 오류 가능성
- retrieved_contexts가 비어 있거나 적절히 입력되지 않은 경우
- Answer Relevancy 0.0의 이유
RAGAS 스코어는 Retrieval-Augmented Generation (RAG) 시스템의 성능을 평가하기 위해 고안된 평가 프레임워크입니다. 주요 평가 지표로는 답변의 연관성(Answer Relevancy), 문맥 재현율(Context Recall), 문맥 정밀도(Context Precision), 그리고 사실성(Faithfulness) 등이 있습니다.
- Answer Relevancy (답변 연관성): 생성된 답변이 원래 질문과 얼마나 관련성이 높은지를 평가하는 지표입니다. LLM이 생성한 답변을 바탕으로 역으로 질문을 여러 번 생성하고, 이 인공 질문들과 원래 질문의 임베딩 코사인 유사도를 평균 내어 계산합니다. 점수가 낮으면 답변이 불완전하거나 불필요한 정보가 포함된 것이고, 높으면 질문에 적절히 답한 것입니다. 이 점수는 보통 0에서 1 사이지만 코사인 유사도 특성상 -1에서 1 사이일 수도 있어 0 또는 1이 아닐 수도 있습니다.
- Context Recall (문맥 재현율): 시스템이 얼마나 많은 관련 정보를 성공적으로 검색해냈는지를 나타내며, 중요한 정보를 놓치지 않는 정도를 평가합니다. 예를 들어 참조 답변(ground truth)을 여러 개의 개별 주장(claim)으로 나눈 뒤, 검색된 문맥(retrieved contexts)이 그 각각을 얼마나 커버하는지 확인하는 방식입니다. 최대 1까지의 값으로 평가되며 0이면 전혀 관련 정보를 못 찾은 것입니다.
두 지표 모두 평가 시 원래 질문(user_input), 참조 답변(reference), 그리고 검색된 문맥(retrieved_contexts)을 활용합니다. 따라서, 만약 answer_relevancy가 0.0, context_recall이 0.0으로 나왔다면 다음과 같은 이유가 있을 수 있습니다.
- Answer Relevancy 0.0의 이유
- 생성된 답변이 질문과 의미상 맞지 않거나 관련성이 거의 없을 때 나타납니다.
- 답변이 너무 짧거나 불완전해서 역으로 질문 생성이 제대로 이뤄지지 않은 경우.
- 질문/답변 데이터 포맷 오류 또는 LLM 임베딩 생성 문제 가능성.
- Context Recall 0.0의 이유
- 참조 답변 내 주장을 커버하는 검색된 문맥이 전혀 없을 때 발생합니다.
- 참조 답변과 검색 문맥간의 내용 불일치 혹은 문맥 설정 오류 가능성.
- retrieved_contexts가 비어 있거나 적절히 입력되지 않은 경우.
- 따라서 사용된
user_input,retrieved_contexts,reference간 내용이 얼마나 의미적으로 맞물려 있는지가 중요합니다. 만약 검색된 문맥에 답변의 주요 내용을 뒷받침하는 정보가 없거나, 생성된 답변이 질문에 부합하지 않으면 이런 0 점수가 산출됩니다. 메트릭은 LLM을 이용하지만 로직상 여전히 입력된 데이터 간 적절한 의미적 연결이 있어야 점수가 높게 나옵니다.- 요약하면,
- answer_relevancy 0.0 → 답변이 질문과 관련성이 전혀 없거나 적절한 질문 역생성이 실패했기 때문
- context_recall 0.0 → 검색된 문맥이 참조 답변의 핵심 주장을 전혀 포함하지 않아서
- 이 두 점수가 모두 0인 경우는 입력 데이터(질문, 답변, 참조, 문맥) 간 의미 불일치 또는 포맷 오류 가능성이 크니 데이터 검증이 필요합니다. 또한 RAGAS 평가 도구가 요구하는 정확한 입력 형식을 따르고 있는지 점검하는 것이 좋습니다.
Ⅲ. CAREER UP
오늘 학습한 내용 복습 & 보충
한국어 WordNet 데이터 처리 방식# 한국어 WordNet 데이터 처리 방식
1. 한국어 WordNet 데이터 준비
- 보통 한국어 WordNet 데이터는 XML, RDF, JSON, 또는 CSV 포맷으로 제공됩니다. 예를 들어 KAIST 오픈 한국어 워드넷(KWN)은 RDF/XML 형태로 배포되기도 합니다.
- 데이터를 내려받아 로컬에 저장하거나, API를 통해 접근할 수도 있습니다.
2. 데이터 파싱
- RDF/XML 형식의 WordNet 데이터를 파이썬에서 파싱하려면
rdflib같은 RDF 처리 라이브러리를 사용합니다. - XML, JSON 등 다른 형식은
xml.etree.ElementTree,json모듈 등으로 파싱합니다.
예 (RDF/XML 파싱 간단 예시):
from rdflib import Graph, URIRef
# 한국어 WordNet RDF 데이터 로드
g = Graph()
g.parse("korean_wordnet.rdf")
# 특정 단어의 동의어(유의어) 조회 예시
word_uri = URIRef("http://ko-wn.nate.com/word/0012345") # 예시 URI
query = """
PREFIX wn: <http://ko-wn.nate.com/wordnet#>
SELECT ?synonym WHERE {
?synset wn:contains ?word .
?synset wn:contains ?synonym .
FILTER(?word = <http://ko-wn.nate.com/word/0012345>)
}
"""
results = g.query(query)
for row in results:
print(str(row.synonym))3. 형태소 분석 및 토큰화
- 한국어 자연어처리에서는 단어 단위 토큰화가 중요합니다.
- KoNLPy나 KiwiTokenizer 등으로 문장을 토큰화 후 어간 처리, 품사 태깅 등 수행합니다.
- 평가에 맞게 형태소 단위 매칭을 할지, 단어 단위 매칭을 할지 결정합니다.
예:
from kiwipiepy import Kiwi
kiwi = Kiwi()
text = "나는 학교에 갑니다"
tokens = kiwi.tokenize(text)
print(tokens) # 형태소와 품사 출력4. 동의어 매칭 함수 구현
- 토큰 하나씩 한국어 WordNet에서 동의어 집합을 조회하는 함수를 만듭니다.
- 두 문장 간 토큰 비교 시 동의어 집합에 포함되면 매칭 점수를 가중치를 주는 식으로 구현.
예:
def get_synonyms(word_uri, graph):
# word_uri에 해당하는 동의어 집합 반환 (URI 혹은 문자열)
synonyms = set()
query = f"""
PREFIX wn: <http://ko-wn.nate.com/wordnet#>
SELECT ?synonym WHERE {{
?synset wn:contains ?word .
?synset wn:contains ?synonym .
FILTER(?word = <{word_uri}>)
}}
"""
results = graph.query(query)
for row in results:
synonyms.add(str(row.synonym))
return synonyms5. METEOR 평가 함수 확장
- 기존 NLTK meteor_score와 달리, 한국어 문장 토큰화 후 동의어 매칭 여부를 판단하여 점수 계산 로직에 반영.
- 형태소 기준으로 정확한 단어 매칭, 어간매칭, 동의어 매칭을 분리 처리.
요약
- 한국어 WordNet 데이터는 RDF/XML에 저장되어 있어
rdflib로 파싱. - 형태소 분석기로 한국어 문장 토큰화.
- WordNet 내부에서 동의어 집합 추출 SPARQL 쿼리 작성.
- 동의어 기반 매칭 로직을 METEOR 평가 산출 로직에 맞게 커스텀 구현.
이 흐름을 바탕으로 코드를 작성하면 한국어 문장 간 METEOR 평가 시 동의어, 어간, 형태 변화까지 반영 가능합니다.
하루 돌아보기
👍 잘한 점
- 수업 참여 열심히 함
- 모르는 내용 보충 그때그때 함
- 정규 수업 시간 안에 오늘 배운 내용 복습 완료함
👎 아쉬웠던 점
- 리눅스 시험 공부를 못했음
🔬 개선점
- 어쩔 수 없지… 잠을 좀 줄이자🫠
