목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. 라우터 쪼개기
B. 2교시
1. app.js에 esportRouter 등록하기
2. Database: MySQL
3. MySQL Workbench
C. 3교시
1. MySQL Workbench (cont.)
Ⅱ. 오후 수업
A. 4교시
1. LangSmith
B. 5교시
1. LangChain 평가 지표
2. ROUGE Score
C. 6교시
1. BLEU 지표
2. METEOR 지표
Ⅲ. CAREER UP
정보보호교육Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
- GET/POST 방식 데이터 처리
- express에서 get 방식의 데이터를 꺼낼 때는 변환이 필요 없다 → express가 했음
- express에서 GET 데이터는
req.query에 객체 형태로 자동 저장됨
- express에서 GET 데이터는
- POST 방식의 데이터 처리
- Express에서 POST 데이터는
req.body에 자동 저장됨 - 단, 먼저 body-parser 모듈을 호출해서 app에 등록해야 함 (buffer 형태의 데이터를 string을 거쳐 object로 바꾸는 모듈임)
- Express에서 POST 데이터는
- express에서 get 방식의 데이터를 꺼낼 때는 변환이 필요 없다 → express가 했음
const bp = require("body-parser");
app.use(bp.urlencoded({extended:true}));
// POST 데이터 처리
app.post("/postLogin",(req,res)=>{
console.log(req.body);
});- 앞으로 express 이용해 서버 만들 때 아래 다섯 줄 코드는 무조건 가져가기!
const express = require("express");
const app = express();
const bp = require("body-parser");
app.use(express.static("public"));
app.use(bp.urlencoded({extended:true}));- routes 활용
- 라우터: 사용자가 보낸 요청에 관련된 업무를 담당하는 파일
- 주의점: 절대경로의 위치가 변경 → 파일을 호출할 때 문제가 발생 → path 모듈로 문제 해결 (path 모듈은 경로 조합 시 사용하는 모듈)
- 라우터를 사용할 때 경로가 여러 그룹이라면 라우터를 쪼개는 게 효율적
- 라우터를 제작하면 반드시 exports 해주기! → 라우터는 내가 만든 모듈이기 때문
- 내가 만든 자바스크립트 모델이고 내가 필요한 기능들을 묶어놓은 하나이 모듈이라는 개념 → 마지막에 수출을 해 줘야 다른 파일에서 가져다가 쓸 수 있음
- 라우터: 사용자가 보낸 요청에 관련된 업무를 담당하는 파일
// mainRouter.js
const express = require("express");
const router = express.Router(); // express의 여러 기능 중 Router만 가져가기
const path = require("path");
const filePath = path.join(__dirname,"../public");
router.get("/",(req,res)=>{
res.sendFile(filePath+"/main.html");
});
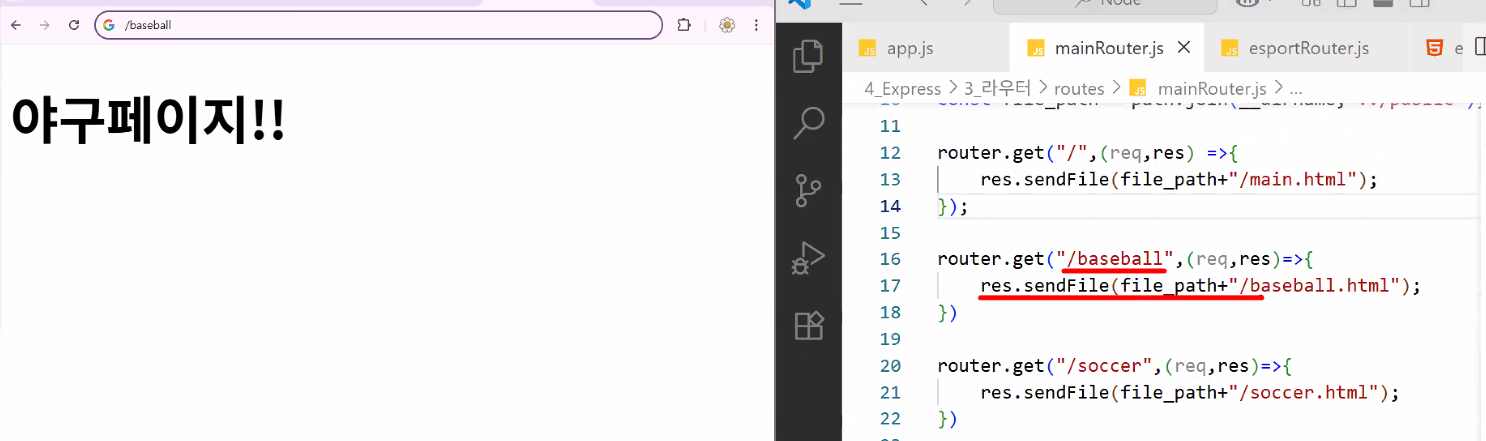
router.get("/baseball",(req,res)=>{
res.sendFile(filePath+"/baseball.html");
});
router.get("/soccer",(req,res)=>{
res.sendFile(filePath+"/soccer.html");
});
module.exports = router;
// app.js
const express = require("express");
const app = express();
const bp = require("body-parser"); // 내장모듈&설치모듈은 이름만 가지고 오면 됨
// 내가 제작한 모듈을 호출할 때는 반드시 경로를 확인하자!
const mainRouter = require("./routes/mainRouter"); // 내가 만든 모듈은 상대경로 써야 함
app.use(express.static("public"));
app.use(bp.urlencoded({extended:true}));
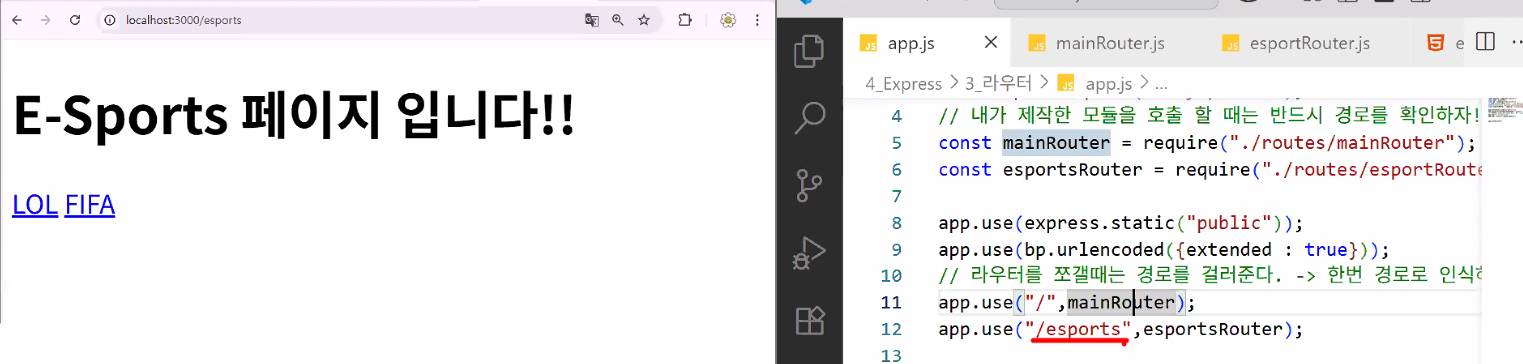
app.use("/",mainRouter); // ※ 사용등록 필수 ※
// 3000번 포트 뒤 경로 확인하고 "/"로 한번에 들어가는 구조라면 mainRouter 사용하겠다는 뜻
app.listen(3000);→ app.get에서 router.get으로: 업무는 동일하지만 실행하는 주체가 바뀜
- 경로 파악하기
__dirname: 현재 실행 중인 파일을 포함하는 폴더까지가 기준- routes 폴더 안에서 public 폴더로 가려면 한 번 뒤로 나가야 함 → path 모듈 사용:
const path = require("path");- 내가 연결하고자 하는 절대 경로와 "../public"을 join으로 연결하면 경로 자체가 생성됨
const filePath = path.join(__dirname,"../public");→res.sendFile(filePath+"/main.html");- 폴더까지만 묶어서 뒤에 파일명 바꿔가며 쓸 수 있도록 하기
- 흐름 파악하기
- 사용자가 3000번 포트 방문 → app.js: 3000번 포트 입장 확인 & 경로 특이사항 확인 → mainRouter.js 호출 → mainRouter.js: 메인 페이지 표출 (경로에 특이사항이 없었으니까) → 사용자가 야구 페이지 클릭 → app.js: 3000번 포트 입장 확인 & 경로 특이사항 확인 (/baseball은 /로만 시작하니까 mainRouter.js가 다시 한번 열림) → mainRouter.js: 경로 뒤 baseball 명칭 확인 (html a 태그로 인해 이미 해당 경로로 이동한 상태니까 sendFile로 파일 돌려주기) → 야구 페이지 표출
2. 라우터 쪼개기
- 그룹화 → 관리를 용이하게 만듦
E스포츠 추가하기
- main.html에 E스포츠를 관장하는 메인 페이지 넣기 → eport a 태그 추가
- app.js에서 서버가 받을 준비하기 → mainRouter.js에 esports 추가
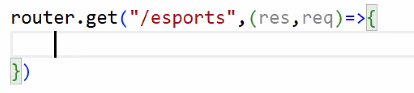
- esports 메인 페이지 만들기 → esports.html
- 경로 연결하기
res.sendFile(filePath+"/esports.html");
- esports 페이지에 게임 두 개 연결 추가하기
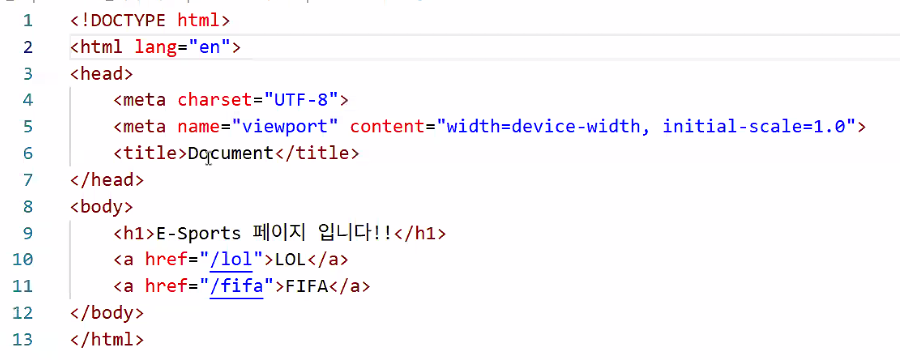
문제점:
a. LOL 누르면 /esports/lol로 가는 게 아니라 /lol로 이동함 (두 번 들어가는 경로인데 한 번만 들어가는 걸로 나옴)
b. 이렇게 만들면 경로 그룹화가 안 됨(mainRouter.js가 다 하니까)
-
esports 그룹 만들기 → 경로에 esports 추가

-
라우터 쪼개기: esportsRouter.js 만들기
- 조건문 거는 것과 비슷하다고 생각하면 됨
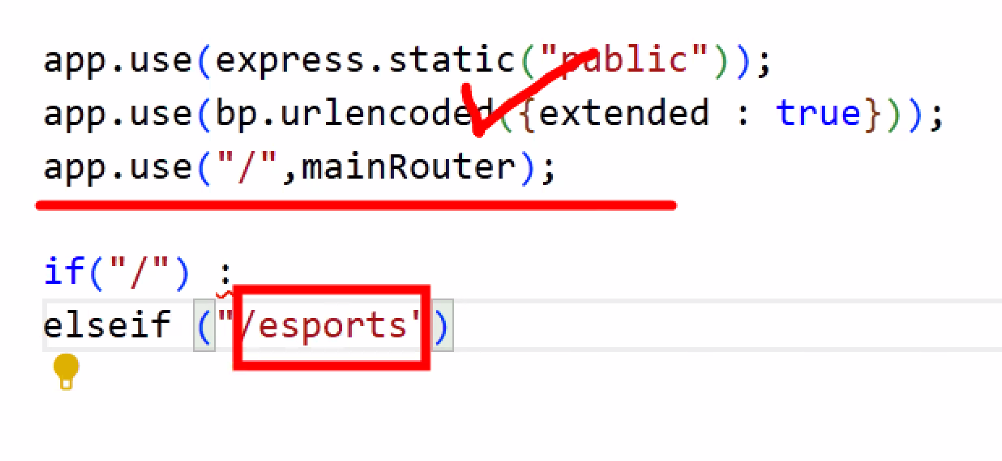
- app.js 라우터의 업무 분배
- 메인 라우터
- E스포츠 라우터
- E스포츠 라우터 생성
const express = require("express"); const router = express.Router(); const path = require("path"); const filePath = path.join(__dirname,"../public"); // esportsRouter는 app.js에서 한번 경로를 걸러서 들어온다 → /esports 경로가 사라진다. router.get("/",(req,res)=>{ res.sendFile(filePath+"/esports.html"); }); router.get("/lol",(req,res)=>{ res.sendFile(filePath+"/lol.html"); }); router.get("/valorant",(req,res)=>{ res.sendFile(filePath+"/valorant.html"); }); module.exports = router;- 미들웨어 등록하기
- 조건문 거는 것과 비슷하다고 생각하면 됨
B. 2교시
1. app.js에 esportRouter 등록하기
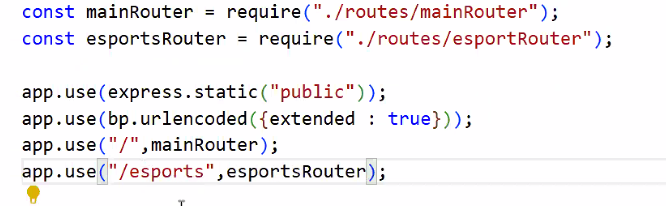
- 라우터를 쪼갤 때는 경로를 걸러준다. → 앞의 경로를 지워준다.
- 한번 경로로 인식하면 '해당 경로는 포함한다'라고 생각
- app.js에서 라우터로 들어오는 순간 앞의 경로는 다 처리된 거니까 없는 거랑 같음
- esportsRouter.js 경로에 'eports'라는 내용이 없는 이유 == 이미 app.js선에서 해결됨
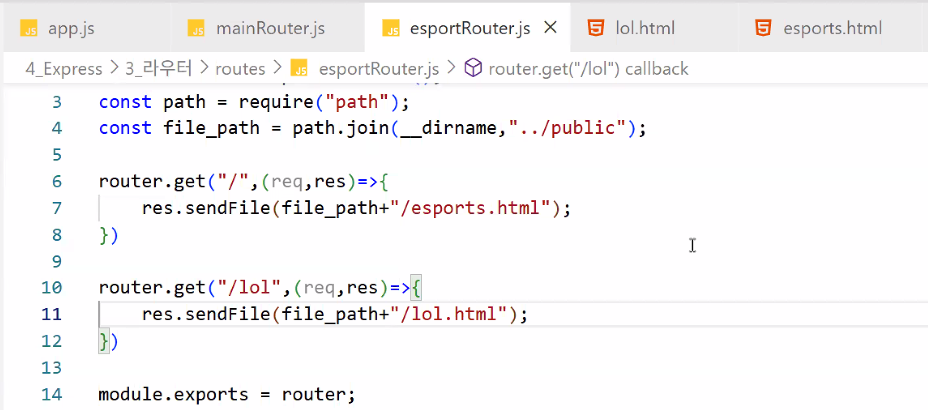
- esportsRouter는 app.js에서 한번 경로를 걸러서 들어온다 → /esports 경로가 사라진다.
- 한번 경로로 인식하면 '해당 경로는 포함한다'라고 생각
- 주의: 반드시 그룹화가 필요한 경우에만 라우터를 쪼개자
- 일단 하나로 다 만들고 만들다가 그룹화가 필요해지면 그때 쪼개면 됨
- 데이터 흐름 정리
- 사용자가 3000번 포트 방문 → app.js: 3000번 포트 입장 확인 & 경로 특이사항 확인 → mainRouter.js 호출 → mainRouter.js: 메인 페이지 표출 (경로에 특이사항이 없었으니까) → 사용자가 E스포츠 페이지 클릭 → app.js: 3000번 포트 입장 확인 & 경로 특이사항 확인 (/esports) → 경로 뒤에 /esports 있어요! → 그럼 esportsRouter.js 실행하세요 → esportsRouter.js: /esports 경로로 입장한 것 확인했습니다. 뒤에 명칭 더 붙는 거 있나요? → 없습니다! → E스포츠 메인 페이지 표출 → 사용자가 E스포츠 메인 페이지에서 LoL 클릭 → app.js: 3000번 포트 입장 확인 & 경로 특이사항 확인 (/esports/lol) → 경로 뒤에 /esports 있어요! → 그럼 esportsRouter.js 실행하세요 → esportsRouter.js: /esports 경로로 입장한 것 확인했습니다. 뒤에 명칭 더 붙는 거 있나요? → /lol 있습니다! → E스포츠 lol 페이지 표출
- Point
- 라우터를 쪼갤 때는 경로를 걸러준다. → 한번 경로로 인식하면 '해당 경로는 포함한다'라고 생각한다.
- esportsRouter는 app.js에서 한번 경로를 걸러서 들어온다 → /esports 경로가 사라진다.
- 반드시 그룹화가 필요한 경우에만 라우터를 쪼개자!
- 처음부터 쪼개려 하지 말고 일단 하나의 라우터에 전부 다 넣은 다음 쪼개야겠다는 생각이 들면 그때 쪼개도록 하자
- 라우터를 쪼갤 때는 경로를 걸러준다. → 한번 경로로 인식하면 '해당 경로는 포함한다'라고 생각한다.
큰 부서 안의 작은 하위부서, 혹은 대분류-소분류를 보는 느낌으로 이해하면 됨
Q. 하위 라우터를 위에 배치하라고 하던데 우리는 하위 라우터가 아래 있네요?
A. 우리가 짠 코드는 경로 중복이 없어서 순서 상관없음 (라우터 간 경로 중복이 있는 경우 순서 중요)
- 전체 흐름 이해하기
- 서버의 시작: 3000번 포트로 사용자 방문
- app.js
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → 없어요~ (
http://localhost:3000→ 뒤에 아무것도 없음) - 경로 뒤에 특이사항 없으면 메인 라우터 실행 (
app.use("/",mainRouter);) → 메인 라우터 호출
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → 없어요~ (
- mainRouter.js
- 한 번 더 경로 확인: 메인 뒤에 특별한 표시 있나요? → 없어요~
- 경로 뒤에 특별한 내용 없으니까
router.get("/",(req,res)=>{res.sendFile(filePath+"/main.html");});실행 → main.html 보여주기
- app.js
- 사용자가 main.html에서 야구 페이지를 누름 (
http://localhost:3000/baseball)- app.js
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → /baseball → app.js 내에 /baseball에 대한 특별한 지시 없음 == 특이사항 없음!
- 경로 뒤에 특이사항 없으면 메인 라우터 실행 (
app.use("/",mainRouter);) → 메인 라우터 호출
- mainRouter.js
- 한 번 더 경로 확인: 메인 뒤에 특별한 표시 있나요? → /baseball →
router.get("/baseball",(req,res)=>{res.sendFile(filePath+"/baseball.html");});실행 → baseball.html 보여주기
- 한 번 더 경로 확인: 메인 뒤에 특별한 표시 있나요? → /baseball →
- app.js
- 사용자가 main.html에서 E스포츠 페이지를 누름 (
http://localhost:3000/esports)- app.js
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → /esports → app.js 내에 /eports에 대한 특별한 지시 존재함:
app.use("/esports",esportsRouter); - 경로 뒤에 /esports가 있네요! esportsRouter로 넘길게요~ → esportRouter 호출
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → /esports → app.js 내에 /eports에 대한 특별한 지시 존재함:
- esportsRouter.js
- 한 번 더 경로 확인: /esports 뒤에 특별한 표시 있나요? → 없어요~
- 들어온 경로 뒤에 특별한 내용 없으니까
router.get("/",(req,res)=>{res.sendFile(filePath+"/esports.html");});실행 → esports.html 보여주기
- app.js
- 사용자가 E스포츠 메인에서 lol 페이지를 누름 (
http://localhost:3000/esports/lol)- app.js
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → /esports/lol → app.js 내에 /eports에 대한 특별한 지시 존재함:
app.use("/esports",esportsRouter); - 경로 뒤에 /esports가 있네요! esportsRouter로 넘길게요~ → esportRouter 호출
- 라우터 업무 분배를 위해 경로 파악: 경로 뒤에 특이사항 있나요? → /esports/lol → app.js 내에 /eports에 대한 특별한 지시 존재함:
- esportsRouter.js
- 한 번 더 경로 확인: /esports 뒤에 특별한 표시 있나요? → /lol
- 들어온 경로(/esports) 뒤에 /lol 있으니까
router.get("/lol",(req,res)=>{res.sendFile(filePath+"/lol.html");});실행 → lol.html 보여주기
- app.js
- 서버의 시작: 3000번 포트로 사용자 방문
이제 '회원 가입, 탈퇴, 수정, 삭제' 구현을 위해 데이터베이스를 배워봅시다!
《함께 알아두면 좋은 내용》
넌적스(Nunjucks)
쿠키와 세션
2. Database: MySQL
- SQL vs. NoSQL
- SQL
- 관계형 데이터베이스(RDBMS)
- 컬럼 만들고 테이블 설계하고 테이블 간 관계 정의
- Oracle, MySQL, SQLite, MariaDB, …
- NoSQL
- "Not only SQL"
- SQL만을 사용하지 않는 데이터베이스 관리 시스템(DBMS)을 지칭하는 단어
- 비관계형 데이터 모델에 대해 특정 용도로 구축되는 데이터베이스로서 현대적인 애플리케이션 구축을 위한 유연한 스키마를 갖추고 있음 → 관계형 테이블과 다른 형식으로 데이터를 저장하는 비관계형 데이터베이스 유형 (like JSON)
- MongoDB(문서형), Redis(키-값형), Amazon DynamoDB(키-값/문서형)
- SQL
- 보통 자바스크립트 베이스인 회사는 대부분 NoSQL을 많이 사용하고 자바 베이스인 회사는 SQL을 많이 사용함
- 국산 DB도 있음: CUBRID
데이터를 저장하는 공간 만들기: 데이터베이스 서버 설치
- 지금 상황
- vscode 라이브 서버와 node.js는 서로 다른 공간임
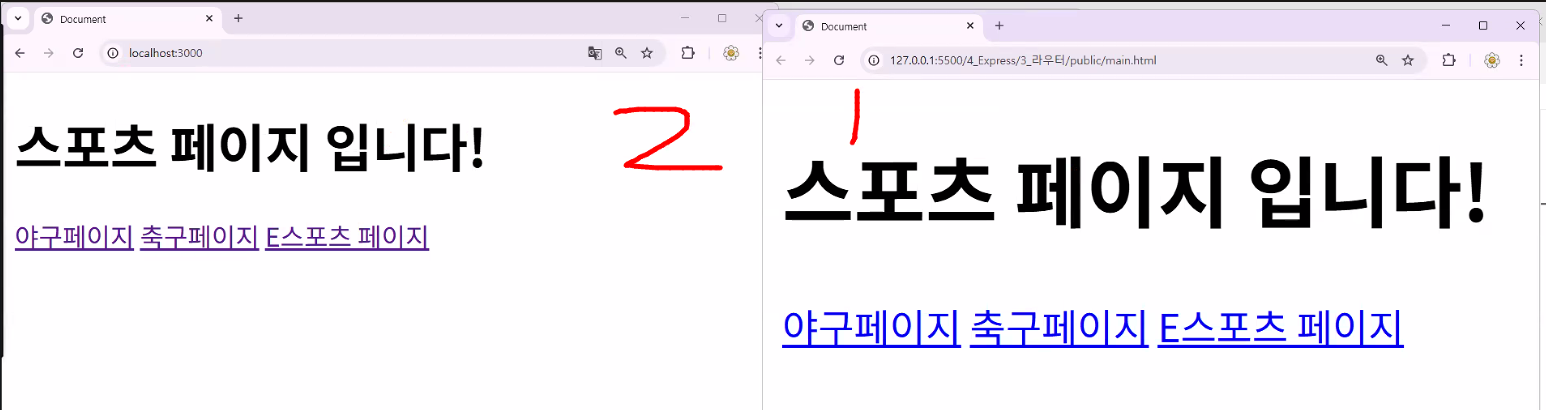
- 포트 번호가 서로 다름(3000, 5500) → 서로 다른 컴퓨터(가상)!
- 우리는 서버 1개(node.js로 만든 3000번 포트)만 가지고 페이지도 보여주고 통신도 했음 → build: 내 서버에 내 페이지를 띄우는 행위를 "bulid"라고 함
- 현재는 사용자가 보낸 데이터를 가지고 작업할 수 있긴 하지만 서버가 꺼지는 순간 데이터가 증발함 → 어딘가에 저장해두자! → 데이터베이스
- 서버와 데이터베이스 사이에 데이터를 주고받으려면 반드시 "서버"가 필요함 → 컴퓨터의 가상 공간에 DB 서버를 만들어서 내가 만든 backend 서버와 데이터를 주고받을 수 있는 구조 만들기
- vscode 라이브 서버와 node.js는 서로 다른 공간임
- MySQL 설치하기
- 다운로드
- mysql-installer-community-8.0.43.0.msi 설치하기
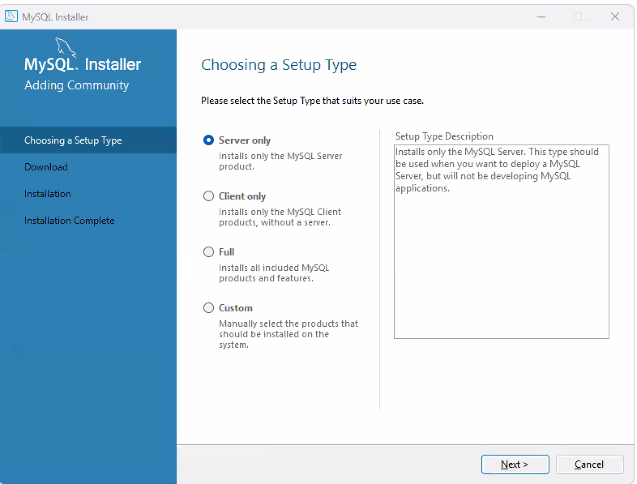
- 'custom' 클릭하고 next
- Server와 Workbench만 설치
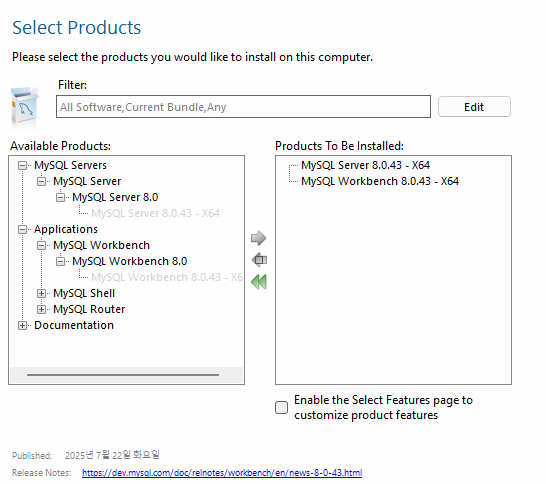
- 만약 선택할 수 있는 게 여러 개 나오면 맨 위에 있는 거 고르기
- DB 서버 설정 확인
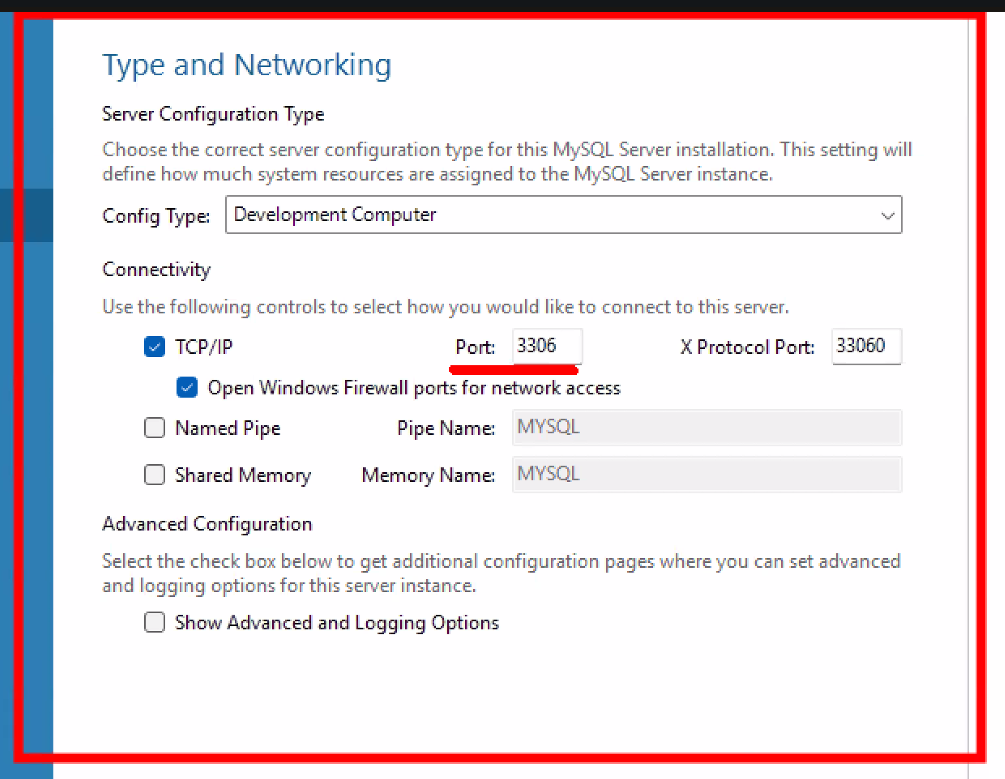
- 3306 포트: MySQL DB 서버의 포트 → DB에서 뭔가 꺼내오려면 3306 포트로 가서 꺼내오면 됨
- 포트는 같은 컴퓨터 상에서 가상의 공간을 쪼갠다는 개념임을 기억하자
- root 비밀번호 설정
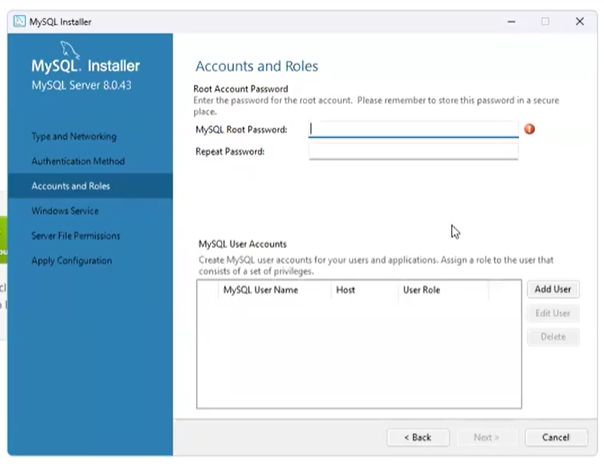
MySQL Workbench 설정
- MySQL Connections
- Local instance MySQL80
- 기본 세팅
- 기본 컴퓨터에 들어가겠다는 뜻
- 보통 이렇게 Root로 테스트용 만든 건 사용하지 않음 → 접속 정보 새로 만들기
- MySQL Connections 옆에 있는 ⊕ 버튼 눌러 접속 정보를 새롭게 만들기
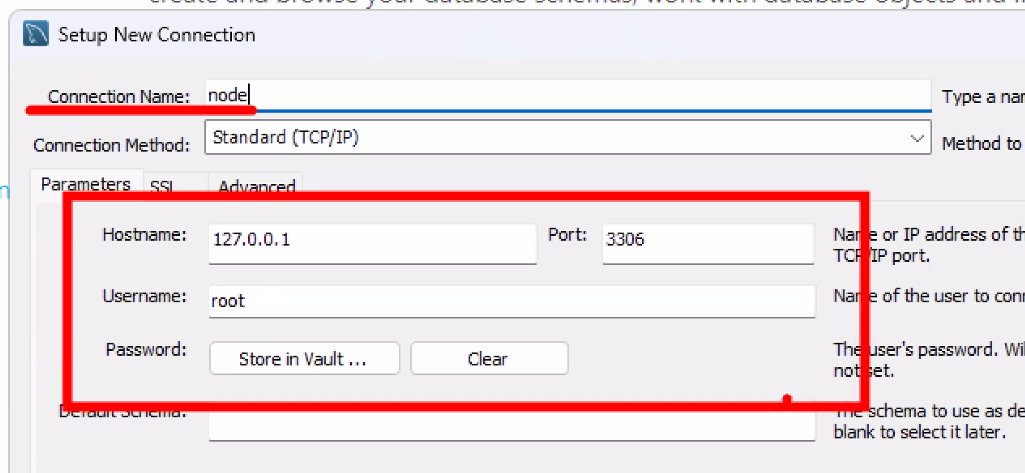
- Connection Name: node
- Store in Vault 눌러서 비밀번호 입력하고 Test Connection 해보기
- 아래처럼 뜨면 OK
- 아래처럼 뜨면 OK
- 생성한 node를 더블클릭하면 Workbench가 뜬다!
- Local instance MySQL80
3. MySQL Workbench
- 내 서버에 존재하는 DB 리스트를 조회
show databases;
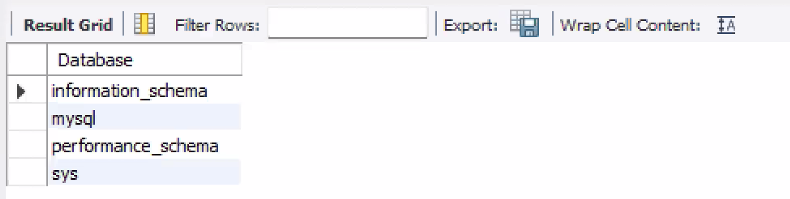
- sys는 컴퓨터에 기본적으로 설치가 되어 있는 데이터베이스
- nodejs 데이터베이스 서버 만들기
create database nodejs;

show databases;로 다시 확인
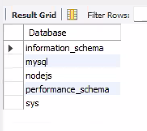
- nodejs는 아직 접속이 안 된 상태라 회색임
- 현재 상황
- nodejs는 아직 접속이 안 된 상태라 회색임
- nodejs 사용등록
use nodejs;
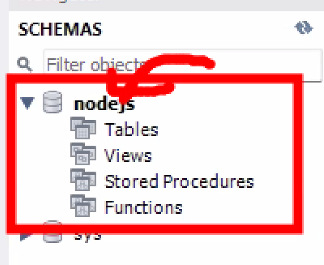
- 사용등록은 MySQL만 있는 과정임: DB를 사용하려면 사용한다는 명령어가 필요 (cf. oracle은 자동으로 됨)
- 껐다 켜면 무조건 다시 사용등록 해주고 쿼리 작성 시작해야 함
C. 3교시
1. MySQL Workbench (cont.)
테이블 만들기
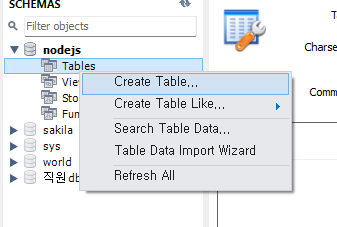
- 테이블 이름 지정
- 보통 회원 정보 관리 테이블은 member, user, user_info라는 이름을 줌
- 컬럼 추가
- id 컬럼
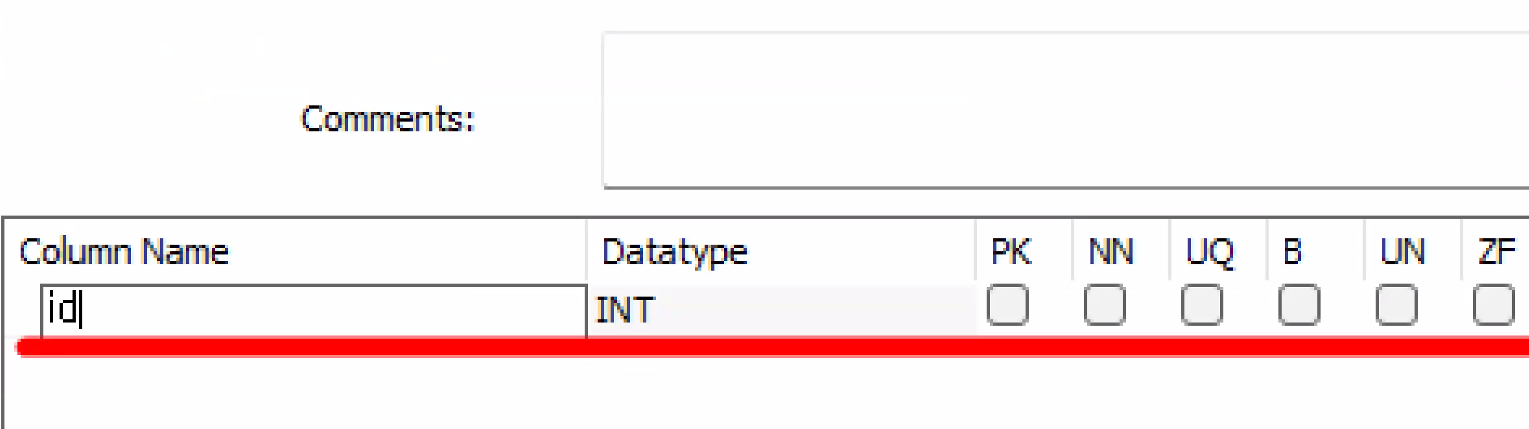
- VARCHAR(50) ← 괄호 안 커서에 숫자 입력해야 함: 크기 지정

- Apply 누르면 테이블&컬럼 생성 명령어 보여줌
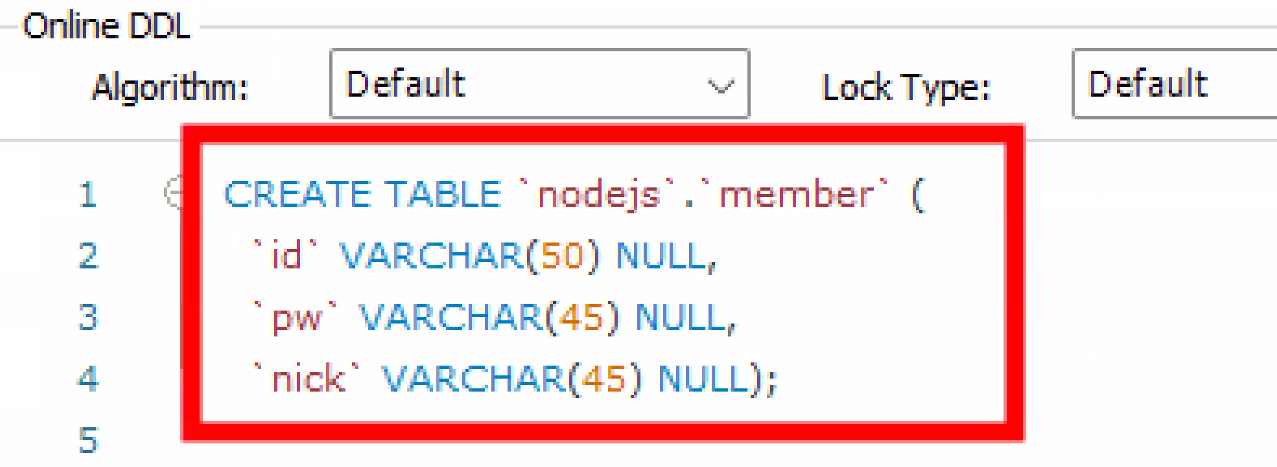
- VARCHAR(50) ← 괄호 안 커서에 숫자 입력해야 함: 크기 지정
- id 컬럼
- 테이블에서 데이터를 조회하는 방법!
select * from member;select id from member;select id,pw from member;- 데이터를 조회하면 DB는 해당 결과를 리턴!
- 리턴한 결과가 0보다 크다면 값이 있다, 그렇지 않다면 값이 없다.

- 리턴한 결과가 0보다 크다면 값이 있다, 그렇지 않다면 값이 없다.
- 배열의 특징과 연결지어 사용
- DB 정보가 배열 → 배열은 length 있음 → length가 0: 넘겨받은 데이터 없음, length가 0보다 크가: 넘겨받은 데이터 존재
- Message 잘 파악하기
- 조회 → 데이터 return
- 생성, 삽입, 수정, 삭제 → 'affected'
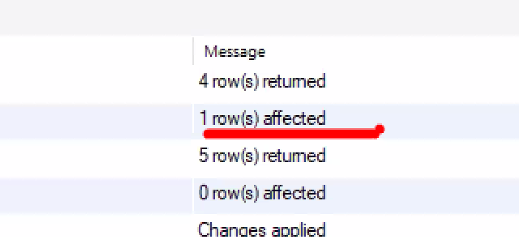
- 테이블에 값을 넣는 방법!
insert into member values ("test","1234","nickname");- 데이터를 삽입하면 DB는 영향받는 결과를 리턴!
- 리턴한 결과가 0보다 크다면 실행했다, 그렇지 않다면 실행을 못했다.
- 테이블의 값을 수정하는 방법!
- 수정 전 Edit > Preferences > SQL Editor > Safe Updates 체크박스 해제 후 Workbench 재시작

update member set nick="hello" where id="test" and pw="1234";- 껐다 켜면 무조건
use명령어 먼저 쓰기 (안 그러면 오류남)

- 수정 전 Edit > Preferences > SQL Editor > Safe Updates 체크박스 해제 후 Workbench 재시작
- 테이블의 값을 삭제하는 방법!
delete from member where id="test" and pw="1234";
Ⅱ. 오후 수업
A. 4교시
LangChain Products 알아보기
: LangChain, LangSmith, LangGraph, LangFlow
- LangChain: LLM 애플리케이션 개발을 위한 기본 프레임워크
- LLM을 활용한 애플리케이션을 보다 쉽고 체계적으로 구축하기
- GPT-4로 초안을 작성한 후, Llama 3가 이를 보완하고, 필요에 따라 외부 데이터를 가져오도록 하는 시스템을 손쉽게 구축 가능
- 주요 기능
- LLM 지원: GPT-4, Llama 3 등 다양한 LLM을 지원하며, API 키만 입력하면 바로 사용할 수 있습니다.
- 프롬프트 템플릿: 하드코딩 없이 유동적으로 프롬프트를 구성할 수 있습니다.
- 체인(Chains): 여러 작업을 연결하여 하나의 워크플로우로 실행할 수 있습니다.
- 인덱스(Indexes): 문서 로더 및 벡터 데이터베이스를 통해 외부 데이터를 활용할 수 있습니다.
- 메모리: 애플리케이션이 이전 대화 내용을 기억할 수 있도록 지원합니다.
- 에이전트(Agents): LLM을 활용해 다음 작업을 자동으로 결정할 수 있습니다.
- LangChain을 사용하면 LLM을 기반으로 한 애플리케이션을 효율적으로 구성하고 확장할 수 있음
- LangSmith: 성능 모니터링 및 평가
- 테스트 & 모니터링 → LLM 기반 애플리케이션의 성능을 관리하고 평가하는 도구
- 주요 기능
- 테스트 및 디버깅: 에이전트와 LLM 호출이 예상대로 동작하는지 확인할 수 있습니다.
- 모니터링 및 비용 분석: 토큰 사용량, API 호출 횟수, 오류 발생률 등을 추적할 수 있습니다.
- 다양한 프레임워크와 호환: LangChain과 LangGraph뿐만 아니라, 다른 LLM 프레임워크와도 함께 사용할 수 있습니다.
- AI 애플리케이션의 성능을 지속적으로 모니터링하고 최적화할 수 있음
- LangGraph: 다중 에이전트 시스템 관리
- 다중 에이전트를 활용한 복잡한 워크플로우를 관리하는 데 초점
- 여러 에이전트가 협력해야 하는 연구 도우미나 자동화된 업무 프로세스를 개발할 때 유용
- 핵심 개념
- State (상태): 애플리케이션의 현재 상태를 유지하며, 사용자 입력과 에이전트의 결과 등을 저장합니다.
- Nodes (노드): 각각의 작업을 수행하는 단위로, 특정 함수 실행, LLM 호출, 외부 도구와 상호 작용할 수 있습니다.
- Edges (엣지): 노드 간의 데이터 흐름을 정의하며, 유연한 경로 설정이 가능합니다.
- 순환적인 인터랙션(cyclical interaction)이 필요한 경우 적합하며, 여러 에이전트가 협업해야 하는 애플리케이션을 개발할 때 유용함
- LangFlow: 시각적 인터페이스를 통한 프로토타이핑
- LangChain을 기반으로 하는 비주얼 개발 도구로, 코드를 작성하지 않고도 드래그 앤 드롭 방식으로 AI 워크플로우를 구축
- 코드 없이 LLM 애플리케이션을 시각적으로 설계
- 특징
- 사용이 간편한 UI: 다양한 LLM, 데이터 처리 도구, 프롬프트 등을 연결하여 AI 워크플로우를 손쉽게 설계할 수 있습니다.
- 빠른 프로토타이핑: LangFlow는 주로 MVP(최소 기능 제품) 개발 및 프로토타이핑 용도로 사용됩니다.
- 클라우드 및 로컬 설치 지원: DataStax 같은 클라우드 서비스를 통해 사용할 수도 있고, 로컬 서버에 직접 설치할 수도 있습니다.
| 도구 | 주요 기능 | 사용 목적 |
|---|---|---|
| LangChain | LLM 기반 애플리케이션 개발 프레임워크 | LLM과 외부 데이터 연동, 프롬프트 체이닝 |
| LangGraph | 다중 에이전트 워크플로우 관리 | 복잡한 에이전트 시스템 구축 |
| LangFlow | 비주얼 노코드 개발 도구 | 빠른 프로토타이핑, AI 워크플로우 설계 |
| LangSmith | 성능 모니터링 및 평가 도구 | LLM 애플리케이션 테스트 및 디버깅 |
→ 각 도구는 서로 보완적인 역할을 하기 때문에, 개발하려는 애플리케이션의 특성에 따라 적절히 선택하여 활용하는 것이 중요
1. LangSmith
- LangChain 팀이 만든 LLM 애플리케이션 관찰 및 평가 플랫폼
- LangChain으로 프로토타입을 만들었다면, LangSmith로는 서비스 수준으로 안정적 운영을 도와줌
- 차이점
- LangChain: 만들기 도구
- LangSmith: 관리/운영 도구
- 디버깅, 모니터링 등 활용
- 공식 웹 사이트: https://smith.langchain.com/
- 구글 연동시키기
- 사용하려면 API 키 필요함
- Setting > API Keys > Create an API Key
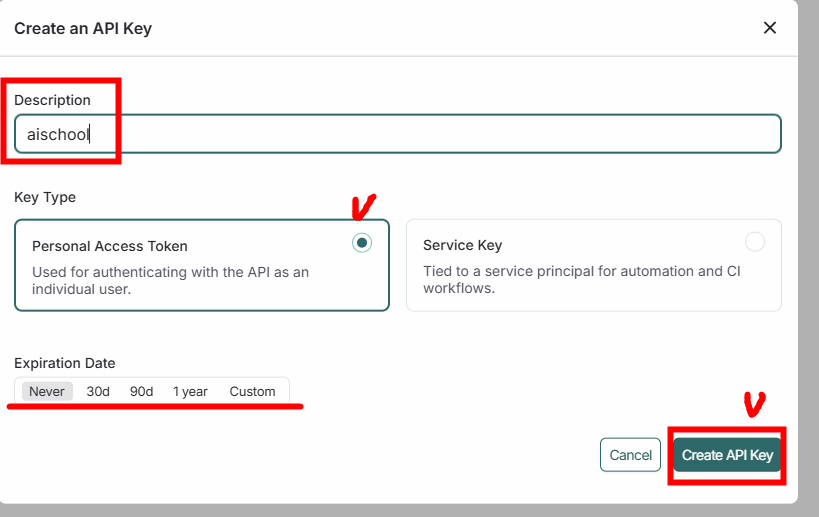
- Setting > API Keys > Create an API Key
# LangSmith API 키 읽어오기
with open("./key/.langsmith_api_key", 'r') as f:
api_key = f.read().strip()
os.environ["LANGCHAIN_API_KEY"] = api_key
# 추적 여부 ("true" → LangChain의 실행 결과가 LangSmith로 전달이 진행)
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# OpenAI API 키 읽어오기
import os
with open('./key/.openai_api_key','r') as f:
api_key = f.read().strip()
# 환경변수 설정 (딕셔너리형태)
os.environ['OPENAI_API_KEY'] = api_key
!pip install -qU openai langchain-openai langchain langchain_community
!pip install -qU langchain-teddynote huggingface_hub
!pip install -qU tiktoken pypdf pdfplumber chromadb faiss-gpu
from langchain_openai import ChatOpenAI
from langchain_teddynote import logging
# 누적할 프로젝트 이름을 작성 → '특정 프로젝트에 기록하세요'라는 의미
logging.langsmith("Project-1",set_enable=True)
llm = ChatOpenAI()
llm.invoke("Hello world!")LangSmith 추적을 시작합니다.
[프로젝트명]
Project-1
AIMessage(content='Hello there! How can I assist you today?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 10, 'total_tokens': 20, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'id': 'chatcmpl-CDNuNXVStd4UTz3n3zg8uTGJIFoG2', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='run--fa885dc8-cb11-4ab3-9611-a7811cf15313-0', usage_metadata={'input_tokens': 10, 'output_tokens': 10, 'total_tokens': 20, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})LangSmith를 통한 추적 및 확인
- tracing vs. tracking
- tracing
- 글자나 그림을 그리는 것과 같이 길이나 선을 따라가는 행위를 설명합니다.
- 그 기원이나 역사를 찾기 위해 무언가를 조사하거나 연구하는 과정을 말합니다.
- 윤곽이나 모양을 따라 무언가를 복사하거나 복제하는 행위에 대해 이야기합니다.
- tracking
- 무언가 또는 누군가의 움직임이나 진행 상황을 추적하거나 모니터링하는 행위를 말합니다.
- 시간 경과에 따른 데이터 또는 정보를 기록하거나 추적하는 프로세스를 설명합니다.
- 특정 목표나 목표에 맞게 조정하거나 정렬하는 행위에 대해 이야기합니다.
- 초점: Tracing는 경로나 선을 따라가는 데 초점을 맞추고 tracking는 움직임이나 진행 상황을 모니터링하는 데 중점을 둡니다.
- 목적: Tracing는 종종 무언가를 복사하거나 복제하는 데 사용되는 반면 tracking는 데이터를 기록하거나 분석하는 데 사용됩니다.
- tracing
- 세부 추적(Tracing)
- 'LLM' 실행의 블랙박스를 열어서 모든 과정을 기록, 확인, 분석하는 과정
- 깊은 실행 기록 (cf. tracking: 단순 이벤트 카운팅 등에 사용)
- LangSmith의 API 키를 설정하면 대시보드에서 실행 로그를 확인할 수 있음
- 서비스 배포 시 사용자가 사용한 내용 및 내역에 대해 확인할 수 있음
- 추적할 프로젝트명
logging.langsmith("특정 프로젝트명",set_enable=True)- '특정 프로젝트명에 기록하세요'라는 의미
- 새로운 이름을 쓰면 새로운 프로젝트가 생성됨? → 안 되는데요😭
- 세션 재시작해야 함
os.environ["LANGCHAIN_PROJECT"] = "Project-2"
- LangSmith에서 프로젝트 추적 내용 확인 가능
- project-1 누르면 세부 내용도 볼 수 있음
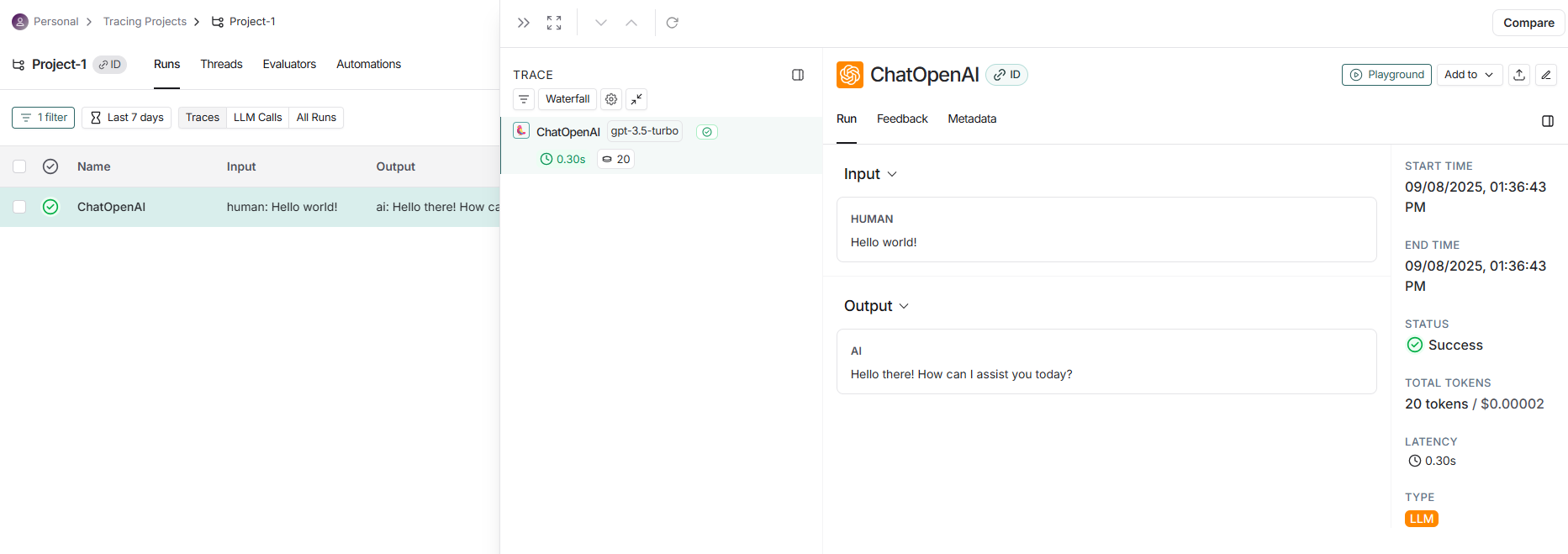
- project-1 누르면 세부 내용도 볼 수 있음
- LangSmith에 신규 프로젝트를 등록하려면 세션을 다시 시작하고 실행하기!
from langchain.prompts.chat import ChatPromptTemplate
# 누적할 프로젝트 이름을 작성 → 새로운 이름을 쓰면 새로운 프로젝트가 생성됨
# 주의 → 새로운 프로젝트에 누적을 위하여 세션 재시작 필요!
logging.langsmith("Project-2",set_enable=True)
# os.environ["LANGCHAIN_PROJECT"] = "Project-2"
template = """너는 쉼표로 구분된 목록을 생성하는 유용한 조수이다.
사용자가 카테고리를 전달하면 해당 카테고리에 쉼표로 구분된 목록으로 5개의 개체를 생성해야 한다.
쉼표로 구분된 목록만 반환하며 그 이상은 반환하지 않는다."""
prompt = ChatPromptTemplate.from_messages([
("system", template)
, ("human", "{text}")
])
chain = prompt | llm
chain.invoke("비유클리드 기하학의 특징")LangSmith 추적을 시작합니다.
[프로젝트명]
Project-2
AIMessage(content='1. 평행선이 없다\n2. 평행선 위의 점을 포함하지 않는 점을 지나는 직선은 한 개이다\n3. 각도의 합이 180도가 아닌 삼각형들이 있다\n4. 원의 중심이 중앙이 아닌 삼각형들이 있다\n5. 직선이 무한대로 뻗어간다', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 118, 'prompt_tokens': 132, 'total_tokens': 250, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'id': 'chatcmpl-CDOLXfny6fZ2FgLGM9vJ6LTTxDKL7', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='run--2a273eff-b430-4e23-9d49-86e6d09bef11-0', usage_metadata={'input_tokens': 132, 'output_tokens': 118, 'total_tokens': 250, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})B. 5교시
1. LangChain 평가 지표
LLM 평가
- 인공지능 언어모델의 성능, 정확성, 일관성 등 중요한 측면을 측정하고 분석하는 과정
- 모델의 개선, 비교, 선택 및 응용 과정에서 적합한 모델 결정에 필수적인 단계
AI 환각 문제점의 심각성
- 왜 언어 모델은 환각을 발생시킬까? ★★★
- LLM 평가의 중요성 대두
- 모델 개선: 약점을 식별하고 개선 방향을 제시
- 신뢰성 확보: 모델의 성능화 한계를 이해하는 데 도움
- 적합한 모델을 선택: 특정 직업에 가장 적합한 모델을 선택
- LLM 평가 방법
- 자동화된 메트릭
- 인간 평가
- 전문가나 아웃소싱을 통한 직접 평가
- LLM-as-Judge
- 다른 LLM을 평가자로 사용하는 방법 → BERTScore
- LLM 성능평가를 위한 지표들
📘 LLM 생성 평가 지표 비교표
| 지표 | 특징 | 장점 | 단점 | 점수 범위 | 해석 | 좋은 점수 기준 | 주의사항 |
|---|---|---|---|---|---|---|---|
| BLEU | 기계 번역 평가용, n-그램 일치율 기반 | 계산 간단, 전통적으로 많이 사용 | 의미 같아도 표현 다르면 낮음 | 0 ~ 1 | 참조와 단어 수준 유사도 | ≥ 0.5: 꽤 유사, ≥ 0.7: 매우 유사 | 어휘 다양성 높은 경우 과소평가 가능 |
| ROUGE | 요약 평가에 특화, n-그램/구절/최장 공통 부분 수열 | 요약 핵심어 커버 잘 측정 | 단어 겹침 위주, 의미는 반영 약함 | 0 ~ 1 | 참조 요약과 단어·구절 겹침 정도 | ≥ 0.5: 주요 내용 커버, ≥ 0.7: 매우 좋음 | 의미 다르더라도 단어 겹치면 점수 높을 수 있음 |
| METEOR | BLEU 보완, 동의어·어간·형태 고려 | 인간 평가와 상관도 높음 | 계산 복잡, 언어 자원 필요 | 0 ~ 1 | 참조와 어휘적·의미적 유사도 | ≥ 0.6~0.7: 꽤 좋은 결과 | 지원 언어 한정, 속도 느릴 수 있음 |
| SemScore | 임베딩 기반 의미 유사도 | 표현 달라도 의미 같으면 높음 | 임베딩 모델 품질에 의존 | -1 ~ 1 (보통 0~1) | 의미적 유사도 (코사인 유사도) | ≥ 0.7: 유사, ≥ 0.85: 거의 동일 | 모델 성능·도메인에 따라 점수 신뢰도 달라짐 |
→ 언어 자원 필요: 동의어 사전 등
다양한 평가 지표를 사용하여 평가하는 것이 가장 좋음!
2. ROUGE
- 자동 요약이나 기계 번역의 품질을 평가하는 데 사용되는 지표
- 생성된 텍스트가 참조 텍스트의 중요 키워드를 얼마나 포함하는지에 대한 측정을 진행
- n-gram 중첩 기반으로 계산
- ROUGE-N: n그램 단어 겹침
- ROUGE-L: LCS(최장 공통 수열; Longest Common Subsequence) → 두 시퀀스 간에 "순서"를 유지한 채 공통으로 나타내는 부분 중 가장 긴 것 → LCS 길이가 길수록 두 문서 간의 유사도가 높다고 평가한다.
- 좋은 점수 기준
- ROUGE-L ≈ 0.5 이상 → 참조 요약의 핵심 단어를 절반 이상 커버
- ROUGE ≈ 0.7 이상 → 매우 높은 커버리지
- 주의: 단어 겹침 위주라 의미가 달라도 점수가 높을 수 있음
!pip install -qU openai langchain-openai langchain langchain_community
!pip install -qU langchain-teddynote huggingface_hub
!pip install -qU tiktoken pypdf pdfplumber chromadb faiss-gpu
!pip install -q rouge_score
sent1 = "안녕하세요. 반갑습니다. 내 이름은 최영화입니다."
sent2 = "안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!"
sent3 = "내 이름은 최영화입니다. 안녕하세요. 반갑습니다."
# 토큰화 → 토크나이저
# 주의: 단순 Kiwi 토크나이저를 사용했을 때 현재 평가지표에 바로 사용하기는 어렵다 → TeddyNote KiwiTokenizer 사용!
# TeddyNote KiwiTokenizer: 평가 라이브러리에 바로 쓸 수 있도록 토크나이저 형태를 맞춰놓음
from langchain_teddynote.community.kiwi_tokenizer import KiwiTokenizer
from rouge_score import rouge_scorer
# 토크나이저 객체 생성
tokenizer = KiwiTokenizer()
# ROUGE 스코어
# rouge_scorer.RougeScorer(# 평가지표 종류, 토크나이저)
scorer = rouge_scorer.RougeScorer(
rouge_types=["rouge1", "rouge2", "rougeL"] # 평가지표 종류
, tokenizer=tokenizer # 토크나이저
, use_stemmer=False
)📘 ROUGE 지표별 특성 요약표
| 지표 | 기준 | 민감한 요소 | 잘 잡아내는 차이 | 약점 |
|---|---|---|---|---|
| ROUGE-1 | 단어 단위(n=1) 겹침 | 단어 존재 여부 | 어휘가 얼마나 겹치는지 | 순서 무시 → 단어만 같으면 1.0 |
| ROUGE-2 | 연속된 두 단어(n=2) 겹침 | 단어 순서와 연속성 | 어휘가 같아도 문맥(연속성) 차이 감지 | 표현 조금만 달라져도 점수 크게 하락 |
| ROUGE-L | 최장 공통 부분 수열(LCS) | 전체 문장 구조·어순 | 단어 배열·문장 구조 유사성 | 단어 같아도 순서 다르면 점수 낮음 |
# sent1과 sent2의 비교
print(f"[sent1] {sent1}\n[sent2] {sent2} \
\n[rouge1] {scorer.score(sent1, sent2)['rouge1'].fmeasure:.5f} \
\n[rouge2] {scorer.score(sent1, sent2)['rouge2'].fmeasure:.5f} \
\n[rougeL] {scorer.score(sent1, sent2)['rougeL'].fmeasure:.5f}")
print("===" * 20)
# sent1과 sent3의 비교
print(f"[sent1] {sent1}\n[sent3] {sent3} \
\n[rouge1] {scorer.score(sent1, sent3)['rouge1'].fmeasure:.5f} \
\n[rouge2] {scorer.score(sent1, sent3)['rouge2'].fmeasure:.5f} \
\n[rougeL] {scorer.score(sent1, sent3)['rougeL'].fmeasure:.5f}")[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent2] 안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!
[rouge1] 0.78788
[rouge2] 0.64516
[rougeL] 0.78788
============================================================
[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent3] 내 이름은 최영화입니다. 안녕하세요. 반갑습니다.
[rouge1] 1.00000
[rouge2] 0.93333
[rougeL] 0.56250📘 ROUGE 지표별 해석 비교표
| 비교 | ROUGE-1 (단어 단위 겹침) | ROUGE-2 (연속 단어 겹침) | ROUGE-L (최장 공통 부분 수열) | 종합 해석 |
|---|---|---|---|---|
| sent1 vs sent2 안녕하세요 vs 안녕하세용, 특수문자 차이 | 0.79 → 대부분 단어 같음 | 0.65 → 어휘 일부 변형으로 연속성 깨짐 | 0.79 → 문장 구조는 비슷 | 표현은 유사하지만 표기·특수문자 차이로 완벽하지 않음 |
| sent1 vs sent3 단어 동일, 순서만 다름 | 1.00 → 단어 100% 동일 | 0.93 → 대부분 연속 단어 동일, 순서 차이로 약간 감점 | 0.56 → 순서 크게 달라 공통 부분 수열 짧음 | 단어는 같지만 구조(순서) 차이 큼 |
C. 6교시
1. BLEU 지표
- 기계 번역 평가에서 사용
- 생성된 텍스트가 참조 텍스트와 얼마나 유사한지를 측정
- n-gram 정밀도를 기반으로 계산
- 범위: 0 ~ 1 (보통 %로 0~100)
- 해석: 값이 높을수록 생성 텍스트가 참조 텍스트와 단어 단위에서 비슷하다는 뜻
- 좋은 점수 기준:
- BLEU ≈ 0.3 이하 → 참조와 크게 다름
- BLEU ≈ 0.5 이상 → 꽤 유사
- BLEU ≈ 0.7~0.8 이상 → 매우 유사 (거의 똑같음)
- 주의: 의미가 같아도 표현 방식이 다르면 낮게 나올 수 있음
- 예: “자동차” vs “승용차”
from nltk.translate.bleu_score import sentence_bleu
sent1 = "안녕하세요. 반갑습니다. 내 이름은 최영화입니다."
sent2 = "안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!"
sent3 = "내 이름은 최영화입니다. 안녕하세요. 반갑습니다."
# sent1과 sent2의 비교
bleu_score = sentence_bleu(
[tokenizer.tokenize(sent1, type="sentence")],
tokenizer.tokenize(sent2, type="sentence")
)
print(f"[sent1] {sent1}\n[sent2] {sent2}\n[score] {bleu_score:.5f}")
print("===" * 20)
# sent1과 sent3의 비교
bleu_score = sentence_bleu(
[tokenizer.tokenize(sent1, type="sentence")],
tokenizer.tokenize(sent3, type="sentence")
)
print(f"[sent1] {sent1}\n[sent3] {sent3}\n[score] {bleu_score:.5f}")[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent2] 안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!
[score] 0.76087
============================================================
[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent3] 내 이름은 최영화입니다. 안녕하세요. 반갑습니다.
[score] 0.95969해석 요약
- 0.7 - 0.8: 단어는 비슷하지만 표현/형태가 조금 다른 경우
- 0.95 ~: 거의 동일. 순서 차이 정도만 있는 경우
- 특징
- BLEU 지표는 순서 차이에는 덜 민감
- sent2: 표현 차이(~용, 특수 문자)로 유사도가 낮게 나옴
- sent3: 순서만 다르기 때문에 거의 완벽 유사도로 평가
- BLEU 지표는 순서 차이에는 덜 민감
2. METEOR[ˈmiːtiər] 지표
- BLEU 와 유사하지만, 동의어·어간·형태변화까지 고려
- 좋은 점수 기준:
- 일반적으로 BLEU보다 높은 값을 줌
- 0.6~0.7 이상이면 사람이 보기에도 꽤 좋은 결과
- 장점: 인간 평가와 상관도가 높음
- 주의: 계산이 느리고 언어 자원(사전 등)에 의존
# 언어자원 제공
# METEOR 평가 지표는 동의어, 어간 매칭 지원 → 언어사전이 필요하다~
import nltk
from nltk.corpus import wordnet as wn
nltk.download("wordnet")
wn.ensure_loaded()
# 단어사전을 활용하여, 동의어, 어간, 형태소변화(run vs running) 등을 매칭
from langchain_teddynote.community.kiwi_tokenizer import KiwiTokenizer
from nltk.translate import meteor_score
kiwi_tokenizer = KiwiTokenizer()
sent1 = "안녕하세요. 반갑습니다. 내 이름은 최영화입니다."
sent2 = "안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!"
sent3 = "내 이름은 최영화입니다. 안녕하세요. 반갑습니다."
# meteor_score 함수 안에서 자동으로 WordNet을 활용
meteor = meteor_score.meteor_score(
[kiwi_tokenizer.tokenize(sent1, type="list")],
kiwi_tokenizer.tokenize(sent2, type="list"),
)
print(f"[sent1] {sent1}\n[sent2] {sent2}\n[score] {meteor:.5f}")
print("===" * 20)
meteor = meteor_score.meteor_score(
[kiwi_tokenizer.tokenize(sent1, type="list")],
kiwi_tokenizer.tokenize(sent3, type="list"),
)
print(f"[sent1] {sent1}\n[sent3] {sent3}\n[score] {meteor:.5f}")[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent2] 안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!
[score] 0.80249
============================================================
[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent3] 내 이름은 최영화입니다. 안녕하세요. 반갑습니다.
[score] 0.97363정리
- METEOR는 표현이 달라도 의미가 같으면 높은 점수를 출력
- BLEU의 보완 평가 지표
3. SemScore
- 의미적 유사도를 파악하여 비교
- Semantic Textual Similarity
- 의미론적 텍스트 유사성(STS)을 사용하여 모델 출력을 황금 표준 응답과 직접 비교
- Semantic Textual Similarity
- 문장 임베딩을 생성하고 두 문장 간의 코사인 유사도를 계산
- 인간 평가와 관련하여 다른 지표보다 우수한 성능
- 범위: -1 ~ 1 (보통 0~1 구간 해석)
- 해석: 두 텍스트의 의미적 유사도를 임베딩 벡터 코사인 유사도로 계산
- 좋은 점수 기준:
- 0.7 이상 → 의미적으로 꽤 유사
- 0.85 이상 → 거의 같은 의미
- 0.9 이상 → 의미적으로 완전히 동일
- 장점: 표현은 달라도 의미가 같으면 높은 점수
- 주의: 임베딩 모델 품질에 따라 결과가 달라질 수 있음
# SentenceTransformer: 사전학습된 문장 임베딩 모델 로드용
# util: 코사인 유사도 계산 같은 유틸 함수 제공
from sentence_transformers import SentenceTransformer, util
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
sent1 = "안녕하세요. 반갑습니다. 내 이름은 최영화입니다."
sent2 = "안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!"
sent3 = "내 이름은 최영화입니다. 안녕하세요. 반갑습니다."
# 임베딩 모델 불러와서 사용하기 → huggingface에서 제공하는 모델 로드
model = SentenceTransformer("all-mpnet-base-v2") # all-mpnet-base-v2: 다국어 지원하는 임베딩 모델
# 문장 인코딩 / PyTorch 텐서 형태로 변환.
sent1_encoded = model.encode(sent1, convert_to_tensor=True)
sent2_encoded = model.encode(sent2, convert_to_tensor=True)
sent3_encoded = model.encode(sent3, convert_to_tensor=True)
# sent1과 sent2 사이의 코사인 유사도 계산
cosine_similarity = util.pytorch_cos_sim(sent1_encoded, sent2_encoded).item()
print(f"[sent1] {sent1}\n[sent2] {sent2}\n[score] {cosine_similarity:.5f}")
print("===" * 20)
# sent1과 sent3 사이의 코사인 유사도 계산
cosine_similarity = util.pytorch_cos_sim(sent1_encoded, sent3_encoded).item() # .item() → 파이토치 텐서를 파이썬 숫자로 변환
print(f"[sent1] {sent1}\n[sent3] {sent3}\n[score] {cosine_similarity:.5f}")[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent2] 안녕하세용 반갑습니다~^^ 내 이름은 최영화입니다!!
[score] 0.87863
============================================================
[sent1] 안녕하세요. 반갑습니다. 내 이름은 최영화입니다.
[sent3] 내 이름은 최영화입니다. 안녕하세요. 반갑습니다.
[score] 0.98596정리
- SemScore는 표현의 차이가 있어도 의미적으로 동일하면 높은 점수를 출력
- 단어가 동일하고 순서만 바뀜 두 번째의 경우 거의 완벽한 유사도를 출력
Ⅲ. CAREER UP
정보보호교육
코드 생성 AI를 이용한 웹 취약점 점검 방법
《목차》
1. 클라이언트 통신 방식
2. 웹 통신 구조(HTTP Packet Message)
3. 주요 취약점 진단 항목
4. AI의 확산과 보안의 변화
5. AI 악용에 따른 보안 위협
6. AI와 보안 전문가 협업: 적용사례 & 기대효과
7. 실습
7-1. 취약점 진단 도구 활용: BurpSuite
7-2. 취약점 진단 도구 활용: Fiddler
7-3. ChatGPT를 활용한 SQLi 공격 시도 과정
8. Q&A- 클라이언트 통신 방식
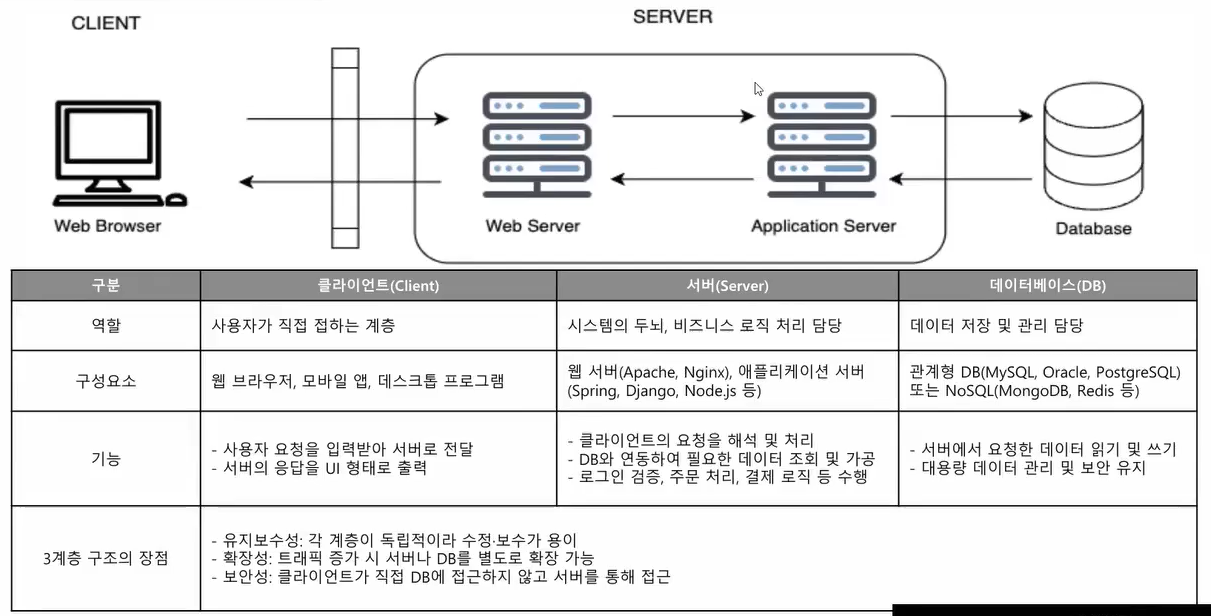
- 3계층(Three-Tier) 계층형 네트워크 아키텍처
- 웹 진단(모의해킹) / SecureCoding
- 통신 방식을 이해해야 진행 가능
- 웹 통신 구조(HTTP Packet Message)
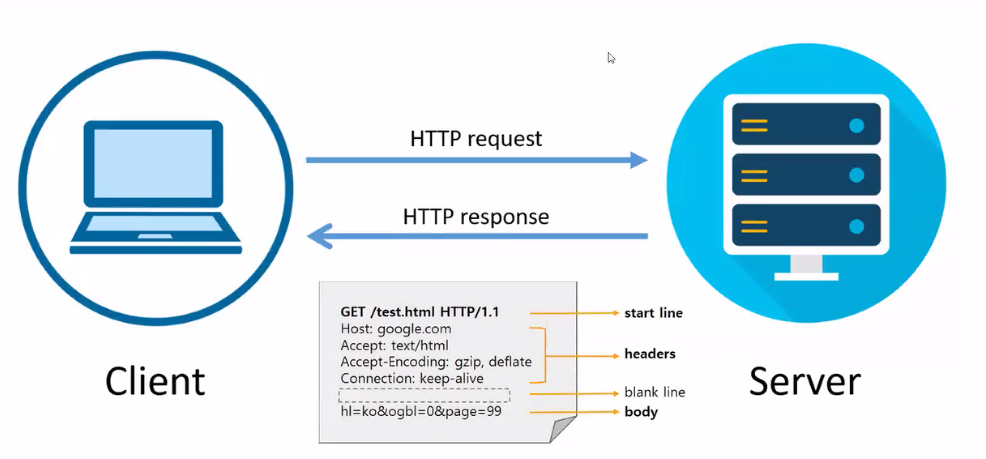
- HTTP → 통신 규약
- protocol: 규약/규칙 → 지키지 않으면 문제 발생
- DDOS 공격은 규약을 침해한 통신을 계속 보내는 것 → 무한 대기
- 개념 정리
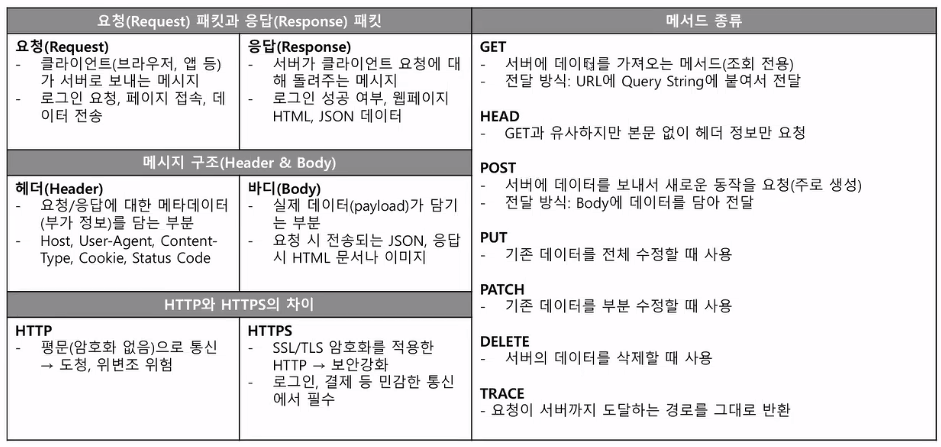
- 웹 진단 → 요청 패킷 또는 응답 패킷 둘 중 하나를 변조 또는 클라이언트가 받은 정보를 변조
- 앞에서 소개한 예제는 사실 잘못된 부분이 있음: get 통신인데 body에 정보를 담고 있음
- 예시: request
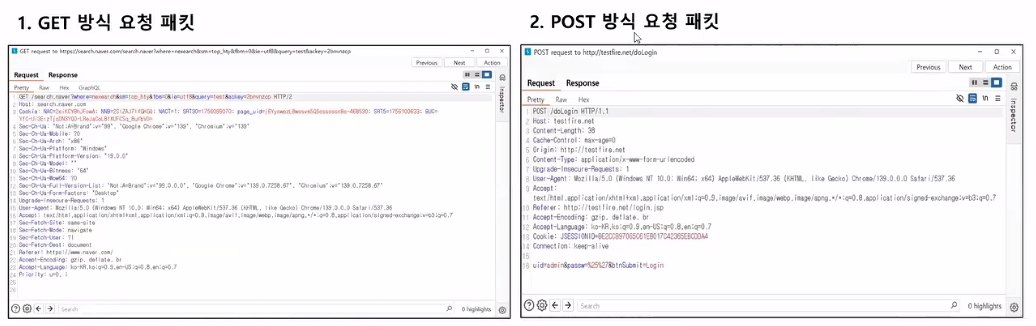
- 예시: response
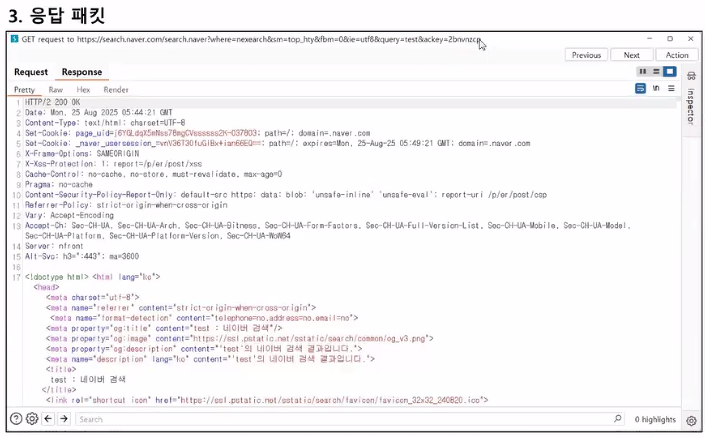
- HTTP → 통신 규약
- 주요 취약점 진단 항목
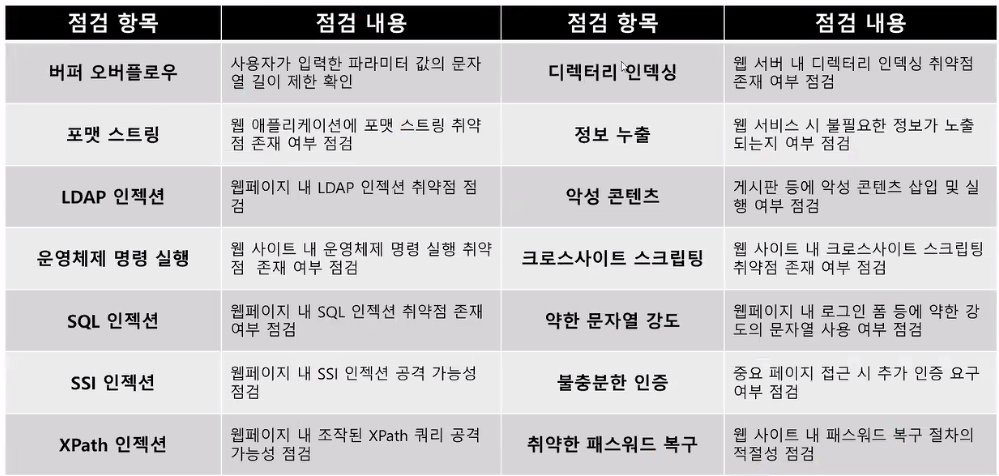
- 국가에서 매년 가이드라인이 내려옴
- KISA '주요정보통신기반시설 기술적 취약점 분석ㆍ평가 방법'
- 올해 계정 예정이라 새로 나오는 거 공부하면 좋다고 함
- 전자금융권
- KISA '주요정보통신기반시설 기술적 취약점 분석ㆍ평가 방법'
- fsb
- c언어 printf
- LDAP
- 쿼리
- 옛날에 구축된 거라 요즘은 잘 안 나옴
- 운영체제 명령 실행
- 웹 서버가 운영되는 운영체제의 명령어를 넣어버리는 것
- 가장 크리티컬한 공격 중 하나
- SQL 인젝션
- 이것도 운영체제 명령까지 할 수 있어서 매우 위험
- SSI, XPath → 요즘 개발하는 언어에서는 잘 안 나옴
- 디렉터리 인덱싱
- 자주 나오는 취약점
- 크로스사이트 스크립팅
- 이것도 자주 나옴
- 크로스사이트 스트립팅
- 자바스크립트 파일을 넣어 실행하게 만듦
- 국가에서 매년 가이드라인이 내려옴
- 웹 브라우저
- HTML 받아서 렌더링
- CSS, JS
- 주요 취약점 진단 항목 (2)
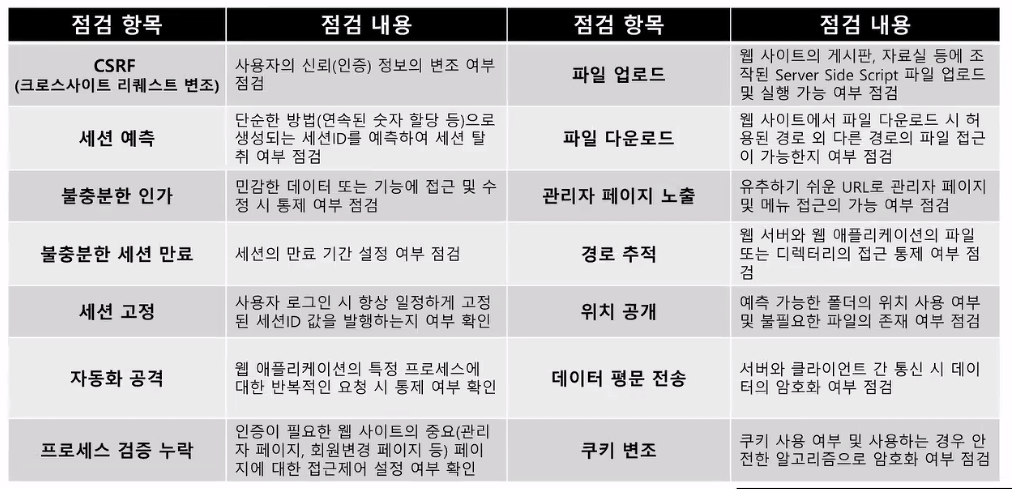
- CSRF(크로스사이트 리퀘스트 변조)
- 크로스사이트 스크립팅과 다름!
- 파일 다운로드
- linux 시스템 정보 등을 다운로드해 특정 데이터를 탈취
- CSRF(크로스사이트 리퀘스트 변조)
- AI의 확산과 보안의 변화

- AI 악용에 따른 보안 위협

- 제로트러스트
- 제로 트러스트는 "절대 신뢰하지 말고, 항상 확인하라(Never Trust, Always Verify)"는 원칙에 기반한 보안 모델로, 네트워크 경계와 관계없이 모든 사용자, 기기, 애플리케이션을 신뢰할 수 없는 대상으로 간주하고, 리소스 접근 시마다 엄격한 신원 확인과 지속적인 검증을 통해 보안을 강화합니다. 기존의 경계 보안 모델이 네트워크 내부는 신뢰할 수 있다고 가정하는 것과 달리, 제로 트러스트는 네트워크 내부의 위협까지 고려하며, 세분화된 정책과 지속적인 모니터링을 통해 데이터를 보호하고 사이버 공격을 방지합니다.
- 제로트러스트
- AI와 보안 전문가 협업: 적용 사례 & 기대 효과

- IPS(침입 방지 시스템)
- SecureCoding log 분류를 AI가 분석 → 관리 자동화
실습: Burp Suite
-
취약점 진단 도구 활용: Burp Suite
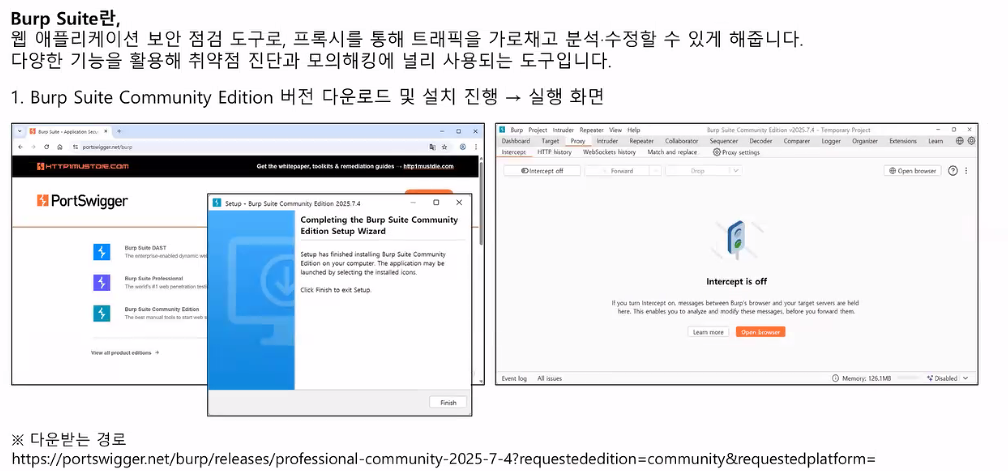
-
web proxy 도구
- proxy: 대리; 중계
- 최종 사용자나 컴퓨터와 서버 사이에 위치하여 통신을 대신 수행하는 중개 서버 또는 중개 역할을 의미합니다.
- proxy server
- 용자는 직접 서버에 접속하는 대신 프록시 서버를 통해 간접적으로 접속하며, 프록시 서버는 사용자의 IP 주소를 숨겨 보안을 강화하거나, 웹 콘텐츠를 캐싱하여 로딩 속도를 높이고 서버의 부하를 줄이는 등의 다양한 용도로 활용됩니다.
- web proxy: 웹 패킷 중계
- proxy: 대리; 중계

- cf. 피들러 Fiddler
- HTTP와 HTTPS의 프로토콜을 캡처하고 분석할 수 있는 웹디버깅 툴
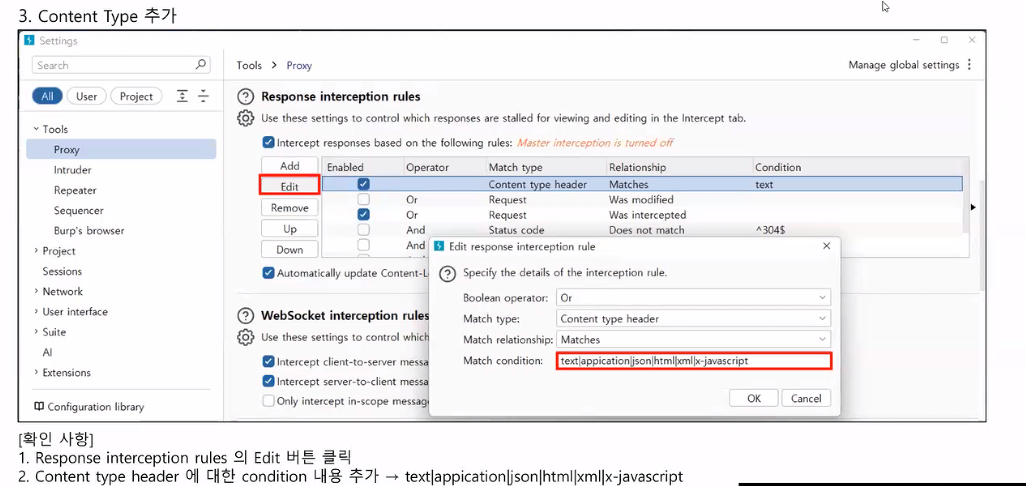
- HTTP와 HTTPS의 프로토콜을 캡처하고 분석할 수 있는 웹디버깅 툴
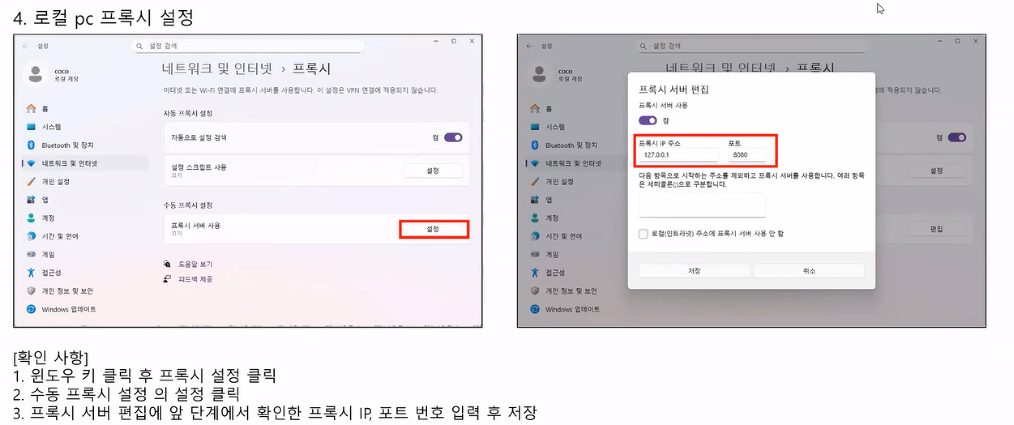
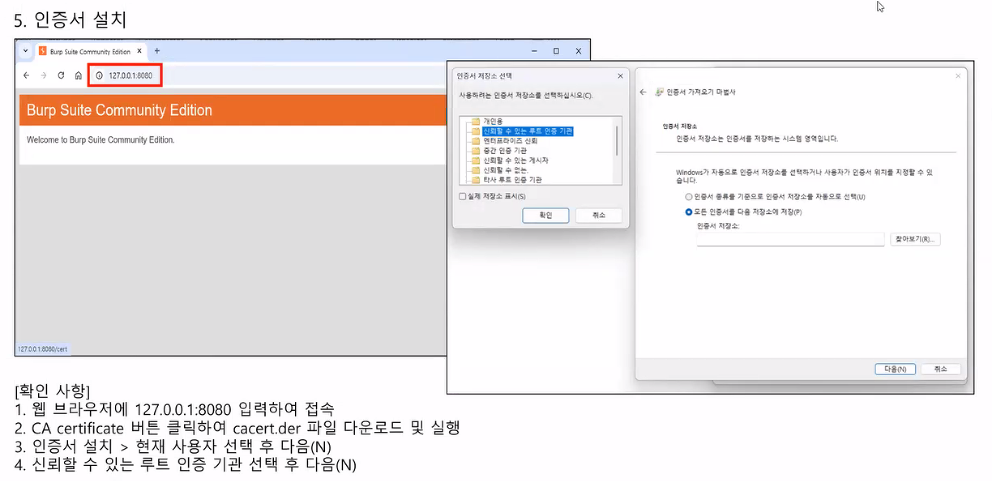
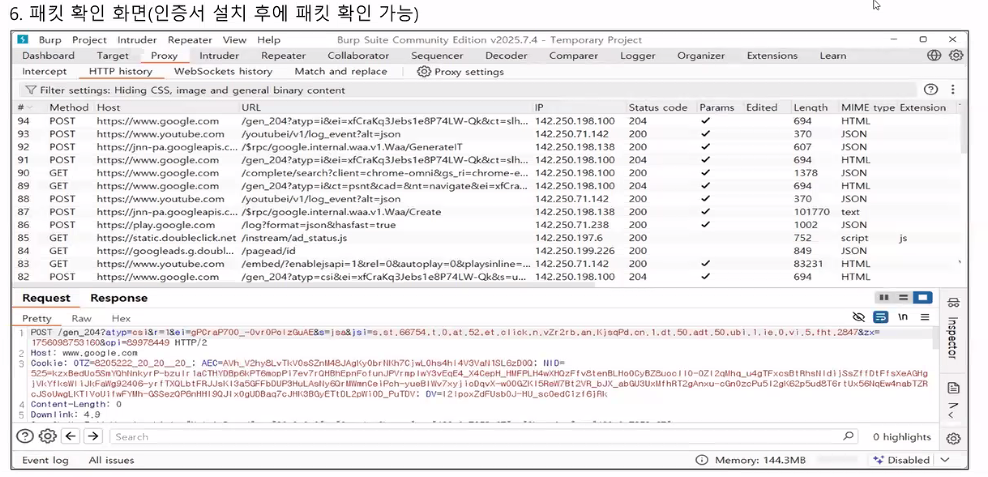
- Scope 기능
- community는 기능 사용 제한 있음
- intruder 기능
- community는 기능 사용 제한 있음 (속도 제한)
- 실제로 하고 싶으면 유료 구매 or Python 코드 짜기
실습: Fiddler
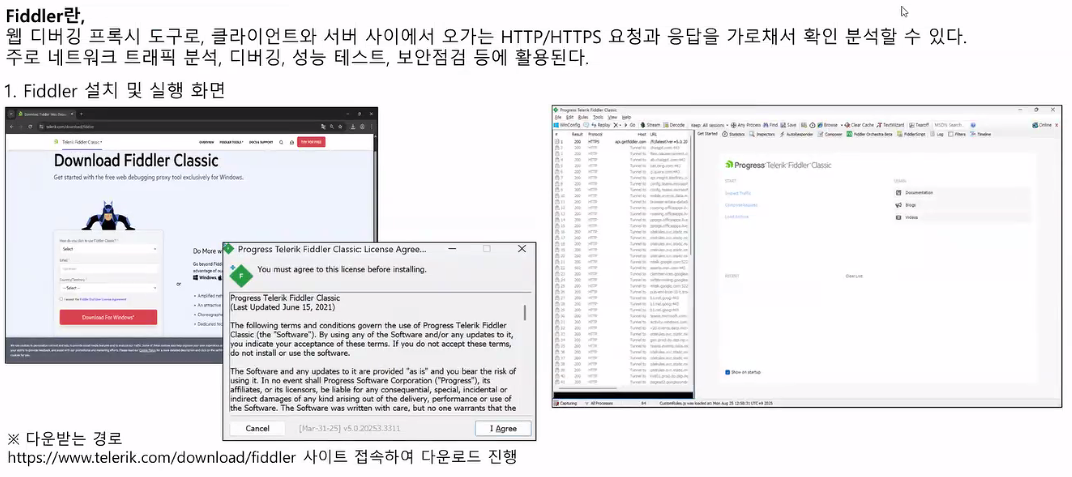
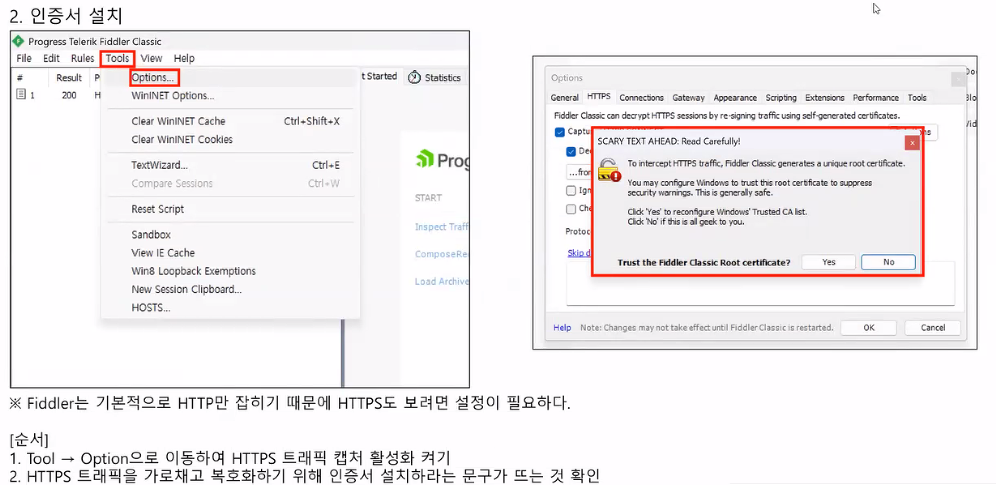
- 주요정보통신기반시설 기술적 취약점 분석ㆍ평가 방법 상세가이드
- KISA에서도 받을 수 있음
- 인프라 진단 (1~7)도 매우 중요하니 공부하면 좋음
-
https://www.kisa.or.kr/2060207에서 다른 내용도 살펴보는 걸 추천
- KISA에서도 받을 수 있음
-
Chrome 확장 프로그램 설치
- SwitchyOmega 3 (ZeroOmega)
- EditThisCookie (V3)
- modheader
- 두 가지 설정 진행
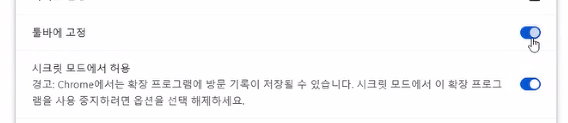
- SwitchyOmega 3 (ZeroOmega)
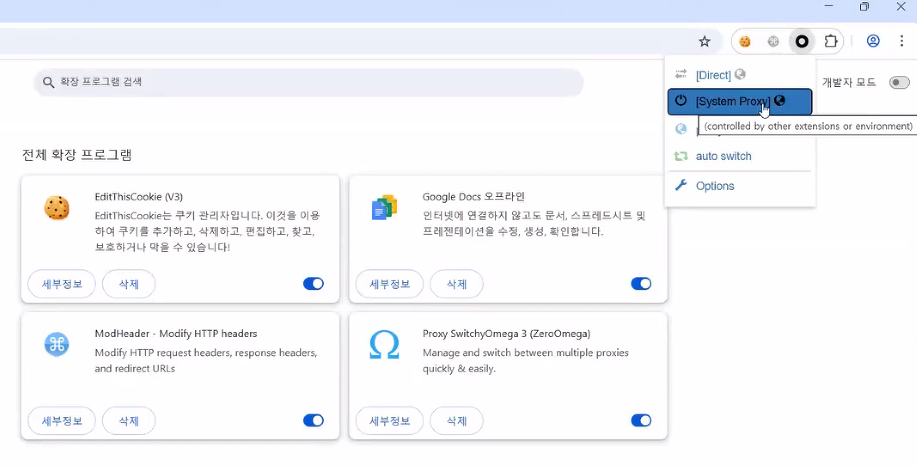
-
ProxyOmega 추가 설정
- new profile > 아래와 같이 설정 후 apply changes
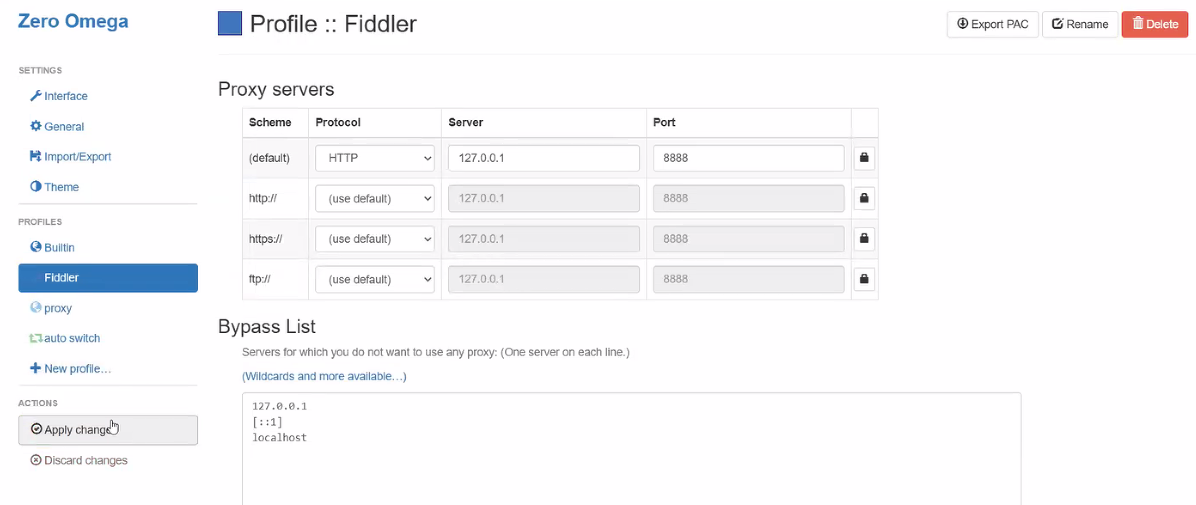
- new profile > 아래와 같이 설정 후 apply changes

2 B R 0 2 B