딥러닝
- 학습목표: 딥러닝의 원리와 아키텍쳐에 대해 알아보기
개요
2022년 12월 ChatGPT가 등장한 이래로 딥러닝에 대한 관심에 더욱 가속화 되었어요.
도대체 딥러닝이 뭐길래 그렇게 온 세상을 바꿀 것처럼 이야기할까요?
머신러닝에서 배운 기본을 바탕으로 딥러닝에 대해서 알아 봅시다.
이론
머신러닝 vs. 딥러닝
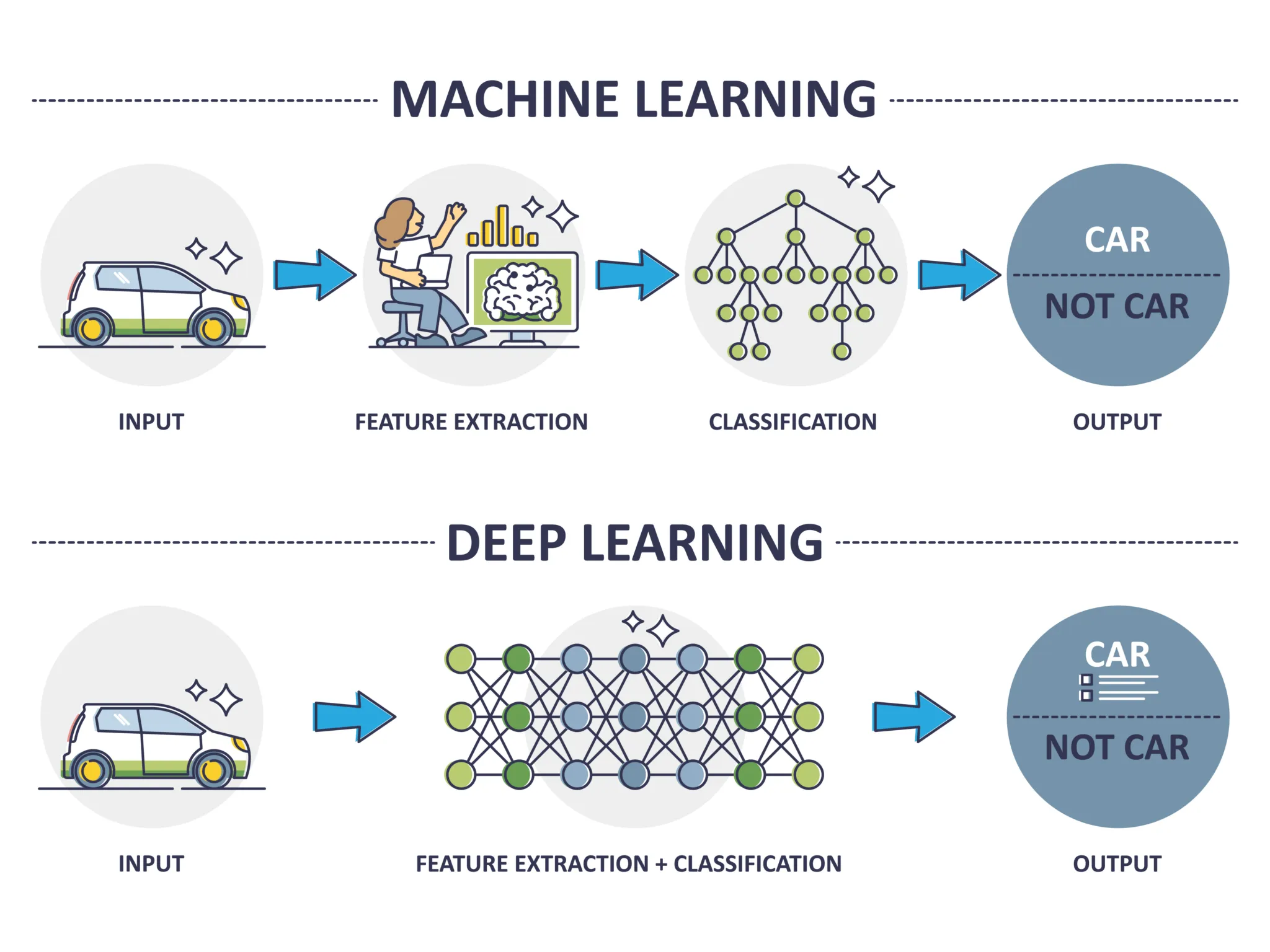
머신러닝과 딥러닝은 내부 구조와 활용범위가 다를 뿐 기본적인 흐름은 같습니다.
다만 딥러닝은 자연어 처리와 이미지 처리에 뛰어난 발전을 이뤘어요.
본 강의에서는 기존 회귀, 분류 문제를 딥러닝 아키텍처로 만들어볼 예정입니다.
- 공통점
- 데이터로부터 가중치를 학습하여 패턴을 인식하고 결정을 내리는 알고리즘 개발과 관련된 인공지능(AI)의 하위 분야
- 차이점
- 머신러닝
- 데이터 안의 통계적 관계를 찾아내며 예측이나 부류를 하는 방법
- 딥러닝
- 머신러닝의 한 분야
- 신경세포 구조를 모방한 인공 신경망을 사용
- 머신러닝
딥러닝의 유래
- 인공 신경망(Artificial Neural Networks)
- 인간의 신경세포를 모방하여 만든 망(Networks)
- 신경세포: 이전 신경세포로 들어오는 자극을 이후 신경세포로 전기신호로 전달하는 기능을 하는 세포
- 인간의 신경세포를 모방하여 만든 망(Networks)
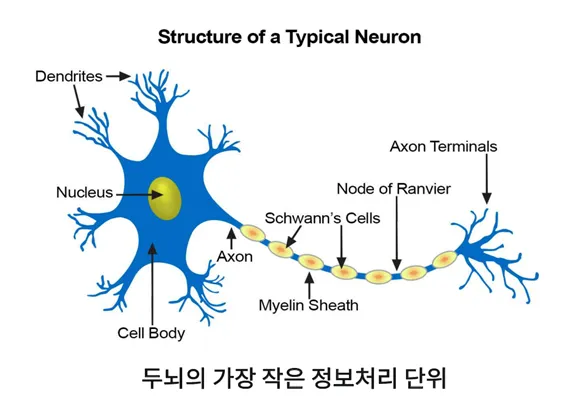
- 퍼셉트론(Perceptron)
- 인공 신경망의 가장 작은 단위
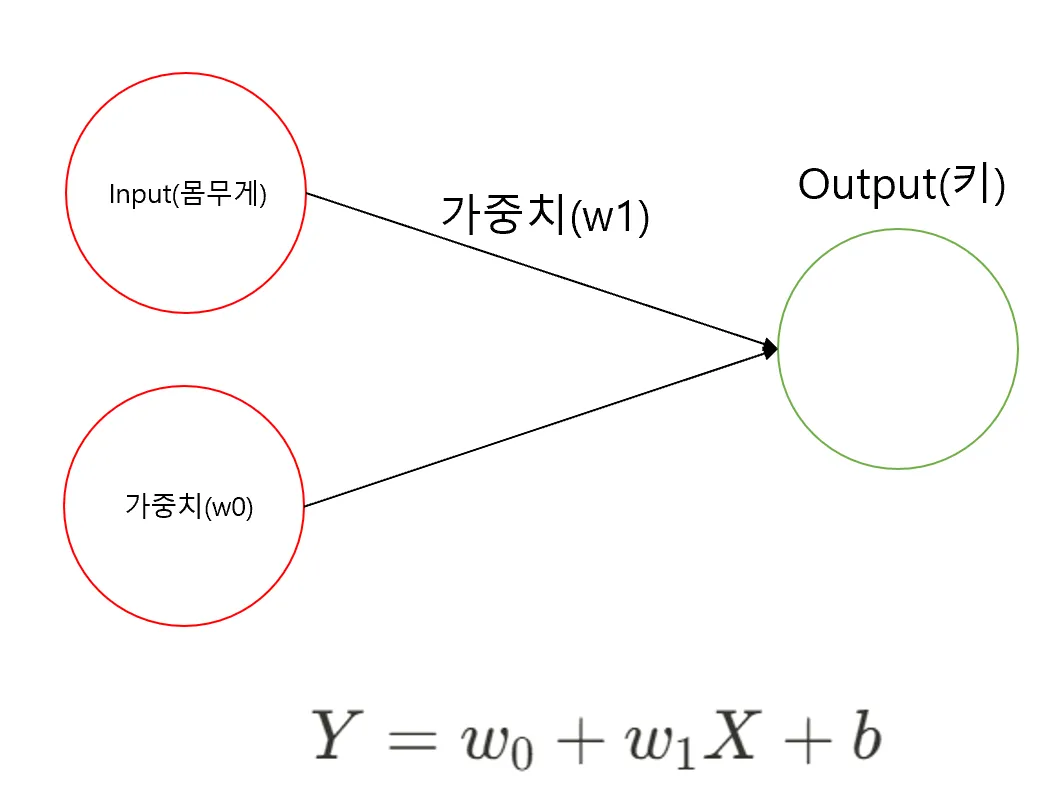
키, 몸무게 예제로 퍼셉트론 그려보기
- 선형회귀식
- 몸무게와 키 데이터
- 예측키 = 몸무게*1+ 100
- Y: 키
- X: 몸무게
- : 100으로 임의로 설정
- : 1로 임의로 설정
- b(편향, bias): 실제 Y값 - 예측 Y
| 키(Y) | 몸무게(X) | 예측 키 | 편향(bias) |
|---|---|---|---|
| 187 | 87 | 187 | 0 |
| 174 | 81 | 181 | -7 |
| 179 | 82 | 182 | -3 |
| 192 | 92 | 192 | 0 |
| 188 | 90 | 190 | -2 |
| 160 | 61 | 161 | -1 |
| 179 | 86 | 186 | -7 |
| 168 | 66 | 166 | +2 |
| 168 | 69 | 169 | -1 |
| 174 | 69 | 169 | +5 |
임의로 , 을 각각 100과 1로 설정하고 해당 식을 바탕으로 편향을 계산하니 위와 같았습니다.
이를 퍼셉트론으로 표현하면 다음과 같습니다.
- 키-몸무게 데이터에 대한 퍼셉트론
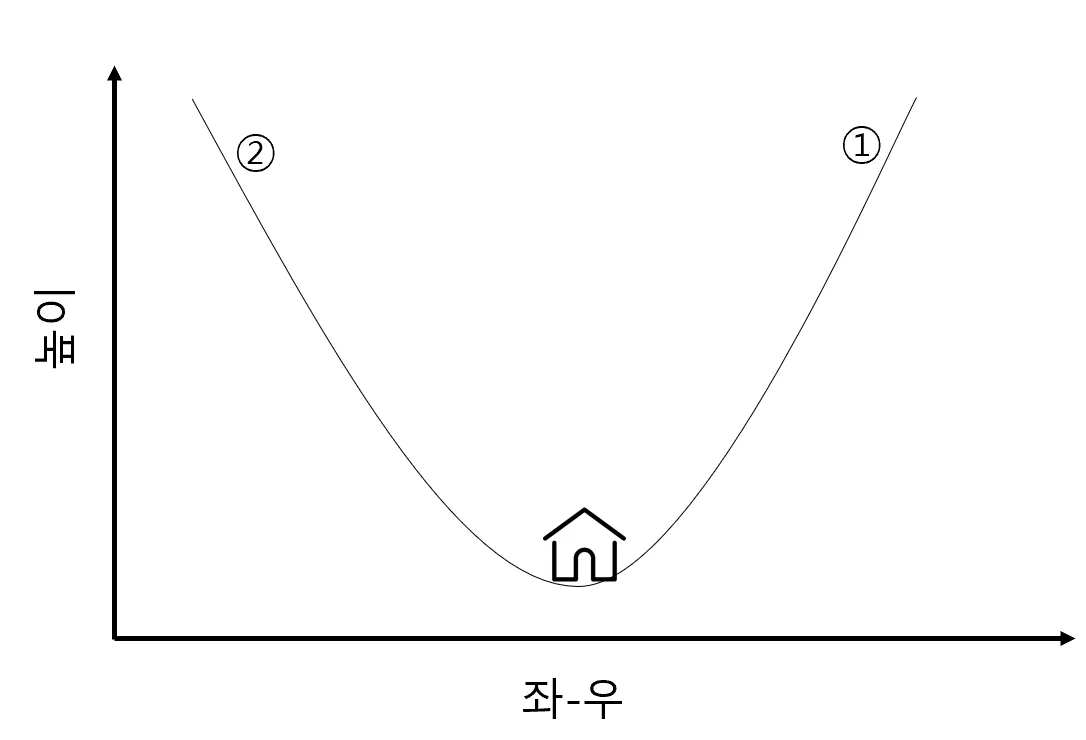
Gradient Descent: 가중치 구하기
2단원 선형 회귀 이론을 배우면서 가중치를 임의로 정한다는 말로 은근슬쩍 넘어갔는데요. 이 원리를 한번 알아 보겠습니다.
- Q. 늦은 밤 산을 내려가는 가장 쉬운 방법은?
- A. 밑으로 밑으로 향하면 된다.
- 회귀 문제에서 최소화 하려는 값은?
- Mean Squared Error(MSE)
- 에러를 제곱한 총합의 평균
- 즉, 가중치(weight)를 이리저리 움직이면서 최소의 MSE를 도출해내면 된다.
- 이렇게 최소화하려는 값을 목적 함수 혹은 손실 함수(cost function)이라고 명명
- Mean Squared Error(MSE)
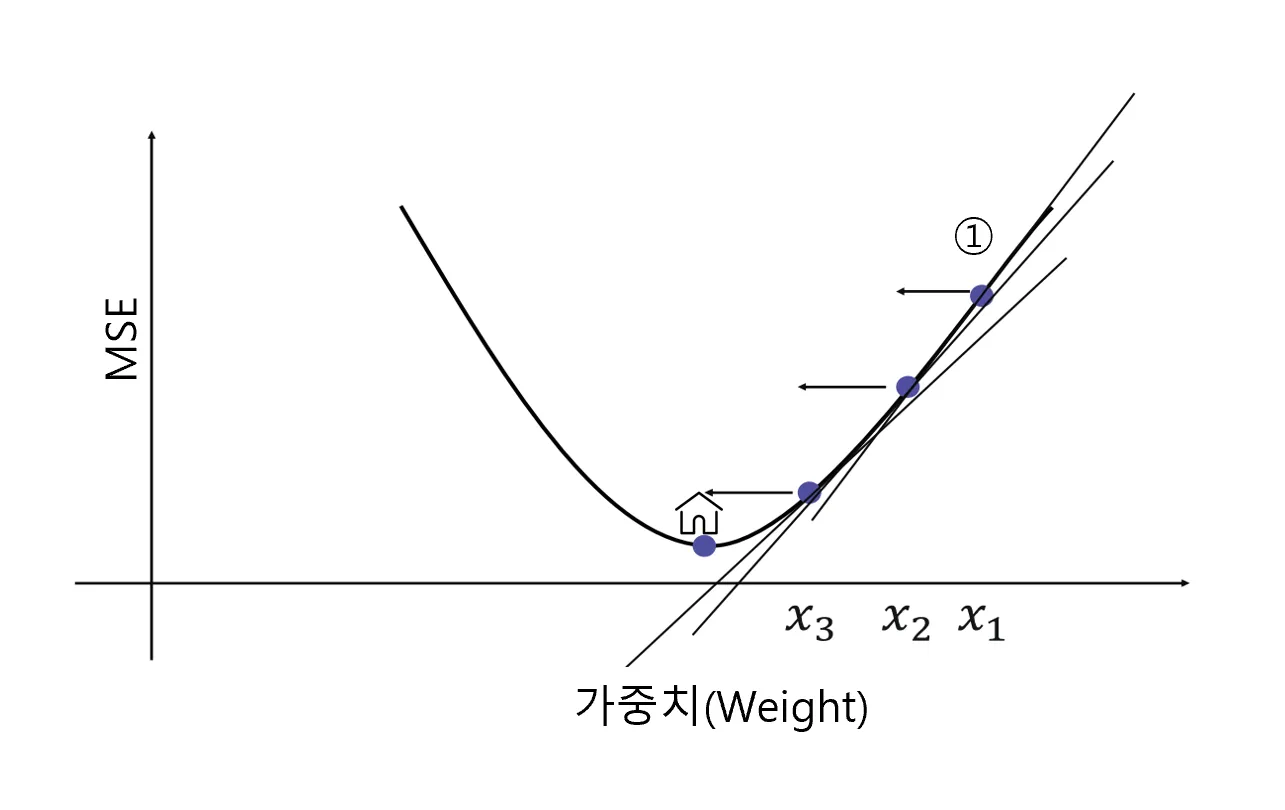
- 경사 하강법(Gradient Descent)
- 모델의 손실 함수를 최소화하기 위해 모델의 가중치를 반복적으로 조정하는 최적화 알고리즘
- weight를 찾기 위한 직관적이고 빠른 계산 방법
- 변수 X가 여러 개 있다면 동시에 여러 개의 값을 조정하면서 최소의 값을 찾으면 됨
경사하강법에는 배치 경사하강법, 확률적 경사하강법 등 다양한 알고리즘이 개발 되었어요. 다만, 이 과목의 범위를 넘어가기에 자세한 설명은 하지 않을게요! 우리는 잘 쓰기만 하면 됩니다!
활성화 함수의 등장
위의 예시는 '키'라는 "수치형 변수"였지만, 타이타닉 문제에서 사망, 생존과 같은 비선형적 분류를 만들기 위해 활성화 함수(Acitvation Fucntion)을 사용하게 되었습니다.
로지스틱회귀 때 배웠던 로지스틱 함수 역시 활성화 함수의 한 예입니다.
- 활성화 함수를 적용한 분류 도식화
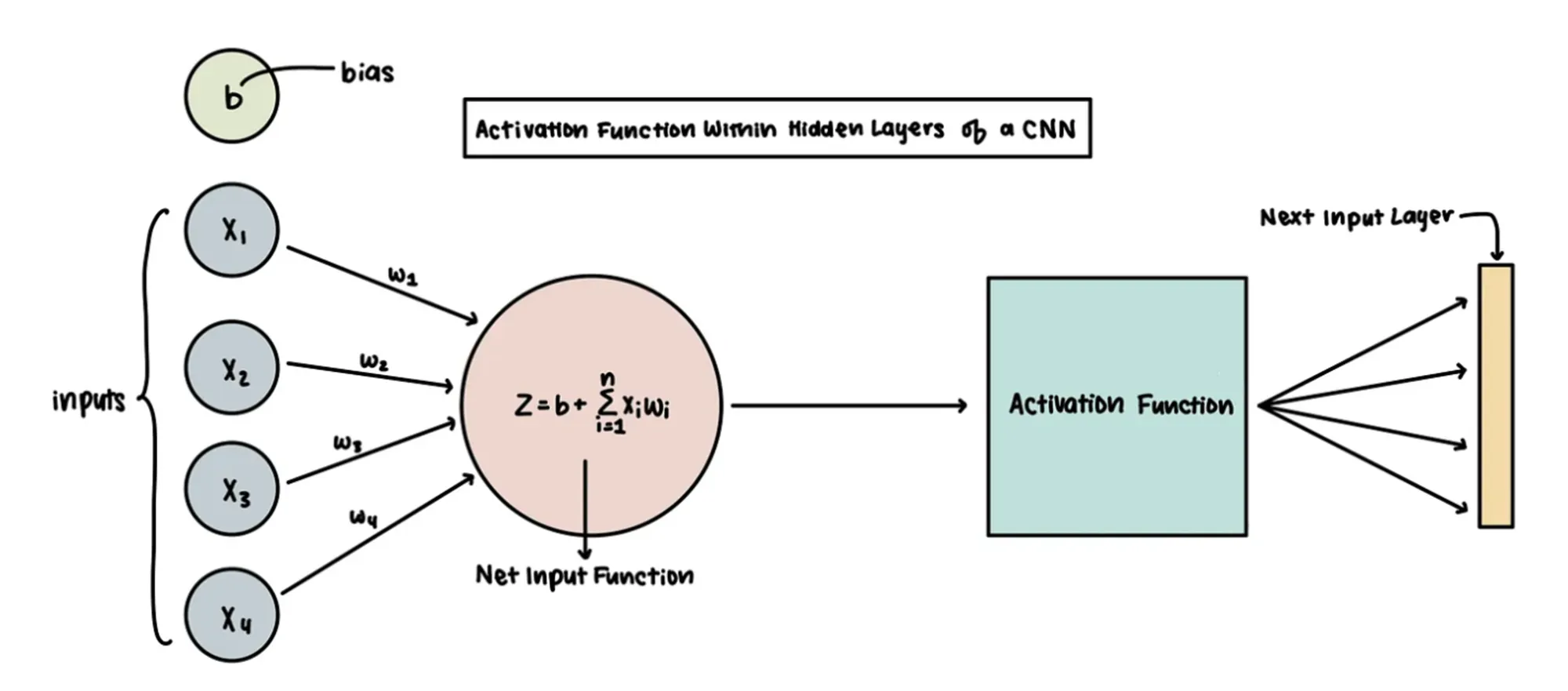
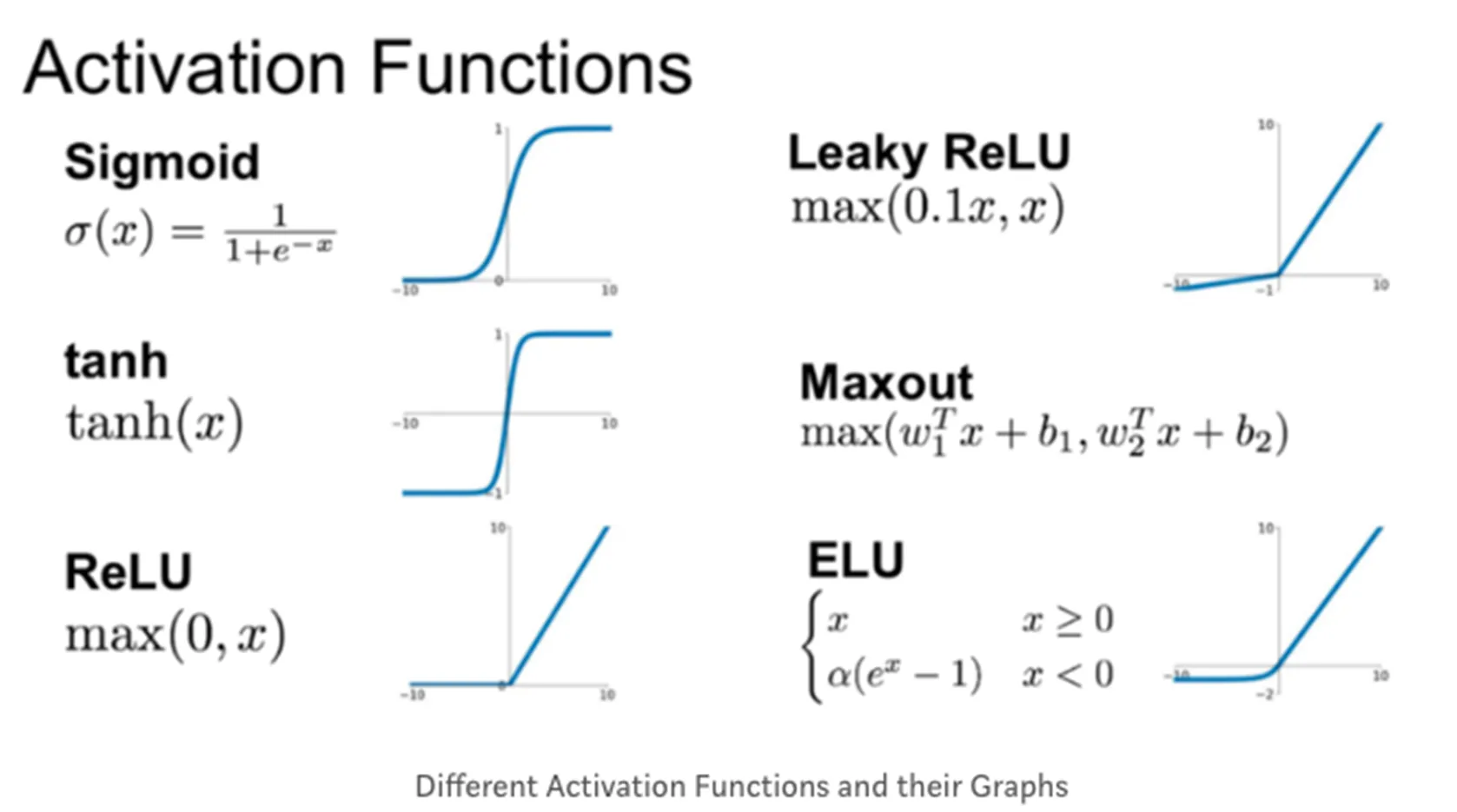
- 로지스틱 함수(시그모이드 함수의 한 예) 외에도 다양한 활성화 함수가 존재
히든 레이어(은닉층)의 등장
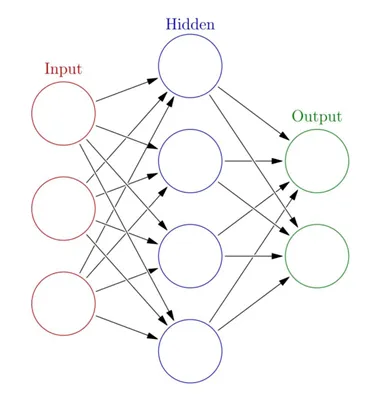
- 숨은 층(Hidden Layer)
- 중간에 입력과 결과 외로 추가하게 되는 값
- 데이터를 비선형적으로 변환함과 동시에 데이터의 고차원적 특성(ex 이미지, 자연어)을 학습하기 위해 등장
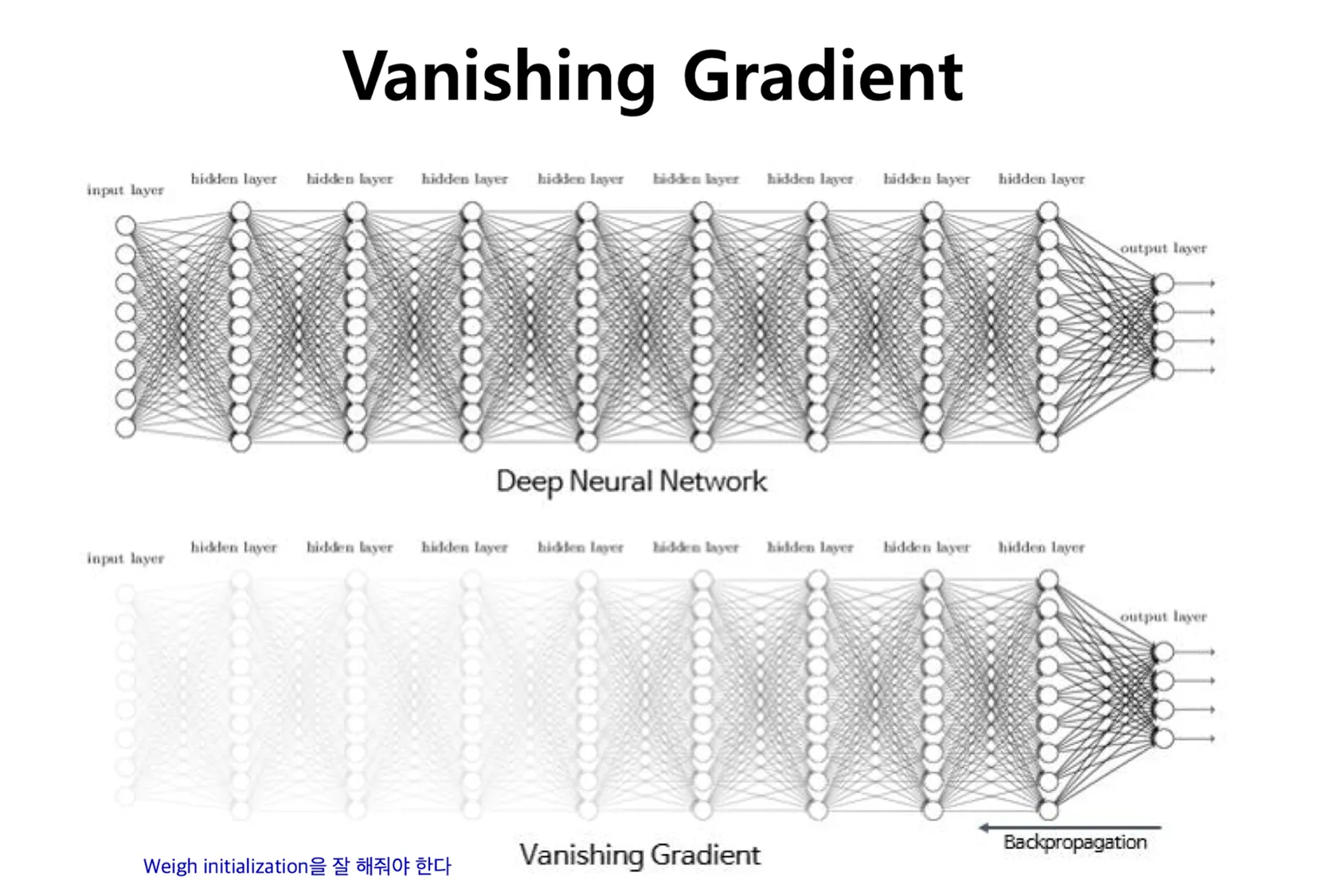
히든 레이어를 추가할수록 더 좋은 모델이 나올 줄 알았으나, 실제로는 기울기 소실이라는 문제가 발생하게 됩니다. 그 이유는 인공 신경망의 학습 과정에 있습니다.
-
인공 신경망의 학습
- 순전파(Propagation)
- 입력 데이터가 신경망의 각 층을 통과하면서 최종 출력까지 생성되는 과정
- 역전파(Backpropagation)
- 신경망의 오류를 역방향으로 전파하여 각 층의 가중치를 조절하는 과정
- 순전파(Propagation)
-
기울기 소실 문제의 등장
- 문제
- 역전파 과정에서 하위 레이어로 갈수록 오차의 기울기가 점점 작아져 가중치가 거의 업데이트 되지 않는 현상
- 해결
- 특정 활성화 함수(예: Relu)를 통해 완화
- 문제
- 각 명칭에 대한 정리
- Input Layer: 주어진 데이터가 벡터(Vector)의 형태로 입력됨
- Hidden Layer: Input Layer와 Output Layer를 매개하는 레이어로 이를 통해 비선형 문제를 해결할 수 있게 됨
- Output Layer: 최종적으로 도착하게 되는 Layer
- Activation function(활성화 함수): 인공신경망의 비선형성을 추가하며 기울기 소실 문제 해결함
epoch: 복습은 도움이 된다!
우리가 공부할 때 한 번만 공부하진 않듯 딥러닝에서도 동일한 데이터에 대해서 여러 번 공부할 수 있답니다.
- epoch
- 전체 데이터가 신경망을 통과하는 한 번의 사이클
(예) 1000 epoch: 데이터 전체를 1000번 학습
- 전체 데이터가 신경망을 통과하는 한 번의 사이클
- batch
- 전체 훈련 데이터 셋을 일정한 크기의 소그룹으로 나눈 것
- iteration
- 전체 훈련 데이터 셋을 여러 개(=batch)로 나누었을 때 배치가 학습되는 횟수
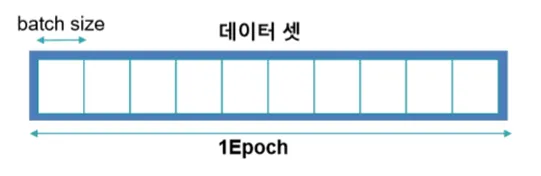
예시
- 1000개의 데이터 batch size 100개라면:
- 1 epoch에는 iteration이 10번 일어남
- 가중치 업데이트도 10번 진행
실습: 딥러닝
딥러닝 이론을 배웠으니 패키지 사용 방법을 알아봅시다.
- 딥러닝 패키지
- Tensorflow

- 구글이 오픈소스로 공개한 기계학습 라이브러리
- 2.0 버전부터는 딥러닝 라이브러리를 구축하는 Keras 패키지를 통합함
- Pytorch

- 메타(전 페이스북)에 의해 개발됨
- 토치(torch)기반의 딥러닝 라이브러리
- Tensorflow
좀 더 접근하기 쉬운 Tensorflow와 keras 패키지로 실습을 진행
Tensorflow 패키지 이해
tensorflow.keras.model 함수 링크
tensorflow.keras.model.Sequential
model.add- 모델에 대한 새로운 층을 추가함
unit
model.compile- 모델 구조를 컴파일하며 학습 과정을 설정
optimizer- 최적화 방법, Gradient Descent 종류 선택
loss- 학습 중 손실 함수 설정
- 회귀: mean_squared_error(회귀)
- 분류: categorical_crossentropy
metrics- 평가척도
mse: Mean Squared Erroracc: 정확도f1_score: f1 score
model.fit- 모델을 훈련시키는 과정
epochs- 전체 훈련 데이터 셋에 대해 학습을 반복하는 횟수
model.summary()- 모델의 구조를 요약하여 출력
tensorflow.keras.model.Dense
- 완전 연결된 층
unit- 층에 있는 유닛의 수
- 출력에 대한 차원 개수
input_shape- 1번째 층에만 필요(처음 들어갈 때에만)
- 입력데이터의 형태를 지정
model.evaluate
- 테스트 데이터를 사용하여 평가
model.predict
- 새로운 데이터에 대해서 예측 수행
실습
!pip install tensorflowfrom tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
from sklearn.preprocessing import StandardScaler
weights = np.array([87,81,82,92,90,61,86,66,69,69])
heights = np.array([187,174,179,192,188,160,179,168,168,174])
# Seqiemtial 모델 초기화
model = Sequential()
# 단일층 추가하기
dense_layer = Dense(units=1, input_shape=[1])
model.add(dense_layer)
model.compile(optimizer="adam", loss="mean_squared_error")
model.summary()
model.fit(weights, heights, epochs=100)
Hidden Layer를 포함한 아키텍처
model_2 = Sequential()
model_2.add(Dense(units=64, activation="relu", input_shape = [1]))
model_2.add(Dense(units=64, activation="relu"))
model_2.add(Dense(units=1))
model_2.compile(optimizer="adam", loss="mean_squared_error")
model_2.summary()
model_2.fit(weights, heights, epochs=100)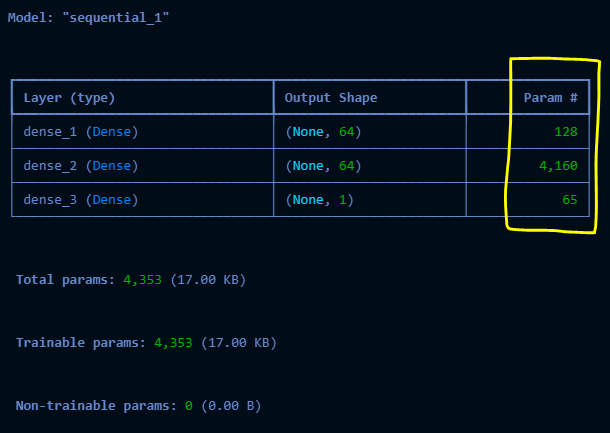
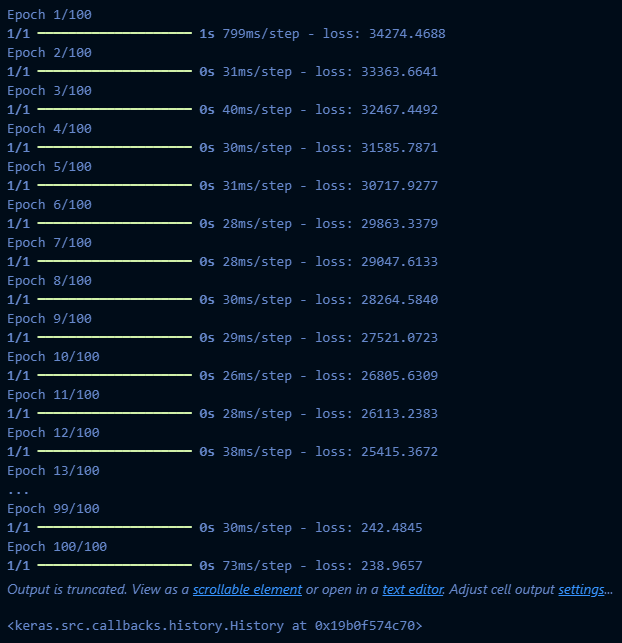
추가: UserWarning 해결
UserWarning: Do not pass an
input_shape/input_dimargument to a layer. When using Sequential models, prefer using anInput(shape)object as the first layer in the model instead.
🡆 공식 문서 참고
from tensorflow.keras import Input
model_3 = Sequential()
model_3.add(Input(shape=(1,)))
model_3.add(Dense(units=64, activation="relu")) # hidden layer 1
model_3.add(Dense(units=64, activation="relu")) # hidden layer 2
model_3.add(Dense(units=1)) # 최종적으로 나올 output이 숫자 하나라서 units=1
# output layer: 회귀 문제이므로 node 1개 & 활성 함수 지정 X
model_3.compile(optimizer="adam", loss="mean_squared_error")
model_3.summary()
model_3.fit(weights, heights, epochs=100, batch_size=10)→ 이렇게 하면 warning 없이 실행 가능
활용 예시
딥러닝의 기본을 배웠으니 우리가 피부로 느끼는 활용 예시를 간단하게 알아봅시다.
자연어 처리
가장 간단한 자연어 처리
- 자연어처리(Natural Language Processing)
- 인간의 언어를 데이터화 하는 것
(예) 단어의 빈도 수 기반 데이터 화(Bag of Words)
- 인간의 언어를 데이터화 하는 것
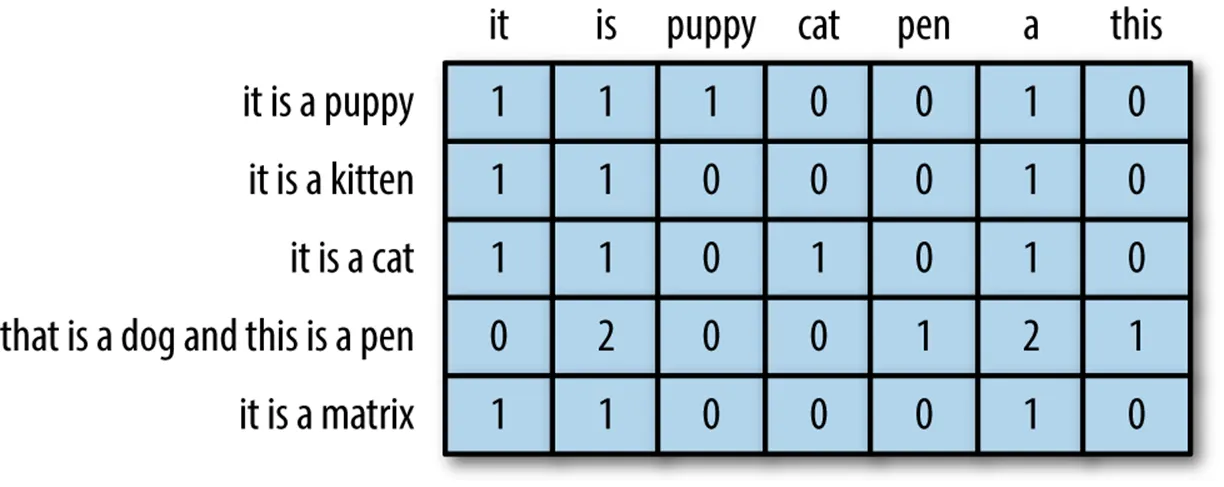
언어라는 특성상 문맥의 고려가 필수적인데, 위 방식은 문맥을 고려하지 않아서 인공 신경망의 발전을 토대로 문맥을 모델이 개발되었어요.
이 모델들이 현재 OPEN AI의 ChatGPT 서비스의 연장선에 있는 것입니다.
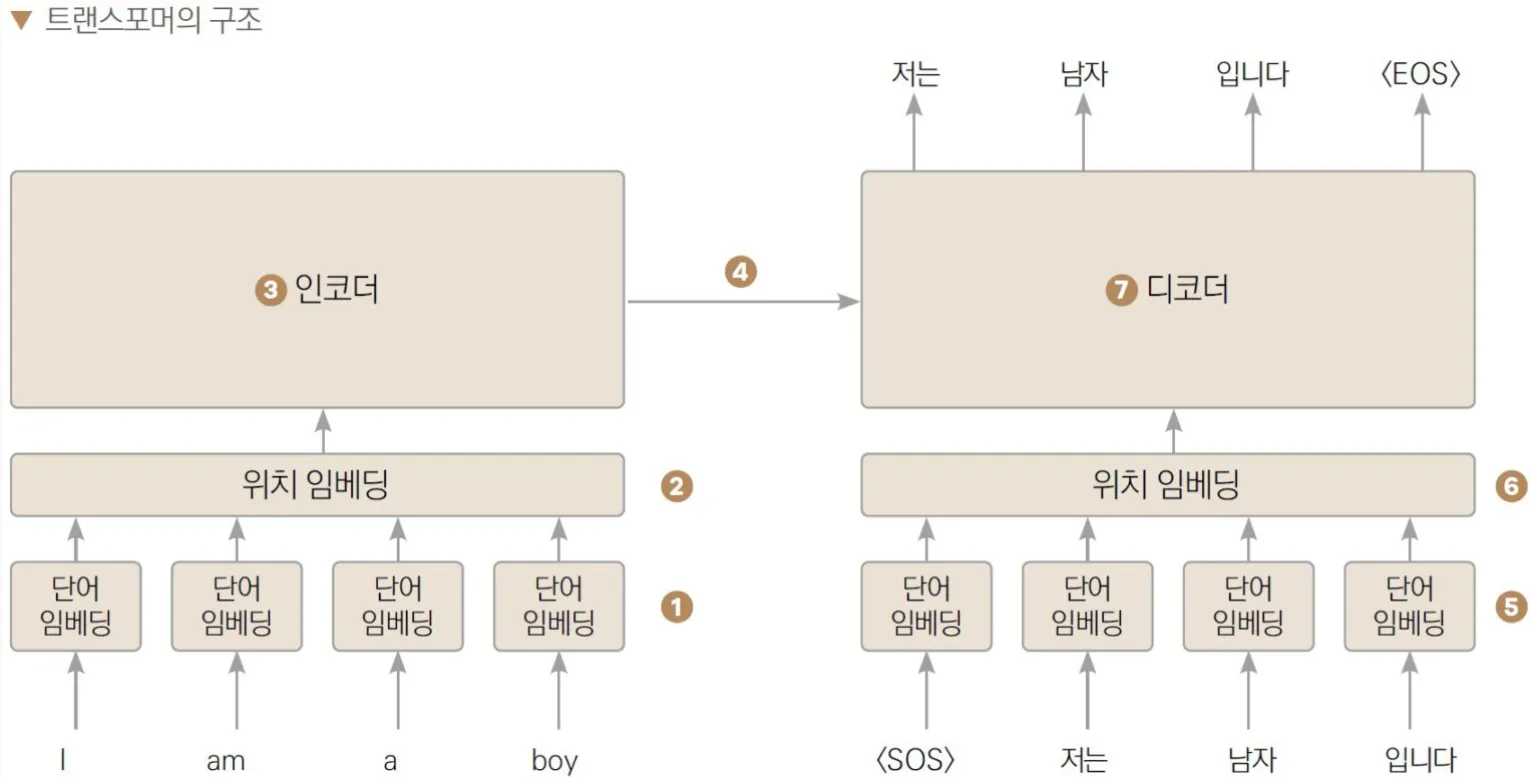
☞ Transformer 모델 - 기계번역의 예시
LLM: 최신 자연어 처리 모델
이런 기반에서 최근에는 빅테크들이 각자의 LLM(Large Language ModeL)을 개발해서 서비스화 하는 중이랍니다.
과연 LLM의 끝에는 인공지능 자비스가 기다리고 있을까요?
- LLM의 종류
- GPT-4(OpenAI), PaLM2(Google), LlaMA(Meta)
이미지
이미지는 색깔이 이미 데이터이기 때문에 합성 곱 연산을 통해 딥러닝 모델에 학습하고 이미지를 생성하는 방식으로 발전해왔습니다.
이미지는 원래 데이터 기반
- 이미지 == RGB 256개의 데이터로 이루어진 데이터의 집합
- 3차원 데이터를 모델에 학습시킴
(예) 숫자 2를 예측하는 딥러닝의 구조
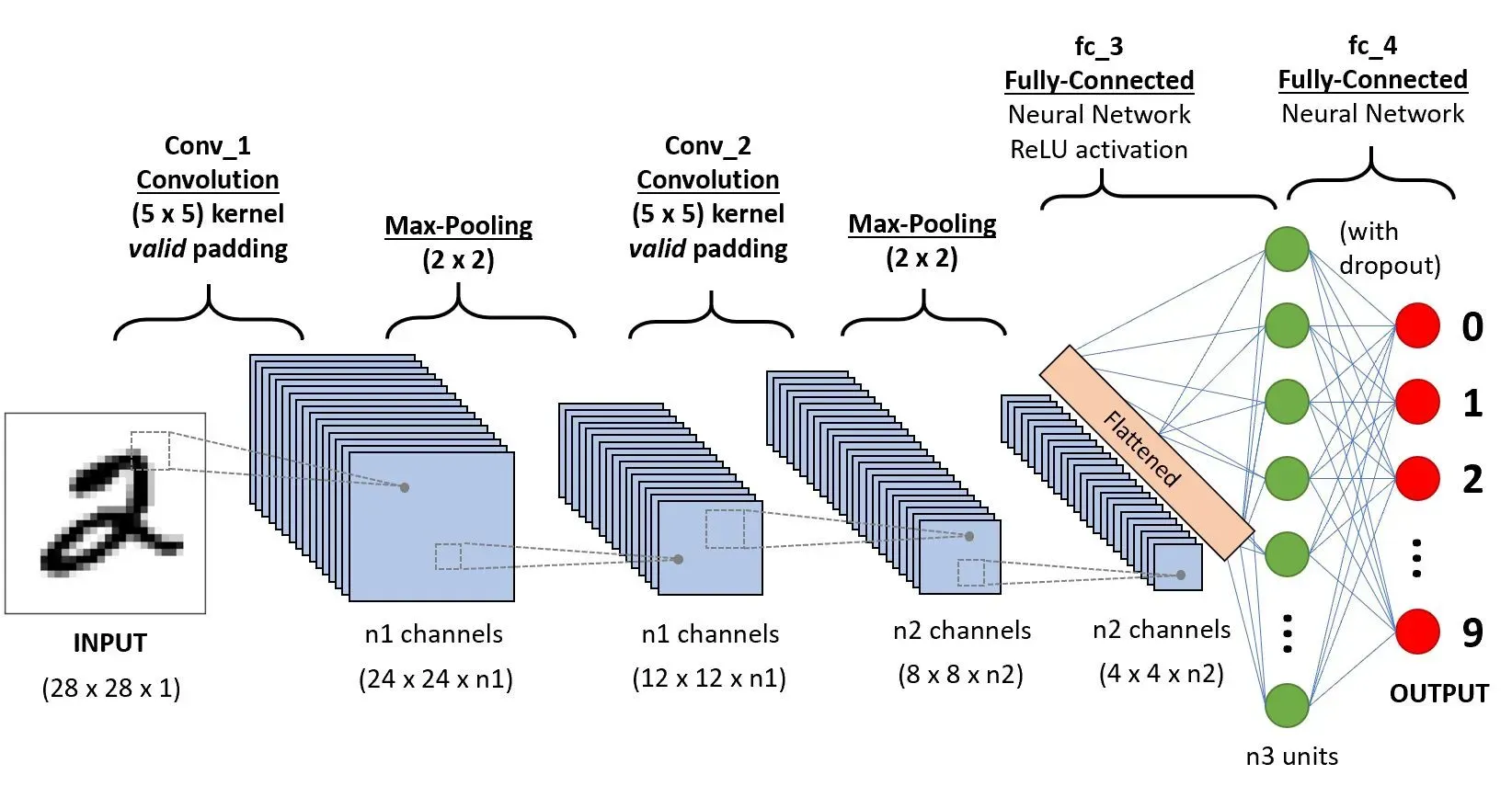
(예) 합성 곱(CNN) 연산의 예시
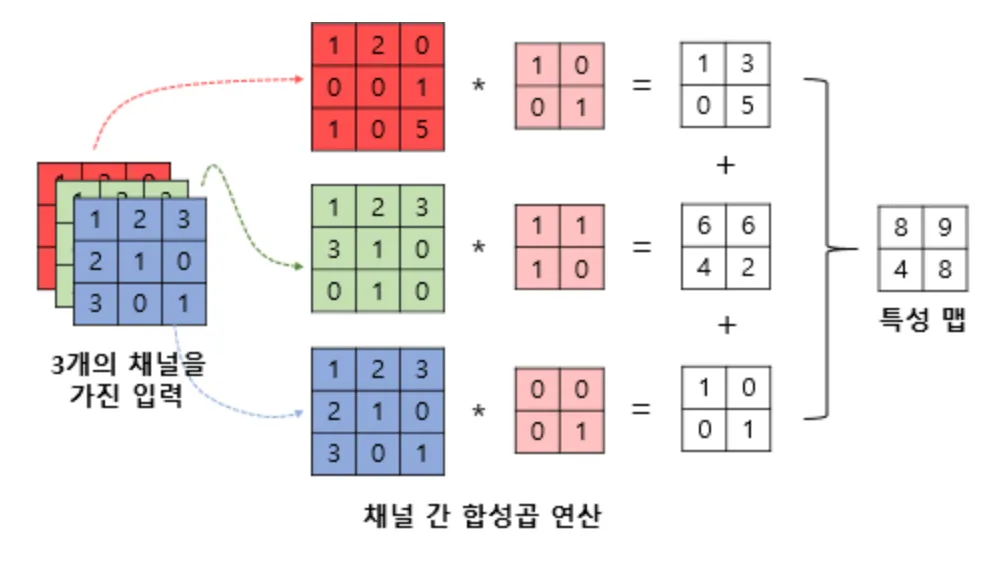
🡆 합성 곱: 가지고 있는 특성을 행렬과 행렬 간 연산을 통해 2x2로 줄임
최근 이미지 생성 딥러닝
최근의 이미지 모델의 특징은 단순히 이미지를 입력 받는 것을 넘어서 텍스트, 이미지, 음성 등 다양한 유형의 데이터를 함께 사용하는 Mutimodal의 시대가 도래했어요.
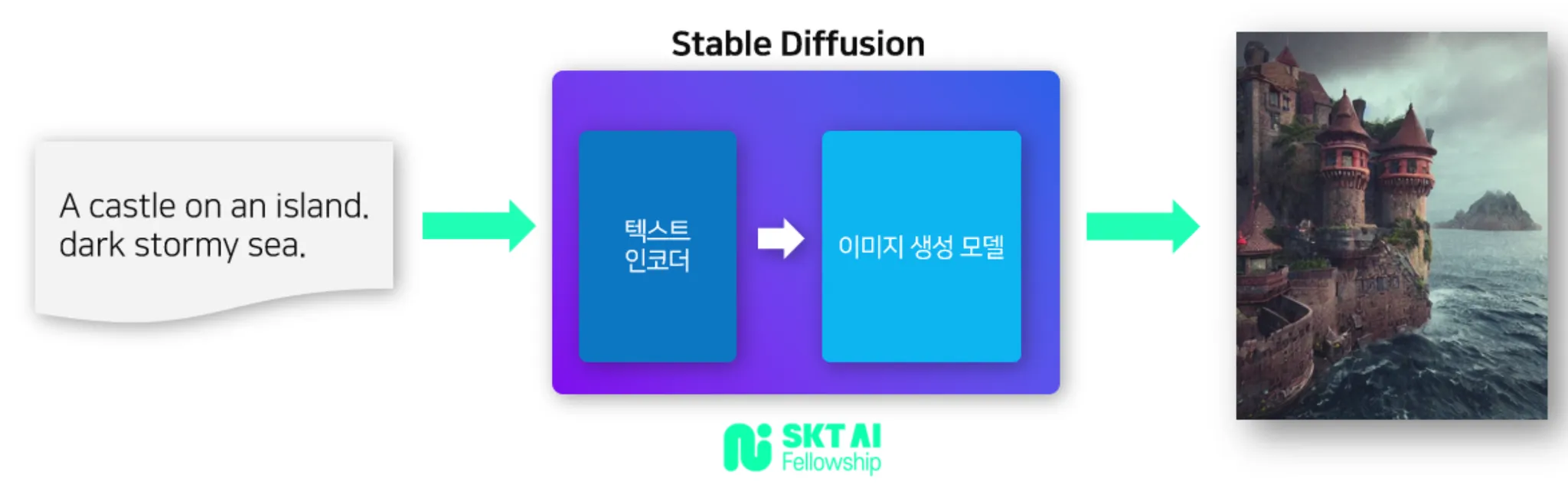
특히 Stable Diffusion은 커뮤니티가 발달해 쉽게 설치할 수 있어 접근성도 매우 뛰어납니다.
- Stable Diffusion(2022)
- 2022년에 발표된 text-to-image Mutimodal 이미지 모델
☞ SK Devocean 테크 블로그
강의 마무리
단원별 한 줄 요약
숨 가쁘게 머신러닝에 대해 알아보았습니다. 지금까지 배운 것을 바탕으로 정리해볼게요.
- 머신러닝의 기초
- 머신러닝의 기본, 개념
- 회귀분석
- 가장 설명을 잘하는 직선을 그리는 법 - 선형회귀
- 실제 값과 예측 값의 오차를 계산하라 - Mean Squared Error
- 분류분석
- 특정 범주에 대한 확률 예측하기 - 로지스틱회귀
- 맞춘 것에 대한 지표: 정확도, f1_score
- 데이터 분석 프로세스
- 데이터 수집 → 전처리 → 모델링 → 평가
- 회귀, 분류 모델링 심화
- 의사결정을 기반으로 한 모델 - 의사결정나무
- 나무를 여러 개 만들어서 다수결 원칙을 사용하자 - 랜덤포레스트
- 유유사종의 원리로 예측하자 - KNN
- 약한 학습기를 여러 개 합치자 - 부스팅 모델
- 비지도학습
- 만약 Y(정답이 없다면) 특성을 이용해 그룹화 하자 - K-means 군집화
- 인공 신경망
- 사람의 신경세포를 모방한 네트워크 - 인공 신경망
데이터 직군별 머신러닝 활용 방안
그럼 이렇게 배운 머신러닝을 각 직군은 어떻게 써먹을 수 있을까요?
직군에 대한 간략한 설명과 머신러닝 적용방안은 다음과 같습니다.
- Data Engineer
- 역할
- 데이터 Extract(추출), transform(변환), Load(적재) 및 데이터 파이프라인 관리
- Workflow 과정 자동화
- ML/DL 활용 낮음
- 역할
- Machine Learning Engineer
- 역할
- 데이터를 기반으로 모델 최적화
- 개발한 모델을 실제 운영에 배포, 성능 평가, 유지 보수
- ML/DL 활용 필수
- 역할
- AI Researcher
- 역할
- 머신러닝/딥러닝 모델을 논문을 통해 읽고 구현
- 논문 작성 및 발표
- ML/DL 활용 필수
- 역할
- Data Analyst
- 역할
- 데이터 분석 및 인사이트 도출
- 보고서 작성 및 데이터 시각화
(예) A/B test, 유저분석을 통해서 PM/PO/대표를 보고&설득
- ML/DL 활용 중간
- 고객 세분화(클러스터링), 고객 이탈 분석(판매량 예측), 텍스트 분석(자연어 처리를 이용한 리뷰 분석)
- 역할
