비지도 학습
- 학습목표
- 군집화 알고리즘을 통해 정답이 없는 데이터를 다루는 비지도 학습 이해하기
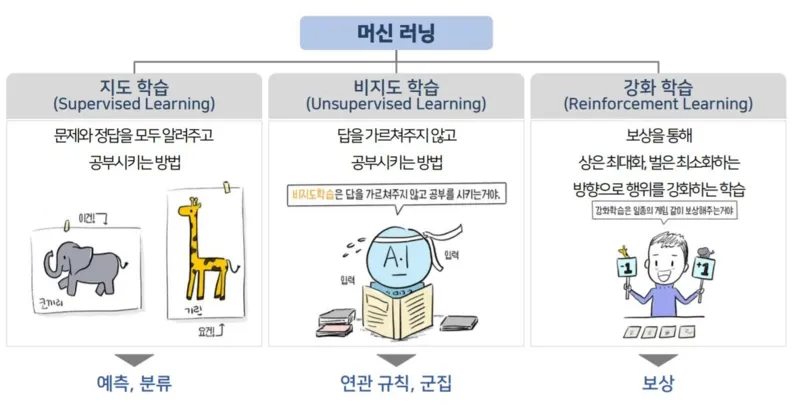
머신러닝 종류 복습
지도 학습과 비지도 학습
우리가 배웠던 회귀와 분류는 대표적인 지도 학습이라고 했습니다.
지도 학습은 문제(X)와 정답(Y)이 주어지고 문제(X)가 주어졌을 때 정답(Y)을 맞추는 학습이였어요.
반면 비지도 학습이란 답(Y)을 알려주지 않고 데이터 간 유사성을 이용해서 답(Y)을 지정하는 방법입니다.
🡆 비지도 학습 → 답은 굉장히 주관적인 것 → 데이터 유사성을 통해서 Y를 지정(레이블링)
- 머신러닝 개요
- 비지도 학습 예시
- 고객 특성에 따른 그룹화
(예) 헤비유저, 일반유저 - 구매 내역별로 데이터 그룹화
(예) 생필품 구매
- 고객 특성에 따른 그룹화
다시 말해 비지도 학습은 데이터를 기반으로 레이블링을 하는 작업이라고 하겠습니다.
정답이 없는 문제이기 때문에 지도 학습보다 조금 어렵고 주관적인 판단이 개입하게 됩니다.
비지도학습
- 대표적인 비지도 학습인 K-평균 알고리즘 알아보기
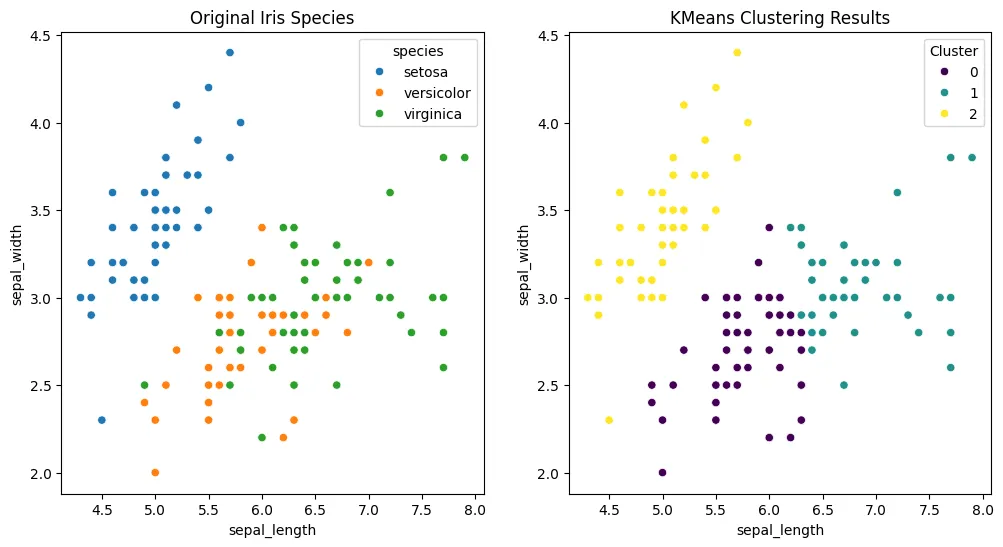
붓꽃 데이터를 이용한 군집화 예시
K - 평균 군집화 혹은 알고리즘(K-means clustering)은 가장 일반적으로 사용되는 알고리즘입니다.
쉬운 예시를 위해서 붓꽃(iris) 데이터로 살펴보겠습니다.
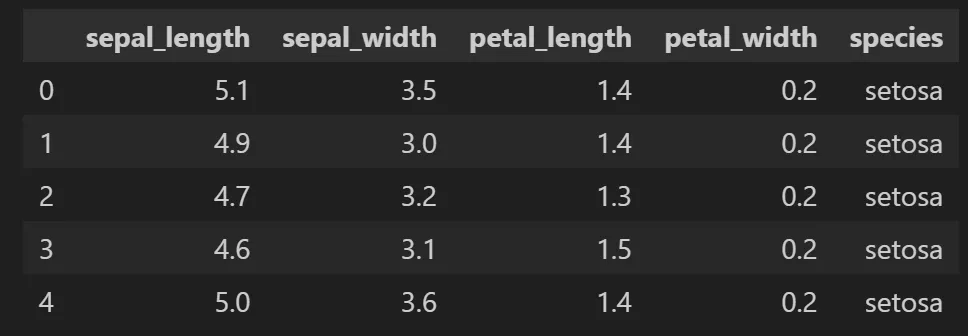
- sepal_length: 꽃 받침의 길이
- sepal_width: 꽃 받침의 너비
- petal_length: 꽃 잎의 길이
- petal_width 꽃 잎의 너비
- species(Y, 레이블): 붓꽃 종(setosa, virginica, versicolor)
꽃에 대한 정보(X)로 종, Species(Y)를 맞추는 문제를 푼다면 지도 학습이라고 합니다.
반면, Species가 없다면? 정보에 따라서 데이터를 분류해볼 수 있지 않을까요?
- Labeling이 안된 꽃 받침 길이-너비 산점도
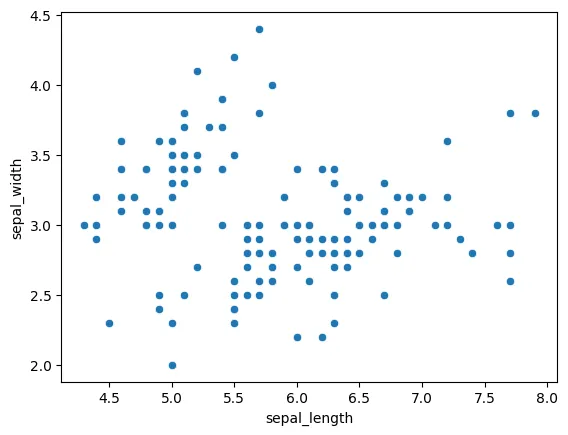
위 점을 적당히 그룹화 해볼까요?
2개 그룹 3개 그룹 등등 다양한 방법이 있을 수 있습니다.
- Labeling이 된 꽃 받침 길이 - 너비 산점도
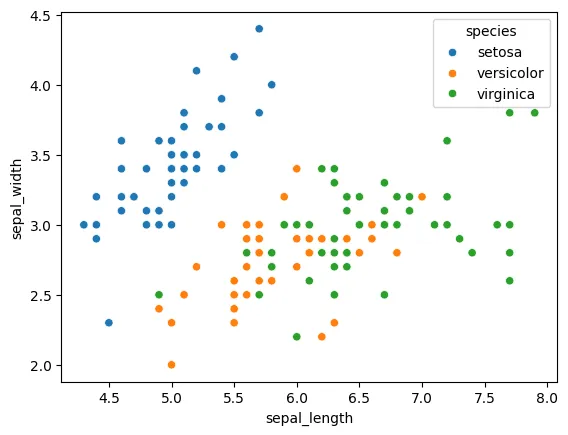
실제 데이터는 위와 같이 표기 되었어요.
이렇게 3개로 분류된 건 학자들의 나름의 기준으로 정의했기 때문입니다.
“데이터”의 기준으로 보면 3개가 아닌 K개의 그룹으로 정해볼 수 있을 거예요.
- 미리보기: K means를 이용한 군집화
K-Means Clustering 이론
K-Means Clustering 수행 순서
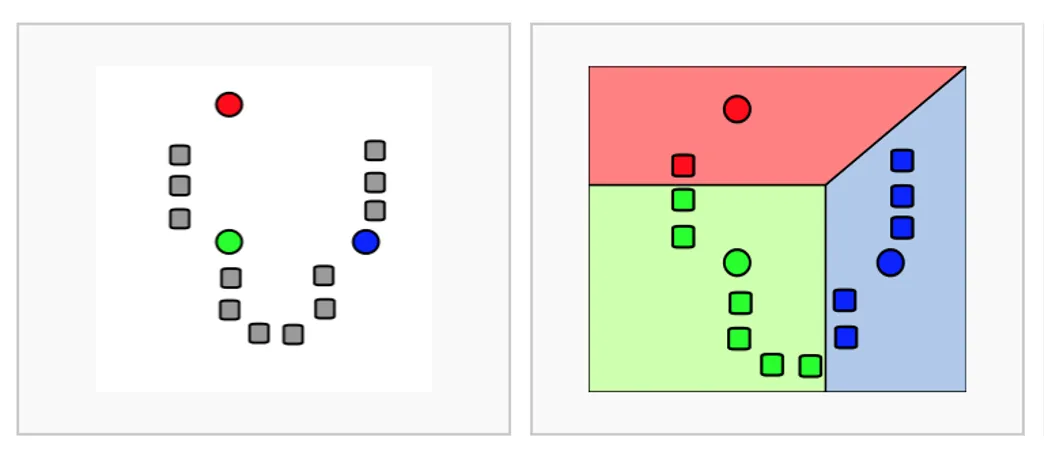
- K개 군집 수 설정
- 임의의 중심을 선정
- 해당 중심점과 거리가 가까운 데이터를 그룹화
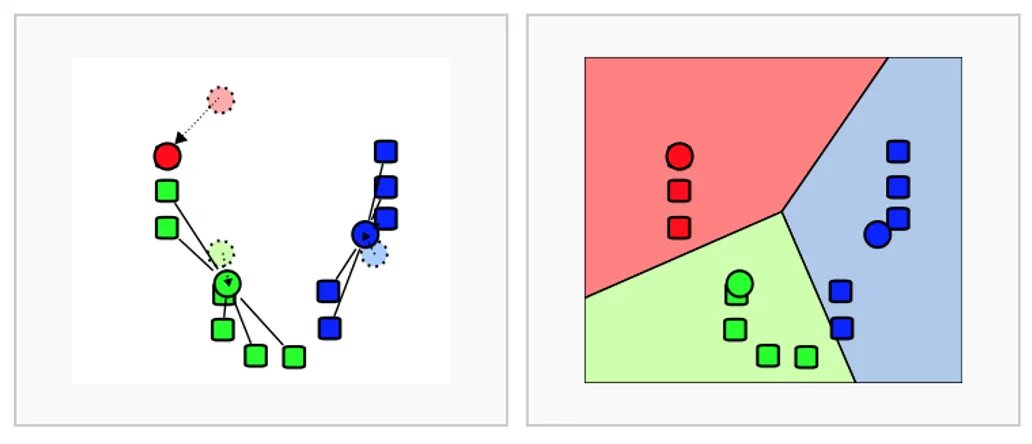
- 데이터의 그룹의 무게 중심으로 중심점을 이동
- 중심점을 이동했기 때문에 다시 거리가 가까운 데이터를 그룹화
(3~5번 반복)
이렇게 임의로 분석가가 선정한 K군집 수(위 그림에서는 3)를 기준으로 데이터 군집화 프로세스를 진행한답니다.
- 장점
- 일반적이고 적용하기 쉬움
- 단점
- 거리 기반으로 가까움을 측정하기 때문에 차원이 많을수록 정확도가 떨어짐
- 반복 횟수가 많을 수록 시간이 느려짐
- 몇 개의 군집(K)을 선정할지 주관적임
- 평균을 이용하기 때문에(중심점) 이상치에 취약함
- Python 라이브러리
sklearn.cluster.KMeans- 함수 입력 값
n_cluster: 군집화 개수max_iter: 최대 반복 횟수
- 메서드
labels_: 각 데이터 포인트가 속한 군집 중심점 레이블cluster_centers: 각 군집 중심점의 좌표
- 함수 입력 값
군집평가 지표
실루엣 계수
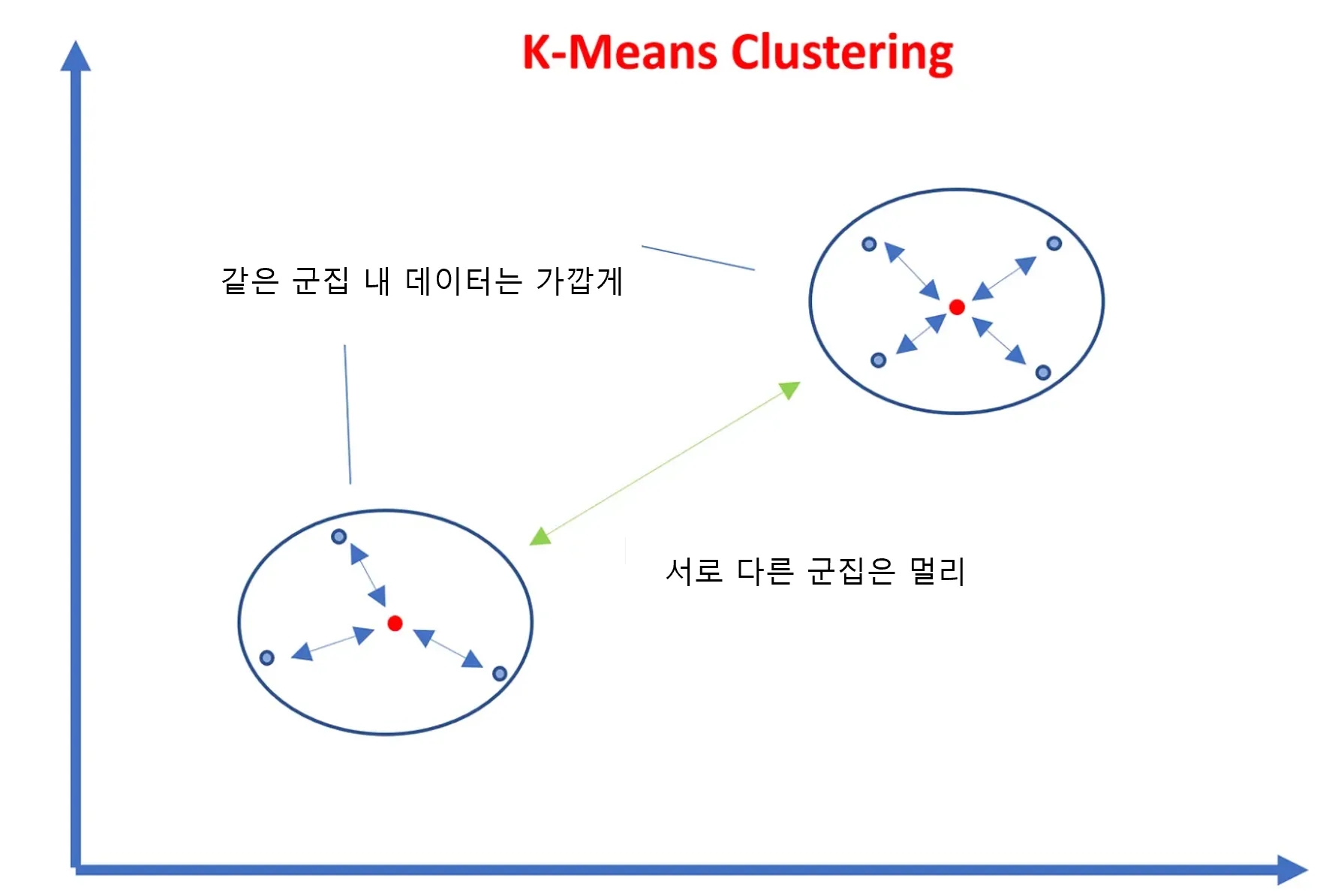
비지도 학습 특성상 답이 없기 때문에 그 평가를 하긴 쉽지 않습니다.
다만, 군집화가 잘 되어 있다는 것은 다른 군집 간의 거리는 떨어져 있고 동일한 군집끼리는 가까이 있다는 것을 의미합니다.
이를 정량화 하기 위해 사용하는 실루엣 분석(silhouette analysis)은 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 측정합니다. 수식은 다음과 같지만 그냥 이해만 해보세요!
-
수식
- 데이터 포인트 과 같은 군집에 속한 다른 포인트들과의 평균 거리
- 데이터 포인트 와 가장 가까운 다른 군집 간의 평균 거리
-
해석
- 1로 갈수록 잘 군집화 되어 있음
- -1에 가까울수록 잘 못 군집화 되어 있음
수식을 해석해보자면 특정한 데이터 i의 실루엣 계수는 얼마나 떨어져있는가()가 클 수록 크며, 이를 단위 정규화를 위해 값 중에 큰 값으로 나눕니다.
- 좋은 군집화의 조건
- 실루엣 값이 높을수록(1에 가까움)
- 개별 군집의 평균 값의 편차가 크지 않아야 함
- Python 라이브러리
sklearn.metrics.sihouette_score- 전제 데이터의 실루엣 계수 평균 값 반환
- 함수 입력 값
X: 데이터 세트labels: 레이블metrics: 측정 기준 기본은euclidean
실습: 붓꽃 데이터를 이용한 군집화
붓꽃 데이터를 이용한 실습을 해봅시다.
- 붓꽃데이터 load
- Kmeans Clustering
- 시각화 결과 비교
- 군집화 평가
1. 붓꽃데이터 load
import pandas as pd
import seaborn as sns
iris_df = sns.load_dataset("iris")
iris_df.head()
# 결측치 확인
iris_df.info()
2. Kmeans Clustring
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, init="k-means++", max_iter=300, random_state=42)
kmeans.fit(iris_df_2)
kmeans.labels_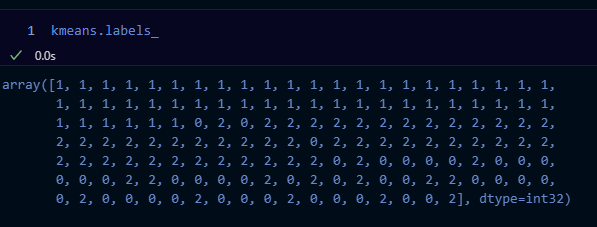
iris_df_2["target"] = iris_df["species"]
iris_df_2["cluster"] = kmeans.labels_
iris_df_2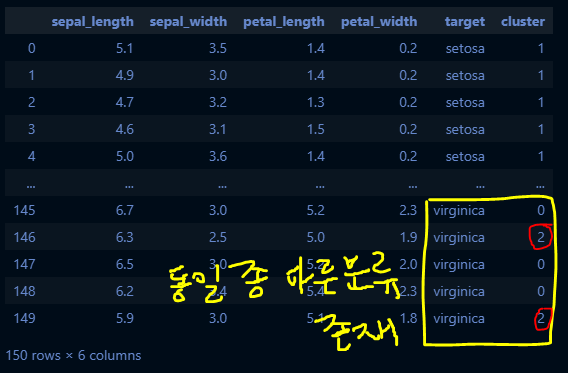
3. 시각화 결과 비교
import matplotlib.pyplot as plt
fig_iris = plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
sns.scatterplot(data=iris_df_2, x="sepal_length", y="sepal_width", hue="target")
plt.title("Original")
plt.subplot(1,2,2)
sns.scatterplot(data=iris_df_2, x="sepal_length", y="sepal_width", hue="cluster", palette="viridis")
plt.title("Clustering")
plt.show()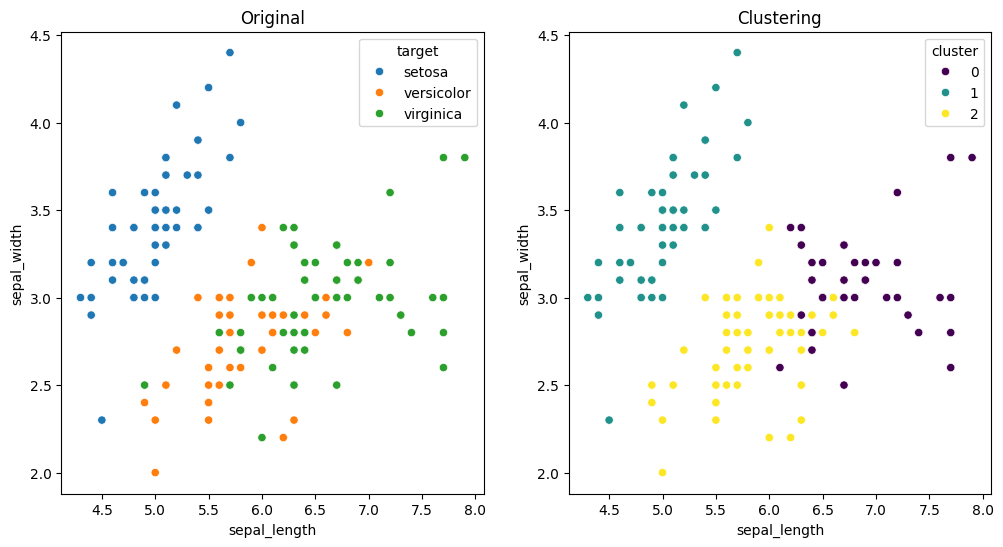
실습: 고객 세그멘테이션
비지도 학습을 배웠으니 실제 업무에 적용해봅시다.
고객 세그멘테이션의 정의
비지도 학습이 가장 많이 사용되는 분야는 고객 관계 관리(Customer Relationship Management, CRM)분야 입니다.
이 중 고객 세그멘테이션(Customer Segmentation)은 다양한 기준으로 고객을 분류하는 기법입니다.
주로 타겟 마케팅이라 불리며 고객 특성에 맞게 세분화 하여 유형에 따라 맞춤형 마게팅이나 서비스를 제공하는 것을 목표로 둡니다.
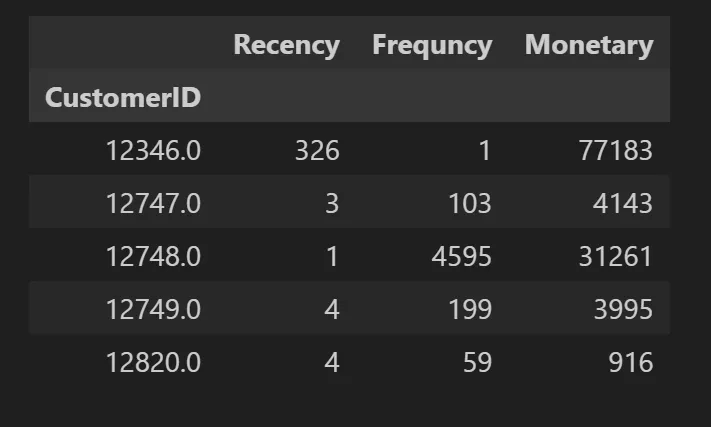
- RFM의 개념
- Recency(R) 가장 최근 구입 일에서 오늘까지의 시간
- Frequency(F): 상품 구매 횟수
- Monetary value(M): 총 구매 금액
실습 개요
-
retail_df.head()

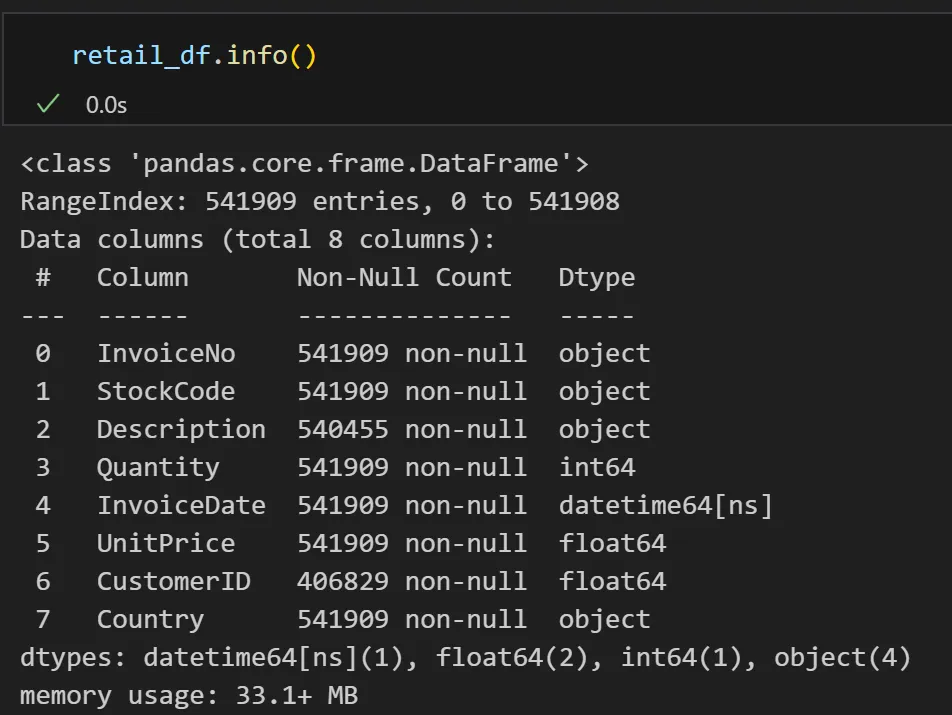
retail_df.info()
- 컬럼 정보
InvoiceNO: 6자리의 주문번호(취소된 주문은 c 로 시작)StockCode: 5자리의 제품 코드Description: 제품 이름(설명)Quantity: 주문 수량InvoiceDate: 주문 일자, 날짜 자료형UnitPrice: 제품 단가CustomerID: 5자리의 고객 번호Country: 국가명
-
EDA
-
데이터 전처리
customerID결측치 삭제InvoiceNo,UniPrice,Quantity데이터 확인 및 삭제- 영국 데이터만 취함
-
RFM 기반 데이터 가공
- 날짜 데이터 가공
- 최종목표
StandardScaler적용
-
고객 세그멘테이션
-
평가
실습
!pip install openpyxl
# RFM 고객 세그멘테이션
retail_df = pd.read_excel("Online Retail.xlsx")
retail_df.head(3)
# 결측치 확인 (1)
retail_df.info()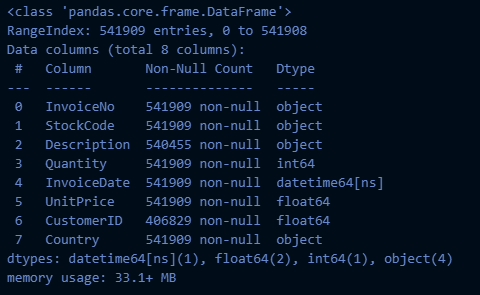
# 결측치 확인 (2)
retail_df.isnull().sum()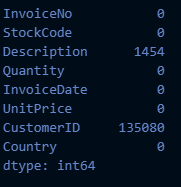
1. 데이터 EDA 및 전처리
retail_df.describe(include="all")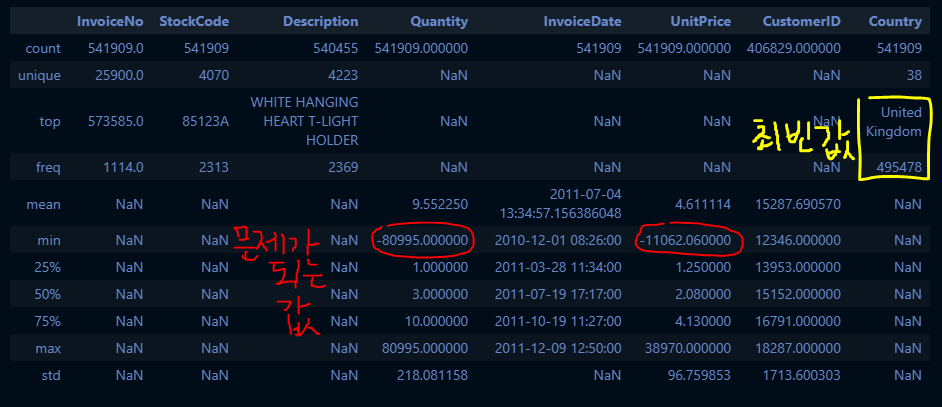
# 음수인 값 확인
cond_1 = retail_df["Quantity"] < 0
retail_df[cond_1]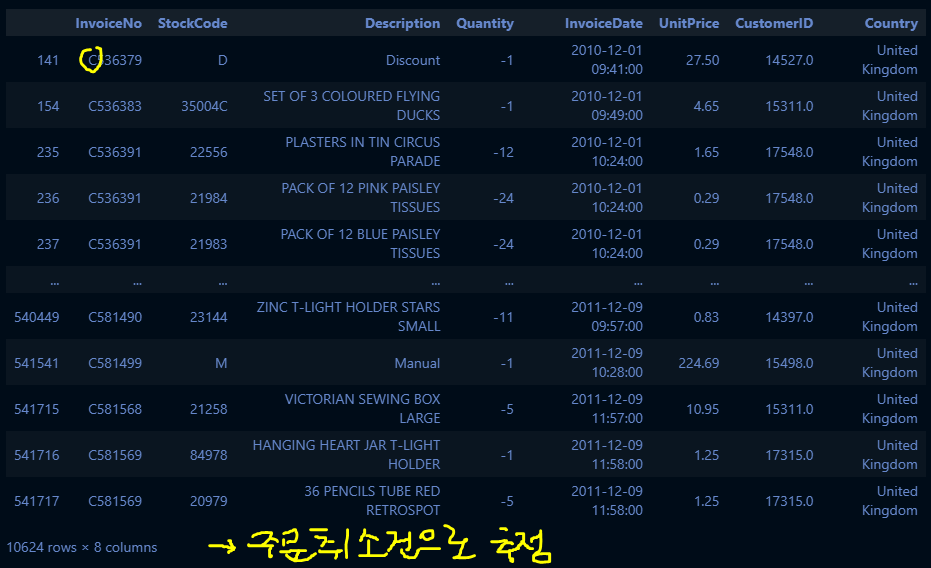
# 데이터 전처리 전략
# 조건1: customerID 결측치인 것은 삭제
# 조건2: Invoice가 C로 시작하거나, quantity가 음수이거나, unitprice가 음수인 것은 모두 삭제
cond_cust = retail_df["CustomerID"].notnull()
retail_df[cond_cust].isnull().sum()
cond_invo = (retail_df["InvoiceNo"].astype(str).str[0] != 'C')
cond_minus = (retail_df["Quantity"]>0)&(retail_df["UnitPrice"]>0)
retail_df_2 = retail_df[cond_cust&cond_invo&cond_minus]
retail_df_2.info()
# 데이터 전처리: 영국 데이터만 취함
retail_df_2["Country"].value_counts()[:10]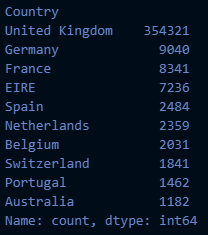
cond_uk = (retail_df_2["Country"] == "United Kingdom")
retail_df_2 = retail_df_2[cond_uk]
retail_df_2
2. RFM 기반 데이터 가공
retail_df_2.describe(include="all")
# Monetary용 데이터 가공
retail_df_2["Amt"] = retail_df_2["Quantity"]*retail_df_2["UnitPrice"]
retail_df_2["Amt"] = retail_df_2["Amt"].astype("int")retail_df_2[["CustomerID"]].drop_duplicates()
retail_df_2.pivot_table(index="CustomerID", values="Amt", aggfunc="sum")
retail_df_2.pivot_table(index="CustomerID", values="Amt", aggfunc="sum").sort_values("Amt", ascending=False)
# Recenct용 데이터 가공
import datetime as dt
# 2011-12-10 기준으로(마지막 결제일이 2011-12-09이기 때문)
# 각 날짜를 빼고 + 1
# 추후 CustomerID 기준으로 Period의 최솟값을 구하면 Recency
retail_df_2["Period"] = (dt.datetime(2011,12,10)-retail_df_2["InvoiceDate"]).apply(lambda x: x.days+1)
retail_df_2.head(3)
retail_df_2.groupby("CustomerID").agg({
"Period": "min"
, "InvoiceNo": "count"
, "Amt": "sum"
})
rfm_df = retail_df_2.groupby("CustomerID").agg({
"Period": "min"
, "InvoiceNo": "count"
, "Amt": "sum"
})
rfm_df.columns = ["Recency", "Frequency", "Monetary"]
sns.histplot(rfm_df["Frequency"])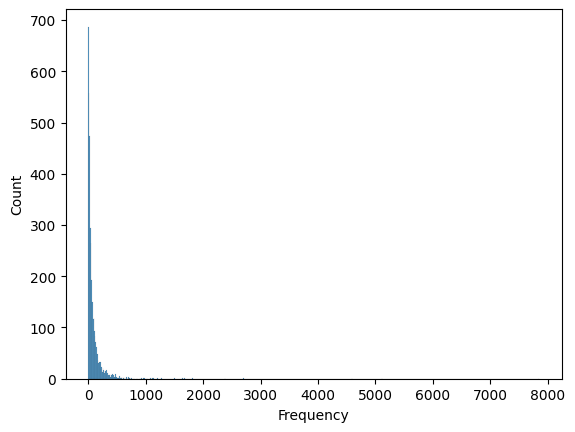
sns.histplot(rfm_df["Monetary"])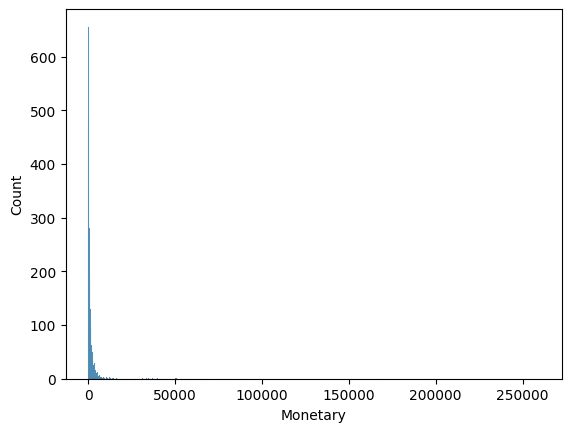
🡆 데이터가 굉장히 많이 치우쳐져 있는 것을 확인 가능
(Recency는 상대적으로 덜 치우쳐져 있음)
sns.histplot(rfm_df["Recency"])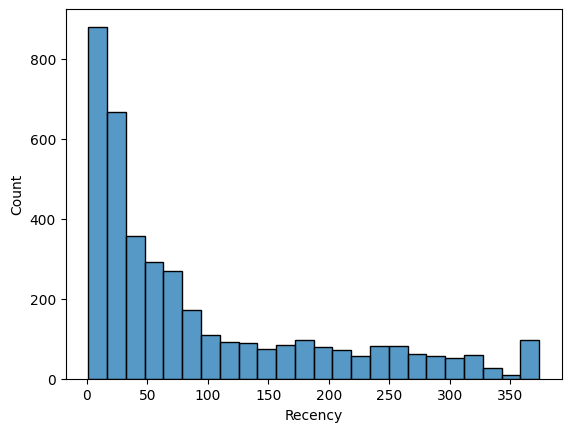
🡆 굉장히 많이 치우쳐져 있는 데이터를 그대로 쓰면 학습이 잘 안되기 때문에 정규화 해야 함
# 데이터 정규화
from sklearn.preprocessing import StandardScaler
std_sc = StandardScaler()
X_features = std_sc.fit_transform(rfm_df[["Recency", "Frequency", "Monetary"]])3. KMeans
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_clusters=3, random_state=42)
labels = kmeans.fit_predict(X_features)
rfm_df["label"] = labels
silhouette_score(X_features, labels)np.float64(0.5930190673437187)
🡆 숫자만 보면 괜찮다는 생각이 들 수 있지만 시각화해서 보면 다름
from kmeans_visaul import visualize_silhouette
visualize_silhouette([2,3,4,5,6], X_features)kmeans_visual은 강사님이 공유해주신
kmeans_visual.py파일!
파일 열어보면def visualize_silhouette(cluster_lists, X_features):함수 정의되어 있는데
이걸 불러와서 시각화에 이용함(꼭 파일 열어서 내용 읽어보기! → 매우 유용함)
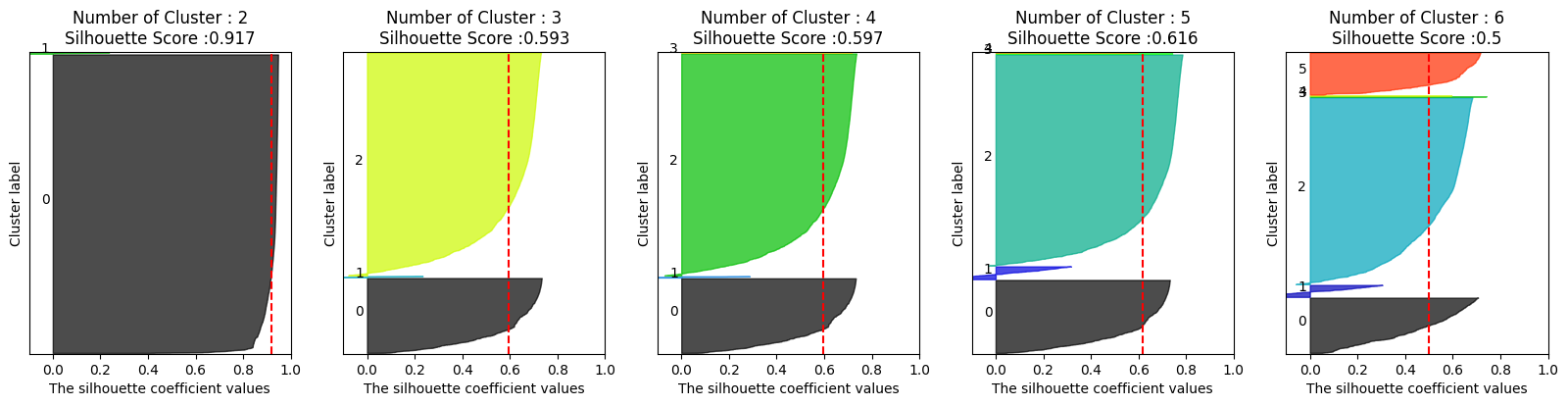
🡆 좋지 않은 형태임(cluster가 5일때 군집이 일정하지 않고 치우쳐 있음)
# log 스케일을 통한 추가 전처리
import numpy as np
rfm_df["Recency_log"] = np.log1p(rfm_df["Recency"])
rfm_df["Frequency_log"] = np.log1p(rfm_df["Frequency"])
rfm_df["Monetary_log"] = np.log1p(rfm_df["Monetary"])
X_features_2 = rfm_df[["Recency_log", "Frequency_log", "Monetary_log"]]
std_sc_2 = StandardScaler()
X_features_2_sc = std_sc_2.fit_transform(X_features_2)
visualize_silhouette([2,3,4,5,6], X_features_2_sc)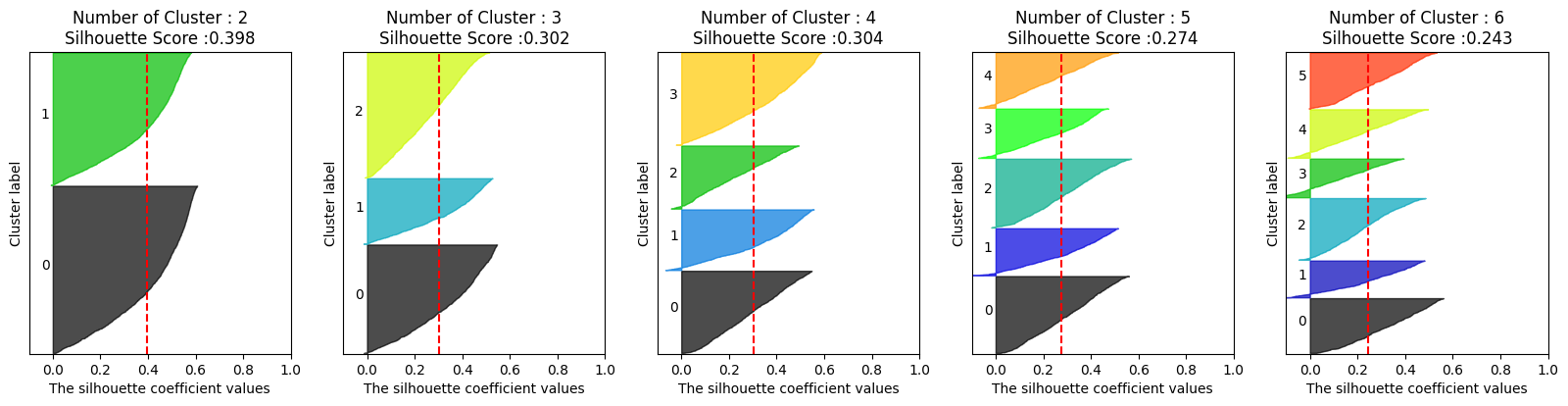
🡆 log로 추가 전처리 하니 군집이 훨씬 예뻐졌음
🡆 뭘 선택해야 하는지는 알 수 없음!
이 데이터를 생성한 조직이나 해당 도메인을 잘 알고 있는 사람이 각각의 군집에 대해 기술 통계나 데이터를 본 뒤 각 군집의 특성을 파악하고 군집화 군집이 몇 개일 때가 가장 적절한지 확인해야 함!
마무리
비지도 학습 중 대표적인 K-Means clustering에 대해서 알아보았습니다.
이 외에도 Gaussian Mixture Model(GMM), DBSCAN 등 다양한 비지도 학습들을 알아 볼 수 있으나 본 과정의 범위 내 가장 쉬운 알고리즘을 알려드렸습니다.
