목표
- 데이터 행 간 비교, WINDOW FUNCTION 알아보기
- WITH 구문 이해
- 그 외 주요한 함수 숙지 및 활용
WINDOW FUNCTION
- 모든 컬럼을 잃고 싶지 않을 때 사용
- 행과 행의 관계를 알기 쉽도록 해 줌
- 여러 행의 관계를 파악하기 위해 사용
- 분석함수 또는 순위 함수로 알려져 있음
정의
- 행과 행 간의 관계를 정의하기 위해서 제공되는 함수
역할
- 순위, 합계, 평균, 행 위치 등을 조작할 수 있음
특징
- 하나의 SELECT 구문에서 GROUP BY와 병행하여 사용할 수 없음
- 윈도우 함수로 인해 결과 건수가 줄어들지는 않음
- 윈도우 함수와 GROUP BY 구문은 둘 다 파티션(기준)을 분할한다는 의미에서 유사함
- 다른 함수와 달리 중첩해서 사용은 못하지만, 서브쿼리에는 사용할 수 있음
종류(총 4가지)
| 종류 | 함수 |
|---|---|
| 순위 | RANK, DENSE_RANK, ROW_NUMBER |
| 집계 | SUM, MAX, MIN, AVG, COUNT |
| 순서 | FIRST_VALUE, LAST_VALUE, LAG, LEAD |
| 비율 | RATIO_TO_REPROT, PERCENT_RANK, CUME_DIST, NTILE |
문법
- SELECT 절에서 사용
ROW_NUMBER() OVER(PARTITION BY 컬럼1 ORDER BY 컬럼2)- ROW_NUMBER 라는 윈도우 함수를 사용하고, 그 기준을 컬럼1로 , 정렬은 컬럼2로 지정한다는 뜻
- 다양한 윈도우 함수 사용을 통해 보다 용이한 데이터 핸들링 가능
# 윈도우 함수 기본 문법
SELECT WINDOW_FUNCTION () OVER([PARTITION BY 컬럼] [ORDER BY 컬럼])
FROM 테이블명
# PARTITION BY는 필수 아님
# ORDER BY는 필수임사용 예시
- 사용자별 채팅 텍스트 데이터
- 유저를 기준으로, 가장 마지막 일자의 CHAT_TEXT 데이터 살펴보기
| USER_ID | CHAT_TEXT | REVIEW_DATE |
|---|---|---|
| 피카츄 | 안녕안녕 | 2024-01-01 |
| 피카츄 | 배고파 | 2024-01-02 |
| 피카츄 | 심심해 | 2024-01-07 |
| 파이리 | 불닭최고 | 2024-01-01 |
| 파이리 | 족발최고 | 2024-01-02 |
| 꼬부기 | 엽떡최고 | 2024-01-01 |
| 꼬부기 | 진화하고싶다! | 2024-01-04 |
- 위 표에서 집계함수를 사용해 user_id별 가장 큰 날짜를 계산하면 아래와 같음
| USER_ID | MAX(REVIEW_DATE) |
|---|---|
| 피카츄 | 2024-01-07 |
| 파이리 | 2024-01-02 |
| 꼬부기 | 2024-01-04 |
# 일반 집계함수 사용 예
select user_id, MAX(review_date)
from 테이블
group by user_id→ 집계함수를 사용하게 되면, 우리는 CHAT_TEXT를 조회 할 수 없게 됨
🡆 CHAT_TEXT 를 같이 보고 싶을 때, 윈도우 함수를 사용
- 윈도우 함수를 사용하면, 결과가 아래와 같이 나올 수 있음
row_number() over(partition by USER_ID order by REVIEW_DATE desc )as rown- 해석: row_number 이라는 윈도우 함수를 사용하여, 유저 ID 를 기준으로 나누고, 날짜를 오름차순으로 하여 rown 이라는 컬럼으로 명명
| USER_ID | CHAT_TEXT | REVIEW_DATE | rown |
|---|---|---|---|
| 피카츄 | 안녕안녕 | 2024-01-01 | 3 |
| 피카츄 | 배고파 | 2024-01-02 | 2 |
| 피카츄 | 심심해 | 2024-01-07 | 1 |
| 파이리 | 불닭최고 | 2024-01-01 | 2 |
| 파이리 | 족발최고 | 2024-01-02 | 1 |
| 꼬부기 | 엽떡최고 | 2024-01-01 | 2 |
| 꼬부기 | 진화하고싶다! | 2024-01-04 | 1 |
→ PARTITION BY가 '피카츄 / 파이리 / 꼬부기'로 나눠서 순위 정할 수 있도록 함
→ ORDER BY가 시간이 큰 날이 rank 1 들어가도록 함
순위 예제
RANK ★★★
- 정의
- ORDER BY를 포함한 쿼리문에서 특정 컬럼의 순위를 구하는 함수
- PARTITION 내에서 순위를 구할 수도 있고 전체 데이터에 대한 순위를 구할 수도 있음
- 동일한 값에 대해서는 같은 순위를 부여하며 중간 순위를 비운 값이 출력
- 문법
RANK() OVER(PARTITION BY 컬럼1 ORDER BY 컬럼2)
- 예제
# 윈도우 함수 - RANK 함수 예제
select *,
rank() over(partition by JOB order by SALARY)
from basic.window1 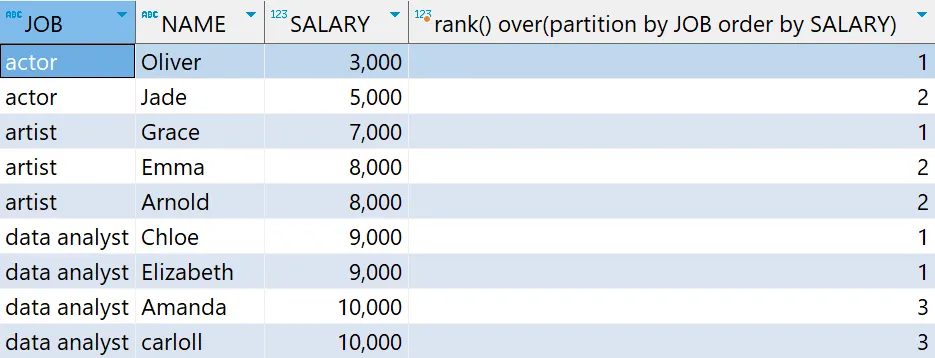
DENSE_RANK
- 정의
- RANK와 작동법은 동일
- 동일한 값에 대해서는 같은 순위를 부여하고 중간 순위를 비우지 않음
- 문법
DENSE_RANK() OVER(PARTITION BY 컬럼1 ORDER BY 컬럼2)
- 예제
# 윈도우 함수 - DENSE_RANK 함수 예제
select *,
dense_rank() over(partition by JOB order by SALARY)
from basic.window1 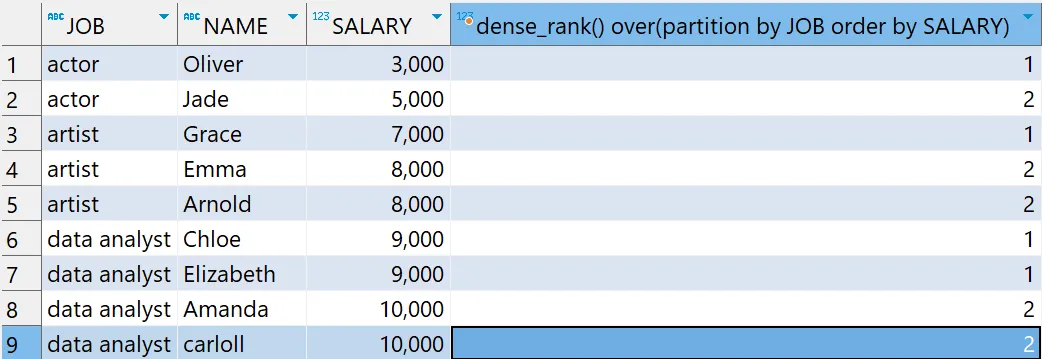
ROW_NUMBER ★★★
- 가장 많이 사용
- 정의
- 동일한 값이어도 고유한 순위를 부여
cf. RANK, DENSE_RANK는 동일한 값에 대해 동일 순위를 부여
- 동일한 값이어도 고유한 순위를 부여
- 문법
ROW_NUMBER() OVER(PARTITION BY 컬럼1 ORDER BY 컬럼2)
- 예시
# 윈도우 함수 - ROW_NUMBER 함수 예제
select *,
ROW_NUMBER() over(partition by JOB order by SALARY)
from basic.window1 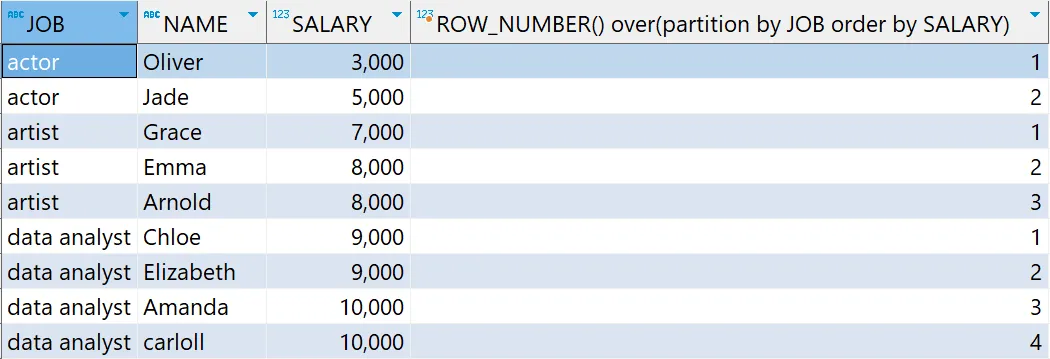
순서 예제
FIRST_VALUE
- 정의
- 파티션별 가장 먼저 나온 값을 구하여 출력
- 공동 등수를 인정하지 않고 처음 나온 행만 가져옴
- MIN함수를 쓰는 것과 동일한 결과
- 문법
FIRST_VALUE(컬럼1) OVER(PARTITION BY 컬럼2 ORDER BY 컬럼3)- FIRST_VALUE 다음에 오는 괄호 안에 컬럼명 꼭 들어가야 함!
- 예시
# 윈도우 함수 - FIRST_VALUE 함수 예제
select *,
first_value(NAME) over(partition by JOB order by SALARY)
from basic.window1 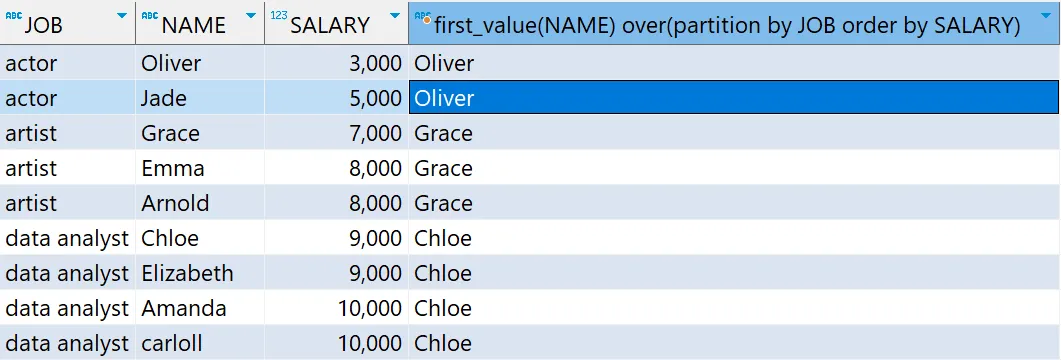
LAST_VALUE
- 정의
- 파티션별 가장 마지막에 나온 값을 구하여 출력
- 공동 등수를 인정하지 않고 나중에 나온 행만 가져옴
- MAX함수를 쓰는 것과 동일한 결과
- 문법
LAST_VALUE(컬럼1) OVER(PARTITION BY 컬럼2 ORDER BY 컬럼3)
- 예시
# 윈도우 함수 - LAST_VALUE 함수 예제
select *,
last_value(NAME) over(partition by JOB order by SALARY)
from basic.window1 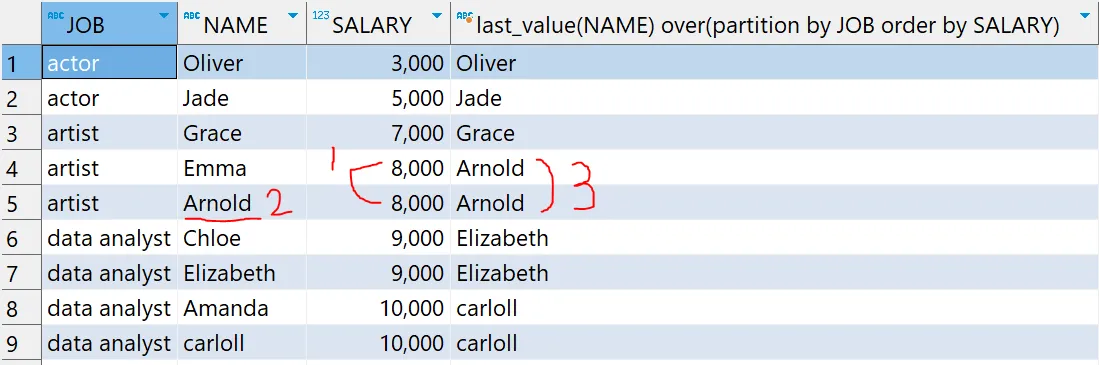
LAG ★★★
- 정의
- 이전 N번째의 행을 가져오는 함수
- N은 최대값으로 3을 가지며, 기본값은 1
- 가져올 행이 없을 경우 DEFAULT값을 지정
- NVL이나 ISNULL함수의 기능과 동일
- NVL: 오라클에서 사용하는 함수. COALESCE, IFNULL과 같은 기능.
LAG(expression,offset, default_value) OVER ( PARTITION BY partition_expression ORDER BY order_expresion ASC|DESC )Q. 안녕하세요~ SQL 세션 오늘 설명에서 LAG 함수 n은 최대값으로 3을 가진다고 하셨는데 dbeaver에서 써 보니까 4 이상의 값도 들어가서 문의드려요!
A. mysql 버전에 따라 다르기도 하고, 계속 업데이트 되고 있어서 만약 run 된다면 그대로 인지하고 사용하셔도 됩니다.
The offset is the number of rows to go back from the current row. The offset must be zero or a positive integer number. If offset is zero, then the LAG() function returns the current row. If you don’t provide the offset argument, it defaults to 1.
- 문법
LAG(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)- 또는
LAG(컬럼1, 숫자) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3) # 숫자는 최대 3으로 3번째 전 행을 의미
- 예시
# 윈도우 함수 - LAG 함수 예제
select *
, LAG(SALARY) OVER (ORDER BY NAME) as PREV_SAL
from basic.window1 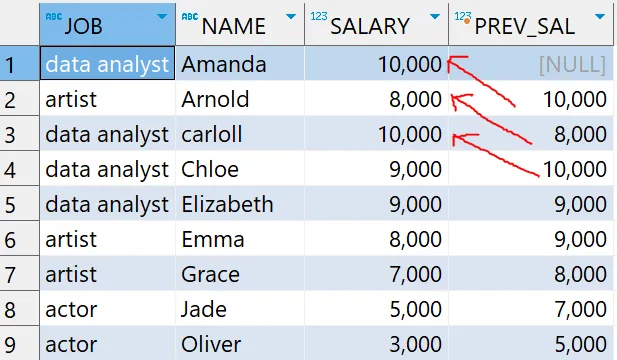
# 윈도우 함수 - LAG 함수 예제2: 2번째 전 값 구하기
select *
, LAG(SALARY,2) OVER (ORDER BY NAME) as PREV_SAL
from basic.window1 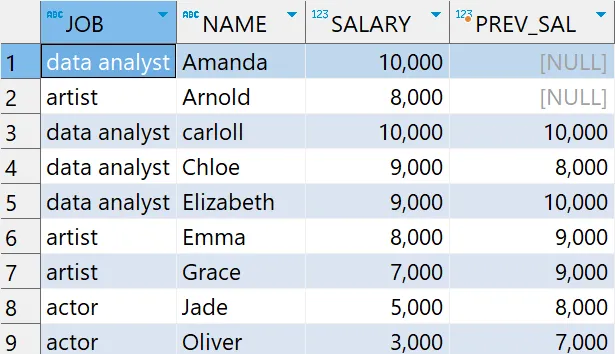
# LAG 추가 예제
SELECT
*
, LAG (salary) OVER (PARTITION BY job ORDER BY name) AS "e.g."
FROM
basic.window1 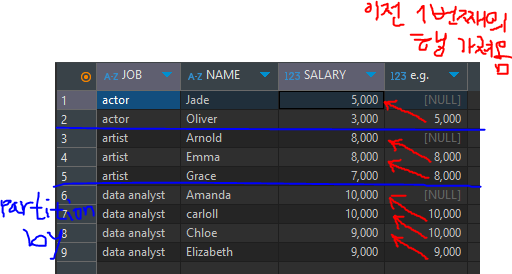
LEAD ★★★
- 정의
- 이후 N행의 값을 가져오는 함수
- N은 최대값으로 3을 가지며, 기본값은 1
- 문법
LEAD(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)- 또는
LEAD(컬럼1, 숫자) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3) # 숫자는 최대 3으로 3번째 후 행을 의미
- 예시
# 윈도우 함수 - LEAD 함수 예제
select *
, LEAD(SALARY) OVER (ORDER BY NAME) as PREV_SAL
from basic.window1 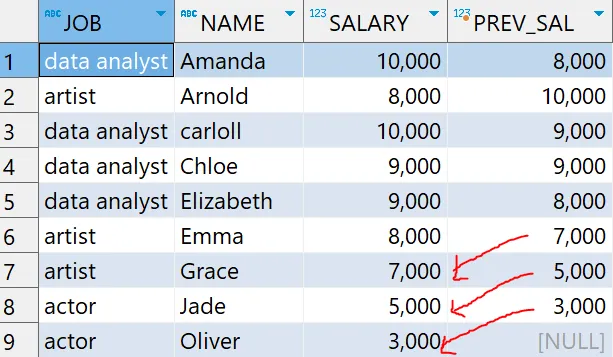
# 윈도우 함수 - LEAD 함수 예제2: 2번째 후 값 구하기
select *
, LEAD(SALARY,2) OVER (ORDER BY NAME) as PREV_SAL
from basic.window1 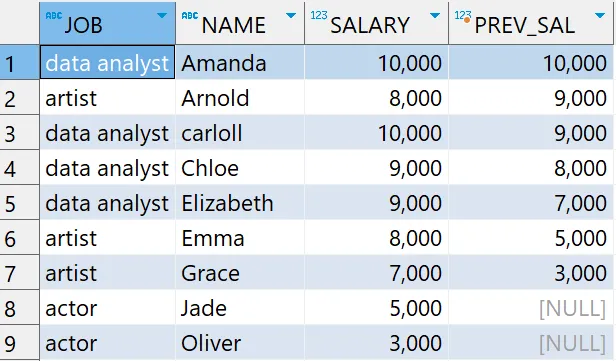
비율 예제
RATIO_TO_REPORT
- 정의
- 파티션 내 전체 SUM값에 대한 행별 백분율을 소수점으로 출력
- 결과값은 0~1 사이이며, 비율의 합은 1
- MySQL 에서는 지원하지 않음
- 문법(Oracle)
RATIO_TO_REPORT(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)
PERCENT_RANK ★★★
- 정의
- 파티션별로 가장 먼저 나오는 값을 0, 가장 마지막에 나오는 값을 1로 정하여 행 순서별 백분율을 출력
- 구간을 나누어 백분율로 출력
- PERCENT_RANK 함수를 활용하면 상위 퍼센트를 구할 수 있다. PERCENT_RANK는 RANK 결과값의 백분율 순위를 계산해준다. 해석하자면, 자신보다 아래 전체의 몇 퍼센트가 있다는 의미이다.(less than)
- 문법
PERCENT_RANK() OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2)
PERCENT_RANK Function
For a specified row, PERCENT_RANK() calculates the rank of that row minus one, divided by 1 less than the number of rows in the evaluated partition or query result set:
(rank - 1) / (total_rows - 1)
In this formula,rankis the rank of a specified row andtotal_rowsis the number of rows being evaluated.
The PERCENT_RANK() function always returns zero for the first row in a partition or result set. The repeated column values will receive the same PERCENT_RANK() value.
PERCENT_RANK 창 함수
- 예시
# 윈도우 함수 - PERCENT_RANK 함수 예제
select *
, PERCENT_RANK() OVER (partition by JOB order BY SALARY)
from basic.window1 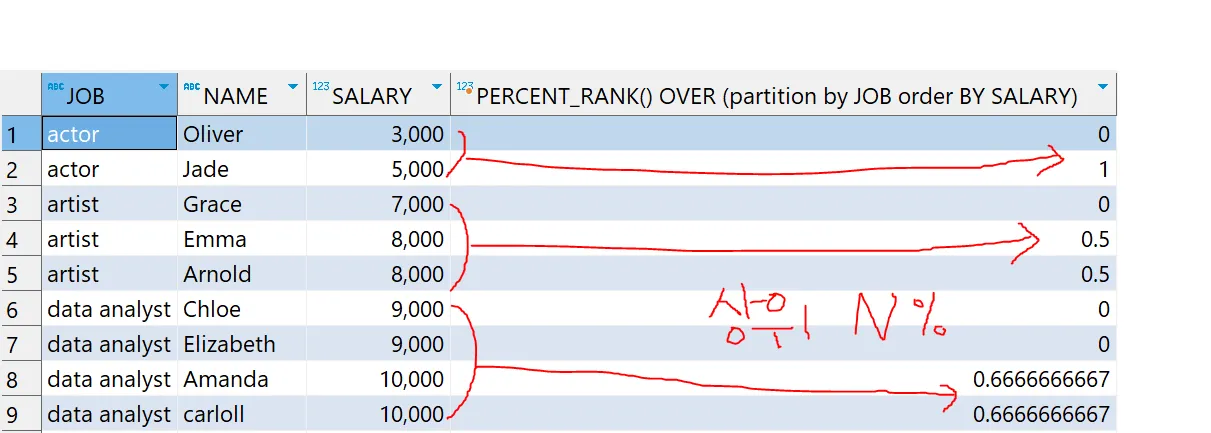
※ 평균과 중앙값은 세트로 다녀야 좋음 ※
CUME_DIST
- 정의
- 파티션별 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율을 출력
- 문법
CUME_DIST() OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2)
- 예시
# 윈도우 함수 - CUME_DIST 함수 예제
select *
, cume_dist() OVER (partition by JOB order BY SALARY)
from basic.window1 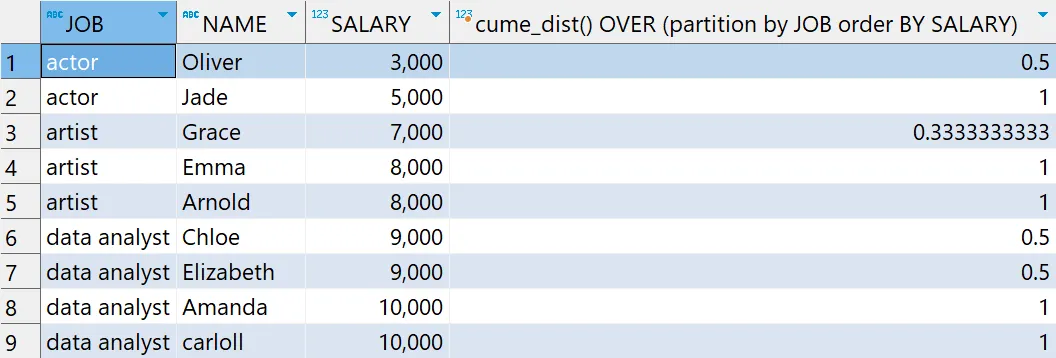
NTILE
- 정의
- 파티션별 전체 건수를 계산한 값으로 N등분한 결과를 출력
- ROW_NUM과 결과값 같음(단, N을 우리가 정할 수 있음)
- 문법
NTILE(숫자) OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2)
- 예시
# 윈도우 함수 - CUME_DIST 함수 예제
select *
, cume_dist() OVER (partition by JOB order BY SALARY)
from basic.window1 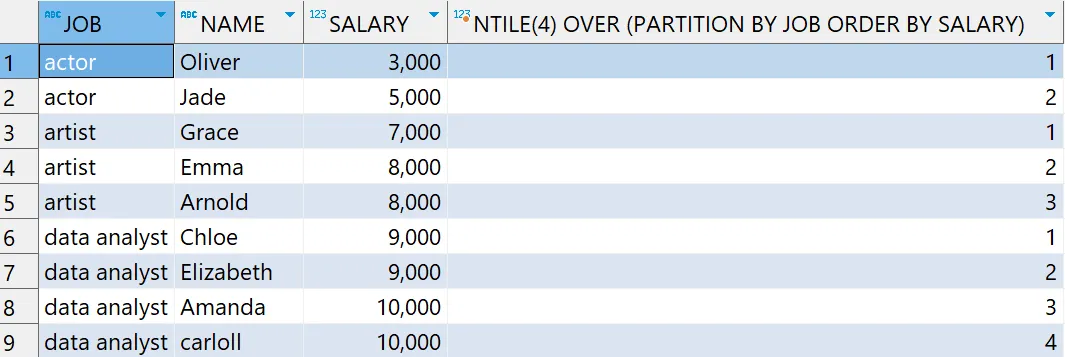
WITH
- 하나의 테이블이 여러 번 필요할 때
WITH 구문: 테이블 재사용
| 구분 | 상세 |
|---|---|
| 정의 | SQL 구문에서 사용되는 임시테이블(가상테이블) |
| 사용 이유 | 쿼리의 가독성 및 쿼리성능 향상 |
| 특징&장점 | ✔️ 임시테이블의 개념을 가지며, 작성한 쿼리 내에서만 실행가능 |
| ✔️ 하나의 SQL 구문에서 여러개의 WITH 문 선언 가능 | |
| ✔️ 하나의 테이블에 대한 여러 조회가 필요한 경우, WITH절 사용으로 1회 조회 및 선언하게 되어 그 가독성 및 쿼리성능이 높음 | |
| ✔️ 복잡한 연산을 보다 효율적으로 처리(JOIN, UNION 등의 결과를 WITH 문에 저장) | |
| 문법 | WITH 임시테이블명 AS ( |
| SELECT 컬럼1, 컬럼2, .. | |
| FROM 테이블명 | |
| ) | |
| SELECT 임시테이블에서 불러온 컬럼 중 필요한 컬럼 | |
| FROM 임시테이블명 |
예시
# with 구문 활용 예시1
with soso as # with 뒤쪽에 임시테이블명 지정
( select etc_str2, etc_str1, count(distinct game_actor_id)as actor_cnt
from basic.users
group by etc_str2, etc_str1 # 임시테이블을 만들 때 활용할 테이블
)
select *
from soso # WITH절에서 지정한 임시테이블명
;
#####################################################################
# with 구문 활용 예시2 - 경험치가 가장 많은 캐릭터 정보 조회하기
with dodo as # with 뒤쪽에 임시테이블명 지정
( select *
from basic.users
)
select *
from( select max(exp)as maxexp
from dodo
)as a
inner join
( select *
from dodo
)as b
on a.maxexp=b.exp
;
#####################################################################
# with 구문 활용 예시3 - 다중 with 구문
with gogo as # 첫번째 with 절
( select game_account_id, exp
from basic.users
where `level` >50
),
hoho as # 두번째 with 절, with 구문은 처음 한번만 작성합니다.
( select distinct game_account_id, pay_amount, approved_at
from basic.payment
where pay_type='CARD'
) # 이 부분에서 with 구문이 종료됩니다.
select case when b.game_account_id is null then '결제x' else '결제o' end as gb
, count(distinct a.game_account_id)as accnt
from gogo as a
left join hoho as b
on a.game_account_id=b.game_account_id
group by case when b.game_account_id is null then '결제x' else '결제o' end
;그 외 중요한 함수
- 놓치면 안 될 중요한 함수
STRING 함수
| 함수 이름 | 정의 | 문법 | 결과 |
|---|---|---|---|
| 🔥CONCAT | 문자열을 병합할 때 | CONCAT(’피카츄’,’라이츄’) | 피카츄라이츄 |
| 🔥SUBSTRING | 문자열을 자를 때 | SUBSTRING(’피카츄라이츄’,2,4) | 카츄라 |
| 🔥SUBSTRING_INDEX | 문자열을 특정 구분기호를 통해 출력할 때 | SUBSTRING_INDEX(’피카츄.라이츄’, ’.’,1) | 피카츄 |
| REVERSE | 문자열을 뒤집을 때 | REVERSE(’피카츄’) | 츄카피 |
| 특정 문자를 찾고자 할 때도 이용 | |||
| LEFT, RIGHT | 문자열을 기준으로부터 N개 출력 | LEFT(’피카츄라이츄1234’, 5) | 피카츄라이 |
| RIGHT(’피카츄라이츄1234’, 5) | 츄1234 |
MATH 함수
| 함수 이름 | 정의 | 문법 | 결과 |
|---|---|---|---|
| 🔥 ABS | 절대값을 출력합니다. | ABS(-1) | 1 |
| 🔥 ROUND | 숫자를 소수점 이하 자릿수에서 올림하여 출력합니다. | ROUND(2.77,1) | 2.8 |
| CEILING | 소수점을 올림하여 출력합니다. | CEILING(2.77) | 3 |
| FLOOR | 소수점을 내림하여 출력합니다. | FLOOR(2.77) | 2 |
| TRUNCATE | 숫자를 소수점 이하 자릿수에서 버림하여 출력합니다. | TRUNCATE(2.77,1) | 2.7 |
| RAND | 지정 숫자 범위 중 하나를 랜덤하게 출력합니다. | ROUND(RAND()*100, 0) → 0~100 사이 랜덤값 | 랜덤출력! |
날짜 함수
| 함수 이름 | 정의 | 문법 | 결과 |
|---|---|---|---|
| 🔥 NOW | 현재시간과 날짜를 출력 | NOW() | 현재시간출력 |
| SYSDATE | SYSDATE() | ||
| CURRENT_TIMESTAMP | CURRENT_TIMESTAMP | ||
| 🔥DATE_ADD | 날짜에서 기준값 만큼 덧셈하여 출력 | DATE_ADD(’2024-04-03’, INTERVAL 1 DAY) | 2024-04-04 |
| 기준값 : YEAR, MONTH, DAY, HOUR, MINUTE, SECOND | |||
| 🔥DATE_SUB | 날짜에서 기준값 만큼 뺄셈하여 출력 | DATE_SUB(’2024-04-03’, INTERVAL 1 DAY) | 2024-04-02 |
| 기준값 : YEAR, MONTH, DAY, HOUR, MINUTE, SECOND | |||
| 🔥DATEDIFF | 두 날짜를 뺄셈하여 출력 | DATEDIFF('2024-04-03','2024-04-01') | 2 |
| 🔥DATE_FORMAT | 날짜를 형식에 맞게 출력 | DATE_FORMAT(now(),'%Y-%m-%d') | 현재 시간이 yyyy-mm-dd로 출력 |
| 🔥 UNIX_TIMESTAMP | 현재시간을 UNIXTIME 으로 구함 | unix_timestamp() | 정수출력 |
| CURDATE | 현재 날짜 출력 | CURDATE() | 현재날짜출력 |
| CURRENT_DATE | CURRENT_DATE() | ||
| CURTIME | 현재 시간 출력 | CURTIME() | 현재시간출력 |
| CURRENT_TIME | CURRENT_TIME() | ||
| YEAR | 날짜의 연도 출력 | year('2024-04-01') | 2024 |
| MONTH | 날짜의 월 출력 | month('2024-04-01') | 4 |
| DAY | 날짜의 일 출력 | day('2024-04-01') | 1 |
UNIXTIME(Unix Timestamp)
- 운영체제 유닉스 등 컴퓨터에서 사용하는 시간 표현 방식
- UTC(협정 세계시)기준 1970년 1월 1일 00:00:00로부터 몇 초가 지났는지를 나타낸 것
- '1970년 1월 1일 00:00:00' == Unix Epoch
- 현제 살고 있는 위치와 상관없이 어디서나 같으므로 컴퓨터에서 시간 기준으로 두기 좋음
