전체 강의 개요
- Python 이 어떠한 언어인지 이해
- 라이브러리의 개념을 이해하고 실습
- kaggle dataset 을 활용한 EDA 를 진행하고, 다양한 라이브러리를 학습
커리큘럼
- 1회차
- python, 라이브러리 개념학습 및 실습환경 준비
- 2회차
- python 활용 테이블 결합
- 3회차
- python 활용 데이터 이상치, 결측치 처리
- 4회차
- python 활용 데이터 시각화
- 개인 과제
- 5회차
- 그 외 주요 라이브러리 살펴보기
- 6회차
- 과제 해설
1회차 목표
- python 언어적 특성을 이해
- SQL과의 차이점
- python 에서의 Library개념에 대해 이해
- Library 지원 함수를 숙지
- 데이터 분석의 기본이 되는 Pandas Library를 학습하고, 활용
Python 언어적 특성 이해
SQL은 통으로, Python은 하나하나
-
SQL, Python은 모두 데이터에 접근하기 위한 QUERY
- SQL이 먼저 상용화 되었으며(1970년대), 이를 개선 및 응용하기 위해 네덜란드의 소프트웨어 개발자가 Python을 개발
- 두 언어는 크게 언어적 차이와 응용여부에 차이점이 존재
-
장/단점
| 구분 | 🔴 SQL | 🔵 Python |
|---|---|---|
| 언어 | 절차지향 언어→통으로! | 객체지향 언어→한줄한줄! |
| 역사 | 개발: 1970 년 | 개발: 1989 년 |
| 표준화: 1986 년 | 표준화: 1991 년 | |
| 장점 | select, from 등의 구문 등 하나의 구문으로 처리되므로, 실제 컴퓨터가 질의를 어떻게 처리하는 지 이해할 필요가 없다는 점에서 이해가 쉬움 | 한 줄(셀) 단위로 실행되어, 트러블 슈팅이 용이(틀린 셀만 다시 작업) |
| 다양한 Library 가 지원되어, 데이터 시각화 , 통계적 의미, 모델링, 자동화 등 데이터 핸들링을 자유롭게 할 수 있음 | ||
| 단점 | 테이블 생성, 삭제, 복제, 치환 은 가능하지만, 시각화 등 Library 지원이 되지 않아 데이터 핸들링시 한계점 존재 | 같은 QUERY 구문을 수행한다고 했을 때, SQL 보다 느리게 출력될 수 있음 |
| 실제 쿼리 컴파일(검사)시 트러블슈팅이 오래 걸릴 수 있음 |
- 실제 현업에서는 파가 나뉨: 🔴SQL파 VS 🔵Python파
- 우리는 프로젝트를 수행하며, 두 언어 모두 놓치지 않는 것으로 방향을 잡을 것
- 데이터를 파헤치기 위해서는 Python을 놓을 수 없기 때문
객체지향 프로그래밍
- 모든 데이터를 하나의 객체로 취급해서 프로그래밍하는 방법
- 각 객체들끼리 스스로 상호작용하여 프로그래밍 진행
Python이라는 언어가 작동할 수 있는 환경과, 데이터 응용 분야
- Python Enviroment 를 이해하고, Data Management 와 Data Visualization을 집중적으로 학습할 예정
Python에서의 Library
알고리즘의 늪
- 어렵고도 어려운 알고리즘을 회피할 수 있는 방법이 바로 Library
- 라이브러리란 “우리가 자주 쓰는 함수들을 모아놓은 묶음” 으로 이해 가능
- 예쁘게 정리되어 있는 라이브러리를 간단히 호출만 함으로써, 복잡한 연산도 쉽게 한 줄로 해결할 수 있음
Library 호출하기
-
import pandas as pd- pandas 라는 라이브러리(모듈)를 호출(import) 하고 그 이름을 pd 로 줄여서 명명한다는 뜻
- pandas 라는 라이브러리 내 모든 함수를 불러오는 것
-
from 으로 시작하는 구문
- 라이브러리 중 특정 함수만 사용하고 싶을 때 사용
-
from matplotlib.pyplot as plt- matplotlib 의 pyplot 함수만 가져오고 이름을 plt 로 줄여서 명명한다는 뜻
import pandas as pd # pandas 는 6글자라서 pd 로 줄여 명령
import numpy as np
import time
from matplotlib.pyplot as plt
# Python은 SQL과 달리 맨 첫 줄부터
# 하나하나씩 실행됨!
# 한 줄이라도 틀리면 다음 줄 실행 안 되니 주의Pandas
- 데이터를 다루기 위한 가장 기본적인 라이브러리
Pandas는 왜 사용해야 할까요?
-
역사
- 계량 경제학 용어인 Panel Data 와 Analysis 의 합성어
- 금융회사에 다니고 있던 Wes Mckinney에 의해 2008년 설계된 라이브러리
- Numpy를 기반으로 개발되었기에, 해당 라이브러리와도 호환성이 좋음
-
목적
- 분석을 위한 함수 제공
- 서로 다른 여러 가지 유형의 데이터를 시리즈와 데이터 프레임이라는 공통의 포맷으로 정리하여 쉽고 빠른 연산 가능
- json, html, csv, hdf5, sql 모두 DataFrame으로 통일해서 표현할 수 있음
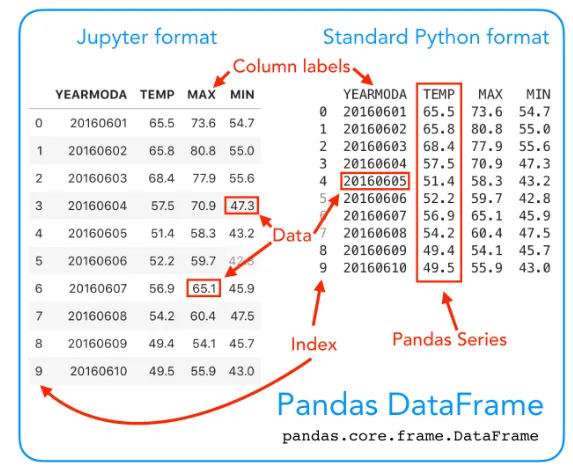
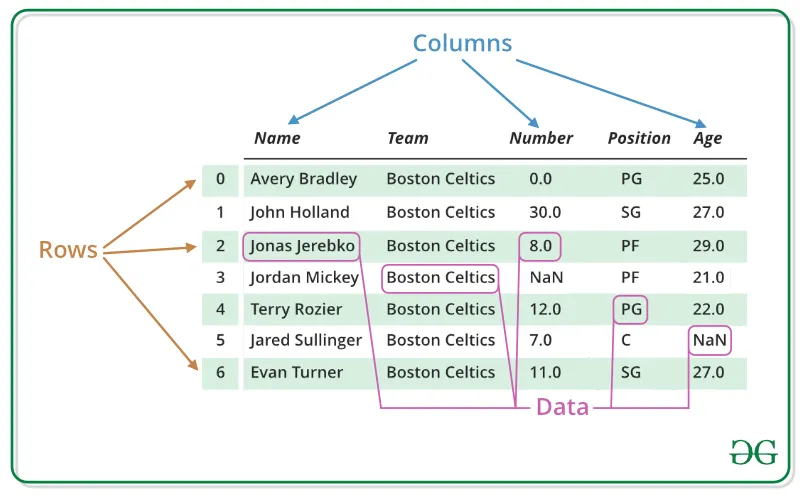
DataFrame
- 통계와 머신러닝 모델에서 가장 기본이 되는(스프레드시트와 같은) 테이블 형태의 데이터 구조
- 기본적으로 행과 열로 구성된 이차원의 행렬을 뜻함
- 파이썬 및 R 에서 사용하는 특정 데이터 포맷
Pandas Series
- 테이블의 열과 같으며, 모든 유형의 데이터를 보유하는 1차원 배열
- Series의 개념 놓치면 안 됨!
그 외 주요 Library
| Library 이름 | 핵심 요약 |
|---|---|
| Pandas | ☑️ Pandas는 R의 dataframe 데이터 타입을 참고하여 만든 것으로 pandas dataframe 이라고 부름 |
| ☑️Pandas의 dataframe: 테이블 형식의 데이터로 열(column), 행(row), 인덱스(index) 로 구성 | |
| ☑️ 리스트, 튜플, 사전 타입의 형태로 데이터를 보관 | |
| ▶️ import pandas as pd | |
| Numpy | ☑️ 파이썬의 리스트를 확장한 다차원 배열 제공 |
| ☑️ 난수생성, 푸리에변환, 행렬연산, 통계분석을 지원 | |
| ☑️ 일반적으로 Scipy, Pandas, matplotlib 등 다른 패키지와 함께 쓰임 | |
| ▶️ import numpy as np | |
| matplotlib | ☑️ Data Visualization 분야에서의 대표적인 파이썬 라이브러리 |
| ▶️ import matplotlib.pyplot as plt | |
| Seaborn | ☑️ matplotlib 을 기반으로 그래픽과 기능을 추가한 라이브러리 |
| ▶️ import seaborn as sns | |
| Scikit-Learn | ☑️ 머신러닝을 시작할 때 제일 먼저 알아야 하는 파이썬 라이브러리 |
| ☑️ 지도 학습, 비지도 학습, 모델 선택 및 평가, 등 라이브러리 6개로 구성 | |
| Data Pre-Processing, Dimensions Reduction, Regression, Classification, Clustering, Model Selection | |
| 📌지도 학습 : X 변수가 주어 졌을 때 , Y 변수를 추정해내는 방법 (새로운 데이터가 나왔을때 진화가 어려움) | |
| 📌비지도 학습 : Y 가 없는 경우, 군집화, 이상치 검출 | |
| 📌모델 선택 및 평가: 모델 과 Data를 fit에 넣어서 예측 모형을 만드는 과정예측모형을 predict에 넣어서 예측 | |
| ▶️ import sklearn | |
| PyGWalker | ☑️ Kanaries에서 배포한 태블로 스타일의 파이썬 패키지 |
| ☑️ 정제된 데이터를 기반으로 데이터 EDA 를 손쉽게 경험할 수 있음 | |
| ▶️ import pygwalker as pyg | |
| Selenium | ☑️ 웹 브라우저(크롬, 파이어 폭스, IE, 사파리 등등)를 콘트롤하는 Framework |
| ☑️ Webdriver라는 API를 통해 웹 브라우저를 제어 | |
| SciPy | ☑️ 과학, 수학, 엔지니어링 등에 사용되는 고급 계산 기능을 제공하는 Python 라이브러리 |
| ☑️선형 대수, 통계, 신호 처리, 최적화 등 다양한 분야의 기능 제공 | |
| ▶️ import scipy | |
| TensorFlow | ☑️ 구글 브레인팀이 연구와 제품개발을 목적으로 만든 머신러닝 라이브러리 |
| ☑️ 수치계산 및 대규모 머신러닝(이미지 인식, 자연어 처리 등) 위한 오픈소스 라이브러리 | |
| ▶️ 설치 방법 | |
| ※ TensorFlow는 중요하니까 따로 또 이야기하기로 해요 |
Data EDA
Magic command를 횔용한 셀 실행시간 확인
- 개념
- Magic command는 IPython kernel에서 제공되는 명령어로 %, %% 키워드를 사용하여 실행할 수 있음
- 특징
- 주피터 노트북에서 지원하는 매직 커맨드로, 셀 가장 위쪽에 작성해야 함
- CPU time
- CPU 가 코드를 실행하는데 걸린 시간
- Wall clock time
- 실제 코드를 실행하는 데 걸린 시간
- 소요시간 측정
- %time 뒤에 나오는 한줄 커맨드 소요시간
- %timeit 뒤에 나오는 한줄 커맨드 반복수행후 (iteration) 평균 소요시간
- %%time 뒤에 나오는 셀 전체 수행 후 소요시간
- %%timeit 뒤에 나오는 셀 전체 수행 후 평균 소요시간
%%time
sum=0
for x in range(10000000) :
sum=sum+x
print("1부터 1000만까지 합 :",sum)코드 핵심요약
# pandas 라이브러리를 활용한 csv 파일 읽기
df = pd.read_csv("xxxx.csv")
# 테이블 확인하기
display(df, df2, df3)
# 처음 5줄만 출력하기
#df2.head()
# 마지막 5줄만 출력하기
#df2.tail()
# 각 테이블의 행(가로) 길이 파악하기
len(df)
# shape: 테이블의 행과 열의 개수를 반환
df.shape
# dtypes: 테이블 내 컬럼타입(문자형, 숫자형, 배열 등) 확인
df.dtypes
# columns: 테이블 내 컬럼 확인
df.columns
# values: 테이블 내 각 행들을 배열 형태로 확인
df.values
# 테이블 기본 구조 한눈에 확인하기
df.info()
# 전체 행 개수, 평균, 표준편차, 최솟값, 사분위수, 최댓값 확인
df2.describe()
#컬럼별로 결측치(데이터가 없는) 확인하기
df.isnull().sum()
# 특정 컬럼 1개 가져오기
#방법1: 속성. 사용
df.Category
#방법2: [] 연산자 사용 → 가장 많이 사용됨
df['Category']
#방법3: iloc 사용
# : 은 모든 행을 가져오겠다는 의미이며 dataframe 의 인덱스 번호 4번(카테고리)컬럼을 가져오겠다는 의미
df.iloc[:,4]
# 특정 컬럼 여러개 가져오기
#방법1: [[]] 연산자 사용
# []를 하나 사용하면 결과값이 series 형태로 반환되어 key error 가 발생되며, [[]] 는 dataframe 으로 반환되어 에러가 나지 않습니다.
df[['Category','Selling Price']]
#방법2: iloc 사용
# : 은 모든 행을 가져오겠다는 의미이며 dataframe 의 인덱스 번호 4번,7번 컬럼을 가져오겠다는 의미
df.iloc[:,[4,7]]
# 특정 컬럼 버리기
# axis=0 은 인덱스 기준, 1은 컬럼 기준 삭제를 의미
# inplace=True 는 원본을 변경하겠다는 의미, False 의 경우 원본테이블은 변경되지 않음
df3.drop('Interaction type', axis=1, inplace=True)
# 조건에 부합하는 데이터 가져오기1
# 조건에 만족하는 행은 정상출력 ,아닌 행은 NaN 으로 반환
df2.where(df2['Age']>50)
# 조건에 부합하는 데이터 가져오기2
# true, false의 개념이 아닌 조건에 부합하는 데이터만 슬라이싱하여 가져오고 싶을 때
# mask 메서드로 불립니다. 이름은 반드시 mask 일 필요가 없습니다.
mask = ((df2['Age']>50) & (df2['Gender']=='Male'))
df2[mask]
# 데이터 그루핑- 기준 1개
df2.groupby('Gender')['Customer ID'].count()
# 데이터 그루핑- 기준 여러개
df2.groupby(['Gender','Location'])['Customer ID'].count()
# 데이터 count 와 nunique(distinct, 중복제거) 차이
df2.groupby('Location')['Age'].count()
df2.groupby('Location')['Age'].nunique()DATA EDA with python
chapter 1. python과 라이브러리의 이해
1-1. 라이브러리 import
import pandas as pd
import numpy as np
import time
# from PIL import Image
# 튜터님이 이미지 넣으려고 추가로 import한 부분이라
# 실습할 내용과는 관계 없음1-2. 라이브러리 지원 함수 살펴보기
- df. 하고 Tab 누르면 제공되는 function 목록 볼 수 있음
- 자동완성 켜 두었으면 df.만 입력하면 바로 목록 나옴
Magic command를 횔용한 셀 실행시간 확인
%%time
sum = 0
for x in range(10000000):
sum += x
print(f"1부터 1000만까지 합: {sum}")
# 실행 결과:
# 1부터 1000만까지 합: 49999995000000
# CPU times: total: 984 ms
# Wall time: 1.1 schapter 2. Pandas를 활용한 EDA 시작
2-1. DataFrame 만들기
- pandas 라이브러리를 이용한 DataFrame 만들기: List 활용
data1 = [['Choi', 22], ['Kim', 48], ['Joo', 32]]
df4 = pd.DataFrame(data1, columns=['Name', 'Age'])- pandas 라이브러리를 이용한 DataFrame 만들기: Dictornary 활용
data2 = {'Name': ['Choi', 'Kim', 'Joo'], 'Age': [22, 48, 32]}
df5 = pd.DataFrame(data2)2-2. CSV 파일을 통한 테이블 LOAD
- pandas 라이브러리를 활용한 csv 파일 읽기
df = pd.read_csv("product_details.csv")
df2 = pd.read_csv("customer_details.csv")
df3 = pd.read_csv("E-commerece sales data 2024.csv")2-3. 테이블 확인하기
display(df, df2, df3)- 하나의 테이블을 가져올 경우 display 사용하지 않고 바로 호출 가능
- 처음 5줄만 출력하기
df2.head()
- 마지막 5줄만 확인하기
df2.tail()
- 처음 5줄만 출력하기
POINT
- 데이터를 로드해올 때 서두르지 말 것
- 데이터가 어떻게 생겼는지 먼저 알고 들어갈 것
- 데이터를 모르면 데이터 분석이 안 됨
- 모델을 구축하는 것도 좋지만 '어떤 데이터를 input으로 받아들이는지' 알고 들어가야 함
- 내가 분석하고자 하는/학습하고자 하는/끌어오고자 하는 데이터가 어떤 모양인지 반드시 먼저 확인하고 코드 작성하기
- 데이터가 어떤 성격인지 알려면 데이터의 feature(특징 = 컬럼)이 무엇으로 이루어져 있는지 알아야 함
- 기술이 고도화되면서 인간적인 능력이 더 중요해졌음 → 아이디어 싸움!
- 분석 진입 전 전략이 중요
2-4. 테이블 구조 파악하기
- 각 테이블의 행(가로) 길이 파악하기
len(df), len(df2), len(df3)- 테이블의 데이터 구조를 파악하는 다양한 방법
- shape
- 테이블 행과 열의 개수 반환
- dtypes
- 테이블 내 컬럼 타입(문자열, 숫자열, 배열 등) 확인
- columns
- 테이블 내 컬럼 확인
- values
- 테이블 내 각 행들을 배열 형태로 확인
- shape
"테이블 열과 행 개수", df.shape, "테이블 컬럼 타입", df.dtypes, "테이블 컬럼 확인", df.columns, "테이블 행 상세확인", df.values- 테이블 컬럼을 리스트로 확인하기
df.columns.to_list()- 테이블 기본 구조 한눈에 확인하기
- 컬럼의 타입과 결측치 데이터 타입 확인 가능
df.info()- 테이블 행렬전환:
df.T- T는 transpose임
- 전체 행 개수, 평균, 표준편차, 최솟값, 사분위수, 최댓값 확인
- 표준편차(standard deviation)
- 분산을 제곱근한 것
- 편차들(deviations)의 제곱합(SS, sum of square)에서 얻어진 값의 평균치인 분산의 성질로부터 다시 제곱근해서 원래 단위로 만들어줌으로써 얻게 됨
- 평균에서 얼마나 멀리 떨어져 있는지(각 데이터가 얼마나 흩어져 있는지) 확인하기 위해 사용
- 사분위수(Quartile)
- 측정값을 낮은 순에서 높은 순으로 정렬한 후 4등분 했을 때 각 등위에 해당하는 값
- 통계의 변량을 도수 분포로 정리하였을 때 적은 것으로부터 1/4, 1/2, 3/4 자리의 변량값
- 임의의 확률변수 축에서 확률분포를 4등분하는 값의 조합
- 표준편차(standard deviation)
df2.describe()2-5. 테이블 결측치 확인하기
- 컬럼별로 결측치(데이터가 없는/데이터에 값이 없는 것) 확인하기
df.isna().sum()
df.isnull().sum() # 동일한 기능2-6. 특정 컬럼 가져오기
컬럼 1개 가져오기
- with dot notation
- 추천하지 않는 방법임
- 이유는 여기
- 추천하지 않는 방법임
# 속성. 사용
df.Category- with the brackets
# [] 연산자 사용
df['Category']- iloc(Integer location) 사용
- 행 번호(row number)로 선택하는 방법
- cf.
.loc: label이나 조건 표현으로 선택
- cf.
- 행 번호(row number)로 선택하는 방법
df.iloc[:,4]
# :은 모든 행을 가져오겠다는 의미
# 4는 DataFrame의 인덱스 번호 4번
# == 카테고리 컬럼을 가져오겠다는 의미컬럼 여러 개 가져오기
[[]]연산자 사용
df[['Category', 'Selling Price']]
# []를 하나 사용하면 결과값이 Series 형태로 반환되어
# key error가 발생
# [[]]는 DataFrame으로 반환되어 에러가 나지 않음- iloc 사용
df.iloc[:, [4,7]]
# :은 모든 행을 가져오겠다는 의미
# [4,7]은 DataFrame의 인덱스 번호
# 4번, 7번 컬럼을 가져오겠다는 의미2-7. 특정 컬럼 버리기
.drop()
df3.drop('Interaction type', axis=1, inplace=False)
# axis=0 은 인덱스 기준, 1은 컬럼 기준 삭제를 의미
# inplace=True 는 원본을 변경하겠다는 의미,
# inplace=False 의 경우 원본테이블은 변경되지 않음2-8. 조건에 부합하는 데이터 가져오기(1)
.where()
# 조건에 만족하는 행은 정상 출력, 아닌 행은 NaN으로 반환
df2.where(df2['Age']>50)2-9. 조건에 부합하는 데이터 가져오기(2)
# 조건에 부합하는 데이터만 가져오고 싶을 때
mask = ((df2['Age']>50) & (df2['Gender']=='Male'))
df[mask]2-10. 데이터 그룹핑
- 예제를 통해 SQL 구문과 비교하기
예제 1
- df2 테이블을 활용해 Gender 기준 Customer ID count하기
- SQL 활용
SELECT
Gender
, COUNT("Customer ID")
FROM
df2
GROUP BY
Gender
;- Python 활용
df2.groupby('Gender')['Customer ID'].count()예제 2
- df2 테이블을 활용해 Gender, Location 기준 Customre ID count하기
- SQL 활용
SELECT
Gender
, Location
, COUNT("Customer ID")
FROM
df2
GROUP BY
Gender
, Location
;- Python 활용
df2.groupby(['Gender', 'Location'])['Customer ID'].count()예제 3
- df2 테이블을 활용해 Location 기준 Age distinct count하기
- SQL 활용
SELECT
Location
, COUNT(DISTINCT Age)
FROM
df2
GROUP BY
Location
;- Python 활용
df2.groupby('Location')['Age'].nunique()# count는 중복 제거를 하지 않음
# nunique는 중복을 제거
df2.groupby('Location')['Age'].count()
df2.groupby('Location')['Age'].nunique()예제 4
- df2 테이블을 활용해 Location 기준 Age dictinct count 및 내림차순 정렬
- SQL 활용
SELECT
Location
, COUNT(DISTINCT Age) AS cnt
FROM
df2
GROUP BY
Location
ORDER BY
cnt DESC
;- Python 활용
#sort_values 사용 시, ascending=True 는 오름차순, False 는 내림차순
df2.groupby('Location')['Age'].count().sort_values(ascending=False)QnA
- 전체 100개 행 결과를 모두 보려면?
pd.set_option('display.max_rows', None)- 옵션에서 변경

2 B R 0 2 B