데이터의 분포
- 목표
- 모집단과 표본에 대해서 이해하고 각각에 대해 설명
- 각각의 분포에 대한 개념과 특징을 설명
- 표본오차와 신뢰구간에 대해 이해
2.1 모집단과 표본
- 모집단은 전체! 표본은 일부!
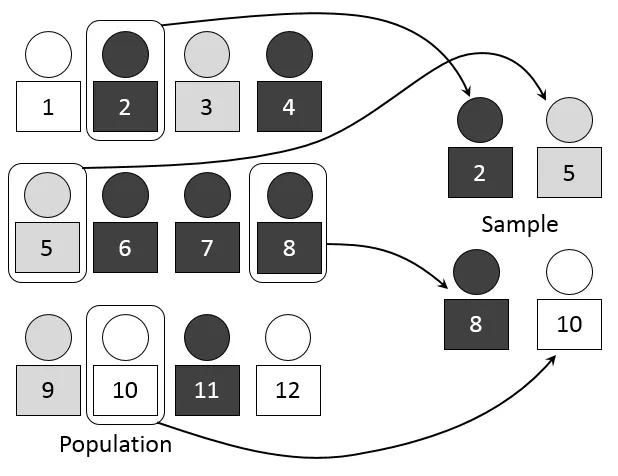
(1) 모집단과 표본이란?
- 모집단
- 관심의 대상이 되는 전체 집단
- (예) 한 국가의 모든 성인
- 표본
- 모집단에서 추출한 일부
- (예) 그 국가의 성인 중 일부를 조사
표본을 사용하는 이유
- 현실적인 제약
- 비용과 시간
- 전체 모집단을 조사하는 것은 비용과 시간이 많이 들기 때문에 대부분의 경우 불가능하거나 비효율적
- 표본 조사는 이러한 자원을 절약하면서도 유의미한 결과를 도출할 수 있는 방법임
- 접근성
- 모든 데이터를 수집하는 것이 물리적으로 불가능한 경우가 많음
- (예) 특정 질병에 걸린 모든 환자의 데이터를 수집 → 현실적으로 어려움
- 비용과 시간
- 대표성
- 표본의 대표성
- 잘 설계된 표본은 모집단의 특성을 반영할 수 있음
- 이를 통해 표본에서 얻은 결과를 모집단 전체에 일반화할 수 있음
- 무작위로 표본을 추출하면 편향을 최소화하고 모집단의 다양한 특성을 포함할 수 있음
- 표본의 대표성
- 데이터 관리
- 데이터 처리의 용이성
- 표본 데이터를 사용하는 것은 전체 데이터를 다루는 것보다 데이터 처리와 분석이 훨씬 용이
- 큰 데이터셋은 분석에 많은 컴퓨팅 자원이 필요할 수 있지만, 작은 표본은 이런 부담을 줄여줌
- 데이터 품질 관리
- 작은 표본에서는 데이터 품질을 더 쉽게 관리하고, 오류나 이상값을 식별하여 수정할 수 있음
- 데이터 처리의 용이성
- 모델 검증 용이
- 모델 적합도 테스트
- 표본 데이터를 사용하여 통계적 모델을 검증할 수 있음
- 모델이 표본 데이터에 잘 맞는다면, 모집단에도 잘 맞을 가능성이 높음
- 모델 적합도 테스트
전수조사와 표본조사
- 전수조사
- 모집단 전체를 조사하는 방법
- 대규모일 경우 비용과 시간이 많이 듦
- 표본조사
- 표본만을 조사하는 방법
- 비용과 시간이 적게 들지만, 표본이 대표성을 가져야 함
(2) 실제 사용 예시
- 실제로 모든 데이터를 다 수집할 수 없을 때 표본을 사용
- 도시 연구
- 한 도시의 모든 가구(모집단) 중 100가구(표본)를 조사하여 평균 전력 사용량을 추정
- 의료 연구
- 특정 치료법의 효과를 알아보기 위해 전체 환자를 조사하는 대신, 표본을 통해 추정하고 이를 바탕으로 결론을 도출
- 시장 조사
- 소비자 선호도를 파악하기 위해 모든 소비자를 조사하는 대신, 무작위로 선택된 표본을 통해 전체 시장의 트렌드를 추정
- 정치 여론 조사
- 선거 전 여론 조사를 통해 전체 유권자의 투표 경향을 추정하여 선거 결과를 예측
- 도시 연구
파이썬 실습
import numpy as np
import matplotlib.pyplot as plt
# 모집단(예: 어떤 국가에 사는 모든 성인의 키 데이터) 생성
population = np.random.normal(170, 10, 1000)
# 표본 추출
population_sample = np.random.choice(population, 100)
plt.hist(population, bins=50, alpha=0.5, label='population', color='blue')
plt.hist(population_sample, bins=50, alpha=0.5, label='sample', color='red')
plt.legend()
plt.title('population and sample distribution')
plt.show()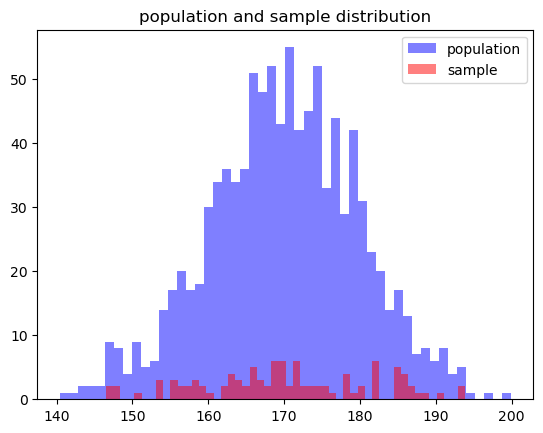
-
numpy.random모듈- NumPy 라이브러리의 일부로, 다양한 확률 분포에 따라 난수를 생성하는 기능을 제공
- 데이터 분석, 시뮬레이션 방법 등 다양한 분야에서 사용
np.random.normal함수- 정규분포(가우시안 분포)를 따르는 난수를 생성
- 정규분포: 평균과 표준편차를 중심으로 데이터가 대칭적으로 분포하는 분포
- 코드 설명:
numpy.random.normal(loc=0.0, scale=1.0, size=None)loc(float): 정규분포의 평균 (기본값: 0.0)scale(float): 정규분포의 표준편차 (기본값: 1.0)size(int 또는 tuple of ints): 출력 배열의 크기 (기본값: None, 즉 스칼라 값 반환)
np.random.choice- 주어진 배열에서 임의로 샘플링하여 요소를 선택
- 지정된 배열에서 무작위로 선택된 요소를 반환하는 기능을 제공
- 코드 설명:
numpy.random.choice(a, size=None, replace=True, p=None)a(1-D array-like or int): 샘플링할 원본 배열. 정수인 경우 np.arange(a)와 동일하게 간주size(int 또는 tuple of ints): 출력 배열의 크기 (기본값: None, 즉 단일 값 반환)replace(boolean): 복원 추출 여부를 나타냅니다. True면 동일한 요소가 여러 번 선택될 수 있습니다 (기본값: True)p(1-D array-like, optional): 각 요소가 선택될 확률. 배열의 합은 1이어야 함
-
plt.hist- Matplotlib 라이브러리에서 히스토그램을 그리는 함수
- 데이터의 분포를 시각화하는 데 유용한 도구
bins- 빈(bins)의 개수 또는 경계를 정함
- 빈(bins): 데이터 몇 개의 구간으로 나눌 것인지에 대한 것
- 정수나 리스트로 입력할 수 있음
- 정수: 빈의 개수 지정
- 리스트: 빈의 경계를 직접 지정 → 140~150, 150~160… 이렇게 경계를 지정하고 싶으면 리스트로 작성
alpha- 히스토그램 막대의 투명도를 지정
- 0(투명)에서 1(불투명) 사이의 값
label- 히스토그램의 레이블을 지정
- 여러 히스토그램을 그릴 때 범례를 추가하는 데 사용
color- 히스토그램 막대의 색상을 지정
2.2 표본오차와 신뢰구간
- 표본이 모집단 대비해서 얼마나 차이나는지, 신뢰할 수 있는지 파악
(1) 표본오차와 신뢰구간
표본오차
신뢰구간
표본오차, 신뢰구간 그림으로 확인하기
(2) 실제 사용 예시
2.3 정규분포
(1) 정규분포란?
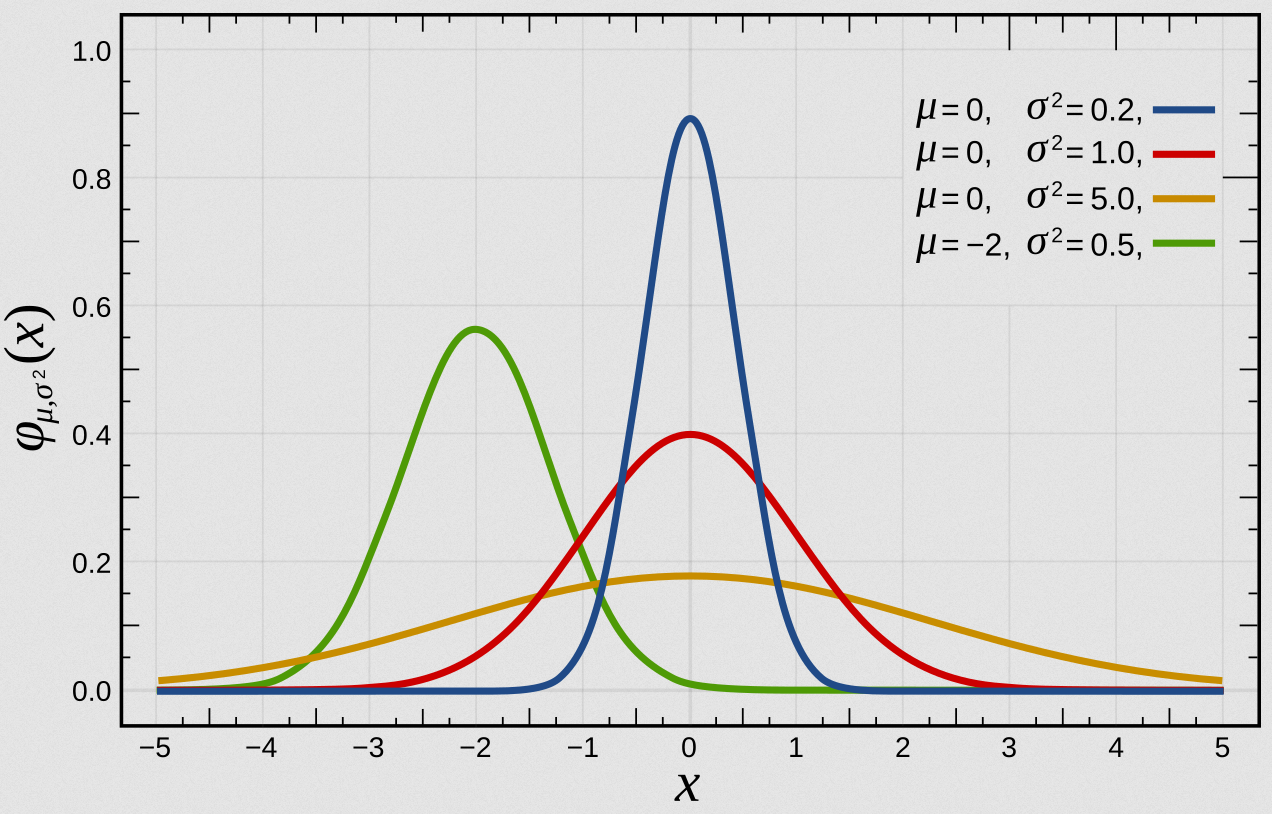
정규분포

2 B R 0 2 B