CodeKata
SQL
165. Population Census
- 작성한 쿼리
SELECT
SUM(city.population)
FROM
city
JOIN country
ON city.countrycode = country.code
WHERE
continent = 'Asia'
;166. African Cities
- 작성한 쿼리
SELECT
city.name
FROM
city
JOIN country
ON city.countrycode = country.code
WHERE
continent = 'Africa'
;167. Average Population of Each Continent
- 작성한 쿼리
SELECT
country.continent
, FLOOR(AVG(city.population))
FROM
city
JOIN country
ON city.countrycode = country.code
GROUP BY
country.continent
;→ rounded down to the nearest integer
== 가장 가까운 정수로 내림을 하라고 요청하는 조건
※ 버림하고 내림 차이가 뭘까? 참고
→ 대상이 음수일 경우 버림과 내림에 차이가 생김!
: -2.8을 내림하면 -3이 나오고 버림하면 -2가 나옴
올림(CEIL())
내림(FLOOR())
반올림(ROUND())
버림(TURNCATE())
Python
64. 체육복
- 작성한 코드
def solution(n, lost, reserve):
answer = 0
reserve_set = set(reserve) - set(lost)
lost_set = set(lost) - set(reserve)
for i in reserve_set:
if i-1 in lost_set:
lost_set.remove(i-1)
elif i+1 in lost_set:
lost_set.remove(i+1)
answer = n - len(lost_set)
return answer→ 비슷하게 푼 사람들 코멘트에 남겨진 피드백 보니까
입력 reserve가 정렬이 되어 있지 않은 경우에는 틀리게 됩니다. 지금 테스트케이스에는 다 정렬이 된 것만 있어서 통과가 되는 것 같은데, 정렬하는 부분만 추가해주면 될 것 같아요
lost = [4, 2], reserve = [3, 5]인 경우만 생각해봐도 위 코드로 연산하게 되면 3번이 먼저 4번을 빌려주게 됩니다. 그럼 5번은 빌려줄 사람이 없으므로 4번만 체육복을 빌린채로 끝이 나게될텐데 만약 3번이 앞에있는 2번을 먼저 빌려주면 5번이 4번을 빌려주는것이 가능해지게 돼서 하나 더 큰 값을 얻을 수 있습니다.
라고 하는데 이해를 잘 못하겠음…
참고할 만한 다른 풀이
def solution(n, lost, reserve):
# 정렬
lost.sort()
reserve.sort()
# lost, reserve에 공통으로 있는 요소 제거
for i in reserve[:]:
if i in lost:
reserve.remove(i)
lost.remove(i)
# 체육복 빌려주기(나의 앞 번호부터 확인)
for i in reserve:
if i-1 in lost:
lost.remove(i-1)
elif i+1 in lost:
lost.remove(i+1)
return n-len(lost)-
가장 먼저 lost, reserve를 오름차순 정렬
- 예를 들어, n = 5, lost = [2, 4], reserve = [3, 1] 일 때를 생각해 보자.
- 1번이 2번에게 체육복을 빌려주고, 3번이 4번에게 체육복을 빌려주면 모두가 체육수업을 들을 수 있을 것
- 하지만, lost, reserve를 정렬하지 않고 체육복을 빌려준다고 하면 결과가 어떻게 될까?
(n = 5, lost = [2, 4], reserve = [3, 1]) - i = 3이면 i - 1 = 2, lost에 존재하므로 lost에서 2 제거 → lost = [4]
- i=1이면 i - 1 = 0, lost에 존재하지 않음 i + 1 = 2, lost에 존재하지 않음 lost = [4]
- 정렬하지 않으면, n - len(lost) = 5 - 1 = 4명이 체육복을 입을 수 있다는 결과가 도출됨
- 예를 들어, n = 5, lost = [2, 4], reserve = [3, 1] 일 때를 생각해 보자.
-
lost, reserve를 정렬하고 다시 과정을 진행해 보면 다음과 같다.
(n = 5, lost = [2, 4], reserve = [1, 3])
- i=1이면 i - 1 = 0, lost에 존재하지 않음 i + 1 = 2, lost에 존재하므로 lost에서 2 제거 → lost = [4]
- i = 3이면 i - 1 = 2, lost에 존재하지 않음 i + 1 = 4, lost에 존재하므로 lost에서 4 제거 → lost = [ ]- 정렬하면, n - len(lost) = 5 - 0 = 5명이 체육복을 입을 수 있다는 결과가 도출
🡆 따라서, 체육복을 빌려주는 과정을 진행하기 전에 lost와 reserve를 정렬하는 과정이 필요
- 정렬하면, n - len(lost) = 5 - 0 = 5명이 체육복을 입을 수 있다는 결과가 도출
-
lost와 reserve를 정렬한 뒤에는 두 배열에 공통으로 존재하는 요소를 각 배열에서 제거
- 문제에서 '여벌 체육복을 가져온 학생이 체육복을 도난당했을 수 있습니다. 이때 이 학생은 체육복을 하나만 도난당했다고 가정하며, 남은 체육복이 하나이기에 다른 학생에게는 체육복을 빌려줄 수 없습니다.'라고 명시하였기 때문
-
여기까지의 과정을 모두 마무리했으면 lost, reserve 배열의 요소들을 비교하여 체육복을 빌려주는 작업을 진행
- reserve를 기준으로 for문을 작성
- 만약, 1번 학생(= i-1)이 체육복이 없으면 1번 학생은 0번은 없으므로 2번 학생(= i)에게만 체육복을 받을 수 있다. 그러므로 reserve의 요소 i를 기준으로 왼쪽인 i-1부터 lost에 존재하는지 확인하고, i-1이 없으면 i+1을 확인하도록 하였다.
- i-1 또는 i+1이 lost에 존재하면 lost에서 해당 값을 제거함으로써 체육복을 빌려준 것으로 한다.
- 이때 둘 다 if문으로 작성하면 3번 학생이 2번 4번 모두에게 빌려주는 사태가 발생하게 된다.
- 한 명에게만 빌려줄 수 있으므로 if - elif로 작성하여 하나의 조건에 대해서만 작업을 진행할 수 있도록 해야 한다.
- reserve를 기준으로 for문을 작성
-
최종적으로 n명의 학생에서 체육복을 입지 못한(=잃어버린) 학생 수를 빼면 체육 수업을 들을 수 있는 학생 수를 구할 수 있다.
# 앞번호 학생이나 바로 뒷번호의 학생에게만 체육복 빌려줄 수 있음
# 예시 : 3번 <- 4번 -> 5번
# 최대한 많은 학생이 체육 수업을 들어야 함
# 전체 학생의 수 n, 체육복 도난당한 학생 번호 배열 Lost, 여벌의 체육복 학생 : reverse
# 1번 학생의 경우 -> 방향으로 줄 수만 있음
# 배열에서 0, 1, 2 판단
def solution(n, lost, reserve):
count = 0
# 학생 배열 생성 (기본 : 1, 잃어버린 학생 : 0, 여벌있는 학생 : 2)
student = [1] * (n + 1)
for l in lost:
student[l] -= 1
for r in reserve:
student[r] += 1
# 앞 사람한테 주기
for i in range(1, n + 1):
if student[i] == 0:
if i - 1 > 0 and student[i - 1] == 2:
student[i] = 1
student[i - 1] = 1
elif i + 1 <= n and student[i + 1] == 2: # 범위 넘어가면 안 되므로
student[i] = 1
student[i + 1] = 1
for i in student:
if i >= 1:
count += 1
return count1. 정답 코드
# 이 코드처럼 n 크기에 맞게 student 배열 초기화해줘서
# 인덱스 문제 발생하지 않도록 해야할 것 같다.
for l in lost:
student[l] -= 1
for r in reserve:
student[r] += 1
2. 오류 코드
# 아래 코드가 잘못된 이유는 여벌이 있는데 도난 당한 학생의 경우
# 제대로 처리되지 않을 수 있으므로
for i in range(len(student)):
if i + 1 in lost:
student[i] -= 1
elif i + 1 in reserve:
student[i] += 1
위처럼 문제를 풀었을 경우 반례 n=3, lost=3, reserve = [1, 3]
여벌이 있는데 도난 당한 학생의 초기값을 설정할 때 오류가 날 수 있으니 주의def solution(n, lost, reserve):
reserved = 0
lostN = list(set(lost) - set(reserve))
reserveN = list(set(reserve) - set(lost))
lostN.sort()
for l in lostN:
for x in range(l-1, l+2):
if x in reserveN:
reserveN.remove(x)
reserved += 1
break
return n - len(lostN) + reserved- 시간복잡도 관련 피드백이 달려 있어 함께 기록
- 짧고 간결하긴 하지만 O(n^2)이네요
- 6줄 for O(n), 7줄 for O(n), 9줄 remove O(n) 이라 O(n^3) 아닌가요?
- 7줄의 range의 크기는 상수라서 7,8줄이 O(n)이 되어 전체 알고리즘의 시간복잡도는 O(n^2)인것 같습니다.
- 6번째 줄, 8번째 줄, 9번째 줄에 의해 O(n**3) 같습니다
- 짧고 간결하긴 하지만 O(n^2)이네요
SDL
Pandas GroupBy의 대괄호 & 소괄호 구분
df.groupby([그룹화 할 컬럼명])[연산을 할 컬럼을 인덱싱].연산()
판다스 데이터프레임 멀티인덱스
파이썬으로 하는 T-test
independent two-sample t-test
워드 클라우드
범주형과 연속형 자료
데이터 종류
데이터 분석 개요
강의: 실습으로 배우는 태블로
개인 과제
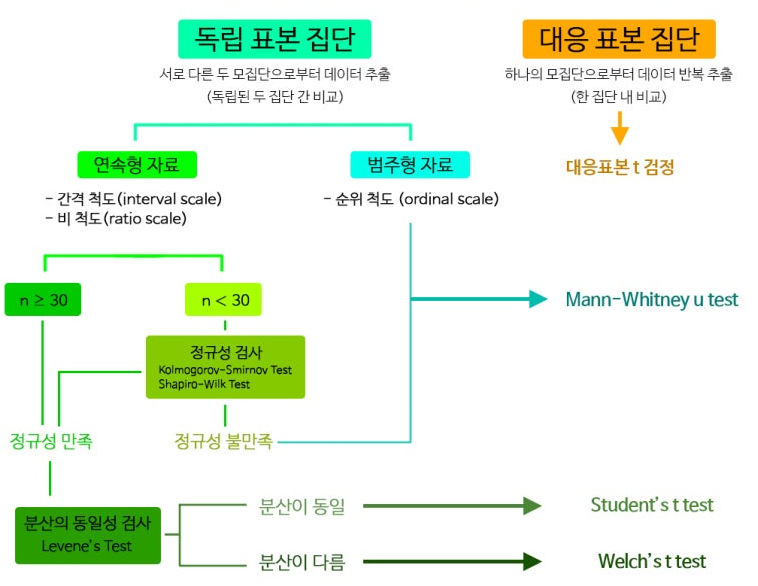
- t-검정의 종류
- 독립표본 검정은 서로 다른(e.g. 남자와 여자) 두 집단을 비교할 때 활용
- 대응표본 검정은 같은 집단의 대응되는 두 변수(사전점수와 사후점수, 국어점수와 수학점수)를 비교할 때 활용
- 부부 100쌍을 뽑아 남편 100명과 아내 100명으로 집단 비교하는 경우는 대응표본
- 무작위로 남자 100명 여자 100명을 뽑아 두 집단을 비교하는 경우는 독립표본
- 카이제곱검정
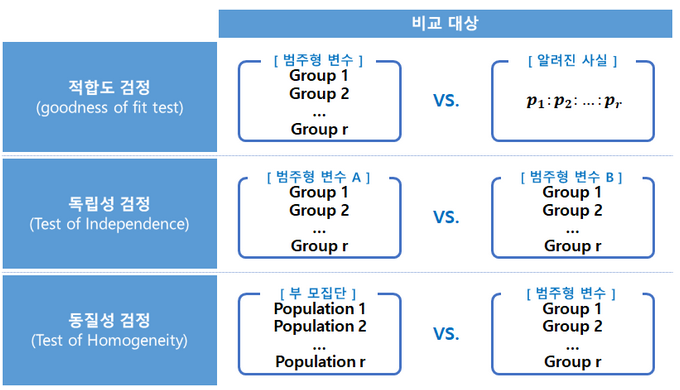
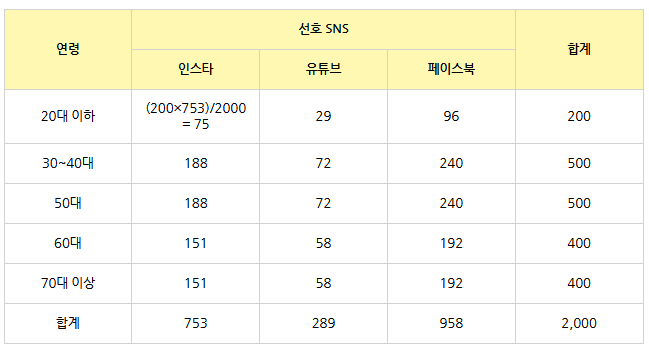
- 카이제곱 통계량은 '관측도수'와 '기대도수' 간 차이를 이용해 구함
- 관측도수: 실제 조사를 통해 얻은 수
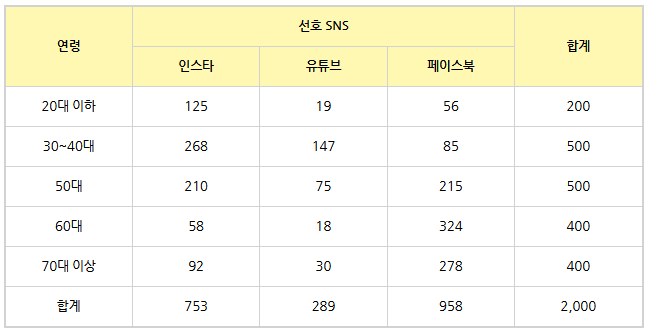
- 기대도수: 사건 A와 B가 서로 관련이 없을 때 얻어지는 값

출처
- 관측도수: 실제 조사를 통해 얻은 수
- scipy 문서: chi2_contingency
- 카이제곱 통계량은 '관측도수'와 '기대도수' 간 차이를 이용해 구함
- 리스트를 데이터 프레임으로 변환하는 법
- 파이썬 변수 선언 ★
- 이중 리스트 인덱싱
- predict_proba
회고
- 블덱스라는 걸 새로 알았다!
- 블로그 지수를 확인하는 사이트인 것 같음
- 다양한 경험을 한 분들이 많아서 이야기 듣는 게 즐거움
- 내일 태블로 특강 있음! 머신러닝 개인 과제 제출 마감일! 머신러닝 개인 과제 해설 있음!
