
CodeKata
SQL
프로그래머스: 대장균들의 자식의 수 구하기
- 작성한 쿼리
SELECT
e1.id
, COUNT(e2.id) AS child_count
FROM
ecoli_data e1
LEFT JOIN ecoli_data e2
ON e1.id = e2.parent_id
GROUP BY
e1.id
ORDER BY
e1.id
;참고할 만한 다른 풀이
SELECT
ID,
COALESCE((SELECT COUNT(*) FROM ECOLI_DATA WHERE PARENT_ID = A.ID), 0) AS CHILD_COUNT
FROM
ECOLI_DATA A
ORDER BY
ID;WITH CTE AS (
SELECT PARENT_ID AS PID,
COUNT(PARENT_ID) AS CNT
FROM ECOLI_DATA
GROUP BY PARENT_ID
)
SELECT ID, COALESCE(CNT, 0) AS CHILD_COUNT
FROM ECOLI_DATA AS E
LEFT JOIN CTE AS C
ON E.ID = C.PID;SELECT
PARENT.ID,
COUNT(CHILD.ID) AS CHILD_COUNT
FROM
ECOLI_DATA AS PARENT
LEFT OUTER JOIN
ECOLI_DATA AS CHILD ON PARENT.ID = CHILD.PARENT_ID
GROUP BY
PARENT.ID
ORDER BY
PARENT.ID자식이 없는 경우까지 포함하기 위해 inner join이 아닌 outer join을 수행
이 경우 자식이 없는 row의 CHILD.ID는 NULL임
COUNT(*)를 사용하면 자식이 없는 row도 CHILD_COUNT의 값이 1로 나타남
따라서 COUNT(CHILD.ID)로 명확하게 개수를 셀 column을 지정해주면 CHILD.ID의 값이 NULL이 아닌 row의 수만 세게 되어 원하는 답이 됨
SELECT E1.ID,
(SELECT COUNT(*)
FROM ECOLI_DATA E2
WHERE E1.ID = E2.PARENT_ID
) CHILD_COUNT
FROM ECOLI_DATA E1
ORDER BY E1.ID최종 프로젝트
트러블 슈팅
request로 HTTP 요청을 보내는 중에 "Max retries exceeded with url" 오류가 났다.
해결 방법을 찾아보니 requests 라이브러리에서는 재시도 횟수를 조절할 수 있다고 한다.
동일한 웹사이트에 대한 여러 HTTP 요청 간에 상태를 유지하도록 해주는 세션 객체를 생성해 요청을 보내는 걸로 변경하였다.
retry_strategy = Retry(
total=30, # Maximum number of retries
status_forcelist=[429, 500, 502, 503, 504], # HTTP status codes to retry on
)
session = requests.Session()
# # Create an HTTP adapter with the retry strategy and mount it to session
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount('http://', adapter)
session.mount('https://', adapter)
session.headers.update({'Connection': 'keep-alive'})
r = session.get(URL, headers=make_Header())딕셔너리 형태의 컬럼
- 데이터프레임 '{}' 안에 있는 값 추출
- get() 함수 사용
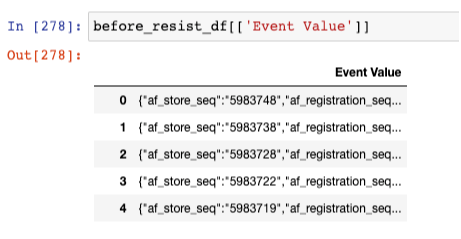


- get() 함수 사용
import json
before_resist_df["Event Value"].map(lambda x: json.loads(x).get("af_user_seq"))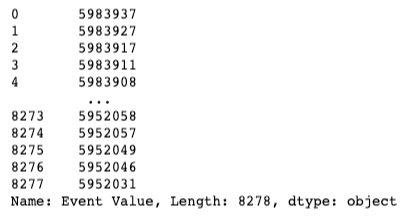
import pandas as pd
import json
# 딕셔너리 모양 문자열 칼럼을 데이터프레임으로 펼치기
def get_columns(columns_list: list):
"""" 딕셔너리 모양으로 들어간 문자열 칼럼을 데이터 프레임으로 변환해주는 함수
Args:
columns_list(list): df_origin(pd.DataFrame)에서 변환이 필요한 칼럼명 리스트
Returns:
pd.DataFrame: 데이터프레임
"""""
df = df_origin.copy()
for col in columns_list:
change_df = pd.json_normalize(json.loads(row) for row in list(df[col]))
change_df.columns = [f'{col}.{subcol}' for subcol in change_df.columns]
df = df.drop(col, axis=1)
df = pd.concat([df, change_df], axis = 1)
return df
json_columns = ['device', 'geoNetwork', 'totals', 'trafficSource']
df = get_columns(json_columns)
df.info()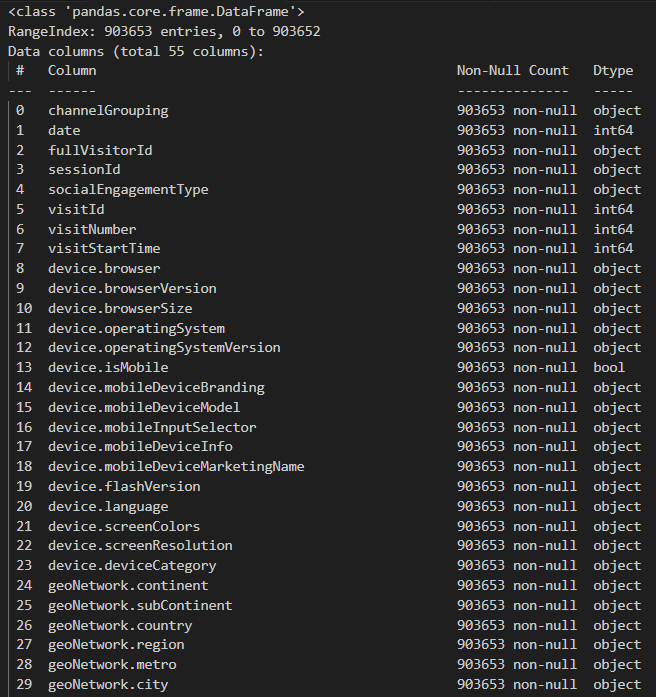
시각화
-
- 자동 시각화
- 데이터의 상관관계나 분포 그리고 통계치 확인 가능
- 비슷한 패키지로는 pandas_profiling이 있음
- 2가지 데이터셋을 비교한다던지, 뭔가를 비교한다고 했을 때 굉장히 유용
- 자동 시각화
import pandas as pd
import sweetviz as sv
df = pd.read_csv("test.csv")
report = sv.analyze(df, pairwise_analysis='off')
report.show_html('report.html')import pandas as pd
from dataprep.eda import create_report
df = pd.read_csv("test.csv")
report = create_report(df, title="My Data")
report.save("Data_EDA.html")
report.show_browser()
report.show()기타
용어 정리
- 메타데이터
- 메타데이터(metadata or metainformation)는 데이터(data)에 대한 데이터이다.
- 캐런 코일(Karen Coyle)에 의하면 '어떤 목적을 가지고 만들어진 데이터(constructed data with a purpose)'라고도 정의한다.
- 즉, 다른 데이터를 정의하고 기술하는 데이터(data that defines and describes other data)이다.
- 가령 도서관에서 사용하는 서지기술용으로 만든 것이 그 대표적인 예이다.
- 지금은 온톨로지의 등장과 함께 기계가 읽고 이해할 수 있는(Machine Actionable) 형태의 메타데이터가 많이 사용되고 있다.
- 메타데이터(metadata or metainformation)는 데이터(data)에 대한 데이터이다.
학습 내용 정리
if-else 리팩토링
library, package, module, function, method
eval() 과 literal_eval()
그래프 데이터를 변수로 관리하기
회고
- 어제 짠 코드가 오류나서 코드카타 한 문제밖에 못 풀었음
- 새로 고친 코드는 다행히? 아직까지는? 잘 돌아감
- 해야 할 일이 왜 이렇게 많을까? 강의 복습하고 싶은데 시간이 안 난다…
- EDA 관련 좋은 툴 2개를 알았다!
- 최종적으로는 Github까지 사용해야 하므로 git을 좀 알아두면 좋을 것 같음

2 B R 0 2 B