CodeKata
SQL
프로그래머스: 대장균의 크기에 따라 분류하기 1
- 작성한 쿼리
SELECT
id
, CASE
WHEN size_of_colony <= 100 THEN 'LOW'
WHEN size_of_colony <= 1000 THEN 'MEDIUM'
ELSE 'HIGH'
END AS size
FROM
ecoli_data
ORDER BY
id
;참고할 만한 다른 풀이
SELECT ID,
CASE
WHEN SIZE_OF_COLONY > 1000 THEN 'HIGH'
WHEN SIZE_OF_COLONY > 100 THEN 'MEDIUM'
ELSE 'LOW'
END SIZE
FROM ECOLI_DATA
ORDER BY ID-- SIZE_OF_COLONY가 100 이하면 LOW 1000 이하면 MEDIUM 1000 초과면 HIGH
-- ID와 SIZE 출력
SELECT ID, IF (SIZE_OF_COLONY <= 100, 'LOW',
IF (SIZE_OF_COLONY <= 1000, 'MEDIUM', 'HIGH')) AS SIZE
FROM ECOLI_DATA
ORDER BY ID프로그래머스: 부모의 형질을 모두 가지는 대장균 찾기
- 작성한 쿼리
SELECT
e1.id
, e1.genotype
, e2.genotype AS parent_genotype
FROM
ecoli_data e1
LEFT JOIN ecoli_data e2
ON e1.parent_id = e2.id
WHERE
e1.genotype & e2.genotype = e2.genotype
ORDER BY
e1.id
;참고할 만한 다른 풀이
SELECT ED.ID, ED.GENOTYPE, EDC.PARENT_GENOTYPE
FROM ECOLI_DATA AS ED
LEFT JOIN (SELECT ID, GENOTYPE AS PARENT_GENOTYPE FROM ECOLI_DATA) AS EDC ON ED.PARENT_ID = EDC.ID
WHERE ED.GENOTYPE & EDC.PARENT_GENOTYPE = EDC.PARENT_GENOTYPE
ORDER BY ID ASC;Python
82. 멀리 뛰기
- 작성한 코드
def solution(n):
answer = 0
jump = {} # 메모제이션
jump[0] = 1 # 움직이지 않는 경우
jump[1] = 1 # 한 칸 움직이는 경우
for i in range(2, n+1): # 두 칸 이상인 경우
jump[i] = jump[i-1] + jump[i-2]
answer = jump[n] % 1234567
return answer1칸 또는 2칸을 이동하여 목표 칸으로 갈 수 있는 방법은 목표 칸의 한 칸 전에서 1칸 이동 또는 목표 칸의 두 칸 전에서 2칸 이동하는 방법뿐
→ n칸 = (n-1)칸 + 1칸 OR (n-2)칸 + 2칸
즉, 다음 수의 경우의 수는 이전 수의 경우의 수와 그 이전 수의 경우의 수를 더한 값
🡆 이거 어디서 많이 봤는데? …피보나치 수열이다!
참고할 만한 다른 풀이
def solution(n):
answer = 0
a, b = 0,1
for i in range(n) :
a,b = b, a+b
answer = b % 1234567
return answern = 1 : [1] 1가지
n = 2 : [1,1], [2] 2가지
n = 3 : [1,1,1], [1,2], [2,1] 3가지
n = 4 : [1,1,1,1], [2,1,1], [1,2,1], [1,1,2], [2,2] 5가지
n = 5 : [1,1,1,1,1], [2,1,1,1], [1,2,1,1], [1,1,2,1], [1,1,1,2], [2,2,1], [1,2,2], [2,1,2] 8가지
n = 6 : [1,1,1,1,1,1], [2,1,1,1,1], [1,2,1,1,1], [1,1,2,1,1], [1,1,1,2,1], [1,1,1,1,2], [2,2,1,1], [2,1,2,1], [2,1,1,2], [1,2,2,1], [1,2,1,2], [1,1,2,2], [2,2,2] 13가지
1,2,3,5,8,13
보면 이런식으로 증가합니다. 규칙성을 찾아보면 피보나치 수열이라는 것을 알 수 있습니다. 그래서 for문을 이용한 반복문으로 n까지 반복하며 값을 증가시킵니다. 반복이 끝나면 b 값에 1234567로 나누어 나머지를 구합니다.
- 동적 계획법(Dynamic Programming) 알고리즘
→ 다들 dp라고 부르더라
→ 복잡한 문제를 간단한 여러 개의 문제로 나누어 푸는 방법을 말한다고 함
# 1
def solution(n):
if n == 1:
return 1
else:
dp = [0] * (n+1)
dp[1] = 1
dp[2] = 2
for i in range(3, n+1):
dp[i] = (dp[i-2] + dp[i-1]) % 1234567
return dp[-1]
# 2
def solution(n):
dp=[0 for _ in range(n+2)]
dp[1]=1
dp[2]=2
for i in range(3,n+1):
dp[i]=dp[i-2]+dp[i-1]
return dp[n]%1234567- 중복 순열 → 시간 초과 발생한다고 함
from itertools import product
def solution(n):
permute_list=[1,2]
result=[]
cnt=0
for i in range(n):
result+=list(product(permute_list,repeat=i))
for num_list in result:
if sum(num_list)==n:
cnt+=1
return cnt+1- 재귀함수
→ 성능이 안 좋으니 지양해야 함
→ 이런 방법도 있다는 걸 보여주는 의미로 넣었음
# 모든 경우 탐색 -> DFS
cnt=0
def dfs(number,target):
global cnt
if number<target:
number=number%1234567
dfs(number+1,target)
dfs(number+2,target)
if number==target:
cnt+=1
return
def solution(n):
dfs(0,n)
return cnt%1234567
# 다른 dfs 풀이
def jumpCase(num):
answer = 0
if num==1:
return 1
elif num==2:
return 2
else:
return jumpCase(num-1)+jumpCase(num-2)최종 프로젝트 관련
이터널리턴 프로젝트 접근 방법 참고
게임 데이터 컬럼 분석
-
routeIdOfStart,routeSlotId컬럼 관련- 이터널 리턴의 기본, '루트' 시스템 가이드
- API
/v1/weaponRoutes/recommend및 에서/v1/weaponRoutes/recommend/routeId}테이블을 호출해 정보 확인 가능
-
placeOfStart컬럼 관련
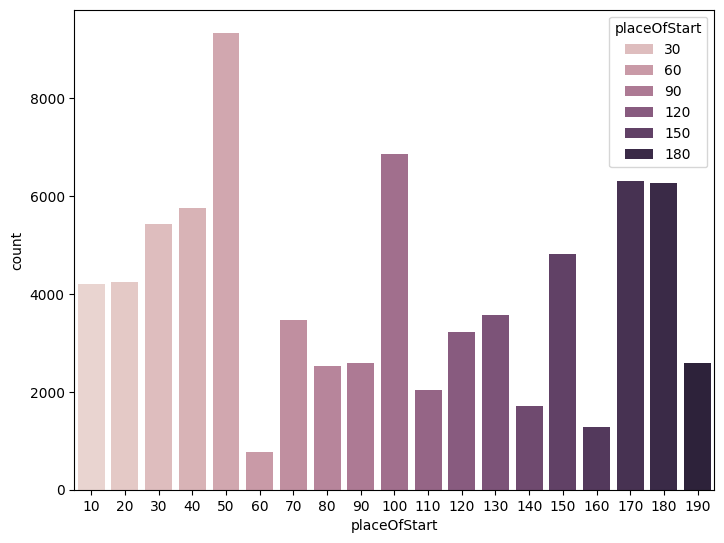
- API
/v2/data/Area에서 테이블을 호출해 code와 일치하는 name(church, factory 등) 찾을 수 있음 - 게임 시작 시 유저가 선택한 루트와 밀접한 관련 있음
- 연결시킬 수 있으면 해보기
- API
Pandas 옵션 수정: 생략 없이 출력하기
#pd.set_option('옵션 이름', 수정할 값)
pd.set_option('display.max_seq_items', None)
pd.set_option('display.max_columns', None)Pandas에서 날짜 다루기
import pandas as pd
# 날짜 문자열 데이터를 포함한 데이터프레임 생성
data = {
'이름': ['홍길동', '김철수', '이영희'],
'가입일': ['2023-01-15 00:00:00', '2023-02-20 00:00:00', '2023-03-25 00:00:00']
}
df = pd.DataFrame(data)
pd.to_datetime() # 문자열을 날짜로 변환.
df['날짜'].dt # 날짜에서 연도, 월, 일 등 추출.
pd.date_range() # 날짜 범위 생성.
df.resample() # 날짜 데이터를 주기적으로 그룹화.
pd.Timedelta # 날짜 간 차이 계산.- 문자열을 날짜로 변환하기
- pd.to_datetime()을 사용하여 문자열을 날짜 형식으로 변환
# '가입일' 열을 날짜로 변환
df['가입일'] = pd.to_datetime(df['가입일'], format='mixed')- 날짜 열에서 연도, 월, 일 추출
# 연도 추출
df['가입_연도'] = df['가입일'].dt.year
# 월 추출
df['가입_월'] = df['가입일'].dt.month
# 일 추출
df['가입_일'] = df['가입일'].dt.day- 날짜로 인덱스 설정
# 가입일을 인덱스로 설정
df.set_index('가입일', inplace=True)- 날짜 계산 (날짜 간 차이)
- 날짜 간 차이를 계산하려면 pd.Timedelta 또는 날짜 간 연산을 사용
# 두 날짜 간 차이 계산
df['오늘과의 차이'] = pd.to_datetime('today') - df.index- 주기별 리샘플링 (Resampling)
- 날짜별 데이터를 주기적으로 그룹화하여 요약할 수 있음
- (예) 일별 데이터를 월별로 리샘플링
- 날짜별 데이터를 주기적으로 그룹화하여 요약할 수 있음
# 예제 데이터 생성
data = {
'날짜': pd.date_range(start='2023-01-01', periods=6, freq='D'),
'값': [10, 20, 30, 40, 50, 60]
}
df = pd.DataFrame(data)
# 날짜를 인덱스로 설정
df.set_index('날짜', inplace=True)
# 주 단위로 리샘플링하여 합계 구하기
weekly_sum = df.resample('W').sum()- 날짜 포맷 지정하기
- pd.to_datetime()에서 format 옵션을 사용하여 특정 날짜 형식을 지정
# 특정 날짜 포맷의 문자열을 날짜로 변환
data = {'이름': ['박영수', '이영희'], '생년월일': ['01-25-1985', '03-12-1990']}
df = pd.DataFrame(data)
# 포맷 지정하여 변환
df['생년월일'] = pd.to_datetime(df['생년월일'], format='%m-%d-%Y')- 날짜 필터링
- 날짜 범위를 기준으로 데이터를 필터링
# '2023-02-01' 이후의 데이터만 필터링
filtered_df = df[df.index >= '2023-02-01']MySQL select 결과 csv 파일로 저장
SELECT name, dept_cd, phone, address FROM class.select_test
INTO OUTFILE '/home/stricky/select_csv/select_test.csv'
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';- (SELECT name, dept_cd, phone, address FROM class.select_test)의 쿼리 결과를 (/home/stricky/select_csv/select_test.csv) 경로에 csv 파일로 저장
첫번째 라인은 우리가 아는 select 문과 같습니다. 텍스트 csv 파일로 저장하고 싶은 데이터의 select 문을 작성 하시면 됩니다.
두번째 라인은 저장 경로 입니다. 이때 주의 하실 점은 저기에 명시하는 저장 경로는 우리가 접속하는 PC 클라이언트의 저장 경로가 아니라, MySQL이 설치 되어 있는 서버의 저장경로를 쓰셔야 합니다. 물론 본인 PC에 MySQL이 설치 되어 있다면 본인 PC의 저장 경로를 쓰시면 되겠죠.
세번째 라인은 컬럼과 컬럼사이의 구분자를 지정 하는겁니다. 일반적으로 csv 파일으면 ' , '를 사용합니다.
네번째 라인은 데이터의 행을 구분하는 건데 '\n'은 줄바꿈을 의미합니다.
seaborn color palette
배운 내용 정리
기본형과 래퍼클래스
int와integer의 차이는 무엇인가?int(primitive type): 변수의 타입(data type; 자료형)
→ 산술 연산 가능함. null로 초기화 불가.- 변수(variable): 값을 저장할 수 있는 메모리 상의 공간
- 자료형은 기본형(primitive type)과 참조형(reference type)으로 나뉘는데, int는 이 중 기본형에 속함
integer(wrapper class): 기본형을 객체로 다루기 위해 사용하는 클래스
→ unboxing 하지 않을 시 산술 연산 불가능. null값 처리 가능- 기본형을 표현해야 하는 경우가 있음
1) 매개변수로 객체를 필요로 할 때
2) 기본형 값이 아닌 객체로 저장해야 할 때
3) 객체 간 비교가 필요할 때
- 기본형을 표현해야 하는 경우가 있음
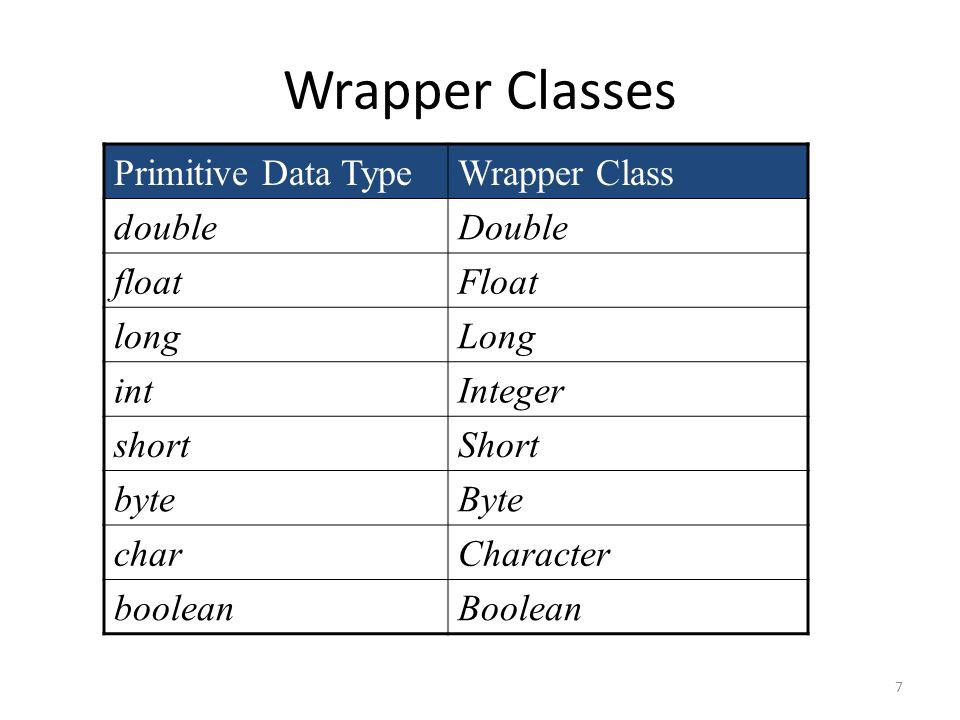
boxing : primitive type -> wrapper class 변환 ( int to Integer )
unboxing : wrapper class -> primitive type 변환 ( Integer to int )
과제
회고
- etl 모듈 돌리는 거 성공했다! MySQL에 데이터가 잘 쌓이는 모습을 보니 뿌듯함
- 확실히 데이터 양이 많아지니까 SQL로 처리하는 게 더 빠름
- 게임을 90일 동안 2000건 넘게 하신 분이 있다… 정말 대단
