네이버 경제 > 증권 뉴스에 보이는 뉴스 제목을 출력해주세요!
첫 번째 시도
import requests
from bs4 import BeautifulSoup
# code here
url = 'https://news.naver.com/breakingnews/section/101/258'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
financial = soup.find('div', {'class': 'section_latest'})
title = financial.find('ul', {'class': 'sa_list'}).find_all('a')
# for i in range(len(title)):
# print(title[i].get_text())
for element in title:
string = element.get_text()
print(string)- 출력 결과:
[단독] 최현만, 금융지주 ‘러브콜’ 고사 “사랑하는 미래에셋 창업멤버로 남겠다” [시그널]
새내기주 잔혹사 끊나… 쓰리빌리언 상장 첫날 15% 강세
카카오페이증권, 홍콩 기업과 AI 업무 자동화 협력
포인트엔지니어링, 3분기 흑자 전환 성공
어피니티, 원금 수준서 SSG 투자 ‘마침표’…이커머스 몸값 회복 ‘쉽지않네’ [투자360]
DI동일, 두번째 자사주 소각…보유분 65%
→ 문제점
① 첫 번째 Section에 있는 기사 6개 제목만 나옴
② 줄바꿈이 너무 많이 들어감: velog에서는 잘 안 보이는데 실제 실행 화면에서는 6줄씩 띄어져 있음…
두 번째 시도
import requests
from bs4 import BeautifulSoup
url = 'https://news.naver.com/breakingnews/section/101/258'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
financial = soup.find_all('strong', {'class': 'sa_text_strong'})
for element in financial:
title = element.get_text()
print(title, end='\n')- 출력 결과:
[단독] 최현만, 금융지주 ‘러브콜’ 고사 “사랑하는 미래에셋 창업멤버로 남겠다” [시그널]
새내기주 잔혹사 끊나… 쓰리빌리언 상장 첫날 15% 강세
카카오페이증권, 홍콩 기업과 AI 업무 자동화 협력
포인트엔지니어링, 3분기 흑자 전환 성공
어피니티, 원금 수준서 SSG 투자 ‘마침표’…이커머스 몸값 회복 ‘쉽지않네’ [투자360]
DI동일, 두번째 자사주 소각…보유분 65%
셀리버리, 분기 매출액 미달 사실 발생
하이브로, 신작 '드래곤빌리지 어드벤처' 출시
iM證 “내년 말 기준금리 2.25% 전망…적극적인 통화완화 정책 필요”
다올투자증권, 3Q 영업익 25억원···전년比 흑자 전환
HLB, 간암신약 허가 후 파이프라인 확장 청신호 켜졌다
제이스코홀딩스, 218억 규모 자기 전환사채 매도 결정
KB금융, 기관투자자 30명 초청해 ‘2024년 주주간담회’ 개최
LS증권, 2024년 신입사원 채용 및 교육 진행
내년 2분기부터 공모펀드 거래소에서 주식·ETF처럼 거래한다 [투자360]
JP모간 “주식, 채권 6대4로 투자하면 연평균 6.4% 수익”
바비톡, 캠페인 영상 공개…모델에 '환승연애' 이나연
디아이동일, 자사주 15% 소각…추가 밸류업 정책 검토
삼성화재, 3분기 누적 순익 1조9000억원…'2조 클럽 눈앞'
3분기 실적 순항한 고려아연…표 대결 앞서 영풍 성과도 주목
"지금이다" 주식 내다 파는 미국 기업들
LG엔솔 버테크, 2조원대 계약…美 테라젠에 8GWh 공급
커넥트밸류, 인적자원개발 대상 교육기관 부문 대상 수상
DB금융투자, '디락실' 게임 서비스 오픈
NH투자증권, 서울대병원과 손잡고 유산기부문화 확산 나선다
SSG닷컴, '앓던 이' 뺐다…새 투자자 찾기 성공
롯데케미칼, 더 팔아도 어닝쇼크…재무체력도 '삐끗'
크라우드웍스, 3분기 영업손실 38억…"내년 턴어라운드 목표"
HB인베스트먼트, 3분기 영업이익 31억…전년比 8.4%↑
DI동일, 1549억원 규모 자사주 소각 결정 [주목 e공시][지스타2024]"설레고 기뻤다"…K게임 수장들 곳곳에
캐스팅보터에 공 넘어간 고려아연 분쟁, 앞으로 변수는
국내 3대 신평사 10년만에 수수료 개편…자본성증권 별도 관리 ‘눈길’
여야 합의로 예보 한도 1억 확대 합의...금융당국은 '난색' 왜?
카카오·설탕 가격 상승 여파…오리온, 3분기 영업익 2.6%↓
견고한 1400원 환율…구두개입도 안 먹히는 이유는[외환분석]
→ 생각했던 내용이 다 나왔음!
BeautifulSoup 보충 공부
-
-
예제로 사용할 HTML 문서: 이상한 나라의 엘리스 이야기의 일부 "three sisters"
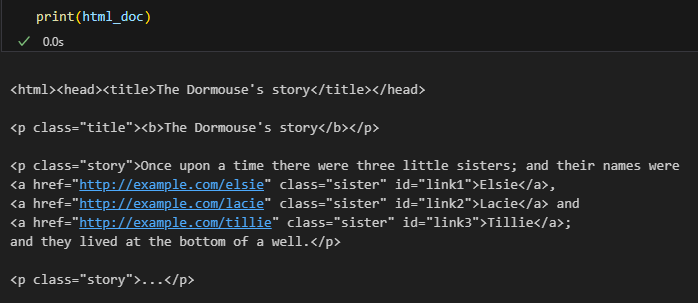
html_doc = """ <html><head><title>The Dormouse's story</title></head> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """print(html_doc)결과
-
-
“three sisters” 문서를 뷰피플수프에 넣으면 BeautifulSoup 객체가 나오는데, 이 객체는 문서를 내포된 데이터 구조로 나타낸다:
.prettify()- html 구조를 파악하기 쉽게 바꿔줌
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
print(soup.prettify())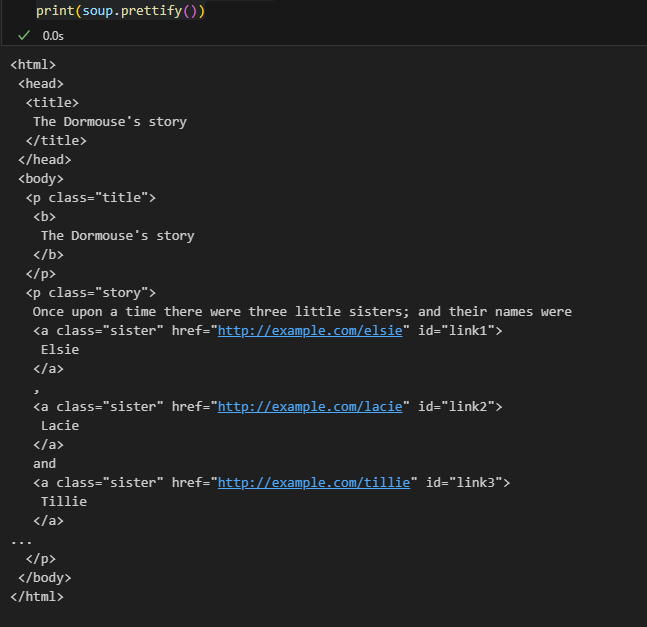
간단하게 데이터 구조를 항해하는 몇 가지 방법
- soup.태그이름
- 특정 태그 안에 있는 데이터들을 뽑아내 줌
- soup.태그이름.name
- 특정 태그의 이름을 알려줌
- soup.태그이름.string
- 특정 태그로 감싸져 있는 string을 뽑아서 알려줌
soup.title
# <title>The Dormouse's story</title>
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>- 한 페이지에서
<a>태그에 존재하는 모든 URL 추출
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie- 페이지에서 텍스트를 모두 추출
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
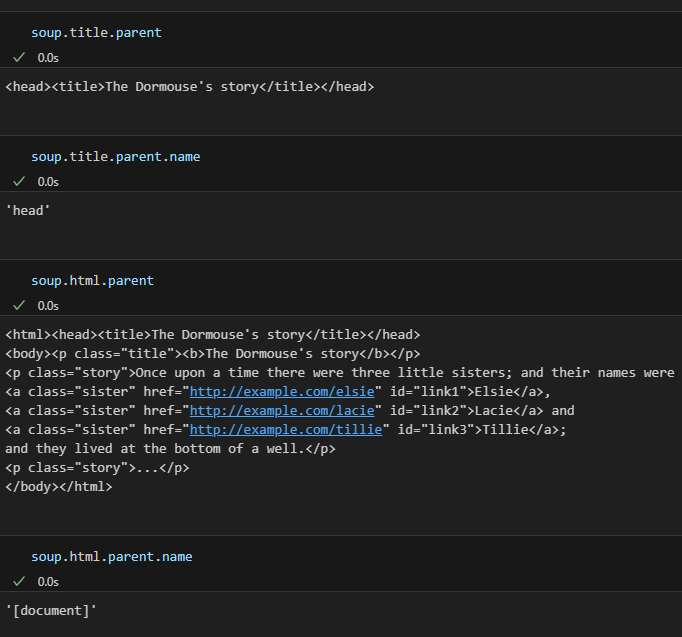
# ...- soup.태그이름.parent
- 특정 태그의 부모 태그의 내용을 알려줌
- soup.태그이름.parent.name
- 특정 태그의 부모 태그 이름을 알려줌
-
soup.태그이름['class']
- 특정 태그의 class가 뭐라고 설정되어있는 지 알 수 있음
-
soup.find('태그이름')또는soup.select_one('태그이름')- 태그 이름에 해당하는 첫 번째 태그 추출

-
soup.find_all('태그이름')또는soup.select('태그이름')- 태그이름에 해당하는 모든 태그들을 추출
find_all의 인수에는 리스트뿐만 아니라 문자열, 정규식도 들어갈 수 있음
#1 fron bs4 import BeautifulSoup bs = BeautifulSoup(html) body_tag = bs.find('body') list1 = body_tag.find_all(['p', 'img']) for tag in list1: print(tag): body 태그를 찾아서 body_tag에 넣어두고 find_all 함수에 리스트 형식으로 찾고 싶은 태그를 넣어줍니다. find_all 함수 실행 결과 p태그와 img태그를 모두 찾아서 리스트로 리턴합니다. 한 번에 여러 가지 태그를 조회하고 싶을 때는 위와 같은 방식으로 해주면 됩니다.
import re tags = bs.find_all(re.compile("^p")) -
find_all 함수에 전달할 수 안수는 태그이름, 속성, 문장, limit 등이 있음
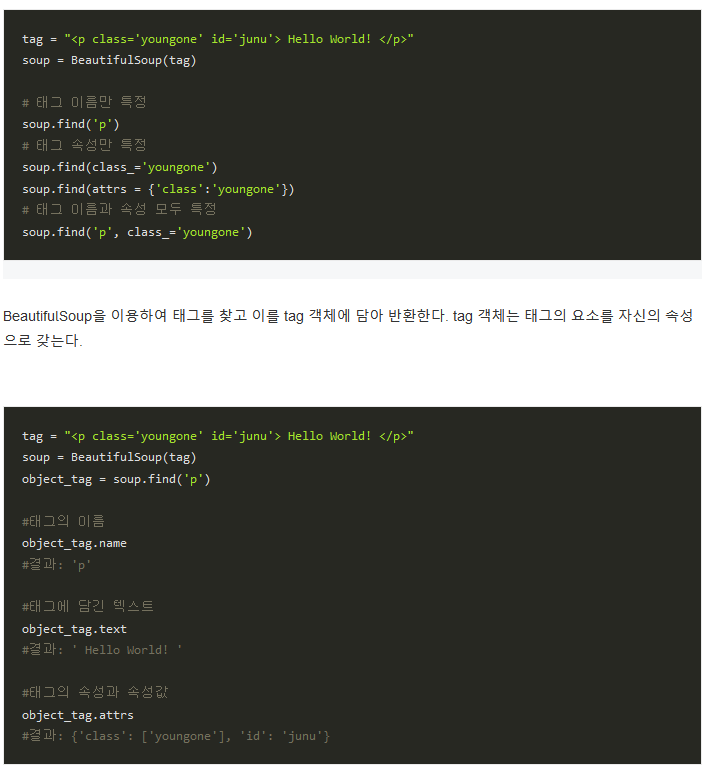
- 속성 이용:
속성 = "속성값"의 형식 - text 인자
- text 인수는 문자열, 정규식, 리스트 등 여러 가지를 인수로 전달할 수 있음
- text는 안에 텍스트가 빈칸을 포함해서 모두 정확히 일치해야 함
- 정규식
(예) text contents 문장 이후에 임의의 한 문자가 존재하는 태그 찾는 코드bs.find_all(text=re.compile(" text +"))
- limit 인수: find_all 함수로 찾아내는 태그의 개수를 제한
- 속성 이용:
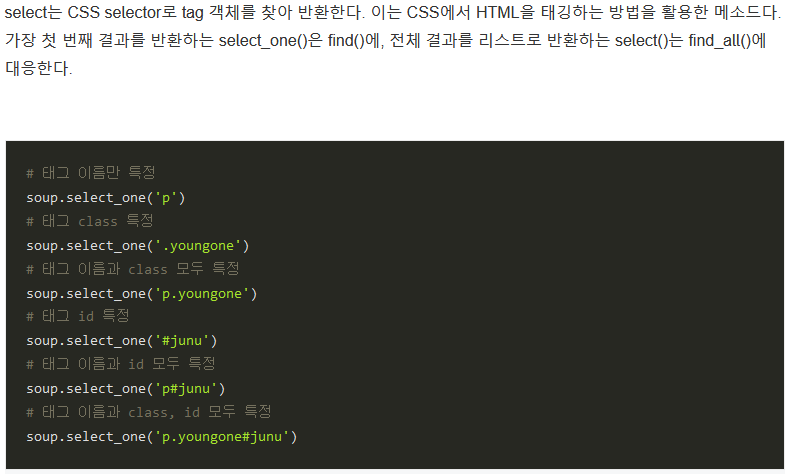
bs.find_all('p', limit=2)find와 select 차이
- find: html tag를 통한 크롤링
- select: css를 통한 크롤링
- select는 >로 하위 태그를 쉽게 찾을 수 잇다는 점이 가장 큰 차이점이라고 함
- 예를 들어 head 태그 아래있는 title태그를 찾고 싶다고 할때, select가 더 직관적인 형태로 태그를 쫓을 수 있음

클래스 이름으로 element 찾기
해석기 설치
- 뷰티플수프는 파이썬 표준 라이브러리에 포함된 HTML 해석기를 지원하지만, 또 수 많은 제-삼자 파이썬 해석기도 지원한다. 그 중 하나는 lxml 해석기이다. 설정에 따라, 다음 명령어들 중 하나로 lxml을 설치하는 편이 좋을 경우가 있다:
$ apt-get install python-lxml
$ easy_install lxml
$ pip install lxml- 각 해석 라이브러리의 장점과 단점
| 해석기 | 전형적 사용방법 | 장점 | 단점 |
|---|---|---|---|
| 파이썬의 html.parser | BeautifulSoup(markup, "html.parser") | 각종 기능 완비, 적절한 속도, 관대함 (파이썬 2.7.3과 3.2에서.) | 별로 관대하지 않음 (파이썬 2.7.3이나 3.2.2 이전 버전에서) |
| lxml의 HTML 해석기 | BeautifulSoup(markup, "lxml") | 아주 빠름, 관대함 | 외부 C 라이브러리 의존 |
| lxml의 XML 해석기 | BeautifulSoup(markup, ["lxml", "xml"]) 또는 BeautifulSoup(markup, "xml") | 아주 빠름, 유일하게 XML 해석기 지원 | 외부 C 라이브러리 의존 |
| html5lib | BeautifulSoup(markup, html5lib) | 아주 관대함, 웹 브라우저의 방식으로 페이지를 해석함, 유효한 HTML5를 생성함 | 아주 느림, 외부 파이썬 라이브러리 의존, 파이썬 2 전용 |
추가로 읽어보면 좋을 블로그
24-11-15 해설
- Ctrl+Shift+C 하면 MouseOver됨
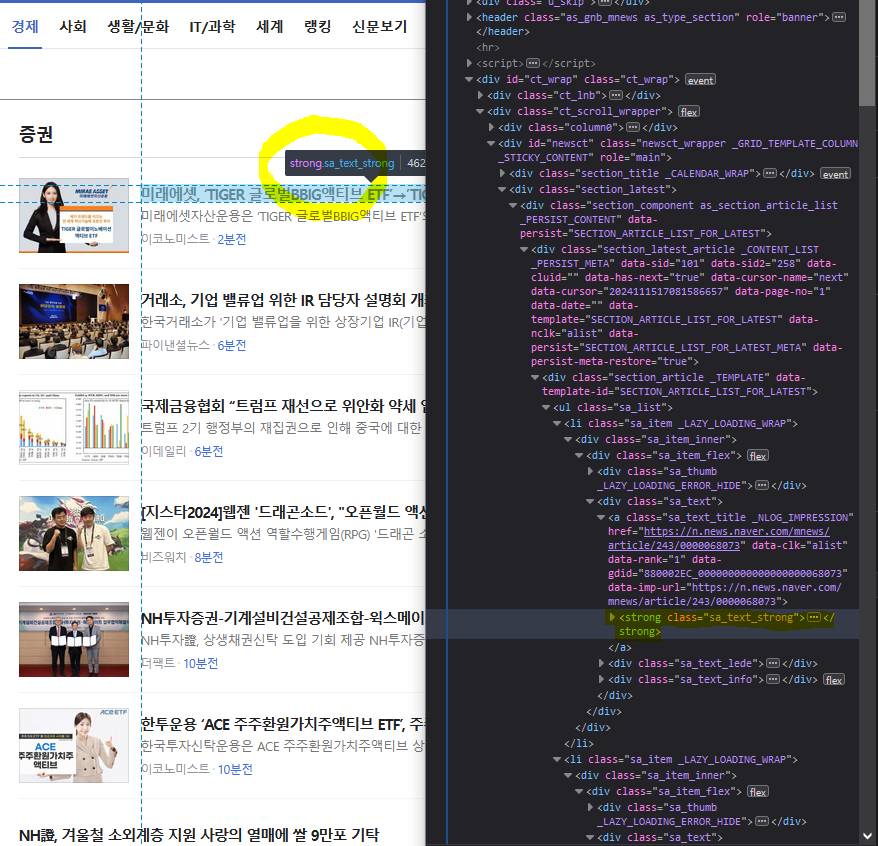
- 제목의 HTML Tag: strong
- strong이 가지고 있는 attributes(속성) 중 class: sa_text_strong
- attribute
- 태그의 동작을 제어하기 위해 "여는 태그" 안에 사용되는 특수 용어
- 속성은 요소 유형의 기본 기능을 수정하거나, 아니면 스스로 기능하지 못하는 특정한 요소 유형에 기능을 제공(HTML 요소 유형의 수정자)
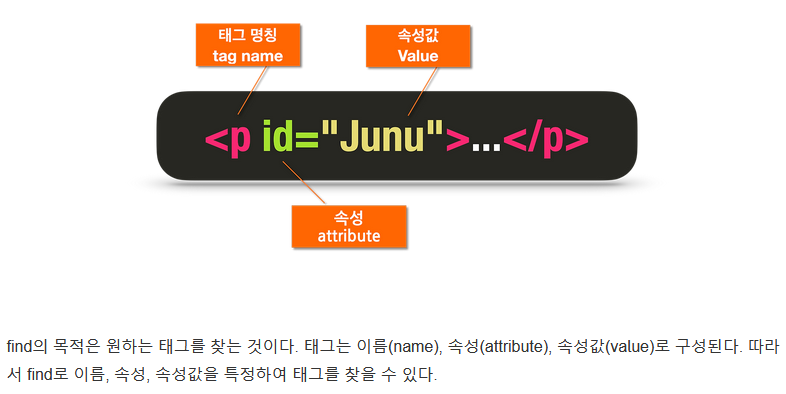
- HTML 요소의 추가적인 정보를 전달하고 이름=“값” 이렇게 쌍으로 온다.
(예)<div class=“my-class”></div>를 보면 div 태그가 class 라는 값이 ‘my-class’인 attribute를 가지고 있음
- attribute
import requests
from bs4 import BeautifulSoup
url = "https://news.naver.com/breakingnews/section/101/258"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 요청이 제대로 들어갔는지 확인
response.status_code[실행 결과]
200titles = soup.find('strong', {'class':'sa_text_strong'})
titles[실행 결과]
<strong class="sa_text_strong">[한경유레카 특징주] HMM, 3분기 호실적에 주가 상승세</strong># 모든 제목을 불러오고 싶을 때
titles = soup.find_all('a', {'class':'sa_text_title'})
for title in titles:
print(title.get_text())-
titles = soup.findAll('a', {'class':'sa_text_title'})라고 써도 됨- 결론부터 말하자면
findAll과find_all은 같은 기능을 하는 메서드임- Beautiful Soup(이하 BS) 3 버전에서는 findAll을 사용했었는데, 이후 Python style guide에서 Methods, Instance Variables의 네이밍을 소문자로 쓰도록 해서 그 점을 반영하기 위해 BS 4버전에서 find_all이라고 이름을 바꿨다고 함
- 결론부터 말하자면
-
.get_text()와.text의 차이-
.text는property(get_text)와 같음- 쉽게 말해
객체.text라고 쓰면get_text메서드 return값이 반환되는 것
- 쉽게 말해
-
get_text와 text가 동일하긴 하지만 get_text()를 쓰게 되면 추가로 인자(Argument)를 매개변수(Parameter)에 넣을 수 있다는 장점이 있음
- 매개변수: 함수를 정의할 때 사용되는 변수
- 인자: 실제 함수가 호출될 때 넘기는 변수값
- get_text() 메서드에는
seperator="",strip=False와 같이 파라미터가 기본으로 지정되어 있는데 호출 시 이를 활용해 seperator를 별도로 주어 연결시키거나 할 수 있는 것
-
자세한 내용은 공식 문서 참고
titles = soup.find_all('strong', {'class':'sa_text_strong'}) for title in titles: print(title.get_text) for title in titles: print(title.text)
-
- class가 두 개 있을 수도 있음!
sa_text_title._NLOG_IMPRESSION- 첫 번째: sa_text_title
- 두 번쨰: _NLOG_IMPRESSION
- 이 경우 둘 중 아무거나 써도 불러올 수 있음
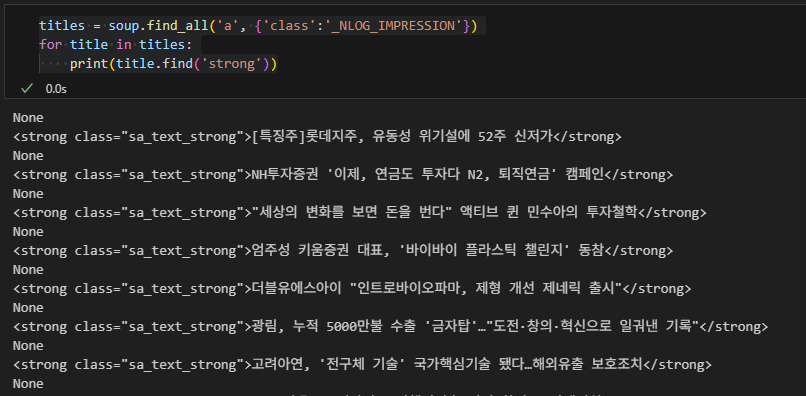
→ 실제로 돌려보니 None값이 나와서 그냥 첫 번째 class 쓰는 게 가장 좋아보임
# 꼭 제목의 제목의 HTML Tag를 가져올 필요는 없음
# 상위 Tag를 가져온 뒤 한 단계 더 깊게(한 번 더 find) 들어가도 됨!
titles = soup.find_all('a', {'class':'sa_text_title'})
for title in titles:
print(title.find('strong')titles = soup.find_all('a', {'class':'sa_text_title'})
for title in titles:
print(title.find('strong').get_text())