📌 Task : 시즌 2와 시즌 3 비교
import pandas as pd
import numpy as np
import time
from PIL import Image
import altair as alt
import seaborn as sns
import matplotlib.pyplot as plt
import datapane as dp
# seaborn 팔레트 설정
palette = sns.color_palette("pastel")
# pandas 라이브러리를 활용한 csv 파일 읽기
set2 = pd.read_csv("set2_game.csv", index_col=0)
set3 = pd.read_csv("set3_game.csv", index_col=0)
del set3['gameDuration_zscore']
del set2['gameDuration_zscore']
# 합치기 전 구분자 달기
set3['Set'] = 'Set3'
set2['Set'] = 'Set2'
df = pd.concat([set3, set2], ignore_index=True)
df
df.groupby('Set').describe()
# 파이 차트 그리기
df_pie = df.groupby('Set')['gameId'].nunique().reset_index()
# matplotlib 라이브러리를 통한 그래프 그리기
# labels 옵션을 통해 그룹값을 표현해줄 수 있습니다.
dplot_pie= plt.figure(figsize=(3,3))
plt.pie(
x=df_pie['gameId'],
labels=df_pie['Set'],
# 소수점 첫째자리까지 표시
autopct='%1.1f',
colors=['#91D9C4', '#9C5FD9'],
startangle=90
)
# 범례 표시하기
plt.legend(df_pie['Set'])
# 타이틀명, 타이틀 위치 왼쪽, 타이틀 여백 50, 글자크기, 굵게 설정
plt.title("pie plot", loc="left", pad=50, fontsize=8, fontweight="bold")
plt.show()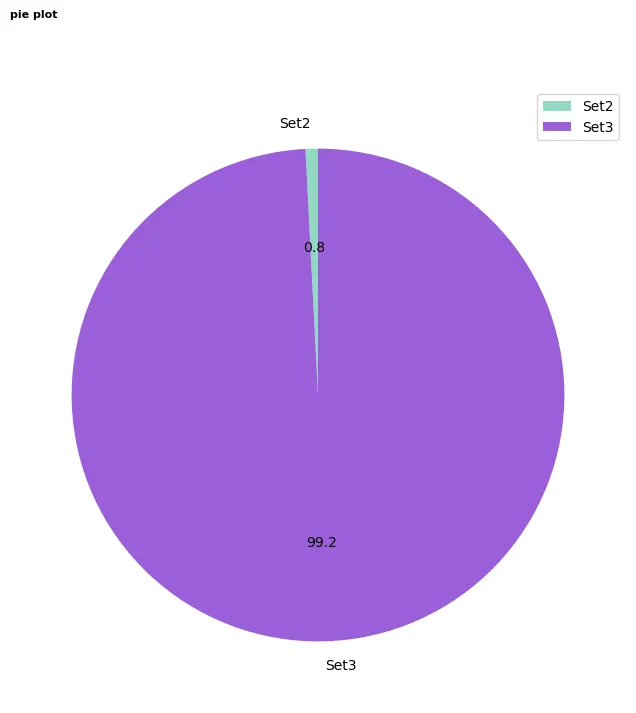
# 시즌별 티어별 게임 시간
df_gameDuration_sns = pd.DataFrame(df_gameDuration.groupby(['Set','Tier'])['gameDuration'].mean())
plt.figure(figsize=(4,6))
sns.barplot(data=df_gameDuration_sns
, x='Tier'
, y='gameDuration'
, hue='Set'
, palette={'Set2':'#91D9C4','Set3':'#9C5FD9'})📌 실행 및 진행 사항 정리
- 데이터 전처리가 끝난 397.944건의 로그에 대해 3,224건의 로그가 시즌 2의 기록으로 판명되었음
- 3,224건 == 406경기
- 일반적으로 모집단이 정규분포라면 표본의 평균의 분포는 정규분포를 이룸
- 중심극한정리에 의해 표본의 크기가 충분히 큰 경우(일반적으로 n≥30), 단일 표본의 평균은 "모집단의 분포와 관계없이" Gaussian에서의 Outcome이라고 볼 수 있음
- 중심극한정리 → 모분포가 어떤 것이라도 여러 가지 조건을 만족한다면 표본의 평균의 분포만은 Gaussian으로 분포한다는 말이라고 함
- 이에 따라 해당 데이터 또한 모집단의 분포와 상관없이 평균의 분포는 정규분포라고 가정할 수 있으므로 표본분산을 이용한 t분포로 대용할 수 있음
- 중심극한정리에 의해 표본의 크기가 충분히 큰 경우(일반적으로 n≥30), 단일 표본의 평균은 "모집단의 분포와 관계없이" Gaussian에서의 Outcome이라고 볼 수 있음
- t 분포는 모분산을 모를 때, Gaussian을 대용해서 실제 표본으로 통계적인 접근을 할 수 있는 분포임
- 중심극한정리를 적용할 수 있는 n≥30인 경우이니 t검정을 해야 함
t검정을 하지 않고, 어느 정도 z검정을 사용할 수 있는 환경이란?
⓵ 평균을 내기 위해 한번에 추출하는 표본 크기가 30보다 큼
⓶ 데이터가 서로 독립적이고, 각각의 데이터는 모집단에서 동일한 확률로 선택되야 함 (i.i.d)
⓷ 또는 모분포가 정규분포 임 (그러나, 평균을 내기 위한 표본크기가 30보다 큰 대규모 표본에서는 중요하지 않음)
💡검정이란 무엇인가
㉠ 분포를 가정할 수 있도록 Null Hypothesis를 정하고,
㉡ 유의수준을 정하고,
㉢ 관측값이 Null Hypothesis에 의한 분포에서 어디에 위치하는지를 찾아낸 후에
㉣ 그 위치를 이용하여 p value를 구한 후에
㉤ 유의수준과 비교해서 Null Hypothesis를 어떻게 할지(채택할지 기각할지)를 정한다.

2 B R 0 2 B