목표
- 머신 러닝의 종류에 대해 알아보기
- 지도 학습
- 비지도 학습
- 강화 학습
학습(러닝)의 종류
머신 러닝이 이제 어떤 것인지 알았으니 머신러닝 모델들에 대해 알아봅시다.
- 학습 방법에 따른 머신 러닝 분류
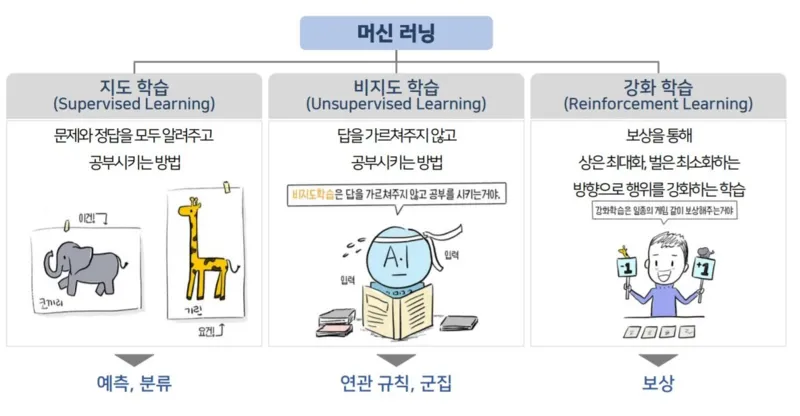
지도 학습(Supervised Learning)
- 문제와 정답을 모두 알려주고 학습시키는 방법
- 독립 변수(특성, Feature, X data)와 종속 변수(타겟, Label, Y data)의 세트로 구성된 데이터셋을 이용해 모델을 학습시킴
- 독립 변수: 원인, 종속 변수: 결과로 이해해도 OK
- Feature가 주어졌을 때 적절한 답변을 모델이 내놓는 것이 목적
- 독립 변수(특성, Feature, X data)와 종속 변수(타겟, Label, Y data)의 세트로 구성된 데이터셋을 이용해 모델을 학습시킴
- 타겟의 성격에 따라 크게 두 가지 문제로 분류
1. 예측(Prediction)
- 타겟이 연속형(Continuous)인 경우
- 평점, 시각, 가격, 변동률 등
- 평점, 시각, 가격, 변동률 등
- 예시
- 머니볼
- 2000년대 초반에 낮은 예산으로 운영되던 오클랜드 애슬레틱스의 단장 빌리 빈은 데이터를 기반으로 선수 가치를 평가하는 ‘세이버 매트릭스’라는 분야를 창시
- 선수 가치를 평가하여 선수 연봉 대비 승리에 미치는 영향을 예측하는 모델을 생성
- 승리에 영향을 변수를 탐색하고 OPS(출루율+장타율), WHIP(이닝당 안타와 볼넷 허용률) 등의 지표를 생성하여 분석에 활용
- 저예산으로도 효율이 좋은 선수를 구매 및 트레이드하여 2002년에 20연승을 하고 플레이오프에 진출하는 등의 저력을 발휘
- 와인 품질 예측
- 프랑스 보르도 지역의 ‘샤토 마고’ 와인의 경우 같은 와이너리에서 생성되는 와인임에도 생산연도에 따라 가격(맛)이 천차 만별임

- 기존에는 포도 원액이 와인으로 바뀌기 전에 전문가가 맛을 보고 품질을 평가
- 프린스턴 대학교 경제학과 Orley Ashenfelter 교수가 보르도 지역의 기후 데이터와 와인 가격을 이용해 와인 품질을 예측하는 모델을 생성
: 보다 객관적인 와인 품질 예측 → 생산성과 투자 획득에 영향

- 프랑스 보르도 지역의 ‘샤토 마고’ 와인의 경우 같은 와이너리에서 생성되는 와인임에도 생산연도에 따라 가격(맛)이 천차 만별임
- 머니볼
2. 분류(Classification)
- 타겟이 범주형(Categorical)인 경우
- 스팸메일, 감염, 이미지 등
- 예시
- Gmail 스팸메일 분류
- 구글의 경우 이메일 서비스인 Gmail에 다양한 머신 러닝 모델을 결합하여 스팸메일을 분류
- 초기에는 키워드 또는 발신자 주소 등을 활용한 규칙(Rule) 기반 필터링 사용
- 나이브 베이즈나 서포트 벡터 머신과 같은 머신 러닝 기법 도입 후 정확도 향상 → 현재는 딥 러닝까지 활용하여 스팸 뿐만 아니라 다양한 카테고리로 메일 분류
- Gmail 스팸메일 분류
비지도 학습(Unsupervised Learning)
- 답을 가르쳐주지 않고 공부시키는 방법
- 모델을 학습할 때 별도의 타겟 변수를 설정하지 않음
- 주어진 데이터에서 모델이 스스로 데이터의 특성을 파악하고 학습
연관 규칙(Association Rule)
- 장바구니 분석이라고도 함
- 데이터셋 내에서 항목 간의 연관된 규칙을 찾는 방법
- 예시
- 타겟(Target)의 임신 예측 모델
- 2002년 타겟은 데이터 분석 전문가 앤드루 폴을 영입해 ‘임신 유무 예측 모델’ 개발
- 매장 및 온라인에서의 구매 상품 데이터, 회원 정보, 온라인 검색 내역 등의 데이터를 활용해 임신 중인 고객의 주요 구매 상품 및 구매 패턴 분석
- 임산부가 무향 티슈나 마그네슘을 구매할 비율이 87%로 높다는 사실 확인
- 임산부일 가능성이 높은 사람에게 산모복, 아기용품 등에 사용 가능한 쿠폰을 우편으로 보내는 타겟 마케팅 진행 → 한 여고생이 이 쿠폰을 받게 되어 아버지가 항의하였으나, 실제 임신 중이었다는 사실을 알게 됨
- 타겟(Target)의 임신 예측 모델
군집 분석(Clustering Analysis)
- 비슷한 특성에 따라 데이터를 더 작은 그룹으로 세분화
- 이상 거래 탐지, 뉴스 주제별 군집화 등
- 예시
- 넷플릭스의 컨텐츠 유사성 지도
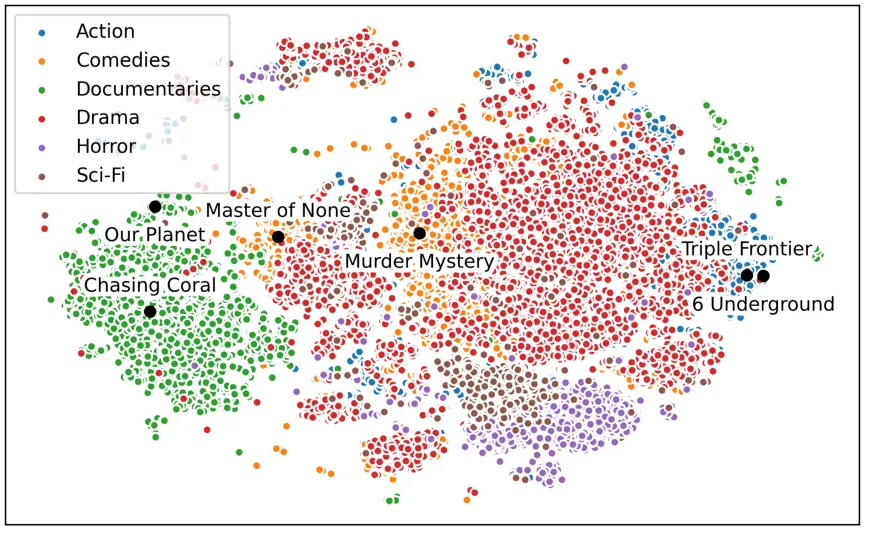
- 작품의 메타 데이터(개봉일, 시간, 장르 등), 키워드, 줄거리 등을 임베딩하여 유사성 지도를 생성 → 넷플릭스 작품과 다른 영화/드라마 사이 관계를 확인하는 데 도움
- 유사 컨텐츠의 국가별 흥행 정도를 참고하여 프로그램 상영 및 마케팅에 활용
- 넷플릭스의 컨텐츠 유사성 지도
embedding
- 고차원의 input space를 다루기 위해, cluster 분산을 최대화할 수 있는 저차원으로 차원축소
- 고차원의 데이터를 저차원으로 맵핑
→ 주성분분석, 차원축소도 넓은 의미로 보면 임베딩에 속함
임베딩은 머신 러닝 모델과 시맨틱 검색 알고리즘에서 사용하도록 설계된 텍스트, 이미지, 오디오와 같은 값 또는 개체의 표현입니다. 임베딩은 이러한 개체를 각 개체가 가지고 있거나 가지고 있지 않은 요소 또는 특성, 개체가 속한 범주에 따라 수학적 형태로 변환합니다.
기본적으로 임베딩을 사용하면 머신 러닝 모델이 유사한 개체를 찾을 수 있습니다. 사진이나 문서가 주어지면 임베딩을 사용하는 머신 러닝 모델이 유사한 사진이나 문서를 찾을 수 있습니다. 임베딩은 컴퓨터가 단어와 다른 개체 간의 관계를 이해할 수 있게 해주므로 임베딩은 인공 지능(AI)의 기초가 됩니다.
기술적으로, 임베딩은 각 객체에 대한 의미 있는 데이터를 캡처하기 위해 머신 러닝 모델에 의해 생성된 벡터입니다.
강화 학습(Reinforcement Learning)

- 보상을 통해 상은 최대화, 벌은 최소화하는 방향으로 행위를 강화하는 학습
- 에이전트가 시행착오를 통해 학습하는 방식
- 실제 사람이나 동물이 학습하는 방식과 유사
- 예시
- 게임 AI(알파고 등)
- 로봇 제어 및 자율주행
- 게임 AI(알파고 등)
→ 게임은 점수를 리워드로 사용

2 B R 0 2 B