목표
데이터를 활용해 머신 러닝 모델을 학스하고 평가하는 과정에 대해 살펴보기
- 머신 러닝 모델링의 전체적인 과정 이해
- 머신 러닝 모델을 학습하고 결과를 해석할 때 주의할 점에 대해 알아보기
머신 러닝 모델링
머신 러닝 모델링을 하는 전반적인 과정 알아보기
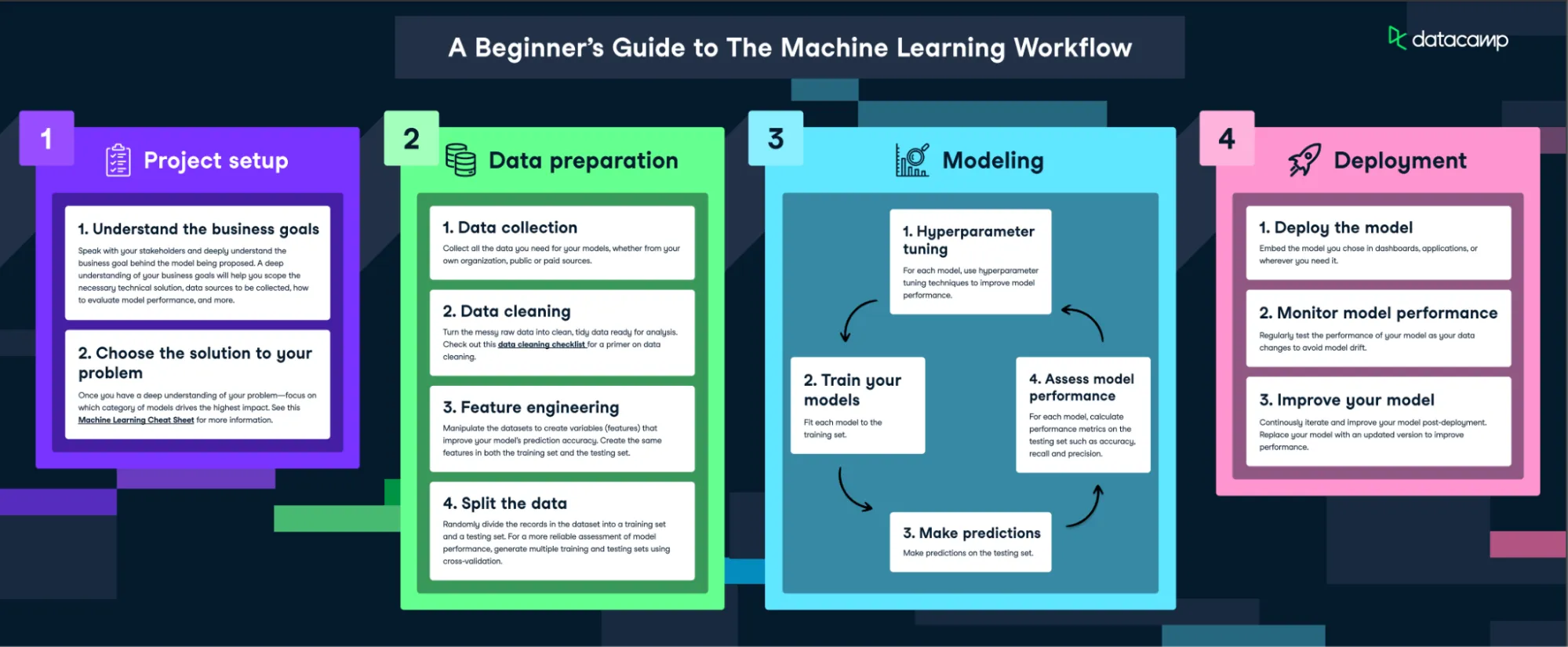
문제 정의
-
모델로 해결하고 싶은 문제가 무엇인지 확실하게 정의
- 타겟이 있는 데이터인가?
- 타겟이 있다면 → 지도 학습
분류 문제인가? 예측 문제인가? - 타겟이 없다면 → 비지도 학습
데이터에서 어떤 가치를 뽑아내고 싶은가?
어떤 모델을 만들어야 하는가?
- 타겟이 있다면 → 지도 학습
- 타겟이 있는 데이터인가?
-
문제에 대한 나의 접근 방식 설정
- 가설 설정
- 어떤 변수가 특정 값에 영향을 줄 것이다
- 모델 설정
- 분류 문제인지, 예측 문제인지에 따라 사용하는 모델이 다르기 때문
- 가설 설정
데이터 전처리
데이터 수집
- 문제 해결에 사용하기 위한 데이터를 수집
- 머신 러닝은 경험으로부터 학습하기 때문에 데이터가 반드시 필요합니다!
- 데이터는 잘 정리되어 있는 경우도 있고, 그렇지 않은 경우도 있음
- 상황에 따라 접근 방식이 달라짐
- Checkpoint
- 지금 바로 확보해서 분석 가능한 데이터인가?
- 회사 데이터 마트에 데이터가 이미 있다면 바로 분석 진행하면 됨
- 당장 확보는 어렵지만 노력하면 획득 가능한 데이터인가?
- Open API를 통해 데이터를 받을 수 있는 경우
- 크롤링을 통해 인터넷에 있는 데이터를 모으는 경우
- 확보하기 어려운 데이터인가?
- 경쟁사 판매량
- 회사 기밀 정보
→ 문제를 다시 정의해서 상단의 두 가지 형태의 데이터로 작업할 수 있는 문제로 만들어햐 함
- 지금 바로 확보해서 분석 가능한 데이터인가?
데이터 클리닝
- 분석에 적합한 형태로 데이터를 정제하고 가공
- 우리가 실습에서 쓰는 데이터들은 공유를 위해 데이터 정합성을 맞추고 올리는 경우가 많음
- 실제 데이터는 그렇지 않은 경우가 훨씬 더 많아서 반드시 데이터 클리닝 확인해야 함
- Checkpoint
- 데이터 타입 확인
- 결측치 처리 및 이상치 제거
- 정규화(Normalization)
- 필요한 경우 정규화 진행
QnA
- 머신러닝 모델에 사용되는 수치형 데이터는 가급적 모두 정규화나 표준화를 해야 하나요?
- 스케일이 변수에 따라 너무 크게 차이나면 해석할 때 어렵기 때문에 스케일링을 통해 각각의 변수를 동등한 조건에서 학습될 수 있도록 정규화를 하는 과정이 필요해요.
- 하지만 의사결정나무 같은 경우는 정규화가 없어도 성능에 큰 차이가 없기 때문에 이러한 경우는 정규화를 진행하지 않아도 되겠죠.
- 해당 스케일을 그대로 적용해 스케일이 모델에 영향을 미치는 걸 확인하고 싶을 경우에는 스케일링을 하지 않을 수도 있겠네요.
피쳐 엔지니어링(Feature Engineering)
- 다양한 독립변수 중에서 분석에 활용하기 위한 변수를 적절하게 선택하거나 필요에 따라 새로운 변수를 생성하는 과정
- feature == 학습에 사용하는 독립변수
- Checkpoint
- 도메인 지식 등을 활용하면 좋음
- 탐색적 데이터 분석(EDA)을 통해 변수 상관관계 분석
→ 지난 시간 '머니볼' 예시에서 새로운 변수를 만든 것도(OPS(출루율+장타율), WHIP(이닝당 안타와 볼넷 허용률) 등의 지표를 생성) 피쳐 엔지니어링이라 할 수 있습니다.
데이터 분할
- 분석에 사용하기 위한 데이터를 나누는 작업
- 보통 Train/Test 데이터로 구분하거나 Train/Validation/Test 데이터로 구분
- Train:Test의 비율은 보통 6:4 또는 7:3 정도로 나눔
- 시계열 데이터의 경우 특정 시점을 기준으로 데이터 분할
- 한 번에 학습하기에 데이터 양이 많다면 batch 단위로 구분
- 보통 Train/Test 데이터로 구분하거나 Train/Validation/Test 데이터로 구분
→ 데이터가 한정적인 경우(데이터 확보가 어려운 경우) 데이터를 세분화해서(Train/Validation/Test 데이터로 구분) 활용하는 경우가 많습니다.
→ 시계열 데이터의 경우 미래 데이터로 학습해서 과거를 예측하면 당연히 잘 맞추게 되고 bias도 커지겠죠? 그래서 시점을 잘 정해줘야 합니다.
모델링
- 학습에 사용할 모델을 선택하고 모델 생성
모델의 종류
- 지도 학습
- 분류 및 예측
- 선형 회귀 (예측)
- 로지스틱 회귀 (분류)
- 나이브 베이즈 (분류)
- 서포트 벡터 머신 (분류, 예측)
- 랜덤 포레스트 (분류, 예측)
- 다층 퍼셉트론 (분류, 예측)
- 분류 및 예측
- 비지도학습
- 군집 분석
- 주성분 분석(PCA)
- 계층적 군집화
- K-means
- DBSCAN
- 군집 분석
모델 작성
- 대부분의 머신 러닝 모델은 sklearn을 활용해 구현 가능

- 모델에 익숙해지기 전까지는 sklearn 공식 문서를 보면서 익히기
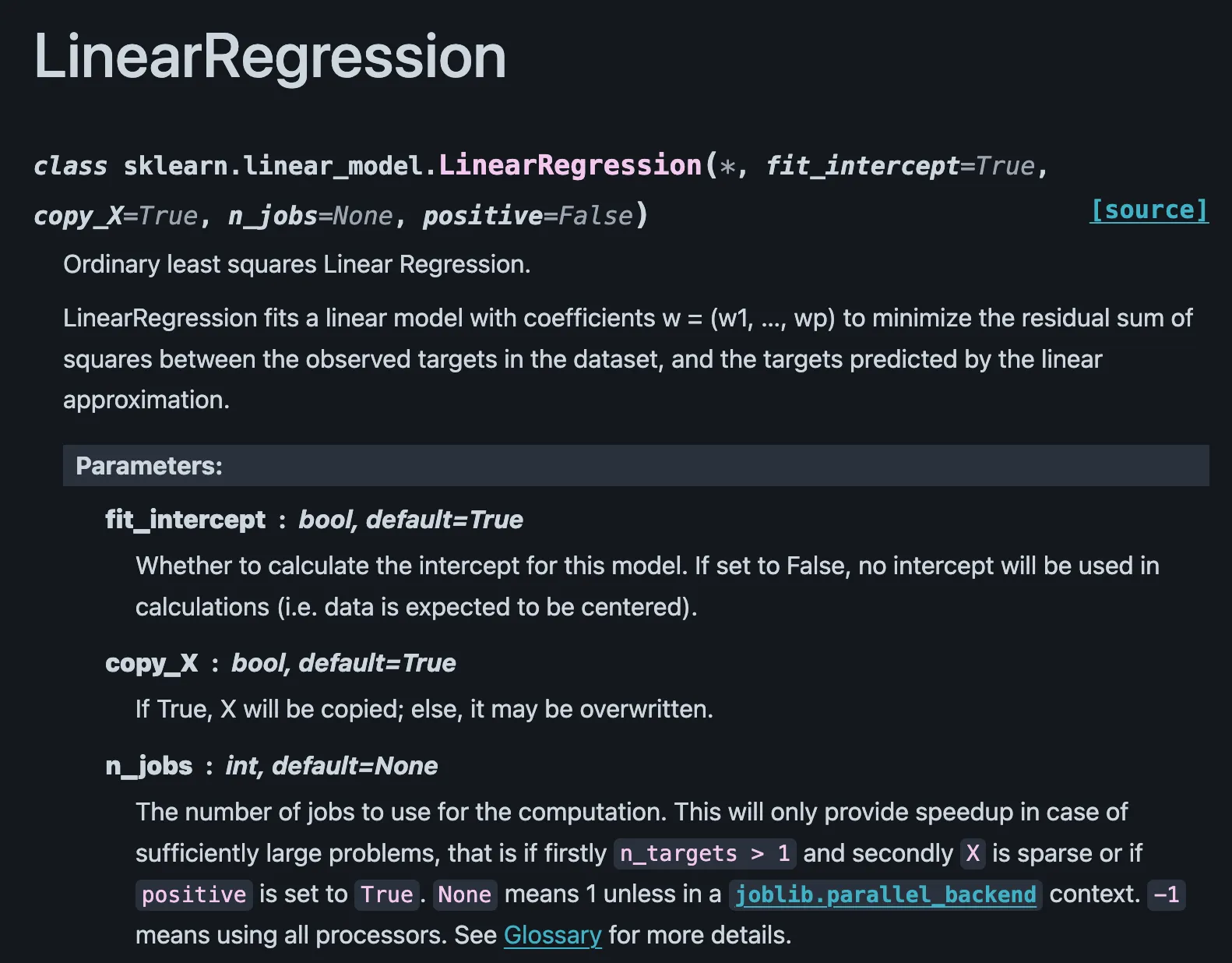
- 모델에 익숙해지기 전까지는 sklearn 공식 문서를 보면서 익히기
-
학습 데이터를 이용해 모델을 학습시키기
-
테스트 데이터를 이용해 모델을 이용한 예측을 진행
-
성능 지표를 활용해 모델의 성능을 평가
- 분류 모델
- 정확도(Accuracy)
- 정밀도(Precision)
- 재현율(Recall)
- 예측 모델
- MSE(Mean Squared Error)
- RMSE(Root Mean Squared Error)
- MAE(Mean Absolute Error)
- 군집 분석의 경우 군집화된 결과물을 직접 확인하며 성능을 평가
- 분류 모델
-
모델 성능을 끌어올리기 위해 모델의 하이퍼 파라미터 값을 변경하며 위 과정을 반복
- 하이퍼 파라미터(Hyper Parameter)란?
- 모델을 학습하기 전에 사용자가 직접 값을 설정해줘야 하는 변수
- 동일한 모델이더라도 어떤 값을 설정하느냐에 따라 모델 성능이 달라질 수 있음
- 하이퍼 파라미터 탐색 방식
- grid Search, Random Search 등의 방식을 이용해 탐색하는 것이 편리
- 하이퍼 파라미터(Hyper Parameter)란?
| 종류 | Grid Search | Random Search |
|---|---|---|
| 탐색 방식 | 모든 조합 시도 | 랜덤 샘플링 |
| 장점 | 체계적, 모든 가능성 고려 | 효율적, 적은 계산량 |
| 단점 | 계산량 많음, 고차원 공간에서 비효율적 | 최적값을 찾지 못할 가능성 |
| 적용 시기 | 하이퍼파라미터 개수가 작고, 정확한 최적값을 찾아야 할 때 | 하이퍼파라미터 개수가 많고, 빠르게 좋은 결과를 얻고 싶을 때 |
보통 처음 머신 러닝 모델을 돌릴 때는 하이퍼 파라미터를 어떻게 설정해야 할지 모르는 상태이므로 기본 설정값으로 돌리거나 휴리스틱(heuristic)한 값을 넣음
- 휴리스틱(heuristic): '대충 어림짐작하기'입니다. (눈대중으로 맞추기, 즉흥적으로 맞추기, 주먹구구식으로 맞추기 등)
- 사람의 심리에 기반을 두고 무엇인가가 대충 이럴 것이다 라고 빠르게 판단을 내리는 것
모델을 학습하고 평가할 때 주의 사항
- 오버피팅(Overfitting, 과적합)
- 머신 러닝 모델이 학습 데이터에 과도하게 맞춰져서 새로운 데이터에 대해 일반화가 떨어지는 현상
- 묻지도 따지지도 않고 성능 지표를 줄이는 것에 집중하기 때문
- 주어진 데이터에 대해서만 결과가 좋게 나오면 되는 거 아닌가요?
- 머신 러닝의 목적이 예측과 일반화 성능을 향상시키는 것이기 때문에 오버피팅은 치명적
- 머신 러닝 모델이 학습 데이터에 과도하게 맞춰져서 새로운 데이터에 대해 일반화가 떨어지는 현상
- 오버피팅을 방지하는 방법
- 모델 단순화
- 모델 학습에 사용하는 독립변수를 일부만 추려서 활용하면 일반화 성능을 높일 수 있음
- 데이터 증강
- 보다 다양하고 많은 양의 데이터를 활용해서 모델을 학습하면 일반화 성능을 높일 수 있음
- 모델 학습에 규제 적용
- 모델 학습 시 L1, L2 규제를 적용하면 오버피팅 방지에 도움을 줌
- L1 규제 (Lasso): 일부 변수의 가중치를 0으로 만들어 피쳐를 선택 효과를 가짐
- L2 규제 (Ridge): 모든 변수의 가중치를 작게 만드는 효과가 있어, 과적합을 방지하고 모델의 일반화 성능을 향상에 도움
- 모델 학습 시 L1, L2 규제를 적용하면 오버피팅 방지에 도움을 줌
- 모델 테스트 시 교차검증 사용
- K-Fold 교차 검증
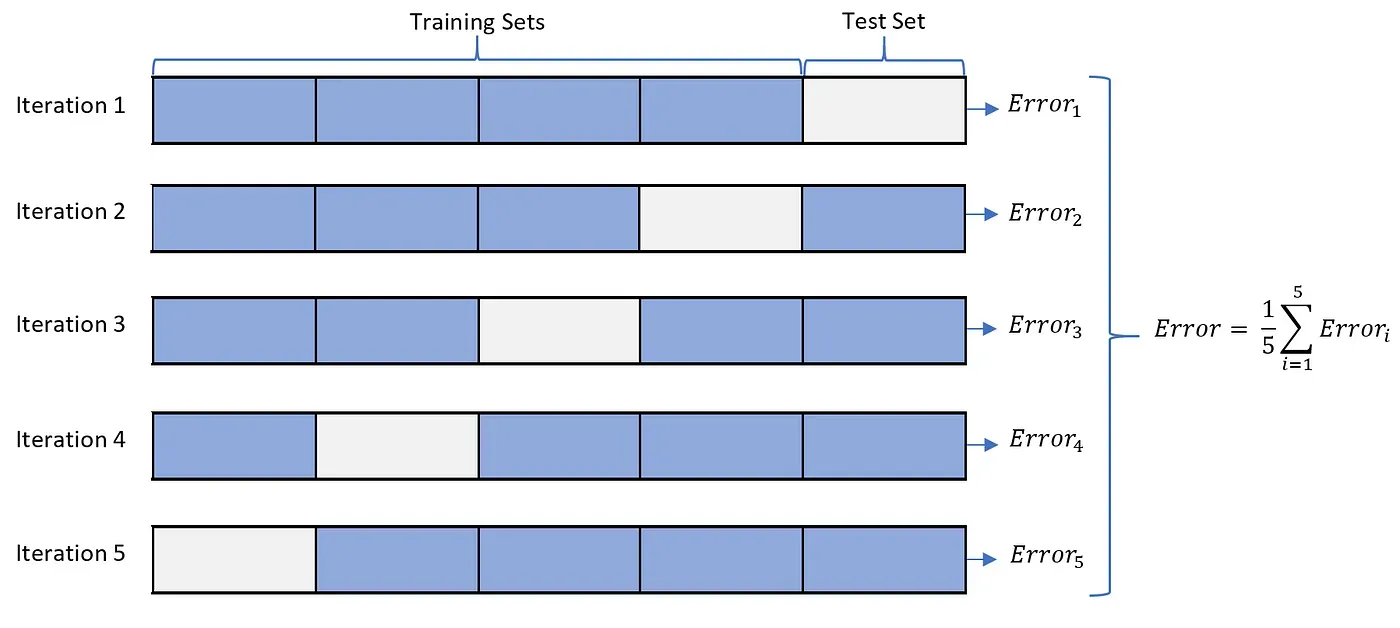
- 전체 데이터를 K개의 서로 다른 조각(Fold)로 나눠서 이를 학습 데이터와 검증 데이터로 번갈아서 사용하는 방식
- K번의 데이터 조합으로 모델을 학습 및 평가하기 때문에 오버피팅을 방지하는 데 도움이 됨
- K-Fold 교차 검증
배포
- 학습된 모델을 서비스화 하는 것
- 데이터 팀에서는 실제 데이터에 바로 머신 러닝 모델을 적용하여 문제 해결에 사용하는 경우가 많음
- 실시간으로 모델을 사용할 필요가 없는 경우에는 모델의 결과물을 분석하여 인사이트를 도출하는 작업을 함
모델의 결과를 해석할 때 고려해야 할 점
- 변수의 중요도
- 모델이 문제 해결을 위한 학습을 하는 과정에서, 특정 변수에 얼마나 가중치를 두고 분류 및 예측을 하는지를 알 수 있는 경우
- 가중치가 높은 변수일수록 문제 해결에 영향을 많이 주는 변수로 이해할 수 있습니다.
→ 원인, 상관관계, 어떤 변수에 집중해야 하는지를 알 수 있음
(머신러닝, 딥러닝의 경우 아웃풋은 인간과 유사하게 원하는 대로 도출할 수 있지만 어떻게&무엇을 근거로 그러한 결과가 나왔는지는 알 수 없음 → BLACK BOX)
딥러닝이 학습하면서 하는 일은 절대적인 정답 또는 해답을 찾는 것이 아닙니다. 인풋이 있을 때 '어떻게' 원하는 아웃풋을 도출하는지를 찾는 것입니다. 일반적으로는 많은 데이터와 지도 학습(supervised learning)을 이용하여 학습시키는데, 어떤 데이터가 주어지느냐에 따라 그 기준도 '상대적'으로 달라질 것입니다.
이 때 내부적으로 원하는 아웃풋을 도출해내기 위한 여러가지 기준을 정하게 되는데 우리는 그 내부를 들여다볼 수 없습니다. 최근의 딥러닝 모델들은 레이어가 최소 수십개로 '딥'하게 학습하기 떄문에 그 계산이 굉장히 복잡하기 때문입니다.
99%의 정확도로 암을 진단하는, 딥러닝으로 학습시킨 AI 가 있다고 해보죠. 이 AI가 어떤 환자를 암으로 진단했는데 현대의 의료기술로는 암이라는 증거를 찾을 수 없었습니다. 그렇다면 이 AI는 학습하는 과정에서 자신만의 기준을 찾았다는 것인데 그것은 굉장히 중요한 발견일 수 있습니다. 하지만 그 기준은 설계한 사람이라도 알 수 없습니다.
- 변수의 중요도를 확인하는 여러 방법들
- 회귀 모델(Regression)의 계수
- 회귀 모델과 로지스틱 회귀 모델의 경우 계수의 절댓값이 클수록 해당 변수가 중요하다고 할 수 있습니다.
- 이 때 변수 별 값의 크기(Scale)가 계수값에 영향을 주기 때문에, 정규화(Normalization)를 한 상태에서 비교하는 것이 옳습니다.
- 의사결정나무 기반 모델의 Feature Importance:
- 여러 개의 의사결정나무의 합으로 이루어진 랜덤 포레스트(Random Forest)나 XGBoost 같은 모델의 경우
- 노드를 분리할 때 어떤 변수가 많이 사용되었는지를 이용해 변수의 중요도를 측정할 수 있습니다.
- SHAP(SHapley Additive exPlanations)
- 게임 이론의 샤플리(Shapley) 값을 기반으로 각 특징이 예측에 얼마나 기여했는지를 설명하는 방법입니다.
- 전체 모델에 대한 변수 중요도 뿐만 아니라 개별 데이터에 대해서도 각 변수의 영향력을 분석할 수 있습니다.
- 자세한 설명은 링크를 참고해주세요
- 회귀 모델(Regression)의 계수
- 성능 지표에 대한 해석
- 모델의 성능을 평가하는 지표의 종류는 다양합니다.
- 이 중에서 모델로 해결하고자 하는 문제에 맞는 평가 지표를 설정하고 비교하는 것이 중요합니다.
- 적절한 평가 지표를 설정하고, 평가 지표의 값이 모델을 일반화하여 사용할 수 있는 지 판단할 수 있어야 합니다.(배경 지식, 도메인 지식 필요)
- ex) 원/달러 가격을 예측하는 모델을 만들었는데 RMSE 값이 100 정도 나왔어요. 이전에 영화 관람객 수 예측 모델에서도 RMSE 값이 비슷하게 나와서 성능이 괜찮았는데 이는 좋은 모델일까요?
→ RMSE는 예측값의 평균 오차를 의미하며, 타겟 변수의 단위에 따라 오차가 큰지 작은지 가늠할 수 있습니다. (가격이 100 차이인 것(환율이 1400인 걸 1300~1500 사이로 예측)과 인원 수가 100 차이(천만 관중 수를 100 차이로 예측)인 건 달라요) - ex) 환자의 데이터를 사용해 특정 질병을 진단하는 모델을 만들었어요. 여러 모델 중에 정확도(Accuracy)가 높은 모델을 택했는데, 재현율(Recall) 기준으로는 성능이 낮아요. 이것은 좋은 모델일까요?
→ 진단 모델에서는 재현율(실제 양성인 것 중 양성으로 분류할 비율)이 중요한 지표입니다.
- ex) 원/달러 가격을 예측하는 모델을 만들었는데 RMSE 값이 100 정도 나왔어요. 이전에 영화 관람객 수 예측 모델에서도 RMSE 값이 비슷하게 나와서 성능이 괜찮았는데 이는 좋은 모델일까요?
🡆 어떤 task를 수행하는지에 따라 평가 지표를 다르게 적용해야 함!
실습
위에서 배운 내용을 바탕으로 머신 러닝 모델링 과정 예제 코드 살펴보기
패키지 호출
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import math
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import warnings
warnings.filterwarnings('ignore')1. 예측 모델: 캘리포니아 집값 예측
데이터 불러오기
dataset_housing = datasets.fetch_california_housing()
df_housing = pd.DataFrame(dataset_housing.data, columns=dataset_housing.feature_names)
df_housing['target'] = dataset_housing.target
print(df_housing.shape) # 사이즈 확인
df_housing.head()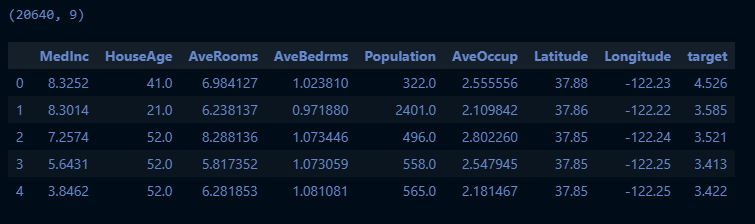
데이터 전처리
## 1. 위치 데이터를 활용한 새로운 피처 생성 -> 공항까지의 거리
## 캘리포니아 주의 5대 공항의 위치 정보를 이용해서 가장 가까운 공항까지의 거리를 새로운 변수로 생성
def calculate_distance(lat, lon):
# 공항 위도, 경도 리스트
airport_lat_lon_list = [(33.9425, -118.4085), (37.6189, -122.3749), (32.7333, -117.1894), (33.6747, -117.8533), (37.3625, -121.929)]
dist_airport_list = []
for airport_lat_lon in airport_lat_lon_list:
airport_lat, airport_lon = airport_lat_lon
# 위도, 경도를 radian 값으로 변환
lat1, lon1, lat2, lon2 = map(math.radians, [lat, lon, airport_lat, airport_lon])
# Haversine formula
dlat = lat2 - lat1
dlon = lon2 - lon1
a = math.sin(dlat/2)**2 + math.cos(lat1) * math.cos(lat2) * math.sin(dlon/2)**2
c = 2 * math.asin(math.sqrt(a))
# Radius of earth in kilometers
r = 6371
# Calculate the distance
distance = c * r
dist_airport_list.append(distance)
res = min(dist_airport_list)
return res
df_housing['dist_airport'] = df_housing.apply(lambda row: calculate_distance(row['Latitude'], row['Longitude']), axis=1)
df_housing.head()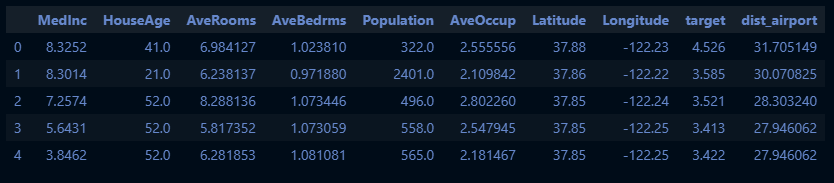
# 데이터 분리
X = df_housing.drop(['target', 'Latitude', 'Longitude'], axis=1)
y = df_housing['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)선형회귀 모델 학습시키기
# Scikit-Learn 의 선형회귀 모델 사용
linear_reg = LinearRegression()
linear_reg.fit(X_train_scaled, y_train)
# 학습 데이터를 입력했을 떄의 모델 성능
y_insample_linear = linear_reg.predict(X_train_scaled)
insample_rmse_linear = mean_squared_error(y_train, y_insample_linear)**0.5
insample_r2_linear = r2_score(y_train, y_insample_linear)
print(f"In-Sample RMSE: {insample_rmse_linear:.4f}")
print(f"In-Sample R²: {insample_r2_linear:.4f}")[실행 결과]
In-Sample RMSE: 0.7468
In-Sample R²: 0.5828학습 결과 확인
# 예측 및 평가
y_pred_linear = linear_reg.predict(X_test_scaled)
rmse_linear = mean_squared_error(y_test, y_pred_linear)**0.5
r2_linear = r2_score(y_test, y_pred_linear)
print(f"RMSE: {rmse_linear:.4f}")
print(f"R²: {r2_linear:.4f}")[실행 결과]
RMSE: 0.7659
R²: 0.5524# 결과 그래프
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred_linear)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)
plt.title('Price Prediction - Linear Regression')
plt.xlabel('Actual ($100K)')
plt.ylabel('Predict ($100K)')
plt.tight_layout()
plt.show()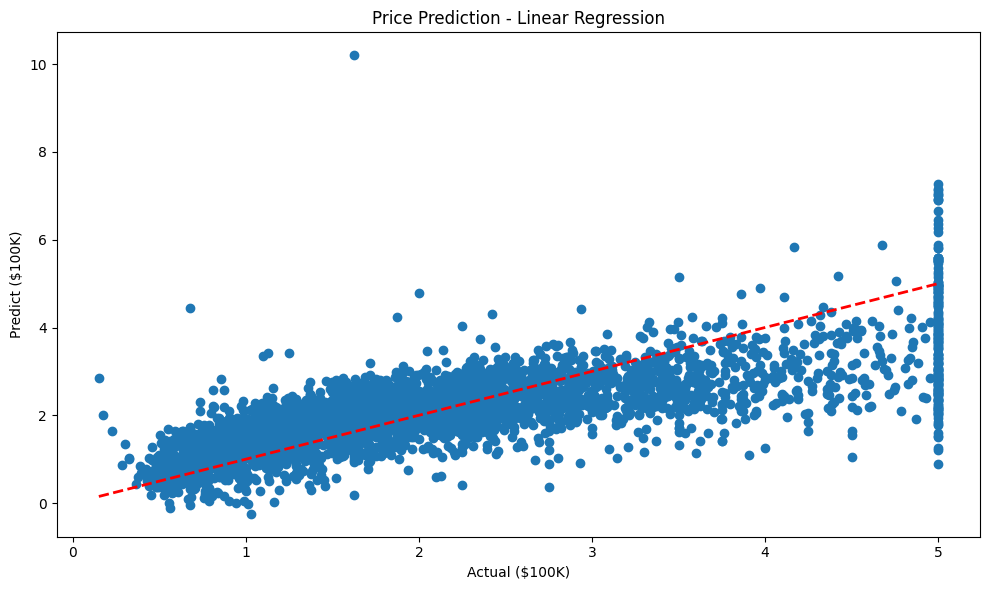
print("\n특징별 계수:")
for name, coef in zip(X.columns, linear_reg.coef_):
print(f"{name}: {coef:.4f}")[실행 결과]
특징별 계수:
MedInc: 0.8845
HouseAge: 0.1440
AveRooms: -0.3327
AveBedrms: 0.3408
Population: -0.0091
AveOccup: -0.0420
dist_airport: -0.25902. 군집 모델: 붓꽃 데이터 군집화
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import seaborn as sns
data_iris = load_iris()
df_iris = pd.DataFrame(data_iris.data, columns=data_iris.feature_names)
df_iris['target'] = data_iris.target
df_iris.head()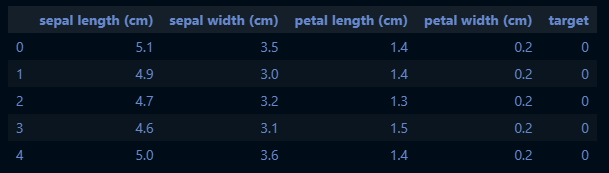
# 데이터 스케일링
X = df_iris.drop('target', axis=1)
y = df_iris['target']
scaler = StandardScaler()
X_iris_scaled = scaler.fit_transform(X)
kmeans = KMeans(n_clusters=3, random_state=1)
kmeans_labels = kmeans.fit_predict(X_iris_scaled)
print(kmeans_labels)[실행 결과]
특징별 계수:
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 0 1 1 1 1 1 1 1 1 2 2 2 0 2 0 2 0 2 0 0 0 0 0 0 2 0 0 0 0 2 0 0 0
0 2 2 2 0 0 0 0 0 0 0 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 2 0 2 2 2 2
2 2 0 2 2 2 2 2 0 2 0 2 2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 0 2 2 2 0 2
2 2]# 결과를 시각화하여 실제 값과 비교
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_iris_scaled)
plt.figure(figsize=(15, 5))
# K-means 클러스터링 결과
plt.subplot(121)
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=kmeans_labels, cmap='viridis')
plt.title('K-means Result')
plt.colorbar(scatter)
# 실제 타겟값
plt.subplot(122)
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.title('Actual Iris')
plt.colorbar(scatter)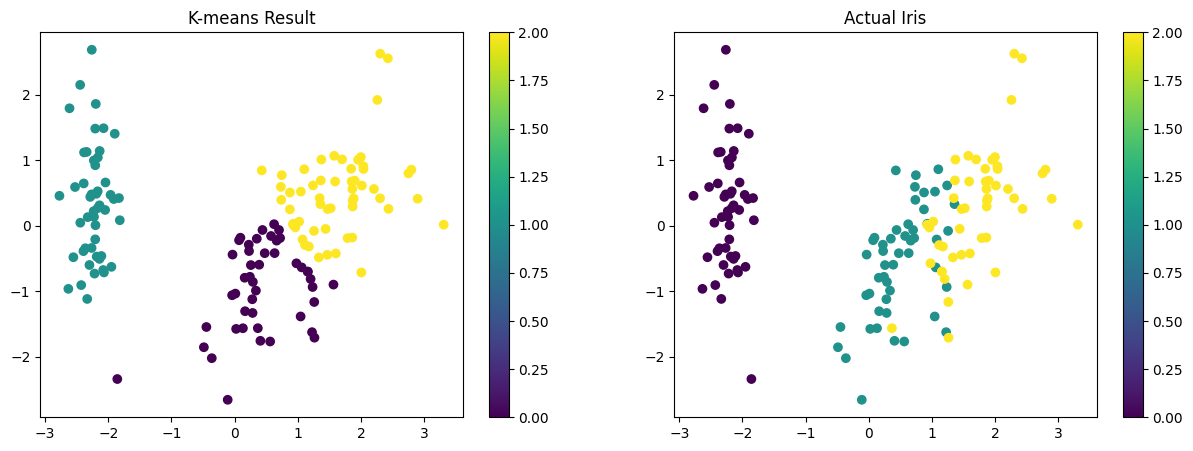
# 실제 값과 새롭게 분류된 라벨을 기준으로 했을 떄의 피처 평균값
feature_summary = df_iris.groupby('target').mean()
print(feature_summary.sort_values(by='sepal length (cm)', ascending=False))[실행 결과]
sepal length (cm) sepal width (cm) petal length (cm) \
target
2 6.588 2.974 5.552
1 5.936 2.770 4.260
0 5.006 3.428 1.462
petal width (cm) cluster
target
2 2.026 1.68
1 1.326 0.52
0 0.246 0.98 df_iris['cluster'] = kmeans_labels
feature_summary_cluster = df_iris.groupby('cluster').mean().drop('target', axis=1)
print(feature_summary_cluster.sort_values(by='sepal length (cm)', ascending=False))[실행 결과]
sepal length (cm) sepal width (cm) petal length (cm) \
cluster
2 6.696364 3.060000 5.418182
0 5.704348 2.634783 4.215217
1 5.016327 3.451020 1.465306
petal width (cm)
cluster
2 1.938182
0 1.332609
1 0.244898 