2회차 숙제 해설
import requests
import pandas as pd
from dotenv import load_dotenv
import os
import json
load_dotenv()
class WeatherApiClient:
"""
OpenWeatherMap API 클라이언트를 사용하여 날씨 데이터를 가져오는 클래스
"""
def __init__(self, api_key: str):
self.base_url = "http://api.openweathermap.org/data/2.5"
if api_key is None:
raise Exception("API 키는 None으로 설정할 수 없습니다.")
self.api_key = api_key
def get_city(self, city_name: str, temperature_units: str = "metric") -> dict:
"""
지정된 도시의 최신 날씨 데이터를 가져옵니다.
Parameters:
- city_name (str): 날씨 정보를 조회할 도시 이름.
- temperature_units (str): 온도 단위 (기본값은 'metric'으로 섭씨 기준).
'metric'은 섭씨, 'imperial'은 화씨, 'standard'는 켈빈 단위를 의미합니다.
Returns:
- dict: 요청한 도시의 날씨 데이터가 포함된 JSON 응답을 반환합니다.
Raises:
- Exception: API 요청이 실패한 경우 상태 코드와 응답 메시지와 함께 예외가 발생합니다.
"""
params = {"q": city_name, "units": temperature_units, "appid": self.api_key}
response = requests.get(f"{self.base_url}/weather", params=params)
if response.status_code == 200:
return response.json()
else:
raise Exception(
f"Open Weather API에서 데이터를 추출하지 못했습니다. 상태 코드: {response.status_code}. 응답: {response.text}"
)
weather_api_client = WeatherApiClient(api_key=os.environ.get("API_KEY"))
data = weather_api_client.get_city("Sydney")
df_weather = pd.json_normalize(data) # JSON 데이터를 Pandas 형태로 변환
# 간단한 전처리
df_weather["measured_at"] = pd.to_datetime(df_weather["dt"], unit="s") + pd.Timedelta(hours=9) # 기준시간(한국 기준)
df_weather["dt"] = df_weather["measured_at"].dt.strftime('%Y%m%d') # 기준년월일 (YYYYMMDD)
df_weather["time"] = df_weather["measured_at"].dt.strftime('%H%M%S') # 기준년월일 (HHHHMMSS)
df_selected = df_weather[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename( # 컬럼명 수정
columns={"name": "city", "main.temp": "temperature", "main.humidity": "humidity", "wind.speed": "wind_speed"}
)
df_selected
# CSV 파일로 저장
df_selected.to_csv("weather_api.csv", index=False)추가: 여러 도시의 데이터를 가져오고 싶은 경우
# 가져 오고 싶은 여러 도시 리스트화
cities = ["Sydney", "London", "New York", "Tokyo", "Toronto", "Seoul"]
all_data = []
# Collect data for each city and store it in a list
for city in cities:
data = weather_api_client.get_city(city)
all_data.append(data)
# normalize all data at once
df_weather = pd.json_normalize(all_data) # JSON 데이터를 Pandas 형태로 변환
df_weather["measured_at"] = pd.to_datetime(df_weather["dt"], unit="s") + pd.Timedelta(hours=9) # 기준시간
df_weather["dt"] = df_weather["measured_at"].dt.strftime('%Y%m%d') # 기준년월일 (YYYYMMDD)
df_weather["time"] = df_weather["measured_at"].dt.strftime('%H%M%S') # 기준년월일 (HHHHMMSS)
df_selected = df_weather[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename( # 컬럼명 수정
columns={"name": "city", "main.temp": "temperature", "main.humidity": "humidity", "wind.speed": "wind_speed"}
)
df_selected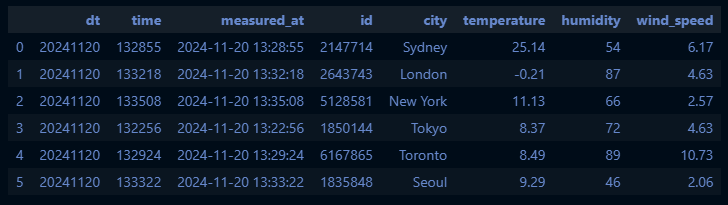
목표
- OpenWeather API를 통해 수집한 데이터를 MySQL 데이터베이스에 업로드하는 방법을 학습
- Python의 SQLAlchemy를 활용하여 데이터베이스에 연결하는 방법을 이해
- 수집된 데이터를 MySQL 테이블에 삽입하고 관리하는 방법을 실습
- 데이터 삭제, 삽입과 같은 데이터베이스 관리 기술 습득
환경 변수 설정 및 MySQL 데이터베이스 연결
-
.envDB 서버 정보 설정 예시
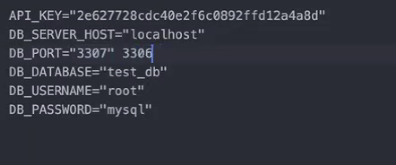
→ Mac은 3306에다가 port를 못 만들어서 3307로 설정하신 거라고 함
(윈도우는 그냥 3306 쓰면 된다고 하셨음) -
먼저 MySQL 데이터베이스와 상호작용하기 위해 필요한 라이브러리를 설치하고 불러오기
- 환경 변수를 로드하여 보안 정보를 관리
-
.env파일에 저장된 MySQL 서버 정보로 데이터베이스에 연결 -
실행 전 설치해야 할 게 두 가지 있음
pip install sqlalchemypip install mysql-connector-python- Mac이라면
pip3
# 패키지 불러오기
from sqlalchemy import create_engine
from sqlalchemy.engine import URL
import os
from dotenv import load_dotenv
load_dotenv() # .env 파일에 저장된 환경 변수 로드
# MySQL 연결 정보 설정
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST') # 데이터베이스 서버의 호스트 이름 (로컬호스트로 설정)
DB_USERNAME = os.environ.get('DB_USERNAME') # 데이터베이스 아이디
DB_PASSWORD = os.environ.get('DB_PASSWORD') # 데이터베이스 비밀번호
DB_DATABASE = os.environ.get('DB_DATABASE') # 사용할 데이터베이스 이름
DB_PORT = os.environ.get('DB_PORT') # 데이터베이스 연결을 위한 포트 (Default: 3306)
# 연결 URL 생성
connection_url = URL.create(
drivername="mysql+mysqlconnector",
username=DB_USERNAME,
password=DB_PASSWORD,
host=DB_SERVER_HOST,
port=DB_PORT,
database=DB_DATABASE,
)
# SQLAlchemy 엔진 생성
engine = create_engine(connection_url)
print("MySQL 데이터베이스에 연결되었습니다.")실습
01. 패키지 불러오기
from sqlalchemy import create_engine, MetaData, Table, Column
from sqlalchemy import text
from sqlalchemy import Integer, String, Float, DateTime
from sqlalchemy.engine import URL
import pandas as pd
import os
from dotenv import load_dotenv
load_dotenv() # .env에 입력한 모든 환경변수를 환경으로 가져옴[실행 결과]
True02. 샘플 데이터 불러오기
data = {
'dt': ['20241112', '20241112'],
'time': ['120000', '123000'],
'measured_at': pd.to_datetime(['2024-11-12 12:00:00', '2024-11-12 12:30:00']),
'id': [1, 2],
'city': ['Seoul', 'Seoul'],
'temperature': [15.5, 16.0],
'humidity': [45, 50],
'wind_speed': [3.5, 4.0]
}
df = pd.DataFrame(data)
print(df.head())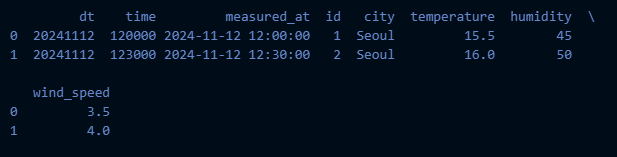
03. MySQL DB 연결
# MySQL 환경 변수 설정
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST') # 데이터베이스 서버의 호스트 이름 (로컬호스트로 설정)
DB_USERNAME = os.environ.get('DB_USERNAME') # 데이터베이스 아이디
DB_PASSWORD = os.environ.get('DB_PASSWORD') # 데이터베이스 비밀번호
DB_DATABASE = os.environ.get('DB_DATABASE') # 사용할 데이터베이스 이름
DB_PORT = os.environ.get('DB_PORT') # 데이터베이스 연결을 위한 포트 (Default: 3306)
connection_url = URL.create(
drivername="mysql+mysqlconnector",
username=DB_USERNAME,
password=DB_PASSWORD,
host=DB_SERVER_HOST,
port=DB_PORT,
database=DB_DATABASE,
)
print(connection_url)
print(f"DB_SERVER_HOST: {DB_SERVER_HOST}")
print(f"DB_USERNAME: {DB_USERNAME}")
print(f"DB_PASSWORD: {'*' * len(DB_PASSWORD) if DB_PASSWORD else None}") # Masked for safety
print(f"DB_DATABASE: {DB_DATABASE}")
print(f"DB_PORT: {DB_PORT}")[실행 결과]
mysql+mysqlconnector://root:***@localhost:3306/test_db
DB_SERVER_HOST: localhost
DB_USERNAME: root
DB_PASSWORD: ****
DB_DATABASE: test_db
DB_PORT: 3306※ URL
→ DBeaver 연결할 때 입력하는 부분을 만드는 것!
→ sqlalchemy 패키지에서 왔음
from sqlalchemy.engine import URL
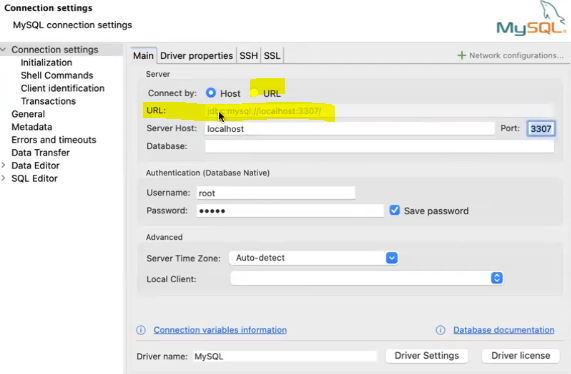
디비버가 데이터베이스와 접속을 시도할 때 사용
→ 참고:
python에서 쓰는 driver는 mysql+mysqlconnector:
DBeaver에서 쓰는 driver는 jdbc:mysql:
04. MySQL 테이블 구조 설정 및 테이블 생성
# SQLAlchemy 엔진 생성
engine = create_engine(connection_url)
table_name = 'daily_weather'
# 테이블에 대한 Metadata 설정
metadata = MetaData()
table = Table(
table_name, metadata,
Column('dt', String(8), nullable=False, primary_key=True), # 'dt'는 문자열이며 기본 키로 설정됨 (고유값)
Column('time', String(6), nullable=False, primary_key=True), # 'time'는 문자열이며 기본 키로 설정됨 (고유값)
Column('measured_at', DateTime, nullable=False), # 'measured_at'은 DateTime 타입이고 null이 허용되지 않음
Column('id', Integer, primary_key=True), # 'id'는 정수 타입이며 기본 키로 설정됨 (고유값)
Column('city', String(100), nullable=True), # 'name'은 문자열이며 null이 허용됨
Column('temperature', Float, nullable=True), # 'temperature'는 부동소수점 타입이며 null이 허용됨
Column('humidity', Integer, nullable=True), # 'humidity'는 정수 타입이며 null이 허용됨
Column('wind_speed', Float, nullable=True) # 'wind_speed'는 부동소수점 타입이며 null이 허용됨
)
# CREATE
metadata.create_all(engine)
생성 테이블 구조 정의
PK (Primary Key)와 FK (Foreign Key)
PK (Primary Key)란?
- 정의
- 데이터베이스 테이블에서 각 행을 고유하게 식별하는 컬럼(또는 컬럼들의 조합)
- 특징
- 유일성
- 한 테이블 내에서 중복되지 않는 값이어야 함
- NULL 허용 불가
- Primary Key는 항상 값이 있어야 함
- 유일성
- 예시
- 학생 테이블에서 student_id가 각 학생을 유일하게 구분하는 경우, student_id가 Primary Key가 될 수 있음
FK (Foreign Key)란?
- 정의
- 다른 테이블의 Primary Key를 참조하는 컬럼으로, 두 테이블 간의 관계를 형성
- 목적
- 데이터의 무결성을 유지
- 테이블 간의 관계를 정의
- 예시
- 수강 테이블에서 student_id가 학생 테이블의 Primary Key를 참조한다면, student_id는 Foreign Key가 됨
🡆 JOIN할 때 사용하는 키
간단한 예시를 통한 이해

- 위와 같이 설정된 관계에서는 수강 테이블의
student_id는 학생 테이블의student_id와 일치하는 값만 가질 수 있으므로, 데이터 일관성이 유지됨
복합 키(Composite Key)
- 정의
- 두 개 이상의 컬럼을 조합하여 Primary Key로 설정하여, 각 행을 고유하게 식별
- 테이블을 구성할 때 하나 이상의 컬럼을 조합하여 Primary Key를 만들 수 있음
- 두 개 이상의 컬럼을 조합하여 Primary Key로 설정하여, 각 행을 고유하게 식별
- 사용 사례
- 복합 키는 두 개 이상의 값의 조합이 반드시 유일하게 유지되어야 할 때 사용
복합키를 사용해 MySQL에 데이터를 저장할 테이블 구조 정의
dt(기준년월일),time(기준시간),id(도시ID)를 활용하여 복합키 만들기- 세 가지를 조합하면 테이블에 대한 고유 값이 생성됨!
from sqlalchemy import MetaData, Table, Column
from sqlalchemy import Integer, String, Float, DateTime
# 테이블 메타데이터 설정
metadata = MetaData()
table_name = 'daily_weather'
# 테이블 정의
table = Table(
table_name, metadata,
Column('dt', String(8), nullable=False, primary_key=True), # 'dt'는 문자열이며 기본 키로 설정됨
Column('time', String(6), nullable=False, primary_key=True), # 'time'은 문자열이며 기본 키로 설정됨
Column('measured_at', DateTime, nullable=False), # 'measured_at'은 DateTime 타입
Column('id', Integer, primary_key=True), # 'id'는 정수 타입이며 기본 키
Column('city', String(100), nullable=True), # 'city'는 문자열
Column('temperature', Float, nullable=True), # 'temperature'는 부동소수점 타입
Column('humidity', Integer, nullable=True), # 'humidity'는 정수
Column('wind_speed', Float, nullable=True) # 'wind_speed'는 부동소수점 타입
)삽입할 데이터 준비
- 삽입할 데이터 샘플 만들기
# 예제 데이터프레임 (API로부터 수집된 데이터가 있다고 가정)
data = {
'dt': ['20241112', '20241112'],
'time': ['120000', '123000'],
'measured_at': pd.to_datetime(['2024-11-12 12:00:00', '2024-11-12 12:30:00']),
'id': [1, 2],
'city': ['Seoul', 'Seoul'],
'temperature': [15.5, 16.0],
'humidity': [45, 50],
'wind_speed': [3.5, 4.0]
}
df = pd.DataFrame(data)MySQL DB 데이터 조작 및 처리 방법
테이블 생성(CREATE)
- 새로운 테이블을 정의하고 만들기
- 테이블은 특정 구조(열 이름과 데이터 타입)를 가지며, 데이터를 저장하고 관리할 수 있는 저장소 역할을 함
create_all매서드를 사용하는 경우 테이블이 이미 존재하면 무시됨- 이미 테이블이 있으면 그냥 아무것도 안 함
- SQL로 치면
CREATE IF NOT EXIST임
# 테이블 메타데이터 설정
metadata = MetaData()
table_name = 'daily_weather'
# 테이블 정의
table = Table(
table_name, metadata,
Column('dt', String(8), nullable=False, primary_key=True), # 'dt'는 문자열이며 기본 키로 설정됨
Column('time', String(6), nullable=False, primary_key=True), # 'time'은 문자열이며 기본 키로 설정됨
Column('measured_at', DateTime, nullable=False), # 'measured_at'은 DateTime 타입
Column('id', Integer, primary_key=True), # 'id'는 정수 타입이며 기본 키
Column('city', String(100), nullable=True), # 'city'는 문자열
Column('temperature', Float, nullable=True), # 'temperature'는 부동소수점 타입
Column('humidity', Integer, nullable=True), # 'humidity'는 정수
Column('wind_speed', Float, nullable=True) # 'wind_speed'는 부동소수점 타입
)
# 테이블 생성
metadata.create_all(engine)
print(f"'{table_name}' 테이블이 생성되었습니다.")테이블 삭제(DROP)
- 기존의 테이블을 완전히 제거하고 데이터베이스에서 지우는 작업
- 데이터베이스 구조가 변경되었거나 더 이상 필요하지 않은 테이블을 삭제할 때 유용
- 주의할 점
- DROP 명령어는 테이블을 완전히 삭제하기 때문에 해당 테이블에 저장된 데이터도 모두 삭제됨!
- 따라서 데이터 손실에 주의해야 하며, 백업이 필요한 경우 사전에 수행해야 함
# 테이블 삭제 (필요시 사용)
with engine.connect() as connection:
connection.execute(f"DROP TABLE IF EXISTS {table_name}")
print(f"'{table_name}' 테이블이 삭제되었습니다.")데이터 삽입(INSERT)
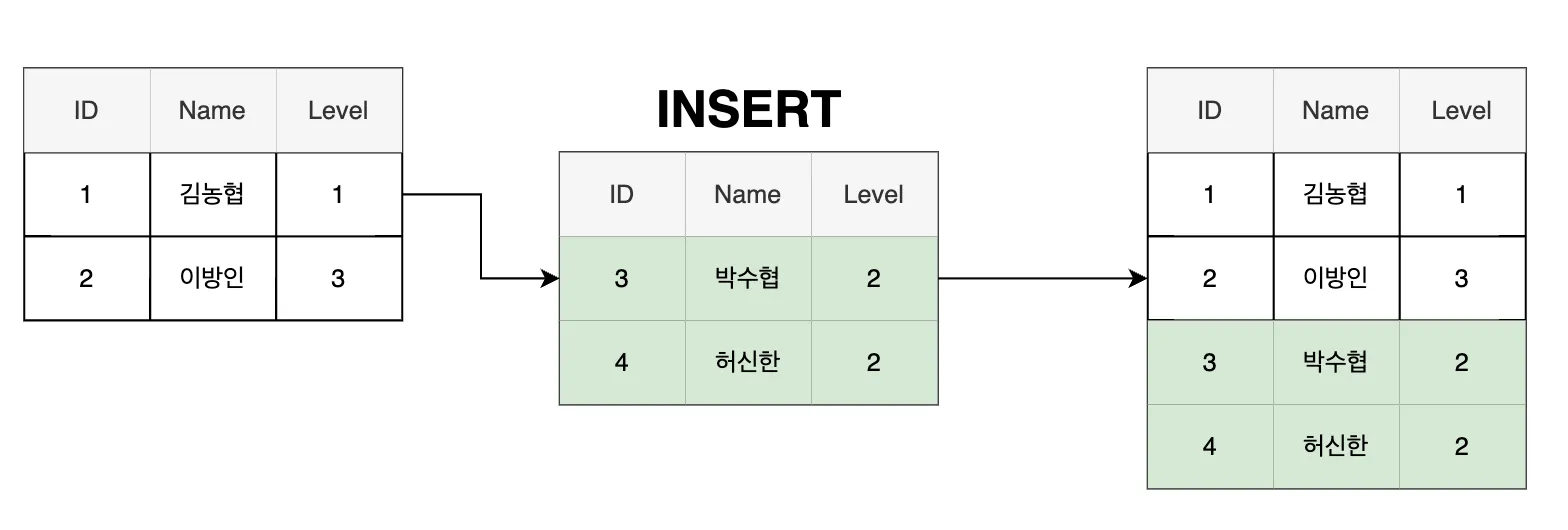
# 존재하는 테이블에 데이터 삽입
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
print(f"'{table_name}' 테이블에 데이터가 삽입되었습니다.")-
새로운 데이터를 데이터베이스에 추가하는 과정
- Pandas DataFrame 데이터를 to_sql 함수를 사용하여 MySQL 테이블에 삽입
-
if_exists='append'옵션- 기존 테이블에 데이터를 추가하는 역할
- 이미 존재하는 테이블에 추가 데이터를 삽입할 때 유용
- 데이터 누적이 필요할 때 주로 사용
-
index=False- DataFrame의 인덱스를 별도의 열로 테이블에 작성하지 않도록 지정
-
새로운 데이터를 추가함으로써 테이블의 정보를 최신 상태로 유지할 수 있음
UPSERT: 데이터 삭제 + 삽입 (DELETE + INSERT)
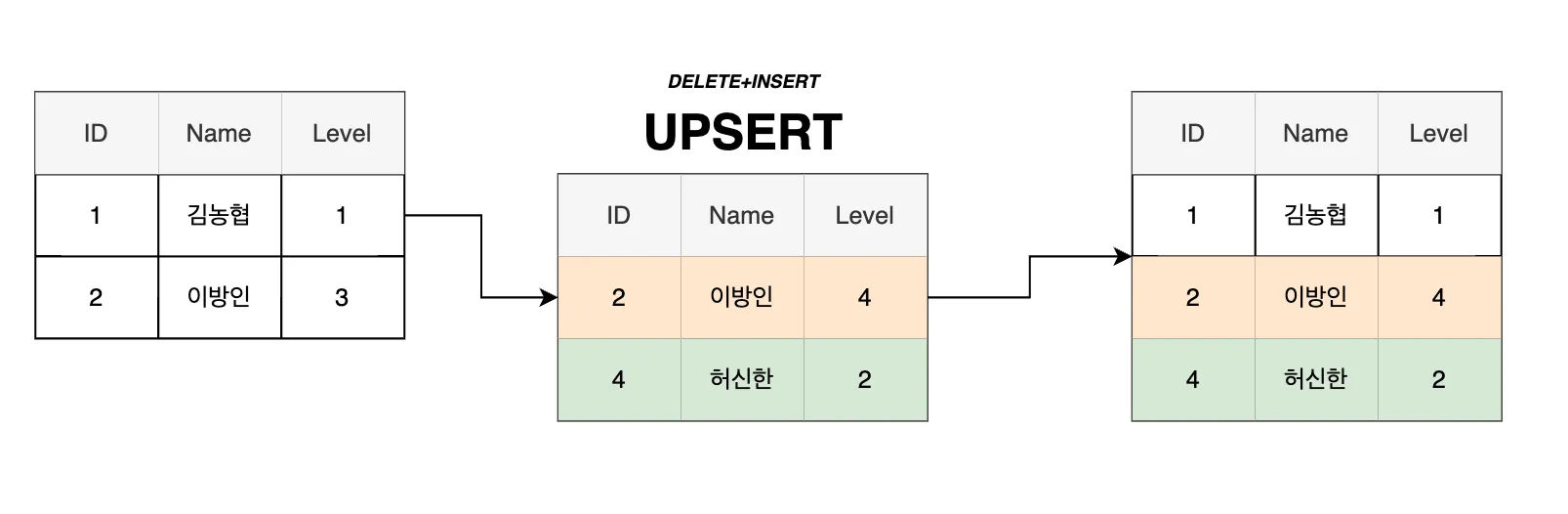
# 데이터프레임을 레코드의 리스트(딕셔너리로 구성된)로 변환
data = df.to_dict(orient='records')
# 테이블에서 기본 키 열을 가져옴
key_columns = [pk_column.name for pk_column in table.primary_key.columns.values()]
key_values = [tuple(row[pk] for pk in key_columns) for row in data]
delete_values = ", ".join([f"({', '.join(map(repr, values))})" for values in key_values])
# DELETE 문 실행 후 재삽입
with engine.connect() as connection:
if key_values:
delete_sql = f"""
DELETE FROM {database_name}.{table_name}
WHERE ({', '.join(key_columns)}) IN (
{delete_values}
)
"""
connection.execute(delete_sql)
connection.commit()
print(f"기존 데이터가 '{table_name}' 테이블에서 삭제되었습니다.")
# 새로운 데이터 삽입
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
print(f"새로운 데이터가 '{table_name}' 테이블에 삽입되었습니다.")-
기존 데이터를 삭제한 후 새로운 데이터를 삽입하는 방식
- 데이터베이스에서 특정 조건을 만족하는 기존 데이터를 삭제하고, 최신 데이터를 삽입하는데 사용
-
주로 최신 데이터로 테이블을 업데이트해야 할 때 활용되며, 중복 데이터나 데이터 일관성을 유지하는 데 유용
-
특정 기준을 기반으로 기존 데이터를 삭제하고 새로운 데이터를 삽입하기 때문에 전체 데이터가 아닌 필요한 데이터만 교체할 수 있는 유연성을 제공
-
데이터가 중복되거나 업데이트가 필요한 경우, 기존 데이터 삭제 후 새로운 데이터 삽입을 통해 정확하고 최신의 데이터를 유지할 수 있음
🡆 SQL에는 없는 기능인데 파이썬으로는 짤 수 있음!
자주 쓰는 SQL 문법
- DML(데이터 조작 언어)
- UPDATE
- 설명
- 특정 조건에 맞는 기존 데이터를 수정
- SQL문 예시
UPDATE
table_name
SET
column1 = 'new_value'
WHERE
column2 = 'specific_value'
;- DML
- DELETE
- 설명
- 특정 조건에 맞는 기존 데이터를 삭제
- SQL문 예시
DELETE
FROM
table_name
WHERE
column1 = 'value_to_delete'
;- DML
- SELECT
- 설명
- 테이블에서 데이터를 조회
- 특정 조건에 따라 데이터를 필터링할 수 있음
- SQL문 예시
SELECT
column1, column2
FROM
table_name
WHERE
column3 = 'value'
;- DML
- ALTER TABLE
- 설명
- 테이블의 구조를 변경
예를 들어, 열을 추가하거나 제거할 수 있음
- 테이블의 구조를 변경
- SQL문 예시
ALTER TABLE
table_name
ADD
column4 FLOAT
;- DML
- TRUNCATE TABLE
- 설명
- 테이블의 모든 데이터를 삭제하지만 테이블의 구조는 유지
- SQL문 예시
TRUNCATE TABLE
table_name
;실습
05. 데이터베이스 조작 기법
- DROP, INSERT, UPSERT 이해 및 활용
# 데이터 삽입 (INSERT)
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)[실행 결과]
2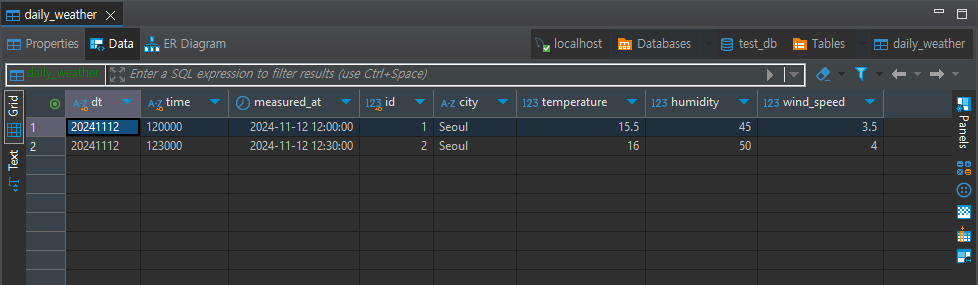
- INSERT 코드를 한 번 더 돌리면 오류 발생: PK error
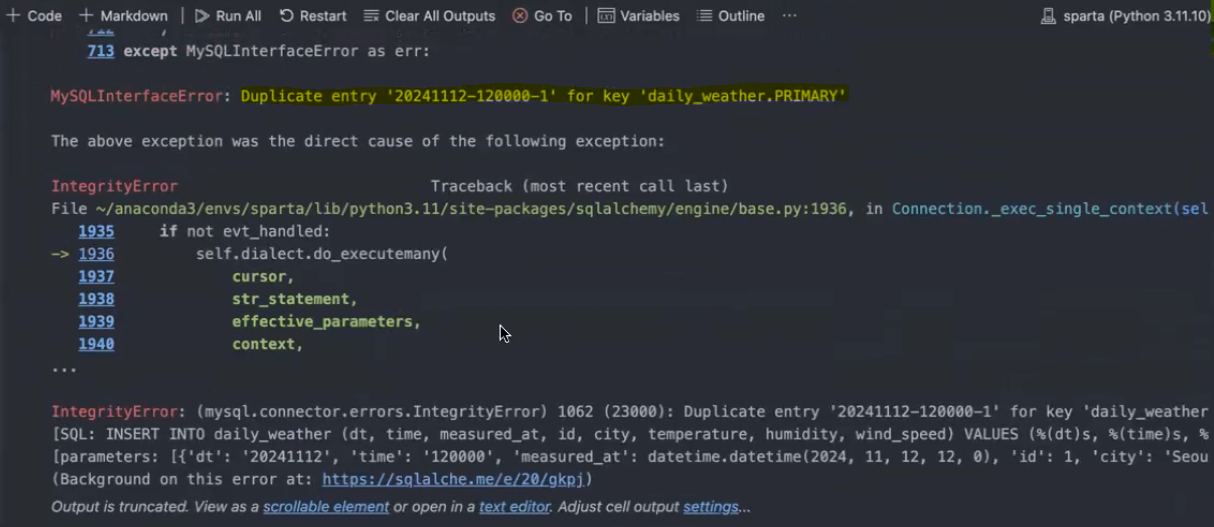
🡆dt(기준년월일),time(기준시간),id(도시ID) 중 하나라도 다르면 오류 안 뜸
# 테이블 삭제 (DROP)
with engine.connect() as connection:
connection.execute(text(f"DROP TABLE IF EXISTS {table_name}")) → 테이블 자체를 날리는 거임!
# SQLAlchemy 엔진 생성
engine = create_engine(connection_url)
table_name = 'daily_weather'
# 테이블에 대한 Metadata 설정
metadata = MetaData()
table = Table(
table_name, metadata,
Column('dt', String(8), nullable=False, primary_key=True), # 'dt'는 문자열이며 기본 키로 설정됨 (고유값)
Column('time', String(6), nullable=False, primary_key=True), # 'time'는 문자열이며 기본 키로 설정됨 (고유값)
Column('measured_at', DateTime, nullable=False), # 'measured_at'은 DateTime 타입이고 null이 허용되지 않음
Column('id', Integer, primary_key=True), # 'id'는 정수 타입이며 기본 키로 설정됨 (고유값)
Column('city', String(100), nullable=True), # 'name'은 문자열이며 null이 허용됨
Column('temperature', Float, nullable=True), # 'temperature'는 부동소수점 타입이며 null이 허용됨
Column('humidity', Integer, nullable=True), # 'humidity'는 정수 타입이며 null이 허용됨
Column('wind_speed', Float, nullable=True) # 'wind_speed'는 부동소수점 타입이며 null이 허용됨
)
# CREATE
metadata.create_all(engine)
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
data = {
'dt': ['20241112', '20241112'],
'time': ['120000', '123000'],
'measured_at': pd.to_datetime(['2024-11-12 12:00:00', '2024-11-12 12:30:00']),
'id': [1, 5],
'city': ['Seoul', 'Seoul'],
'temperature': [15.5, 16.0],
'humidity': [45, 50],
'wind_speed': [3.5, 4.0]
}
df = pd.DataFrame(data)
# 데이터 삭제 후 삽입 (DELETE+INSERT)
# 데이터프레임을 레코드의 리스트(딕셔너리로 구성된)로 변환
data = df.to_dict(orient='records')
# 테이블에서 고유 키(Primary Key) 열을 가져옴
key_columns = [pk_column.name for pk_column in table.primary_key.columns.values()]
key_values = [tuple(row[pk] for pk in key_columns) for row in data]
delete_values = ", ".join([f"({', '.join(map(repr, values))})" for values in key_values])
with engine.connect() as connection:
if key_values:
delete_sql = f"""
DELETE FROM {DB_DATABASE}.{table.name}
WHERE ({', '.join(key_columns)}) IN (
{delete_values}
)
"""
connection.execute(text(delete_sql))
connection.commit() # 생성된 DELETE 문 실행
# 변환된 데이터프레임을 테이블에 추가 (INSERT)
df.to_sql(name=table_name, con=engine, if_exists='append', index=False)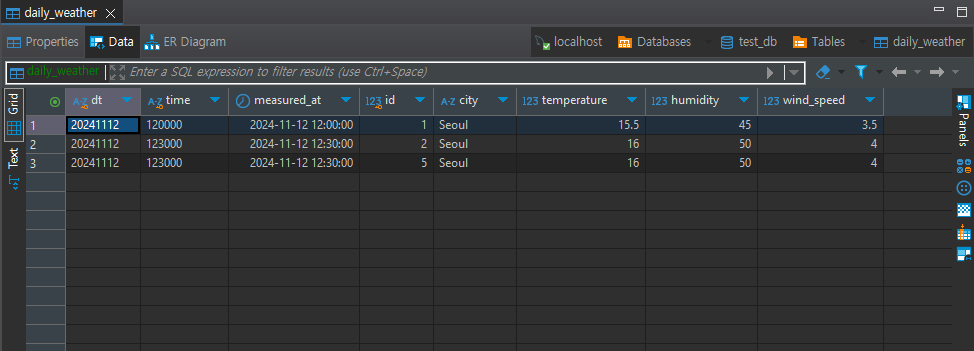
Class로 만들기
from sqlalchemy import create_engine, MetaData, Table, Column
from sqlalchemy import text
from sqlalchemy.engine import URL
import pandas as pd
class MySqlClient:
"""
MySQL 데이터베이스와 상호작용하기 위한 클라이언트 클래스입니다.
이 클래스는 SQLAlchemy를 사용하여 MySQL 데이터베이스에 연결하고 테이블을 생성, 삭제, 삽입,
업서트(upsert)와 같은 작업을 지원합니다.
"""
def __init__(
self,
server_name: str,
database_name: str,
username: str,
password: str,
port: int = 5432,
):
# 데이터베이스 연결을 위한 초기 설정
self.host_name = server_name
self.database_name = database_name
self.username = username
self.password = password
self.port = port
# MySQL 연결 URL 생성
connection_url = URL.create(
drivername="mysql+mysqlconnector",
username=username,
password=password,
host=server_name,
port=port,
database=database_name,
)
# SQLAlchemy 엔진 생성
self.engine = create_engine(connection_url)
def create_table(self, metadata: MetaData) -> None:
"""
주어진 메타데이터 객체를 기반으로 테이블을 생성합니다.
Parameters:
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
metadata.create_all(self.engine)
def drop_table(self, table_name: str) -> None:
"""
지정된 테이블을 삭제합니다. 테이블이 존재하지 않으면 무시합니다.
Parameters:
- table_name (str): 삭제할 테이블의 이름.
"""
with self.engine.connect() as connection:
connection.execute(text(f"DROP TABLE IF EXISTS {table_name}"))
def insert(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
주어진 DataFrame을 테이블에 삽입합니다. 테이블이 존재하지 않으면 생성합니다.
Parameters:
- df (pd.DataFrame): 삽입할 데이터를 포함하는 Pandas DataFrame.
- table (Table): 데이터 삽입을 위한 SQLAlchemy Table 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
self.create_table(metadata=metadata)
df.to_sql(name=table.name, con=self.engine, if_exists="append", index=False)
def upsert(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
주어진 DataFrame 데이터를 테이블에 삽입하고, 기존 레코드가 있으면 업데이트합니다.
Parameters:
- df (pd.DataFrame): 삽입 또는 갱신할 데이터를 포함하는 Pandas DataFrame.
- table (Table): 업서트 작업을 수행할 SQLAlchemy Table 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
self.create_table(metadata=metadata)
# 데이터프레임을 레코드(딕셔너리 목록)으로 변환
data = df.to_dict(orient="records")
# 테이블의 고유 키(Primary Key) 추출
key_columns = [
pk_column.name for pk_column in table.primary_key.columns.values()
]
key_values = [tuple(row[pk] for pk in key_columns) for row in data]
delete_values = ", ".join(
[f"({', '.join(map(repr, values))})" for values in key_values]
)
with self.engine.connect() as connection:
if key_values:
delete_sql = f"""
DELETE FROM {self.database_name}.{table.name}
WHERE ({', '.join(key_columns)}) IN (
{delete_values}
)
"""
connection.execute(text(delete_sql))
connection.commit() # DELETE 문 실행
# 변환된 데이터프레임을 테이블에 추가 (INSERT)
df.to_sql(name=table.name, con=self.engine, if_exists="append", index=False)__init__- MySQL 데이터베이스에 연결하는 클라이언트를 초기화합
- 서버 정보와 사용자 정보를 설정하여 연결 URL을 생성
create_table- 주어진 metadata를 기반으로 테이블을 생성
drop_table- 지정된 테이블을 삭제
insert- 데이터를 테이블에 삽입
- 테이블이 없으면 생성 후 추가
upsert- 데이터를 테이블에 삽입하고, 기존 레코드가 있으면 업데이트
- 테이블이 없으면 생성 후 추가
MySqlClient 활용
- 새로 만든 MySqlClient 를 활용해 API 를 통해 새로운 테이블을 만들고 기존에 요청한 API 데이터를 삽입
from sqlalchemy import Integer, String, Float, DateTime
from sqlalchemy import MetaData, Table, Column
import pandas as pd
import os
from dotenv import load_dotenv
load_dotenv()
# 2회차에서 쌓아둔 데이터 불러오기
df = pd.read_csv(
'weather_api.csv',
dtype={
'dt': 'object',
'time': 'object',
'id': 'int64',
'city': 'object',
'temperature': 'float64',
'humidity': 'int64',
'wind_speed': 'float64'
},
parse_dates=['measured_at']
)
table_name = 'daily_weather'
# 테이블에 대한 Metadata 설정
metadata = MetaData()
table = Table(
table_name, metadata,
Column('dt', String(8), nullable=False, primary_key=True), # 'dt'는 문자열이며 기본 키로 설정됨 (고유값)
Column('time', String(6), nullable=False, primary_key=True), # 'time'는 문자열이며 기본 키로 설정됨 (고유값)
Column('measured_at', DateTime, nullable=False), # 'measured_at'은 DateTime 타입이고 null이 허용되지 않음
Column('id', Integer, primary_key=True), # 'id'는 정수 타입이며 기본 키로 설정됨 (고유값)
Column('city', String(100), nullable=True), # 'name'은 문자열이며 null이 허용됨
Column('temperature', Float, nullable=True), # 'temperature'는 부동소수점 타입이며 null이 허용됨
Column('humidity', Integer, nullable=True), # 'humidity'는 정수 타입이며 null이 허용됨
Column('wind_speed', Float, nullable=True) # 'wind_speed'는 부동소수점 타입이며 null이 허용됨
)
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST') # 데이터베이스 서버의 호스트 이름 (로컬호스트로 설정)
DB_USERNAME = os.environ.get('DB_USERNAME') # 데이터베이스 아이디
DB_PASSWORD = os.environ.get('DB_PASSWORD') # 데이터베이스 비밀번호
DB_DATABASE = os.environ.get('DB_DATABASE') # 사용할 데이터베이스 이름
DB_PORT = os.environ.get('DB_PORT') # 데이터베이스 연결을 위한 포트 (Default: 3306)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT
)
my_sql_client.create_table(metadata=metadata)
my_sql_client.insert(df=df, table=table, metadata=metadata)
# my_sql_client.upsert(df=df, table=table, metadata=metadata)숙제
MySqlClientclass 안에overwrite함수를 생성해주세요!
- overwrite 함수는 기존 테이블의 모든 데이터를 삭제한 후 새로운 데이터를 삽입하는 작업을 수행합니다. 즉, 테이블의 데이터를 완전히 교체하는 방식입니다.
- 구현 방법
- 테이블의 모든 데이터를 삭제합니다 (DROP).
- 새로운 테이블을 생성합니다 (CREATE).
- 새로운 데이터를 삽입합니다 (INSERT).
