3회차 숙제 해설
from sqlalchemy import create_engine, MetaData, Table, Column
from sqlalchemy import Integer, String, Float, DateTime
from sqlalchemy import text
from sqlalchemy.engine import URL
import pandas as pd
import os
from dotenv import load_dotenv
load_dotenv()[실행 결과]
Trueclass MySqlClient:
"""
MySQL 데이터베이스와 상호작용하기 위한 클라이언트 클래스입니다.
"""
def __init__(
self,
server_name: str,
database_name: str,
username: str,
password: str,
port: int = 5432,
):
# 데이터베이스 연결을 위한 초기 설정
self.host_name = server_name
self.database_name = database_name
self.username = username
self.password = password
self.port = port
# MySQL 연결 URL 생성
connection_url = URL.create(
drivername="mysql+mysqlconnector",
username=username,
password=password,
host=server_name,
port=port,
database=database_name,
)
# SQLAlchemy 엔진 생성
self.engine = create_engine(connection_url)
def create_table(self, metadata: MetaData) -> None:
"""
주어진 메타데이터 객체를 기반으로 테이블을 생성합니다.
Parameters:
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
metadata.create_all(self.engine)
def drop_table(self, table: Table) -> None:
"""
지정된 테이블을 삭제합니다. 테이블이 존재하지 않으면 무시합니다.
Parameters:
- table_name (str): 삭제할 테이블의 이름.
"""
with self.engine.connect() as connection:
connection.execute(text(f"DROP TABLE IF EXISTS {self.database_name}.{table.name}"))
def insert(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
데이터를 테이블에 삽입합니다. 테이블이 없으면 생성 후 추가합니다.
Parameters:
- df (pd.DataFrame): 삽입할 데이터를 포함하는 Pandas DataFrame.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
self.create_table(metadata=metadata)
df.to_sql(name=table.name, con=self.engine, if_exists="append", index=False)
def upsert(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
데이터를 테이블에 삽입하고, 기존 레코드가 있으면 업데이트합니다. 테이블이 없으면 생성 후 추가합니다.
Parameters:
- df (pd.DataFrame): 삽입 또는 갱신할 데이터를 포함하는 Pandas DataFrame.
- table (Table): 업서트 작업을 수행할 SQLAlchemy 테이블 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
self.create_table(metadata=metadata)
# 데이터프레임을 레코드(딕셔너리 목록)으로 변환
data = df.to_dict(orient="records")
# 테이블의 고유 키(Primary Key) 추출
key_columns = [
pk_column.name for pk_column in table.primary_key.columns.values()
]
key_values = [tuple(row[pk] for pk in key_columns) for row in data]
delete_values = ", ".join(
[f"({', '.join(map(repr, values))})" for values in key_values]
)
with self.engine.connect() as connection:
if key_values:
delete_sql = f"""
DELETE FROM {self.database_name}.{table.name}
WHERE ({', '.join(key_columns)}) IN (
{delete_values}
)
"""
connection.execute(text(delete_sql))
connection.commit() # DELETE 문 실행
# 변환된 데이터프레임을 테이블에 추가 (INSERT)
df.to_sql(name=table.name, con=self.engine, if_exists="append", index=False)
def overwrite(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
주어진 DataFrame 데이터를 테이블의 기존 데이터를 모두 대체하도록 삽입합니다.
Parameters:
- df (pd.DataFrame): 데이터를 포함하는 Pandas DataFrame.
- table (Table): 데이터를 대체할 SQLAlchemy Table 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
# 기존 테이블 데이터 삭제
self.drop_table(table=table)
# 테이블이 존재하지 않으면 생성
self.create_table(metadata=metadata)
# 새로운 데이터를 테이블에 삽입: upsert 써도 됨
self.insert(df=df, table=table, metadata=metadata)🡆 def drop_table 형태가 이전 강의와 달라졌으니 참고!
# 수정 전
def drop_table(self, table_name: str) -> None:
"""
지정된 테이블을 삭제합니다. 테이블이 존재하지 않으면 무시합니다.
Parameters:
- table_name (str): 삭제할 테이블의 이름.
"""
with self.engine.connect() as connection:
connection.execute(text(f"DROP TABLE IF EXISTS {table_name}"))
# 수정 후
def drop_table(self, table: Table) -> None:
"""
지정된 테이블을 삭제합니다. 테이블이 존재하지 않으면 무시합니다.
Parameters:
- table (Table): 삭제할 SQLAlchemy Table 객체.
"""
with self.engine.connect() as connection:
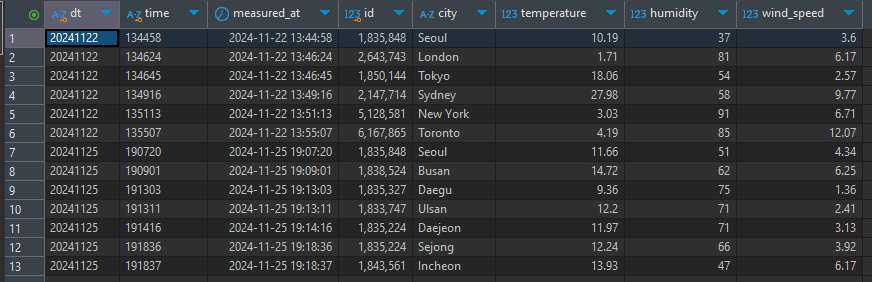
connection.execute(text(f"DROP TABLE IF EXISTS {self.database_name}.{table.name}"))# 2회차에서 쌓아둔 데이터 불러오기
df = pd.read_csv(
'weather_api.csv',
dtype={
'dt': 'object',
'time': 'object',
'id': 'int64',
'city': 'object',
'temperature': 'float64',
'humidity': 'int64',
'wind_speed': 'float64'
},
parse_dates=['measured_at']
)
table_name = 'daily_weather'
# 테이블에 대한 Metadata 설정
metadata = MetaData()
table = Table(
table_name, metadata,
Column('dt', String(8), nullable=False, primary_key=True), # 'dt'는 문자열이며 기본 키로 설정됨 (고유값)
Column('time', String(6), nullable=False, primary_key=True), # 'time'는 문자열이며 기본 키로 설정됨 (고유값)
Column('measured_at', DateTime, nullable=False), # 'measured_at'은 DateTime 타입이고 null이 허용되지 않음
Column('id', Integer, primary_key=True), # 'id'는 정수 타입이며 기본 키로 설정됨 (고유값)
Column('city', String(100), nullable=True), # 'name'은 문자열이며 null이 허용됨
Column('temperature', Float, nullable=True), # 'temperature'는 부동소수점 타입이며 null이 허용됨
Column('humidity', Integer, nullable=True), # 'humidity'는 정수 타입이며 null이 허용됨
Column('wind_speed', Float, nullable=True) # 'wind_speed'는 부동소수점 타입이며 null이 허용됨
)
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST')
DB_USERNAME = os.environ.get('DB_USERNAME')
DB_PASSWORD = os.environ.get('DB_PASSWORD')
DB_DATABASE = os.environ.get('DB_DATABASE')
DB_PORT = os.environ.get('DB_PORT')
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT
)
my_sql_client.overwrite(df=df, table=table, metadata=metadata)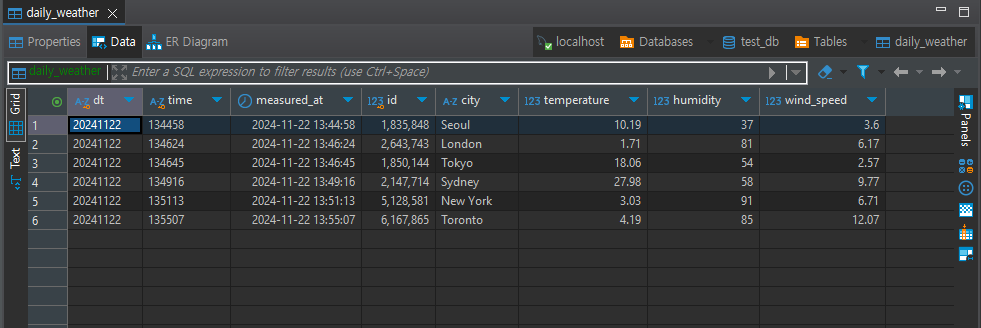
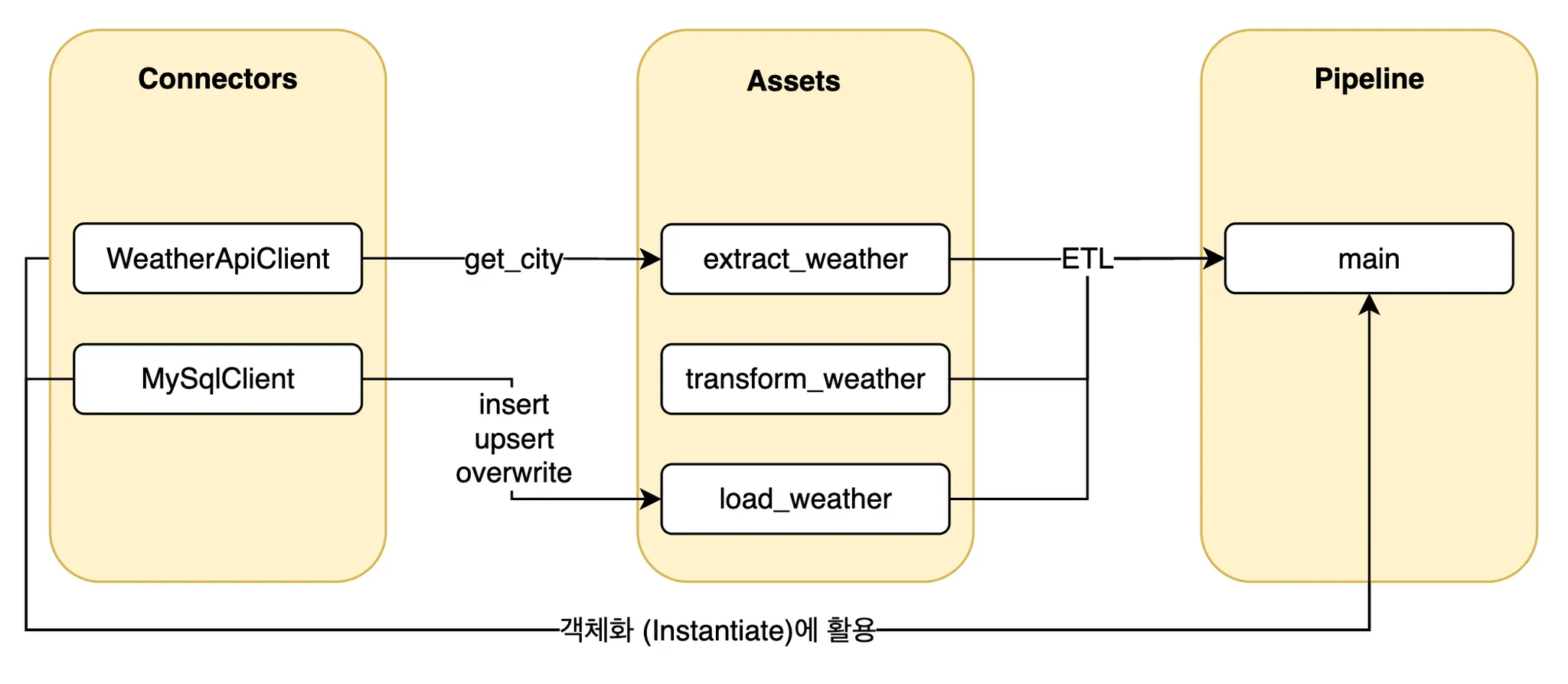
목표
- Weather API 호출 및 데이터를 MySQL에 적재하는 작업을 모듈화
- Extract, Transform, Load (ETL) 프로세스를 함수화하여 파이프라인으로 실행
프로젝트 폴더 구조 구성
etl_module/
├── assets/
│ └── __init__.py
│ └── weather.py
├── connectors/
│ └── __init__.py
│ ├── weather_api.py
│ └── mysql_client.py
├── pipeline/
│ └── etl_pipeline.py
├── .env
├── 4_challenge_module.ipynb
└── requirements.txt-
VS Code Terminal에
pip install -r requirements.txt입력하면 실습에 필요한 모든 라이브러리를 설치할 수 있음- 이제까지 잘 따라왔으면 안 해도 됩니다!
-
etl_module폴더를 VS Code로 열기: 작업환경 설정- File>Open Folder
또는 File>New Window>Open Folder
- File>Open Folder
-
이제 우리는
.ipynb파일보다.py파일에 익숙해져야 함!- 함수 불러 와 돌릴 수 있게 모아 놓은 script라 생각하면 편함(실행파일처럼 돌릴 수 있음)
-
connectors폴더에는 지금까지 만든 class가 모두 들어가 있음- 설계도 모음집임
-
asset폴더에는 실제로 쓸 거(부를 거) 넣음
폴더 구조의 이점
- 모듈화
- 각각의 폴더가 독립적으로 관리되어 코드의 가독성과 유지보수성이 높아짐
- 재사용성
- 특정 데이터 연결자 또는 변환 로직을 다른 프로젝트에서도 재사용할 수 있음
- 확장성
- 새로운 연결자나 변환 로직 추가 시 기존 구조를 유지하면서 손쉽게 확장할 수 있음
Assets 폴더
- 구성 요소
__init__.py- Python 패키지로 폴더를 인식하게 하기 위한 초기화 파일
- 이 폴더 내의 모듈이나 함수들을 다른 위치에서 불러올 수 있도록 하는 역할
- 열어보면 안에 내용 아무 것도 없음(모듈이라는 걸 인식시키려고 넣는 거라 파일만 있으면 되고 내용은 필요 없음)
- 이게 없으면
assets.weather하고 부를 수가 없음!
- Weather(
weather.py)- 날씨 데이터를 다루는 ETL 관련 함수가 포함된 파일 또는 모듈
(예) API로 받은 날씨 데이터를 정제, 가공, 변환하는 코드를 포함할 수 있음
- 날씨 데이터를 다루는 ETL 관련 함수가 포함된 파일 또는 모듈
- 역할
- 데이터의 가공과 관련된 코드 및 기타 자산(리소스)을 담아두는 폴더
- 데이터를 다루는 데 필요한 다양한 변환 로직과 설정들을 이곳에 모아두어, 나중에 재사용하거나 쉽게 확장할 수 있음
QnA
- 파일 구조 구성 시 궁금한 내용입니다.
코드에서는 필요한 정보이나, 배포 시 공개를 원하지 않는 정보가 ‘env’ 파일에 포함된다면,(예: private key 등) 보통 어떤 방법으로 배포에서 제외하나요?
(또는 어떻게 파일구조를 수정하나요?)- .env는 절대 외부에 유출하면 안 됩니다!
- .gitignore에 .env 넣으면 github에 .env만 빼고 올라가요~
- github: 코딩용 드라이브(코드 보관소)
→ repository: 개발자가 애플리케이션 소스 코드에 대한 변경을 수행 및 관리하는 데 사용하는 중앙화된 디지털 스토리지
- github: 코딩용 드라이브(코드 보관소)
- aws secrets manager
- 환경변수를 따로 클라우드에서 관리해주는 기능
- aws에서 해당 코드를 돌리고 싶을 때 개인 정보가 담긴 파일만 모아 따로 관리할 수 있음
Connectors 폴더
- 구성 요소
__init__.py- Python 패키지로 인식할 수 있도록 초기화하는 파일
- MySQL Connector(
mysql.py)- MySQL 데이터베이스와 연결하고 데이터를 읽거나 쓰는 작업을 수행하는 코드가 들어감
(예) MySQL 연결을 위한 초기화 코드 작업을 수행하는 함수 등
- MySQL 데이터베이스와 연결하고 데이터를 읽거나 쓰는 작업을 수행하는 코드가 들어감
- Weather API Connector(
weather_api.py)- 외부 날씨 API와의 통신을 관리하는 코드
- API 키 인증, 데이터 요청, 응답 처리와 같은 작업을 수행
- 역할
- 데이터 소스에 연결하고 데이터를 가져오거나 쓰는 작업을 담당
- 각 연결자는 특정 데이터 소스(예: 데이터베이스 또는 외부 API)와의 통신 로직을 처리하여 ETL 파이프라인에서 재사용될 수 있음
Pipeline 폴더
- 구성 요소
- ETL 실행 코드(
etl_pipeline.py)- ETL 프로세스를 실행하는 메인 코드가 들어감
- Assets와 Connectors에 있는 모듈을 불러와 ETL의 각 단계(추출, 변환, 로드)를 순차적으로 실행
- ETL 실행 코드(
- 역할
- ETL 파이프라인의 전체적인 흐름을 정의하고 실행하는 중심부
- 데이터를 추출하고(Connectors를 통해), 가공하여(Assets를 활용), 최종적으로 데이터를 특정 위치에 로드하는 작업을 포함
Connectors 모듈 코드 작성(connectors)
지난번 실습에 만들었던 Class를 모듈 파일로 변환해 보겠습니다.
Docstring 및 주석도 꼭 포함해주세요.
connectors/weather_api.py
import requests
class WeatherApiClient:
"""
OpenWeatherMap API 클라이언트를 사용하여 날씨 데이터를 가져오는 클래스입니다.
"""
def __init__(self, api_key: str):
self.base_url = "http://api.openweathermap.org/data/2.5"
if api_key is None:
raise Exception("API 키는 None으로 설정할 수 없습니다.")
self.api_key = api_key
def get_city(self, city_name: str, temperature_units: str = "metric") -> dict:
"""
지정된 도시의 최신 날씨 데이터를 가져옵니다.
Parameters:
- city_name (str): 날씨 정보를 조회할 도시 이름.
- temperature_units (str): 온도 단위 (기본값은 'metric'으로 섭씨 기준).
'metric'은 섭씨, 'imperial'은 화씨, 'standard'는 켈빈 단위를 의미합니다.
Returns:
- dict: 요청한 도시의 날씨 데이터가 포함된 JSON 응답을 반환합니다.
Raises:
- Exception: API 요청이 실패한 경우 상태 코드와 응답 메시지와 함께 예외가 발생합니다.
"""
params = {"q": city_name, "units": temperature_units, "appid": self.api_key}
response = requests.get(f"{self.base_url}/weather", params=params)
if response.status_code == 200:
return response.json()
else:
raise Exception(
f"Open Weather API에서 데이터를 추출하지 못했습니다. 상태 코드: {response.status_code}. 응답: {response.text}"
)connectors/mysql.py
from sqlalchemy import create_engine, MetaData, Table, MetaData, Column
from sqlalchemy import text
from sqlalchemy.engine import URL
import pandas as pd
class MySqlClient:
"""
MySQL 데이터베이스와 상호작용하기 위한 클라이언트 클래스입니다.
이 클래스는 SQLAlchemy를 사용하여 MySQL 데이터베이스에 연결하고 테이블을 생성, 삭제, 삽입,
업서트(upsert)와 같은 작업을 지원합니다.
"""
def __init__(
self,
server_name: str,
database_name: str,
username: str,
password: str,
port: int = 3306,
):
# 데이터베이스 연결을 위한 초기 설정
self.host_name = server_name
self.database_name = database_name
self.username = username
self.password = password
self.port = port
# MySQL 연결 URL 생성
connection_url = URL.create(
drivername="mysql+mysqlconnector",
username=username,
password=password,
host=server_name,
port=port,
database=database_name,
)
# SQLAlchemy 엔진 생성
self.engine = create_engine(connection_url)
def create_table(self, metadata: MetaData) -> None:
"""
주어진 메타데이터 객체를 기반으로 테이블을 생성합니다.
Parameters:
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
metadata.create_all(self.engine)
def drop_table(self, table: Table) -> None:
"""
지정된 테이블을 삭제합니다. 테이블이 존재하지 않으면 무시합니다.
Parameters:
- table_name (str): 삭제할 테이블의 이름.
"""
with self.engine.connect() as connection:
connection.execute(text(f"DROP TABLE IF EXISTS {table.name}"))
def insert(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
주어진 DataFrame을 테이블에 삽입합니다. 테이블이 존재하지 않으면 생성합니다.
Parameters:
- df (pd.DataFrame): 삽입할 데이터를 포함하는 Pandas DataFrame.
- table (Table): 데이터 삽입을 위한 SQLAlchemy Table 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
self.create_table(metadata=metadata)
df.to_sql(name=table.name, con=self.engine, if_exists="append", index=False)
def upsert(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
주어진 DataFrame 데이터를 테이블에 삽입하고, 기존 레코드가 있으면 갱신합니다.
Parameters:
- df (pd.DataFrame): 삽입 또는 갱신할 데이터를 포함하는 Pandas DataFrame.
- table (Table): 업서트 작업을 수행할 SQLAlchemy Table 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
self.create_table(metadata=metadata)
# 데이터프레임을 레코드(딕셔너리 목록)으로 변환
data = df.to_dict(orient="records")
# 테이블의 고유 키(Primary Key) 추출
key_columns = [
pk_column.name for pk_column in table.primary_key.columns.values()
]
key_values = [tuple(row[pk] for pk in key_columns) for row in data]
delete_values = ", ".join(
[f"({', '.join(map(repr, values))})" for values in key_values]
)
with self.engine.connect() as connection:
if key_values:
delete_sql = f"""
DELETE FROM {self.database_name}.{table.name}
WHERE ({', '.join(key_columns)}) IN (
{delete_values}
)
"""
connection.execute(text(delete_sql))
connection.commit() # DELETE 문 실행
# 변환된 데이터프레임을 테이블에 추가 (INSERT)
df.to_sql(name=table.name, con=self.engine, if_exists="append", index=False)
def overwrite(self, df: pd.DataFrame, table: Table, metadata: MetaData) -> None:
"""
주어진 DataFrame 데이터를 테이블의 기존 데이터를 모두 대체하도록 삽입합니다.
Parameters:
- df (pd.DataFrame): 테이블의 기존 데이터를 대체할 데이터를 포함하는 Pandas DataFrame.
- table (Table): 데이터를 대체할 SQLAlchemy Table 객체.
- metadata (MetaData): 테이블 정의를 포함하는 SQLAlchemy MetaData 객체.
"""
# 테이블이 존재하지 않으면 생성
self.create_table(metadata=metadata)
# 기존 테이블 데이터 삭제
self.drop_table(table=table)
# 새로운 데이터를 테이블에 삽입
self.insert(df=df, table=table, metadata=metadata)실습
01. 패키지 불러오기
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
import pandas as pd
import os
from dotenv import load_dotenv
load_dotenv()from etl_module.connectors.weather_api import WeatherApiClient- from 폴더.폴더.파일 import 클래스
- 작성 중인 파일의 위치에 따라 from의 경로가 달라짐
- 현재는 파일이 etl_module 폴더 밖에 위치해 있어 위와 같이 코드 작성
- 만약 작성 중인 ipynb 파일이 etl_module 폴더 안에 있다면
from connectors.weather_api import WeatherApiClient로 작성
# 환경변수 설정
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST') # 데이터베이스 서버의 호스트 이름 (로컬호스트로 설정)
DB_USERNAME = os.environ.get('DB_USERNAME') # 데이터베이스 아이디
DB_PASSWORD = os.environ.get('DB_PASSWORD') # 데이터베이스 비밀번호
DB_DATABASE = os.environ.get('DB_DATABASE') # 사용할 데이터베이스 이름
DB_PORT = os.environ.get('DB_PORT') # 데이터베이스 연결을 위한 포트 (Default: 3306)
DB_DATABASE[실행 결과]
'test_db'- 환경변수가 잘 들어가 있는지 확인
.env파일에 들어가 있는 값 가져오는 것
02. Weather, MySQL 클래스를 객체(인스턴스)화
# Client
weather_api_client = WeatherApiClient(api_key = API_KEY)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT
)
# 잘 들어갔는지 확인
weather_api_client.api_key[실행 결과]
(내 api key 출력)# 잘 들어갔는지 확인 (2)
my_sql_client.database_name[실행 결과]
'test_db'# test
weather_api_client.get_city(city_name='seoul')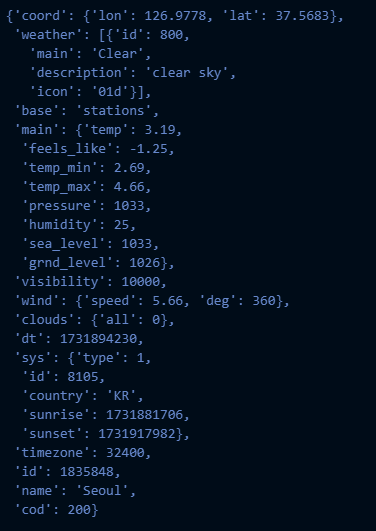
ETL 파이프라인 함수 구성(assets)
ETL이란?
- 데이터를 다양한 소스에서 추출(Extract), 변환(Transform), 적재(Load)하는 프로세스를 의미
- 데이터 통합 및 처리를 통해 분석 가능한 데이터를 제공하는 데 핵심 역할
- Extract (추출)
- 데이터 소스에서 데이터를 가져오는 단계
- 예: API, 파일 등
- Transform (변환)
- 데이터를 원하는 형식으로 가공하는 단계
- 예: 정제, 변환
- Load (적재)
- 가공된 데이터를 목표 데이터베이스에 저장하는 단계
- ETL의 중요성은 데이터를 일관성 있게 가공해 분석 가능한 형태로 제공하는 데 있음
환경변수 설정
import os
from dotenv import load_dotenv
import pandas as pd
from connectors.weather_api import WeatherApiClient
from connectors.mysql_client import MySqlClient
from sqlalchemy import MetaData, Table, Column, String, DateTime, Integer, Float
load_dotenv()Extract 함수 작성
- 서울 (seoul), 부산 (busan), 세종 (sejong), 대구 (daegu), 인천 (incheon), 대전 (daejeon) 및 울산 (ulsan)에 대한 날씨를 한번에 가져오기
def extract_weather(api_client: WeatherApiClient) -> pd.DataFrame:
"""
여러 도시의 날씨 데이터를 추출합니다.
Parameters:
- weather_api_client (WeatherApiClient): API에서 날씨 데이터를 가져오기 위한 클라이언트.
Returns:
- pd.DataFrame: 지정된 도시들의 날씨 데이터를 포함하는 DataFrame.
"""
cities = ['seoul', 'busan', 'sejong', 'daegu', 'incheon', 'daejeon', 'ulsan']
weather_data = [api_client.get_city(city_name=city) for city in cities]
df = pd.json_normalize(weather_data)
return dfTransform 함수 작성
- 기준시간
- 한국 시간으로 변환: +9시간
- UTC → KST
- 기준년월일
- dt 컬럼 추가
- 기준 시간
- time 컬럼 추가
- dt, time, measured_at, id, name, main.temp, main.humidity, wind.speed 컬럼 필터링
- city, temperature, humidity, wind_speed로 일부 컬럼명 수정
def transform_weather(df: pd.DataFrame) -> pd.DataFrame:
"""
날씨 데이터를 변환하고 전처리합니다.
Parameters:
- df (pd.DataFrame): 원본 날씨 데이터를 포함하는 DataFrame.
Returns:
- pd.DataFrame: 선택된 컬럼과 이름이 변경된 데이터로 구성된 변환된 DataFrame.
"""
df["measured_at"] = pd.to_datetime(df["dt"], unit="s") + pd.Timedelta(hours=9) # 한국시간
df["dt"] = df["measured_at"].dt.strftime("%Y%m%d") # 기준년월일 (YYYYMMDD)
df["time"] = df["measured_at"].dt.strftime("%H%M%S") # 기준년월일 (HHHHMMSS)
df_selected = df[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename(columns={
"name": "city",
"main.temp": "temperature",
"main.humidity": "humidity",
"wind.speed": "wind_speed"
})
return df_selectedLoad 함수 작성
- 테이블 구조 설정,
insert및overwrite함수를 추가
def load_weather(df: pd.DataFrame, my_sql_client: MySqlClient, method: str = "upsert",) -> None:
"""
변환된 날씨 데이터를 MySQL에 로드하는 함수.
Parameters:
- df (pd.DataFrame): 변환된 데이터
- my_sql_client (MySqlClient): 데이터베이스 클라이언트
- method (str, optional): 삽입 방법 ('insert', 'upsert', 'overwrite')
"""
metadata = MetaData()
table = Table(
"daily_weather",
metadata,
Column("dt", String(8), nullable=False, primary_key=True),
Column("time", String(6), nullable=False, primary_key=True),
Column("measured_at", DateTime, nullable=False),
Column("id", Integer, primary_key=True),
Column("city", String(100), nullable=True),
Column("temperature", Float, nullable=True),
Column("humidity", Integer, nullable=True),
Column("wind_speed", Float, nullable=True),
)
if method == "insert":
my_sql_client.insert(df=df, table=table, metadata=metadata)
elif method == "upsert":
my_sql_client.upsert(df=df, table=table, metadata=metadata)
elif method == "overwrite":
my_sql_client.overwrite(df=df, table=table, metadata=metadata)
else:
raise Exception("올바른 method를 설정해주세요: [insert, upsert, overwrite]")실습
03. 추출(Extract)
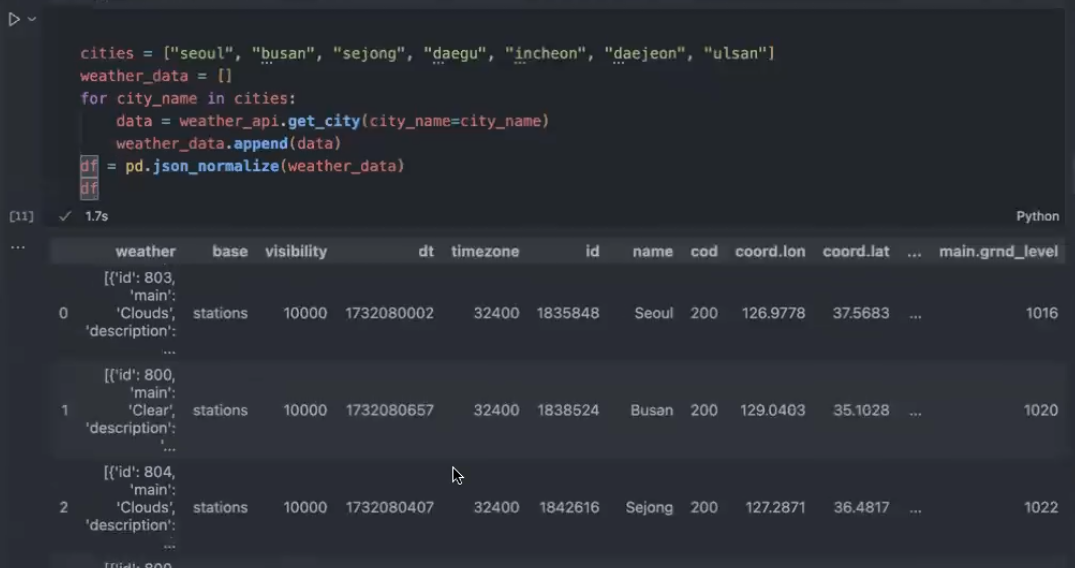
# 서울말고도 여러 도시에 대해 날씨 정보를 추출해볼까요?
def extract_weather(weather_api_client: WeatherApiClient) -> pd.DataFrame:
"""
여러 도시의 날씨 데이터를 추출합니다.
Parameters:
- weather_api_client (WeatherApiClient): API에서 날씨 데이터를 가져오기 위한 클라이언트.
Returns:
- pd.DataFrame: 지정된 도시들의 날씨 데이터를 포함하는 DataFrame.
"""
cities = ["seoul", "busan", "sejong", "daegu", "incheon", "daejeon", "ulsan"]
weather_data = []
for city_name in cities:
weather_data.append(weather_api_client.get_city(city_name=city_name))
df = pd.json_normalize(weather_data)
return df
df = extract_weather(weather_api_client=weather_api_client)
df.head()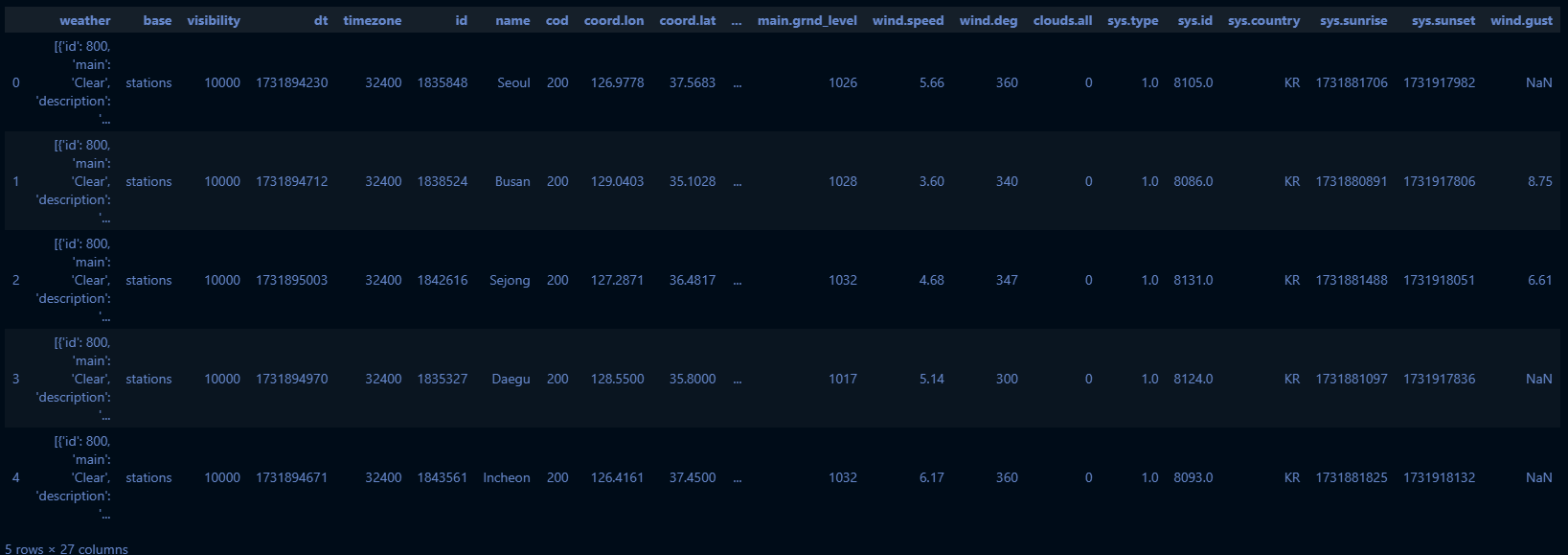
04. 변환(Transform)
# 전처리 코드를 함수로 만들어볼게요.
def transform_weather(df: pd.DataFrame) -> pd.DataFrame:
"""
날씨 데이터를 변환하고 전처리합니다.
Parameters:
- df (pd.DataFrame): 원본 날씨 데이터를 포함하는 DataFrame.
Returns:
- pd.DataFrame: 선택된 컬럼과 이름이 변경된 데이터로 구성된 변환된 DataFrame.
"""
df["measured_at"] = pd.to_datetime(df["dt"], unit="s") + pd.Timedelta(hours=9) # 한국시간
df["dt"] = df["measured_at"].dt.strftime("%Y%m%d") # 기준년월일 (YYYYMMDD)
df["time"] = df["measured_at"].dt.strftime("%H%M%S") # 기준년월일 (HHHHMMSS)
df_selected = df[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename(columns={
"name": "city",
"main.temp": "temperature",
"main.humidity": "humidity",
"wind.speed": "wind_speed"
})
return df_selected
clean_df = transform_weather(df)
clean_df.head()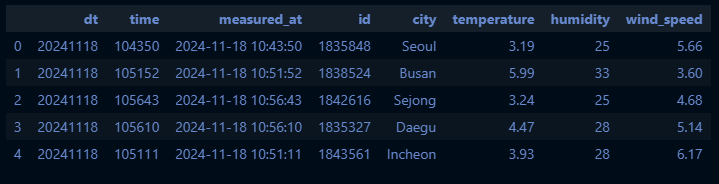
05. 적재(Load)
from sqlalchemy import MetaData, Table, Column, String, DateTime, Integer, Float
def load_weather(df: pd.DataFrame, my_sql_client: MySqlClient, method: str = "upsert",) -> None:
"""
변환된 날씨 데이터를 MySQL 데이터베이스에 로드합니다.
Parameters:
- df (pd.DataFrame): 변환된 날씨 데이터를 포함하는 DataFrame.
- my_sql_client (MySqlClient): MySQL 데이터베이스와 상호작용하는 클라이언트.
- table (Table): 데이터를 로드할 대상 데이터베이스 테이블.
- metadata (MetaData): 테이블 정의에 대한 SQLAlchemy 메타데이터 객체.
- method (str, optional): 데이터 삽입 방법을 지정합니다.
옵션: "insert", "upsert", "overwrite".
기본값은 "upsert"입니다.
"""
metadata = MetaData()
table = Table(
"daily_weather",
metadata,
Column("dt", String(8), nullable=False, primary_key=True),
Column("time", String(6), nullable=False, primary_key=True),
Column("measured_at", DateTime, nullable=False),
Column("id", Integer, primary_key=True),
Column("city", String(100), nullable=True),
Column("temperature", Float, nullable=True),
Column("humidity", Integer, nullable=True),
Column("wind_speed", Float, nullable=True),
)
if method == "insert":
my_sql_client.insert(df=df, table=table, metadata=metadata)
elif method == "upsert":
my_sql_client.upsert(df=df, table=table, metadata=metadata)
elif method == "overwrite":
my_sql_client.overwrite(df=df, table=table, metadata=metadata)
else:
raise Exception("올바른 method를 설정해주세요: [insert, upsert, overwrite]")
load_weather(df=clean_df, my_sql_client=my_sql_client, method="upsert")Assets 모듈 코드 작성(assets)
- ETL 함수를 모듈 파일로 변환
- Docstring 및 주석 꼭 포함해주세요!
connectors/mysql.py
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
import pandas as pd
from sqlalchemy import MetaData, Table, Column, String, DateTime, Integer, Float
def extract_weather(weather_api_client: WeatherApiClient) -> pd.DataFrame:
"""
여러 도시의 날씨 데이터를 추출합니다.
Parameters:
- weather_api_client (WeatherApiClient): API에서 날씨 데이터를 가져오기 위한 클라이언트.
Returns:
- pd.DataFrame: 지정된 도시들의 날씨 데이터를 포함하는 DataFrame.
"""
cities = ["seoul", "busan", "sejong", "daegu", "incheon", "daejeon", "ulsan"]
weather_data = []
for city_name in cities:
weather_data.append(weather_api_client.get_city(city_name=city_name))
df = pd.json_normalize(weather_data)
return df
def transform_weather(df: pd.DataFrame) -> pd.DataFrame:
"""
날씨 데이터를 변환하고 전처리합니다.
Parameters:
- df (pd.DataFrame): 원본 날씨 데이터를 포함하는 DataFrame.
Returns:
- pd.DataFrame: 선택된 컬럼과 이름이 변경된 데이터로 구성된 변환된 DataFrame.
"""
df["measured_at"] = pd.to_datetime(df["dt"], unit="s") + pd.Timedelta(hours=9) # 한국시간
df["dt"] = df["measured_at"].dt.strftime("%Y%m%d") # 기준년월일 (YYYYMMDD)
df["time"] = df["measured_at"].dt.strftime("%H%M%S") # 기준년월일 (HHHHMMSS)
df_selected = df[["dt", "time", "measured_at", "id", "name", "main.temp", "main.humidity", "wind.speed"]]
df_selected = df_selected.rename( # 컬럼명 수정
columns={
"name": "city",
"main.temp": "temperature",
"main.humidity": "humidity",
"wind.speed": "wind_speed",
}
)
return df_selected
def load_weather(
df: pd.DataFrame,
my_sql_client: MySqlClient,
method: str = "upsert",
) -> None:
"""
변환된 날씨 데이터를 MySQL 데이터베이스에 로드합니다.
Parameters:
- df (pd.DataFrame): 변환된 날씨 데이터를 포함하는 DataFrame.
- my_sql_client (MySqlClient): MySQL 데이터베이스와 상호작용하는 클라이언트.
- table (Table): 데이터를 로드할 대상 데이터베이스 테이블.
- metadata (MetaData): 테이블 정의에 대한 SQLAlchemy 메타데이터 객체.
- method (str, optional): 데이터 삽입 방법을 지정합니다.
옵션: "insert", "upsert", "overwrite".
기본값은 "upsert"입니다.
"""
metadata = MetaData()
table = Table(
"daily_weather",
metadata,
Column("dt", String(8), nullable=False, primary_key=True),
Column("time", String(6), nullable=False, primary_key=True),
Column("measured_at", DateTime, nullable=False),
Column("id", Integer, primary_key=True),
Column("city", String(100), nullable=True),
Column("temperature", Float, nullable=True),
Column("humidity", Integer, nullable=True),
Column("wind_speed", Float, nullable=True),
)
if method == "insert":
my_sql_client.insert(df=df, table=table, metadata=metadata)
elif method == "upsert":
my_sql_client.upsert(df=df, table=table, metadata=metadata)
elif method == "overwrite":
my_sql_client.overwrite(df=df, table=table, metadata=metadata)
else:
raise Exception("올바른 method를 설정해주세요: [insert, upsert, overwrite]")왜 ETL을 ETL Class로 만들지 않나요?
- ETL을 클래스로 만들지 않는 주된 이유
- ETL 프로세스가 일반적으로 순차적인 데이터 추출, 변환, 적재 작업을 수행하는 절차적 흐름이기 때문
- 각 단계가 독립적 → 함수 기반으로 작성하면 코드가 단순하고 명확하며, 유지보수와 테스트가 쉬움
- 반면, 상태 관리가 필요하거나 복잡한 설정을 유지해야 하는 경우에는 클래스를 사용해 전체 프로세스를 객체로 관리하는 것이 더 유용할 수 있음
PipeLine 함수 구성(pipeline)
import os
from dotenv import load_dotenv
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
from etl_module.assets.weather import extract_weather, transform_weather, load_weather
def main():
"""
ETL 프로세스를 실행하는 메인 함수.
1. 환경 변수를 로드하여 API 및 데이터베이스 연결 정보를 가져옵니다.
2. WeatherApiClient 및 MySqlClient 객체를 생성합니다.
3. ETL 프로세스를 순차적으로 수행합니다 (데이터 추출 -> 변환 -> 데이터베이스 적재).
"""
load_dotenv()
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST')
DB_USERNAME = os.environ.get('DB_USERNAME')
DB_PASSWORD = os.environ.get('DB_PASSWORD')
DB_DATABASE = os.environ.get('DB_DATABASE')
DB_PORT = os.environ.get('DB_PORT')
weather_api_client = WeatherApiClient(api_key = API_KEY)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT
)
# ETL 실행
df = extract_weather(weather_api_client=weather_api_client)
clean_df = transform_weather(df)
load_weather(df=clean_df, my_sql_client=my_sql_client)실습
06. ETL(추출(Extract), 변환(Transform), 적재(Load)) 메인 스립트 실행
df = extract_weather(weather_api_client=weather_api_client)
clean_df = transform_weather(df)
load_weather(df=clean_df, my_sql_client=my_sql_client, method="overwrite")import os
from dotenv import load_dotenv
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
from etl_module.assets.weather import extract_weather, transform_weather, load_weather
def main():
load_dotenv()
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get('DB_SERVER_HOST')
DB_USERNAME = os.environ.get('DB_USERNAME')
DB_PASSWORD = os.environ.get('DB_PASSWORD')
DB_DATABASE = os.environ.get('DB_DATABASE')
DB_PORT = os.environ.get('DB_PORT')
weather_api_client = WeatherApiClient(api_key = API_KEY)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT
)
# ETL 실행
df = extract_weather(weather_api_client=weather_api_client)
clean_df = transform_weather(df)
load_weather(df=clean_df, my_sql_client=my_sql_client)main()PipeLine 모듈 코드 작성(pipeline)
main함수를 모듈 파일로 변환- Docstring 및 주석 꼭 포함해주세요!
pipeline/etl_pipeline.py
import os
from dotenv import load_dotenv
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
from etl_module.assets.weather import extract_weather, transform_weather, load_weather
def main():
"""
main 함수는 전체 ETL 프로세스를 실행합니다.
1. 환경 변수를 로드하여 Weather API와 MySQL 데이터베이스 연결에 필요한 정보를 가져옵니다.
2. WeatherApiClient와 MySqlClient 객체를 생성합니다.
3. ETL 프로세스를 순차적으로 수행합니다:
- 데이터를 Weather API에서 추출합니다.
- 추출된 데이터를 변환하여 필요한 형태로 가공합니다.
- 가공된 데이터를 MySQL 데이터베이스에 적재합니다.
"""
load_dotenv()
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get("DB_SERVER_HOST")
DB_USERNAME = os.environ.get("DB_USERNAME")
DB_PASSWORD = os.environ.get("DB_PASSWORD")
DB_DATABASE = os.environ.get("DB_DATABASE")
DB_PORT = os.environ.get("DB_PORT")
weather_api_client = WeatherApiClient(api_key=API_KEY)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT,
)
# ETL 실행
df = extract_weather(weather_api_client=weather_api_client)
clean_df = transform_weather(df)
print(clean_df.shape)
load_weather(df=clean_df, my_sql_client=my_sql_client)
if __name__ == "__main__":
main()if __name__ == "__main__":- Python 파일을 직접 실행하도록 설정할 수 있음
PipeLine 실행
# Mac
python3 -m etl_module.pipeline.etl_pipeline
# Window
python -m etl_module.pipeline.etl_pipeline- 터미널에서 실행
python -m명령어는 모듈에서 직접 실행하기 위해 사용- 현재 작업 폴더(디렉토리)를 기준으로 모듈 경로 탐색
- 프롬프트로 실행할 거면 작업 폴더 위치까지 가서 실행
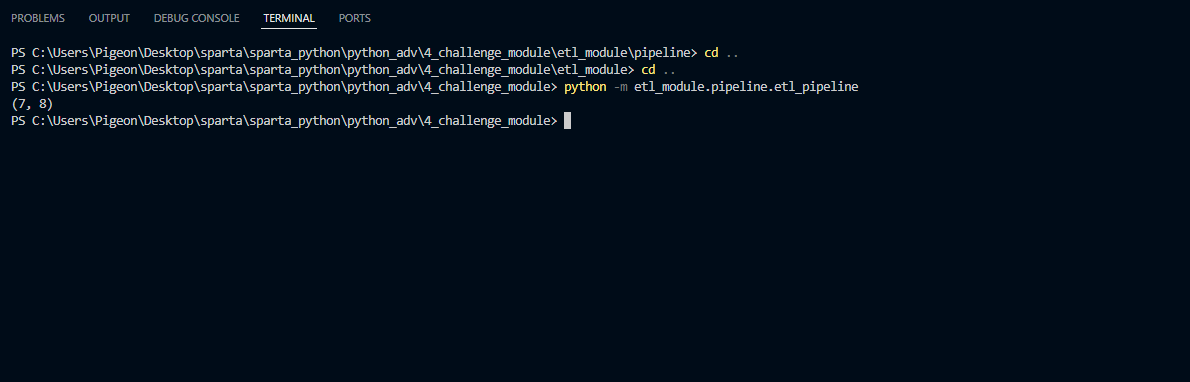
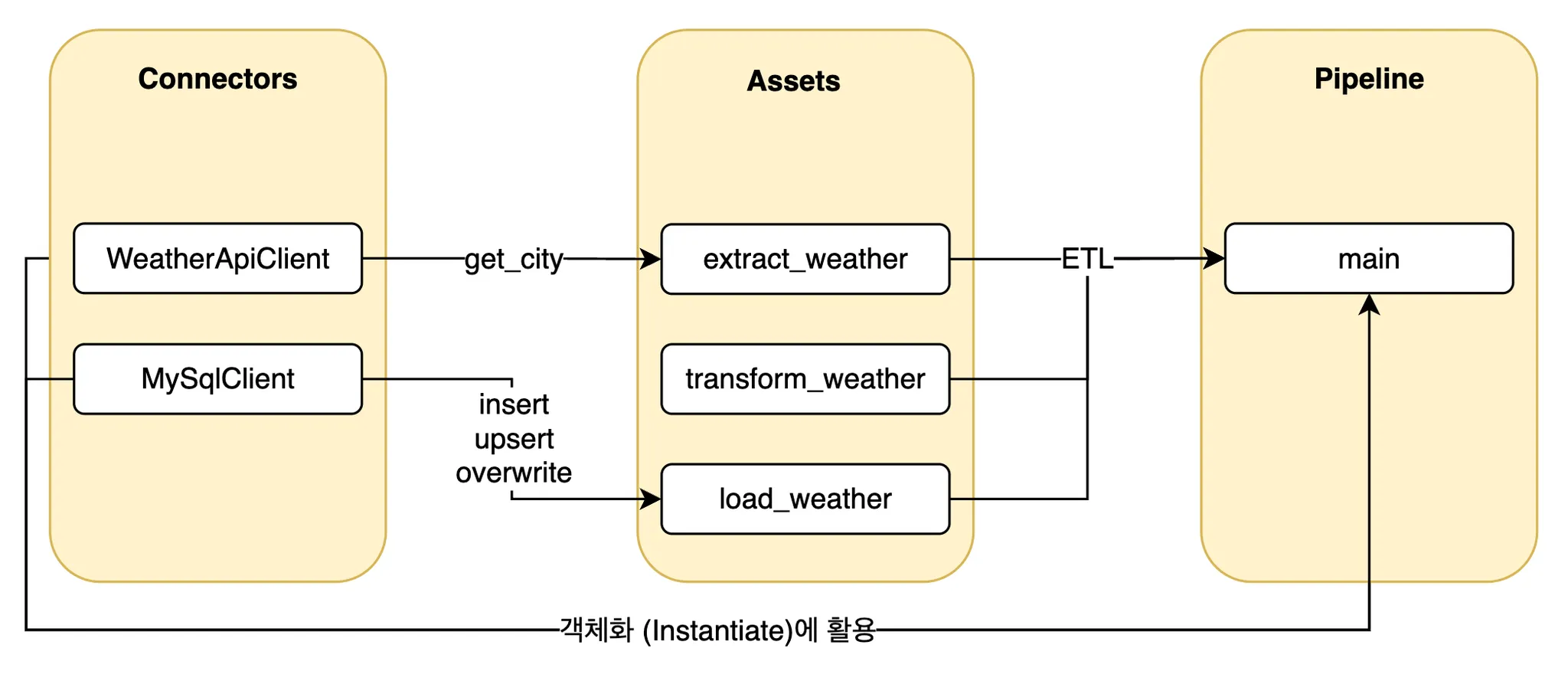
PipeLine 구조 설명
숙제
- 실습한 파이프라인 실행해보기
- 파이프라인이 잘 돌아가는지 pipeline/etl_pipeline.py 중간 중간에 print 를 추가해 여러 step 을 출력하기
- (예) [0시 0분] 파이프라인 시작
- (예) [0시 0분] 파이프라인 종료, XYZ 테이블에 8건이 추가되었습니다.
QnA
-
AWS
- IAM(Identity and Access Management)
- AWS 리소스에 대한 액세스를 안전하게 제어할 수 있는 웹 서비스
- IAM을 사용하면 사용자가 액세스할 수 있는 AWS 리소스를 제어하는 권한을 관리할 수 있음 → 리소스를 사용하도록 인증(로그인) 및 권한 부여(권한 있음)된 대상을 제어
- IAM(Identity and Access Management)
-
Networking
-
IP 허용
- 특정 IP 주소에서 액세스를 허용하거나 거부하는 목록을 구성하여 엔터프라이즈의 프라이빗 리소스에 대한 액세스를 제한할 수 있음
-
Inflow Outflow

2 B R 0 2 B