4회차 과제 해설
파이프라인이 잘 돌아가는지 pipeline/etl_pipeline.py 중간 중간에 print 를 추가해 여러 step 을 출력하기
(예) [0시 0분] 파이프라인 시작
(예) [0시 0분] 파이프라인 종료, XYZ 테이블에 8건이 추가되었습니다.
-
etl_pipeline.py에print함수로 내용만 추가해 주면 됩니다. -
내가 작성한 코드
import os
from dotenv import load_dotenv
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
from etl_module.assets.weather import extract_weather, transform_weather, load_weather
import time
def main():
"""
main 함수는 전체 ETL 프로세스를 실행합니다.
1. 환경 변수를 로드하여 Weather API와 MySQL 데이터베이스 연결에 필요한 정보를 가져옵니다.
2. WeatherApiClient와 MySqlClient 객체를 생성합니다.
3. ETL 프로세스를 순차적으로 수행합니다:
- 데이터를 Weather API에서 추출합니다.
- 추출된 데이터를 변환하여 필요한 형태로 가공합니다.
- 가공된 데이터를 MySQL 데이터베이스에 적재합니다.
"""
"""
step 출력해야 할 것
- ETL 파이프라인 시작
- 환경변수(.env) 파일 읽음
- 객체 생성(weather, mysql)
- Extract 시작, 끝 log
- Transform 시작, 끝 log
- Load 시작, 끝 log
- ETL 파이프라인 끝
"""
print(f"[{time.strftime('%X')}] 파이프라인 시작")
print(f"[{time.strftime('%X')}] .env 파일 읽기 시작")
load_dotenv()
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get("DB_SERVER_HOST")
DB_USERNAME = os.environ.get("DB_USERNAME")
DB_PASSWORD = os.environ.get("DB_PASSWORD")
DB_DATABASE = os.environ.get("DB_DATABASE")
DB_PORT = os.environ.get("DB_PORT")
print(f"[{time.strftime('%X')}] .env 파일 읽기 끝")
print(f"[{time.strftime('%X')}] 객체 생성(weather, mysql) 시작")
weather_api_client = WeatherApiClient(api_key=API_KEY)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT,
)
print(f"[{time.strftime('%X')}] 객체 생성(weather, mysql) 끝")
# ETL 실행
print(f"[{time.strftime('%X')}] Extract 시작")
df = extract_weather(weather_api_client=weather_api_client)
print(f"[{time.strftime('%X')}] Extract 끝")
print(f"[{time.strftime('%X')}] Transform 시작")
clean_df = transform_weather(df)
print(clean_df.shape)
print(f"[{time.strftime('%X')}] Transform 끝")
print(f"[{time.strftime('%X')}] Load 시작")
load_weather(df=clean_df, my_sql_client=my_sql_client)
print(f"[{time.strftime('%X')}] Load 끝")
print(f"[{time.strftime('%X')}] 파이프라인 종료, {DB_DATABASE} 테이블에 {clean_df.shape[0]}건이 추가되었습니다.")
if __name__ == "__main__":
main()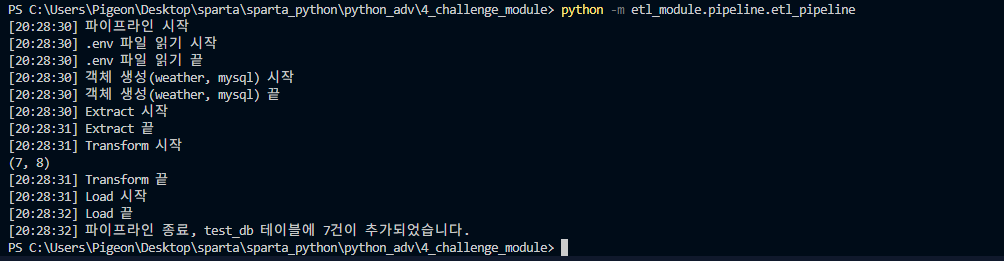
- 튜터님 해설
```python
import os
from dotenv import load_dotenv
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
from etl_module.assets.weather import extract_weather, transform_weather, load_weather
import time
def main():
"""
main 함수는 전체 ETL 프로세스를 실행합니다.
1. 환경 변수를 로드하여 Weather API와 MySQL 데이터베이스 연결에 필요한 정보를 가져옵니다.
2. WeatherApiClient와 MySqlClient 객체를 생성합니다.
3. ETL 프로세스를 순차적으로 수행합니다:
- 데이터를 Weather API에서 추출합니다.
- 추출된 데이터를 변환하여 필요한 형태로 가공합니다.
- 가공된 데이터를 MySQL 데이터베이스에 적재합니다.
"""
"""
step 출력해야 할 것
- ETL 시작
- 환경변수(.env) 읽었다
- 객체 생성(weather, mysql) 했다
- extract log 시작, 끝
- transform log 시작, 끝
- load log 시작, 끝
- ETL 파이프라인 끝
"""
print("ETL 시작")
print(".env 파일 읽기 시작")
load_dotenv()
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get("DB_SERVER_HOST")
DB_USERNAME = os.environ.get("DB_USERNAME")
DB_PASSWORD = os.environ.get("DB_PASSWORD")
DB_DATABASE = os.environ.get("DB_DATABASE")
DB_PORT = os.environ.get("DB_PORT")
print(".env 파일 읽기 끝")
print("객체 생성(weather, mysql) 시작")
weather_api_client = WeatherApiClient(api_key=API_KEY)
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT,
)
print("객체 생성(weather, mysql) 끝")
# ETL 실행
print("E 시작")
df = extract_weather(weather_api_client=weather_api_client)
print("E 끝")
print("T 시작")
clean_df = transform_weather(df)
print(clean_df.shape)
print("T 끝")
print("L 시작")
load_weather(df=clean_df, my_sql_client=my_sql_client)
print("L 끝")
print("ETL 끝")
if __name__ == "__main__":
main()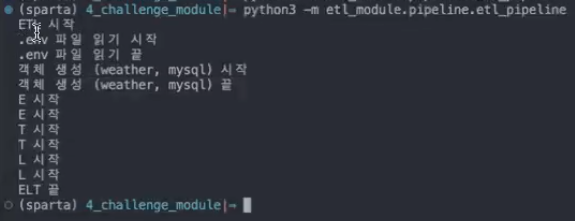
목표
- 로깅
loguru을 사용하여 다양한 로그 레벨로 메시지를 기록하고, 로그 파일로 저장하여 ETL 작업 추적
- 스케줄링
schedule을 사용하여 주기적으로 실행해야 하는 작업을 예약하고 자동화
- YAML 파일 관리
PyYAML을 사용하여 YAML 파일을 읽고 쓰며, 애플리케이션 설정을 관리
로깅(Logging)
-
애플리케이션에서 발생하는 다양한 이벤트를 추적하는 중요한 도구
- 코드의 실행 시간, 실행한 위치, 오류 발생 지점 등을 기록 → 디버깅을 더 쉽게 할 수 있음
-
loguru 라이브러리를 활용하여 로그 레벨별로 로그를 기록하는 방법 배우기
-
로그 심각도 수준에 따른 순서
- TRACE < DEBUG < INFO < WARNING < ERROR < CRITICA
| 심각도 | 이름 | 설명 | 예시 |
|---|---|---|---|
| 최하 | TRACE | 세부 정보 기록 | 함수 진입/출력, 변수 값 추척 등 |
| 하 | DEBUG | 디버깅 및 개발 중 필요한 정보 기록 | 함수 호출, 변수 값 등 |
| 중하 | INFO | 일반적인 경고 메시지 | 시스템 시작, 중요한 작업 완료 등 |
| - | SUCCESS | (이 밑으로는 안 좋은 것들임) | |
| 중상 | WARNING | 경고 메시지 | 예기치 않은 상황, 잠재적인 오류 발생 가능성 등 |
| 상 | ERROR | 오류 메시지 | 예외 발생, 시스템 장애 등 |
| 최상 | CRITICAL | 심각한 오류 메시지 | 시스템 다운 등 |
→ DEBUG는 보통 확인용으로 많이 넣음
e.g. 데이터 클렌징 한 후 데이터프레임에 대한 shape 출력 등
→ 일반적으로 INFO와 ERROR를 자주 씀
필요한 패키지 설치하기
pip install loguru기본 사용법
from loguru import logger
# 로그 레벨별 메시지 출력
logger.debug("디버그 메시지입니다.") # 디버깅 메시지
logger.info("정보 메시지입니다.") # 일반적인 정보 메시지
logger.warning("경고 메시지입니다.") # 경고 메시지
logger.error("에러 메시지입니다.") # 에러 메시지
logger.critical("심각한 에러 메시지입니다.") # 심각한 에러 메시지로그 파일에 기록하기
from datetime import datetime
# 로그 파일 이름 생성
current_datetime = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
log_filename = f"etl_process_{current_datetime}.log"
# 로그를 파일로 기록
logger.add(log_filename)
# 로그 메시지 출력
logger.info("정보 메시지입니다.")로그 레벨 설정
- 모든 로그를 저장 할 필요는 없음!
level="WARNING"설정하면 WARNING 이상의 중요도를 가진 로그만 기록됨
로그의 출력 형식 설정
- 로그의 출력 형식을 변경할 수 있음
- 예: 시간에서 milisecond 단위를 제거하고 level과 message만 포함해서 파일에 출력
logger.add("logfile_format.log", format="{time:YYYY-MM-DD HH:mm:ss} | {level} | {message}")
logger.info("정보 메시지")기타 파라미터
- rotation
- 로그 파일 회전 (로그 파일 크기나 시간 기준으로 회전)
- retention
- 오래된 로그 파일 삭제
- compression
- 로그 파일 압축
실습
- 로깅
- loguru 라이브러리를 사용하여 다양한 심각도 수준의 로그 메시지를 출력하는 예제
- 각 로그 레벨에 따라 다른 메시지를 기록
- 로그 심각도 수준에 따른 순서
: TRACE < DEBUG < INFO < WARNING < ERROR < CRITICAL
- loguru 라이브러리를 사용하여 다양한 심각도 수준의 로그 메시지를 출력하는 예제
from loguru import logger
# 다양한 심각도 수준으로 로그 메시지를 기록
logger.debug("디버그 메시지입니다.") # 디버깅 메시지
logger.info("정보 메시지입니다.") # 일반적인 정보 메시지
logger.success("모든 것이 잘 작동하고 있습니다!") # 성공 메시지
logger.warning("경고 메시지입니다.") # 경고 메시지
logger.error("에러 메시지입니다.") # 에러 메시지
logger.critical("심각한 에러 메시지입니다.") # 심각한 에러 메시지
→ 코드가 실행된 시간 | 심각도 | 코드 실행 줄 | 내용
from loguru import logger
from datetime import datetime
# 현재 시간에 기반한 파일명 생성
current_datetime = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
current_datetime[실행 결과]
'2024-11-21_12-07-53'log_filename = f"etl_process_{current_datetime}.log"
log_filename[실행 결과]
'etl_process_2024-11-21_12-07-53.log'# 파일 생성
logger.add(log_filename) # 파일로 저장히기 위해 사용
logger.debug("디버그 메시지입니다.") # 디버깅 메시지
logger.info("정보 메시지입니다.") # 일반적인 정보 메시지
logger.success("모든 것이 잘 작동하고 있습니다!") # 성공 메시지
logger.warning("경고 메시지입니다.") # 경고 메시지
logger.error("에러 메시지입니다.") # 에러 메시지
logger.critical("심각한 에러 메시지입니다.") # 심각한 에러 메시지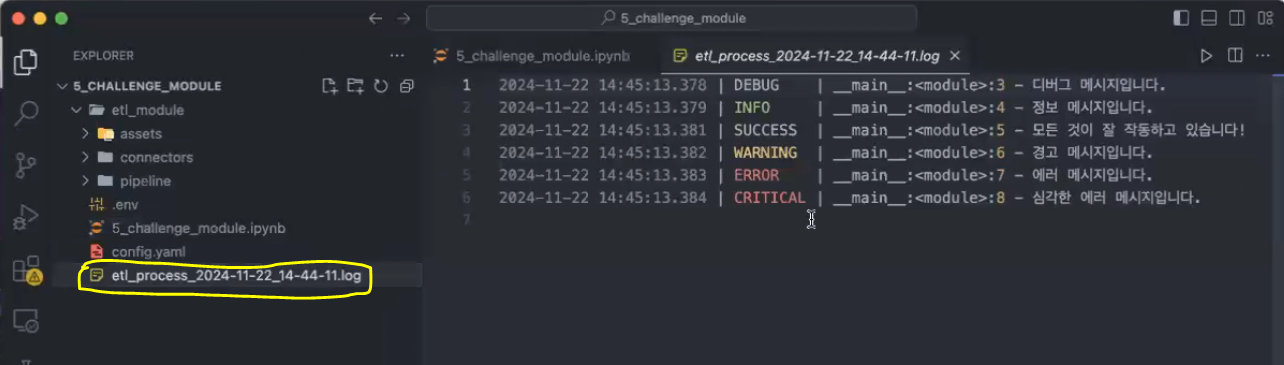
→ logger.add 다음에 나오는 내용들을 모두 파일에 저장함
→ 한 번 더 코드를 돌리면 파일명을 바꾸지 않은 상태이므로 해당 파일에 누적되어 다시 저장됨
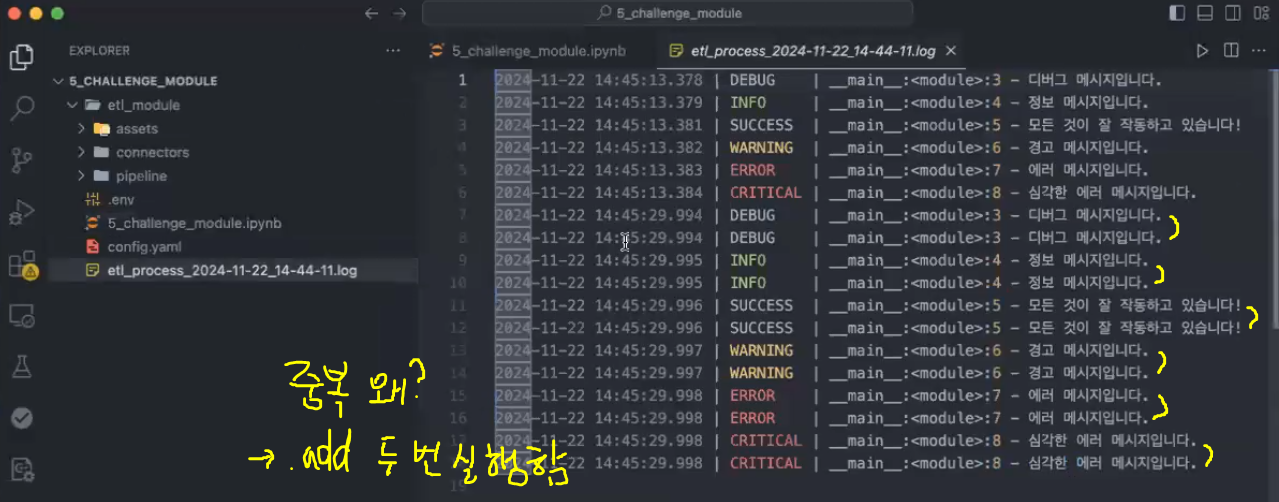
: add를 한 번 더 불러왔기 때문에 두 배로 생성이 됨
- level: 로그의 최소 기록 수준 설정
- 로그를 기록할 최소 수준을 설정할 수 있음
- 예를 들어, level="WARNING"로 설정하면 WARNING 이상의 중요도를 가진 로그만 기록
- [참고] 심각도 수준: TRACE < DEBUG < INFO < WARNING < ERROR < CRITICAL
- 로그를 기록할 최소 수준을 설정할 수 있음
logger.add("logfile_level.log", level="WARNING")
logger.debug("디버그 메시지입니다.") # 기록되지 않음
logger.info("정보 메시지입니다.") # 기록되지 않음
logger.success("모든 것이 잘 작동하고 있습니다!") # 기록되지 않음
logger.warning("경고 메시지입니다.") # 기록됨
logger.error("에러 메시지입니다.") # 기록됨
logger.critical("심각한 에러 메시지입니다.") # 기록됨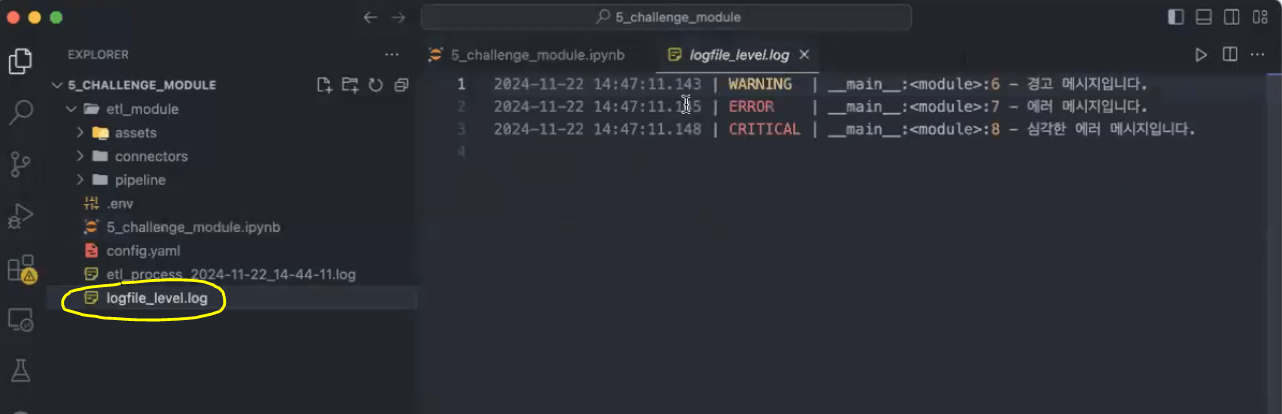
logger.add(log_filename)은 파일 하나 당(파일 이름 같으면) 한 개만 사용해야 함!(코드 전체에서 한 번만 불러와야 중복 없이 로그 기록됨)- 로그 레벨 따라 파일을 나눠 저장하는 것도 추천
- 전체 로그 파일: logfile_all.log
- 중요도 높은 로그 파일: logfile_level.log
- 로그 레벨 따라 파일을 나눠 저장하는 것도 추천
logger.add("logfile_all.log")
logger.add("logfile_level.log", level="WARNING")
logger.debug("디버그 메시지입니다.") # level 파일에는 기록되지 않음
logger.info("정보 메시지입니다.") # level 파일에는 기록되지 않음
logger.success("모든 것이 잘 작동하고 있습니다!") # level 파일에는 기록되지 않음
logger.warning("경고 메시지입니다.") # 둘 다 기록됨
logger.error("에러 메시지입니다.") # 둘 다 기록됨
logger.critical("심각한 에러 메시지입니다.") # 둘 다 기록됨- format: 로그의 출력 형식 설정
logger.add("logfile_format.log", format="{time:YYYY-MM-DD HH:mm:ss} | {level} | {message}")
logger.info("정보 메시지")→ 밀리초를 지우고 시간, 레벨, 메시지만 남기고 싶어서 출력 형식을 조절

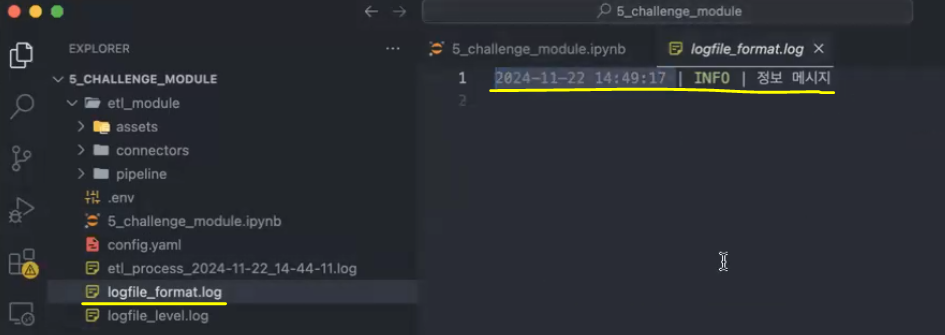

cf. format 설정 전 로그

스케줄링(Scheduling)
schedule라이브러리를 사용하여 주기적인 작업을 설정하고 관리
필요한 패키지 설치
pip install schedule기본 사용법
job()함수가 1초마다 실행되도록 설정schedule.every()를 사용하여 주기적으로 실행할 시간을 설정do()를 통해 실행할 작업을 지정합니다.
- 스케줄을 설정하고 나서 실제로
schedule.run_pending()을 통해 설정한 스케줄을 실행
import schedule
import time
# 실행할 함수 정의
def job():
print("작업이 실행되었습니다!")
# 1초마다 작업 실행
schedule.every(1).seconds.do(job)
# 스케줄러 실행
while True:
schedule.run_pending() # 예약된 작업이 있으면 실행
time.sleep(1) # 1초마다 체크다양한 주기 설정
- 이외에도 다양한 방법으로 스케줄 주기를 설정할 수 있음
- 10초마다 실행
- 1분마다 실행
- 매일 자정에 실행
- 매주 월요일 9시에 실행
# 10초마다 실행
schedule.every(10).seconds.do(job)
# 1분마다 실행
schedule.every(1).minute.do(job)
# 매일 자정에 실행
schedule.every().day.at("00:00").do(job)
# 매주 월요일 9시에 실행
schedule.every().monday.at("09:00").do(job)실습
- job() 함수가 1초마다 실행되도록 설정하는 코드
- schedule.every()를 사용하여 주기적으로 실행할 시간을 설정
- do()를 통해 실행할 작업을 지정
import schedule
import time
# 실행할 함수 정의
def job():
print("작업이 실행되었습니다!")
# 작업을 1초마다 실행하도록 스케줄링
schedule.every(1).seconds.do(job)
# 스케줄러 실행
while True:
schedule.run_pending() # 예약된 작업이 있으면 실행
time.sleep(1) # 1초마다 체크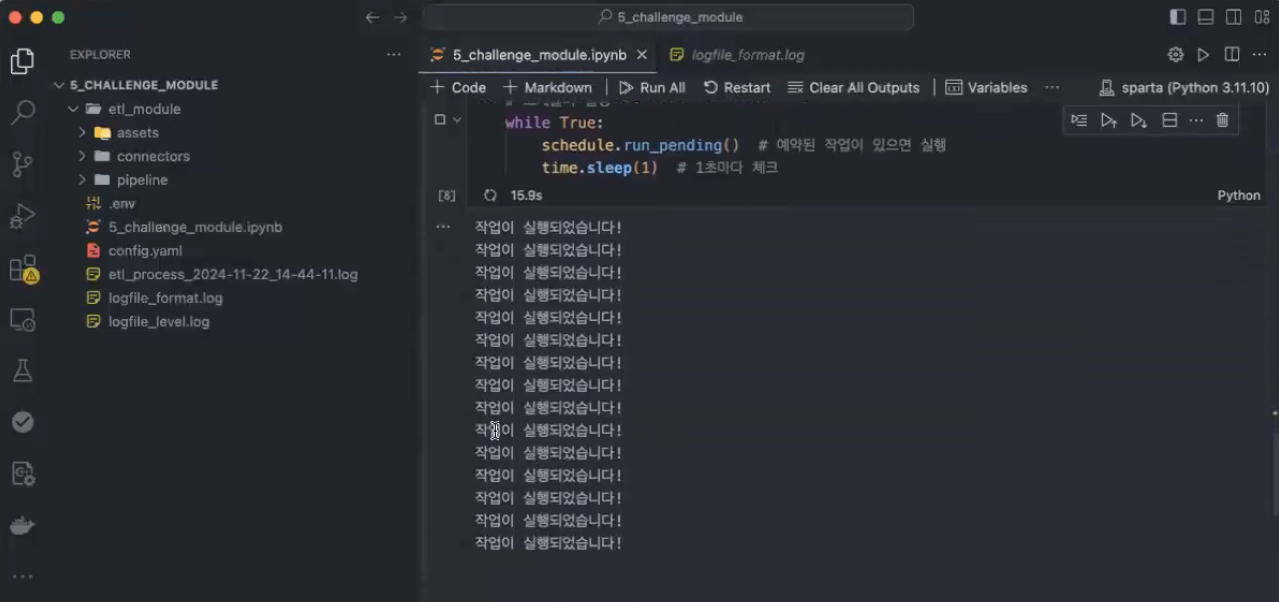
→ 내가 멈추게 하지 않는 이상 계속 돌아감

→ interrupt로 강제 멈춘 모습
- 다양한 주기 설정
# 10초마다 실행
schedule.every(10).seconds.do(job)
# 1분마다 실행
schedule.every(1).minute.do(job)
# 매일 자정에 실행
schedule.every().day.at("00:00").do(job)
# 매주 월요일 9시에 실행
schedule.every().monday.at("09:00").do(job)[실행 결과]
Every 1 week at 09:00:00 do job() (last run: [never], next run: 2024-11-25 09:00:00)def job():
print("작업실행")
schedule.every(1).second.do(job)
while True:
schedule.run_pending()
time.sleep(1)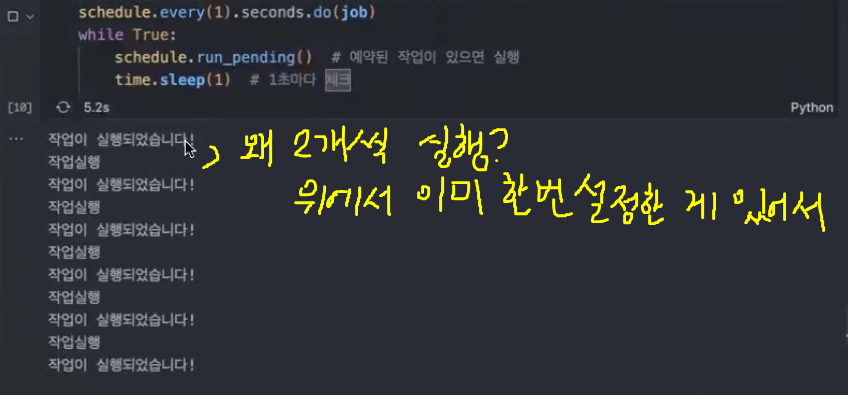
예약 관련 포인트
- 스케줄 하나 걸 때마다 하나 돌아감
- 자유도가 높아서
schedule.every(1).second.do(job) schedule.every(1).second.do(job) schedule.every(1).second.do(job)이렇게 하면 3개 켜져서 계속 돌아감
- 스케줄을 한 코드 당 하나만 하는 게 아니라 여러 가지를 할 수 있음 == 자유도가 높음
QnA
- 스레드 가능한가요?
- schedule 내의 변수를 설정하면 멀티스레드 가능합니다.
스레드(컴퓨팅)
- 스레드(thread): 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위
- 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있음 → 멀티스레드(multithread)
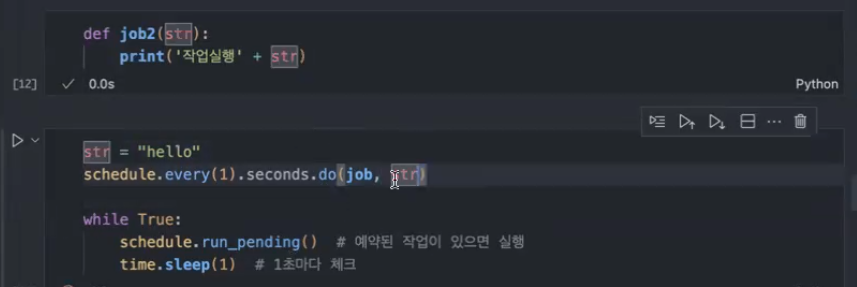
- 예약 실행하려는 함수에 파라미터가 있으면 어떻게 하나요?
,하고 파라미터 넣으면 됩니다.
(함수 옆에다가 입력하고자 하는 파라미터 적기)
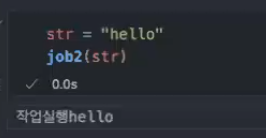
- 보통 함수를 부를 때(함수에 파라미터를 넣을 때)는 이렇게 햡니다.
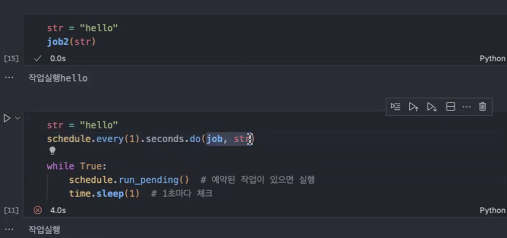
- 하지만 예약을 하는 경우에는 파라미터 입력하는 방법이 조금 달라요~ →
,로 구분!
YAML
- YAML Ain’t Markup Language의 약자
- 파일 형태의 하나임:
.yaml
- 파일 형태의 하나임:
- 사람이 읽기 쉬운 데이터 직렬화 형식
데이터 파이프라인은 다양한 설정과 구성이 필요하기 때문에 복잡해질 수 있습니다. 이때 YAML 파일을 사용하면 설정을 보다 간편하게 관리할 수 있습니다. 예를 들어, 데이터 소스, 처리 방식, 출력 위치, 스케줄링 정보 등을 YAML 파일로 정의하면 파이프라인을 더 쉽게 설정하고 관리할 수 있습니다.
.env 파일과의 차이점
-
.env파일은 주로 애플리케이션의 환경 변수를 저장하는 데 사용 → 보안 정보: 다른 사람이 보면 절대 안 됨!- 예를 들어, 데이터베이스 연결 정보나 API 키와 같은 비밀 정보를 관리할 때 유용
-
반면,
YAML파일은 애플리케이션의 구성 정보를 저장하는 데 사용 → 다른 사람이 봐도 상관 없음- 예를 들어, 데이터 파이프라인 일정, 로그 출력 위치 등을 계층적인 형태로 정의
결론
.env파일은 주로 환경 변수나 민감한 정보를 저장하는 데 사용YAML은 자동화 부분의 설정이나 구성을 관리하는 데 적합
필요한 패키지 설치
pip install pyyamlYAML 파일 작성(config.yaml)
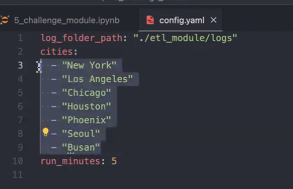
log_folder_path: "./etl_module/logs"
cities:
- "New York"
- "Los Angeles"
- "Chicago"
- "Houston"
- "Phoenix"
run_minutes: 5- log_folder_path
- 로그를 저장하고 싶은 위치를 입력
- cities
- 가져오고 싶은 도시 입력
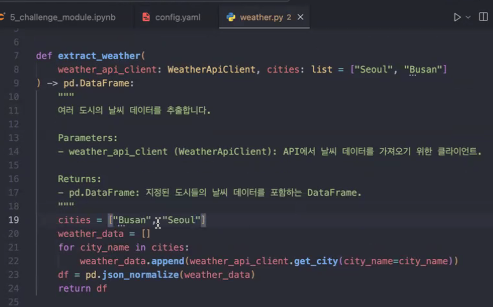
- 이전 코드를 보면 assets>weather.py에 직접
cities = ["도시1", "도시2", …, "도시n"]해서 입력했었는데 이제는 그렇게 안 해도 됨
- 이전 코드를 보면 assets>weather.py에 직접
- 가져오고 싶은 도시 입력
- run_minutes
- 스케줄링 할 때 쓰는 변수
- yaml 파일 cities의 장점
- city 바꾸고 싶을 때 기존 방식은 복잡
- YMAL에 넣으면 관리하기 편함!
YAML 파일 읽기
import yaml
# YAML 파일 경로
yaml_file_path = 'config.yaml'
# YAML 파일을 읽어 Python 객체로 변환
with open(yaml_file_path, 'r') as yaml_file:
config = yaml.safe_load(yaml_file)
# 읽은 데이터 출력
print(config.get('log_folder_path')) # 로그 폴더 경로 출력
print(config.get('cities')) # 도시 목록 출력실습
- PyYAML을 사용하여 이 YAML 파일을 읽어 Python에서 사용할 수 있는 데이터로 변환
import yaml
yaml_file_path = 'config.yaml'
# YAML 파일을 읽어서 Python 객체로 변환
with open(yaml_file_path, 'r') as yaml_file:
config = yaml.safe_load(yaml_file)
# 읽은 데이터 출력
config[실행 결과]
{'log_folder_path': './etl_module/logs',
'cities': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix'],
'run_minutes': 5}→ with open(): 여러 가지 파일을 읽을 때 사용하는 파이썬 내장 함수
→ 'r'는 읽기 전용으로 읽겠다는 의미!
→ as yaml_file은 읽은 걸 yaml_file 변수에 넣겠다는 의미
→ config는 python dictionray 형태
config.get('log_folder_path')[실행 결과]
'./etl_module/logs'config.get('cities')[실행 결과]
['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix']config.get('run_minutes')[실행 결과]
5파이프라인에 추가(Live)
: pipeline 폴더에 파일 저장
etl_pipeline.yaml
log_folder_path: "etl_module/logs"
cities:
- "New York"
- "Los Angeles"
- "Chicago"
- "Houston"
- "Phoenix"
run_minutes: 5etl_pipeline.py-
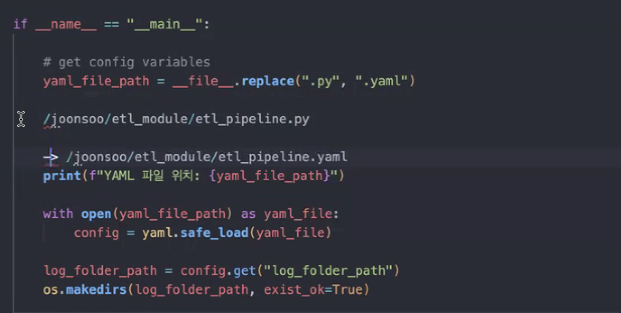
yaml은 line 104부터
__file__: 현재etl_pipeline.py이 있는 경로 정보(파이썬 파일 만들면 기본으로 가지고 있는 정보임)
-
line 111
os.makedirs(log_folder_path, exist_ok=True)는 뭘 하는 건가요?- log_folder_path가 존재하지 않는 경우 폴더를 만드는 역할을 합니다.
-
→ 코드 돌리면 logs 폴더가 생기는 걸 확인
import os
from datetime import datetime
from dotenv import load_dotenv
from etl_module.connectors.weather_api import WeatherApiClient
from etl_module.connectors.mysql import MySqlClient
from etl_module.assets.weather import extract_weather, transform_weather, load_weather
from loguru import logger
import schedule
import yaml
import time
def main(config):
"""
main 함수는 전체 ETL 프로세스를 실행합니다.
1. 환경 변수를 로드하여 Weather API와 MySQL 데이터베이스 연결에 필요한 정보를 가져옵니다.
2. WeatherApiClient와 MySqlClient 객체를 생성합니다.
3. ETL 프로세스를 순차적으로 수행합니다:
- 데이터를 Weather API에서 추출합니다.
- 추출된 데이터를 변환하여 필요한 형태로 가공합니다.
- 가공된 데이터를 MySQL 데이터베이스에 적재합니다.
"""
# 현재 날짜와 시간을 기반으로 Log 파일명 생성
current_datetime = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
log_filename = f"{config.get('log_folder_path')}/etl_process_{current_datetime}.log"
logger.add(log_filename)
logger.info("ETL 프로세스를 시작합니다.")
load_dotenv()
try:
API_KEY = os.environ.get("API_KEY")
DB_SERVER_HOST = os.environ.get("DB_SERVER_HOST")
DB_USERNAME = os.environ.get("DB_USERNAME")
DB_PASSWORD = os.environ.get("DB_PASSWORD")
DB_DATABASE = os.environ.get("DB_DATABASE")
DB_PORT = os.environ.get("DB_PORT")
if not all(
[API_KEY, DB_SERVER_HOST, DB_USERNAME, DB_PASSWORD, DB_DATABASE, DB_PORT]
):
# 누락된 변수들 확인
missing_vars = [
var
for var, value in [
("API_KEY", API_KEY),
("DB_SERVER_HOST", DB_SERVER_HOST),
("DB_USERNAME", DB_USERNAME),
("DB_PASSWORD", DB_PASSWORD),
("DB_DATABASE", DB_DATABASE),
("DB_PORT", DB_PORT),
]
if value is None
]
error_message = f"누락된 환경 변수: {', '.join(missing_vars)}"
logger.error(error_message)
raise ValueError(error_message) # 누락된 환경 변수가 있으면 예외를 발생시킴
logger.info("환경 변수를 성공적으로 로드했습니다.")
weather_api_client = WeatherApiClient(api_key=API_KEY)
logger.info("WeatherApiClient가 초기화되었습니다.")
my_sql_client = MySqlClient(
server_name=DB_SERVER_HOST,
database_name=DB_DATABASE,
username=DB_USERNAME,
password=DB_PASSWORD,
port=DB_PORT,
)
logger.info("MySqlClient가 초기화되었습니다.")
# ETL 실행
logger.info("Weather API에서 데이터 추출을 시작합니다.")
df = extract_weather(
weather_api_client=weather_api_client, cities=config.get("cities")
)
logger.info(
f"데이터 추출이 완료되었습니다. 총 {len(df)}개의 레코드가 있습니다."
)
logger.info("데이터 변환을 시작합니다.")
clean_df = transform_weather(df)
logger.info(
f"데이터 변환이 완료되었습니다. 변환된 데이터프레임의 크기: {clean_df.shape}"
)
logger.info("MySQL 데이터베이스로 데이터 적재를 시작합니다.")
load_weather(df=clean_df, my_sql_client=my_sql_client)
logger.info("데이터 적재가 성공적으로 완료되었습니다.")
except Exception as e:
logger.exception(f"ETL 프로세스 중 오류가 발생했습니다. 오류: {e}")
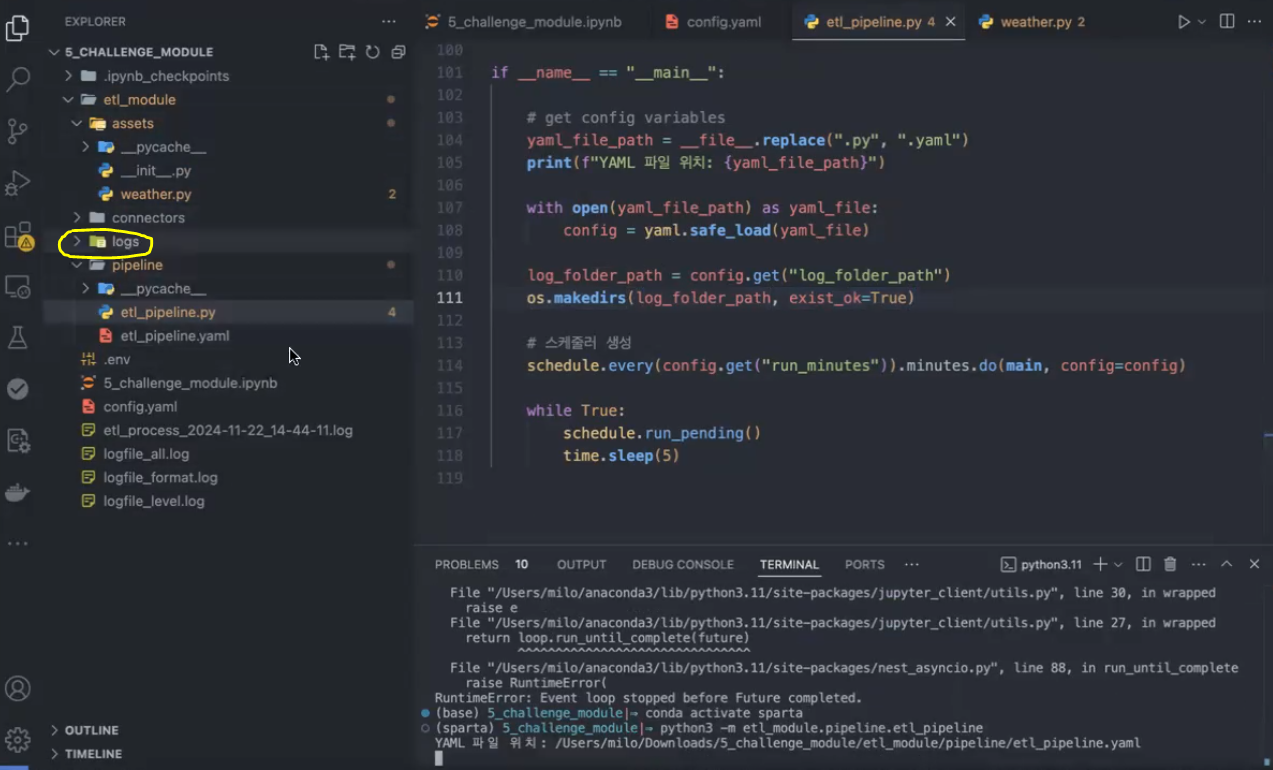
if __name__ == "__main__":
# get config variables
yaml_file_path = __file__.replace(".py", ".yaml")
print(f"YAML 파일 위치: {yaml_file_path}")
with open(yaml_file_path) as yaml_file:
config = yaml.safe_load(yaml_file)
log_folder_path = config.get("log_folder_path")
os.makedirs(log_folder_path, exist_ok=True)
# 스케줄러 생성
schedule.every(config.get("run_minutes")).minutes.do(main, config=config)
while True:
schedule.run_pending()
time.sleep(5)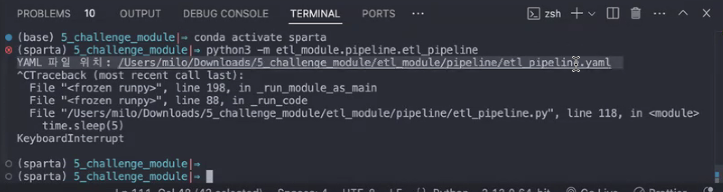
→ run_minutes가 5분으로 설정되어 있어서 terminal에서 실행하고 5분 지날 때마다 계속 돌아감
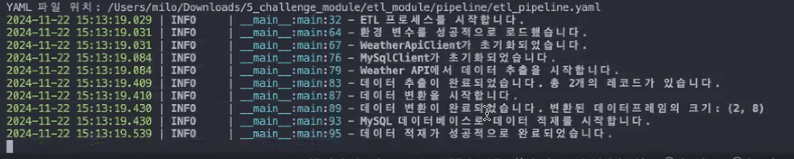
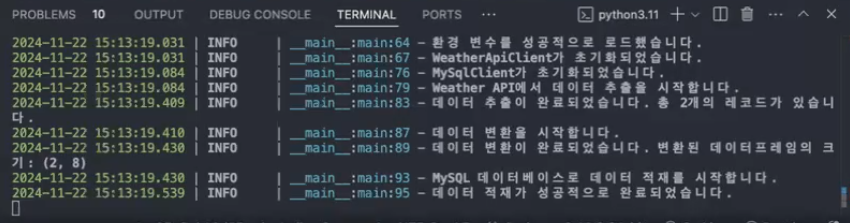
- 오류가 있는 경우 아래와 같이 작동: 환경 변수 하나를 누락시키고 실행시킨 상황
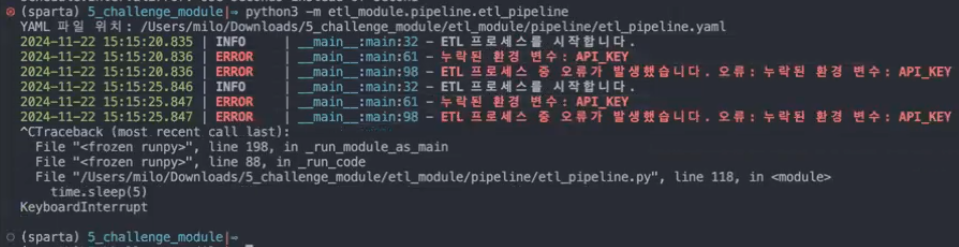
QnA
- 우리는 Python만을 활용해서 ETL 데이터 파이프라인을 설계했습니다.
하지만 이외에도 이를 자동화 할 수 있는 다양한 툴이 존재해요.- Airbyte : https://airbyte.com
- ELT 파이프라인의 Extract & Load 부분을 담당
※ ELT(Extract-Load-Transform) 파이프라인: 데이터 가져오기(API 등) - 바로 MySQL에 저장 - 이후 SQL을 써서 전처리
→ 데이터 적재 비용이 처리 비용보다 더 저렴해져서 요즘은 ELT 방식을 선호한다고 함
→ ETL은 데이터 적재 비용이 비싸던 시절에 데이터 양을 최대한 줄여서 넣는 게 트렌드였음(요즘은 ELT가 트렌드) - API 에서 데이터 불러오는 부분 등 손쉽게 설정 가능
- ELT 파이프라인의 Extract & Load 부분을 담당
- dbt : https://www.getdbt.com
- Data-Build-Tool
- Analytics Engineer 가 많이 활용함
- ELT 나 ELT 에서 Transform 을 담당
- Scheduling Tools
- Airflow : https://airflow.apache.org
- dagster : https://dagster.io
- Airbyte : https://airbyte.com
5회차 동안 열심히 수강하시느라 고생 많으셨습니다. 👏👏👏
Give yourselves a pat on the back!

