출력문
- Python의 가장 기본
- 코드상의 어떤 결과물들을 출력시켜 사람이 직접 그 결과물을 볼 수 있도록 해주는 문법
- 코드 작성시 수시로 확인하기 위해, 수정할 에러를 점검하기 위해, 데이터 시각화를 위해 등등 다양한 경우에서 사용되기 때문에 가장 많이 쓰는 문법
1) print()
- 파이썬의 출력문 중 가장 많이 사용하는 함수 (앞으로 계속해서 보게 될 함수이기도 함)
- 화면에 값을 출력하는 데 사용
- 괄호 안에 출력하고자 하는 값을 넣어주면 됨
- 여러 값을 출력할 때는 쉼표(,)로 구분
예시
- Hello, World! 문구 출력
- 문자를 파이썬에서 사용할 땐 “”(따옴표) 사이에 문자를 작성해야 함
(변수 배울 때 한번 더 나옴)
print("Hello, World!")- 숫자 출력
print(123)- 변수 출력
- 변수: 무언가를 담고 있는 바구니
(변수 배울 때 한번 더 나옴)
x = 10
print(x)- 변수와 문자열 함께 출력
- 콤마(,)를 이용하면 print 함수 내에서 여러 개의 출력을 한 번에 할 수 있음
- 변수에 대한 출력과 그에 대한 설명을 함께 출력할 때 많이 사용
x = 10
print("변수 x의 값은", x, "입니다.")실전 사용 예시 1: 데이터 분석 결과물 출력
- 위에서 배운 것을 토대로 실제 데이터 분석 상황에서 사용될 법한 예시를 다루기
- 데이터 분석 결과를 설명과 함께 출력해 보는 코드 작성
# 데이터 분석 결과
num_records = 1000
# 결과 출력
print("총 ", num_records, "명의 레코드가 분석되었습니다.")실전 사용 예시 2: AI 모델의 정확도 출력
- AI 모델의 결과를 출력하는 상황의 예시
- AI모델의 결과가 accuracy라는 변수에 담겨졌다고 가정하고 그 결과를 출력
- 데이터 분석 결과를 설명과 함께 출력해 보는 코드 작성
# 딥러닝 모델의 정확도
accuracy = 0.8765
'''
지금은 숫자가 바로 들어갔지만
실전에선 AI의 모델의 결과들을 가지고
따로 계산해서 얻어냅니다.
'''
# 결과 출력
print("모델의 정확도는 ", accuracy, "입니다.")파이썬의 핵심 '변수'
- 무언가 담을 수 있는 바구니 같은 존재
1) 변수란
변수 선언
- 변수는 값을 저장하는 공간으로, 사용하기 전에 선언되어야 함
- 변수를 선언할 때에는 변수명을 지정하고 할당 연산자(=)를 사용하여 값을 할당
- 변수명은 본인이 짓고 싶은 이름 아무거나로 지으면 됨
# 변수 선언과 할당
age = 25
name = "Alice"변수 사용
- 변수에는 어떠한 값이든 할당할 수 있음
- 변수명을 사용하여 해당 값에 접근할 수 있음
- 변수는 값을 다양한 연산에 사용할 수 있음
# 변수 사용
print(name) # "Alice" 출력
print("나이:", age) # "나이: 25" 출력
# 변수를 사용한 연산
double_age = age * 2
print("나이의 두 배:", double_age) # "나이의 두 배: 50" 출력변수의 자료형
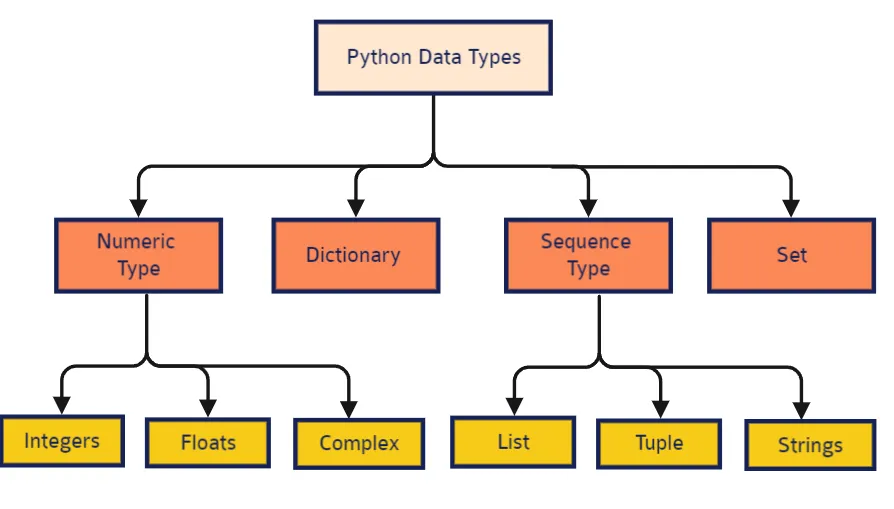
- 파이썬은 동적 타이핑 언어 → 변수에 할당되는 값에 따라 자료형이 자동으로 결정
- 주요 자료형: 정수(int), 실수(float), 문자열(str), 리스트(list), 튜플(tuple), 딕셔너리(dict) 등
- 특히, Sequence Type에 해당하는 자료형(리스트, 튜플, 문자열)은 앞으로도 자주 사용할 것이니 꼭 기억
참고: Sequence Type
- 여기서 Sequence Type은 ‘순서대로 나열된 자료형’을 의미
- 문자도, 리스트, 튜플 모두 순서대로 값들이 나열된 데이터 자료형
e.g.
"apple": 첫번째 글자가 a, 다섯번째 글자가 e (a,p,p,l,2)
100: 100이라는 숫자는 숫자 그 자체입니다. 그렇기 때문에 계산을 할 때도 숫자 그 자체를 보고 계산을 합니다. 100과 2를 더하면 102라는 결과값이 나와야지 1002라는 결과값(순서대로 나열)이 나오면 안되겠죠?
참고: type 함수를 이용하면 해당 변수가 어떤 자료형인지 알 수 있음
※ print나 type과 같은 함수 == ‘내장함수’(이미 파이썬에서 만들어져 있는 함수)# 변수의 자료형 확인 print(type(age)) # <class 'int'> 출력 print(type(name)) # <class 'str'> 출력
2) 변수의 종류 1: 문자열
변수에 문자열 넣기
- 문자열은 작은 따옴표('')나 큰 따옴표("")로 감싸서 선언
# 문자열 변수 선언
name = "Alice"
greeting = 'Hello, World!'
'''
작은 따옴표, 큰 따옴표 모두 쓰는 이유는
문자열 자체에 따옴표가 들어가 있는 경우가 있기 때문
'''
name = "Alice's something"문자열 연산
- 문자열 변수끼리 연결(concatenate)하여 새로운 문자열을 만들 수 있음
# 문자열 연산
full_greeting = greeting + " My name is " + name
print(full_greeting) # "Hello, World! My name is Alice" 출력문자열과 함께 메서드 사용
- 메서드: 함수를 사용하는 방법 중 하나
- 모든 함수가 메서드로 사용되는 건 아님(메서드로 사용되는 함수는 특정되어 있음)
# 문자열 메서드 활용
sentence = "python programming is fun"
print(sentence.upper()) # 전부 대문자로 변환하여 출력3) 변수의 종류 2: 숫자열
숫자열 선언
- 정수(int)나 실수(float) 형태의 숫자열 → 그냥 변수에 할당하면 됨
# 숫자열 변수 선언
num1 = 10
num2 = 3.14숫자열 연산
- 숫자열 변수끼리 사칙연산 가능
- 나눗셈
- / 연산자를 사용하면 실수로 결과가 반환
- // 연산자를 사용하면 정수로 결과가 반환
- 나머지(modulus) 연산자인 %를 사용하여 나머지를 계산할 수 있음
- 활용: 딥러닝에서 반복 실행 결과를 10번째마다 한 번 출력하고 싶을 때
반복시행횟수%10 == 0일 때만 출력하면 딥러닝 결과값이 10의 배수에 해당하는 횟수 번째에만 출력됨
- 활용: 딥러닝에서 반복 실행 결과를 10번째마다 한 번 출력하고 싶을 때
# 숫자열 연산
sum_result = num1 + num2
diff_result = num1 - num2
product_result = num1 * num2
division_result = num1 / num2
integer_division_result = num1 // num2
remainder_result = num1 % num2
print("합:", sum_result)
print("차:", diff_result)
print("곱:", product_result)
print("나누기:", division_result)
print("정수 나누기:", integer_division_result)
print("나머지:", remainder_result)숫자열 함수와 메서드
- 숫자열에는 다양한 함수와 메서드가 내장되어 있음
- 예를 들어, abs() 함수는 절댓값을 반환하고, round() 함수는 반올림한 값을 반환
# 숫자열 함수와 메서드 활용
num3 = -7.89
abs_result = abs(num3) # 절댓값 계산
round_result = round(num3) # 반올림 계산
print("절댓값:", abs_result)
print("반올림:", round_result)정수형과 실수형의 차이점
정수형(Integer)
- 소수점 이하의 부분이 없는 숫자
int형으로 표현되며, 연산 결과도 항상 정수로 나옴
e.g. 1, 100, -5 등
# 정수형 변수 선언
num1 = 10
num2 = -5
# 정수형 변수끼리의 연산
sum_result = num1 + num2
print("합:", sum_result) # 출력: 합: 5
# 정수형 연산 결과
print("합의 자료형:", type(sum_result)) # 출력: 합의 자료형: <class 'int'>실수형(Float)
- 소수점 이하의 숫자를 포함하는 숫자
float형으로 표현되며, 연산 결과도 소수점 이하를 포함한 실수로 나옴
e.g. 3.14, -0.5, 2.71828 등
# 실수형 변수 선언
num3 = 3.14
num4 = -0.5
# 실수형 변수끼리의 연산
product_result = num3 * num4
print("곱:", product_result) # 출력: 곱: -1.57
# 실수형 연산 결과
print("곱의 자료형:", type(product_result)) # 출력: 곱의 자료형: <class 'float'>- 정수랑 실수랑 연산하면? 실수형!
4) 변수의 종류 3: 불리언(Boolean)
- 파이썬에서는 Boolean 자료형이 주어진 조건이 참(True) 또는 거짓(False)을 나타내는 데 사용
- 조건식을 평가하는 데 매우 중요하며 데이터 분석에서도 자주 활용함
설명 및 예시
- Boolean 자료형을 변수에 선언하거나, 간단한 논리 연산을 수행하는 방법 살펴보기
# Boolean 변수 선언
is_raining = True
is_sunny = False
# 비교 연산자를 사용하여 Boolean 값 비교
x = 10
y = 5
greater_than = x > y
print(greater_than) # True 출력5) NaN (결측값)
- NaN(Not a Number: 데이터에서 결측치(missing value)를 나타내는 특수한 값
- 주로 수치형 데이터에서 발생
- 특히 데이터 과학이나 머신 러닝 분야에서 데이터 정제 및 처리 과정에서 자주 다룸
- NaN 자체가 자료형인 건 아니고 숫자형 안에 들어 있는 하나의 값임
설명
- 정의할 수 없는 수치값
e.g. 0으로 나누는 연산이나 유효하지 않은 수학적 연산 결과를 나타낼 때 사용 - 데이터프레임과 같은 데이터 구조에서는 결측치를 표현할 때 NaN 사용
예시
수학 연산에서 발생하는 NaN
# 0으로 나누는 연산
result = 1 / 0
print(result) # 출력: Infinity
# 유효하지 않은 수학적 연산
import math
result = math.sqrt(-1)
print(result) # 출력: nan데이터프레임에서의 NaN
# NaN을 포함한 데이터프레임 생성
import pandas as pd
data = {'A': [1, 2, None],
'B': [3, None, 5]}
df = pd.DataFrame(data)
print(df)
# 출력:
# A B
# 0 1.0 3.0
# 1 2.0 NaN
# 2 NaN 5.06) 입력문(input)
- 사용자로부터 키보드로 입력을 받는 함수
- 이 함수를 사용하면 사용자와 상호작용하여 프로그램을 만들 수 있음
- ※주의※ input 함수로 받아들이는 모든 값은 "문자"임
# 예시 1
name = input("이름을 입력하세요: ")
print("안녕하세요,", name, "님!")
'''
사용자로부터 이름을 입력받아 화면에 출력하는 프로그램:
프로그램이 실행되면 "이름을 입력하세요: "라는 메시지가 표시되고,
사용자는 키보드로 이름을 입력할 수 있습니다.
그런 다음 입력된 이름이 화면에 출력됩니다.
'''
# 예시2
num1 = int(input("첫 번째 숫자를 입력하세요: "))
num2 = int(input("두 번째 숫자를 입력하세요: "))
sum = num1 + num2
print("두 숫자의 합은", sum, "입니다.")
'''
사용자로부터 두 개의 숫자를 입력받아 덧셈을 수행하는 프로그램:
사용자가 숫자를 입력하면 input() 함수로 문자열 형태로 입력을 받습니다.
이후 int() 함수를 사용하여 문자열을 정수로 변환하고,
두 숫자를 더하여 합을 구한 후 화면에 출력합니다.
'''추가: int()
number = 17.7 type(number) # 출력: float new_number = int(number) new_number # 출력: 17 type(new_number) # 출력: int '''문자 형태로 된 숫자도 정수 형태로 된 숫자로 바꿀 수 있음''' '100' type('100') # 출력: str new_number2 = int('100') type(new_number2) # 출력: int
7) 실전 사용 예시 1: 데이터를 담고자 할 때
- 각 학생의 성적을 개별 변수에 할당하여 저장하고, 이후에 각 변수에 담긴 데이터를 출력
- 이 방식은 간단하고 직관적이지만, 많은 데이터를 다룰 때는 리스트나 딕셔너리를 사용하는 것이 더 효율적임
- 변수의 수가 많아질수록 코드가 복잡해지고 관리하기 어려워지기 때문
- 이 방식은 간단하고 직관적이지만, 많은 데이터를 다룰 때는 리스트나 딕셔너리를 사용하는 것이 더 효율적임
# 학생들의 성적 데이터를 변수에 할당
grade1 = 85
grade2 = 92
grade3 = 78
grade4 = 90
grade5 = 88
# 각 변수에 담긴 데이터 출력
print("첫 번째 학생의 성적:", grade1)
print("두 번째 학생의 성적:", grade2)
print("세 번째 학생의 성적:", grade3)
print("네 번째 학생의 성적:", grade4)
print("다섯 번째 학생의 성적:", grade5)8) 실전 사용 예시 2: 계산된 값을 담고자 할 때
- 리스트를 사용하지 않고 각각의 데이터를 개별 변수에 할당하여 이를 활용하여 데이터의 평균을 계산
- 리스트를 사용하는 것보다 간단하고 직관적일 수 있으나, 데이터의 개수가 많아질수록 변수의 수가 많아지고 코드가 복잡해지는 단점이 있음
- 때문에 일반적으로는 리스트나 다른 자료구조를 사용하여 데이터를 관리하는 것이 더 효율적
# 데이터를 변수에 할당
data1 = 85
data2 = 92
data3 = 78
data4 = 90
data5 = 88
# 데이터의 평균 계산
total = data1 + data2 + data3 + data4 + data5 # 모든 데이터의 합을 계산
count = 5 # 데이터의 개수를 직접 지정
average = total / count # 데이터의 평균을 계산
# 결과 출력
print("데이터 평균:", average)9) 실전 사용 예시 3: 머신러닝 모델구조 자체를 담을 때
- 주로 변수에 모델 객체를 할당하는 방법 사용
- 이를 통해 모델을 저장하고 필요할 때 불러와 재사용할 수 있음
- 예시는 Scikit-learn 라이브러리를 사용하여 간단한 선형 회귀 모델을 변수에 할당
- 라이브러리를 불러오는 건 마지막 수업에서 다룰 예정
from sklearn.linear_model import LinearRegression
# 선형 회귀 모델 객체 생성
model = LinearRegression()
/*Scikit-learn 라이브러리를 사용하여 선형 회귀 모델을 생성하고 model이라는 변수에 담았음!
이후부터 선형회귀 모델을 사용할때 model이라고 정한 변수를 사용하여 선형회귀 모델을 다루면 됨*/Quiz
1) 숫자 자료형 값을 변수에 저장하고 출력하기
- 퀴즈: 다음 두 수의 합을 구하여 출력하세요.
- 첫 번째 수: 15
- 두 번째 수: 27
num1 = 15
num2 = 27
print(num1+num2)
# 답안
# 다양한 정답이 있을 수 있으므로 아래 답은 참고로 확인하세요!
first = 15
second = 27
print(first + second)
# 결과로 42가 출력되면 정답입니다!
>>> 422) 문자 자료형 값을 변수에 저장하고 출력하기
- 퀴즈: 다음 문장을 변수에 담고 출력하세요.
- "Python은 데이터 분석과 인공지능 분야에서 매우 인기 있는 프로그래밍 언어입니다."
str = "Python은 데이터 분석과 인공지능 분야에서 매우 인기 있는 프로그래밍 언어입니다."
print(str)
# 답안
# 다양한 정답이 있을 수 있으므로 아래 답은 참고로 확인하세요!
string = "Python은 데이터 분석과 인공지능 분야에서 매우 인기 있는 프로그래밍 언어입니다."
print(string)
# 결과로 아래 문장이 출력되면 정답입니다!
>>> 'Python은 데이터 분석과 인공지능 분야에서 매우 인기 있는 프로그래밍 언어입니다.'
2 B R 0 2 B