목표
- 리스트가 무엇인지 알고 생성하며 활용할 수 있다.
- 리스트와 튜플의 차이점을 이해하고 튜플을 생성할 수 있다.
- 딕셔너리의 키(Key)와 값(Value)의 개념을 이해하고 딕셔너리를 자유자재로 다룰 수 있다.
파이썬의 뼈대: 리스트, 튜플, 딕셔너리
- 리스트, 튜플, 딕셔너리가 뭘까?
- 리스트 비중이 가장 큼! 이해 잘 하고 활용할 수있어야 함
- 튜플은 리스트와 많은 부분이 닮아 있음
- 차이: 튜플은 변경 불가능
- 딕셔너리는 사전 생각하면 편함
1) 리스트, 튜플, 딕셔너리를 배워야 하는 이유
- 데이터 분석을 할 때 다양하고 많은 데이터들을 다루어야 하는데 이런 데이터들을 구조화하고 조작하기 위해 필요한 것임
- 문법을 정확하게 알고 있어야 데이터를 적절하게 다룰 수 있고 이 문법들을 잘 알고 있을수록 훨씬 효율적인 프로그래밍을 할 수 있음
- 파이썬 문법을 정복하기 위해 반드시 이해해야 함
2) 결과물 미리보기
- 리스트, 튜플, 딕셔너리를 통해 할 수 있는 일
: 데이터를 담고, 정리하고, 꺼낼 수 있다- 설명
- 딥러닝 모델을 반복 학습하며 결과를 리스트에 추가
- 데이터 불러올때, 경로 처리할때 split 사용
- 데이터를 임의의 범위만큼 선택할때 슬라이싱, 인덱싱 사용
- 데이터를 변경 불가능하게 사용하고 싶을 때 사용
- 데이터를 담는 하나의 방법
- 목적
- 주로 맨 처음 데이터를 불러오고 가공할 때 사용
- 결과를 저장할 때 많이 사용
- 기대 효과
- 데이터를 자유자재로 다룰 수 있고 정리할 수 있음
- 설명
리스트 기본 사용법
1) 리스트(list)란
- 파이썬에서 가장 자주 사용되는 데이터 구조 중 하나
- 여러 항목들을 담을 수 있는 가변(mutable)한 시퀀스(sequence)
- 시퀀스 자료형: 순서대로 값들이 나열된 자료형
- 대괄호
[]를 사용해 만들 수 있음
기본 구조
- 여러 값을 순서대로 담을 수 있음
- 각 값은 쉼표로 구분되며, 대괄호 안에 들어감
# 1. 리스트 생성
my_list = [1, 2, 3, 4, 5]
# 2. 리스트의 기본 구조
print(my_list) # 출력: [1, 2, 3, 4, 5]2) 리스트 기본 사용법
인덱싱(Indexing)
- 리스트에서 특정 값에 접근하거나 일부분을 추출하는 방법
- 인덱싱: 리스트에서 특정 위치의 값에 접근하는 방법
# 리스트 생성
numbers = [1, 2, 3, 4, 5]
# 첫 번째 요소에 접근하기
first_number = numbers[0]
print("First number:", first_number)
'''
※ 파이썬에서 첫 번째는 1이 아닌 "0"
'''
# 두 번째 요소에 접근하기
second_number = numbers[1]
print("Second number:", second_number)
# 마지막 요소에 접근하기
last_number = numbers[-1]
print("Last number:", last_number)
'''
앞에서부터 순서 정할 때: 0 1 2
뒤에서부터 순서 정할 때: -1 -2 -3
'''
# 음수 인덱스를 사용하여 역순으로 요소에 접근하기
second_last_number = numbers[-2]
print("Second last number:", second_last_number)※ 범위에서 벗어난 인덱싱 → error 뜸
다양한 메서드(Methods)
- 리스트에 대해 유용한 여러 가지 메서드 존재
- append(): 리스트에 항목을 추가 ★★★
- array.append(x) 형태
- extend(): 리스트에 다른 리스트의 모든 항목을 추가 ★
- array.extend(iterable) 형태
- insert(): 리스트의 특정 위치에 항목을 삽입
- array.insert(i, x) 형태
- array의 원하는 위치 i 앞에 추가할 값 x를 삽입
- remove(): 리스트에서 특정 값을 삭제
- pop(): 리스트에서 특정 위치의 값을 제거하고 반환(리턴)
- 리스트 값 중 하나 빼서 "변수에 담을 수 있음"
- index(): 리스트에서 특정 값의 인덱스를 찾음
- count(): 리스트에서 특정 값의 개수 세기
- sort(): 리스트의 항목들을 정렬 ★
- reverse(): 리스트의 항목들을 역순으로 뒤집기
- append(): 리스트에 항목을 추가 ★★★
'반환’이라는 표현은 함수의 결과 값을 밖으로 끄집어 낸다라는 것을 의미합니다. 이에 대한 자세한 내용은 함수에서 다루게 됩니다! 여기서는 ‘결과 값을 얻어냈다’ 정도로만 이해하셔도 충분합니다 🙂
# 리스트 생성
my_list = [1, 2, 3, 4, 5]
#리스트의 다양한 메서드(Methods)
my_list.append(6) # 리스트에 새로운 항목 추가
print(my_list) # 출력: [1, 2, 3, 4, 5, 6]
my_list.extend([7, 8, 9]) # 다른 리스트의 모든 항목을 추가
print(my_list) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9]
my_list.insert(2, 10) # 세 번째 위치에 값 삽입
print(my_list) # 출력: [1, 2, 10, 3, 4, 5, 6, 7, 8, 9]
my_list.remove(3) # 값 3 삭제
print(my_list) # 출력: [1, 2, 10, 4, 5, 6, 7, 8, 9]
popped_value = my_list.pop(5) # 다섯 번째 위치의 값 제거하고 반환
print(popped_value) # 출력: 6
print(my_list) # 출력: [1, 2, 10, 4, 5, 7, 8, 9]
print(my_list.index(4)) # 출력: 3 (값 4의 인덱스)
print(my_list.count(7)) # 출력: 1 (값 7의 개수)
my_list.sort() # 리스트 정렬
print(my_list) # 출력: [1, 2, 4, 5, 7, 8, 9, 10]
my_list.reverse() # 리스트 역순으로 뒤집기
print(my_list) # 출력: [10, 9, 8, 7, 5, 4, 2, 1]
# 참고: 리스트의 insert 구문 형태
# 이건 실행하는 코드가 아닙니다
a_list.insert(index, element)
'''
리스트의 insert 메서드는
위와 같은 구문으로 사용할 수 있음
index: 요소를 삽입할 위치의 인덱스
element: 삽입할 요소의 값
'''값 삭제
- 특정 값을 삭제하거나 전체를 삭제하는 방법
# 리스트의 항목 삭제
del my_list[0]
print("첫 번째 항목 삭제 후 리스트:", my_list)
# 리스트 내 값들의 모든 항목 제거
my_list.clear()
print("모든 항목 제거 후 리스트:", my_list) 리스트의 항목 삭제 del
- 값의 인덱스를 알려줘서 삭제
cf. remove(): 값 자체를 알려줘서 삭제
cf. pop(): 몇 번째 위치의 값을 제거하고 나서 어떤 변수에 그 값을 담아줄 수 있음(반환 가능)
값 변경
- 인덱싱을 활용하여 특정 위치의 리스트 값을 다른 값으로 변경
my_list = ['apple', 'banana', 'cherry', 'date', 'elderberry']
# 리스트 값 변경하기
my_list[3] = 'dragonfruit'
print(my_list) # 출력: ['apple', 'banana', 'cherry', 'dragonfruit', 'elderberry']🡆 이상치, 결측치, 값으로 정의할 수 없는 NaN 등이 리스트에 있을 때 리스트를 인덱싱 해서 새로운 값으로 수정
중첩된 리스트에서 인덱싱
- 두 개 이상의 중첩된 리스트에서도 인덱싱이 가능
# 중첩된 리스트에서 인덱싱하기
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(nested_list[1][0]) # 출력: 4 (두 번째 리스트의 첫 번째 항목)🡆 두 번 중첩된 리스트 인덱싱 시 대괄호를 두 번 써야 함!
e.g. list[1][0]: 전체 리스트에서 두 번째, 작은 리스트에서 첫 번째 값 == 4
실전 사용 예시: 간단한 데이터 계산
- 학점 데이터 값들을 리스트 형태로 만들어 간편하게 평균을 계산하는 코드
# 리스트를 사용한 간단한 데이터 계산 예시
grades = [85, 92, 88, 78, 90]
average_grade = sum(grades) / len(grades)
print("평균 성적:", average_grade)🡆 len(): 길이를 알려주는 함수
🡆 리스트에서 길이 == 요소의 개수(데이터 값의 개수)
리스트 고급 사용법
- 조금 더 세련된 방법 배우기
1) 슬라이싱: [start:end:step]
- 리스트의 일부분을 추출하는 것
- 리스트에서 특정 범위의 항목을 선택하거나 리스트를 자르는 등의 작업을 할 수 있음
# 리스트 슬라이싱의 구분
# 아래는 실행하는 코드가 아닙니다
new_list = old_list[start:end:step]※ 파이썬은 맨 처음을 가리키는 인덱스가 0임! (1이 아님에 유의 ← SQL은 1임)
※ 슬라이싱을 할 때 끝에 입력할 인덱스는 내가 선택할 인덱스보다 +1을 해주어야 함!
(1번째부터 12번째까지의 요소를 가져올 것이면 [0:13] 이렇게 슬라이싱을 해야 한다)
예시
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 1. 일부분만 추출하기
# 항상 끝 인덱스의 한 칸 전까지만 간다!
'''
아니면 '값 사이에 있는 순서가 다섯 번째인 곳까지'
슬라이싱한다고 생각해도 됨
'''
print(my_list[2:5]) # 출력: [3, 4, 5]
# 2. 시작 인덱스 생략하기 (처음부터 추출)
print(my_list[:5]) # 출력: [1, 2, 3, 4, 5]
# 3. 끝 인덱스 생략하기 (끝까지 추출)
print(my_list[5:]) # 출력: [6, 7, 8, 9, 10]
# 4. "음수 인덱스" 사용하기 (뒤에서부터 추출)
print(my_list[-3:]) # 출력: [8, 9, 10]
'''
마이너스는 '인덱싱'이 뒤에서부터 시작한다는 의미
슬라이싱의 방향은 step의 부호임
→ print(my_list[0:10:-1]) 하면 [] 출력됨
첫 번째 요소(1)에서 왼쪽 방향 값은 없기 때문
→ print(my_list[10:-11:-1]) 하면
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1] 출력됨
첫 번째 요소의 인덱스 값이 0인 동시에 -10이기 때문
'''
# 5. 간격 설정하기 (특정 간격으로 추출)
print(my_list[1:9:2]) # 출력: [2, 4, 6, 8]
# 6. 리스트 전체를 복사하기
copy_of_list = my_list[:]
print(copy_of_list) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 7. 리스트를 거꾸로 뒤집기
reversed_list = my_list[::-1]
print(reversed_list) # 출력: [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
'''
→ print(my_list[5:2:-1]) 하면 [6, 5, 4] 출력
→ 방향이 바뀌었으므로 인덱스 값이 2인 요소(3)의 한 칸 전은 오른쪽 값인 4임
(정방향이었을 때는 한 칸 전이 왼쪽 값 2였음)
'''- 슬라이싱을 활용하여 홀수나 짝수 값만 추출하는 것도 가능
- 코딩테스트 할 때 가끔 나옴
# 리스트에서 홀수 번째 인덱스의 값들 출력하기
my_list = [10, 20, 30, 40, 50, 60, 70, 80, 90]
odd_index_values = my_list[1::2]
print("홀수 번째 인덱스의 값들:", odd_index_values) # 출력: [20, 40, 60, 80]
even_index_values = my_list[::2]
print("짝수 번째 인덱스의 값들:", even_index_values) # 출력: [10, 30, 50, 70, 90]2) 정렬: sort() 메서드
- 리스트의 항목들을 정렬하는 데 사용
- 이 메서드를 호출하면 리스트 내의 항목들이 오름차순으로 정렬됨
- 기본적으로 숫자와 문자열에 대해서는 오름차순으로 정렬되며, 리스트의 항목들이 동일한 형태일 경우에만 정렬
- 원래의 리스트를 변경하며, 새로운 정렬된 리스트를 반환하지 않음
my_list = [1, 5, 4, 2, 3]
my_list.sort(reverse=False) # 출력: [1, 2, 3, 4, 5]
# reverse: 정렬 순서를 지정
# 기본값은 False로 오름차순을 의미하며, True로 설정하면 내림차순으로 정렬됨
my_list = [1, 5, 4, 2, 3]
my_list.sort() # 출력: [1, 2, 3, 4, 5]
my_list = [1, 5, 4, 2, 3]
my_list.sort(reverse=True) # 출력: [5, 4, 3, 2, 1]예시
# 숫자로 이루어진 리스트 정렬 예시
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5]
numbers.sort()
print("정렬된 리스트:", numbers) # 출력: [1, 1, 2, 3, 4, 5, 5, 6, 9]
# 문자열로 이루어진 리스트 정렬 예시
words = ['apple', 'banana', 'orange', 'grape', 'cherry']
words.sort()
print("정렬된 리스트:", words) # 출력: ['apple', 'banana', 'cherry', 'grape', 'orange']
# 내림차순으로 리스트 정렬 예시
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5]
numbers.sort(reverse=True)
print("내림차순으로 정렬된 리스트:", numbers) # 출력: [9, 6, 5, 5, 4, 3, 2, 1, 1]
# 리스트의 문자열 길이로 정렬 예시
words = ['apple', 'banana', 'orange', 'grape', 'cherry']
words.sort(key=len)
print("문자열 길이로 정렬된 리스트:", words) # 출력: ['apple', 'grape', 'banana', 'cherry', 'orange']3) 실전 예시
데이터를 임의의 범위만큼 선택할때 슬라이싱, 인덱싱 사용
- 실제 Iris 공용 데이터셋을 활용하여 데이터 중의 일부를 train dataset, 나머지를 test dataset으로 구분하는 작업 진행해보기
- AI모델을 학습할 때 train dataset으로 학습하고 test dataset으로 평가를 진행
- 이 두 데이터는 절대로 섞이면 안되고 따로 구분을 해주어야 함
from sklearn.datasets import load_iris
# Iris 데이터셋 불러오기
iris = load_iris()
# Iris 데이터셋에서 특정 범위의 데이터 슬라이싱하기
train_data = iris.data[:100] # 인덱스 0부터 99까지의 데이터 추출
print("학습 데이터:", train_data)
test_data = iris.data[100:] # 인덱스 100부터 끝까지의 데이터 추출
print("학습 데이터:", test_data)튜플 사용법
- 리스트와 튜플 차이 이해하기
1) 튜플(tuple)이란?
- 변경할 수 없는(immutable) 시퀀스(sequence) 자료형
- 여러 개의 요소를 저장하는 컨테이너
- 리스트와 유사하지만, 한 번 생성된 이후에는 요소를 추가, 삭제, 수정할 수 없음
- 이러한 특성으로 인해 파이썬에서 데이터를 보호하고 싶을 때 주로 사용
- 소괄호
()를 사용하여 생성하며, 각 요소는 쉼표,로 구분
my_tuple = (1, 2, 3, 'hello', 'world')
# 괄호가 없어도 생성됨!
my_tuple = 1, 2, 3, 'hello', 'world'
print(my_tuple) # 출력: (1, 2, 3, 'hello', 'world')2) 튜플 인덱싱, 슬라이싱
- 튜플은 인덱스와 슬라이싱을 사용하여 요소에 접근할 수 있음
- 인덱스는 0부터 시작
- 음수를 사용하여 뒤에서부터 접근할 수도 있음
- 튜플은 변경할 수 없기 때문에 요소를 추가, 삭제, 수정하는 것은 불가능
- 하지만 튜플을 합치거나 반복하여 새로운 튜플을 생성할 수는 있음
- 데이터 불변성을 보장하고, 데이터 분석에서 데이터의 무결성을 유지하는 데 도움이 됨
my_tuple = (1, 2, 3, 'hello', 'world')
print(my_tuple[0]) # 첫 번째 요소에 접근
print(my_tuple[-1]) # 마지막 요소에 접근
print(my_tuple[2:4]) # 인덱스 2부터 3까지의 요소를 슬라이싱3) 튜플에서 자주 사용하는 메서드
count(): 지정된 요소의 개수를 반환index(): 지정된 요소의 인덱스를 반환
# 튜플 생성
my_tuple = (1, 2, 3, 4, 1, 2, 3)
# count() 메서드 예제
count_of_1 = my_tuple.count(1)
print("Count of 1:", count_of_1) # 출력: 2
# index() 메서드 예제
index_of_3 = my_tuple.index(3)
print("Index of 3:", index_of_3) # 출력: 24) 튜플과 리스트의 차이점
- 튜플은 변경할 수 없기 때문에 요소를 추가, 삭제, 수정하는 것은 불가능
- 튜플을 합치거나 반복하여 새로운 튜플을 생성할 수는 있음
데이터 불변성(immutable)
- 불변성이란 변경할 수 없는 상태를 얘기하는 것
↔ 가변성(mutable) - 튜플이 불변성이다 == 튜플 안에 있는 값을 임의로 수정할 수 없다
tuple1 = (1, 2, 3)
tuple2 = ('a', 'b', 'c')
new_tuple = tuple1 + tuple2 # 두 개의 튜플을 합치기
print(new_tuple)
repeated_tuple = tuple1 * 3 # 튜플을 반복하기
print(repeated_tuple)5) 튜플 → 리스트로 변경, 리스트 → 튜플로 변경
- 튜플을 리스트로 변경하려면
list()함수를 사용하고, 리스트를 튜플로 변경하려면tuple()함수를 사용 - 각 함수는 인자로 변환하려는 자료형을 전달받아 새로운 자료형으로 변환
예시
# 튜플을 리스트로 변경하기
my_tuple = (1, 2, 3, 4, 5)
my_list = list(my_tuple)
print(my_list) # 출력: [1, 2, 3, 4, 5]
# 리스트를 튜플로 변경하기
my_list = [1, 2, 3, 4, 5]
my_tuple = tuple(my_list)
print(my_tuple) # 출력: (1, 2, 3, 4, 5)6) 실전 예시
변하면 안되는 개인정보 데이터를 튜플로 변수에 담기
- 데이터의 불변성을 유지해야 하는 경우에 튜플을 사용하여 데이터를 표현
- 데이터의 불변성을 보장하고 데이터의 일관성을 유지
# 데이터 표현 예시
record = ('John', 30, 'john@example.com')딕셔너리 사용법
- 데이터를 사전처럼 정리
1) 딕셔너리란?
- 키-값 쌍의 데이터를 저장하는 자료구조
- 중괄호
{}로 둘러싸여 있으며 각 요소는 쉼표로 구분 - 각 키는 유일해야 하지만 값은 중복될 수 있음
- 파이썬 딕셔너리는 해시 테이블로 구현되어 있어 키를 사용하여 매우 빠르게 값을 찾을 수 있음
- 해시 테이블(Hash Table): 키를 값에 매핑(Key: Value)할 수 있는 구조인, 연관 배열(Associative Array)을 구현하는 자료구조. 해시 테이블의 핵심은 해시 함수('임의 크기 데이터'를 '고정 크기 값'으로 매핑하는 데 사용할 수 있는 단방향 함수. 키를 해시 값으로 인코딩)임
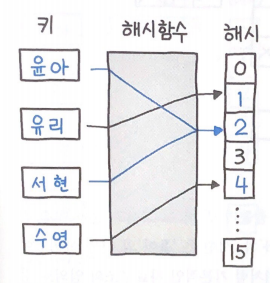
my_dict = {
'key1': 'value1',
'key2': 'value2',
'key3': 'value3'
}
# 'key1', 'key2', 'key3': 키
# 'value1', 'value2', 'value3': 키에 대응하는 값2) 딕셔너리 기본기
-
다양한 용도로 사용
- 학생 이름을 키로 하고 점수를 값으로 하는 성적표 만들기
- 도시 이름을 키로 하고 인구를 값으로 하는 도시 인구 정보를 저장
-
Pandas와 연계해 사용하기 편해서 자주 이용
- pandas의 데이터프레임(df) 형태를 만들 때 딕셔너리를 이용해 만들 수 있음 → 표 형식이라
-
인덱스 번호 대신에 키(key)를 사용한다고 생각하면 쉬움
# 빈 딕셔너리 생성
empty_dict = {}
# 학생 성적표
grades = {
'Alice': 90,
'Bob': 85,
'Charlie': 88
}
# 접근하기
print(grades['Alice']) # 출력: 90
# 값 수정하기
grades['Bob'] = 95
# 요소 추가하기
grades['David'] = 78
# 요소 삭제하기
del grades['Charlie']3) 딕셔너리에서 자주 사용되는 메서드
keys(): 모든 키를 dict_keys 객체로 반환values(): 모든 값을 dict_values 객체로 반환items(): 모든 키-값 쌍을 (키, 값) 튜플로 구성된 dict_items 객체로 반환get(): 지정된 키에 대한 값을 반환합니다. 키가 존재하지 않으면 기본값을 반환pop(): 지정된 키와 해당 값을 딕셔너리에서 제거하고 값을 반환popitem(): 딕셔너리에서 마지막 키-값 쌍을 제거하고 반환
# 딕셔너리 생성
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# keys() 메서드 예제
keys = my_dict.keys()
print("Keys:", keys) # 출력: dict_keys(['name', 'age', 'city'])
# values() 메서드 예제
values = my_dict.values()
print("Values:", values) # 출력: dict_values(['John', 30, 'New York'])
# items() 메서드 예제
items = my_dict.items()
print("Items:", items) # 출력: dict_items([('name', 'John'), ('age', 30), ('city', 'New York')])
# get() 메서드 예제
age = my_dict.get('age')
print("Age:", age) # 출력: 30
# pop() 메서드 예제
city = my_dict.pop('city')
print("City:", city) # 출력: New York
print("Dictionary after pop:", my_dict) # 출력: {'name': 'John', 'age': 30}
# popitem() 메서드 예제
last_item = my_dict.popitem()
print("Last item popped:", last_item) # 출력: ('age', 30)
print("Dictionary after popitem:", my_dict) # 출력: {'name': 'John'}4) 실전 예시: 데이터를 사전처럼 저장하고 싶을 때
- 파이썬 딕셔너리는 다양한 상황에서 유용하게 사용
- 딕셔너리를 활용하여 다양한 데이터를 효율적으로 관리하고 분석할 수 있음
사용자 정보 관리
user_info = {
'username': 'john_doe',
'email': 'john@example.com',
'age': 30,
'is_active': True
}제품 카탈로그
products = {
'1001': {'name': 'Keyboard', 'price': 20.99, 'stock': 50},
'1002': {'name': 'Mouse', 'price': 15.50, 'stock': 70},
'1003': {'name': 'Monitor', 'price': 199.99, 'stock': 30}
}날짜별 이벤트 관리
events = {
'2024-04-01': ['Meeting with client', 'Team lunch'],
'2024-04-02': ['Presentation preparation', 'Project review'],
'2024-04-03': ['Training session', 'Code debugging']
}영화 정보 저장
movies = {
'Interstellar': {'genre': 'Sci-Fi', 'director': 'Christopher Nolan', 'year': 2014},
'Inception': {'genre': 'Sci-Fi', 'director': 'Christopher Nolan', 'year': 2010},
'The Shawshank Redemption': {'genre': 'Drama', 'director': 'Frank Darabont', 'year': 1994}
}Quiz
1) 리스트 활용 퀴즈
# Q1. 다음 리스트에서 세 번째 요소를 출력하세요.
my_list = [10, 20, 30, 40, 50]
# A1
my_list = [10, 20, 30, 40, 50]
print(my_list[2])
# Q2. 다음 리스트에 60을 추가하세요.
my_list = [10, 20, 30, 40, 50]
# A2
my_list = [10, 20, 30, 40, 50]
my_list.append(60)
# Q3. 다음 리스트의 길이를 출력하세요.
my_list = ['apple', 'banana', 'orange', 'grape']
# A3
my_list = ['apple', 'banana', 'orange', 'grape']
print(len(my_list))
# Q4. 다음 리스트의 마지막 요소를 제거하세요.
my_list = ['car', 'bus', 'bike', 'train']
# A4
my_list = ['car', 'bus', 'bike', 'train']
del my_list[3]
# 답지 ★
my_list = ['car', 'bus', 'bike', 'train']
my_list.pop(-1)
'''
내가 푼 방식으로도 동일한 값이 나오긴 하지만
리스트가 아주 길어 마지막 요소의 인덱스가
매우 클 수 있으므로 답지처럼 푸는 게 좋겠음
'''
# Q5. 다음 리스트를 역순으로 출력하세요.
my_list = ['red', 'green', 'blue', 'yellow']
# A5
my_list = ['red', 'green', 'blue', 'yellow']
my_list.reverse()
print(my_list)
# 다른 풀이 ★
my_list = ['red', 'green', 'blue', 'yellow']
new_list = my_list[::-1]
print(new_list)2) 튜플 활용 퀴즈
# Q1. 다음 튜플에서 세 번째 요소를 출력하세요.
my_tuple = (10, 20, 30, 40, 50)
# A1
my_tuple = (10, 20, 30, 40, 50)
print(my_tuple[2])
# Q2. 다음 튜플의 길이를 출력하세요.
my_tuple = ('apple', 'banana', 'orange', 'grape')
# A2
my_tuple = ('apple', 'banana', 'orange', 'grape')
print(len(my_tuple))
# Q3. 다음 튜플을 역순으로 출력하세요.
my_tuple = ('red', 'green', 'blue', 'yellow')
# A3
my_tuple = ('red', 'green', 'blue', 'yellow')
reversed_tuple = my_tuple[::-1]
print(reversed_tuple)
# 다른 풀이 ★
my_tuple = ('red', 'green', 'blue', 'yellow')
reversed_tuple = tuple(reversed(my_tuple))
print(reversed_tuple)
# 다른 풀이(2)
my_tuple = ('red', 'green', 'blue', 'yellow')
my_tuple_list = list(my_tuple)
reversed_list = my_tuple_list[::-1]
reversed_tuple = tuple(reversed_list)
print(reversed_tuple)
# Q4. 다음 튜플을 리스트로 변환하세요.
my_tuple = (1, 2, 3, 4, 5)
# A4
my_tuple = (1, 2, 3, 4, 5)
list(my_tuple)
# Q5. 다음 튜플과 다른 튜플을 연결하여 새로운 튜플을 만드세요.
my_tuple1 = ('a', 'b', 'c')
my_tuple2 = ('d', 'e', 'f')
# A5
my_tuple1 = ('a', 'b', 'c')
my_tuple2 = ('d', 'e', 'f')
new_tuple = my_tuple1 + my_tuple23) 딕셔너리 활용 퀴즈
# Q1. 다음 딕셔너리에서 'name'에 해당하는 값을 출력하세요.
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
# A1
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
print(my_dict[name])
# Q2. 다음 딕셔너리에 'gender'를 추가하세요.
my_dict = {'name': 'Bob', 'age': 25, 'city': 'Los Angeles'}
# A2
my_dict = {'name': 'Bob', 'age': 25, 'city': 'Los Angeles'}
my_dict['gender'] = 'man'
# 답지
my_dict = {'name': 'Bob', 'age': 25, 'city': 'Los Angeles'}
my_dict['gender'] = '값은 아무거나'
print(my_dict)
'''
값이 잘 들어갔나 확인해보는 과정이 필요해요~
'''
# Q3. 다음 딕셔너리의 길이를 출력하세요.
my_dict = {'a': 100, 'b': 200, 'c': 300}
# A3
my_dict = {'a': 100, 'b': 200, 'c': 300}
print(len(my_dict))
# 답지
my_dict = {'a': 100, 'b': 200, 'c': 300}
dict_length = len(my_dict)
print(dict_length)
'''
왜 변수 선언해서 따로 넣었을까?
그냥도 나오는데...
'''
# Q4. 다음 딕셔너리에서 'age'를 제거하세요.
my_dict = {'name': 'Charlie', 'age': 35, 'city': 'Chicago'}
# A4
my_dict = {'name': 'Charlie', 'age': 35, 'city': 'Chicago'}
del my_dict['age']
2 B R 0 2 B