목표
- 데이터의 이상치와 결측치 개념 이해
- python 라이브러리를 사용해 이상치와 결측치를 처리하는 과정 학습
이상치, 결측치란?
- 정상범위를 벗어나는 데이터와, 누락된 데이터
반드시 이상치, 결측치 처리를 진행해야 하는 이유
- 이상치
- 전체 데이터 범위에서 벗어난 아주 작은 값이나 큰 값
- 결측치
- 데이터 수집 과정에서 측정되지 않거나 누락된 데이터
🡆 데이터를 분석을 위한 EDA 시 필수적으로 이상치, 결측치 처리가 진행되어야 함
평균이 가지는 오류
- 아래와 같이 만점이 100점인 국어 점수 데이터가 있다고 가정
| 과목 | 점수 | |
|---|---|---|
| 0 | 국어 | 50 |
| 1 | 국어 | 50 |
| 2 | 국어 | 50 |
| 3 | 국어 | 50 |
| 4 | 국어 | 1000 |
- 국어 점수의 평균?
- 50+50+50+50+1000/5 = 240점???
- 100 점을 넘길 수 없는 데이터에 1000 점이 기록되어 전체 데이터 분포를 정확하게 살펴볼 수 없음
- 50+50+50+50+1000/5 = 240점???
- 우리는 이러한 부분을 놓치지 않고, 다양한 방법을 통하여 해당 값을 처리해야 함!
🡆 Data EDA 과정 중 하나인 "Data Cleaning" 또는 "데이터 정제"
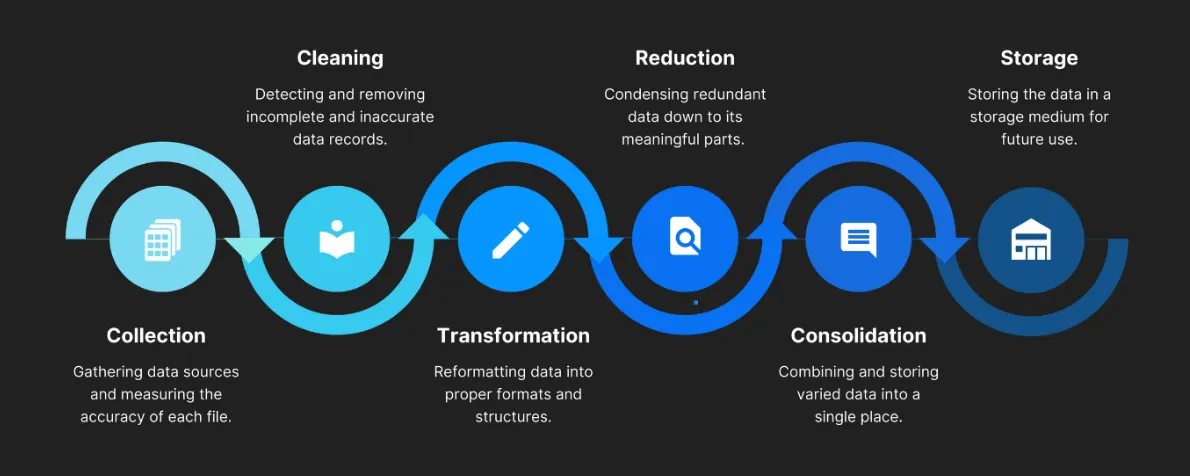
결측치 파헤치기
- 누락된 데이터를 어떻게 처리해야 할까?
결측치?
- 데이터의 누락된 부분을 의미
- 데이터는 가장 먼저 서버를 통해 수집되는데, 이렇게 서버실에 쌓인 데이터들은 아래와 같이 생겼음
→ raw data

- 해당 데이터들은 규칙에 맞게 CLUSTER에 할당되고, RDBMS를 통해 테이블로 저장되는데 이 과정에서 데이터가 누락될 수 있음
- 데이터는 가장 먼저 서버를 통해 수집되는데, 이렇게 서버실에 쌓인 데이터들은 아래와 같이 생겼음
- 참고: 데이터가 흘러가는 과정(Data Analytics Pipeline) ★
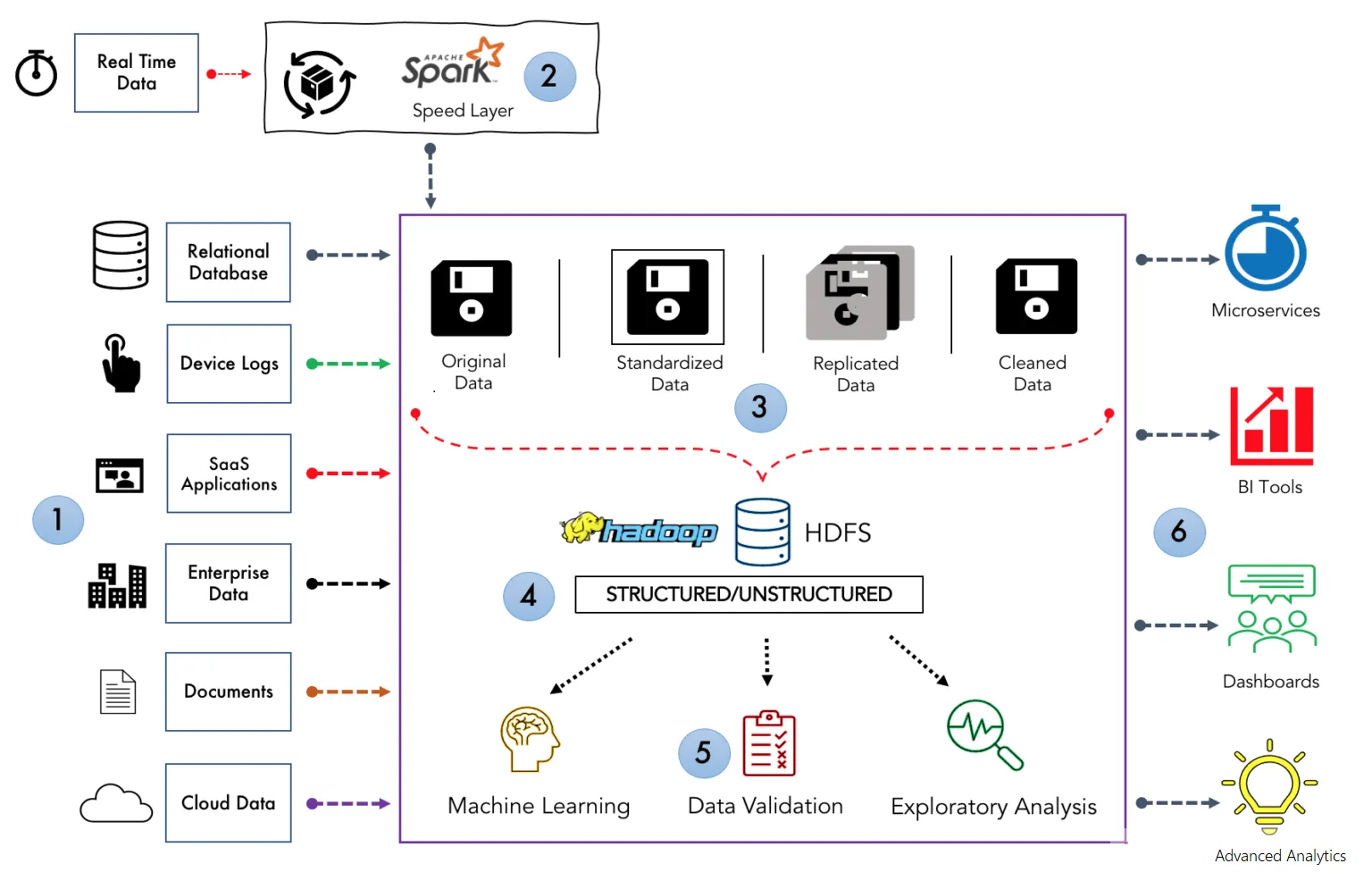
🡆 과정을 보면 누락이 발생할 수밖에 없다! 누락된 데이터들을 알맞게 처리하는 과정을 반드시 익혀야 함
결측치 처리: 제거
- 결측치가 존재하는 행 또는 열을 제거
# 컬럼별 결측치 식별
df3.isnull().sum()
# 결측치 제거1 - 열 제거하기
df3 = df3.drop('Unnamed: 4', axis=1)
# 결측치 제거2 - 결측치가 있는 행들을 모두 제거 ★
df3.dropna()
# 같은 표현
df3.dropna(axis=0, how='any')| 이름 | 나이 | LOCATION | CATEGORY |
|---|---|---|---|
| NULL | NULL | NULL | NULL |
| 농담곰 | 10 | 나고야 | 곰 |
| 퍼그씨 | 31 | 나고야 | 퍼그 |
| 두더지고로케 | NULL | 오사카 | 고로케 |
🡆 df3.dropna() 🡆
| 이름 | 나이 | LOCATION | CATEGORY |
|---|---|---|---|
| 농담곰 | 10 | 나고야 | 곰 |
| 퍼그씨 | 31 | 나고야 | 퍼그 |
# 결측치 제거3 - 결측치가 있는 열을 모두 제거
# 열로 제거하면 컬럼이 제거되는 현상이 발생하므로 매우 위험합니다.
# df3.dropna(axis=1)| 이름 | 나이 | LOCATION | CATEGORY |
|---|---|---|---|
| 농담곰 | 10 | 나고야 | 곰 |
| 퍼그씨 | 31 | 나고야 | 퍼그 |
| 두더지고로케 | NULL | 오사카 | 고로케 |
🡆 df3.dropna(axis=1) 🡆
|이름|LOCATION|CATEGORY|
|--|--|--|
|농담곰|나고야|곰|
|퍼그씨|나고야|퍼그|
|두더지고로케|오사카|고로케|
→ 나이 컬럼이 아예 없어짐
# 결측치 제거4 - 전체 행이 결측값인 경우만 삭제하고 싶은 경우
# how='all'을 사용해줍니다.
df3.dropna(how='all')| 이름 | 나이 | LOCATION | CATEGORY |
|---|---|---|---|
| NULL | NULL | NULL | NULL |
| 농담곰 | 10 | 나고야 | 곰 |
| 퍼그씨 | 31 | 나고야 | 퍼그 |
| 두더지고로케 | NULL | 오사카 | 고로케 |
🡆 df3.dropna() 🡆
| 이름 | 나이 | LOCATION | CATEGORY |
|---|---|---|---|
| 농담곰 | 10 | 나고야 | 곰 |
| 퍼그씨 | 31 | 나고야 | 퍼그 |
| 두더지고로케 | NULL | 오사카 | 고로케 |
# 결측치 제거5 - 결측치 제거 후 결과를 바로 저장하고 싶을 때
# inplace=True 조건을 넣어줍니다.
df3.dropna(inplace=True)
# drop 이후 결측치가 잘 제거되었는지 체크가 필요하겠죠?
df3.isnull().sum()결측치 처리: 대체
- 최빈값
- 범주형 변수(카테고리값)에 주로 사용
- 데이터가 가장 많이 도출된 값으로 대체
- mode() 메서드: 최빈값을 Series로 구함
- 중앙값, 평균값
- 수치형 변수에 주로 사용
- 결측치에 평균값이나 중앙값을 넣음
- 그 외에 행 기준으로 바로 위나 아래의 값을, 또는 group by 연산의 결과로 대체할 수 있음
# 결측치 대체: 최빈값
# mode 는 최빈값을 의미
# df3 의 Interaction type 컬럼을 fillna함수를 이용하여 채워주되, mode() 함수를 사용하여 최빈값으로 넣어줌
# mode 함수는 시리즈를 output으로 가집니다.
# 따라서,[0]을 통해 시리즈 중 단일값을 가져와야 합니다.
df3 = df3['Interaction type'].fillna(df3['Interaction type'].mode()[0])
# 결측치 대체: 평균값
df['sw'] = df['sw'].fillna(df['sw'].mean())
df.isnull().sum()
# 결측치 대체: 중간값
# inplace=True 로 하면 원본 데이터가 바뀌게 됩니다.
df['sw'] = df['sw'].fillna(df['sw'].median())
df.isnull().sum()
# 결측치 대체: 바로 위 값으로 대체
df['sw'] = df['sw'].fillna(method='ffill')
df.isnull().sum()
# 결측치 대체: 바로 아래 값으로 대체
df['sw'] = df['sw'].fillna(method='bfill')
#df.isnull().sum()
# 결측치 대체: group by 값으로 대체
# 사전 데이터 확인
df.groupby('Is Amazon Seller')['sw'].median()- group by한 데이터를 데이터프레임의 컬럼으로 추가하기 위해 transform 함수 사용
df['sw'] = df['sw'].fillna(df.groupby('Is Amazon Seller')['sw'].transform('median'))
df.isnull().sum()→ df['sw'].fillna(df.groupby(기준 컬럼)[계산할 컬럼].transform(계산 방식))
이상치 파헤치기
- 이상한 숫자를 그대로 버려야 할까요?
이상치?
- 이상치 탐색 및 처리에 앞서 생각해보기
- ‘이상하다’ 의 기준은 무엇일까?
- 선뜻 떠오르는 기준이 없는 게 당연함. 위의 질문에 정답이 없기 때문!
🡆 통용되는 몇 가지 방식을 사용하여 이상치 처리에 접근하기: 방식에 따라, 이상치의 개수가 달라질 수 있음
특히나 정답이 없는 데이터(비지도학습)를 가지고 데이터 분석을 진행할 때는 통계적 기법 + 데이터분석가의 주관이 적절히 조화를 이뤄야 합니다.
이상치 식별: Z-Score(StandardScaler) ★★
- "평균으로부터 얼마나 떨어져 있는가?"를 통한 이상치 판별
- 데이터의 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지하는 방법
- python의 scikit-learn 라이브러리가 지원함
정규분포?
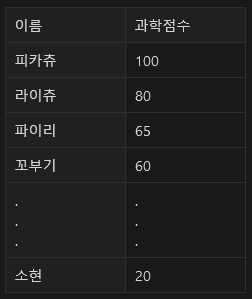
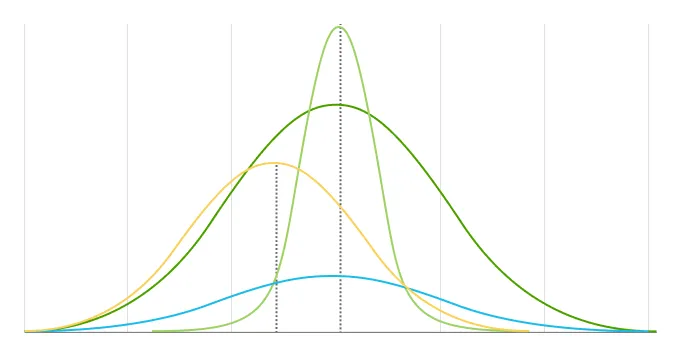
전국 학생 n명에 대한 과학시험 점수 데이터가 위와 같이 있다고 가정하고 이를 ‘점수가 나올 확률’에 대한 그래프로 그리게 되면 평균에서 가장 그 확률이 높고, 평균을 중심으로 멀어지면서 그 수가 적어지게 되는데요. 이와 같은 종 모양의 분포를 정규 분포라고 합니다.
→ 면적의 합은 1
- 각 데이터(행) 마다 Z-score를 구할 수 있음
- Z값은 X에서 평균을 뺀 데이터를 표준편차로 나눈 값
- 표준 점수라고 부름
- 표준 점수는 평균으로부터 얼마나 멀리 떨어져 있는지를 보여줌
- 일반적으로 -3에서 3 사이의 값을 가지고 있음
- ±3 이상이면 이상치로 간주
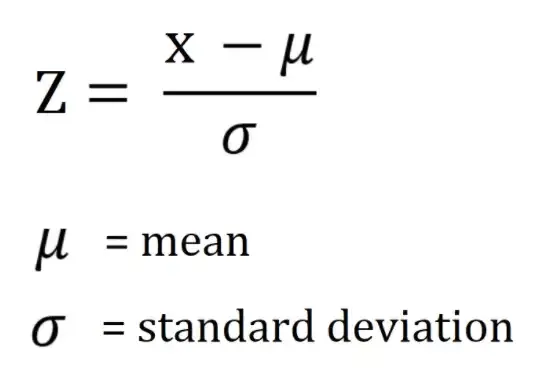
- Z-Score == 0
- 해당 데이터가 평균과 같음을 의미(=평균에서 떨어진 거리가 0)
- Z-Score > 0
- 해당 데이터가 평균보다 큼
- Z-Score가 1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 큰 값임을 의미
- Z-Score < 0
- 해당 데이터가 평균보다 작음
- Z-Score가 -1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 작음을 의미
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("p.csv")
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0.0).astype(int)
# z-score 를 적용할 컬럼 선정
df1 = df[['sw']]
# 표준화 진행
# 표준화 : 평균을 0으로, 표준 편차를 1로
# 데이터를 0을 중심으로 양쪽으로 데이터를 분포시키는 방법
# 표준화를 하게 되면 각 데이터들은 평균을 기준으로 얼마나 떨여져 있는지를 나타내는 값으로 변환
scale_df = StandardScaler().fit_transform(df1)
merge_df = pd.concat([df1, pd.DataFrame(StandardScaler().fit_transform(df1))],axis=1)
merge_df.columns = ['Shipping Weight', 'zscore']
# 이상치 감지
# Z-SCORE 기반, -3 보다 작거나 3보다 큰 경우를 이상치로 판별
mask = ((merge_df['zscore']<-3) | (merge_df['zscore']>3))
# mask 메소드 사용
strange_df = merge_df[mask]
# 총 55 건 탐지
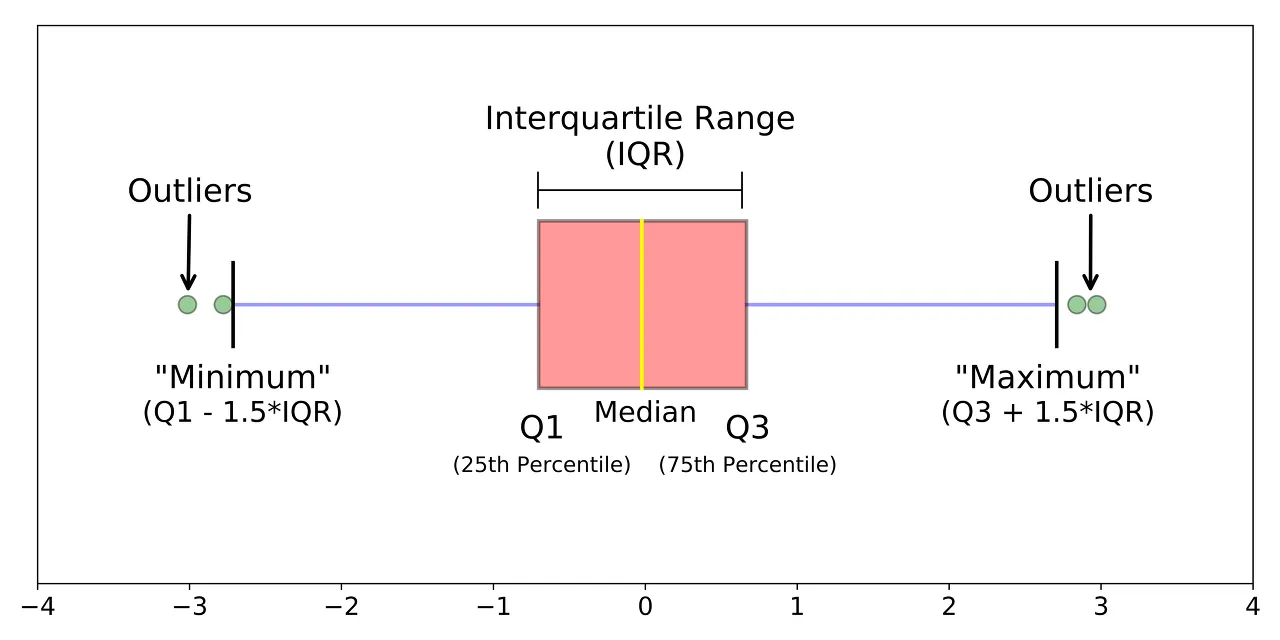
strange_df.count()이상치 식별: IQR(Interquartile Range) ★★
- 데이터의 분포가 정규 분포를 이루지 않을 때 사용
- 데이터의 25% 지점()과 75% 지점() 사이의 범위()를 사용: IQR == (제 3사분위 값) - (제 1사분위 값)
- 이를 벗어나는 값들은 모두 이상치로 간주
🡆 Box Plot!
: IQR를 그림으로 그린 것이 Box Plot → IQR 밖의 데이터 포인트는 이상치로 표시
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("p.csv")
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0.0).astype(int)
# 이상치를 감지할 컬럼 선정
df1 = df[['sw']]
# Q3, Q1, IQR 값 구하기
# 백분위수를 구해주는 quantile 함수를 적용하여 쉽게 구할 수 있음
# 데이터프레임 전체 혹은 특정 열에 대하여 모두 적용이 가능
q3 = df1['sw'].quantile(0.75)
q1 = df1['sw'].quantile(0.25)→ quantile(): 괄호 안의 숫자는 고정입니다.
iqr = q3 - q1
q3, q1, iqr
# 이상치 판별 및 dataframe 저장
# Q3 : 100개의 데이터로 가정 시, 25번째로 높은 값에 해당합니다.
# Q1 : 100개의 데이터로 가정 시, 75번째로 높은 값에 해당합니다.
# IQR : Q3 - Q1의 차이를 의미합니다.
# 이상치 : Q3 + 1.5 * IQR보다 높거나 Q1 - 1.5 * IQR보다 낮은 값을 의미
def is_outlier(df1):
score = df1['sw']
if score > 7 + (1.5 * 6) or score < 1 - (1.5 * 6):
return '이상치'
else:
return '이상치아님'→ if문 조건도 고정입니다.
# apply 함수를 통하여 각 값의 이상치 여부를 찾고 새로운 열에 결과 저장
df1['이상치여부'] = df1.apply(is_outlier, axis = 1) # axis = 1 지정 필수
# IQR 방식으로 구한 이상치 개수는 349 개
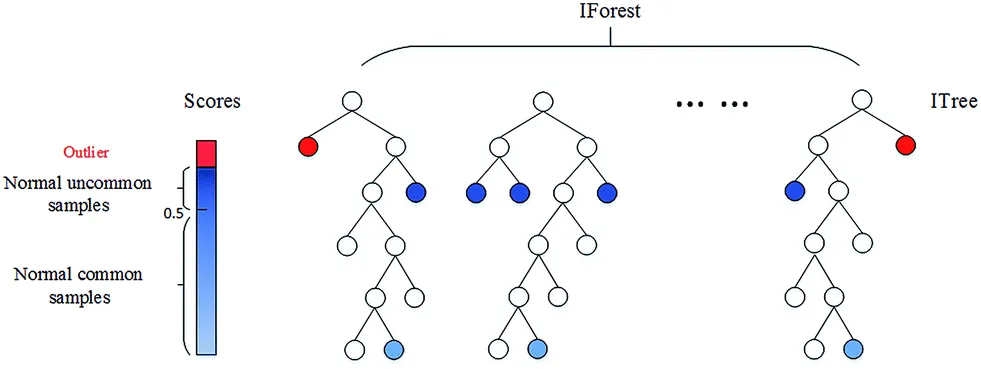
df1.groupby('이상치여부').count()이상치 식별: Isolation Forest
※ 개념만 익혀두기
- 머신러닝 기법 중 하나
- 컬럼 갯수가 많을 때 이상치를 판별하기 용이
- 데이터셋을 결정트리 형태로 표현
- 결정트리는 질문에 질문들이 꼬리를 물고 이어져, 이에 각 값은 매, 펭귄, 돌고래, 곰 중 하나에 배치됨
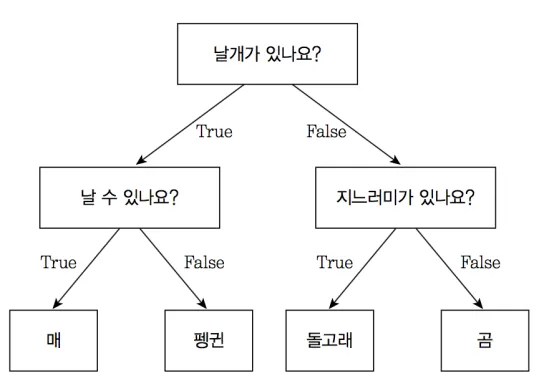
- 이상치의 경우, 이 어디에도 속하지 않을 확률이 높아 구분되지 않을 것 → 나무에서 자라지 않는 나뭇가지를 자르는 것과 같음
- 한 번 분리될 때 마다 경로 길이가 부여되며, 트리에서 몇 번을 분리해야 하는지 (데이터까지의 경로 길이)를 기준으로 데이터가 이상치인지 아닌지를 판단
- 결정트리는 질문에 질문들이 꼬리를 물고 이어져, 이에 각 값은 매, 펭귄, 돌고래, 곰 중 하나에 배치됨
- 즉, 다른 관측치에 비해 짧은 경로 길이를 가진 데이터를 이상치라 판단함
- 경로 길이로 점수는 0 에서 1 사이로 산출
- 결과가 1 에 가까울수록 이상치로 간주
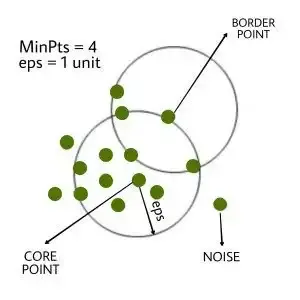
이상치 식별: DBScan
※ 개념만 익혀두기
- 밀도 기반의 클러스터링 알고리즘으로 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지
- 복잡한 구조의 데이터에서 이상치를 판별하는 데 유용
- 각 데이터의 밀도를 기반으로 군집을 형성시키고, 설정된 거리 내에 설정된 최소 개수의 다른 포인트가 있을 경우, 해당 포인트는 핵심 포인트로 간주
- 핵심 포인트들이 서로 연결되어 군집을 형성하며, 이와 연결되지 않은 포인트는 이상치로 분류
- 주로 지리 데이터 분석, 이미지 데이터 분석의 이상치 기법으로 사용
이상치 처리
제거 ★
- 이상치가 데이터 오류나 적절하지 않은 값일 경우 제거(가장 많이 사용)
- 하지만 이 방식은 데이터의 표본 크기를 줄일 수 있다는 점을 꼭 기억
대체
- 로그 변환
- 데이터에 로그 변환을 적용하여 극단적인 값을 완화
- 상한값과 하한값
- 하한값과 상한값을 결정한 후 하한값보다 적으면 하한값으로 대체, 상한값보다 크면 상한값으로 대체
- 평균 절대 편차
- 중위수로부터 n편차 큰 값을 대체
- 자주 사용하지 않음
분리 ★
- 이상치를 별도의 그룹으로 분리하여 분석할 수 있음
- 이상치가 데이터에 중요한 정보를 포함하고 있을 때 유용
- 즉, 새로운 데이터프레임을 생성하여 이상치를 저장해둔다고 이해해주세요!
