1. 결측치 파헤치기
1-1. 라이브러리 import
import pandas as pd
import numpy as np
import time
from PIL import Image # 사진 첨부하려 할 때
import warnings
# 오류 경고 무시하기
warnings.filterwarnings(action='ignore')1-2. CSV 파일을 통한 테이블 LOAD
- pandas 라이브러리를 활용한 csv 파일 읽기
# pandas 라이브러리를 활용한 csv 파일 읽기
df = pd.read_csv("product_details.csv") # product_details.csv
df2 = pd.read_csv("customer_details.csv") # customer_details.csv
df3 = pd.read_csv("E-commerece sales data 2024.csv") # E-commerece sales data 2024.csv1-3. 결측치 제거
# 전체 데이터셋 확인
df3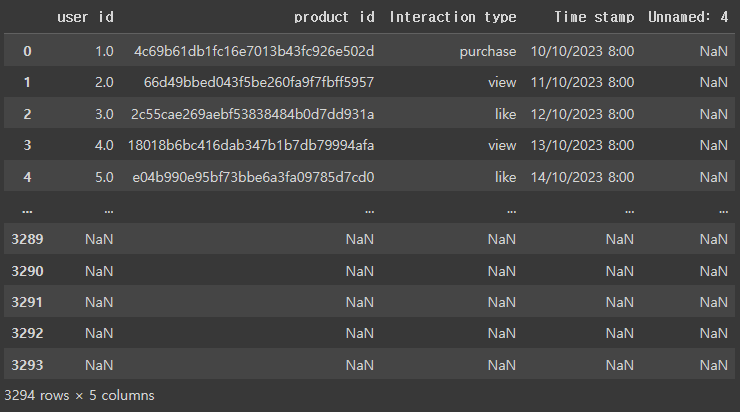
- Unnamed: 4 컬럼의 모든 값이 NaN인 것을 확인할 수 있음
- 필요 없는 열이니 제거합시다!
함수:
함수명()으로 호출
메서드:.메서드명()으로 호출
# 결측치 제거1 - 열 제거하기
df3 = df3.drop('Unnamed: 4', axis=1)
#컬럼별 결측치 확인
df3.isnull().sum()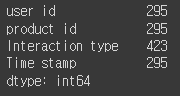
- 파이썬은 항상 "선언"(=)을 해 주세요!
.drop()으로 계산된 결과를 계속 담아줘야 함
# 결측치 제거2 -결측치가 있는 행들은 모두 제거
df3.dropna(inplace=True)
df3.isnull().sum()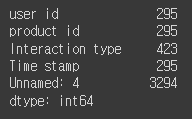
.dropna()로 하면 원본 데이터는 안 변함- 따라서 계산 결과를 따로 선언해서 담아줘야 함
1-4. 결측치 대체: 최빈값
# 데이터 블러오기
df3 = pd.read_csv("E-commerece sales data 2024.csv") # E-commerece sales data 2024.csv
# Interaction type 의 결측치: 423개
df3.isnull().sum()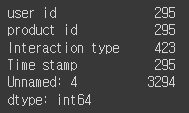
# 결측치는 카운트 되지 않습니다.
df3.groupby('Interaction type').count()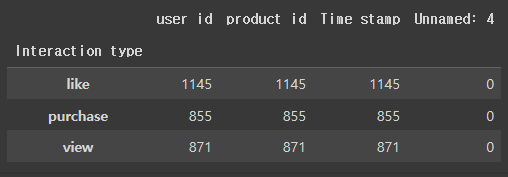
- Q. 현업에서 결측치를 대체할지 제거할지 둘 중에 결정하는 기준은 무엇인가요?
- A. Case By Case
# 결측치가 있는 Interaction type 컬럼을 최빈값으로 대체하기 위해, 해당 컬럼의 최빈값을 구함
df3['Interaction type'].mode()
- mode의 output은 Series인 점에 유의
- mode() 함수는 시리즐을 반환
- Q. mode를 써서 2개 이상의 값이 나왔다고 가정했을 때 첫 번째 값을 써야 하는 이유가 있을까요?
- A. mode만 가지고는 판단할 수 없습니다. groupby와 window 함수를 써서 결과를 보고 판단해야 합니다.
- groupby를 통한 검증
- A. mode만 가지고는 판단할 수 없습니다. groupby와 window 함수를 써서 결과를 보고 판단해야 합니다.
# mode 는 최빈값을 의미
# df3 의 Interaction type 컬럼을 fillna함수를 이용하여 채워주되, mode() 함수를 사용하여 최빈값으로 넣어줌
# mode 함수는 시리즈를 output으로 가집니다.
# 따라서, [0]을 통해 시리즈 중 단일값을 가져와야 합니다.
df3 = df3['Interaction type'].fillna(df3['Interaction type'].mode()[0])
# 연산 후 인덱스 재설정
df3= df3.reset_index()
# 최빈값으로 대체된 데이터프레임 확인
df3.groupby('Interaction type').count()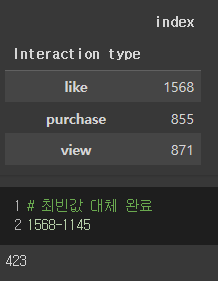
1-5. 결측치 대체: 평균, 중앙값
# 데이터 불러오기
df = pd.read_csv("product_details.csv") # product_details.csv
# Shipping Weight 의 경우, 1138 개의 결측치가 있습니다.
# 13번째 인덱스, int 타입입니다.
df.isnull().sum()[13],df.isnull().sum()[13].dtype
# 실행 결과: (1138, dtype('int64'))# str.split 을 통해 문자열을 분리하고, 그 값 중 첫번째 인덱스를 가져옴
# df['sw'] = df['Shipping Weight'].str.split().str[1]과 비교해보세요!
df['sw'] = df['Shipping Weight'].str.split().str[0]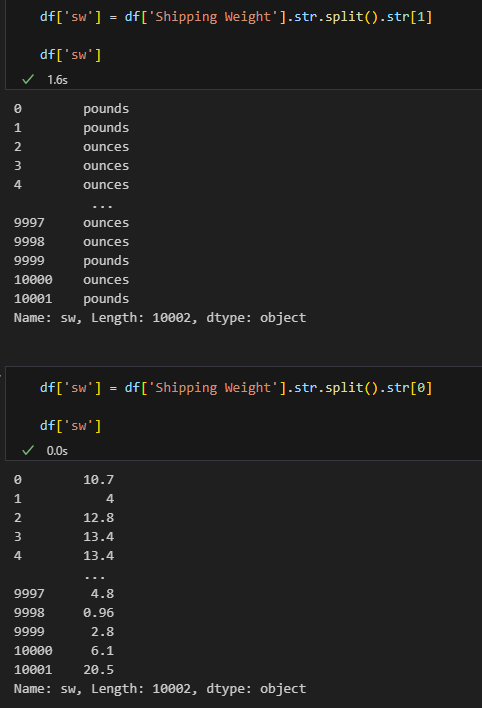
# string to float, 에러무시
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce')
# 평균값 대체
# inplace=True 로 하면 원본 데이터가 바뀌게 됩니다.
df['sw'] = df['sw'].fillna(df['sw'].mean())
df.isnull().sum()
# 중간값 대체
# inplace=True 로 하면 원본 데이터가 바뀌게 됩니다.
df['sw'] = df['sw'].fillna(df['sw'].median())
df.isnull().sum()
# 바로 위 값으로 대체
df['sw'] = df['sw'].fillna(method='ffill')
df.isnull().sum()
# 바로 아래 값으로 대체
df['sw'] = df['sw'].fillna(method='bfill')
#df.isnull().sum()1-6. 결측치 대체: group by
# 데이터 불러오기
df = pd.read_csv("product_details.csv") # product_details.csv
df['sw'] = df['Shipping Weight'].str.split().str[0]
# string to float, 에러무시
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce')
# group by 값으로 채워넣기 - 사전 데이터 확인
df.groupby('Is Amazon Seller')['sw'].median()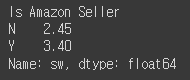
#group by한 데이터를 데이터프레임의 컬럼으로 추가하기 위해
#transform 함수 사용
df['sw'] = df['sw'].fillna(df.groupby('Is Amazon Seller')['sw'].transform('median'))
df.isnull().sum()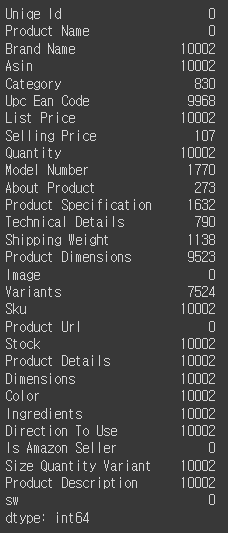
-
.transform()- 데이터프레임에서 특정한 열의 값을 수정하거나, 추가할 때 사용
- 특질들을 추출하는 함수
- 기존에 있던 특질로부터 새로운 특질을 추출할 때 사용할 수 있음
- groupby()와 merge()를 사용해서 동일한 기능을 수행할 수 있는데, 이것과 transform() 함수를 사용하는게 얼마나 차이가 나는지 이해할 것
- apply() 와 비교해보기
-
Q. groupby, transform을 써서 결측치를 대체하는 구문을 어떤 경우에 사용하는지 감이 안 오는데 예제를 하나 더 들어주실 수 있나요?
- A. 다른 컬럼을 넣어보세요~
첫 번재 방법: 데이터의 요약치를 계산하기 위해서 groupby() 함수를 사용한 뒤, 다시 이 데이터를 merge() 함수로 본래 형태로 변환
위의 과정을 통하게 되면 차원이 바뀜
즉, 데이터의 사이즈가 바뀌고, 이것을 다시 본래 데이터의 형태로 바꾸어 줘야 함 → merge()
원하는 결과는 얻었지만, 뭔가 번거로운 과정들이 많음
🡆 판다스에 있는 transform() 함수를 사용하게 되면 한번에 이러한 과정이 가능
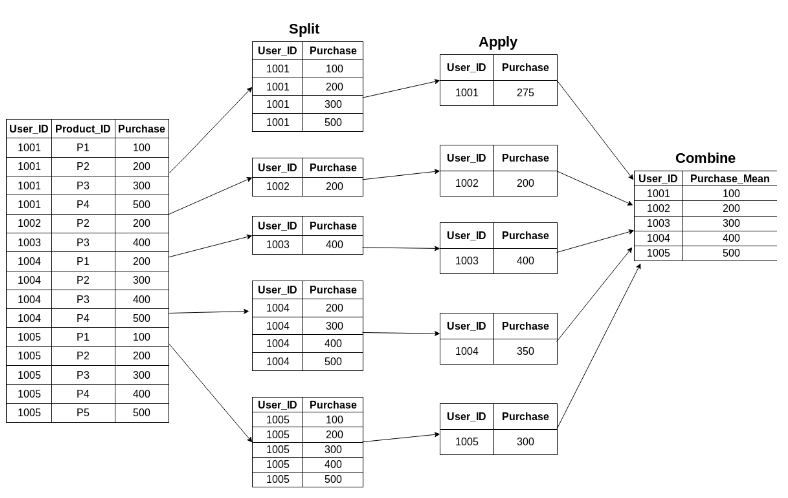
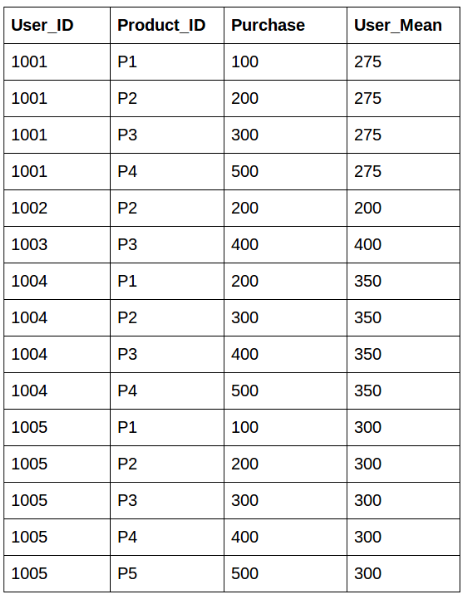
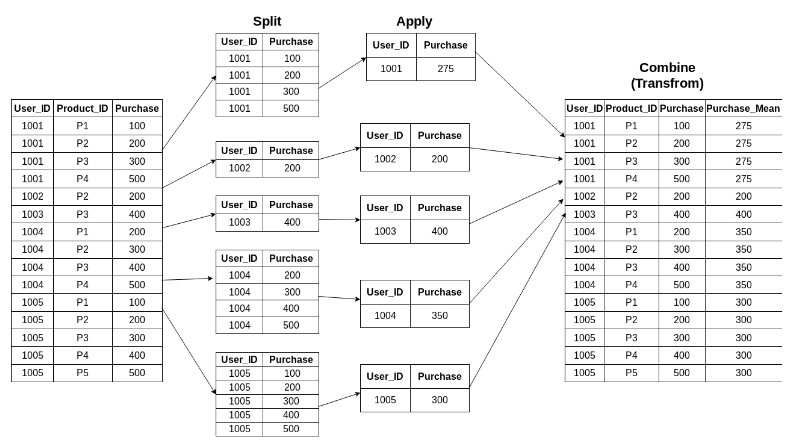
apply() VS. transform()
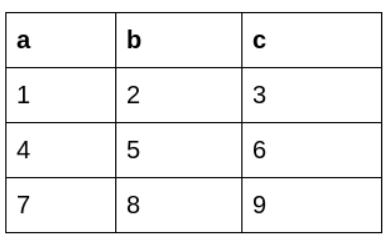
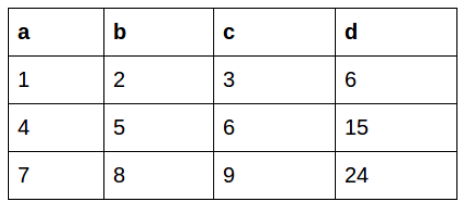
아래와 같은 데이터 프레임을 이용하여 새로운 열을 만드는 것을 생각해보기
apply() 함수를 사용하게 되면, 데이터 프레임 전체 열의 값들을 조작하면서 값을 계산할 수 있다. 즉, d를 계산하기 위해서 a, b, c 열의 값을 모두 계산할 수 있다.
df['d'] = df.apply(lambda row: row.a + row.b + row.c, axis=1)
하지만, transform() 함수를 사용하게 되면? 사실, 이러한 계산은 transform() 함수를 사용해서는 불가능하다. transform() 함수의 경우, 하나의 열 또는 행을 조작하는 것이지, 전체 데이터 프레임을 한번에 연산할 수 없기 때문이다.
따라서 파이썬 프로그래밍을 할 때, 이러한 상황을 잘 기억해두었다가 apply()를 사용해야 하는 순간인지, transform()을 사용해야 하는 순간인지에 맞게 적절한 함수를 사용하도록 하자.
df['sw'].mode()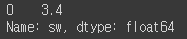
df.groupby(['sw'])['Uniqe Id'].count().sort_values(ascending=False).reset_index()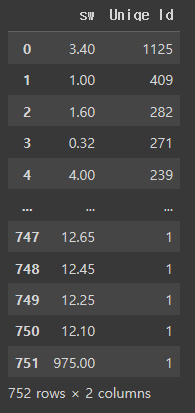
2. 이상치 파헤치기
2-1. 이상치 탐지: Z-SCORE
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("product_details.csv") # product_details.csv
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0)
# z-score 를 적용할 컬럼 선정
df1 = df[['sw']]
df1
from sklearn.preprocessing import StandardScaler
# 표준화 진행
# 표준화 : 평균을 0으로, 표준 편차를 1로
# 데이터를 0을 중심으로 양쪽으로 데이터를 분포시키는 방법
# 표준화를 하게 되면 각 데이터들은 평균을 기준으로 얼마나 떨여져 있는지를 나타내는 값으로 변환
scale_df = StandardScaler().fit_transform(df1)
scale_df
# array 형태로 반환된 것을 dataframe 으로 받아줍니다.
scale_df = pd.DataFrame(scale_df)
# 기존 raw 값과 표준화 이후 데이터를 비교하기 위해 merge 진행
merge_df = pd.concat([df1, scale_df],axis=1)
# 표준화 된 데이터를 확인할 할 수 있게 되었습니다.
merge_df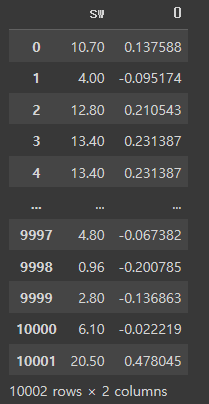
merge_df.columns = ['Shipping Weight', 'zscore']
# 이상치 감지
# Z-SCORE 기반, -3 보다 작거나 3보다 큰 경우를 이상치로 판별
mask = ((merge_df['zscore']<-3) | (merge_df['zscore']>3))
# mask 메소드 사용
strange_df = merge_df[mask]
strange_df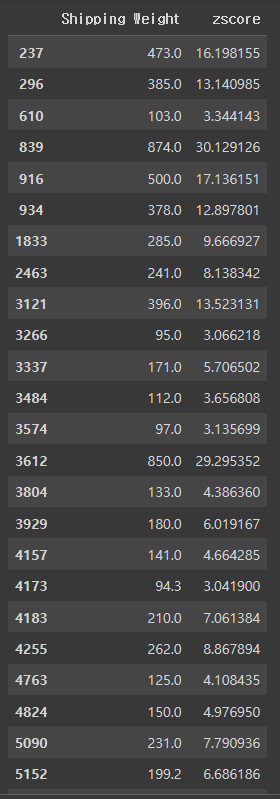
# 총 55 건 탐지
strange_df.count()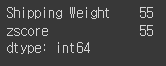
2-2. 이상치 탐지: IQR
# df 의 Shipping Weight를 기준으로 다양한 이상치 감지 기법을 적용해 보겠습니다.
df = pd.read_csv("product_details.csv") # product_details.csv
# string -> float -> int
df['sw'] = df['Shipping Weight'].str.split().str[0]
df['sw'] = pd.to_numeric(df['sw'] , errors='coerce').fillna(0).astype(int)
# 이상치를 감지할 컬럼 선정
df1 = df[['sw']]
# Q3, Q1, IQR 값 구하기
# 백분위수를 구해주는 quantile 함수를 적용하여 쉽게 구할 수 있음
# 데이터프레임 전체 혹은 특정 열에 대하여 모두 적용이 가능
q3 = df1['sw'].quantile(0.75)
q1 = df1['sw'].quantile(0.25)
iqr = q3 - q1
q3, q1, iqr
# 실행 결과: (7.0, 1.0, 6.0)# 이상치 판별 및 dataframe 저장
# Q3 : 100개의 데이터로 가정 시, 25번째로 높은 값에 해당합니다.
# Q1 : 100개의 데이터로 가정 시, 75번째로 높은 값에 해당합니다.
# IQR : Q3 - Q1의 차이를 의미합니다.
# 이상치 : Q3 + 1.5 * IQR보다 높거나 Q1 - 1.5 * IQR보다 낮은 값을 의미
def is_outlier(df1):
score = df1['sw']
if score > 7 + (1.5 * 6) or score < 1 - (1.5 * 6):
return '이상치'
else:
return '이상치아님'
# apply 함수를 통하여 각 값의 이상치 여부를 찾고 새로운 열에 결과 저장
df1['이상치여부'] = df1.apply(is_outlier, axis = 1) # axis = 1 지정 필수
df1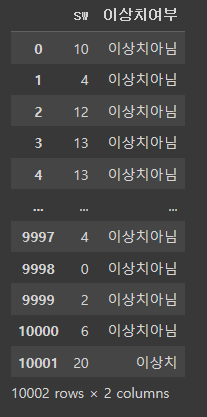
# IQR 방식으로 구한 이상치 개수는 349 개
df1.groupby('이상치여부').count()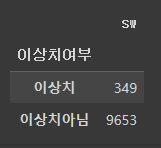
- Q. 얼마나 정규분포에 가까운지를 판단할 수 있는 방법은 없나요?
- A. 통계 시간에 확인 가능
