목표
- python 라이브러리를 활용한 기본적인 데이터 시각화 진행
- 나만의 그래프 그리기
1. 기본 그래프 그리기
.plot.bar()붙여 바로 그래프 그리기
그래프 한눈에 보기
데이터 분석가에게 시각화란?
- 데이터를 한 눈에 이해할 수 있도록 표나 차트로 정리하는 작업
- 데이터 분석 결과를 시각적으로 표현하고 의사소통 하는 것
- 데이터 시각화는 ‘도구’가 아닌 ‘전략’
- 옛날에는 그냥 현황 확인하는 도구로만 썼음
- 지금은 전략임!
- 대시 보드를 데이터 분석가가 설계(디자인)하기도 함(보통은 Tableau에서 만듦)
- 데이터 분석가가 지표 추출뿐만 아니라 지표 개발까지 함
- 지표를 대시보드 중에 어디에 넣을지 고민해야 함
- 데이터 내 이상치, 패턴 등 주요 정보를 신속하고 용이하게 발견할 수 있음
- 관련 부서에 자료를 공유할 때 텍스트로 전달하는 것보다 사용자의 흥미를 유발할 수 있음
🡆 데이터 분석가의 중요한 역량 중 한 부문!
시각화 예시
python에서 그래프 그리기
- python 은 SQL 과 다르게 ‘라이브러리’ 의 개념이 있음
- 즉, 원하는 데이터를 추출한 뒤 바로 시각화(
.plot) 진행 가능!
- 즉, 원하는 데이터를 추출한 뒤 바로 시각화(
유용한 시각화 라이브러리
| 라이브러리 | 특징 |
|---|---|
| Matplotlib | Python에서 가장 많이 쓰는 라이브러리 |
| 라인, 바, 산점도, 히스토그램, 파이 차트 등 지원 | |
| 제목, 레이블, 색상 지원 | |
| 그래프를 PNG, PDF, SVG 등의 형식으로 저장 지원 | |
| seaborn | matplotlib 기반의 시각화 라이브러리 |
| 통계 그래픽을 그리기 위한 고급 인터페이스를 제공 | |
| 라인, 바, 산점도, 히스토그램, 박스, 커널 밀도, 조인트, 관계, 히트맵 등 지원 | |
| Altair | Python에서 사용되는 선언적인 통계 데이터 시각화 라이브러리 |
| 문법이 간단하다는 특징을 가지고 있음 | |
| 인터렉티브 그래프 지원 | |
| 필수요소 - 데이터, 마크, 인코딩, 인터렉티브 여부(기본값 off) | |
| 추가요소 - 트랜스폼, 결합, 스케일, 가이드 | |
| PyGWalker | Kanaries에서 개발한 태블로 스타일의 파이썬 패키지 |
| Pandas/Polars/Modin 데이터 프레임을 지원 | |
| Python 코드 없이 데이터 시각화 가능 | |
| 바, 박스, 라인, 산점도와 같이 기본적인 시각화 가능 | |
| data load 후 드래그 앤 드랍으로 간단하게 EDA 가능 | |
| Streamlit 웹 프레임워크와 호환성이 좋음 | |
| plotly | 약 40가지의 차트가 내장되어 있는 라이브러리 |
| 다양한 소프트웨어와 호환성이 좋다는 특징이 있음 | |
| 인터렉티브 그래프 지원 |
※ Matplotlib: 시각화 근본 라이브러리 → seaborn, Altair 모두 Matplotlib에서 쓰는 문법 그대로 사용(문법이 통일되어 있다.)
※ PygWalker: Tableau처럼 쓸 수 있음
- Kanaries docs
- Field List에서 원하는 것 골라 드래그&드롭 → 커스터마이즈 된 그래프 자동 생성
(1) 기본 내장함수를 이용한 그래프 그리기
- groupby 연산 이후
.plot을 통해 간단히 그래프 구현
# 기본 그래프 그리기
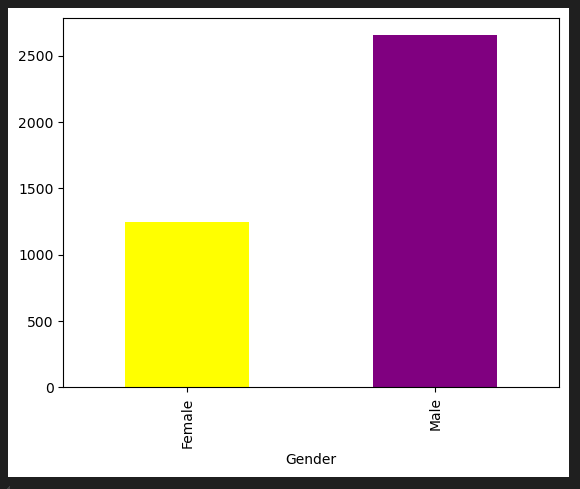
df2.groupby('Gender')['Customer ID'].count().plot.bar()
# 컬러 지정
df2.groupby('Gender')['Customer ID'].count().plot.bar(color=['yellow','purple'])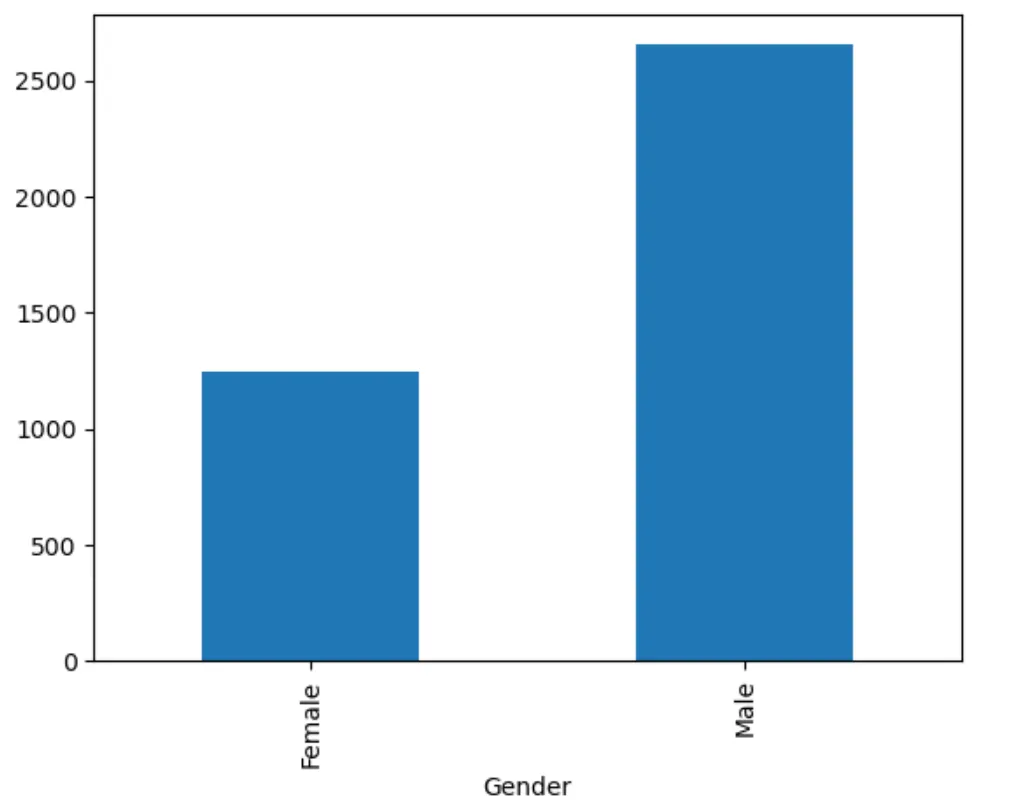
2. 다양한 그래프 그리기
Matplotlib
- 설치:
pip install matplotlib - python 시각화 라이브러리 중 가장 많은 기능을 지원하는 라이브러리
- 다른 라이브러리 개발에 토대가 됨
Matplotlib 라이브러리가 핸들링 할 수 있는 영역
- Line(line plot)
- Markers(scatter plot)
- 동그라미로 표현할 수도 있고 별, 세모, 네모 등 다양한 형태로 표현 가능
- 축 지정
- Axes
- Spines
- Y axis label
- X axis label
- Figure
- Major tick
- Major tick label
- Minor tick
- minor tick label
- Grid
- Legend(범례)
- Title
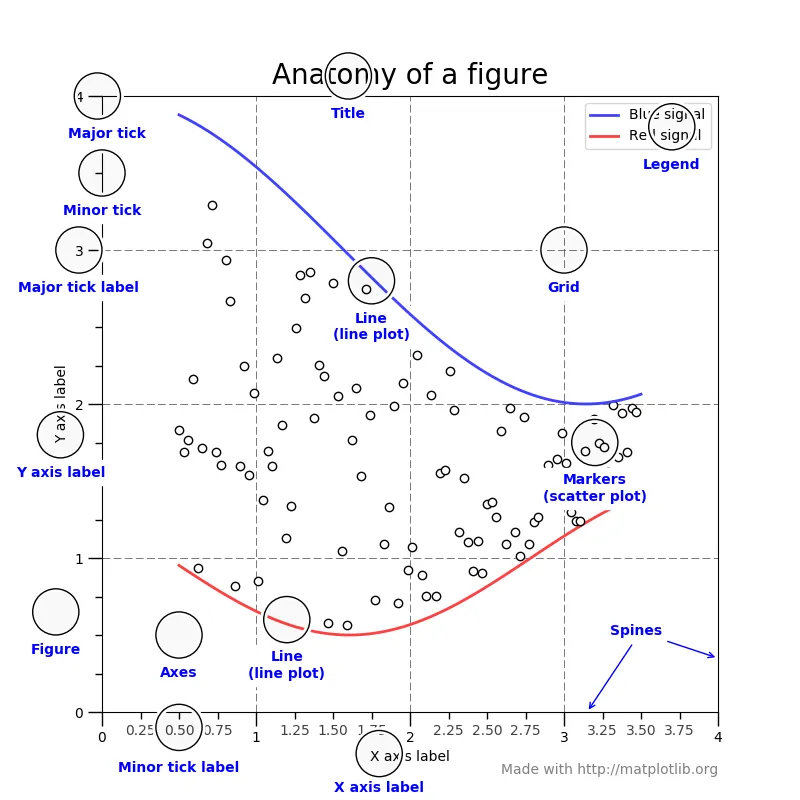
주요 지원 옵션
| 기능 | 예제 |
|---|---|
| 타이틀 & font 설정 | plt.title('그래프제목', fontsize=20) |
| 축 이름 지정 | plt.xlabel('X축', fontsize=20) |
plt.ylabel('Y축', fontsize=20) | |
| 눈금레이블 회전 | plt.xticks(rotation=90) |
plt.yticks(rotation=30) | |
| grid 옵션 추가 | plt.grid() |
| 범례 추가 | plt.legend(['Mouse', 'Cat']) |
| 그래프 색상 변경 | plt.bar(x, y, width=0.7, color="blue") |
| x,y 축 구간 지정 | plt.xlim(2,3) |
plt.ylim(5,20) |
여러 개의 그래프를 동시에 그리기
| 구분 | 상세 |
|---|---|
| 개념 | matplotlib.pyplot 내 subplot 모듈을 사용하면 여러 개의 그래프를 동시에 시각화할 수 있음 |
| 전체 도화지를 그려주고(figure) 위치에 각 그래프들을 배치하는 개념 | |
| 구문 | 총 행(row)의 개수와 열(column) 개수를 각각 입력하고, 시각화할 그래프마다 그래프 위치를 지정 |
| 예제 | 총 4개의 구역 만들기: fig,ax=plt.subplots(2,2) |
| ㅁㅁ | |
| ㅁㅁ |
seaborn
- 설치:
pip install seaborn - Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지
- 기본적인 핸들링은 matplotlib 를 통해 설정 가능
- 막대, 라인, 파이차트 외 아래와 같은 그래프를 지원(전체 중 일부만 소개)
| PLOT 종류 | 활용 예 |
|---|---|
| distplot | 분포 그래프로, 평균, 중위수, 범위, 분산, 편차 등을 이해할 수 있음. 범위에 포함화는 관측수를 세어 표시 |
| countplot | 범주형 변수의 발생 횟수를 세어주는 그래프. 해당 그래프를 사용하면, Group by 연산이 필요하지 않음 |
| boxplot | 최대, 최소, 평균, 사분위수를 확인할 수 있음. 지난 시간에 배운 IQR 방식을 그리면 box plot |
| jointplot | 두 변수에 대한 displot의 조합. 두 변수에 분포에 대한 분석이 가능함 |
| kdeplot | 하나 혹은 두 개의 변수에 대한 밀도 기반 분포 그래프 |
| violinplot | box plot에서 분포에 대한 정보가 추가된 형태 |
| Heat Map | 일반적으로 연속형 변수의 상관관계를 파악하기 위한 그래프 (pearson) (범주형도 가능하나 자주 사용하지 않습니다. -Cramer's V) |
※ 상관관계
- A가 있을 때 B도 있을 확률
- "치긴과 맥주의 상관 관계는 0.8이다."
- 현업에서는 0.7 넘기도 쉽지 않다고 함
- "치긴과 맥주의 상관 관계는 0.8이다."
- -1부터 1까지의 값을 가짐
- 1에 가깝다 == 양의 상관 관계 == 비례
- -1에 가깝다 == 음의 상관 관계 == 반비례
- 0에 가깝다 == 관련성이 없다
Altair: 인터렉티브(동적) 그래프
- 설치: pip install altair
- 다른 라이브러리와 다르게, 문법적인 요소가 강한 라이브러리
- 지원되는 함수에 따라 값을 넣어주면 그래프가 도출되는 형식으로 작동
- Python 3.6 이상 지원
- Altair 라이브러리를 통한 시각화의 장점은, 동적(움직이는) 그래프의 구현
- 현업에서 자주 사용하는 라이브러리는 아니나, 익혀두면 ++
주요 문법
| 요인 | 설명 |
|---|---|
| 데이터 | Pandas Dataframe 지정 |
| 마크 | Plot 종류 지정 |
| 인코딩 | x축, y축 등 변수 지정 |
| 인터렉티브(옵션) | 인터렉티브 설정 여부(명시해주지 않으면 off상태입니다.) |
| 트랜스폼(옵션) | 데이터 전처리 여부 지정 |
| 결합(옵션) | 여러 차트의 결합여부 지정(예제에서 함께 살펴보겠습니다.) |
| 스케일 & 가이드(옵션) | x,y 축 범위, 범례 지정 |
3. 그 외
- pyg Walker를 통해 드래그 앤 드랍으로!
pygWalker - 편리한 EDA
- 간단한 설치만으로도 EDA가 가능
- 간편하게 그린 그래프를 PNG FILE 로 내보내기가 가능
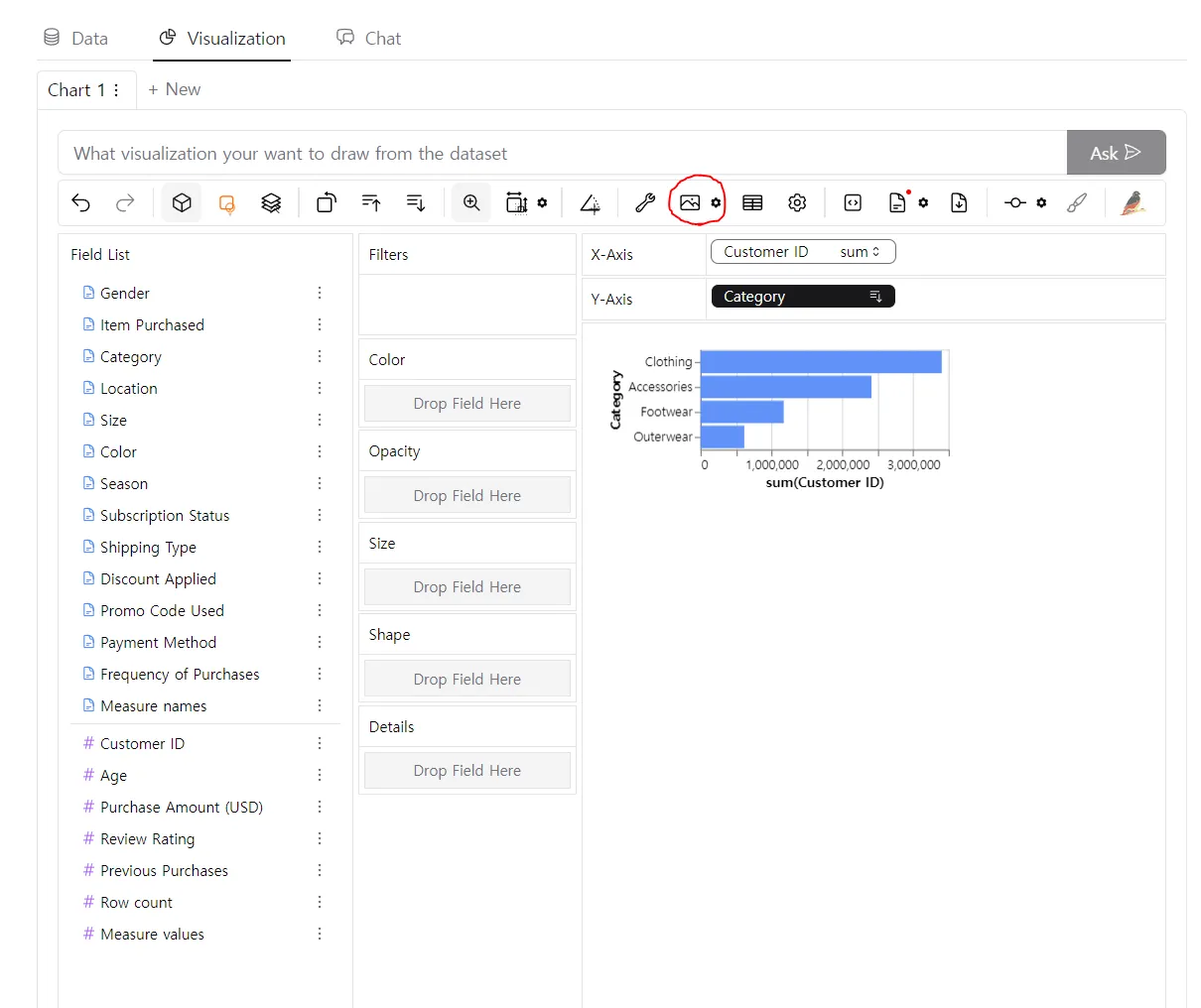
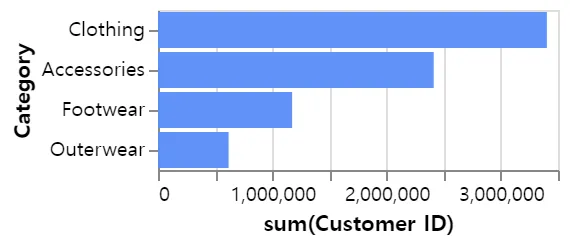
실습
1. 데이터 시각화: Matplotlib
1-1. 라이브러리 input
import pandas as pd
import numpy as np
import time
from PIL import Image
import altair as alt
import seaborn as sns
import matplotlib.pyplot as plt
# import datapane as dp → chart 및 table 등을 조합하여 report.html 파일을 작성할 수 있게 해 주는 라이브러리
# seaborn 팔레트 설정
palette = sns.color_palette("pastel")
import warnings
# 오류 경고 무시하기
warnings.filterwarnings(action='ignore')※ seabone palette

1-2. CSV 파일을 통한 테이블 LOAD
# pandas 라이브러리를 활용한 csv 파일 읽기
df = pd.read_csv("product_details.csv") # product_details.csv
df2 = pd.read_csv("customer_details.csv") # customer_details.csv
df3 = pd.read_csv("E-commerece sales data 2024.csv") # E-commerece sales data 2024.csv1-3. 기본 그래프 그리기
# 결측치 제거하기
df2 = df2.dropna()
df2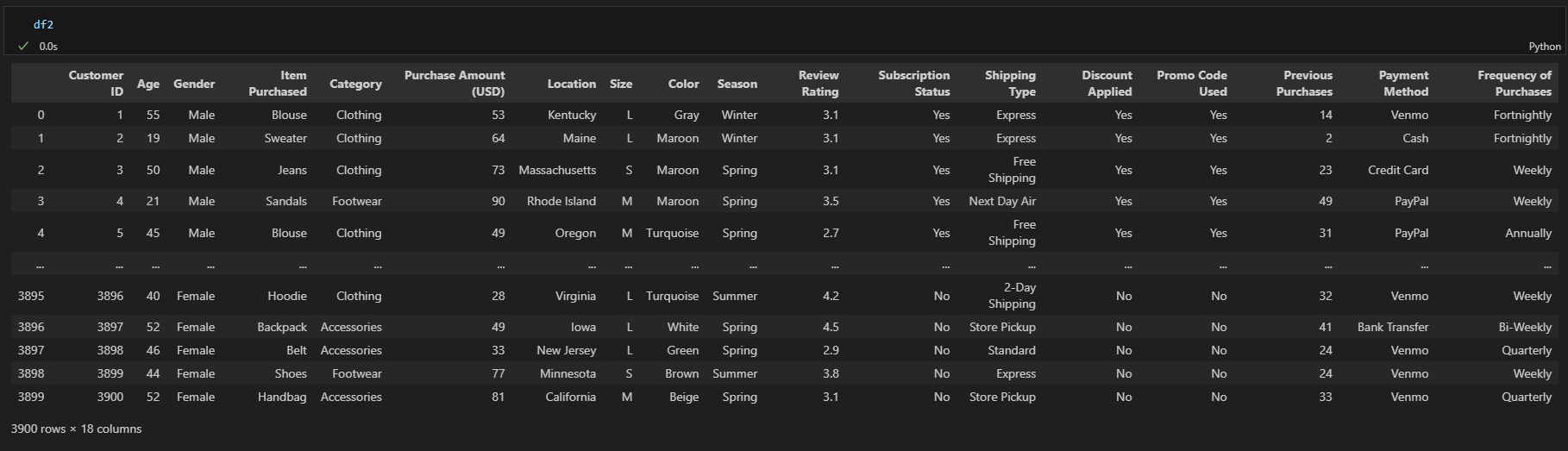
# python 내장함수 plot 사용하기
# 성별 유저수 막대그래프
# 막대그래프
df2.groupby('Gender')['Customer ID'].count().plot.bar(color=['yellow','green'])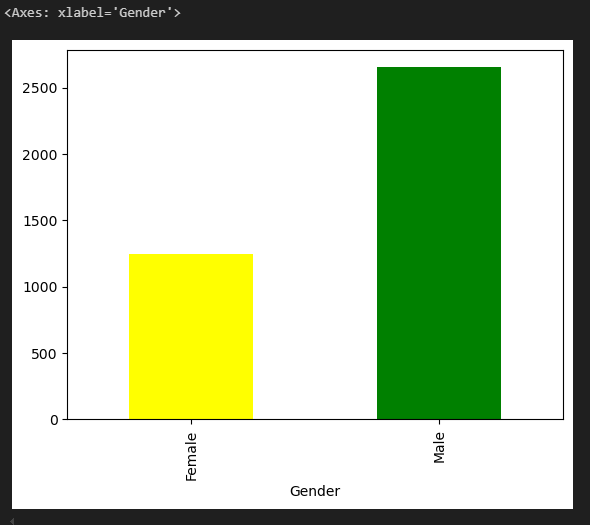
1-4. 라인그래프 그리기
# dataframe 컬럼 확인하기
df2.columns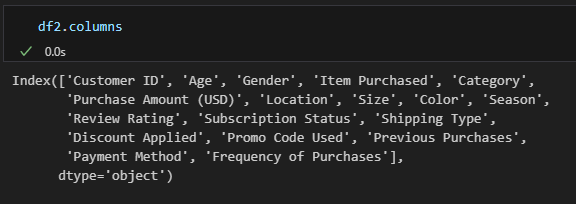
1-1. 라이브러리 input
1-1. 라이브러리 input
1-1. 라이브러리 input
1-1. 라이브러리 input
1-1. 라이브러리 input
1-1. 라이브러리 input
1-1. 라이브러리 input
2. 데이터 시각화: seaborn
2-1. 바 그래프 그리기
2-2. 바 그래프 그리기 (2)
2-3. 카운트 그래프 그리기
2-4. 히스토그램 그래프 그리기
2-5. 박스 플롯 그리기
2-6. 상관관계 그래프 그리기
# seaborn 라이브러리를 통한 그래프 그리기
# annot: 각 셀의 값 표기,camp 는 팔레트
dplot10 = sns.heatmap(df10.corr(), annot = True, cmap = 'viridis') # camp =PiYG 도 넣어서 색상을 비교해보세요.
dplot10.set(title='corr plot')2-7. 조인트 그래프 그리기
# seaborn 라이브러리를 통한 그래프 그리기
#두 변수에 분포에 대한 분석시 사용
#hex 를 통해 밀도 확인
sns.jointplot(x=df2['Purchase Amount (USD)'], y=df10['Review Rating'], kind = 'hex', palette='cubehelix')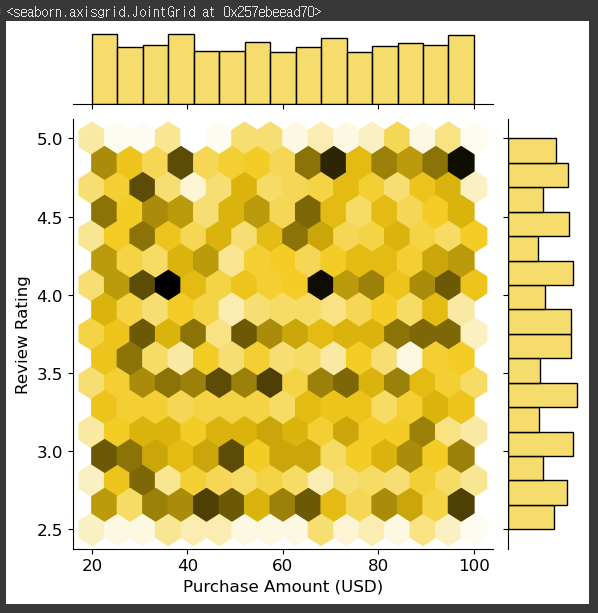
3. 데이터 시각화: Altair
3-1. bar graph 그리기
# altair 라이브러리를 통한 그래프 그리기
# 월별 유저수 interactive 그래프 구현
source=df9
alt.Chart(source).mark_bar().encode(
x='Date',
y='user count'
).interactive() # 동적 구현 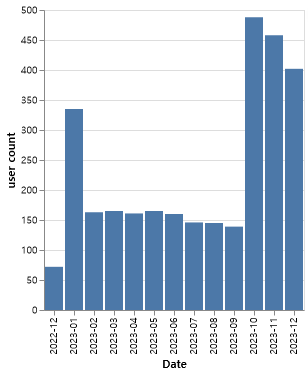
3-2. pie chart 그리기
# altair 라이브러리를 통한 그래프 그리기
source = df33
colors = ['#F4D13B','#9b59b6']
#innerRadius=50 >> 도넛차트의미
dplot3 = (
alt.Chart(source).mark_arc(innerRadius=50).encode(
theta="Customer ID",
color="Gender",
).configure_range(category=alt.RangeScheme(colors))) # 컬러 반영하기
dplot3.title = "donut plot" # 타이틀 설정
dplot3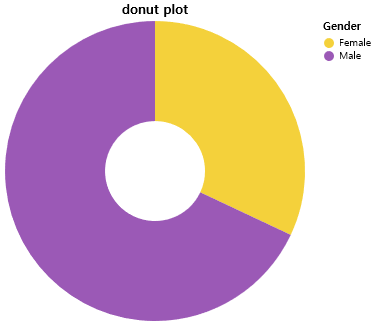
3-3. 동적 그래프 그리기
# altair 라이브러리를 통한 그래프 그리기
#나이, 구매금액에 따른 남성/여성 유저수 확인하기
df5 = df2.groupby(['Age','Gender'])['Purchase Amount (USD)'].sum().reset_index()
df6 = df2.groupby(['Age','Gender'])['Customer ID'].count().reset_index()
merge_df =pd.merge(df5, df6, how='inner', on=['Age','Gender'])
merge_df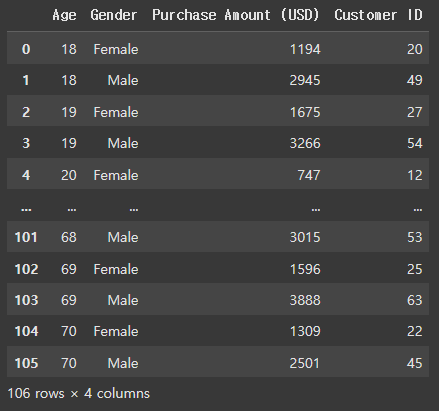
# altair 라이브러리를 통한 그래프 그리기
source = merge_df
colors = ['pink','#9b59b6']
# 선택(드래그) 영역 설정
brush = alt.selection_interval()
points = (alt.Chart(source).mark_point().encode(
# Q: 양적 데이터 타입 / N: 범주형 데이터 타입
x='Age:Q',
y='Purchase Amount (USD):Q',
# 선택되지 않은 부분은 회색으로 처리
color=alt.condition(brush, 'Gender:N', alt.value('lightgray')),
).properties( # 선택 가능영역 설정
width=1000,
height=300
)
.add_params(brush)) # 산점도에 드래그 영역 추가하는 코드
# 아래쪽 가로바차트
bars = alt.Chart(source).mark_bar().encode(
y='Gender:N',
color='Gender:N',
x='sum(Customer ID):Q'
).properties(
width=1000,
height=100
).transform_filter(brush) # 산점도에서 선택된 데이터만 필터링해 막대 그래프에 반영
#산점도와 막대 그래프를 수직으로 결합
dplot4 = (points & bars)dplot4= dplot4.configure_range(category=alt.RangeScheme(colors))dplot4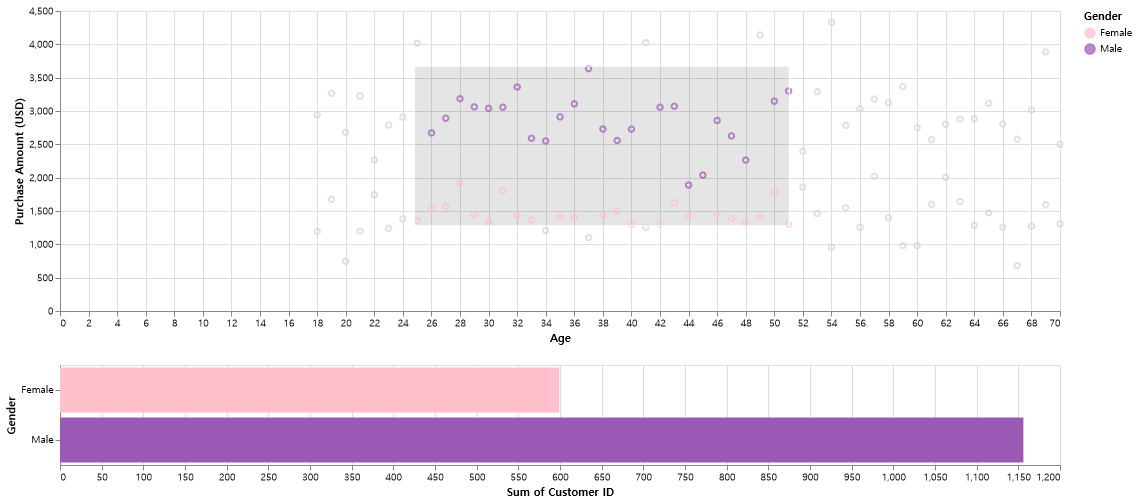
4. pygwalker
#pip install pygwalker
import pygwalker as pyg
df2 = pd.read_csv("customer_details.csv") # customer_details.csv
walker = pyg.walk(df2)
2 B R 0 2 B