"대용량 데이터엔 스파크!"
스파크는 굉장히 다루기 까다로운 툴이고, 분석가에게 반드시 요구되는 역량은 아닙니다. 하지만 스파크를 다루는데 필요한 많은 지식들은, 스파크를 떠나 데이터를 다루는 모두에게 유용합니다.
스파크는 대규모 데이터(>100GB)를 다루는 도구이지만, 그 지식은 소용량 데이터(<10GB)를 다룰 때 필수적입니다. 현대의 데이터 분석가는 최소 기가 단위의 데이터를 다루기 때문에, 본인이 그 정도의 규모를 다루는데 어려움을 느끼신다면 꼭 자세히 들어보시길 바랍니다. 실제 채용할 때, 면접에서 물어보는 내용을 많이 담아두었으며, 실습 코드 또한 다수가 실무에서 사용하는 레벨의 코드입니다.
-
학습 목적
- 파이썬을 중심으로 컴퓨터가 데이터를 다루는 방법
- 작업을 분산시키는 다양한 방법론
- 파이썬 작업 효율화 / 메모리 경량화
- 스파크를 쓰는 이유와 배경
- 스파크의 작동 원리
-
학습 목표
- 1주차
- CPU와 메모리, IO
- 컴퓨터에서 데이터와 물리적으로 저장되는 파일의 유형
- 온프레미스 vs. 클라우드
- 2주차
- 병렬 처리와 분산 처리
- Sampling과 작업 분할
- 스파크 대안과 자동화
- 3주차
- 스파크의 구성과 작동 원리
- 스파크 메모리 관리 팁
- 1주차
왜 스파크일까?
- 학습 목표
- 스파크를 실제 사용하는, 그리고 사용하지 않는 사례 알아보기
스파크가 뭐길래?
스파크를 실제로 쓰리라는 보장은 없지만, 대규모 데이터 전처리에 있어 스파크는 표준이며 실제 많은 회사가 스파크를 운용하고 있기에 협업 차원에서 도움이 됩니다. 또한 여기서 배우는 개념들은 파이썬이나 쿼리 기반 분석에 있어서도 도움이 됩니다.
- 정의
- Apache Spark란 무엇인가요?
- SQL, 스트리밍, 머신러닝 및 그래프 처리를 위한 기본 제공 모듈이 있는 대규모 데이터 처리용 통합 분석 엔진
- Spark는 클라우드의 Apache Hadoop, Apache Mesos, Kubernetes에서 자체적으로 실행될 수 있으며 다양한 데이터 소스에 대해 실행될 수 있음
- 아파치 재단이 관리하고 있음
- Apache Spark란 무엇인가요?
- 쉬운 설명
- 대용량 데이터를 다루는 것에 특화된 프레임 워크
- 왜 스파크를 알아야 할까?
- Pyspark
- Python을 기반으로 하여 별도의 언어 공부가 필요 없음
→ 원래는 자바 기반으로 개발된 '스칼라'라는 언어로 개발되었음(파이썬으로 이식된 게 Pyspark)
- Python을 기반으로 하여 별도의 언어 공부가 필요 없음
- 대용량 데이터
- 대용량 데이터를 다루는 기술에 대한 이해
- 분산 처리
- 여러 대의 컴퓨터를 사용한다는 것에 대한 이해
- Pyspark
스파크를 왜 쓰나?
쓸 수 밖에 없는 경우: 진짜 대용량 데이터
- 대용량 데이터 처리는 분할(Partition)하여 처리함으로써 스파크를 우회할 수 있지만, Graph 형식의 데이터는 분할하기 어려워 스파크를 사용해야 함
(예) 약 800GB의 Microsoft Academic Graph 데이터를 다룰 때- 약 10~20대의 컴퓨터를 사용하여 수백만 건의 논문 데이터를 교정했다고 함
- 약 10~20대의 컴퓨터를 사용하여 수백만 건의 논문 데이터를 교정했다고 함
써야 하지만 회피할 수도 있음
- MAU(월간 이용 유저)가 1천만 명 이상이었던 일본 웹툰 서비스 분석
- 하루에도 수십억 건의 데이터가 발생하는 상황 → 하나의 머신으로는 감당 불가
- 하지만 샘플링, 경량화, 분할, 스케일업을 통해 스파크를 통하지 않고 문제 해결힘 → Why not spark? 비싸고, 오래 걸리고, 승인도 번거롭고, 코드도 다시 짜야하니까
- 하루에도 수십억 건의 데이터가 발생하는 상황 → 하나의 머신으로는 감당 불가
쓰지 않아도 되는 경우
- NFT 가격 추정을 위해 수백GB의 데이터를 전처리하여 모델링
- 스케일업 vs 스케일아웃 → 실험으로 증명하자
- 데이터가 본질적으로 분할(by projecct)되어 있어 스파크의 폐기 결정
- 스케일업 vs 스케일아웃 → 실험으로 증명하자
파이썬과 데이터
- 학습 목표
- 싱글 머신의 한계를 메모리 관점에서 이해
- 다양한 데이터의 종류를 보며 메모리 최적화를 위한 기본 지식을 쌓기
파이썬과 데이터, 메모리
OOM(Out of Memory)
- 파이썬 작업을 하다보면 아래와 같은 이유를 알 수 없는 에러를 만날 수 있음
- 이를 컴퓨터 공학에서는 OOM(Out of Memory)이라 하며, 특히 대용량 데이터를 처리할 때 자주 만나게 되는 문제임
- 스파크를 쓰는 이유는 보통 대용량 데이터(>100GB) 처리를 위한 것이기 때문에, 이러한 에러를 먼저 만나는 것은 아주 일반적임
- 스파크를 쓸 때도 맨날 OOM으로 터진다고 함
- 스파크를 쓰든, 파이썬을 쓰든 메모리의 관리는 굉장히 중요!
메모리
- 메모리란 기억 장치로, 굉장히 세분화가 되어 있음
- 윈도우에서는 작업 관리자, 맥에서는 활성 상태 보기, 리눅스에서는 htop 등으로 메모리 사용량 확인 가능
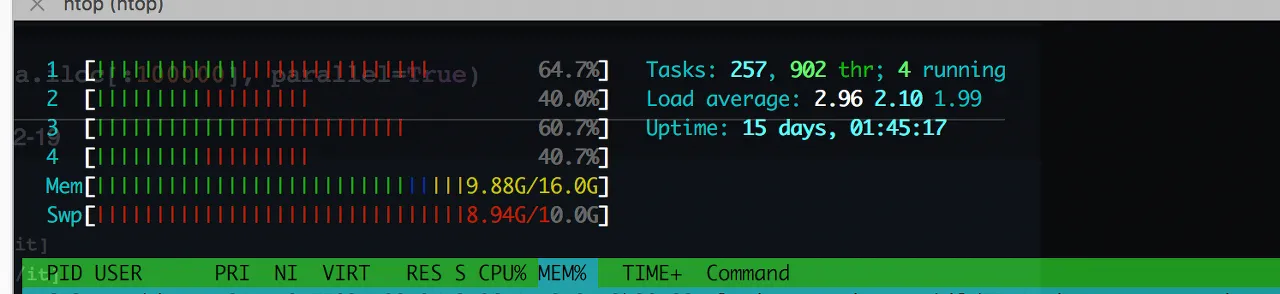
- 여기서는 크게 RAM과 Disk(SSD)로 나눠 알아볼 것
- 레지스터와 캐시 메모리까지는 다루지 않을 거지만 알아두면 좋아요!
- 레지스터: CPU가 가장 빠르게 접근이 가능한 저장 공간이며, CPU 내부에 위치
- 캐시 메모리: 메모리 접근 속도를 향상시키기 위해 중간 버퍼 역할을 하는 저장 공간
- 레지스터와 캐시 메모리까지는 다루지 않을 거지만 알아두면 좋아요!
RAM

- 작업 공간
- 책상이나 도마라고 생각하면 됨
- 데이터를 갖고 작업하기 위해 데이터를 RAM이란 곳에 올림
e.g.read_csv: 하드 디스크에 있는 데이터를 RAM로 옮기는 작업
- 여기에 OS(윈도우 등)와 기본적인 프로그램을 올리면 2~6GB 정도 차지함
- 컴퓨터를 끄면 RAM에 올라간 데이터는 삭제됨: 휘발성
Disk(hdd/ssd)
- 저장 공간
- 장기적으로 데이터를 보관(저장)하는 공간
- 컴퓨터를 꺼도, Disk의 데이터는 사라지지 않음
CPU
- CPU는 일꾼
- 보통 컴퓨터는 여러 일꾼을 가지고 있음
- 모두 이해할 필요는 없으며, 가장 중요한 것은 코어의 수라고 봐도 됨
- 같은 코어 수라도, 고성능의 CPU는 수 배 이상 빠를 수 있음
- 인텔 vs 애플 M3, M4(애플 제품이 더 빠름)
- 같은 코어 수라도, 고성능의 CPU는 수 배 이상 빠를 수 있음
- 병렬 처리
- 하나의 작업을 위해 여러 코어를 사용하는 것
- 스파크 또한 여러 대의 PC를, 그리고 각 PC의 여러 코어를 모두 사용(병렬 처리 & 분산 처리 다 하는 게 )
- 스레드, 프로세스, GIL도 알아두면 좋아요
- GIL(Global Interpreter Lock)
- 다수의 쓰레드가 동시에 바이트코드를 실행하지 못하도록 막는 락 기능
- GIL(Global Interpreter Lock)
Data type
-
메모리에는 그럼 어떤 데이터가 올라갈까?
- 파이썬이 다루는 데이터를 Pandas 기반으로 알아보기
- MySQL과 같은 Database도 비슷함
- 예: 붓꽃(Iris) 데이터
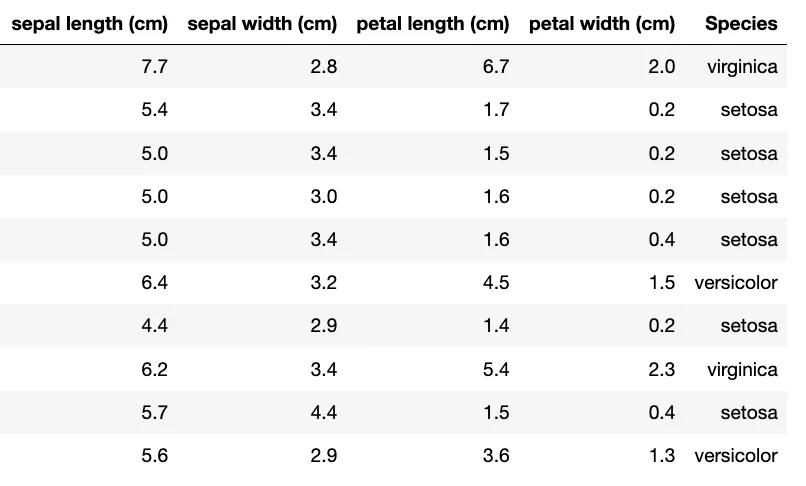
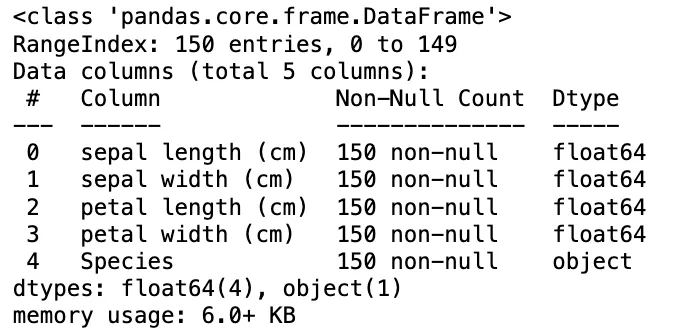
- 파이썬이 다루는 데이터를 Pandas 기반으로 알아보기
-
내부적으로는 각 데이터에 대한 명확한 타입이 존재함
- 적절한 데이터 타입을 사용하면, 보통 30% 이상의 메모리를 절약할 수 있음
Integers
- 컴퓨터에서는 정수를 이진법으로 표현
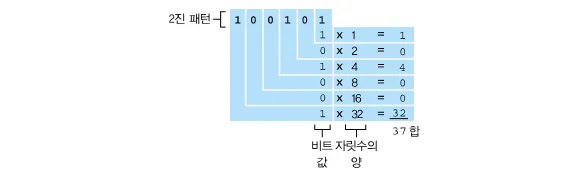
- 뒤의 숫자는 얼마나 많은 메모리를 할당(assign)할 것인지에 대한 것
- 더 많은 메모리를 할당할 수록, 더 큰 숫자를 담을 수 있음
int8:-128 ~ 127int16: -32768 ~ 32727int32: -2,147,483,648 ~ 2,147,483,647int64: -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807
- 엄밀히는, 부호를 위해 1비트(메모리의 단위)를 사용함
Overflow
- 쉽게 말하면 크기에 맞지 않는 데이터를 넣어 의도하지 않은 결과가 나오는 것이 바로 오버플로(overflow)
- 정확한 정의는 좀 더 복잡해요
- 파이썬의 데이터 타입은 기본적으로 동적(Dynamic)이기 때문에 자동으로 데이터형이 바뀜 → 따라서 큰 숫자를 다루는 것은 굉장히 주의해야 함!
Floating points
-
부동소수점은 사람에게 직관적이지 않지만, 컴퓨터는 부득이 사용하는 개념
- 컴퓨터는 이진법을 사용하기 때문에, 정수는 어렵지 않게 표현할 수 있지만 0.2, 18.5, 와 같은 정수가 아닌 숫자는 정확하게 표현할 수 없음
- 이를 보완하기 위해 컴퓨터 공학에서는 부동소수점을 사용
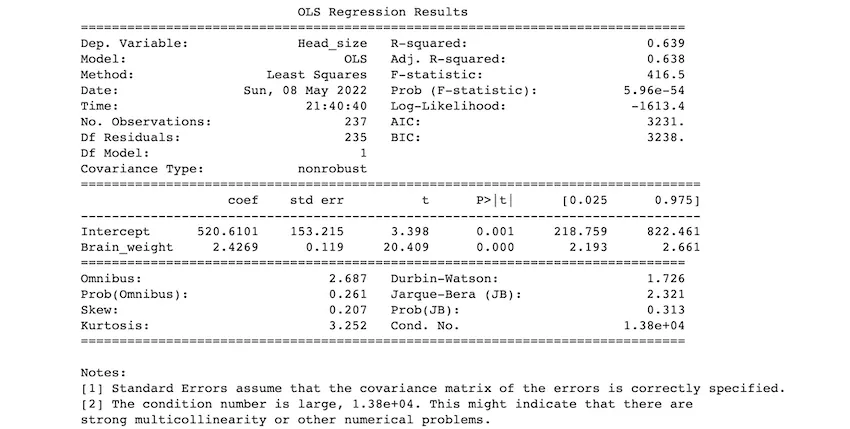
- 5.96e-54같은 게 바로 부동소수점
-
부동소수점은 하나의 숫자를 형태와 자릿수로 구분하여 표현하는 것

- 일부의 데이터는 형태(4.78224)를, 나머지 데이터로 자릿수(2)를 표현
- 이진법이고, 소수부와 정수부가 다르기 때문에 정확하게는 조금 다름 → 원리상 필연적으로 오차를 동반함
-
부동소수점 또한 정수와 마찬가지로 float16, float64 등을 사용하는데, 더 큰 메모리를 사용할수록 값이 정확해지지만 데이터가 더 무거워짐
부동소수점 오차
- 오차는 더 많은 메모리(16 → 32)를 사용할수록 줄어들지만
이론적으로는 무한히 많은 메모리를 사용해야만 이 오차를 정확히 없앨 수 있음 - 딥러닝의 경우 메모리 사용을 줄이기 위해,
의도적으로 오차를 감수해서라도 메모리를 줄이기도 함(float 16 등)- 예: float8을 이용(양자화)하여 경량한 LLM 모델
- 예: float8을 이용(양자화)하여 경량한 LLM 모델
String, Category
- 문자열은 문제가 더 복잡함
- 일반적으로 우리에게 친숙한 대부분의 소프트웨어는
유니코드unicode를 이용하여 문자열을 인코딩
- 일반적으로 우리에게 친숙한 대부분의 소프트웨어는
- 이러한 원리를 모두 지금 이해할 필요는 없고 메모리를 굉장히 많이 차지한다는 점을 기억하는 게 중요함
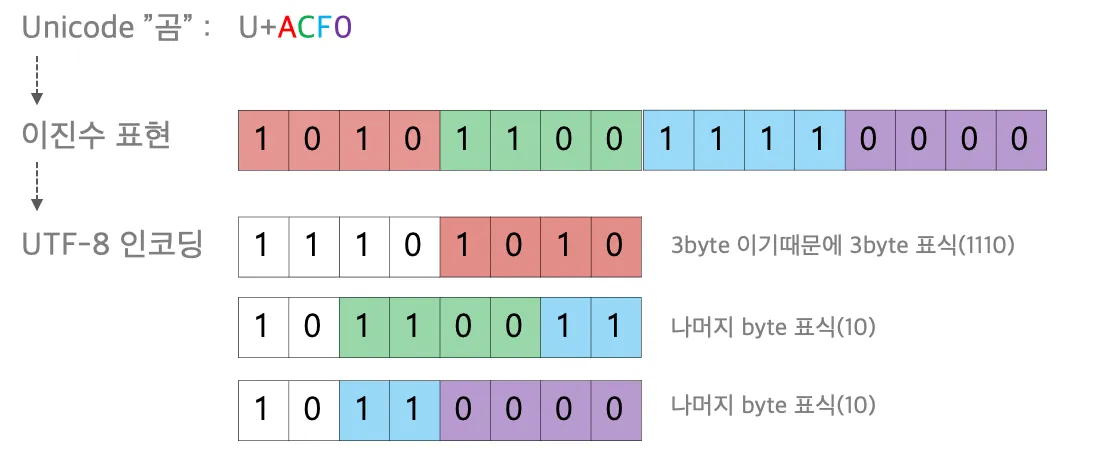
- 이에 대한 대안으로, 범주Category형 자료를 사용할 수 있음
- Pandas의 경우 각 데이터의 고유값을 내부에서 숫자로 치환하여 사용
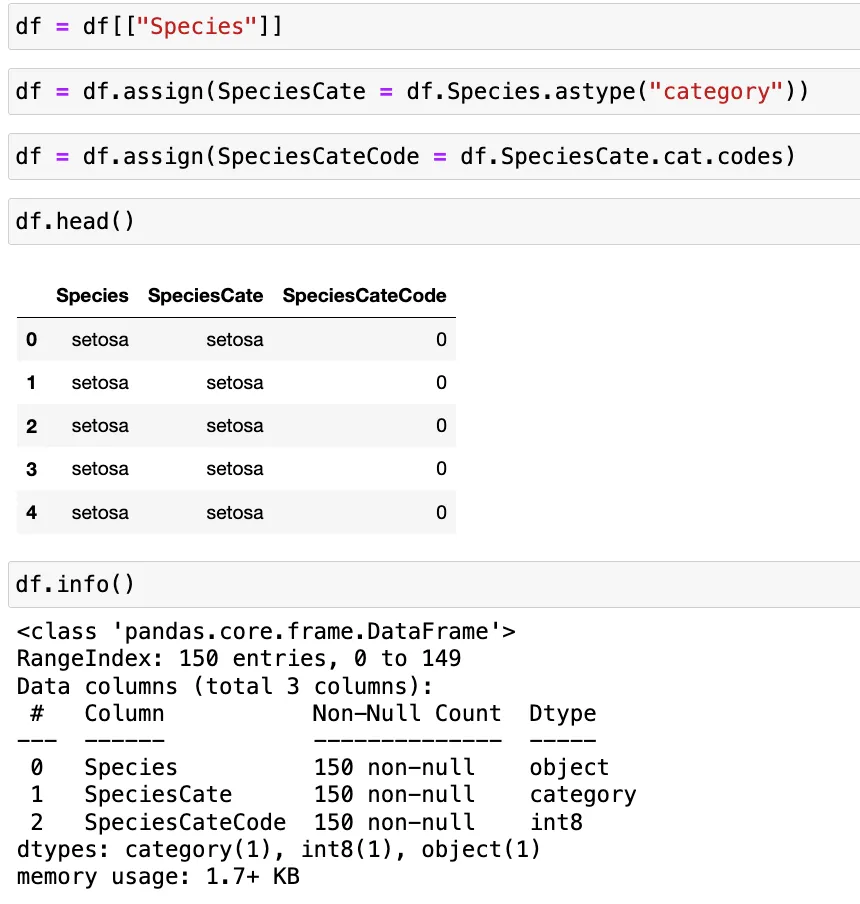
- 본래 문자열로 이루어졌던
Species컬럼을 범주형으로 변환(SpeciesCate) - 해당 범주 자료가 내부에서는 숫자로 사용되고 있음(
SpeciesCateCode)
→ 이를 통해 90% 이상의 메모리를 절약할 수 있음!
- 본래 문자열로 이루어졌던
- Pandas의 경우 각 데이터의 고유값을 내부에서 숫자로 치환하여 사용
Datetime
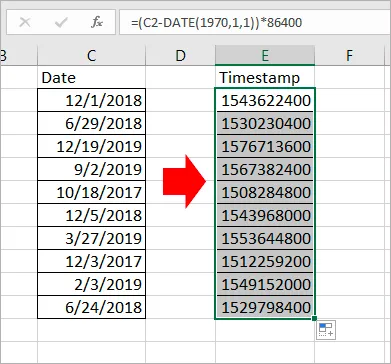
- 시간과 관련된 정보
- 일반적으로 소프트웨어들은 Unix Timestamp를 기준으로 함
- UTC time zone을 사용
- 1970년 1월 1일 0시를 기준으로 몇 초가 경과했는지를 숫자로 표현한 것
- 연, 월, 일 시 등의 표현은 사람마다, 소프트웨어마다, 회사마다, 팀마다 모두 다를 수 있음
- 이러한 표현들을 일반적으로 표현하기 위한 양식 또한 존재함
- 이를 통해 숫자인 Unix timestamp를 사람이 이해 가능한 문자열로 바꾸거나 거꾸로 문자열을 Unix timestamp로 바꿀 수 있음
- 일반적으로 년도는
%y나%Y(4자리)로, 월은%m, 일은%d로 표현- 자세한 내용은 여기 참조
- 이러한 표현들을 일반적으로 표현하기 위한 양식 또한 존재함
## 21년 11월 6일 4시 30분을 파싱
dt = datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M")
dt
>> datetime.datetime(2006, 11, 21, 16, 30)Time zone
- 시간대는 시간 데이터를 다룰 때 굉장히 중요한 부분
- 특히 소프트웨어는 범국가적이기 때문에, 시간의 표준화는 필수!
- 일반적으로 컴퓨터 공학에서는 UTC를 기준으로 하며, Unix timestamp도 UTC를 따름
- 대부분의 Database 또한 timezone 정보를 필수로 함
마무리
- 자료형은 소프트웨어에 따라 다소 차이가 있으며, 파이썬 내에서도 패키지마다 차이가 존재함
- 지금까지는 특정 소프트웨어(예컨대 파이썬)에서 메모리에 데이터를 띄우는 과정이었지만 우리는 디스크에도 데이터를 저장하며, 이때 굉장히 다양한 옵션을 마주하게 됨
파일 유형
- 학습 목표
- 디스크에 올리는 데이터의 유형과 용도 알아보기
File format
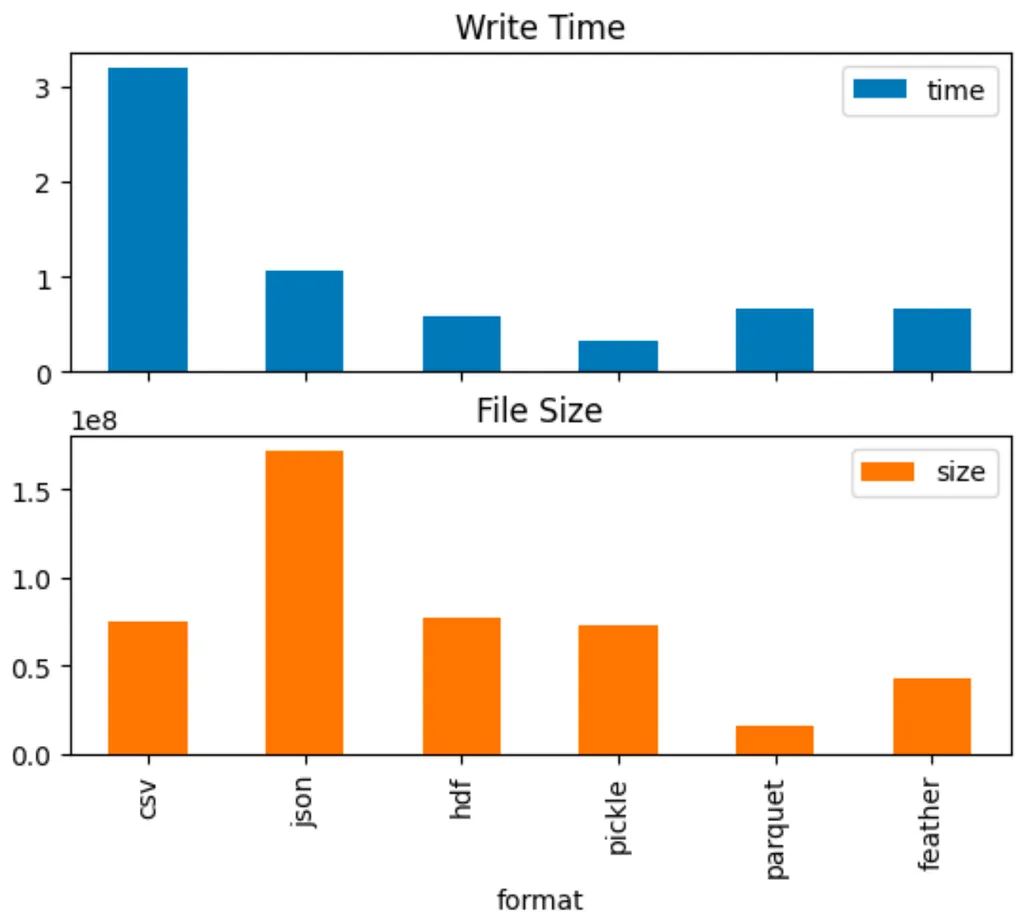
- 다양한 파일 유형이 존재: 크게 시간적 비용과 공간적 비용으로 장단점 비교
- 시간적 비용
- 읽고 쓰는 데 걸리는 시간
- 파일 유형에 따라 수십 배까지 차이가 남
- 공간적 비용
- 저장된 파일의 크기
- 마찬가지로 파일 유형에 따라 수십 배까지 차이가 남
- 좀 더 나아가, 입/출력 시에 필요한 메모리도 굉장히 중요
- 시간적 비용
csv, txt
- 가장 흔한 포맷
- 개발이나 분석 직군이 아닌 사람도 많이 다룸
- CSV(Comma-separated value)
- 콤마로 구분된 정형 데이터를 가리킴
- Comma(
,) 대신 Tab(\t)과 같은 다른 구분자(seperator)를 사용할 수 있음 - 데이터 안에 구분자가 들어있는 경우, 방어할 수는 있지만 깨질 위험이 있음
- 가장 느리고, 무거워서 소규모 데이터가 아니면 부적절
- 내부적으로는 encoding(utf-8, cp949 등)에 따라 다르게 저장
json

- csv, txt와 크게 다르지 않지만 저장된 자료를 python의 dictionary와 같은 형식으로 강제함
- 이를 JSON Object라 함(
{”키”:”값”})- dict와 같은 것은 아니지만 파이썬의 dict를 json으로 변환하여 사용할 수 있음 → 이를 dump한다고 함
(좀 더 자세히 들어가면 byte serialize를 이해해야겠지만, 여기서는 생략)
- dict와 같은 것은 아니지만 파이썬의 dict를 json으로 변환하여 사용할 수 있음 → 이를 dump한다고 함
- 여러 JSON Object를 JSON Array에 담을 수 있음

- 이를 JSON Object라 함(
- 비교적 개발자의 선호도가 높으며, 비교적 대용량의 데이터도 JSON으로 관리하는 경우가 많음
- API 통신도 보통 JSON 형식
- 하지만 여전히 무거워서 대용량 데이터를 다루는 데는 불편하고 txt와 마찬가지로 encoidng방법에 따라 다르게 저장되는데, utf-8을 사용하는 것이 일반적임
Pickle
- 하나의 컴퓨터로 개인용 프로젝트에서 데이터를 관리할 때 편리한 데이터 형식
- 버전과 운영체제에 대한 의존(Dependency)이 있음
- 협업할 때 데이터를 주고 받으면 작동하지 않을 위험 존재
- 버전과 운영체제에 대한 의존(Dependency)이 있음
- 위의 유형(csv, json)보다 2~30% 정도 용량이 가벼움
- read/write 속도가 수십 배 이상 빠름
- (고급) nested type을 지원
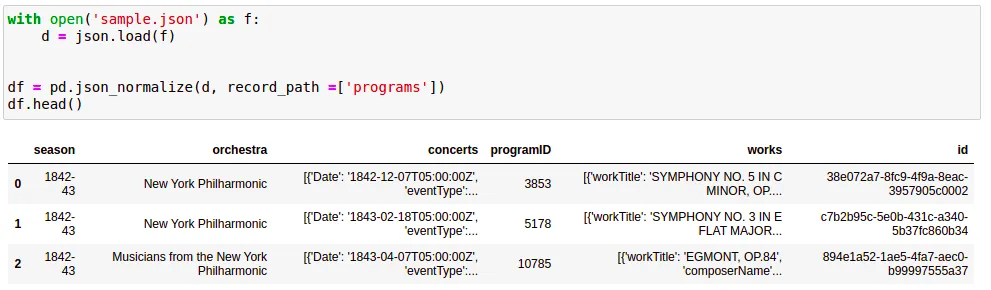
- 중첩nested 칼럼: concerts, works와 같은 칼럼
- (고급) 병렬처리에서 그리고 때로는 분산처리에서 내부 데이터를 pickle로 직렬화(Serialize)함
Parquet
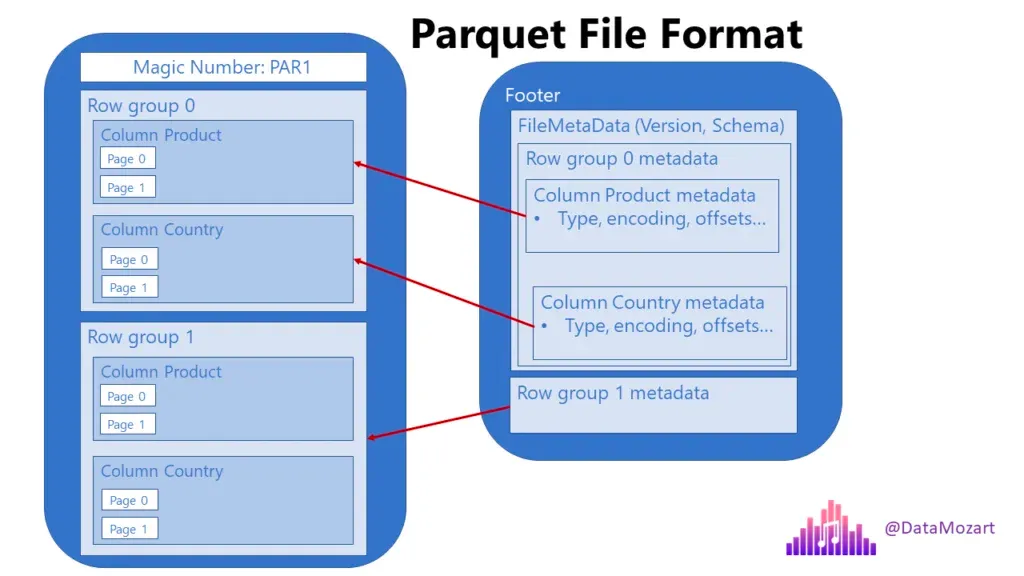
- 대용량 데이터 저장에서 표준
- 보통 “파케이”라고 읽음
- 굉장히 가볍고 빠름
- 다수의 OLAB Database가 내부적으로 parquet를 사용하여 데이터를 저장
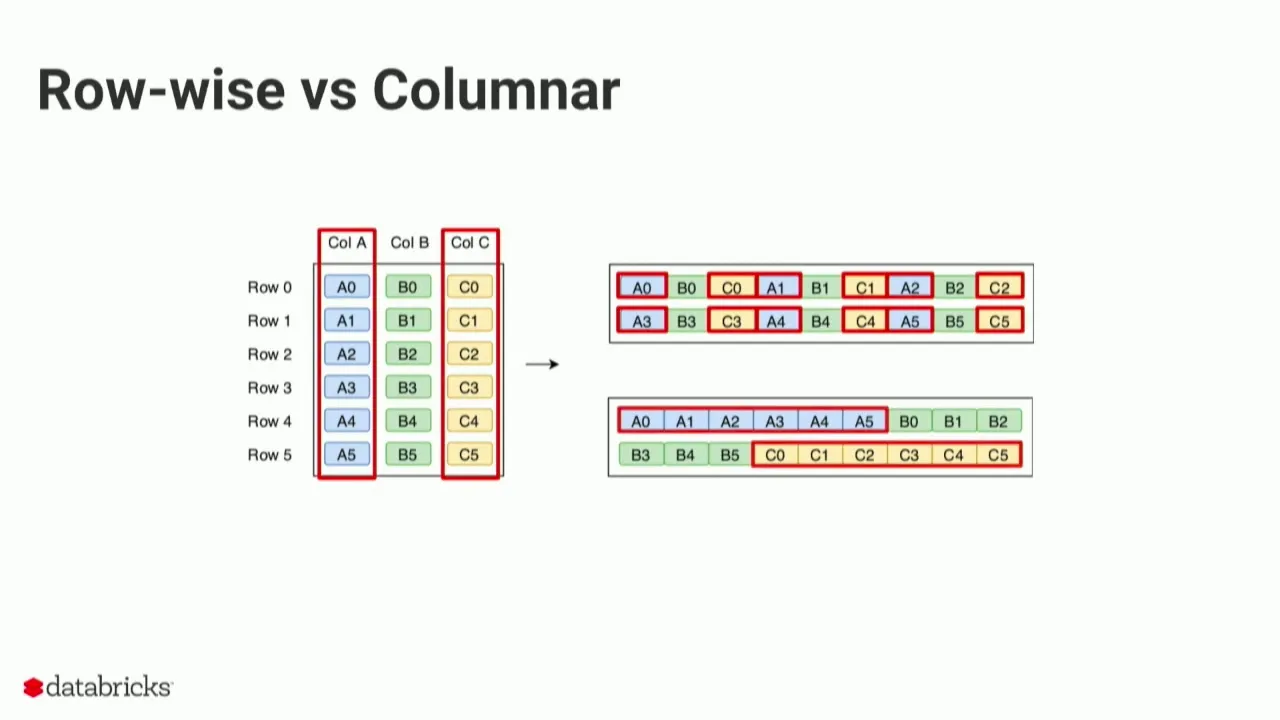
- Spark 또한 Parquet를 지원
기타
- arrow나 hdfs, feather도 때에 따라 유용하게 사용
- 기본적으로 컬럼 기반(columnnar)이기 때문에 위와 같은 압축, 속도가 가능
I/O
- Input & Output을 가리킴
- 다양한 맥락에서 쓰이지만, 여기서는 데이터의 입출력을 말함
I/O의 메모리 사용
- 전처리에서 잘 돌던 데이터가 저장save에서 터지는(OOM) 경우가 있음
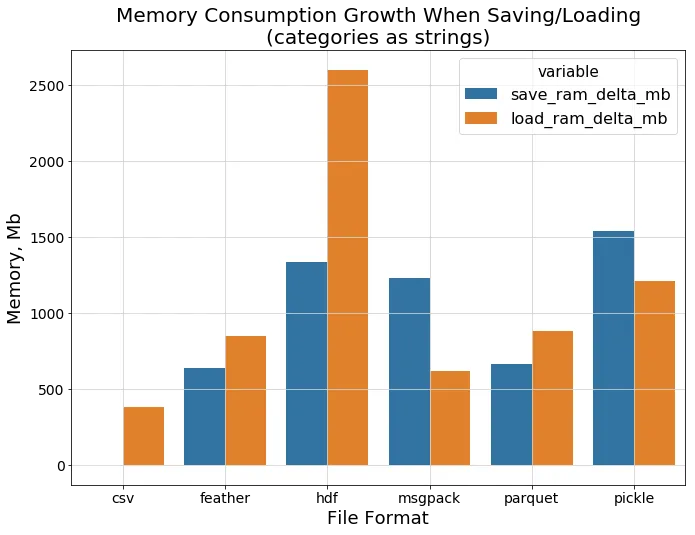
I/O Speed
- 언급한 것 중 가장 빠른 데이터 수급은 메모리
- 좀 더 자세히는 Network < Disk < Memory
(캐시 쪽은 생략) - 이러한 이유로 In-memory DB를 사용하기도 함
- 좀 더 자세히는 Network < Disk < Memory
- 스파크는 기본적으로 모든 데이터를 Memory에서 처리
- 내부적으로는 lazy computation 등으로 좀 더 복잡
마무리
- 위에서 다룬 내용은 중간 규모 이상의 데이터 처리를 한다면, 스파크와 무관하게 꼭 알아둬야 하는 지식임
- 모두 다 이해하고 기억할 필요는 없지만, 큰 흐름과 주요 키워드만이라도 알아두기
클라우드 살펴보기
- 학습 목표
- 로컬 머신이 아닌 클라우드를 왜 쓰는지 이해하기
- 클라우드에서 사용 가능한 서버에는 어떤 게 있는지 알아보기
왜 클라우드일까?

- 관리가 훨씬 쉽고, 보안이 뛰어나며, 가용성이 좋음
- 스파크를 쓸 때는 여러 대의 컴퓨터를 사용하는데, 보통 클라우드의 서버를 빌려 사용
클라우드 3대장
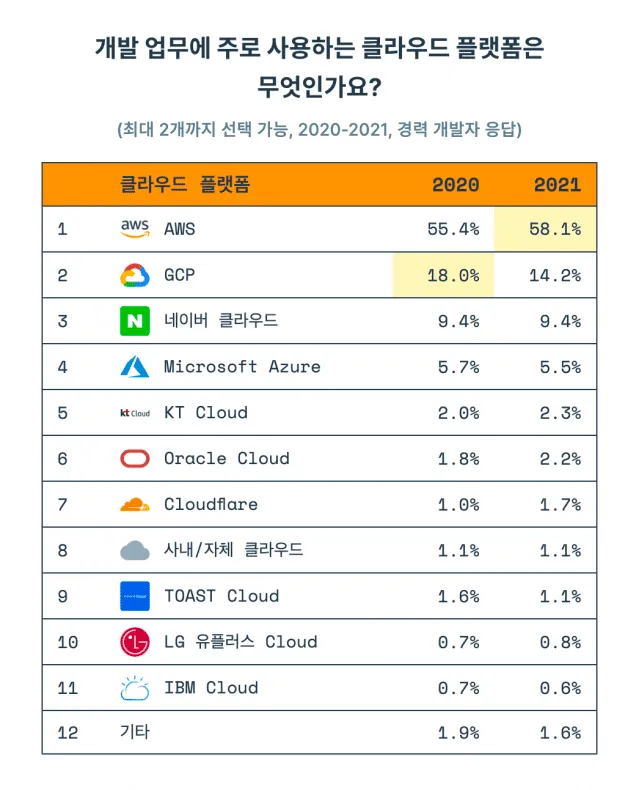
- AWS, GCP, Azure
- AWS는 지금까지 시장을 지배해왔고, 앞으로도 그럴 가능성이 높음
- 한 번 시장을 지배한 이후로, 모든 것의 기준이 되었음
- GCP는 Bigquery 원툴일 수 있지만, 그 원툴이 너무 강력함
- Azure는 편하지만 비쌈
- AWS는 지금까지 시장을 지배해왔고, 앞으로도 그럴 가능성이 높음
- 하지만 여러 가지 이유(지원, 투자, 계열사 등)로 기타 클라우드를 사용하는 경우도 많음
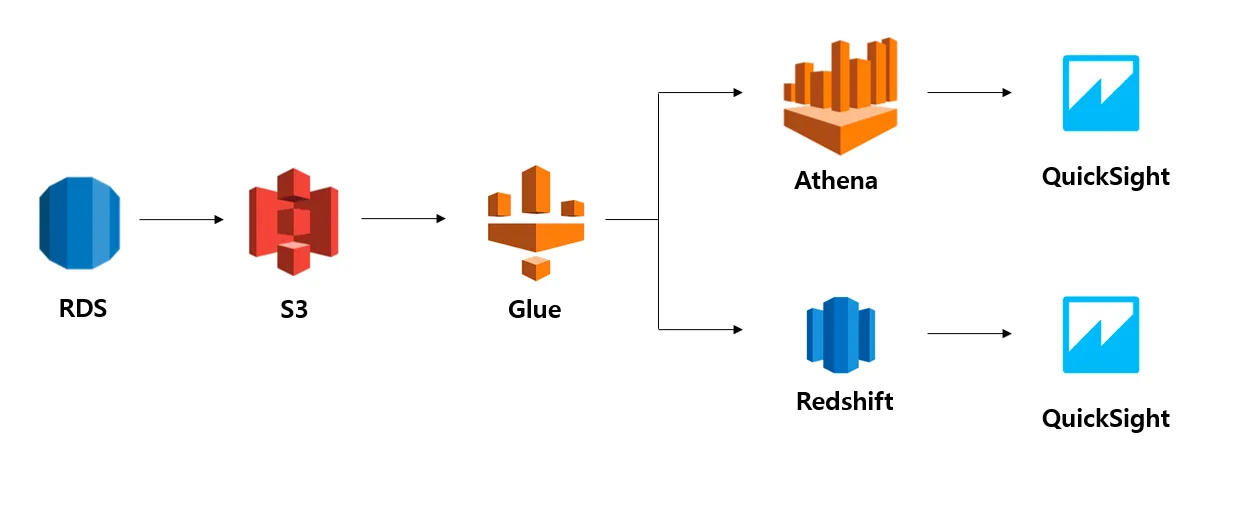
스토리지

- AWS를 이용하게 되면 기본적으로 대부분의 파일(데이터)를 S3에 보관
- 내 컴퓨터에 보관하는 것보다 안전하며, 임의의 팀원이 접근할 수 있음
- 그 데이터를 다시 데이터베이스에 연결하여 사용할 수도 있음
- 스파크는 S3에서 직접 읽을 수도, DB를 통해 읽을 수도 있음
- 비용에 주의
엔진

- 쉽게 말해 컴퓨터를 빌리는 것
- 단일 기기를 빌릴 수도 있고, 여러 대를 빌려쓸 수도 있음
- 접속은 보통 ssh를 이용하고, vscode를 이용하면 좀 더 편리
데이터베이스
왜 데이터베이스를 사용하나요?
- 데이터 공유
- 여러 사용자가 동시에 접근하여 데이터를 공유할 수 있음
- 데이터 보호
- 데이터를 보호하기 위해 다양한 보안 기능을 제공
- 데이터 검색
- 데이터를 쉽게 검색할 수 있도록 인덱싱 기능을 제공
- 데이터 백업과 복원
- 데이터를 백업하고 복원하는 기능을 제공하여 데이터 손실을 방지
- 이를 통해 중요한 데이터를 안전하게 보호할 수 있음
데이터베이스의 유형
- 수십 가지 데이터베이스가 존재
- 서로 다른 세 가지 유형의 대표적인 데이터베이스 살펴보기
- RDS
- postgres와 mysql 등 다양한 옵션 존재
- 보통 엔지니어가 결정한 걸 따르면 됨
- 대동소이하며, 인덱싱을 잘 활용하면 좋음
(실습에서 확인 가능) - 항상 서버가 떠 있어야 해서 그 비용이 나감
- Athena
- S3에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스
- 보통 S3에 있는 데이터와 연동
- 쿼리를 운용할 때만 잠시 기기를 빌려 연산한 뒤 다시 반납 → Serverless라고 함
- 따라서 비용이 저렴한 것이 보통
- 바로 Spark와 연동 가능
- Redshift
- 빠르고 강력한 데이터 웨어하우징
- 구동을 위해서는 클러스터(여러 대의 컴퓨터)를 구성하여 운영해야 함
- 비쌈
- 복잡한 연산에 조금 더 효율적
- Spark와 연동 가능
아키텍쳐 예시
EMR
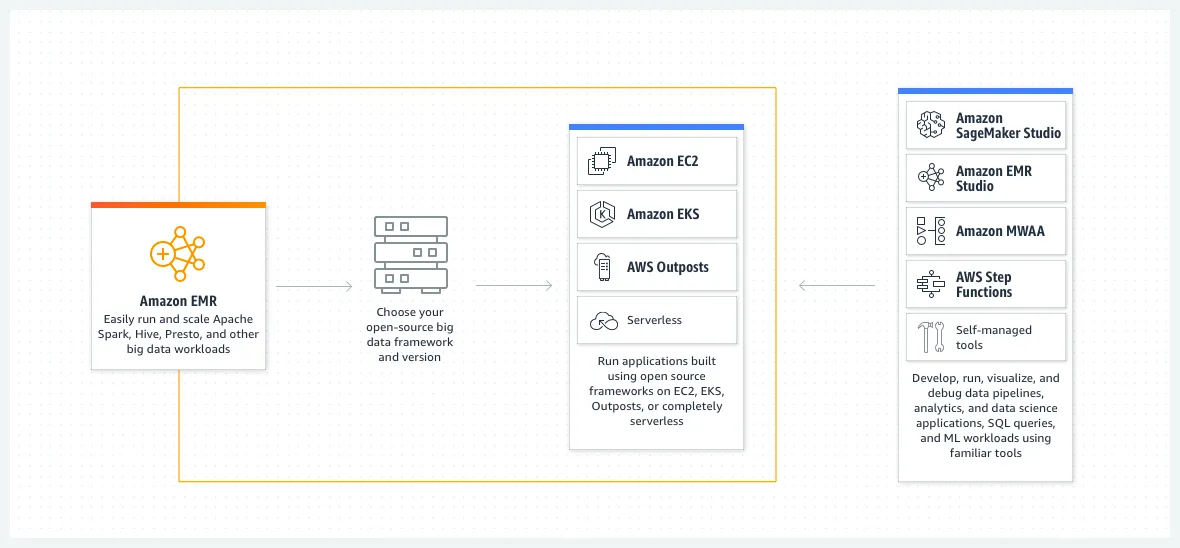
- 페타바이트급 데이터 처리, 대화식 분석 및 기계 학습을 위한 빅 데이터 솔루션
- AWS에서 Spark를 사용하면, 보통 EMR을 이용
- 직접 운영하는 건 여기서 다룰 난이도가 아니며, 분석가가 할 가능성이 낮기에 강의에서는 다루지 않음

2 B R 0 2 B