11/04 오전 회의 결과
- gm 테이블 combination 컬럼과 champion 컬럼에
{}만 있는 경우가 존재한다는 사실을 공유해 주셨음 → 결측치(Missing Value; 데이터 수집 과정에서 측정되지 않거나 누락된 데이터)에 속함!
- 한 경기 모든 데이터의 combination, champion 컬럼이 중괄호만 있을 때는 결측치라고 볼 수 있지만 한 경기 중 한 명, 두 명 정도의 데이터만 그렇다면 결측치로 볼 수 없다는 의견
- 게임 중간에 챔피언을 모두 팔고 항복할 수 있다고 함
- Ranked가 0인 경우 처리를 어떻게 할 것인지 각자 테이블 다시 한번 확인하고 나서 오후에 이야기 나누기로 함
분석 내용
원소가 {}인 경우 찾기
# combinatinon 컬럼의 값이 {}이거나 champion 컬럼의 값이 {}인 게임 찾기
gm_missing = gm[((gm['combination'] == '{}')|(gm['champion'] == '{}'))]
gm_missing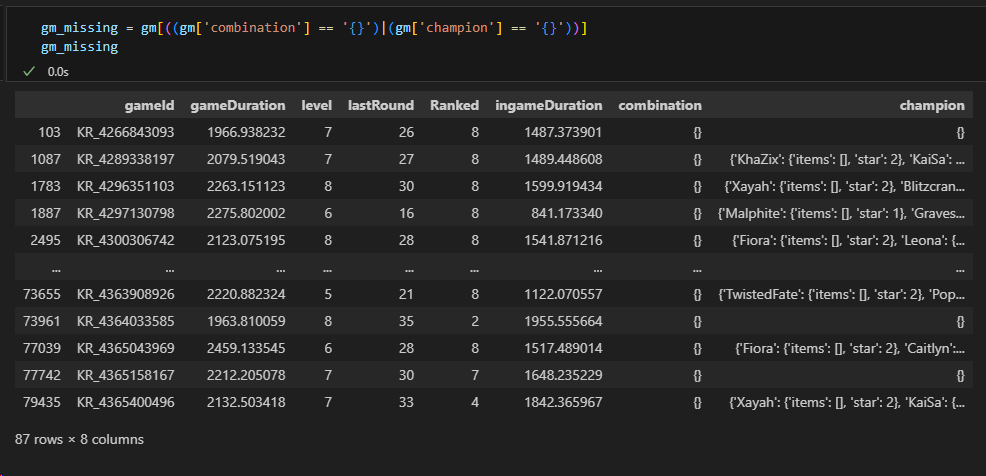
pd.pivot_table(gm_missing, index='gameId', values=['combination', 'champion'], aggfunc='count').plot(kind='bar')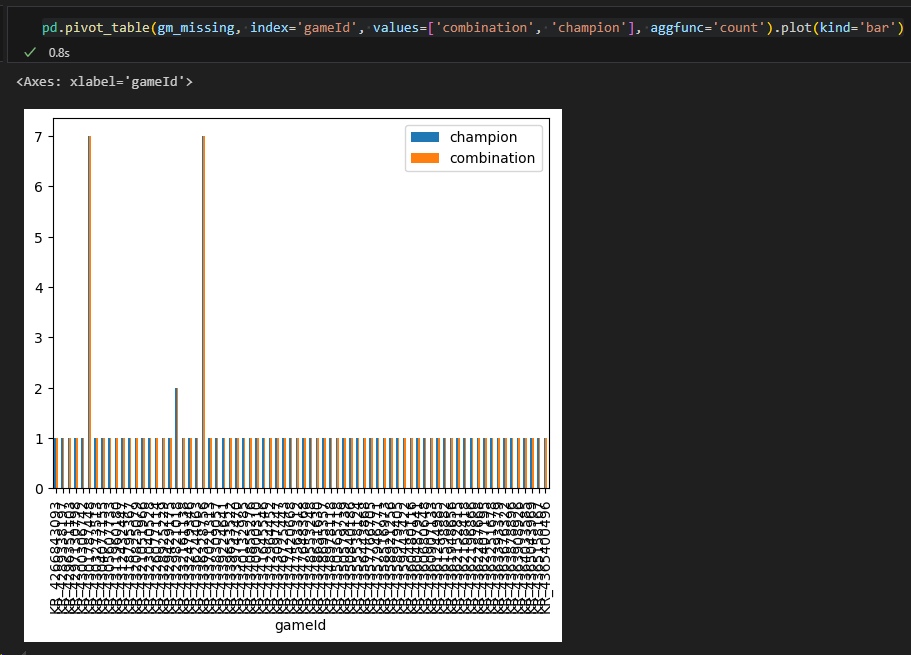
학습 내용
이상치와 결측치
- 이상치(Outlier)
- 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이나 큰 값
- 결측치(Missing Value)
- 데이터 수집 과정에서 측정되지 않거나 누락된 데이터
- 이상치와 결측치는 모두 데이터 전처리 과정에서 처리를 진행해주지 않으면 데이터 분석에 큰 영향을 끼치게 되기 때문에 알맞은 처리를 진행해야 함
이상치 탐지 방법
정규분포(Standard Deviation)
- 데이터의 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지
작업 내용
Z-score로 이상치 처리 + base_df 만들기
- 시각화를 제외한 이상치, 결측치 → 대체할지 제거할지 결정하고 이상치 처리 방법 2가지 사용해서 비교한 다음 한 가지 선택
- 논의 결과 gameDuration 컬럼을 이용하여 z-score로 이상치 처리하기로 함
import pandas as pd
import numpy as np
import time
from PIL import Image
import altair as alt
import seaborn as sns
import matplotlib.pyplot as plt
# seaborn 팔레트 설정
palette = sns.color_palette("pastel")
# pandas 라이브러리를 활용한 csv 파일 읽기
Challenger = pd.read_csv("TFT_Challenger_MatchData.csv")
GrandMaster = pd.read_csv("TFT_GrandMaster_MatchData.csv")
Master = pd.read_csv("TFT_Master_MatchData.csv")
Diamond = pd.read_csv("TFT_Diamond_MatchData.csv")
Platinum = pd.read_csv("TFT_Platinum_MatchData.csv")
# 테이블 결합 전 Tier 데이터 추가하기
Challenger['Tier'] = 'Challenger'
GrandMaster['Tier'] = 'GrandMaster'
Master['Tier'] = 'Master'
Diamond['Tier'] = 'Diamond'
Platinum['Tier'] = 'Platinum'
# concat으로 합치기
concat_df = pd.concat([Challenger, GrandMaster, Master, Diamond, Platinum], ignore_index=True)
# 확인
concat_df.shape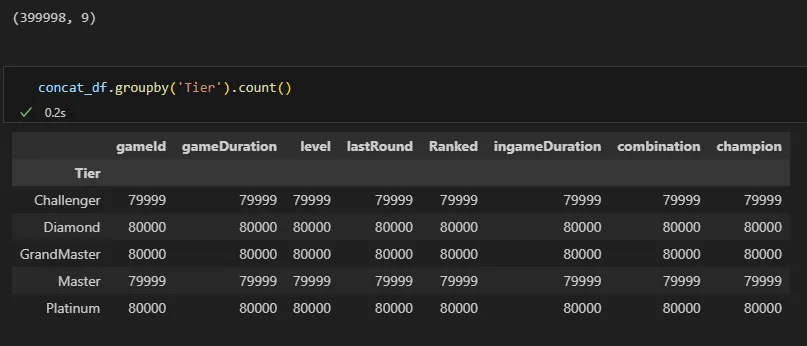
# 결측치 확인
concat_df.isnull().sum()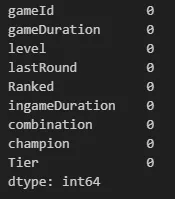
# 이상치 탐지: Z-Score
from sklearn.preprocessing import StandardScaler
# Z-score를 적용할 컬럼 선정
df = concat_df[['gameDuration']]
# 표준화 진행
scale_df = StandardScaler().fit_transform(df)
# array 형태로 반환된 결과를 DataFrame으로 받기
scale_df = pd.DataFrame(scale_df)
# 기존 raw 값과 표준화 이후 데이터를 비교하기 위해 merge 진행
merge_df = pd.concat([df, scale_df],axis=1)
merge_df.columns = ['gameDuration', 'gameDuration_zscore']
# Z-SCORE 기반, -3 보다 작거나 3보다 큰 경우를 이상치로 판별
mask = ((merge_df['gameDuration_zscore']<-3) | (merge_df['gameDuration_zscore']>3))
strange_df = merge_df[mask]
strange_df.count()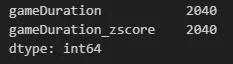
# 이상치 탐지: IQR
concat_df_iqr = concat_df
q3 = concat_df['gameDuration'].quantile(0.75)
q1 = concat_df['gameDuration'].quantile(0.25)
iqr = q3 - q1
def is_outlier(concat_df):
score = concat_df['gameDuration']
if score > q3 + (1.5 * iqr) or score < q1 - (1.5 * iqr):
return 'strange'
else:
return 'normal'
concat_df_iqr['gameDuration_iqr'] = concat_df_iqr.apply(is_outlier, axis = 1)
concat_df_iqr.groupby('gameDuration_iqr').count()
# z-score 값 컬럼으로 추가하기
concat_df_z = concat_df.assign(gameDuration_zscore=lambda x:x.gameDuration.sub(x.gameDuration.mean()).div(x.gameDuration.std()))
# 3 표준편차만큼을 벗어나는 데이터를 이상치로 처리: 신뢰도 99.7% 기준 이상치 추출
mask = ((concat_df_z['gameDuration_zscore']<-3)|(concat_df_z['gameDuration_zscore']>3))
strange_df = concat_df_z[mask]
strange_df.count()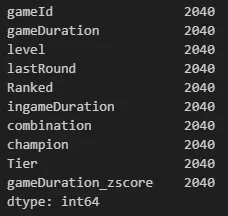
# z-score에서 판단하는 정상 데이터만 분리 후 저장
Base_df = concat_df_z[abs(concat_df_z['gameDuration_zscore'])<=3]
Base_df.to_csv('C:/Users/Pigeon/Desktop/Base_df.csv')# z-score에서 판단하는 이상치를 넘어가는 데이터만 분리 후 저장
concat_df_z_strange = concat_df_z[abs(concat_df_z['gameDuration_zscore'])>3]
concat_df_z_strange.to_csv('C:/Users/Pigeon/Desktop/strange.csv')조원 피드백
- 79999인 두 티어(Challenger, Master)의 경우 게임 참여 인원이 8명이 아닌 경기가 하나 들어간 상태로 보임
- 해당 경기 결측치가 존재하므로 경기 내용 전체 제거하기로 결정
- Challenger: KR_4318806255 → 6등 플레이어의 정보 누락
- Master: KR_4335870255 → 2등 플레이어의 정보 누락
- 해당 경기 결측치가 존재하므로 경기 내용 전체 제거하기로 결정
→ 각각의 DataFrame에 대하여 concat()을 실행하기 전 해당 경기를 먼저 삭제
# Challenger에서 gameId가 KR_4318806255인 경우를 분리하고 해당 행 삭제
strange_ch = Challenger[Challenger['gameId']=='KR_4318806255']
Challenger = Challenger[Challenger.gameId != 'KR_4318806255']
# Master에서 gameId가 KR_4335870255인 경우를 분리하고 해당 행 삭제
strange_ma = Master[Master['gameId']=='KR_4335870255']
Master = Master[Master.gameId != 'KR_4335870255']
# 해당 경기 삭제된 DataFrame으로 다시 concat 진행
concat_df = pd.concat([Challenger, GrandMaster, Master, Diamond, Platinum], ignore_index=True)
concat_df.groupby('Tier').count()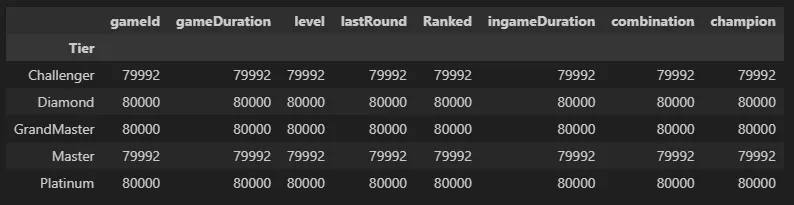
→ 이후 진행한 이상티 탐지에서 z-score, IQR로 추출되는 이상치 개수는 이전과 동일하므로 사진 첨부 및 코드 첨부 생략
→ 분석에 사용하지 않는 데이터 모으는 부분은 아래와 같이 수정됨
# z-score에서 판단하는 이상치를 넘어가는 데이터만 분리 후 분석에 사용하지 않는 데이터 모아 저장
concat_df_z_strange = concat_df_z[abs(concat_df_z['gameDuration_zscore'])>3]
strange_total = pd.concat([strange_ch, strange_ma, concat_df_z_strange])
strange_total.to_csv('C:/Users/Pigeon/Desktop/strange.csv')
2 B R 0 2 B