0. Abstract
기존의 merging 기법들은 (1) redundant parameter value interference, (2) 모델 간 주어진 parameter간의 부호 간의 불일치를 고려하지 않아 중요한 정보들을 잃는 경향을 보였다. 이에, TIES-Merging (Trim, Elect Sign & Merge)는 다음과 같은 세 가지 기법을 제안한다.
- fine-tuning 과정에서 조금만 바뀐 parameter들의 값을 reset
- sign conflict 해결
- 합의된 sign과 일치하는 파라미터만 합치기
그 결과, 기존의 여러 방법보다 좋은 성능을 보이는 것을 발견했다.
1. Introduction
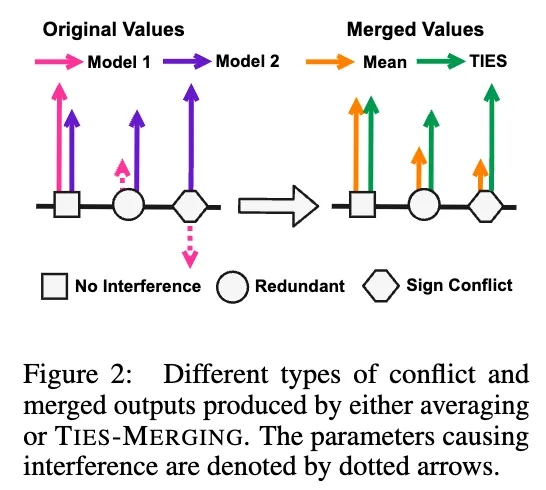
model merging에서 여러 개의 single task fine-tune model들을 한 개의 multi task model로 training-free하게 합치기 위해 여러 기법이 등장하고 있다. 이러한 weighted averaging 기법들이 효과적임은 증명이 되었으나, 모델 간의 파라미터 값들이 서로 영향을 준다는 것을 무시하곤 한다. 이 연구에서는 우선 모델 간의 이러한 간섭이 크게 두 가지 영향으로 생겨남을 설명한다. 이 두 가지 영향은 둘 다 merged model의 parameter magnitude를 줄어들게 하며, value 간의 미묘한 구별을 없앤다:
-
Interference From redundant Parameters
model pruning에 대한 선제 연구는 fine tuning 과정에서 많은 parameter의 값이 바뀌지만 그 중 적은 파라미터만에 성능에 영향을 준다고 밝혔다. 하지만 model merging 과정에서는 해당 parameter가 한 모델에서는 영향이 적지만 다른 모델에서는 영향을 주는 parameter일 경우에 성능을 저하하는 원인이 될 수 있다.
-
Interference From Sign Disagreement
어떤 parameter는 어떤 모델에서는 양의 값, 어떤 모델에서는 음의 값을 보일 수 있다. 이러한 경우 간단하게 둘을 평균내는 것은 두 task 모두에 부정적인 영향을 가져올 수 있다.
이러한 parameter 간의 간섭은 합치는 task의 수를 늘릴수록 task의 performance가 저하되는 것을 잘 설명한다.
위와 같은 간섭을 해결하기 위해, 다음과 같은 TIES-Merging을 제안한다.
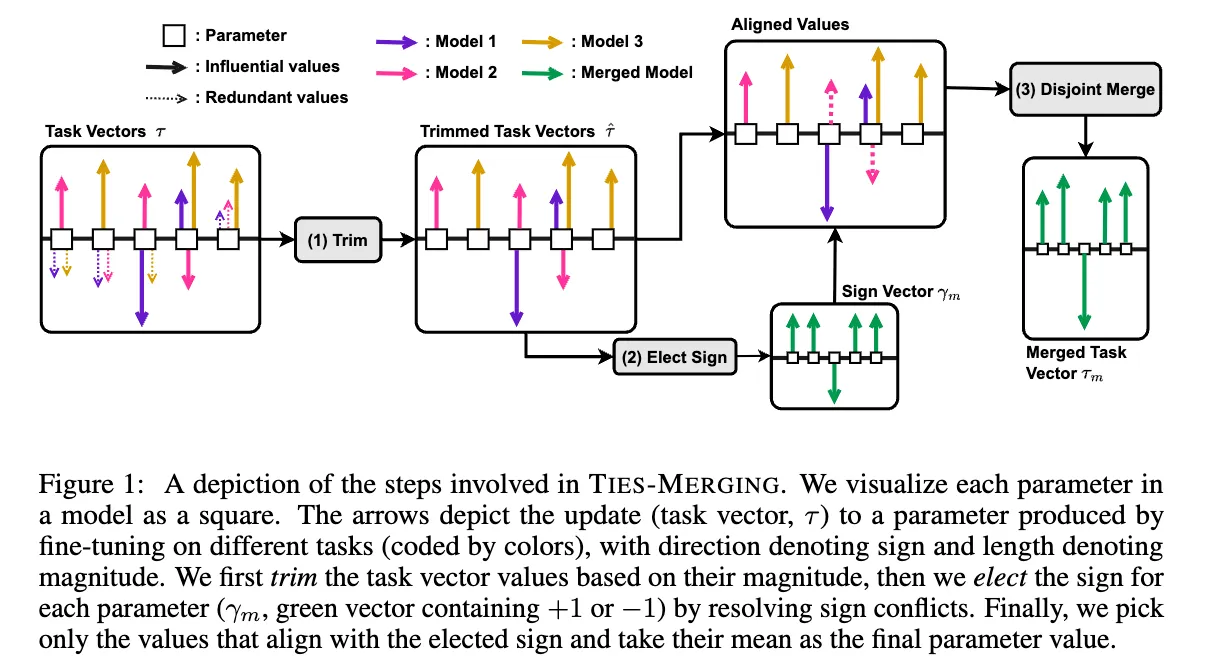
(1) Trim : task vector에서 의미 있는 parameter만 남기기 위해 trim을 진행한다. 이는 여러 task vector에서 반복되는 parameter의 값을 0으로 설정하여 이루어진다.
(2) Elect Sign : sign conflict가 생기는 parameter들의 충돌을 없앤다. (절대값이 더 큰 쪽의 sign만 받아들인다.)
(3) Disjoint Merge : 위에서 합의한 sign에 해당하는 값들만 평균내어 사용한다.
이러한 TIES-Merging 기법은 여러 조건에서 실험되었다: 다양한 modality(language & vision benchmarks), 여러 모델 크기와 구성들 (T5-base andT5-large, ViT-B/32 and ViT-L/14) 등
3. Background and Motivation
- Redundancies in Model Parameters
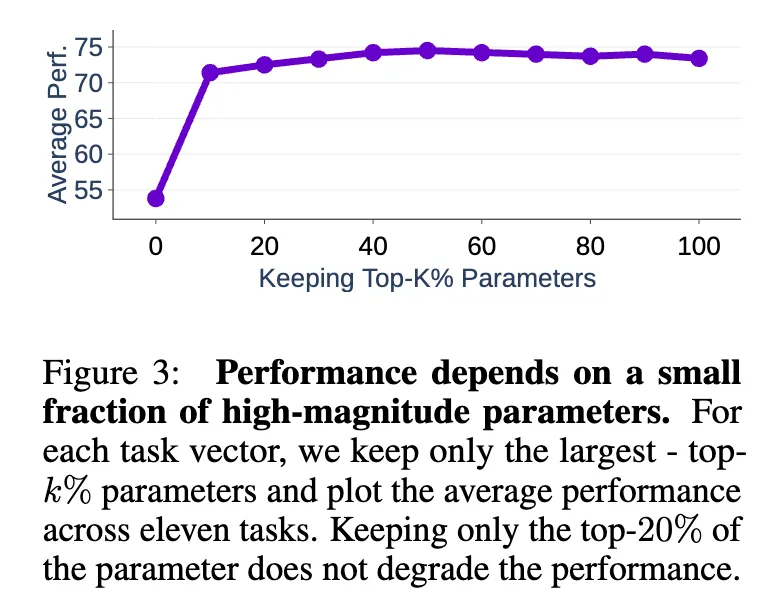
Figure 3에서 볼 수 있듯이, task vector에서 가장 큰 magnitude를 가지는 top-k%의 파라미터만 유지하고 나머지를 initial value로 바꾸었을 때 성능 저하가 크게 일어나지 않음을 알 수 있었다. top-20%의 파라미터만 남겨도 원래 성능과 비슷한 성능이 나타났다고 한다.
- Disagreement between Parameter Signs
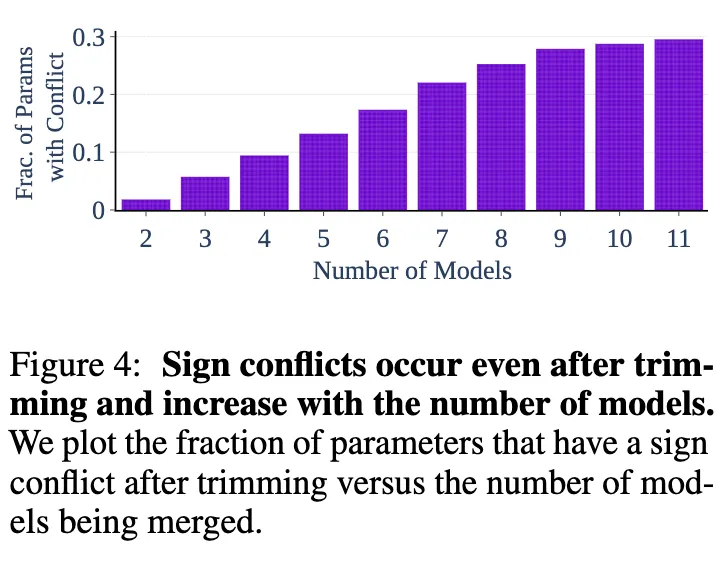
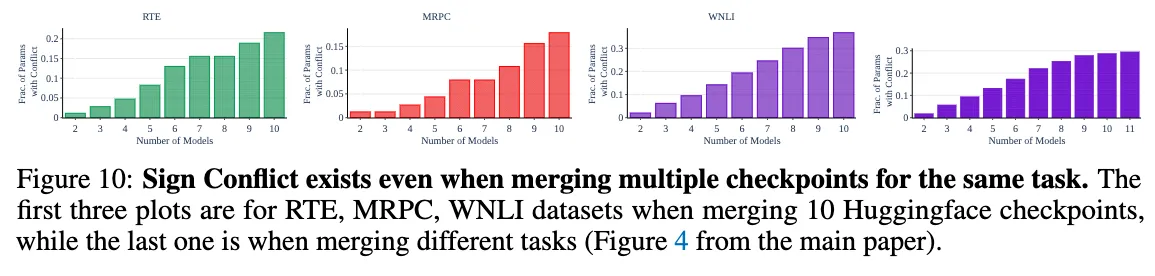
Fig 4. 는 모델의 수에 따른 sign conflict가 일어난 파라미터의 비율을 나타낸다. 이 실험 결과는 trimming을 진행한 후에 sign conflict가 나타난 비율만을 나타낸 것으로, 2개의 모델을 합치거나 같은 task의 모델을 합치는 것만으로도 sign conflict가 나타남을 관찰할 수 있었다.
4. TIES-Merging: Trim, Elect Sign & Merge
Preliminaries
주어진 task vector 가 있으면, 이 task vector를 sign vector 와 magnitude vector 로 나누어 생각할 수 있으며, 라고 표현할 수 있다. ( : elementwise product) 이때, 의 원소들은 +1, 0, -1 중의 값을 가지며, 라고 정의하자.
Steps in TIES-Merging
주어진 task vector들에 대해, TIES-Merging은 다음과 같은 과정을 따른다.
-
Trim : parameter의 magnitude에 따라 가장 높은 top-k%의 파라미터만 남기는 trimming을 진행한다. 이렇게 생성된 trimmed task vector를 라고 하자.
-
Elect : 이제, elected sign vector 을 만들어 각 파라미터에 대한 diagreements in sign을 해결한다. 이를 위해, 모든 관련된 모델 중에서 가장 highest total magnitude를 가지는 파라미터의 부호를 고른다. 즉, 모든 파라미터들을 부호에 따라 나누고, 각자 합을 취해 양수 파라미터와 음수 파라미터의 total magnitude를 계산한다. 이는 다음과 같이 쓸 수 있다:
-
Disjoint Merge : 그리고, 각 파라미터 p에 대해, elected sign과 같은 부호를 파라미터를 선택하여 평균을 구한다. (disjoint mean)
이렇게 구해진 에 대해, 이를 scale하고 더해 다음과 같이 model hyperparameter를 계산할 수 있다.
( 는 scaling hyperparameter)
5. Experimental Setup
이 연구는 4개의 baseline merging 기법들과 비교하고 있다.
- Simple Averaging : 각 task의 모든 모델의 element-wise mean 구하기
- Fisher Merging : Fisher Information Matrix를 이용해 task t에 대해 각 parameter의 중요도를 측정하여 각 fine-tune model의 파라미터를 reweighting하여 가중치합
- RegMean : 각 individual model과 합쳐진 모델의 activation 간의 거리를 최소화하는 least-squares regression problem에 대한 closed-form solution인 파라미터를 구한다.
- Task Arithmetic : 각 individual model에서 initial model의 파라미터를 element wise subtract하여 얻어지는 task vector를 더해 merged model을 만든다.
위의 merged model에 더해서, 각 dataset에 finetune 된 fine-tuned model과 모든 task의 dataset으로 훈련되어 있는 multi-task model의 성능도 함께 비교한다.
앞선 연구들은 Fisher matrix를 계산하거나 hyper parameter를 조정하기 위해 validation set에 접근하는 경우가 있다. 이를 피하기 위해 RegMean에서는 각 task의 training data의 inner product를 저장하고 전달하는 방법을 제안하였다. 이런 작업은 모델의 수나 크기가 커질수록 선형적으로 비용이 증가하곤 한다.
validation set에 접근하는 것이 불가능하다고 가정하고, 이 연구는 고정된 hyperparameter를 이용한 TIES-Merging의 일반적인 recipe를 개발하였으며, 이는 validation set을 이용할 때도 hyperparameter tuning이 필요하지 않다. 이 recipe는 task vector의 top-20%의 파라미터를 유지하고 나머지를 0으로 세팅하며, 를 0로 설정한다. 이 결과는 PETF(parameter-efficient fine-tuning)의 설정값에 기반하였으므로 ViT(vision)과 T5(language) 의 전체 모델의 unseen setting에만 적용한다.
또한, TIES-Merging은 validation set 없이 추천된 값인 0.4를 이용하여 task arithmetic과 비교하기도 한다.
6. Main Results
Merging PEFT models
TO-3B를 기본 모델로 사용, 11개의 데이터셋을 이용해 파인튜닝을 하고 IA라는 PEFT 모델을 이용하였으며, 평가는 Public Pool of Prompts (P3)의 프롬프트 템플릿을 사용하여 각 데이터셋의 예시를 text-to-text 형식으로 변환하고, 모든 템플릿의 중앙값 점수를 보고한다.
Merging Fully Finetuned Vision Models
Vision Model은 CLIP의 ViT-B/32와 ViT-L/14를 이용하며 8가지 이미지 분류 task에서 인코더를 finetune하였다.
Merging Fully Finetuned NLP Models
NLP model은 T5를 사용하고, 7가지 task에서 모델을 fully finetune하였다.
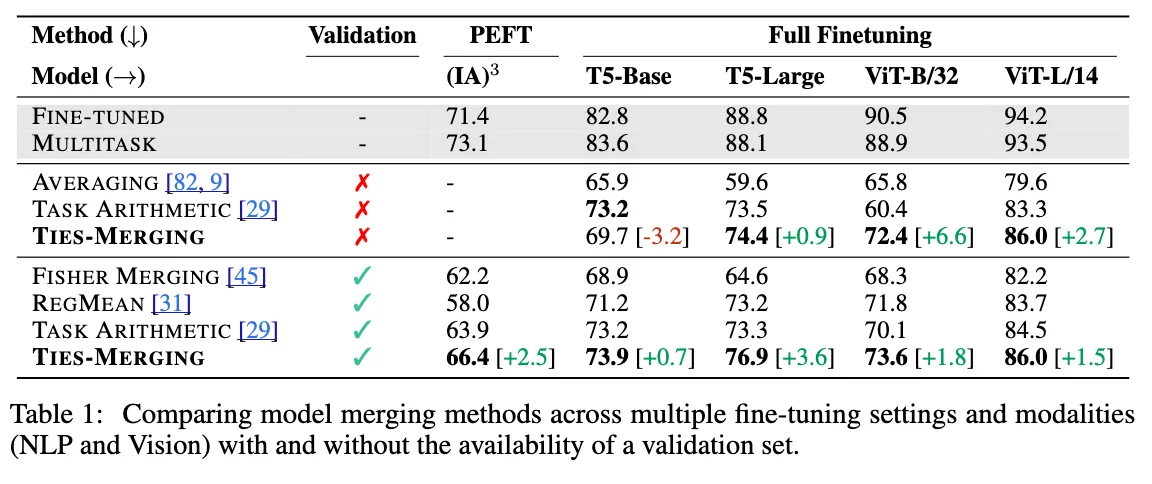
그 결과, PEFT의 경우 Validation set을 사용하는 다른 모든 baseline보다 높은 성능을 보였으며, full finetuning의 경우에도 T5-base에서 validation set을 사용하지 않은 경우를 제외하고 모두 성능이 높아짐을 알 수 있었다.
특히, Validation set을 사용하는 모든 경우에서 baseline보다 좋은 성능을 보였다.
Out-of-Domain Generalization
multi-task model들은 종종 domain shift를 하여 generalize를 더 잘하기 위해 사용되기도 한다. 이를 위해, 이 연구에서는 T5-base와 T5-large 모델을 7개의 도메인에서 merge하여 6개의 사용되지 않은 데이터셋에서 평가해보았다.
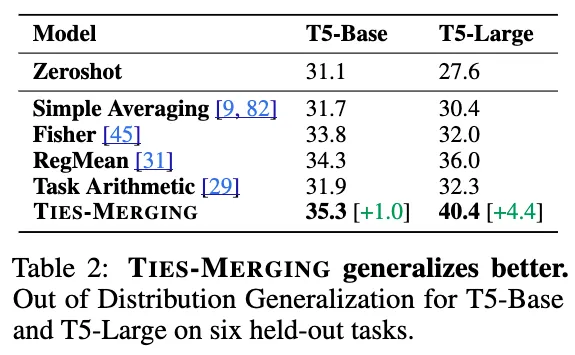
그 결과, TIES-Merging은 다른 4개의 baseline을 모두 뛰어넘는 결과를 보였다.
Merging Different Number of Tasks
merged model의 in-domain task를 측정할 때, task의 수를 다양하게 하여 측정해보았다.
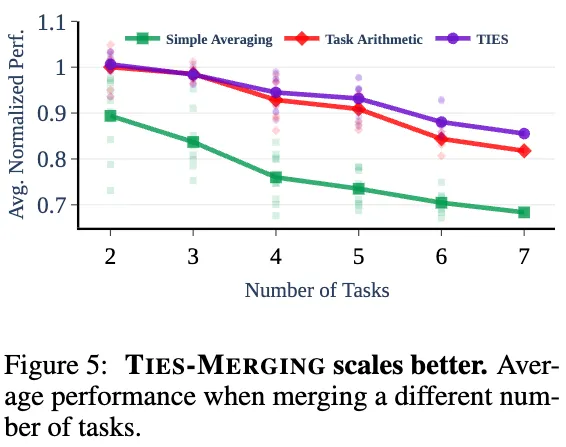
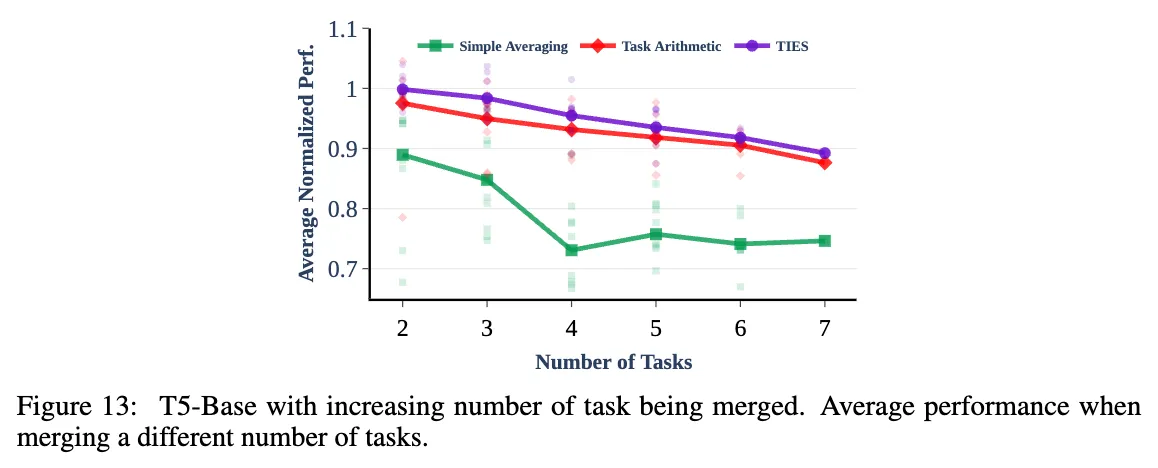
각 task의 정확도를 해당 fine-tune model의 정확도를 이용해 정규화하고, 그 평균값을 측정한 결과 다음과 같은 그래프를 얻을 수 있엇다. 이 결과에 따르면, TIES-Merging이 다른 방법(Strongest baseline; Task Arithmetic & Simple Merging)에 비해 좋은 성능을 얻을 수 있었다.
또한, 다음과 같은 사실을 관찰하였다:
- 모든 방법에서 합쳐지는 모델의 수가 늘어날수록 성능이 저하된다.
- 두 개의 task를 합칠 때, TIES-merging과 Task Arithmetic 모두 individual task일 때와 거의 동일한 성능을 보여, 무시할 정도의 성능 저하를 나타냈으며, 그에 비해 Simple Averaging은 10%가량의 성능 저하가 나타났다.
- task의 수가 늘어날수록 Task Arithmetic의 정확도가 낮아지는 정도가 TIES-Merging보다 급격했다. 이는 Task Arithmetic을 수행할 때 task inferterenece가 나타남을 암시한다.
Merging Checkpoints of the Same Task for Better Robustness
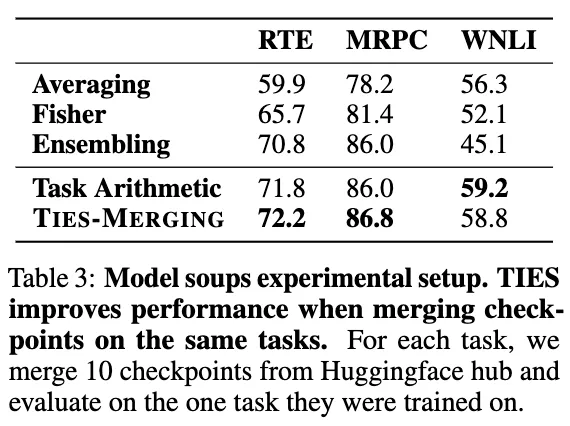
또한, 같은 task에 대해 훈련된 여러 checkpoint를 합치는 것이 robustness를 증가시키는지에 대해서도 실험해보았다. BERT 모델의 서로 다른 10개의 fine-tuned parameter를 사용하였으며 WNLI dataset를 제외한 모든 dataset에서 성능 향상을 보였다.(Table3) 특히, Averaging, Fisher merging, Ensembling보다 눈에 띄게 좋은 성능을 보이는 것을 알 수 있엇으며, 추가적인 실험을 통해 서로 다르게 finetune된 checkpoint 사이에서도 interference가 발생함을 알 수 있었다. (fig10)
Merging Models for Better Initialization
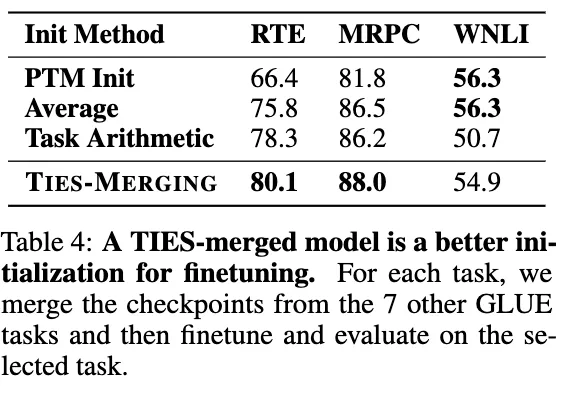
서로 다른 task의 checkpoint를 합쳐서 새로운 downstream task에 대해 finetuning 할 때 더 좋은 initialization을 제공할 수 있도록 실험해보았다. 이를 위해 huggungface의 8개의 GLUE task에 대한 bert-base-uncased checkpoint를 사용하였으며, 이중 3개의 task를 downstream task로 사용하였다. 하나의 task에 대해 downstream training을 할 때는 이를 제외한 다른 7개의 task를 사용하여 initial parameter를 만들었으며, WNLI를 제외한 다른 task에 대해 유의미하게 좋은 성능을 보였다.
7. Additional Results and Analysis
7.1. Types of Interference and Their Effect on Merging
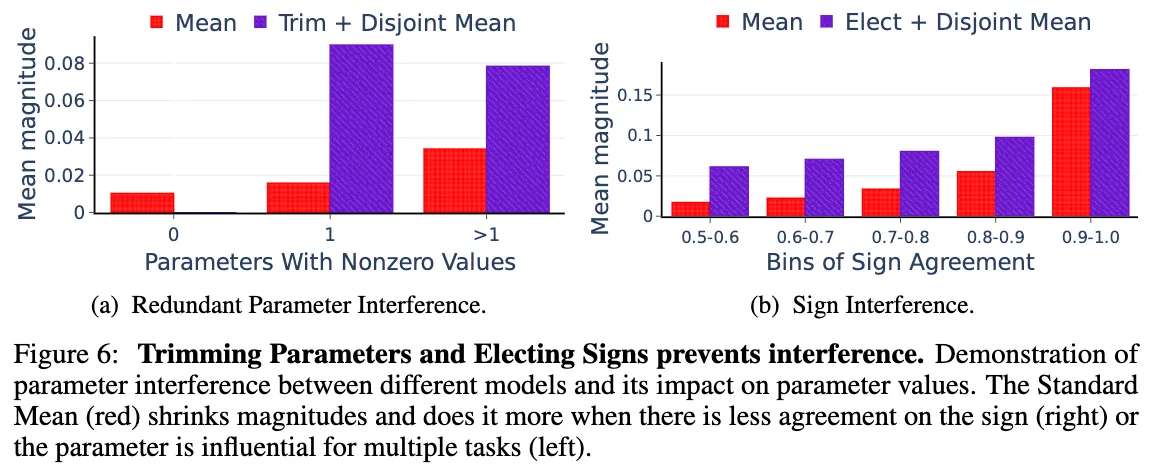
Importance of Removing Redundant Parameters
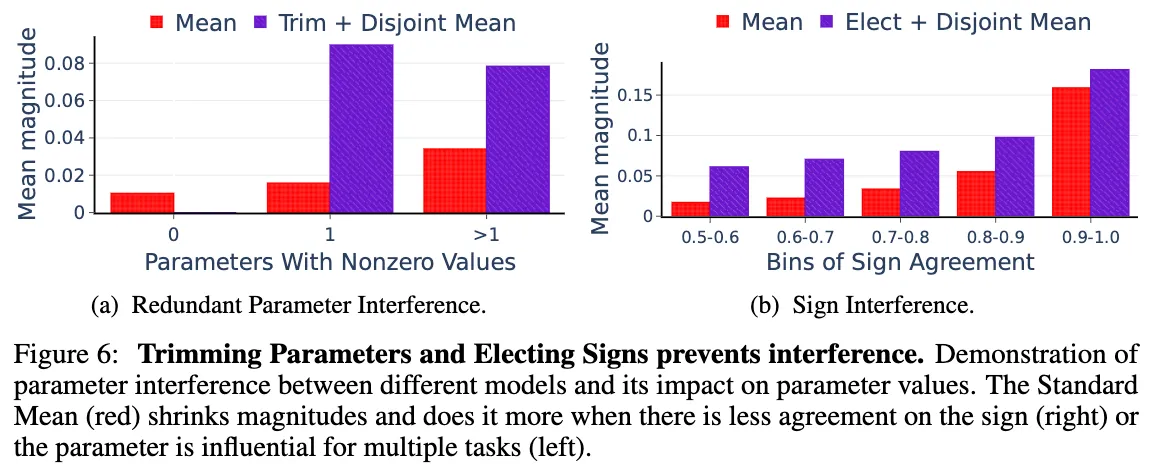
figure 6.a에서 보는 것과 같이 redundant parameter가 interference를 일으킴을 알 수 있다.
그냥 평균을 취하면 하나의 모델에서 influent한 Parameter도 다른 non-influent한 parameter 때문에 값이 작아지는 모습을 보이는데 비해, trimming을 이용하면 이러한 간섭이 줄어들어 mean magnitude가 상승하며, 평균적인 크기를 유지할 수 있게 되었다.
Importance of Resolving Sign Interfence
Sign Agreement 비율을 파라피터끼리 같은 부호를 가지는 비율이라고 정의할 때, Fig 6b와 같이 Sign agreement가 높을수록 원래 모델이 가지고 있던 mean maginitude가 높아짐을 볼 수 있었다.
7.2. Relevance of Signs of the Top-k% Parameters
이 실험에서는 (IA)^3 모델을 사용하여 실험하며, top-k Parameter의 중요성과 이들의 방향(부호)를 뒤집었을 때 task의 성능에 어떤 영향을 주는지 분석한다. 각 task vector에 대해 q의 확률로 top-k parameter를 뒤집는다. k와 p를 조정하며 실험하였으며, baseline으로 bottom-(100-k)% parameter를 뒤집는 경우를 상정하였으며 3번의 실험을 진행해 평균값을 사용하였다.
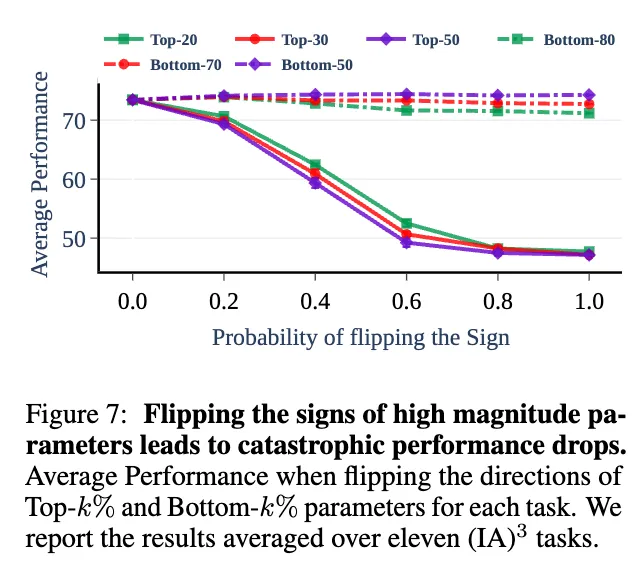
실험 결과, top-20,30,50% 의 파라미터를 뒤집는 것은 확률을 높일수록 성능 저하를 가지고 왔으나 bottom-80,70,50%의 파라미터를 뒤집는 것은 거의 성능 저하를 가지고 오지 않았다.
7.3. Ablation of TIES-Merging Components
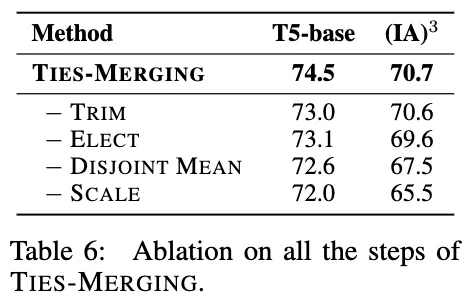
TIES의 각 부분을 제거하여 실험해본 결과, 각 부분이 성능 향상에 기여함을 알 수 있었다.
7.4. Importance of Estimating Correct Signs When Merging Models

모델을 합칠 때, 한 parameter의 부호를 추정하는 것에 대해 알아보자. 단순히 TIES-Merging을 한 경우보다, multitask에 대해 훈련시킨 후 해당 모델의 각 parameter의 부호를 그대로 TIES-Merging 모델에 sign vector로 적용한 경우 눈에 띄게 상승된 정확도를 보였다.
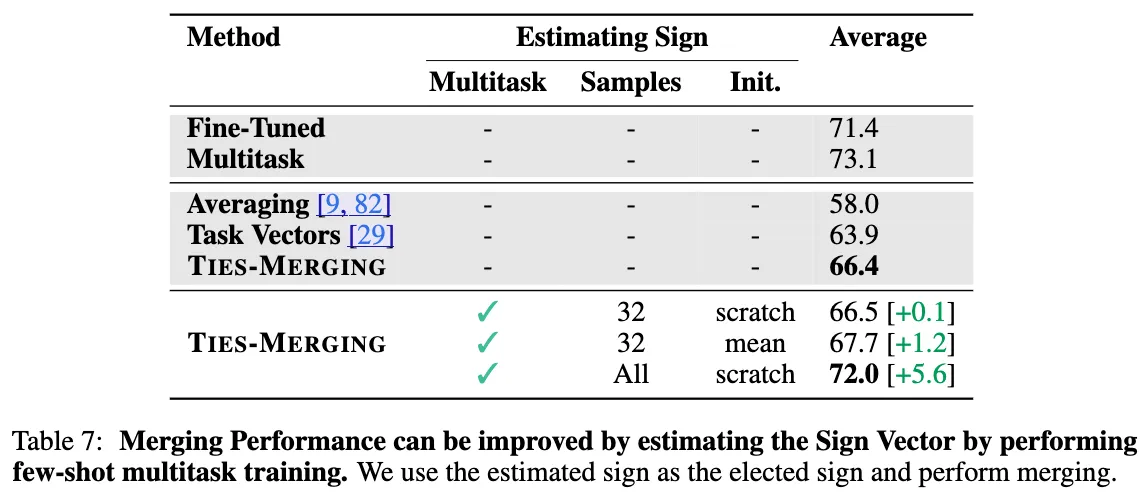
또한, few-shot multitask training만을 통해 부호만 추정해서 적용해본 결과에도 더 좋은 성능을 보임을 알 수 있었다.
8. Conclusion
TIES-Merging은 fine-tune model에서 작은 크기로 변화한 parameter들을 trim하고, 합쳐지는 모델 간의 sign disagreement를 해결한다. 이를 통해 고정된 hyperparameter에서도 다른 다양한 세팅과 환경에서 merge되는 모델들보다 좋은 성능을 보임을 알 수 있었다. 또한, 해당 연구는 모델 파라미터 간의 간섭에 대한 중요성과 합치는 과정에서 파라미터의 부호의 중요성을 강조한다.
Limitations
- weight interpolation이 왜 성능을 보이는지에 대한 이론적인 이해가 부족하다.
- 위와 같은 merging은 같은 initialization과 구조를 가지는 모델에 대해서만 성립한다.
- individual task model들을 합치는 것은 아직 simultaneous multitask training의 성과보다 뒤처진다.
- 또한, 여러 domain에서 성립하는 multitask model을 만들기 위해 개별 모델의 어떤 checkpoint를 사용해야 하는지도 불분명하다.
- TIES-Merging에서 각 parameter의 부호를 추정하는 zero-shot method를 제안하긴 하였으나 아직 multitask model의 부호를 사용하는 것이 더 유효하다.
Additional Results
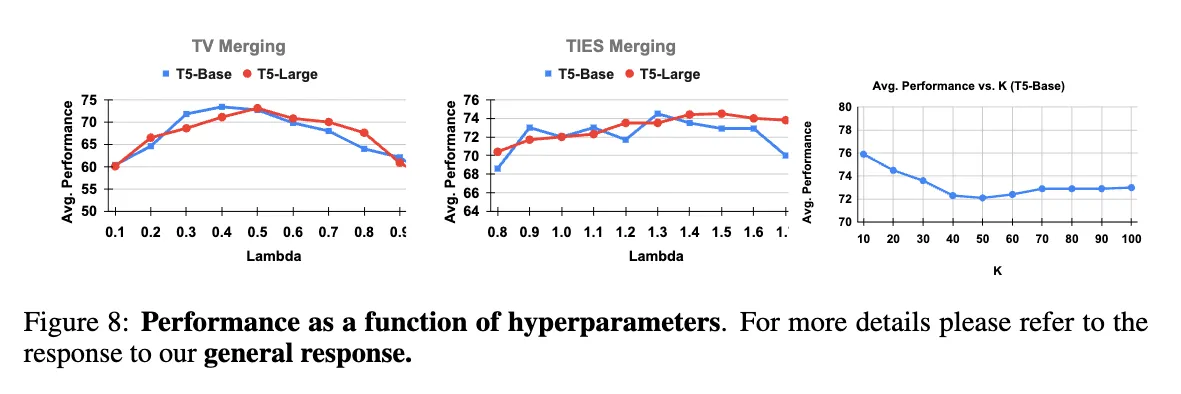
lambda 값을 조정함에 따른 정확도 변화. TIES-Merging은 이미 일종의 mean value이므로 lambda가 1인 것을 기본으로 한다. 이때, Task Arithmetic에 비해서 lambda의 변화에 덜 민감함을 알 수 있었다.
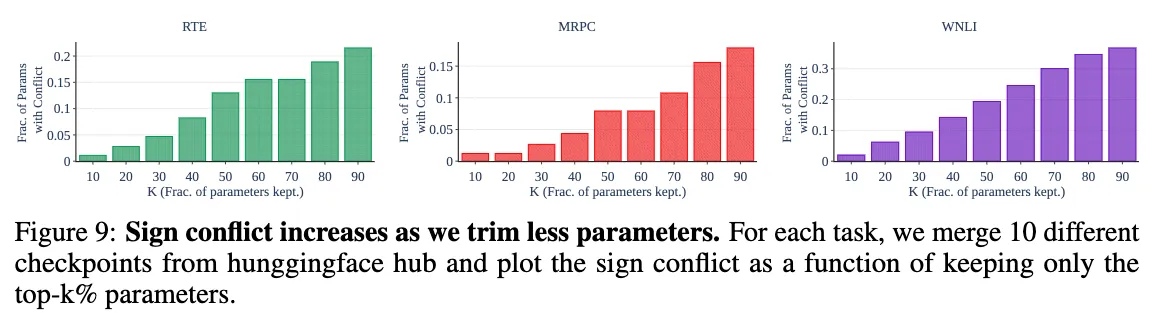
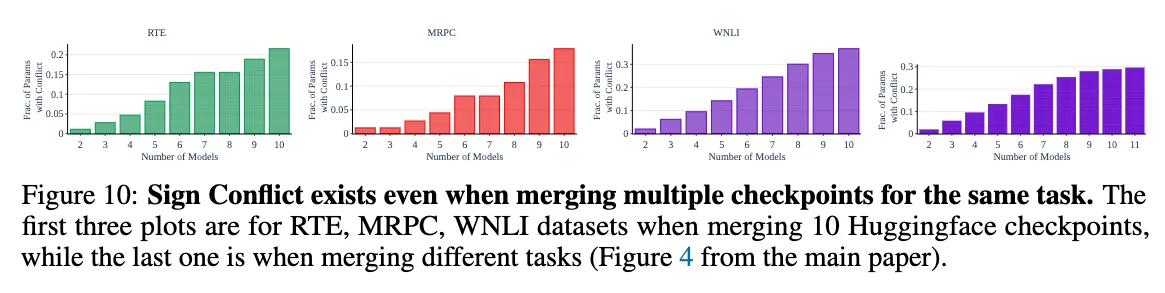
같은 task에 대해 서로 다른 checkpoint를 합칠 때도 모델의 수가 늘어남에 따라 Sign Conflict가 늘어남을 알 수 있었다.
