논문리뷰
1.REVIEW: Editing Models With Task Arithmetic
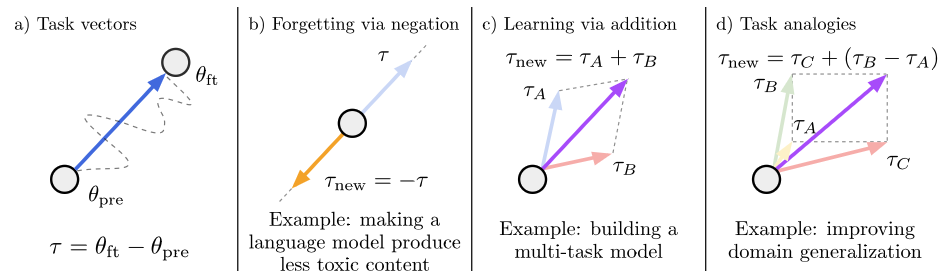
이 논문은 특정 pre-trained model의 행동을 바꾸는, 즉 새로운 downstream task의 성능을 높이거나 편향을 제거하는 등의 일을 하기 위해 task vector라는 새로운 개념을 제안한다.
2025년 6월 15일
2.REVIEW : VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos
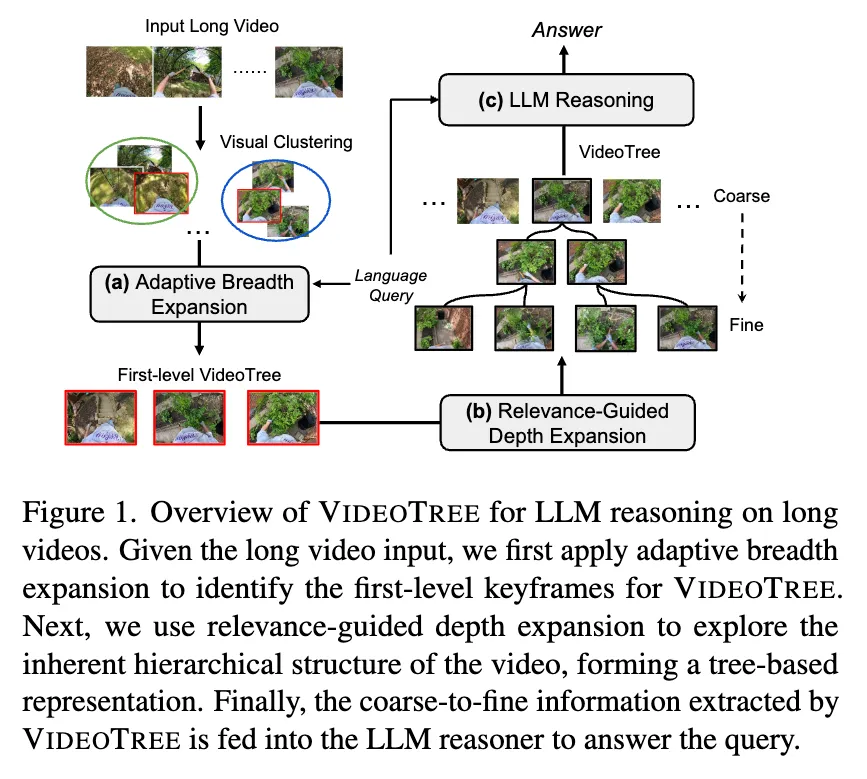
VideoTree is a adaptive, hierarchical framework of training-free long-form video understanding using LLM agent.
2025년 7월 29일
3.REVIEW : VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding

VideoAgent is a multimodal agentic video understanding model that utilizes a structured, unified memory capturing both temporal events and object-cent
2025년 7월 29일
4.REVIEW : TIES-Merging: Resolving Interference When Merging Models
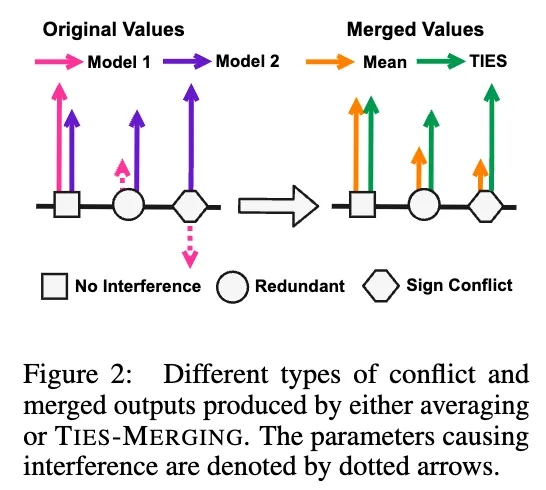
Trimming redundant parameters and resolving sign conflicts in model merging step helps to address interference between parameters
2025년 8월 11일
5.REVIEW : DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent)
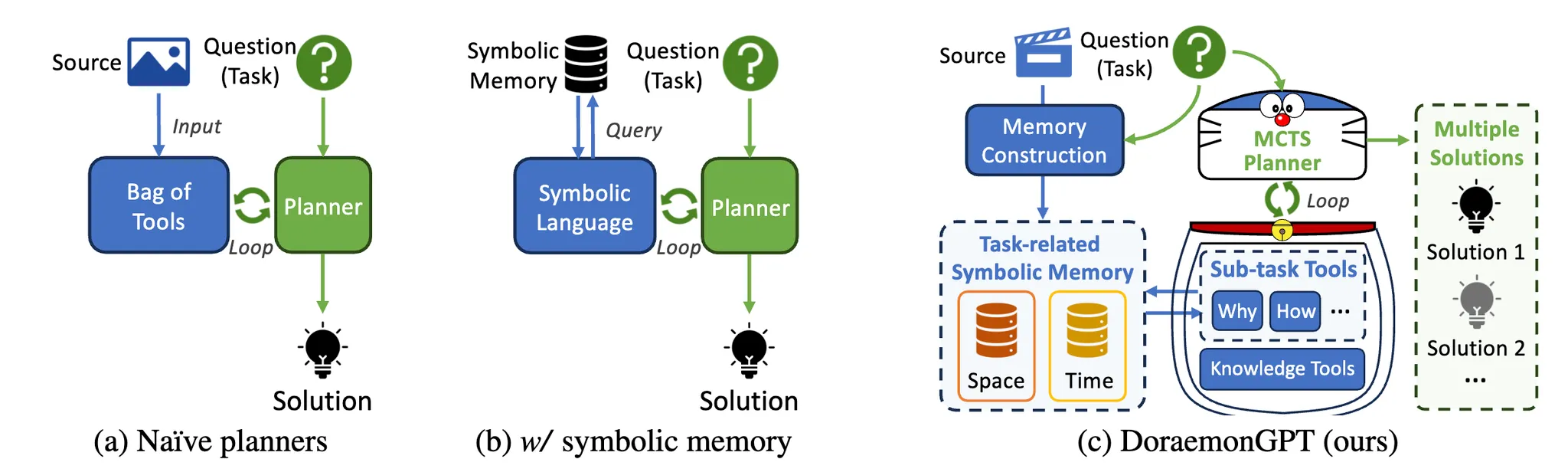
DoraemonGPT is a Video Agent based on LLM that understands dynamic scenes.
2025년 8월 11일