인공지능 > 머신러닝 > 딥러닝
인공지능
- 기계가 인간처럼 지능적인 행동을 할 수 있도록 하는 모든 기술
- 사람의 인지 능력을 기계가 모방하려고 하는 모든 시도를 포함하는 굉장히 큰 기술임
머신러닝
- 인공지능의 하위 분야
- 명시적으로 어떤 프로그래밍이 되어 있지 않아도, 많은 데이터로부터 학습을 하고 결정할 수 있는 시스템을 만드는 기술
- 데이터로부터 패턴을 인식하고, 그 패턴을 기반으로 결과를 예측하는 모델(=패턴 인식)
딥러닝
- 머신러닝의 하위 분야
- 다층 신경망 모델(Deep Neural Network)을 이용해 복잡한 데이터의 패턴을 학습
머신러닝이란?
- 컴퓨터가 경험을 통해 성능을 향상시키는 알고리즘을 연구하는 학문
- 제대로 정의된 학습 과제는 <P, T, E> 에 의해 주어짐. (Tom Mitchell의 정의)
-> 어떤 작업 T에 대해 / 경험 E와 함께 / 성능 P를 향상시킴.
# 예시: 이미지 분류
T: 주어진 이미지가 고양이인지 개인지 분류하는 작업
E: 다양한 고양이와 개 이미지 학습 데이터셋
P: 이미지 분류 정확도예시:
- 이미지 분류: 주어진 이미지가 고양이인지 개인지 분류하는 작업
- 스팸 메일 필터링: 이메일을 스팸인지 아닌지 분류하는 작업
전통적 프로그래밍 vs 머신러닝
- 전통적 프로그래밍 = 데이터 + 프로그램 -> 컴퓨터 -> 출력값
예시) 정렬되지 않은 array + 정렬 알고리즘 -> 컴퓨터 -> 정렬된 array - 머신러닝 = 데이터 + 출력값 -> 컴퓨터 -> 프로그램
예시) 수많은 class의 이미지, 레이블 -> 컴퓨터 -> 분류 모델
머신 러닝의 적용 사례
- 컴퓨터 비전: 이미지 및 객체 인식
- 문자 인식: 필기체 및 문서 인식
- 음성 인식: 음성을 텍스트로 변환
- 자연어 처리: 텍스트 번역, 감정 분석 등
학습의 종류
지도 학습(=귀납적 학습) (Supervised Learning)
- label된 데이터로 predictive model을 학습
- 딥러닝의 많은 방법론이 지도 학습에 속함
- 주요 응용: 회귀(Regression)와 분류(Classification)
비지도 학습 (Unsupervised Learning)
- label이 없는 데이터 로 학습하며, 데이터의 숨겨진 구조를 파악
- input에 있는 본연의 성질을 이용해 패턴을 학습
- 주요 응용: 클러스터링(군집화)
강화 학습 (Reinforcement Learning)
- 보상이 있는 상태와 액션의 시퀀스가 주어졌을 때, policy를 출력
- policy = 주어진 상태에서 수행해야할 작업을 알려주는 상태->작업 형식의 매핑
- agent(예: 로봇)을 만들어 특정 환경에 던져 놓음 -> agent는 환경과 interaction 하며 스스로 기술을 자동으로 습득
- 주요 응용: 게임 플레이(알파고, Dota 2), 로봇 제어, 자율 주행
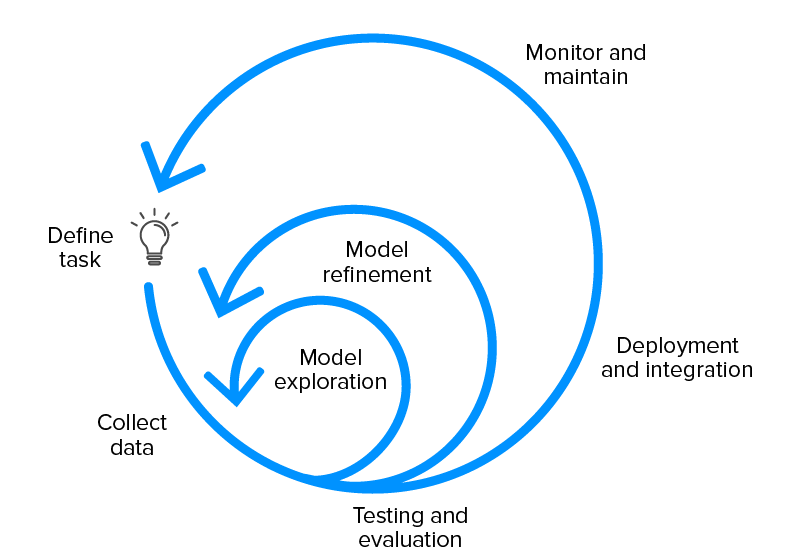
ML Life Cycle
- 머신러닝 모델을 개발, 배포, 유지보수하는 모든 단계를 정의하는 Life Cycle
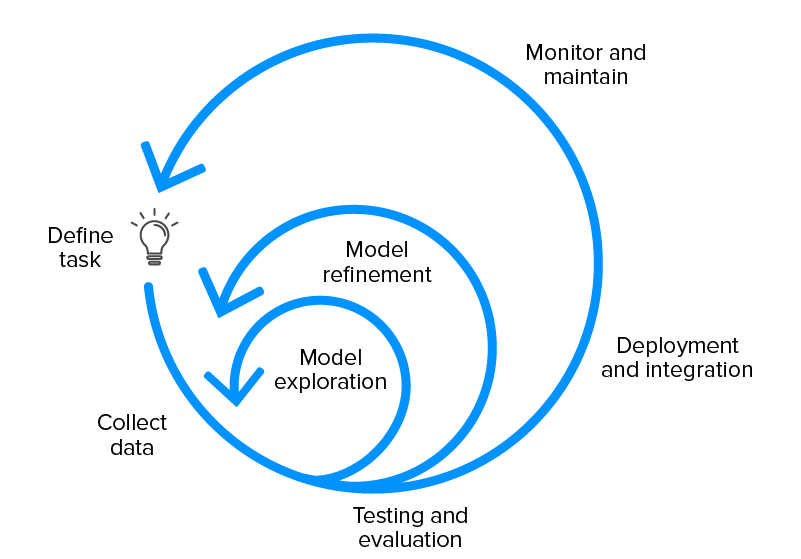
직무별 ML Life Cycle
- 데이터 엔지니어: 데이터 수집 및 전처리(Data collection, pre-processing, cleaning)
- 데이터 사이언티스트: 코드 작성, 머신러닝 모델 구축
- ML 엔지니어, 개발자: 배포 및 프로덕트화
1. 계획하기 (Planning)
- ML 애플리케이션의 범위, 성공 지표, 실현 가능성을 평가
- 비즈니스와 머신 러닝을 활용하여 현재 프로세스를 개선할 방법을 모색
- 명확하고 측정 가능한 성공 지표를 정의하고 타당성 보고서를 작성
2. 데이터 준비 (Data Preparation)
- 데이터 수집 및 라벨링
- 데이터 정리
- 데이터 처리
- 데이터 관리
3. 모델 엔지니어링 (Model Engineering)
- 모델 아키텍처를 구축하고 메트릭을 정의
- 학습 및 검증 데이터셋으로 모델을 학습, 검증
- 모델 압축 및 앙상블 수행
- 도메인 지식 전문가를 통해 결과 해석
4. 모델 평가 (Model Evaluation)
- 모델이 제품으로 사용될 준비가 되었는지 확인하기 위해 모델을 평가
- 테스트 데이터셋으로 모델을 테스트하고 전문가의 피드백을 통해 예측 오류를 파악
- 산업적, 윤리적, 법적 프레임워크를 준수하는지 확인
- 무작위 및 실제 데이터에 대한 견고성(robustness) 테스트
- 결과와 계획된 성공 지표를 비교해 모델 배포 여부 결정
5. 모델 배포 및 모니터링 (Model Deployment and Monitoring)
- 머신러닝 모델을 시스템에 배포
- 배포 후 지속적으로 시스템을 모니터링 및 개선
- 모델 지표, 하드웨어 및 소프트웨어 성능, 고객 만족도를 모니터링하여 성능을 최적화
Outro

LLM Safety 일짱이 되겠다.