ICLR 2025 [Paper] [Code]
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, Jianfeng Gao
Tsinghua University | Microsoft Corporation
8 Feb 2025
Introduction
LLM 기반 대화형 에이전트를 실제 서비스에서 쓰려면 여러 세션에 걸쳐 쌓인 대화를 기억하고, 현재 사용자 요청에 맞는 정보를 다시 찾아와야 합니다. 기존 접근은 대체로 전체 conversation history를 prompt에 붙이거나, 과거 대화를 summary로 압축하거나, turn-level 또는 session-level 단위로 memory bank를 만든 뒤 retrieval augmented response generation을 수행하는 방식이었습니다.
이 논문이 집중하는 지점은 memory construction에서 가장 기본적인 선택지인 memory unit granularity입니다. Turn-level memory는 단위가 너무 작아 관련 정보가 여러 turn에 흩어지기 쉽습니다. 반대로 session-level memory는 한 unit 안에 서로 다른 topic이 함께 들어갈 수 있습니다. Summarization-based memory는 context 길이를 줄이는 데는 유리하지만, QA에 필요한 세부 근거가 summary 과정에서 빠질 위험이 있습니다.
저자들은 이 문제를 다루기 위해 SeCom을 제안합니다. SeCom은 conversation history를 topic 단위의 Segment로 나누어 memory bank를 만들고, retrieval 전에 prompt Compression을 적용해 memory unit의 redundancy를 줄입니다. 다시 말해 memory를 “얼마나 길게 저장할 것인가”뿐 아니라, “retrieval을 방해하는 noise를 어떻게 덜어낼 것인가”까지 함께 다루는 방법입니다.
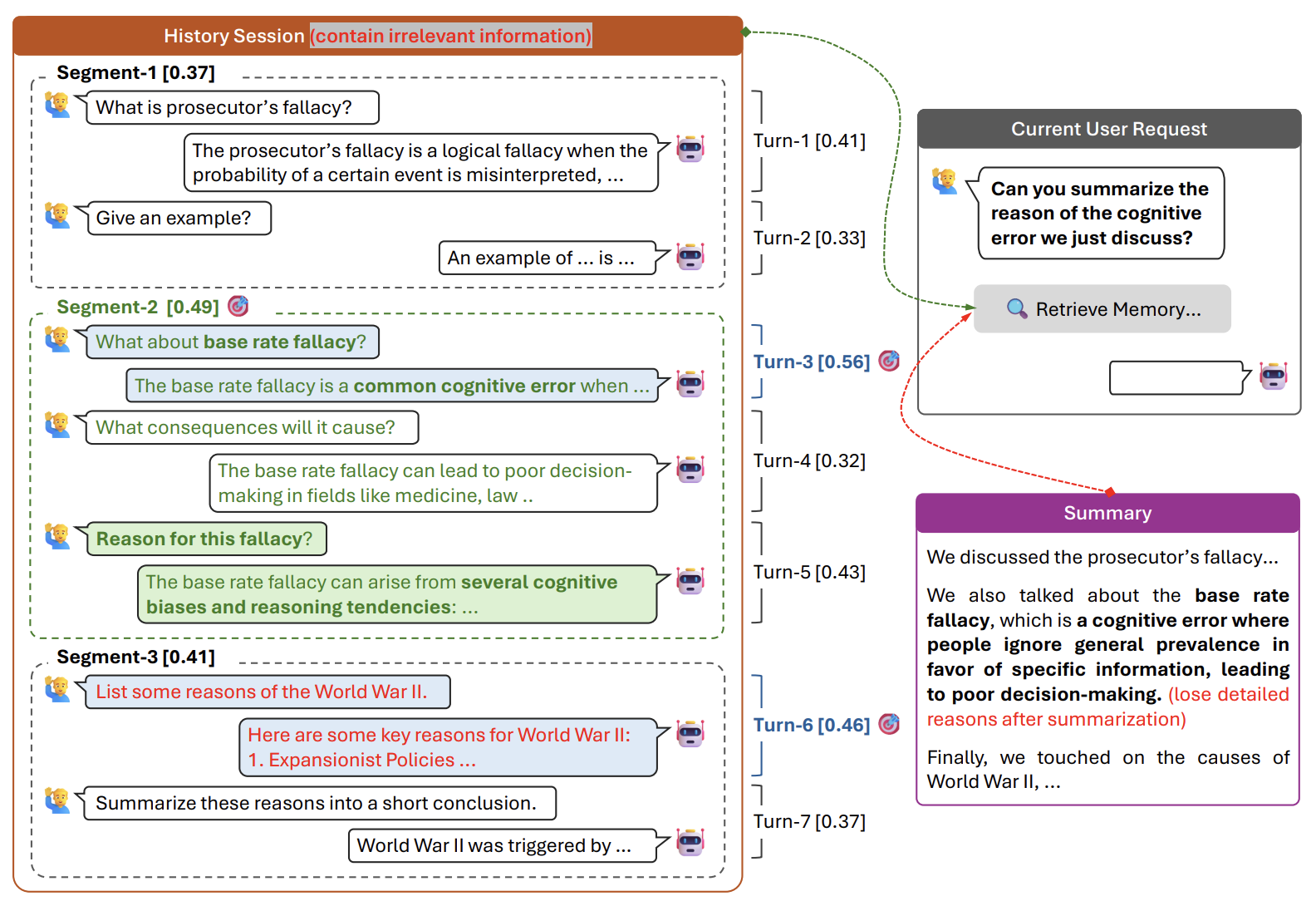
[Figure 1. turn-level, session-level, summary-based memory와 segment-level memory의 context 품질 차이]
Figure 1을 보면 논문의 문제의식이 바로 드러납니다. Turn-level memory는 query와 직접 겹치는 일부 turn만 고르다가 대화 흐름을 놓칠 수 있습니다. Session-level memory는 필요한 정보와 상관없는 topic까지 함께 가져옵니다. Summary-based memory는 짧지만, 원문에 있던 근거가 사라질 수 있습니다. SeCom의 segment-level memory는 topic coherence를 기준으로 memory unit을 구성해 세 방식 사이의 중간 지점을 찾습니다.
SeCom
Preliminary
논문에서는 long-term conversation을 여러 session으로 이루어진 history로 정의합니다. 전체 conversation history는 다음처럼 둘 수 있습니다.
- : 사용 가능한 conversation history
- : session 수
- 각 session 는 순차적인 interaction turn으로 구성됨.
- : i번째 session의 turn 수
- : user request 와 agent response 로 이루어진 하나의 interaction turn
기본 retrieval augmented response generation은 세 단계로 정리됩니다. 먼저 conversation history 에서 memory bank 을 만듭니다. target request 가 주어지면 retrieval system 이 관련 memory unit 개를 가져옵니다.
마지막으로 response generation model 은 검색된 memory unit을 context로 삼아 응답 를 생성합니다.
이 formulation에서 핵심 변수는 입니다. 같은 retrieval model과 generation model을 쓰더라도 memory bank를 turn-level, session-level, summary-level, segment-level 중 어떤 단위로 구성하느냐에 따라 검색 품질과 최종 응답이 달라집니다.
Method
Conversation Segmentation
SeCom은 하나의 session을 topic coherence가 유지되는 여러 segment로 나눕니다. Conversation segmentation model 는 session 를 입력으로 받아 segment index 집합을 예측합니다.
- : session 안의 segment 수
- : 번째 segment
- , : 해당 segment의 시작 turn과 마지막 turn index
- 연속된 segment가 대화를 빠짐없이 덮도록 조건도 둡니다.
저자들은 open-domain conversation segmentation을 위해 GPT-4를 zero-shot segmentation model로 사용합니다. 이때 원본 session에 turn index와 role identifier를 붙여 모델이 대화 흐름을 더 분명하게 읽도록 합니다. 각 turn은 예를 들어 Turn j, [user], [agent] 형식으로 정리됩니다.
Annotated segmentation data가 일부 있을 때는 reflection mechanism을 적용합니다. 모델이 segmentation을 수행한 뒤 WindowDiff 기준으로 error가 큰 hard example을 고릅니다. 이어서 LLM이 자신의 segmentation mistake를 분석하고 segmentation guidance를 갱신합니다. 논문은 이 과정을 SGD와 비슷한 prompt-level optimization으로 봅니다. 실제 parameter를 업데이트하는 대신 segmentation rubric을 반복해서 다듬는 방식입니다.
Compression based Memory Denoising
SeCom의 두 번째 구성 요소는 compression based memory denoising입니다. 자연어 대화에는 반복, filler, 부연 설명, topic drift가 쉽게 섞입니다. 이런 redundancy는 retrieval model이 query와 memory 사이의 relevance signal을 잡는 데 방해가 됩니다.
SeCom은 memory retrieval 전에 memory bank를 prompt compression model로 처리합니다.
여기서 는 memory unit을 압축하는 함수입니다. 논문에서는 LLMLingua-2를 사용합니다. 이 압축은 generation 단계의 context를 줄이기 위한 장치에 그치지 않습니다. retrieval 전에 불필요한 token을 제거해 관련 segment가 더 잘 검색되도록 만드는 denoising 역할도 합니다.
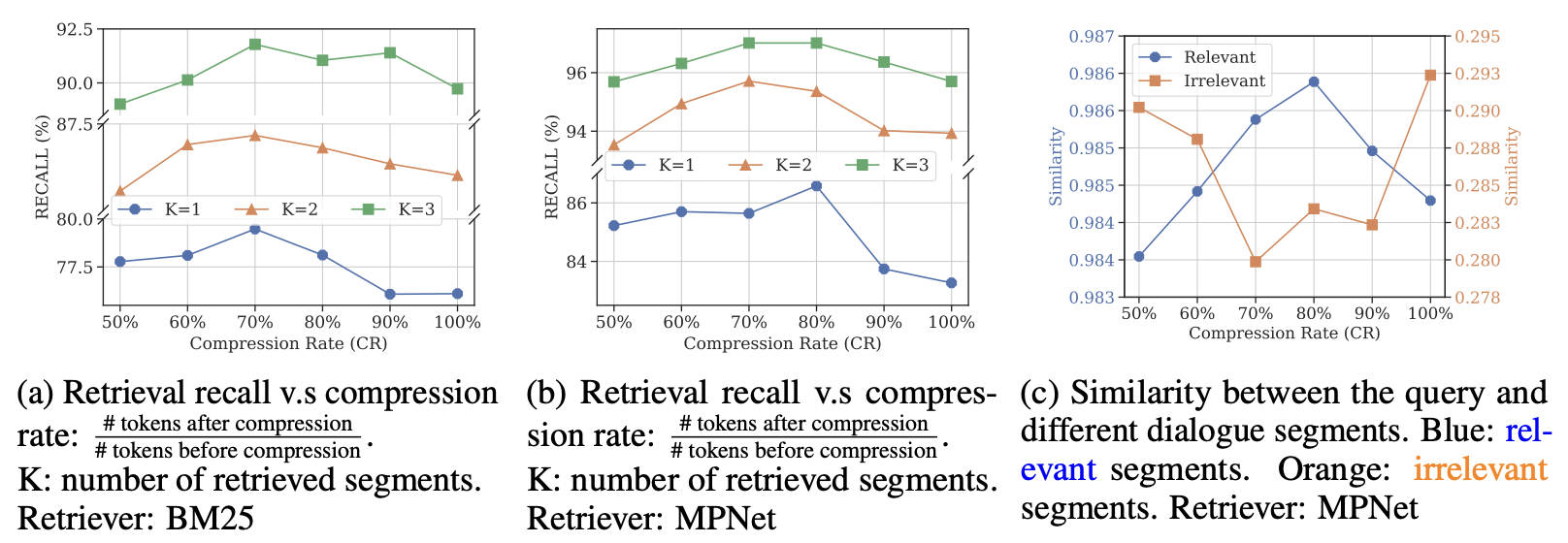
[Figure 3. LLMLingua-2 compression rate에 따른 retrieval recall과 relevant/irrelevant segment similarity 변화]
Figure 3은 compression이 retrieval에 어떤 영향을 주는지 보여줍니다. BM25와 MPNet retriever 모두 일정 compression rate 이상에서 recall이 개선됩니다. compression 이후 query와 relevant segment의 similarity는 올라가고, irrelevant segment와의 similarity는 낮아지는 경향도 나타납니다. prompt compression이 단순한 token reduction이 아니라 retrieval signal을 정제하는 과정으로도 작동한다는 해석이 가능합니다.
Experiments
논문은 SeCom을 long-term conversation QA와 dialogue segmentation 두 축에서 평가합니다. Response generation에는 주로 GPT-35-Turbo를 사용했고, robustness를 확인하기 위해 Mistral-7B-Instruct-v0.3도 함께 사용했습니다. Retrieval model은 BM25와 MPNet 기반 retriever를 모두 실험합니다. Compression에는 LLMLingua-2를 쓰며, 주요 실험의 compression rate는 75%입니다.
Long-term conversation benchmark로는 LOCOMO와 Long-MT-Bench+를 사용합니다. LOCOMO는 평균 300 turns와 9K tokens 수준의 긴 conversation으로 설명되며, Long-MT-Bench+는 MT-Bench+를 long-range QA 형태로 재구성한 benchmark입니다. 평가 지표에는 BLEU, ROUGE, BERTScore, GPT4Score가 포함됩니다. 저자들은 GPT-4를 이용한 pairwise comparison도 함께 수행했습니다.
Baseline은 네 부류로 나뉩니다. Zero History는 과거 대화를 전혀 사용하지 않고, Full History는 전체 history를 context에 넣습니다. Turn-Level과 Session-Level은 memory granularity를 달리한 retrieval baseline입니다. SumMem, RecurSum, ConditionMem, MemoChat은 기존 memory management 또는 summarization 기반 접근을 대표합니다.
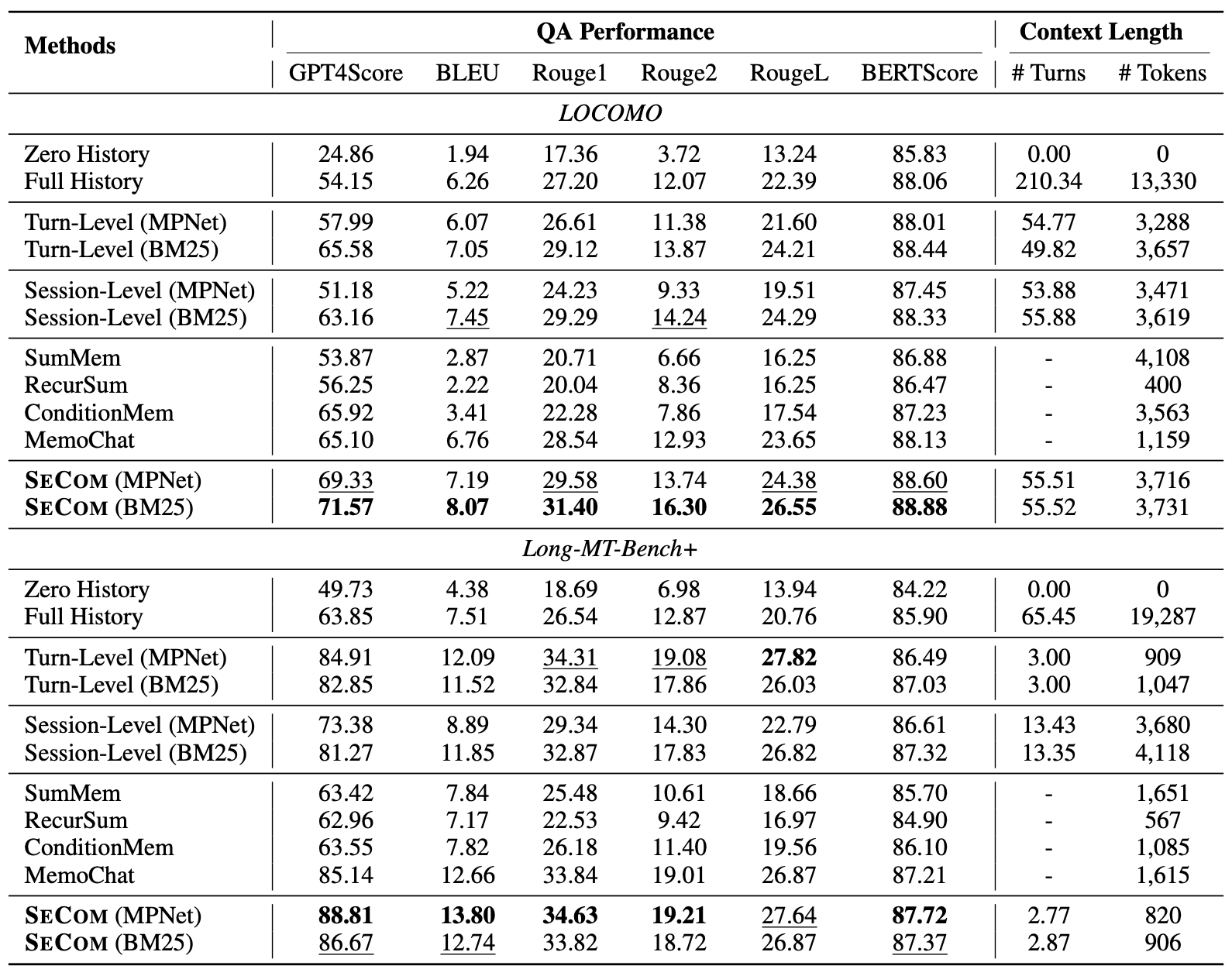
[Table 1. LOCOMO와 Long-MT-Bench+에서 SeCom과 baseline의 QA 성능 비교]
Table 1에서 SeCom은 두 benchmark 모두에서 강한 성능을 보입니다. LOCOMO에서는 SeCom(BM25, GPT4-Seg)이 GPT4Score 71.57을 기록해, 가장 높은 baseline인 ConditionMem의 65.92를 앞섭니다. Long-MT-Bench+에서는 SeCom(MPNet, GPT4-Seg)이 GPT4Score 88.81을 기록했고, MemoChat의 85.14보다 높습니다.
차이는 LOCOMO에서 더 뚜렷합니다. LOCOMO는 대화가 길고 topic이 여러 session에 걸쳐 흩어져 있어 memory construction의 영향이 크게 드러나는 설정입니다. Long-MT-Bench+는 평균 turn 수가 더 짧기 때문에 baseline도 상대적으로 높은 점수를 얻습니다.
흥미로운 부분은 retriever에 따른 민감도입니다. Turn-Level과 Session-Level은 BM25와 MPNet 중 어떤 retriever를 쓰느냐에 따라 GPT4Score가 크게 달라집니다. SeCom은 두 retrieval setting에서 비교적 안정적인 성능을 보입니다. Segment-level memory가 fragmentary context와 irrelevant context 사이의 균형을 맞추기 때문으로 해석할 수 있습니다.
Evaluation of Conversation Segmentation Model
저자들은 conversation segmentation module 자체도 별도로 평가합니다. 사용한 dataset은 DialSeg711, TIAGE, SuperDialSeg입니다. 평가 지표는 Pk, WindowDiff, F1, segment score입니다.
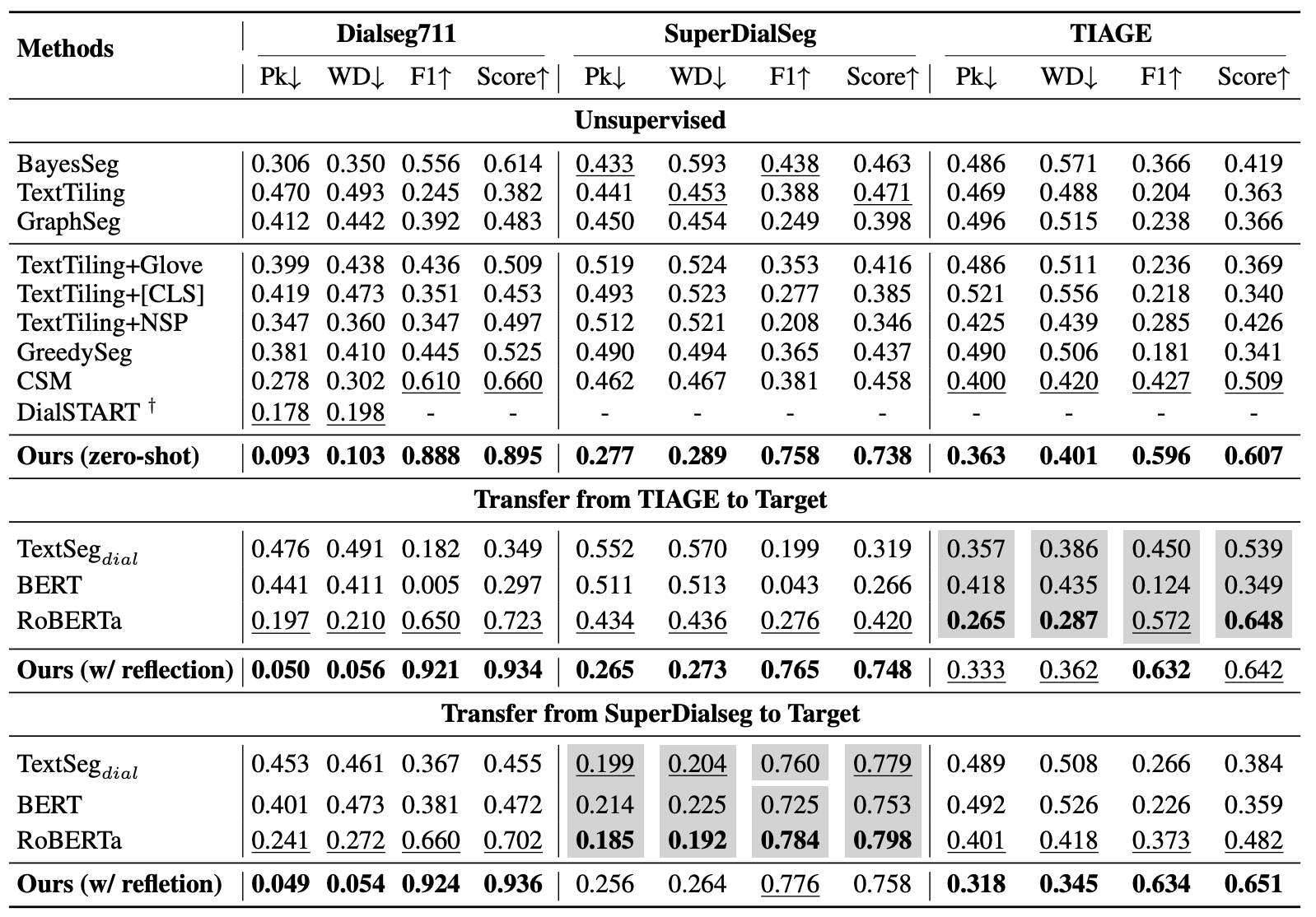
[Table 4. DialSeg711, SuperDialSeg, TIAGE에서 conversation segmentation model의 성능 비교]
Table 4에서 GPT-4 기반 zero-shot segmentation은 unsupervised baseline보다 전반적으로 나은 성능을 냅니다. Limited annotated data가 있는 transfer learning setting에서는 reflection으로 학습한 segmentation guidance가 쓰입니다. 이 경우 모델은 source dataset의 hard example 100개만으로 rubric을 개선하지만, 일부 target dataset에서는 full training set으로 학습된 baseline보다 좋은 결과를 보입니다.
Analysis
SeCom의 이점은 segment-level memory와 compression-based denoising이 함께 작동할 때 분명해집니다. Segment-level memory는 turn-level보다 문맥을 더 보존하고, session-level보다 불필요한 topic을 덜 끌고 옵니다. 이 granularity는 long-term conversation에서 자주 생기는 topic shift를 memory construction 단계에서 반영합니다.
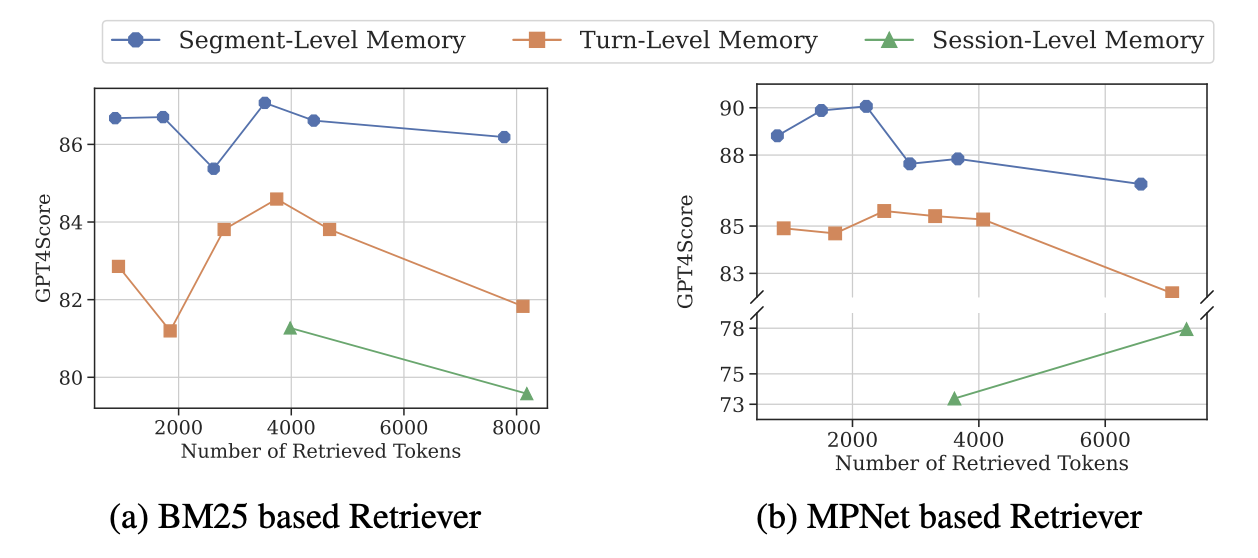
[Figure 5. context budget 변화에 따른 memory granularity별 GPT4Score 비교]
Figure 5는 context budget이 달라져도 segment-level memory가 turn-level과 session-level보다 일관되게 높은 성능을 내는 흐름을 보여줍니다. 단순히 더 많은 token을 넣는 방식이 항상 답은 아니라는 뜻입니다. Retrieval unit이 너무 작으면 필요한 근거가 잘리고, 너무 크면 irrelevant information이 섞입니다.
Compression-based denoising도 별도로 기여합니다. Table 2에서 denoising을 제거하면 LOCOMO 기준 GPT4Score가 69.33에서 59.87로 떨어집니다. Long-MT-Bench+에서는 88.81에서 87.51로 감소합니다. 두 benchmark에서 하락 폭이 다른 이유는 대화 길이와 noise 구조의 차이로 볼 수 있습니다. LOCOMO처럼 긴 history에서는 redundant token과 topic drift가 retrieval에 더 큰 영향을 주므로 compression 효과가 더 크게 나타납니다.

[Table 2. compression-based memory denoising 제거에 따른 성능 변화]
Full History의 한계도 눈에 띕니다. Mistral-7B-Instruct-v0.3은 32K context window를 갖고 있어 Long-MT-Bench+ 전체 history를 넣을 수 있지만, Full History는 SeCom보다 낮은 성능을 보입니다. long context window가 retrieval-free memory management를 곧바로 대체하지는 못한다는 결과입니다. 모델이 긴 context를 받을 수 있더라도, 관련 정보가 얼마나 잘 정리되어 들어가는지가 응답 품질에 영향을 줍니다.
물론 trade-off도 있습니다. GPT-4 기반 segmentation은 가장 좋은 결과를 내지만 비용과 latency가 따릅니다. 논문은 Mistral-7B와 RoBERTa 기반 segmentation도 실험하지만, 성능은 GPT-4-Seg보다 낮습니다. Compression rate를 지나치게 높이면 필요한 정보까지 제거될 수 있습니다. 따라서 SeCom을 실제 시스템에 적용하려면 segmentation model, retriever, compression rate, context budget을 함께 조정해야 합니다.
Limitations
이 논문은 memory construction과 retrieval granularity를 비교적 분명하게 분석하지만, 남는 한계도 있습니다.
우선 가장 좋은 결과가 GPT-4 기반 segmentation에 의존합니다. 저자들은 Mistral-7B와 RoBERTa-scale model도 사용할 수 있음을 보였지만, 특히 RoBERTa-Seg 설정에서는 성능 하락이 관찰됩니다. Resource-constrained environment에서 SeCom을 쓰려면 segmentation 품질과 비용 사이의 절충이 필요합니다.
평가의 중심이 long-term conversation QA에 놓여 있다는 점도 한계입니다. LOCOMO와 Long-MT-Bench+는 memory retrieval을 분석하기 좋은 benchmark이지만, 실제 personalized conversational agent에서는 memory update, deletion, privacy control, user-specific preference drift 같은 문제가 함께 생깁니다. 이 논문은 memory를 어떻게 저장하고 검색할지에 초점을 맞추며, 장기 서비스 운영에 필요한 memory governance까지 다루지는 않습니다.
Compression-based denoising도 항상 안전한 연산은 아닙니다. LLMLingua-2가 redundant token을 제거해 retrieval을 개선하더라도 task에 따라 세부 근거가 압축 과정에서 약해질 수 있습니다. 논문 결과에서는 75% compression rate가 효과적이지만, 다른 domain이나 multilingual dialogue에서도 같은 설정이 최적이라고 보기는 어렵습니다.
마지막으로 SeCom은 retrieval pipeline의 여러 component를 조합하는 방식입니다. Segmenter, compressor, retriever, generator가 각각 독립적으로 작동하므로 error propagation이 생길 수 있습니다. 예를 들어 segmentation boundary가 잘못 잡히면 compression과 retrieval은 그 오류를 전제로 수행됩니다. End-to-end로 memory construction policy를 학습하는 방향은 후속 연구로 남아 있습니다.
Conclusion
이 논문은 personalized conversational agent에서 memory bank를 어떤 단위로 구성해야 하는지 체계적으로 살펴봅니다. Turn-level, session-level, summarization-based memory는 각각 fragmentary context, irrelevant context, information loss라는 문제를 안고 있습니다. SeCom은 conversation segmentation으로 topic-level segment를 만들고, LLMLingua-2 기반 compression으로 retrieval noise를 줄여 이 문제를 완화합니다.
실험 결과는 segment-level memory가 long-term conversation QA에서 더 안정적인 retrieval context를 제공한다는 점을 보여줍니다. 특히 LOCOMO처럼 긴 대화에서는 SeCom의 이점이 크게 나타납니다. Full History가 가능한 long-context model에서도 SeCom이 더 나은 결과를 얻었다는 점은 memory management가 단순한 context length 확장과는 다른 문제임을 보여줍니다.
SeCom의 기여는 새로운 generation model을 제안하는 데 있지 않습니다. 이 논문은 conversational agent의 장기 기억 성능이 memory unit의 구조, retrieval 전처리, context budget 설계에 크게 좌우된다는 점을 실험으로 정리합니다. 장기 대화형 agent를 설계할 때는 memory를 많이 저장하는 것보다, 검색 가능한 형태로 잘 나누고 정제하는 일이 더 중요하다는 방향을 제시합니다.
