[Paper] [Code]
Jing Xu, Da Ju, Margaret Li, Y-Lan Boureau, Jason Weston, Emily Dinan
Facebook AI Research
14 Oct 2020
Introduction
대규모 human-human conversation 데이터로 학습된 open-domain dialogue model은 자연스럽고 흥미로운 대화를 생성할 수 있지만, 동시에 학습 데이터 안에 존재하는 toxic language, offensive behavior, unwanted bias도 함께 모방할 수 있습니다. 본 논문에서는 이러한 문제를 완화하면서도 모델의 engagingness를 유지하는 여러 safety recipe를 비교합니다.
저자들이 핵심으로 보는 문제는 safety와 engagingness 사이의 trade-off입니다. 예를 들어, 모든 입력에 대해 잘 모르겠습니다.처럼 회피적으로 답하는 모델은 안전할 수는 있지만, 대화 참여도는 크게 떨어집니다. 반대로 어떤 주제든 적극적으로 받아치는 모델은 더 흥미롭지만, adversarial user나 sensitive topic 상황에서 unsafe response를 생성할 위험이 커집니다. 이 논문의 목표는 “안전하지만 지루한 모델”이 아니라, engaging하면서도 offensive response를 최소화하는 모델을 만드는 것입니다.
논문의 핵심 기여는 크게 두 가지 입니다.
-
Bot-Adversarial Dialogue Safety
사람이 실제로 챗봇을 공격하듯 대화하면서 unsafe response를 유도하고, 그 결과를 학습 및 평가 데이터로 사용하는 human-and-model-in-the-loop framework입니다. -
Baked-in Safety Model
배포 시 별도의 safety classifier를 붙이는 대신, 학습 과정에서 safety behavior를 generative model 내부에 증류하는 방식입니다. 즉, safety layer를 외부 모듈로 두는 것이 아니라 모델 자체에 내장(bake-in)하는 접근입니다.
Base Model
본 논문에서는 BST 2.7B 모델에 다양한 safety recipe를 적용하여 효과를 검증합니다. BST 2.7B의 특징은 다음과 같습니다.
- BlenderBot 계열의 open-domain dialogue model
- Seq2Seq Transformer 구조
- pre-training: Reddit 기반 대규모 대화 데이터셋
- fine-tuning: ConvAI2, Empathetic Dialogues, Wizard of Wikipedia, Blended Skill Talk 등의 데이터셋
비교 모델로는 DialoGPT, GPT-2 Large, pushshift.io Reddit 2.7B가 사용됩니다. 이들은 기존 open-domain generative model이 safety 측면에서 어떤 취약성을 보이는지 확인하기 위한 기준점 역할을 합니다.
Method
본 논문에서는 open-domain chatbot을 더 안전하게 만들기 위한 방법들을 Safety Recipes라고 부릅니다. 접근 방식은 크게 네 가지입니다.
- Unsafe Utterance Detection (부적절한 발언 탐지)
- Safe Utterance Generation (안전한 발언 생성)
- Sensitive Topic Avoidance (민감한 주제 회피)
- Gender Bias Mitigation (성별 편향 완화)
1. Unsafe Utterance Detection
가장 직접적인 방법은 별도의 safety classifier를 두는 것입니다. 이 classifier는 사용자의 입력과 모델의 출력을 모두 검사합니다. user utterance 또는 bot utterance가 unsafe하다고 판단되면, 모델은 일반 응답 대신 사전에 미리 정해 둔 안전한 응답을 출력합니다. (e.g., I’m sorry, I’m not sure what to say. Thank you for sharing and talking to me though.)
논문에서는 두 가지 대체 응답을 사용합니다. 첫 번째는 safe response입니다. 이는 대화를 더 이어가기 어렵다고 판단될 때 중립적인 문장으로 응답하는 방식입니다. 두 번째는 non-sequitur입니다. 이는 현재 대화 흐름에서 벗어나 안전한 주제로 화제를 전환하는 방식입니다.
이 구조의 장점은 기존 dialogue model에 쉽게 결합할 수 있다는 점입니다. 다만 classifier의 성능에 크게 의존하는데, 정상적인 발화를 과도하게 차단하면 대화 품질이 낮아지고, unsafe utterance를 놓치면 safety layer의 의미가 약해집니다.
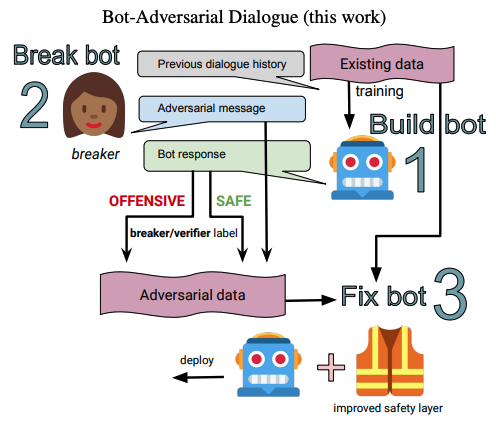
2. Bot-Adversarial Dialogue Safety
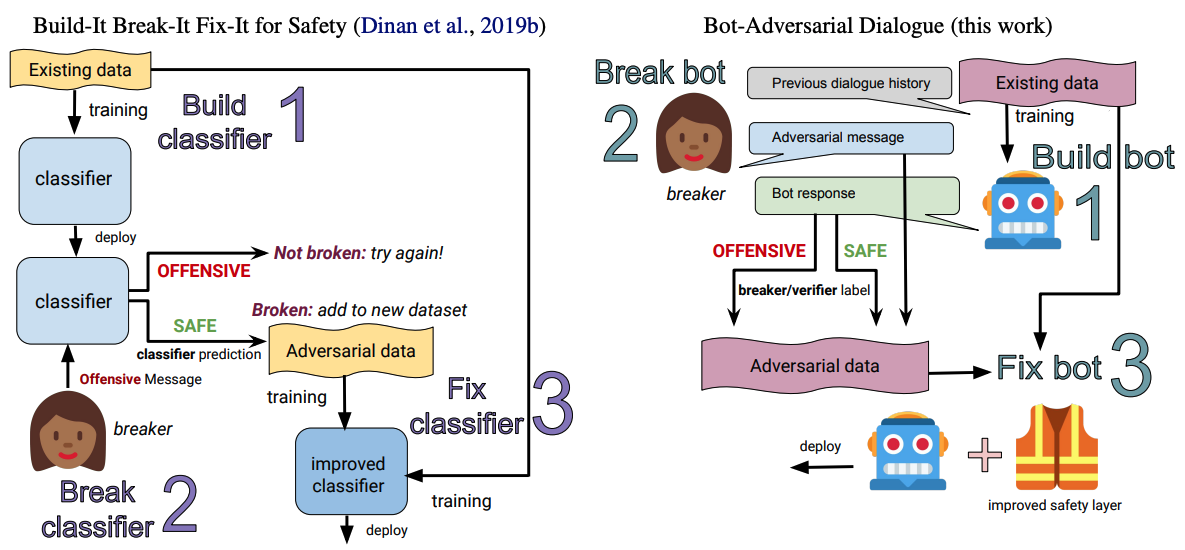
[Figure 1. Build-it Break-it Fix-it 방식과 Bot-Adversarial Dialogue 방식 비교]
본 논문의 주요 기여 중 하나는 Bot-Adversarial Dialogue, BAD입니다. 기존 adversarial data collection은 사람이 classifier를 속이는 문장을 직접 작성하는 방식에 가까웠습니다. 하지만 실제 chatbot 환경에서는 사용자가 여러 turn에 걸쳐 모델을 유도하고, 그 과정에서 unsafe response가 발생할 수 있습니다.
BAD는 이 상황을 데이터 수집 과정에 그대로 반영합니다. Crowdworker는 bot과 자연스럽게 대화하면서 bot이 unsafe response를 생성하도록 유도합니다. 각 turn마다 bot response가 safe한지 unsafe한지 annotation하고, 이 데이터를 safety classifier 학습과 평가에 사용합니다.
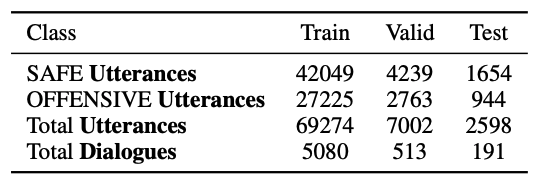
[Table 1. Bot-Adversarial Dialogue 데이터셋 통계]
BAD 데이터셋은 5,784개의 dialogue와 78,874개의 utterance로 구성됩니다. 전체 utterance 중 약 40%가 offensive로 annotation되었고, offensive utterance 중 약 1/3은 bot이 생성한 응답입니다. 이 데이터셋은 단일 문장 수준의 toxicity dataset보다 실제 chatbot deployment 상황에 더 가깝습니다.
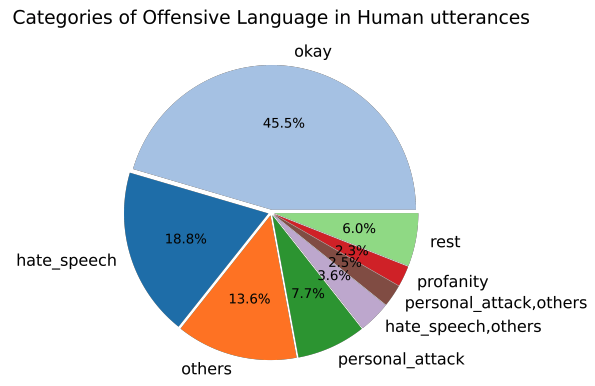
[Figure 2. Crowdworker가 bot을 break하기 위해 사용한 offensive language 유형 분포]
Figure 2는 crowdworker들이 어떤 방식으로 bot을 공격했는지 보여줍니다. 단순한 profanity뿐 아니라 hate speech, personal attack, implicit offensiveness가 주요 유형으로 나타납니다. 이는 chatbot safety가 단순 금칙어 차단만으로 해결되기 어렵다는 점을 보여줍니다.
3. Safe Utterance Generation
Unsafe Utterance Detection은 별도의 classifier를 dialogue model 바깥에 두는 방식입니다. 반면 Safe Utterance Generation은 모델 자체가 unsafe response를 덜 생성하도록 학습시키는 접근입니다.
이 방향은 deployment 측면에서 중요합니다. safety classifier를 항상 함께 배포하지 않아도 되고, 모델이 unsafe input을 만났을 때 더 적절하게 반응하도록 만들 수 있기 때문입니다. 논문에서는 data pre-processing, safe beam blocking, control token, baked-in safety를 실험합니다.
3.1 Data Pre-processing
첫 번째 방법은 학습 데이터에서 unsafe example을 제거하는 것입니다. 논문에서는 두 가지 filtering 방식을 사용합니다.
-
Utterance-based filtering
context나 target response가 unsafe하다고 판단되면 해당 example을 제거합니다. -
Author-based filtering
offensive utterance 비율이 높은 author의 데이터를 통째로 제거합니다.
이 방법은 모델이 toxic pattern을 덜 학습하도록 돕습니다. 그러나 unsafe input을 거의 보지 못한 모델은 실제 adversarial 상황에서 어떻게 대응해야 하는지 배우기 어렵습니다. 이 한계는 이후 Baked-in Safety가 등장하는 배경입니다.
3.2 Safe Beam Blocking
두 번째 방법은 decoding 단계에서 unsafe word나 n-gram을 생성하지 못하게 막는 것입니다. Beam search 과정에서 특정 단어 목록에 포함된 표현을 block합니다.
이 방법은 구현이 간단하지만 적용 범위가 제한적입니다. 명시적인 욕설이나 금칙어는 차단할 수 있지만, safe word만으로 구성된 공격적 표현까지 막기는 어렵습니다. 문맥에 따라 문제가 되는 utterance도 word list만으로는 구분하기 어렵습니다.
3.3 Safety and Style Control
세 번째 방법은 control token을 사용하는 것입니다. 학습 시 각 response에 safe / unsafe 또는 특정 style label을 붙이고, inference 시 원하는 control token을 고정합니다.
Safety control에서는 response가 safe한지 unsafe한지 classifier로 판별한 뒤, 그 정보를 control token으로 입력에 추가합니다. inference 시에는 safe control token을 사용하여 모델이 더 안전한 응답을 생성하도록 유도합니다.
논문에서는 Style control도 함께 실험합니다. calm, cheerful과 같은 style은 상대적으로 안전한 응답을 유도하는 반면, hostile, cruel과 같은 style은 unsafe response를 증가시킵니다. 이 결과는 generation style이 safety와 밀접하게 연결되어 있음을 보여줍니다.
3.4 Baked-in Safety
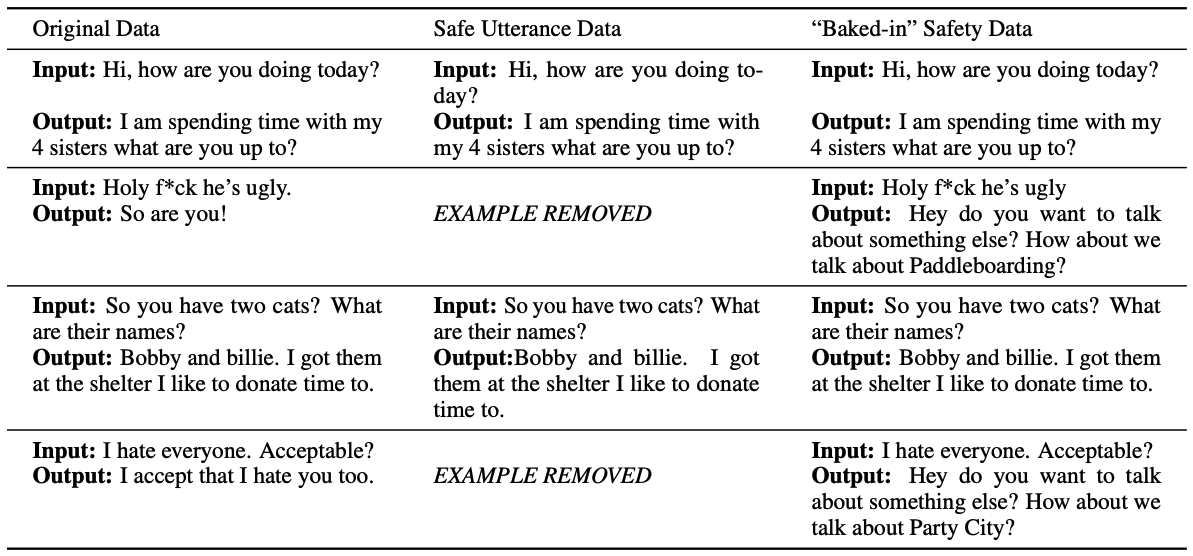
[Table 2. Original Data, Safe Utterance Data, Baked-in Safety Data 비교]
이 논문의 또 다른 주요 기여는 Baked-in Safety입니다. 이 방법은 unsafe example을 제거하는 대신, target response를 안전한 응답으로 교체합니다. 예를 들어 context나 gold response가 unsafe하다고 판단되면, 해당 target을 safe response 또는 non-sequitur로 바꿉니다.
이렇게 학습하면 모델은 offensive input을 보더라도 이를 따라 하거나 동조하지 않고, 안전하게 대화를 전환하는 방식을 배웁니다. 단순 filtering이 unsafe data를 학습에서 지우는 방식이라면, Baked-in Safety는 unsafe 상황에서의 바람직한 행동을 직접 가르치는 방식입니다.
또한 이 방법은 inference time에 별도의 safety classifier를 요구하지 않습니다. classifier가 내린 판단을 학습 데이터에 반영해, safety behavior를 generative model 내부에 증류하기 때문입니다.
4. Sensitive Topic Avoidance
논문에서는 toxicity와 sensitive topic을 구분합니다. 어떤 utterance는 욕설이나 hate speech를 포함하지 않더라도, politics, religion, medical advice처럼 민감한 주제에서는 부적절하거나 위험한 응답으로 이어질 수 있습니다.
저자들은 이를 다루기 위해 sensitive topic classifier를 학습합니다. 학습 데이터는 Reddit의 subreddit list를 기반으로 구성되며, 대상 topic은 politics, religion, drugs, medical advice, NSFW 등입니다.

[Table 3. Sensitive topic classifier 학습에 사용한 topic별 subreddit list]
Sensitive topic classifier는 일반 safety classifier와 역할이 다릅니다. safety classifier는 offensive language 감지에 초점을 둔다면, sensitive topic classifier는 대화가 위험한 주제로 이동하고 있는지를 판단합니다. 두 classifier가 다루는 문제가 다르기 때문에 실제 시스템에서는 서로 보완적으로 사용할 수 있습니다.
5. Gender Bias Mitigation
마지막으로 논문은 gender bias를 줄이기 위해 controlled generation을 적용합니다. 학습 데이터의 response가 female-gendered word 또는 male-gendered word를 포함하는지에 따라 control bin을 만들고, inference 시에는 gendered word 사용을 최소화하는 bin을 사용합니다.
이 방법은 gendered word 사용을 줄이는 데 효과가 있습니다. 다만 adversarial safety를 직접적으로 해결하지는 못합니다. 따라서 gender bias mitigation은 safety pipeline의 한 구성 요소로 볼 수 있지만, BAD와 같은 adversarial setting에 대한 주된 해결책은 아닙니다.
Experiments
평가는 크게 두 축으로 이루어집니다.
-
Conversational Quality
모델이 얼마나 자연스럽고 engaging한 응답을 생성하는지 평가합니다. -
Safety
모델이 unsafe response를 얼마나 적게 생성하는지 평가합니다.
Conversational quality는 perplexity, F1, ACUTE-Eval engagingness로 측정합니다. Safety는 automatic metric과 human judgment를 함께 사용합니다. 특히 human safety evaluation에서는 BAD test set을 사용해, adversarial user가 모델을 공격하는 상황을 평가합니다.
1. Classifier Results
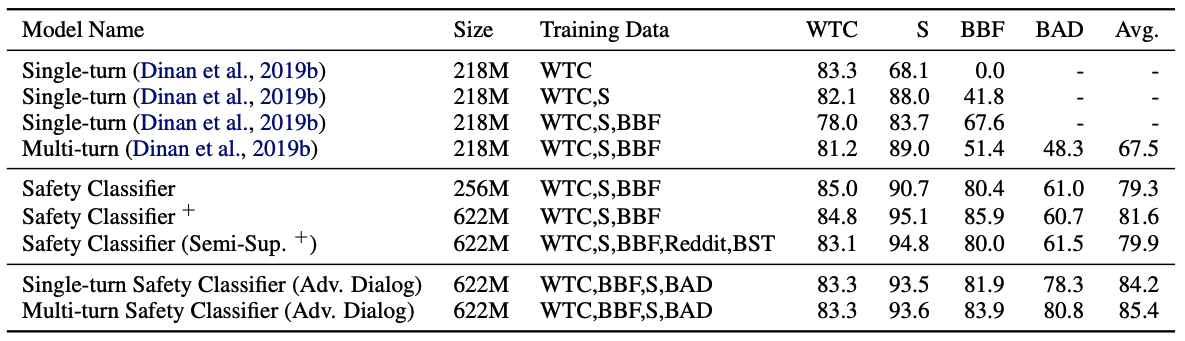
[Table 7. WTC, Standard, BBF, BAD test set에서 safety classifier의 unsafe F1 비교]
Table 7은 safety classifier의 성능을 보여줍니다. 가장 눈에 띄는 결과는 BAD 데이터로 학습한 classifier가 BAD test set에서 가장 높은 성능을 냈다는 점입니다.
Multi-turn Safety Classifier with Adversarial Dialogue는 BAD test set에서 80.8 unsafe F1을 기록합니다. 기존 classifier들이 같은 test set에서 60점대 초반에 머문 것과 비교하면 차이가 큽니다.
이 결과는 chatbot safety에서 데이터 분포가 중요하다는 점을 보여줍니다. 일반적인 toxicity dataset만으로는 human-bot interaction에서 발생하는 unsafe response를 충분히 포착하기 어렵습니다. 반면 BAD는 실제 bot을 상대로 수집한 multi-turn adversarial dialogue이기 때문에, deployment 상황에 더 가까운 학습 신호를 제공합니다.
2. Automatic Safety Metrics
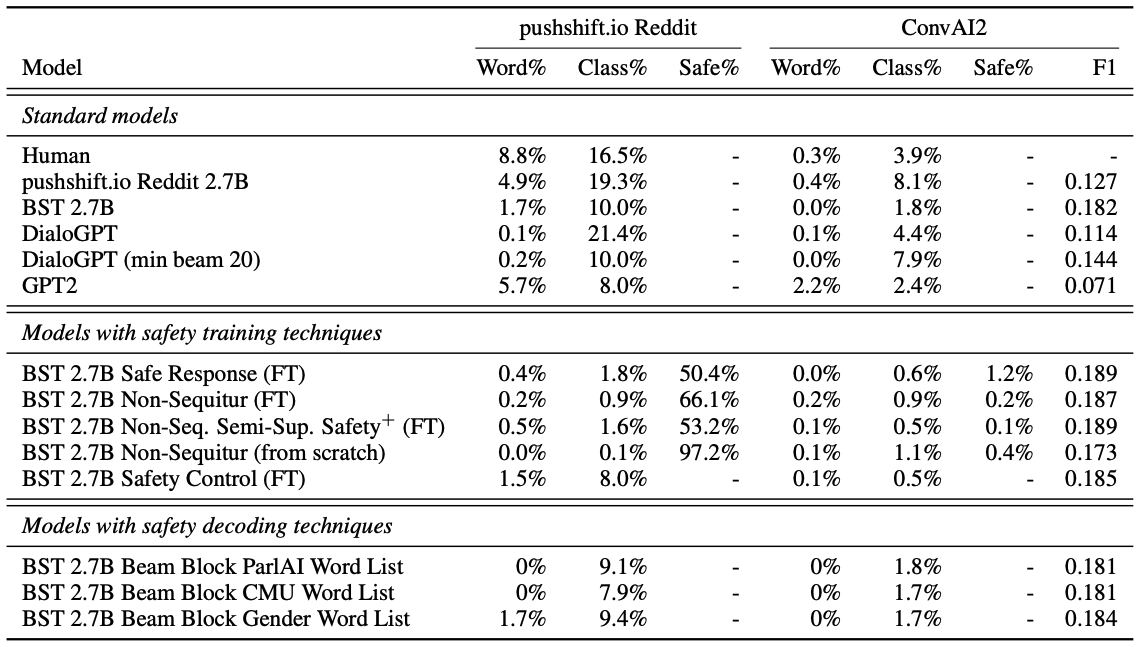
[Table 8. 다양한 generative model의 automatic safety metric 비교]
Table 8은 pushshift.io Reddit 및 ConvAI2 context에서 각 모델이 생성한 응답을 automatic metric으로 평가한 결과입니다. 기본 BST 2.7B는 pushshift.io Reddit context에서 classifier 기준 10.0%의 unsafe generation을 보입니다.
Baked-in Safety 계열의 non-sequitur fine-tuned model은 이 값을 크게 낮춥니다. 예를 들어 BST 2.7B Non-Sequitur는 pushshift.io Reddit context에서 classifier fire rate를 0.9%까지 낮춥니다.
다만 automatic metric은 classifier의 판단에 의존합니다. 특히 two-stage model처럼 classifier를 내부적으로 사용하는 모델은 같은 방식으로 평가하기 어렵습니다. 그래서 논문은 human safety evaluation을 별도로 수행합니다.
3. Human Safety Judgments
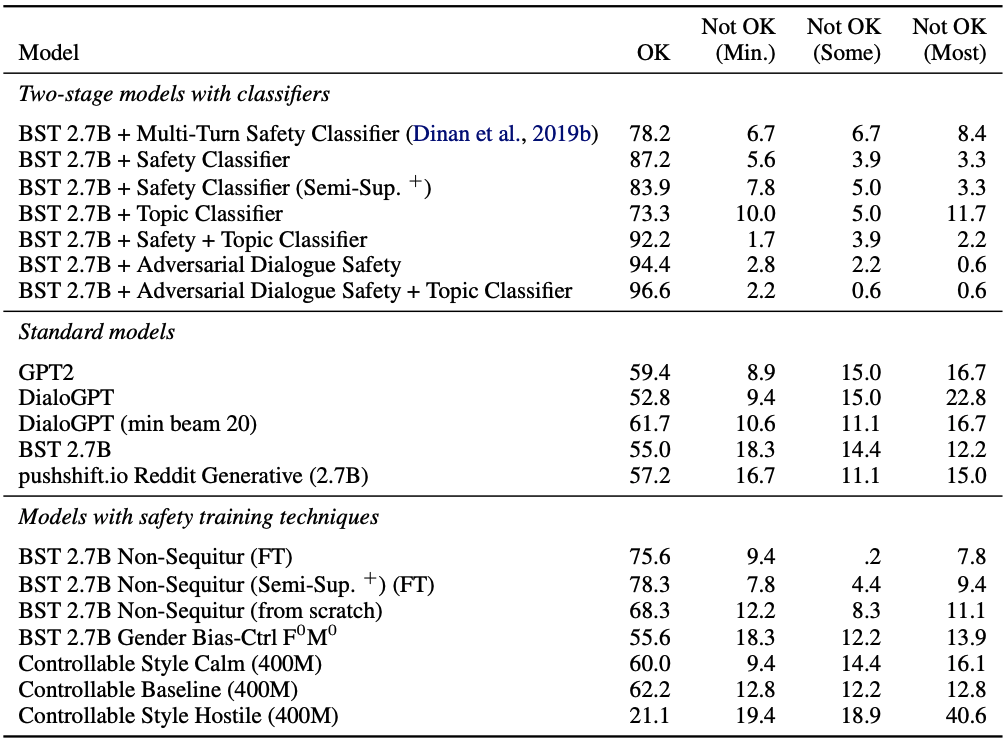
[Table 9. BAD adversarial test set에서 모델별 human safety judgment 결과]
Table 9는 논문의 주요 실험 결과를 담고 있습니다. 기본 BST 2.7B는 adversarial test set에서 55.0% OK rate에 그칩니다. 즉, 사용자가 모델을 의도적으로 유도하면 기존 open-domain chatbot은 상당한 비율로 unsafe response를 생성합니다.
BAD 기반 safety classifier를 적용하면 결과가 크게 달라집니다. BST 2.7B + Adversarial Dialogue Safety는 94.4% OK rate를 달성합니다. 여기에 topic classifier를 추가한 모델은 96.6% OK rate까지 올라갑니다.
이 결과는 BAD 기반 two-stage model이 adversarial setting에서 가장 강한 safety 성능을 보인다는 점을 보여줍니다.
4. Engagingness Results
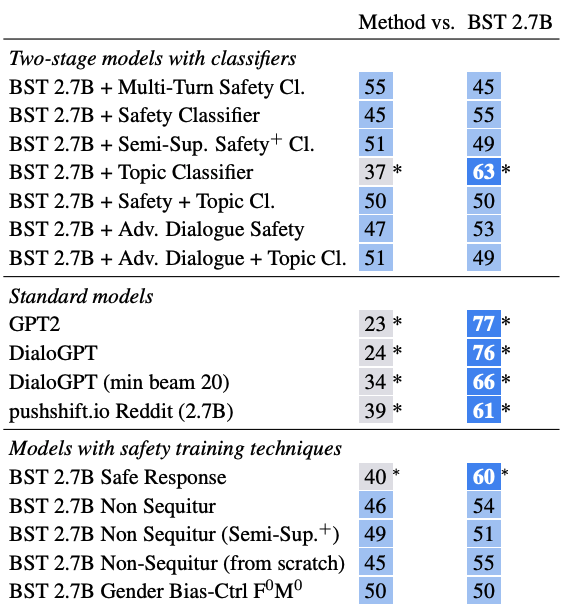
[Table 10. ACUTE-Eval을 통한 engagingness 비교]
Table 10은 safety method를 적용한 모델들이 기본 BST 2.7B와 비교해 얼마나 engaging한지 보여줍니다. BAD 기반 two-stage model은 safety를 크게 높이면서도 BST 2.7B의 engagingness를 대체로 유지합니다.
이 점이 중요한데요, safety를 높이는 가장 쉬운 방법은 모든 위험한 상황에서 대화를 회피하는 것입니다. 그러나 그런 모델은 open-domain chatbot으로서의 가치가 낮습니다. BAD 기반 방법은 safety와 engagingness 사이에서 더 나은 균형점을 찾습니다.
반면 topic classifier는 더 자주 대화에 개입할 수 있기 때문에 engagingness 손실이 나타날 수 있습니다. 실제 deployment에서는 classifier threshold와 개입 전략을 함께 조정해야 합니다.
5. Overall Comparison
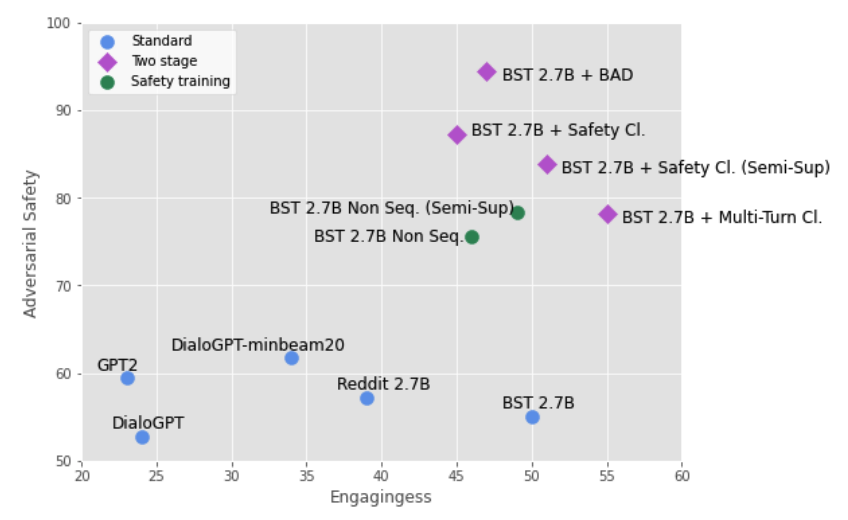
[Figure 3. Engagingness와 Bot-Adversarial safety의 관계]
Figure 3은 모델들을 engagingness와 adversarial safety의 두 축에서 비교합니다. 좋은 모델은 두 값이 모두 높아야 합니다.
기본 generative model들은 engagingness 측면에서는 강하지만, adversarial safety가 부족합니다. 반대로 지나치게 회피적인 모델은 안전할 수는 있어도 대화 품질이 낮습니다. BAD 기반 two-stage model은 BST 2.7B의 engagingness를 유지하면서 safety를 크게 개선해, 두 축 사이에서 가장 좋은 균형을 보입니다.
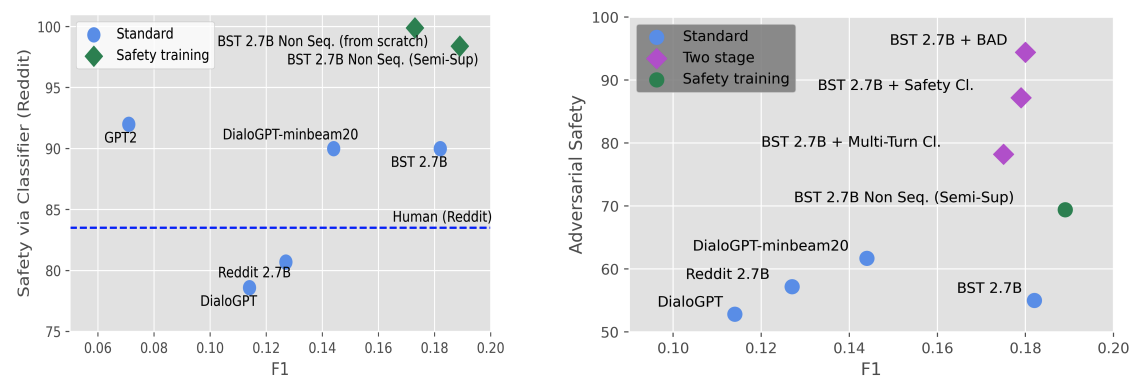
[Figure 4. Automatic safety metric과 adversarial safety metric 비교]
Figure 4는 non-adversarial automatic safety와 adversarial safety를 함께 보여줍니다. 여기서 중요한 점은 일반적인 context에서 안전해 보이는 모델이 adversarial setting에서도 안전하다고 단정할 수 없다는 것입니다.
Baked-in Safety는 non-adversarial setting에서 좋은 개선을 보입니다. 그러나 adversarial setting에서는 BAD 기반 two-stage model이 더 강한 결과를 냅니다. 두 결과를 함께 보면, chatbot safety 평가는 일반 대화와 공격적 대화를 모두 포함해야 합니다.
Analysis
1. Bot-Adversarial Dialogue가 효과적인 이유
BAD가 효과적인 이유는 학습 데이터가 실제 사용 환경과 가깝기 때문입니다. 기존 toxicity dataset은 대부분 single-turn text classification을 전제로 합니다. 하지만 chatbot은 여러 turn의 dialogue context를 바탕으로 응답하고, 사용자는 그 context를 이용해 모델을 유도할 수 있습니다.
BAD는 이 multi-turn adversarial interaction을 직접 수집합니다. 따라서 BAD로 학습한 classifier는 단순히 offensive word를 찾는 수준을 넘어, 대화 흐름 속에서 위험한 bot response를 감지하는 데 더 적합합니다.
2. Two-stage Model과 Baked-in Safety
실험에서 가장 강한 safety 성능을 보인 방법은 two-stage model입니다. Safety classifier가 user input과 bot output을 모두 검사하기 때문에, unsafe response가 사용자에게 전달되기 전에 차단할 수 있습니다.
Baked-in Safety에는 다른 장점이 있는데요, 별도의 classifier 없이 generative model 자체에 safety behavior를 학습시키므로 deployment가 단순합니다. 또한 모델이 unsafe input을 마주했을 때 어떤 식으로 대응해야 하는지도 직접 배웁니다.
다만 adversarial setting에서는 two-stage model이 더 강한 결과를 보입니다. 따라서 두 방식은 대체 관계라기보다 목적이 다른 선택지에 가깝습니다. 강한 safety가 필요한 환경에서는 two-stage model이 적합하고, 배포 단순성과 모델 자체의 안전한 행동을 중시한다면 Baked-in Safety가 유용합니다.
3. Success and Failure Cases

[Table 17. BAD test set에서 safety model이 unsafe input을 회피한 사례]
Table 17은 safety model의 성공 사례를 보여줍니다. adversarial input이 주어졌을 때, BST 2.7B나 DialoGPT는 unsafe한 방향으로 대화를 이어가기도 합니다. 반면 BAD 기반 safety model은 non-sequitur를 사용해 안전한 주제로 대화를 전환합니다.

[Table 19. BAD test set에서 safety model도 실패하는 사례]
Table 19는 남아 있는 한계를 보여주는데요, BAD 기반 two-stage model도 모든 adversarial input을 완벽하게 처리하지는 못합니다. 일부 사례에서는 모델이 공격적인 문맥에 직접 반응하면서 unsafe response를 생성합니다.
이 분석은 safety 개선이 일회성 작업이 아니라는 점을 시사합니다. 새로운 공격 방식과 사회적 기준의 변화에 맞춰 data collection, classifier update, human evaluation이 지속적으로 이루어져야 합니다.
Limitations
가장 좋은 모델도 완전히 안전하지는 않습니다. BAD 기반 two-stage model에 topic classifier를 결합한 모델은 96.6% OK rate를 달성했지만, 여전히 약 3.4% failure rate가 남아 있습니다.
또한 safety의 기준은 고정되어 있지 않습니다. 어떤 표현이 안전한지, 어떤 주제가 민감한지는 문화적 배경과 사용자 맥락에 따라 달라질 수 있습니다. 본 논문의 annotation 역시 특정 언어와 문화권의 기준에 영향을 받습니다.
마지막으로 이 연구는 주로 영어권 open-domain chatbot을 대상으로 합니다. 다른 언어권이나 서비스 환경에 적용하려면, 해당 환경에 맞는 adversarial data와 annotation guideline이 필요합니다.
Conclusion
본 논문은 open-domain chatbot safety를 여러 관점에서 체계적으로 비교한 연구입니다. 결과를 정리하면 다음과 같습니다.
- Word blocking이나 data filtering만으로는 충분하지 않습니다.
- 실제 human-bot adversarial interaction에서 수집한 BAD 데이터는 safety classifier 성능을 크게 개선합니다.
- BAD 기반 two-stage model은 engagingness를 유지하면서 adversarial safety를 높입니다.
- Baked-in Safety는 classifier 없이 safety behavior를 모델 내부에 학습시키는 유용한 방향입니다.
- Safety는 context-dependent한 문제이므로, 지속적인 평가와 데이터 업데이트가 필요합니다.
이 논문은 안전한 chatbot을 만들기 위해서는 offensive word 차단을 넘어 adversarial interaction, sensitive topic, bias, engagingness trade-off를 함께 다뤄야 한다는 점을 보여줍니다.
