0 또는 1로 초기화된 텐서 생성 - zeros(), ones()
zeros(size)
- 모든 요소가 0으로 초기화된 텐서를 생성
# 3x4 크기의 모든 요소가 0인 텐서 생성
zero_tensor = torch.zeros(3, 4)
print(zero_tensor) # 출력: tensor([[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]])ones(size)
- 모든 요소가 1로 초기화된 텐서 생성
# 2x2 크기의 모든 요소가 1인 텐서 생성
one_tensor = torch.ones(2, 2)
print(one_tensor)난수로 초기화된 텐서 생성 - rand(), randn()
rand(size)
- [0, 1] 구간의 연속균등분포 난수 텐서를 생성
- 연속균등분포: 두 경계값 사이의 모든 값에 대해 동일한 확률을 가지는 확률 분포
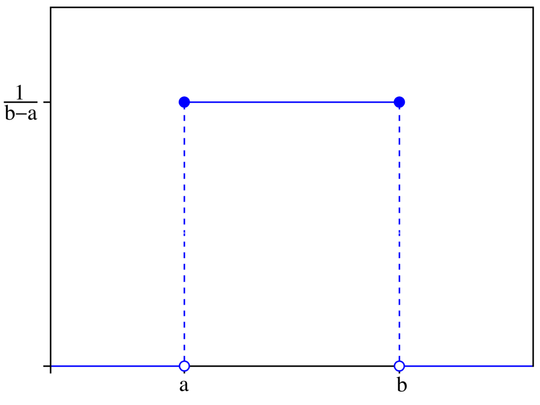
random_tensor = torch.rand(2, 3)
print(random_tensor) # 출력: 0과 1 사이의 랜덤 값으로 채워진 2x3 텐서randn(size)
- 표준정규분포에서 추출한 난수로 채워진 텐서를 생성
- 표준정규분포: 평균이 0이고 표준편차가 1인 종 모양의 곡선
-> 평균 0을 중심으로 좌우 대칭인 종모양; 평균, 중앙값, 최빈값 모두 0
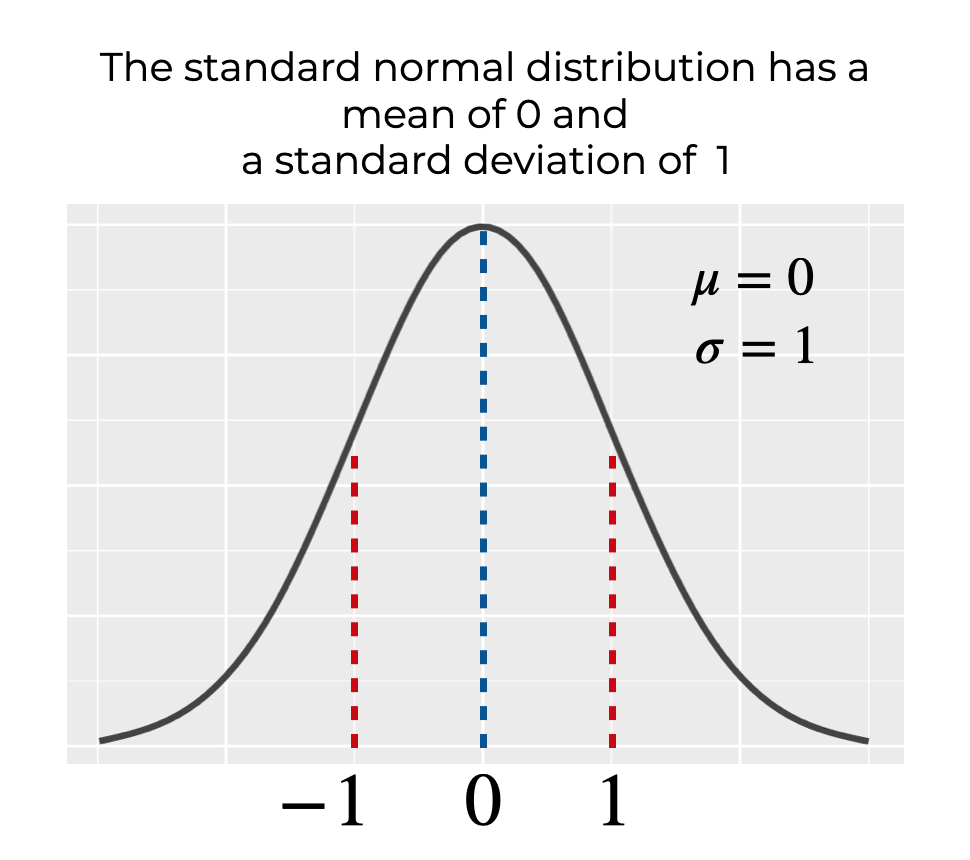
normal_tensor = torch.randn(2, 3)
print(normal_tensor) # 출력: 평균 0, 표준편차 1을 가지는 랜덤 값으로 채워진 2x3 텐서
입력 텐서와 같은 크기의 텐서 생성 - _like()
zeros_like(input)
- 입력 텐서와 같은 크기의 모든 요소가 0인 텐서를 생성
x = torch.randn(2, 3)
zero_like_x = torch.zeros_like(x)
print(zero_like_x.shape) # 출력: torch.Size([2, 3]) # x와 동일한 shapeones_like(input)
- 입력 텐서와 같은 크기의 모든 요소가 1인 텐서를 생성
one_like_x = torch.ones_like(x)
print(one_like_x) # 출력: tensor([[1., 1., 1.],
# [1., 1., 1.]])rand_like(input)
- 입력 텐서와 같은 크기의 [0, 1] 구간의 연속균등분포 난수 텐서를 생성
randn_like(input)
- 입력 텐서와 같은 크기의 표준정규분포의 난수 텐서를 생성
지정 범위 값으로 초기화된 텐서 생성 - arange()
arange(start, end, step=1)
- 지정된 시작값(start)부터 끝값(end)까지, 지정된 간격(step)으로 증가하는 값을 가진 1차원 텐서를 생성
arange_tensor = torch.arange(0, 10, 2)
print(arange_tensor) # 출력: tensor([0, 2, 4, 6, 8])초기화되지 않은 텐서 생성 - empty()
empty(size)
- 메모리만 할당하고 초기화하지 않은 텐서를 생성
- 사용 이유: 성능 향상 및 메모리 사용 최적화
empty_tensor = torch.empty(2, 3)
print(empty_tensor) # 출력: 임의의 값으로 채워진 2x3 텐서 (매번 실행 시 값이 다름)
텐서를 지정된 값으로 초기화 - fill_()
fill_(value)
- 기존 텐서의 모든 요소를 지정된 값으로 채움.
- in-place 연산이므로 원본 텐서가 변경됨.
x = torch.empty(2, 3)
x.fill_(5) # 모든 요소를 5로 채움
print(x) # 출력: tensor([[5., 5., 5.],
# [5., 5., 5.]])list, tuple, NumPy 배열을 텐서로 변환 - tensor(), from_numpy()
tensor(data)
- 다양한 형태의 데이터(리스트, 튜플, NumPy 배열 등)와 유사한 PyTorch 텐서를 생성
- 데이터를 공유하지 않아 Tensor를 수정해도 NumPy 배열은 변경 X
import numpy as np
# 리스트를 텐서로 변환
list_data = [1, 2, 3]
tensor_from_list = torch.tensor(list_data)
print(tensor_from_list) # tensor([1, 2, 3])
# NumPy 배열을 텐서로 변환
numpy_array = np.array([4, 5, 6])
tensor_from_numpy = torch.tensor(numpy_array)
print(tensor_from_numpy) # tensor([4, 5, 6])from_numpy(data)
- NumPy 배열을 PyTorch 텐서로 변환
- 기존 NumPy 배열과 데이터를 공유하며, Tensor를 수정하면 원본 NumPy 배열도 수정됨.
-> 즉, NumPy 배열과 Tensor가 메모리 상에서 동일한 위치를 참조
import numpy as np
# NumPy 배열을 텐서로 변환 (메모리 공유)
numpy_array = np.array([1, 2, 3])
tensor_from_numpy = torch.from_numpy(numpy_array)
# 텐서의 값 변경
tensor_from_numpy[0] = 10
# NumPy 배열의 값도 변경된 것을 확인
print(numpy_array) # [10 2 3]
CPU 텐서 생성 - IntTensor(), FloatTensor(), ...
torch.IntTensor(value), torch.FloatTensor(value)
- 특정 데이터 타입의 CPU 텐서를 생성
int_tensor = torch.IntTensor([1, 2, 3])
print(int_tensor) # 출력: tensor([1, 2, 3], dtype=torch.int32)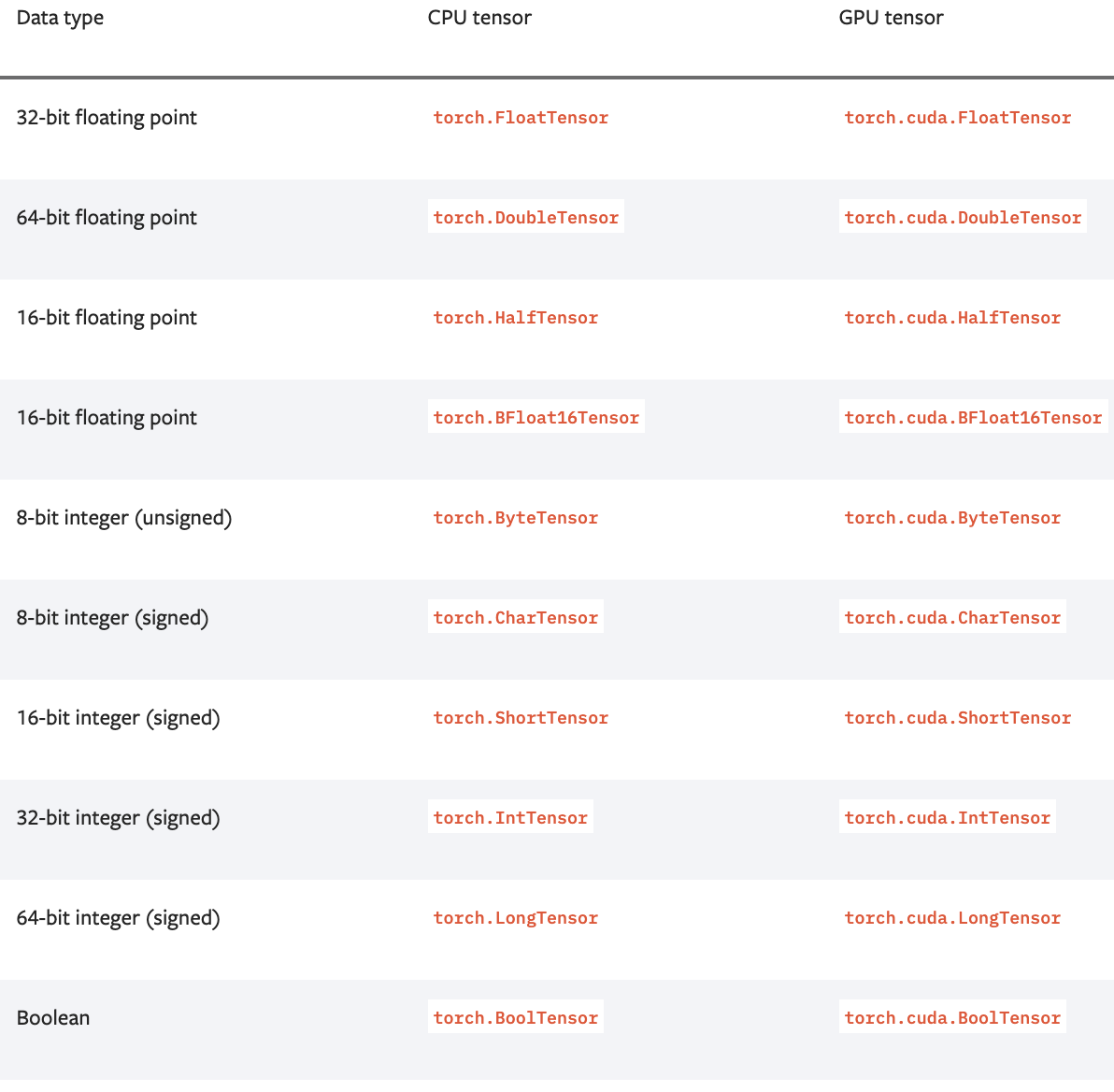
CUDA 텐서 생성과 변환 - to('cuda'), cuda()
- CPU 텐서를 CUDA 텐서로 변환
if torch.cuda.is_available():
cuda_tensor = cpu_tensor.to('cuda')
print(cuda_tensor.device) # 출력: cuda:0 (GPU 사용 가능 여부에 따라 달라짐)- 반대로
to(device='cpu')또는cpu()로 GPU에 할당된 텐서를 CPU 텐서로 변환 가능
텐서의 복제 - clone(), detach()
clone()
- 텐서와 메모리를 복사(deep copy)
detach()와 달리 텐서를 그래프에서 제외시키지 않음
x = torch.randn(2, 2)
x_clone = x.clone()
print(x_clone.equal(x)) # 출력: True (두 텐서가 완전히 같음)detach()
- 텐서를 복사(deep copy), 메모리는 공유(shallow copy)
- 텐서를 계산 그래프에서 분리 -> 그래디언트 계산 방지
x_detached = x.detach()
print(x_detached.requires_grad) # 출력: False (gradient 계산 불가)하지만 detach 메서드는 텐서를 복사하지만 복사 대상 텐서와 메모리를 공유합니다. 따라서 기존 텐서의 값이 변하면 복사한 텐서의 값도 따라서 변하게 됩니다. 다만, back-propagation을 위한 기울기 계산 그래프에서 제외되죠. 먼저 clone 메서드부터 보겠습니다.
Outro
더 읽어볼 것
참고 자료

AI Safety 일짱이 되겠다.