선형 회귀란?
- ① 주어진 트레이닝 데이터를 사용하여 ② 특징 변수와 목표 변수 사이의 선형 관계를 분석하고, ③ 이를 바탕으로 모델을 학습시켜, ④ 트레이닝 데이터에 포함되지 않은 새로운 데이터의 결과를 연속적인 숫자 값으로 예측하는 과정이다.
- 즉, 입력과 출력 사이의 관계를 직선(1차 함수)으로 모델링하는 것.
활용 예시
- 임금 예측: 연차(YearsExperience)에 따른 연봉(Salary)
- 부동산 가격 예측: 주택의 방 개수, 교육환경, 범죄율 등에 따른 주택 가격
트레이닝 데이터
데이터 구성
- 특징 변수(feature):
YearsExperience() - 목표 변수(target):
Salary()
| YearsExperience () | Salary () |
|---|---|
| 1.2 | 39344 |
| 3.1 | 60151 |
| 6.1 | 93941 |
| 10.4 | 122392 |
데이터 불러오기
# Kaggle에서 데이터셋 다운로드
!kaggle datasets download -d abhishek14398/salary-dataset-simple-linear-regression
!unzip salary-dataset-simple-linear-regression.zipimport pandas as pd
# 트레이닝 데이터 불러오기
data = pd.read_csv("Salary_dataset.csv", sep=",", header=0)
print(data)
# 특징 변수와 목표 변수 분리
x = data.iloc[:, 1].values # YearsExperience
t = data.iloc[:, 2].values # Salary
print(x)
print(t)data.iloc[:, 1]: 두 번째 열(YearsExperience)을 특징 변수로 사용data.iloc[:, 2]: 세 번째 열(Salary)을 목표 변수로 사용.values: pandas Series를 numpy 배열로 변환
상관 관계 분석
특징 변수와 목표 변수 사이에 선형 관계가 있는지 확인하기 위해 상관 관계 분석을 수행한다.
상관 관계 분석의 목적
- 두 변수 간의 선형 관계 존재 여부 파악
- 그 관계가 양의 관계인지 음의 관계인지 파악
- 높은 상관 관계를 가지는 특징 변수들을 파악 (다중 선형 회귀에서 필요)
표본상관계수 수식
- : 특징 변수의 i번째 값
- : 목표 변수의 i번째 값
- , : 각 변수의 평균
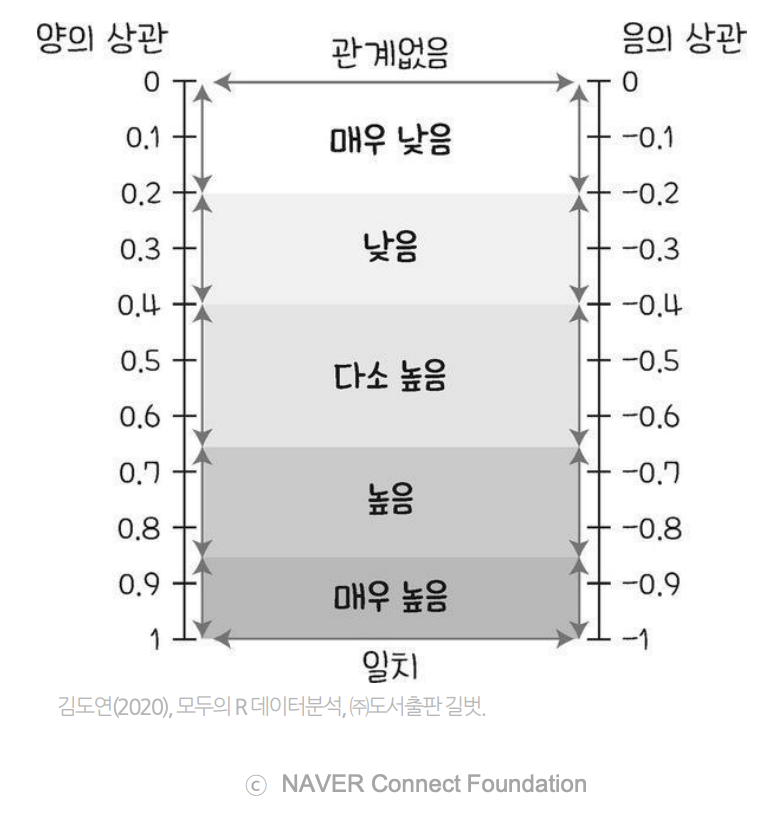
- 의 범위는
상관 관계의 정도
상관 관계 분석 코드
import numpy as np
# 상관 관계 분석
correlation_matrix = np.corrcoef(x, t)
correlation_coefficient = correlation_matrix[0, 1]
print(correlation_matrix)
print('Correlation Coefficient between YearsExperience and Salary :', correlation_coefficient)np.corrcoef(x, t): x와 t 사이의 상관계수 행렬을 반환correlation_matrix[0, 1]: x-t 간 상관계수 값
상관 관계 시각화
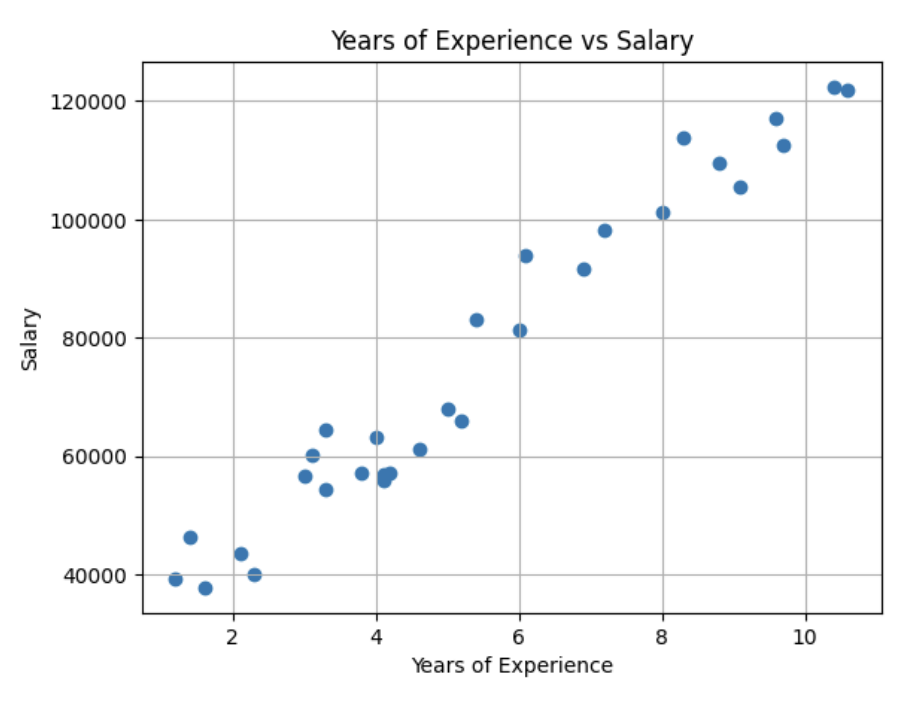
산점도(scatter plot)를 그리면 두 변수 간의 관계를 직관적으로 파악할 수 있다.
import matplotlib.pyplot as plt
plt.scatter(x, t)
plt.xlabel('YearsExperience')
plt.ylabel('Salary')
plt.title('YearsExperience vs Salary')
plt.grid(True)
plt.show()산점도를 보면 YearsExperience가 증가할수록 Salary도 증가하는 강한 양의 선형 관계가 나타난다.
선형 회귀 모델에서의 학습
학습의 의미
선형 회귀 모델에서 학습이란, 주어진 트레이닝 데이터의 특성을 가장 잘 표현할 수 있는 직선 의 가중치(기울기) 와 바이어스(y절편) 를 찾는 과정을 의미한다.
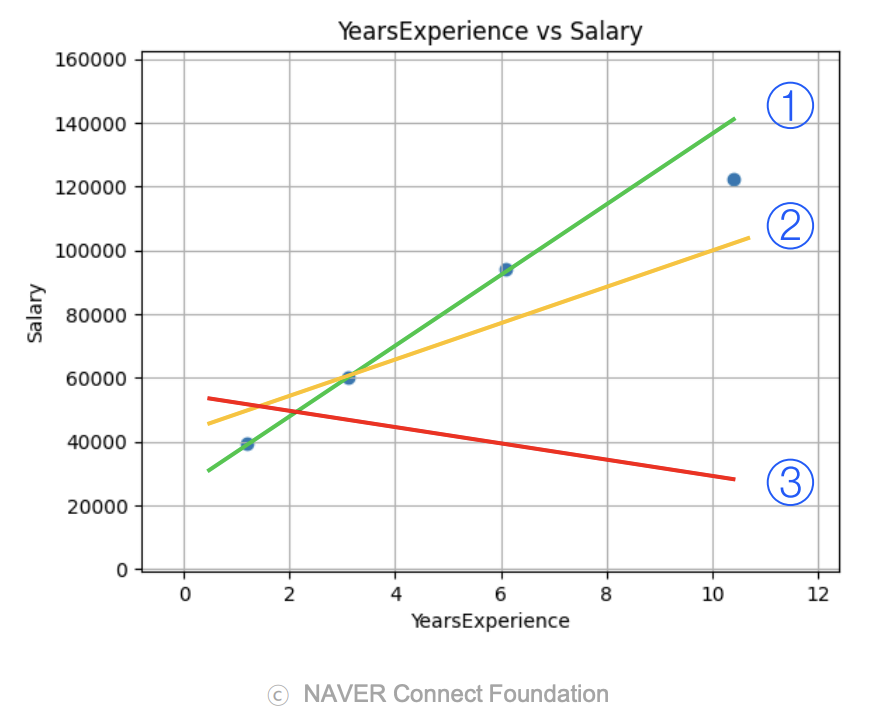
- 와 에 따라 여러 가지 직선 형태가 존재할 수 있음.
- 트레이닝 데이터를 가장 잘 표현하는 최적의 직선을 찾는 것이 목표.
신경망 관점에서의 선형 회귀 모델
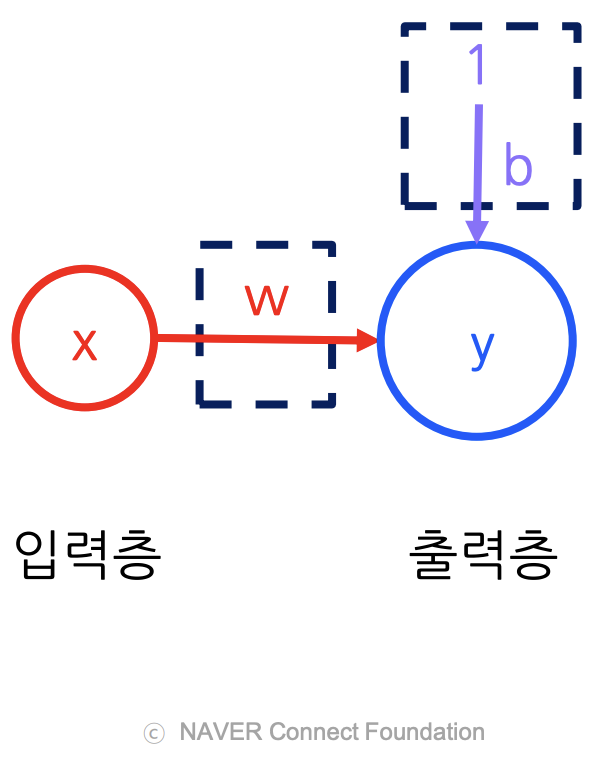
신경망 관점에서 선형 회귀 모델은 입력층의 특징 변수가 출력층의 예측 변수로 사상(mapping)되는 과정이다.
- 입력층: 특징 변수를 포함하며, 각 특징 변수는 하나의 뉴런에 대응 (여기서는 = YearsExperience)
- 가중치 , 바이어스 : 모델이 학습하는 파라미터. 입력층과 출력층의 뉴런을 연결
- 출력층: 예측 변수 . 선형 회귀 모델에서는 단 하나의 뉴런으로 존재
PyTorch에서의 선형 회귀 모델 구축
nn.Module 기반 모델 정의
PyTorch에서 선형 회귀 모델은 nn.Module 클래스를 상속받아 생성한다.
nn.Module은 신경망의 모든 계층을 정의하기 위해 사용되는 기본 클래스nn.Module을 상속받아 신경망의 각 계층을 정의하고, 여러 계층들을 조합하여 복잡한 신경망 모델을 구축함
nn.Module의 장점:
- 일관성: 모든 신경망 모델을 같은 방식으로 정의하고 사용할 수 있음
- 모듈화: 모델을 계층별로 나누어 관리할 수 있어 코드가 깔끔하고 이해하기 쉬움
- GPU 지원: 대규모 연산을 가속화하여 모델의 학습 속도를 높임
- 이외에도 자동 미분과 최적화, 디버깅과 로깅 등의 장점이 있음 (8강에서 설명)
클래스, 인스턴스, 메서드, 속성
선형 회귀 모델 코드를 이해하기 위한 OOP 기본 개념 정리:
- 클래스(class): 인스턴스(객체)를 생성하기 위한 틀. 메서드와 속성을 정의.
- 인스턴스(instance): 클래스에서 생성된 구체적인 객체. 클래스에서 정의된 속성과 메서드를 가짐.
- 메서드(method): 클래스 내부에 정의된 함수. 클래스가 수행하는 동작이나 기능을 정의.
- 속성(attribute): 클래스 내부에 정의된 변수.
모델 코드
import torch.nn as nn
# 클래스 정의
class LinearRegressionModel(nn.Module):
def __init__(self): # 생성자 메서드
super(LinearRegressionModel, self).__init__() # 부모 클래스 초기화
self.linear = nn.Linear(1, 1) # 속성: 입력 1개, 출력 1개인 선형 계층
def forward(self, x_tensor): # 순전파 메서드
y = self.linear(x_tensor) # 입력 데이터를 선형 계층에 통과시켜 예측값 계산
return y
# 인스턴스 생성
model = LinearRegressionModel()생성자 메서드 (__init__):
super(LinearRegressionModel, self).__init__(): 부모 클래스인nn.Module의 생성자를 호출하여 상속받은 모든 초기화 작업을 수행self.linear = nn.Linear(1, 1): 입력과 출력 차원이 모두 1인 선형 계층. 모델의 구조와 파라미터(, )를 정의하는 핵심 요소
순전파 메서드 (forward):
- 특징 변수
x_tensor를 받아 선형 계층self.linear를 통해 예측 변수y를 계산하고 반환
Tensor 변환 및 GPU 지원
모델에 데이터를 입력하기 전에, numpy 배열을 PyTorch Tensor로 변환해야 한다.
import torch
# 1차원 numpy 배열을 2차원 Tensor로 변환
x_tensor = torch.tensor(x, dtype=torch.float32).view(-1, 1) # (N, 1) 형태
t_tensor = torch.tensor(t, dtype=torch.float32).view(-1, 1) # (N, 1) 형태
print('x_tensor =', x_tensor)
print('t_tensor =', t_tensor).view(-1, 1): 1차원 배열을 2차원 텐서로 변환.nn.Linear는 2차원 입력을 기대하기 때문.
# GPU 지원
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device) # 모델을 GPU로 전송
x_tensor = x_tensor.to(device) # 입력 데이터를 GPU로 전송
t_tensor = t_tensor.to(device) # 정답 데이터를 GPU로 전송오차와 손실 함수
오차 (Error)
- 오차란 목표 변수 와 예측 변수 의 차이 를 의미함
- 오차가 크다면 → 와 의 값을 수정해야 함
- 오차가 작다면 → 와 의 값이 최적화된 것으로 판단
- 따라서 선형 회귀 모델에서는 오차의 총합이 최소가 되도록 하는 와 를 찾아야 함
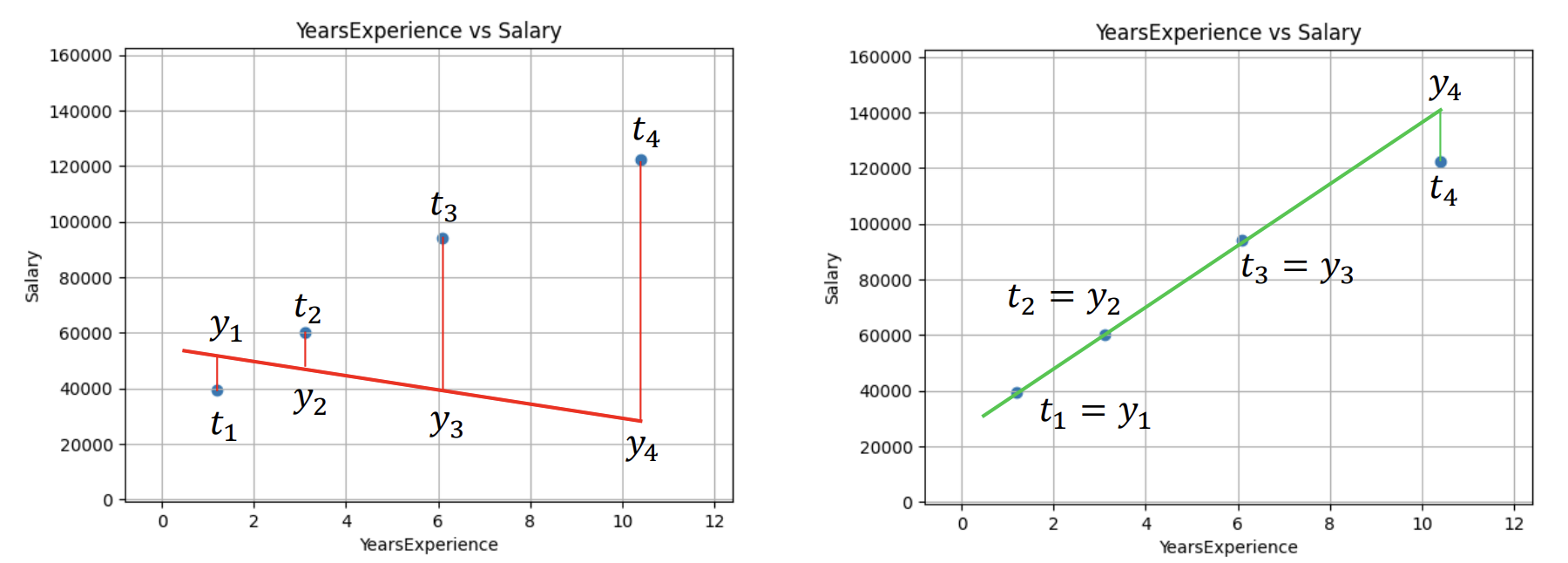
손실 함수 (Loss Function)
- 손실 함수는 목표 변수와 예측 변수 간의 차이를 측정하는 함수이며, 모델을 최적화하기 위해 사용됨
- 오차의 값이 양수와 음수가 혼재할 수 있으므로, 단순히 더하는 방식으로는 전체 오차를 정확하게 구하기 어려움
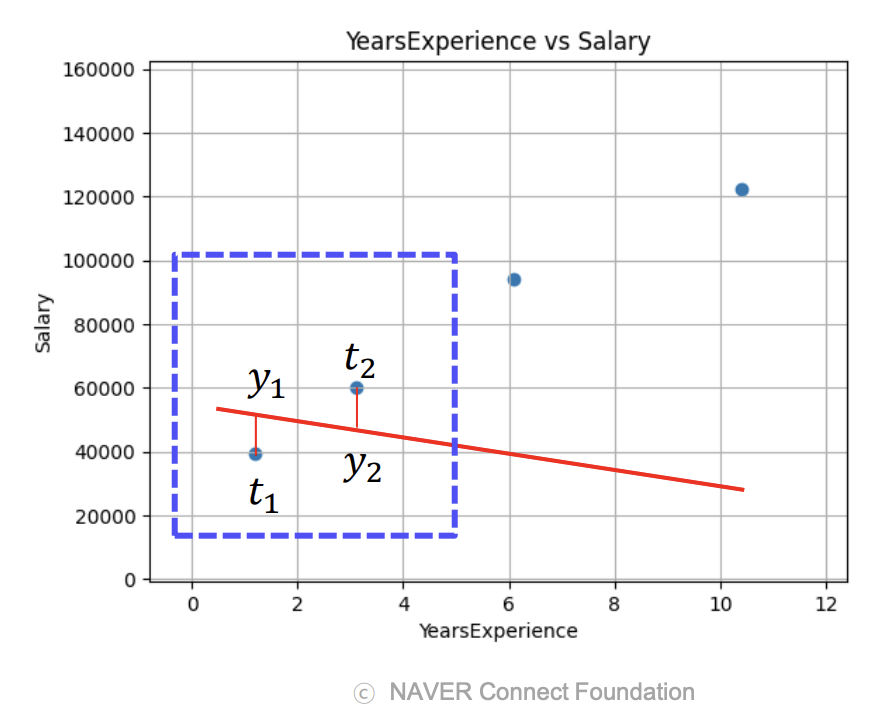
- 이를 해결하기 위해 오차를 제곱하거나 절대값을 취하여 모든 오차를 양수로 변환한 후 더하는 방식을 사용
- 제곱을 하면 목표 변수와 예측 변수의 차이가 클수록 오차가 더 큰 값을 가지게 되어, 학습이 수월해짐
평균 제곱 오차 (MSE, Mean Squared Error)
오차를 제곱하여 더한 후 평균을 구하는 손실 함수:
- 와 는 트레이닝 데이터로부터 주어지는 값이므로, 우리가 주목해야 하는 변수는 가중치 와 바이어스 임
손실 함수의 목적
- 손실 함수의 값이 크다면 → 목표 변수와 예측 변수의 평균 오차가 크다는 의미
- 손실 함수의 값이 작다면 → 목표 변수와 예측 변수의 평균 오차가 작다는 의미
- 손실 함수 값이 최소가 되도록 하는 가중치 와 바이어스 를 찾아야 함
손실 함수 코드
# 손실 함수 정의
loss_function = nn.MSELoss()학습 정리
- 선형 회귀란 트레이닝 데이터를 사용하여 특징 변수와 목표 변수 사이의 선형 관계를 분석하고, 모델을 학습시켜 새로운 데이터의 결과를 연속적인 숫자 값으로 예측하는 과정이다.
- 특징 변수와 목표 변수 간의 선형 관계를 파악하기 위해 상관 관계 분석을 수행한다.
- 신경망 관점에서 선형 회귀 모델은 입력층의 특징 변수가 출력층의 예측 변수로 사상(mapping) 되는 과정이다.
- 선형 회귀 모델에서 학습이란 의 가중치 와 바이어스 를 찾는 과정을 의미한다.
- 손실 함수(MSE) 를 통해 오차를 측정하고, 이 값이 최소가 되도록 파라미터를 최적화한다.

AI Safety 일짱이 되겠다.