Semantic HTML
Semantic HTML
: 의미론적 HTML
HTML 파일은 document이다 (첫 번째 줄에 <!DOCTYPE>을 선언하는 것에서부터 명백하게 드러난다)
모든 웹의 근간이 되는 문서이기때문에 원칙적으로 모든 스타일을 제거하고도 HTML 하나만으로 모든 정보가 전달되어야 한다.
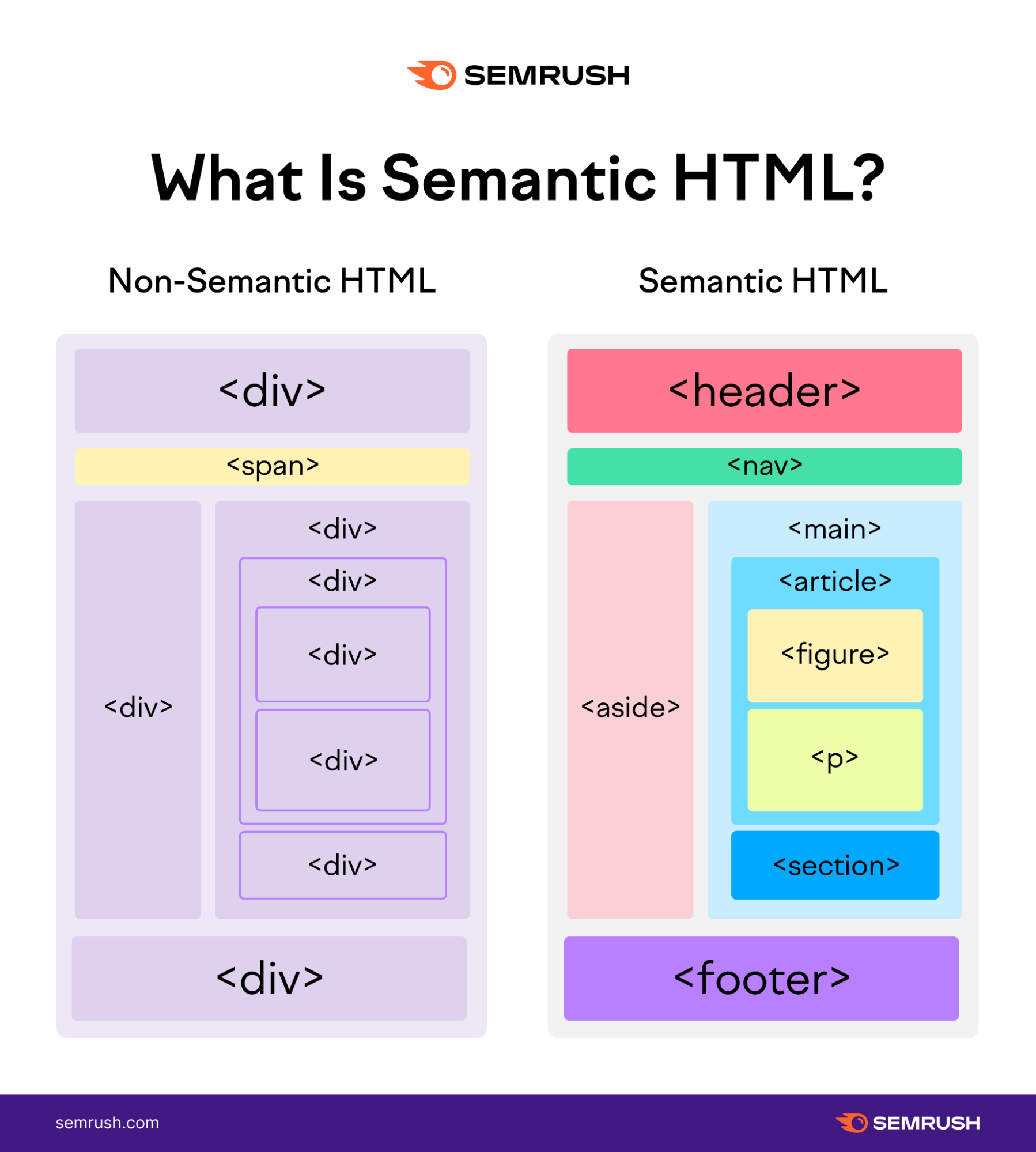
시맨틱하지 않은(non-semantic) elements의 예시
div와 span는 그 자체만으로는 내용물에 대한 어떠한 것도 알려주지 못한다.
검색엔진은 전세계에 있는 웹사이트의 정보를 수집하는데, 이 과정에서 사용자가 검색할 만한 키워드를 미리 예상하여 해당 웹사이트의 키워드에 대응하는 인덱스를 만들게 된다.
이 때 Semantic Element가 없다면 HTML 코드에서 어떤 것이 중요하고 어떤 것이 중요하지 않은 건지 확인할 수 없게 된다. 이는 해당 웹사이트의 인덱싱을 어렵게 만드는 안 좋은 결과를 초래할 수 있다.
※ 웹 크롤러(web crawler)
: 조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램이다.
웹 크롤러가 하는 작업을 '웹 크롤링'(web crawling) 혹은 '스파이더링'(spidering)이라 부른다. 검색 엔진과 같은 여러 사이트에서는 데이터의 최신 상태 유지를 위해 웹 크롤링한다. 웹 크롤러는 대체로 방문한 사이트의 모든 페이지의 복사본을 생성하는 데 사용되며, 검색 엔진은 이렇게 생성된 페이지를 보다 빠른 검색을 위해 인덱싱한다. 또한 크롤러는 링크 체크나 HTML 코드 검증과 같은 웹 사이트의 자동 유지 관리 작업을 위해 사용되기도 하며, 자동 이메일 수집과 같은 웹 페이지의 특정 형태의 정보를 수집하는 데도 사용된다.
웹 크롤러는 봇이나 소프트웨어 에이전트의 한 형태이다. 웹 크롤러는 대개 시드(seeds)라고 불리는 URL 리스트에서부터 시작하는데, 페이지의 모든 하이퍼링크를 인식하여 URL 리스트를 갱신한다. 갱신된 URL 리스트는 재귀적으로 다시 방문한다.
Semantic HTML의 필요성
- 기계와 사람의 일치
Semantic하게 마크업을 한다는 것
= 적절한 의미의 태그들을 사용하여 문서를 정보 구조에 맞게 마크업한다는 것이다. 좋은 정보구조는 해당 문서를 사람과 기계가 동일하게 이해하도록 도와준다.
사람은 CSS로 꾸며진 웹을 통해 볼드로 적혀진 부분이 중요한 정보이고, 한 제목과 한 문단이 한 덩어리의 정보를 만든다는 것을 시각적으로 인식할 수 있다.
기계는 em 태그를 통하여 해당 부분이 중요하다는 것을, h1을 통하여 제목이라는 것을, article을 통하여 한 덩어리의 정보라는 것을 인식할 수 있다.
- SEO (Search Engine Optimization)
구글과 같은 검색 엔진들은 HTML 문서로 검색 결과를 도출해낸다.
예를 들어 회사 이름을 p태그 안에 넣는다고 한다면 h1태그에 넣었을 때보다 훨씬 더 약한 의미와 연관성을 갖게 되고 이는 SEO에 악영향을 끼친다.
- 웹 접근성(Web Accessibility)
누구나 인터넷(웹) 개별 사이트에 접근하기 쉽게 기술적으로 보장되어야 한다.
시각 장애인은 스크린 리더로 웹을 본다. 스크린 리더는 HTML 문서를 읽어내려가며, 각 요소들의 내용을 음성으로 알려주는 장치이다.
사진, 영상 등의 미디어의 경우 alt 속성에 있는 텍스트를 읽어주어, 시각 장애인도 문제없이 모든 정보에 접근할 수 있도록 도와준다. 그렇기 때문에 마크업을 하는 개발자는 모든 사람이 내가 만든 문서에 접근할 수 있도록 도움을 주는 장치들을 마련해야한다.
Semantic Tag를 이용하여 문서를 제작하면 접근성을 높일 수 있다. 만약 여러 항목을 열거하는 경우 모두 span 태그에 넣어 리스트를 만드는 것보다 리스트의 의미를 가지고 있는 ul > li 태그를 사용하는 것이 좋다.
시맨틱 태그를 이용하여 마크업을 한 이후엔, alt, aria-label 등의 속성을 사용해 정보를 채워 넣어준다. 디자인 요소로만 사용한 태그는 aria-hidden을 사용하여 스크린 리더가 무시하도록 할 수 있다.
- 유지 보수, 협업
다른 사람들도 수정을 하고, 협업을 해야하는 페이지라면 모두가 알아보기 쉽게 정갈한 코드를 짜야한다. Semantic Markup은 기계에게도 의미를 전달해주지만, 동료 개발자에게도 의미를 전달해준다.
대표적인 Semantic Tag
- header : 문서 전체나 섹션의 헤더(머릿말 부분)
- nav : 내비게이션
- aside : 사이드에 위치한 공간, 메인 컨텐츠와 관련성이 적은 컨텐츠
- section : 문서의 일반적인 구분, 컨텐츠의 그룹을 표현
본문의 여러 내용을 포함하는 공간 - article : 문서, 페이지, 사이트 안에서 독립적으로 구분되는 영역(본문의 주내용이 들어가는 공간)
- footer : 문서 전체나 섹션의 푸터(마지막 부분)
- table : 표
참조 : https://geonlee.tistory.com/96
참조 : https://csmoon.tistory.com/7
참조 : https://velog.io/@jujusnake/HTML-Semantic%ED%95%98%EA%B2%8C-%EC%9E%91%EC%84%B1%ED%95%B4%EC%95%BC%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0
