대학원을 다니면서 공부를 하나하나 다시하고 있다. 특히 산학 프로젝트를 하면서 실무 데이터를 다루면서, overfitting이나 유난히 낮은 성능을 올리기 위해서 여러 생각을 해봤다. 그러면서 지금까지도 많이 되고있는 Fine-Tuning 방법론도 찾아보았고, 더 나은 답변을 뱉을 수 있는 방법론을 몇 개 찾아보면서 개념을 정리해보았다.
Fine-Tuning
Model Tuning이라고 한 때 부르기도 했지만, 일반적으로 현재에 와서 Fine-Tuning의 의미는 특정 down-stream task에 맞춰진 input, output 데이터셋을 사용해서 model의 모든 가중치, parameter를 조정하는 겁니다. Transfer Learning이라고 하기도 합니다.
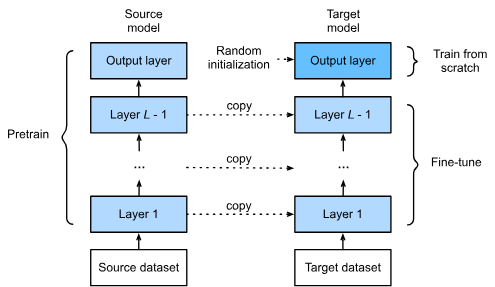
Transfer Learning의 학습 방법
1. Pre-trained model의 아키텍처와 파라미터를 복사하여 새로운 Target model(Fine-Tuning model)을 생성합니다. 이 과정에서 출력층(output layer)은 제외됩니다.
2. Pre-trained model에서 전달된 파라미터는 Pre-trained 데이터셋에서 학습된 지식을 포함하고 있으며, 이 지식이 Fine-Tuning을 위한 Target 데이터셋에도 적용될 수 있다고 가정합니다. Pre-trained model의 output layer은 Pre-trained 데이터셋에 특화되어 있으므로 Target model(Fine-Tuning model)에서는 사용하지 않습니다.
3. Fine-Tuning 데이터셋의 카테고리 수와 동일한 출력을 갖는 새로운 output layer을 Target model에 추가합니다. 이 output layer의 파라미터는 랜덤으로 초기화합니다.
4. Fine-Tuning 데이터셋으로 Target model을 학습시킵니다. 이 과정에서 새로운 output layer은 처음부터 학습됩니다. 나머지 레이어의 파라미터는 Pre-trained model에서 가져온 사전 학습된 가중치를 기반으로 Fine-Tuning 데이터셋에 맞게 미세 조정됩니다.
그래서 SFT(Supervised Fine-tuning Trainer) 사용해서 Full FineTuning 시켜본 사람은 경험해볼 수 있는데, 특정 task에 fine-tuning을 한 후에는 그 목적이 된 task에 대해서는 제대로 일을 하는 LLM이 될 수 있지만, 기존 Pre-trianed 상태에서 잘했던 기본적인 대화를 다시 시켜보면 이상한 말을 간혹 뱉기도 합니다. 즉, Task Mismatch의 상황에 대응이 안된다는 겁니다.
그렇다보니, Pre-trained 상태의 모델을 최대한 잘 활용해서 최고의 성능을 뽑아내는 것과, 아니면 fine-tuning처럼 모든 parameter을 건들지 않고 적절히 일부의 parameter만 tuning을 하는 방법들이 연구되어 왔습니다.
Prompt Engineering
Prompt Engineering은 LLM 모델에게 제공할 prompt를 구성하는 방법론입니다. 성능이 좋은 LLM일수록, 모델사이즈가 큰 LLM 모델을 쓸수록, prompt에 대해서 어느 정도는 좋은 결과를 줄 것이지만, Question Answering이나 (mathematical) Reasoning 등의 복잡한 테스크를 줄수록 LLM을 사용하는 것에 한계가 있을 것입니다.
따라서 복잡한 테스크에서 조금이라도 더 효율을 높이기 위해서는 좋은 prompt를 사용하는 것이 필요합니다. 또한 원하는 형태의 답변을 낼 수 있도록 유도함으로써 LLM의 답변을 이용하는 다른 툴에서도 효과적으로 LLM을 사용할 수 있게 할 수 있습니다.
Prompt Engineering 의 효과
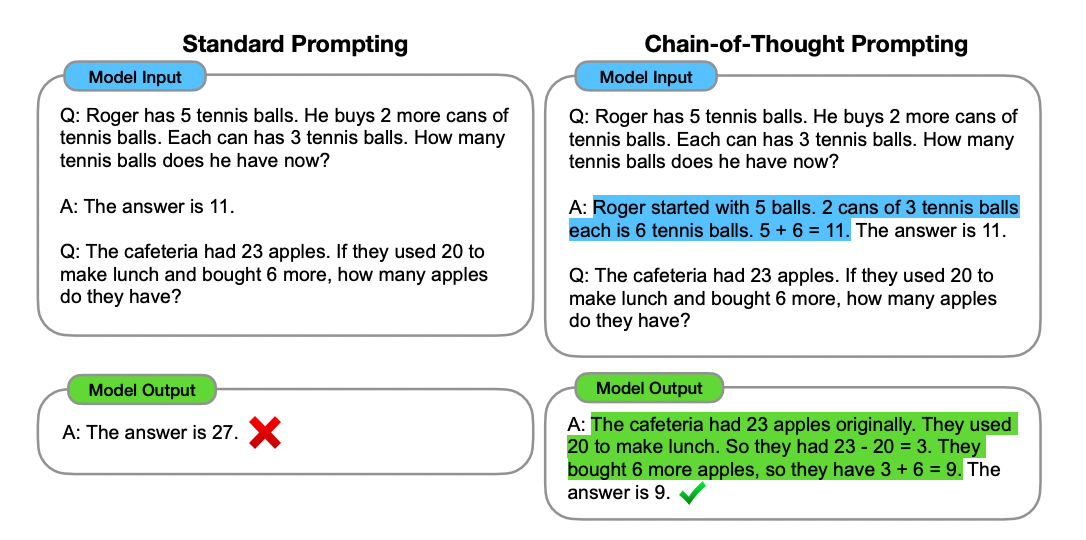
그림에서 보면, stardard prompt를 주었을 경우에는 답변을 하지 못하지만, 파란색으로 쳐진 추론 과정을 추가해주면, LLM이 이에 따라 비슷한 방식의 추론을 통해 답변을 냅니다. 그 답변은 정답인 것을 확인할 수 있습니다.
단순히 추론을 위한 간단한 설명을 넣어주었을 뿐인데, 이제는 정답을 말할 수 있는 것입니다.
Soft Prompting 와 Hard Prompting
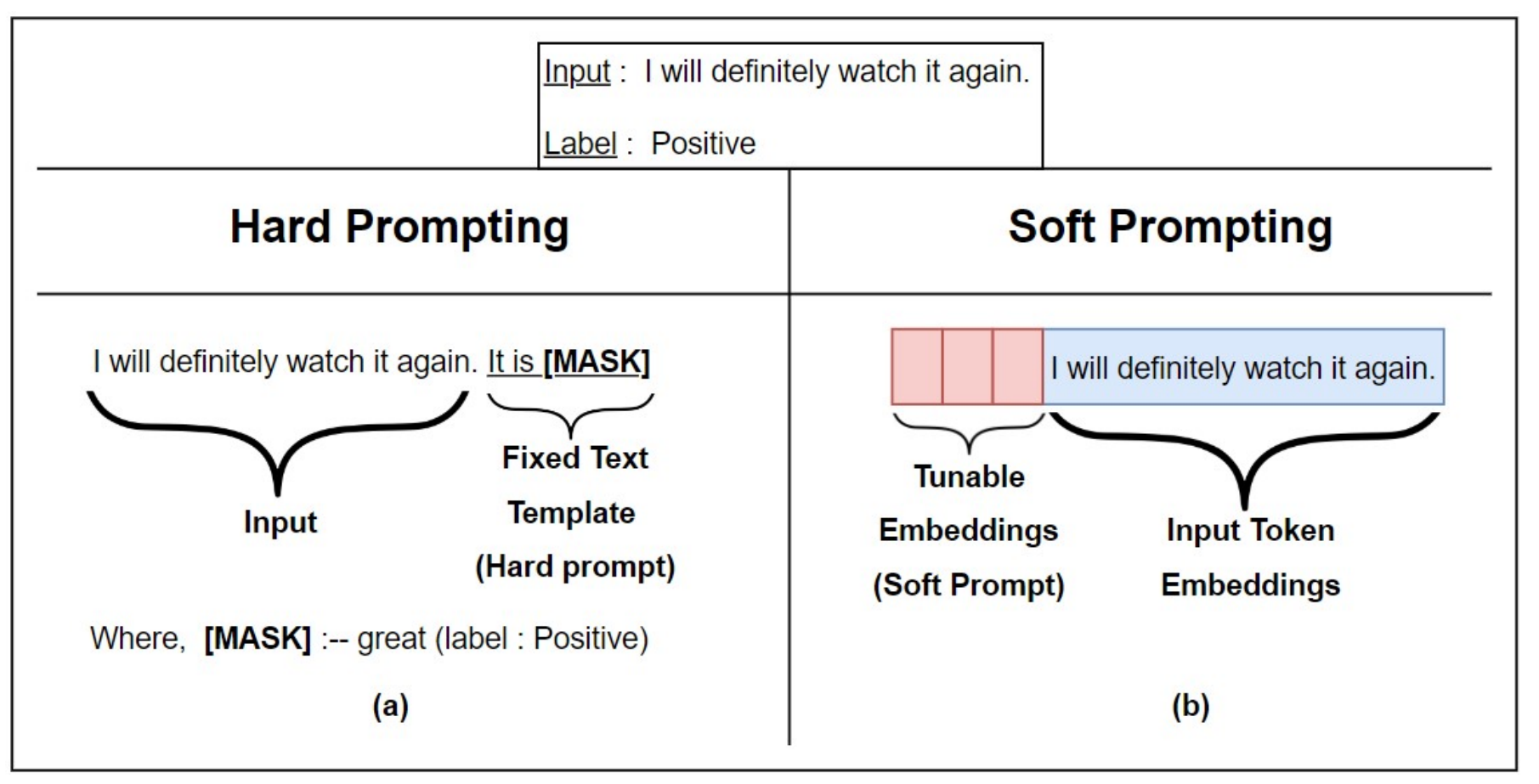
🤔🤔 LLM은 결국 임베딩으로 우리의 prompt에 대한 response를 생성하는데, 굳이 prompt를 자연어 text로 줄 필요가 있을까? 라는 생각도 해볼 수 있습니다.
초기에는 사람이 직관적으로 이해할 수 있는 Hard Prompt(Discrete)가 주로 연구되었습니다. Hard Prompt는 주어진 태스크에 맞게 사람이 직접 모델과 상호작용하며 적절한 프롬프트를 탐색하는 과정을 포함합니다. 하지만 이렇게 정의된 하드 프롬프트는 Suboptimal(비최적화) 하다는 문제가 존재합니다. 이는 인공지능 모델이 이산적인 값이 아닌 연속적인 값으로 학습할 수 없기 때문입니다.
이러한 한계를 극복하기 위해, 연속적(Contiunous)이고 조정 가능한(Tunable) Soft Prompt가 등장했습니다. Soft Prompt는 학습 가능한 파라미터로 구성되며, 모델의 학습 과정에서 최적화가 가능합니다. 이로 인해 관련 연구가 활발히 이루어지고 있으며, 더 나은 성능과 유연성을 제공하는 방식으로 발전하고 있습니다.
앞선 예시에서 우리가 사용하는 자연어,text로 prompting 을 추가해준 경우는 Hard Prompting 에 해당합니다.
🔖 Soft Prompt + ❄️Pre-trained Model -> Fine-tuning 효과
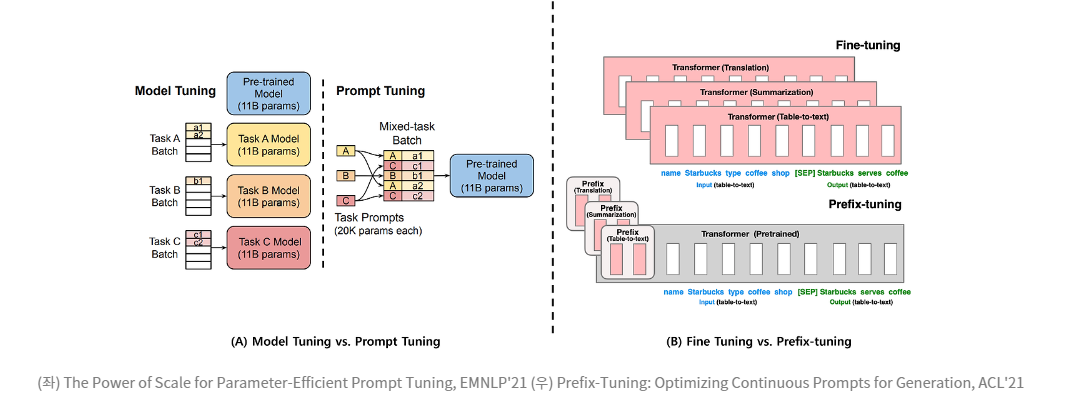
soft prompt로 가장 대표적인 방법론으로 prefix-tuning과 prompt-tuning 이 있습니다.
둘다 사전학습 모델을 그대로 가져와서 앞에 추가 prompt 임베딩을 추가해서 그 부분만 학습해서 특정 task에 맞출 수 있는 방법론입니다.
✒️ Prefix-Tuning: Optimizing Continuous Prompts for Generation(⭐2021-ACL-Long)
✒️ The Power of Scale for Parameter-Efficient Prompt Tuning(⭐2021-EMNLP-Main)
Chain-of-Thought 등 Prompt Engineering(Prompting) method
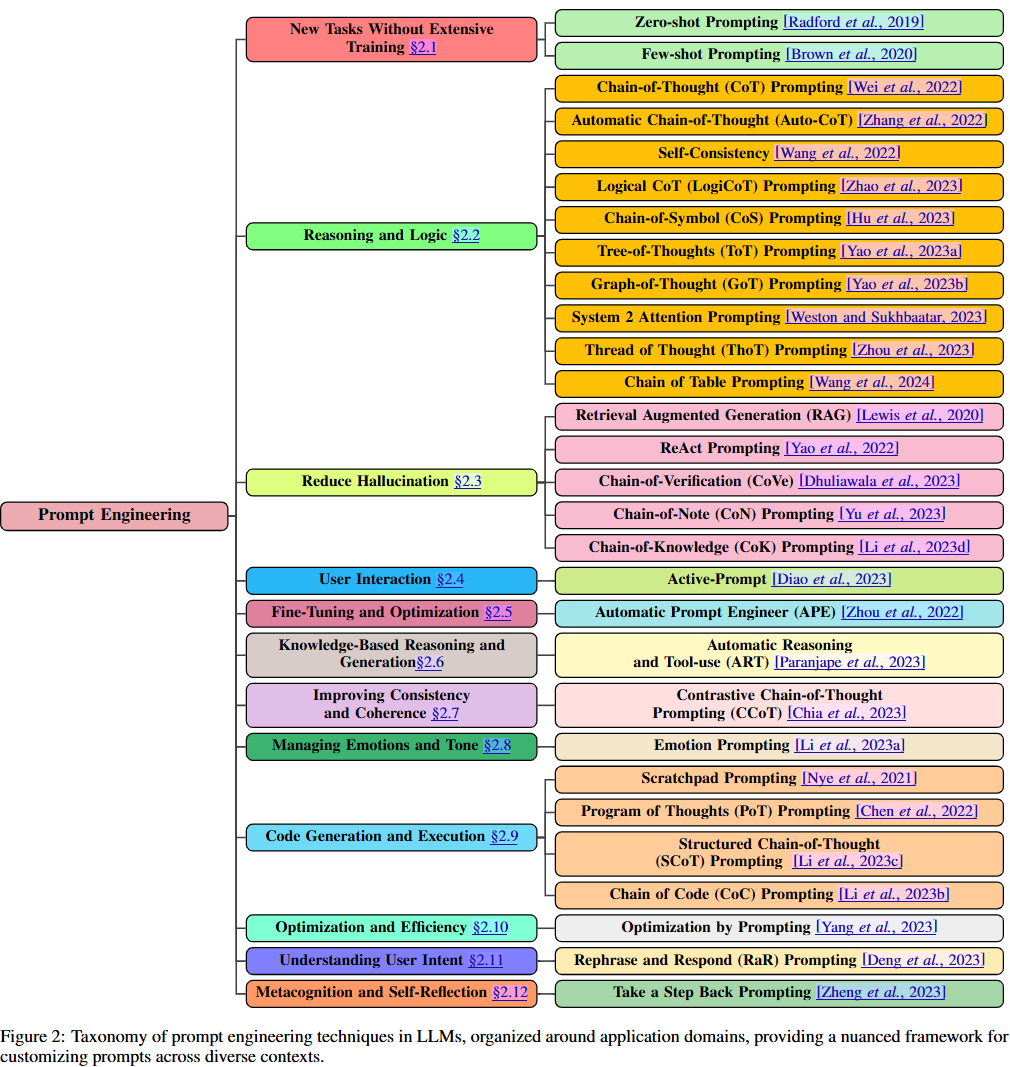
위의 texamony diagram of prompt engineering 은 Prompt Engineering에 대한 전반적인 최신 동향을 리뷰한 논문에서 가져왔는데, 기존에 알고 있던 Chain-of-Thought(CoT)같은 거 말고도 prompting method 가 꽤 많을 것을 확인할 수 있습니다.
🤗 PEFT (Parameter-Efficient Fine-Tuning)
PEFT는 대규모 사전학습 모델을 다양한 다운스트림 애플리케이션에 효율적으로 적응시키기 위한 라이브러리입니다. 기존 방식처럼 모델의 모든 파라미터를 미세 조정(Fine-Tuning)하지 않고, 추가적인 소수의 파라미터만 조정하여 학습합니다.
이 방식은 다음과 같은 장점을 제공합니다
- 컴퓨팅 및 저장 비용 절감: 조정해야 할 파라미터의 양이 극히 적기 때문에 대규모 모델을 훈련하고 저장하는 데 드는 비용이 대폭 감소합니다.
- 풀튜닝과 유사한 성능: 모델의 일부만 튜닝하더라도 완전 미세 조정(Fully Fine-Tuning)된 모델에 버금가는 성능을 달성할 수 있습니다.
=> 이러한 효율성 덕분에 PEFT는 소비자 하드웨어에서도 대규모 언어 모델(LLMs)을 훈련하거나 저장하는 것이 훨씬 더 접근 가능해졌습니다.
LoRA (Low-Rank Adaptation)
✒️ LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS(⭐ICLR-2022-Poster)
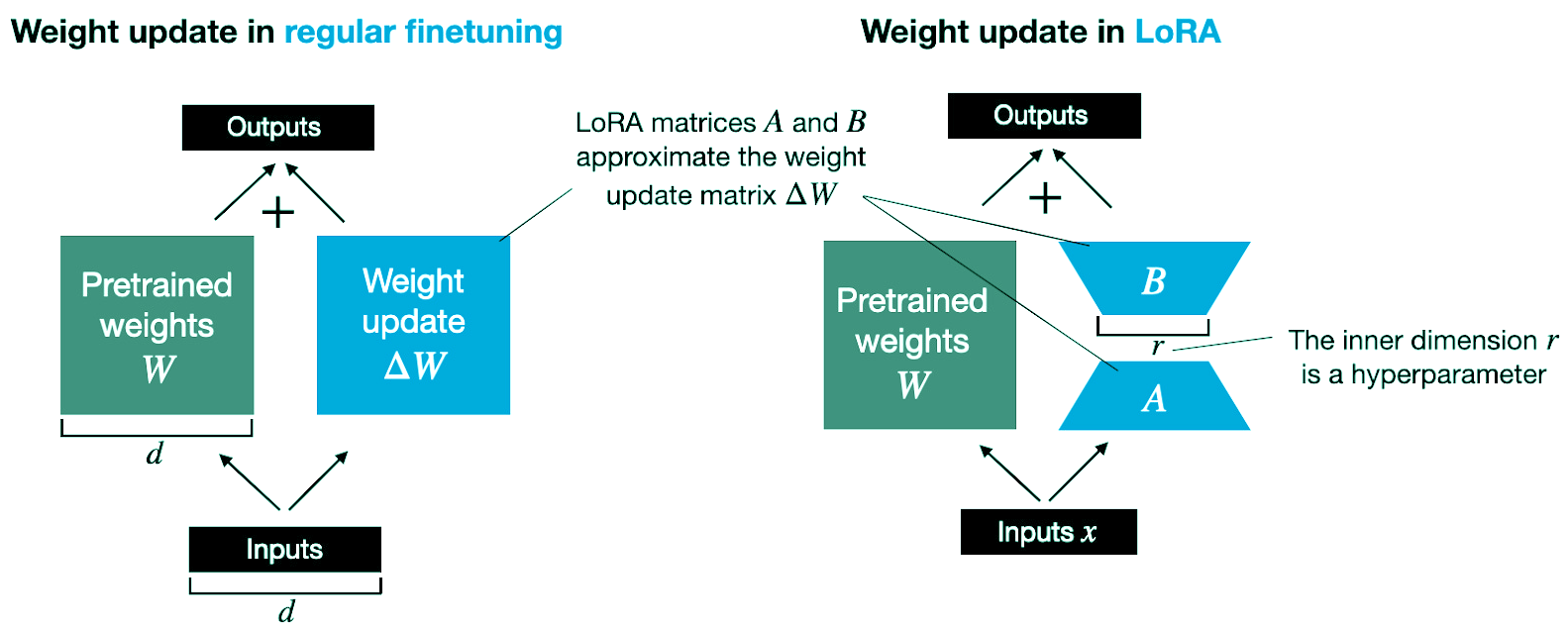
대표적인 PETF 방법론 중에 하나인 LoRA는 모델의 파라미터를 직접 수정하지 않고, reparametrizatioin 을 통해 저차원 행렬(보조 가중치)로 기존 parameter 임베딩을 구조화해서 학습합니다. 이를 통해 원본 모델의 구조를 유지하면서 메모리와 계산 비용을 절감할 수 있습니다. 원본 파라미터를 동결(Freeze)하여 모델의 무결성을 유지하기에, 기존 pre-trained model의 성능을 유지하면서 추가 파라미터만 학습합니다.
parameter efficient tuning : Prefix Tuning, Prompt Tuning, P-Tuning
Prefix Tuning, Prompt Tuning, P-Tuning 등 이 해당됩니다.
전자인 두 가지는 앞서 대략 설명했었고, P-Tuning만 간단하게 정리하자면,
✒️ GPT Understands, Too(⭐Journal: AI Open, 5, 208-215.)
✒️ P-Tuning v2:: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks(⭐2022-ACL-Short)
GPT에 P-Tuning을 적용하여 큰 성능 향상을 보이면서, P-Tuning은 2021년에 발표된 논문 "GPT Understands, Too"에서 처음 제안되었습니다.
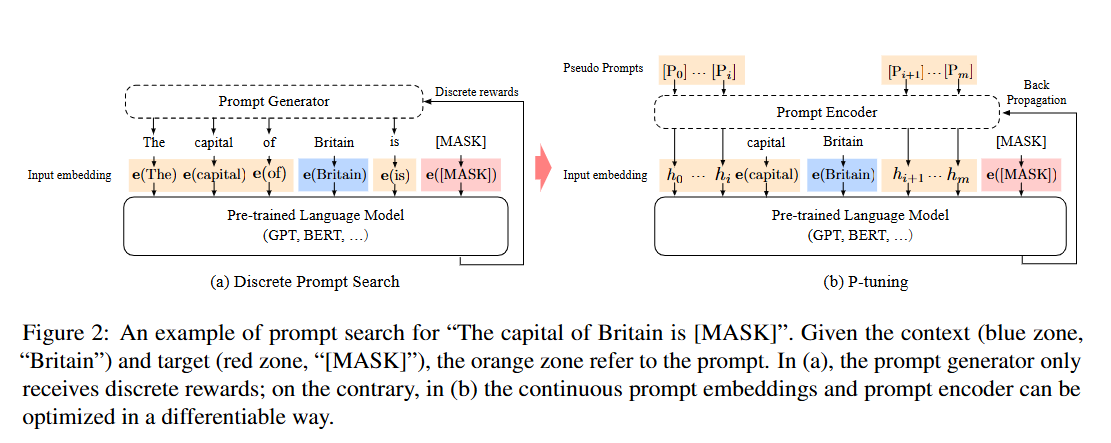
이 블로그를 P-Tuning이 잘 정리되어 있는데 한 번 확인해보길 바랍니다.
위의 그림에서 는 trainable embedding tensor(Prompt Encoder output)로 논문의 설명대로라면 원래의 언어모델이 표현할 수 있는 vocabulary 의 한계를 넘어 continuous space상에서 존재하는 prompt를 얻을 수 있게 된다고 합니다.
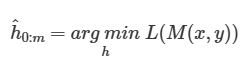
Prompt Encoder로는 LSTM을 사용했고, 언어모델의 parameter는 고정시켜두고 원래의 loss function 을 사용하여 continuous prompt 미분을 통해 optimize합니다. 현재의 soft-prompt인데, 당시 NLU task에 대해서 높은 성능 향상을 보였고, Fine-tuning보다 같거나 더 좋은 결과를 보여주고 있습니다.
P-Tuning v2는 기존 P-Tuning(2021)에서 prompts가 input embedding에만 들어가는데, tunable parameters 너무 적고 model prediction layer까지 대체 거리가 얼마인데 input embedding에만 prompting 하면 그 역할이 다 희석된다는 문제를 제기하면서 등장하였습니다.
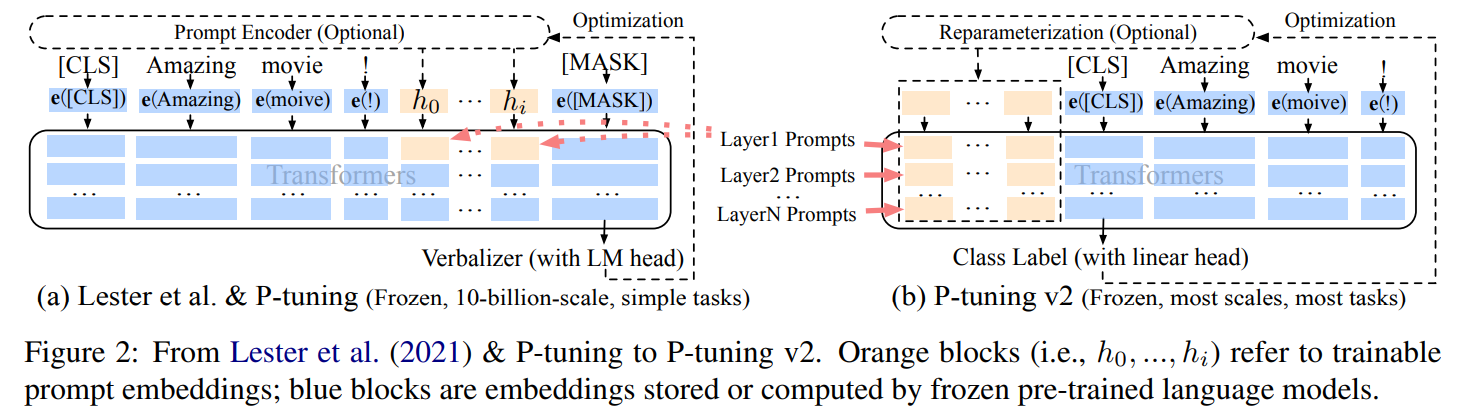
기존 P-Tuning 과 달리 모든 layers에 prefixed tokens가 prompting 됩니다. 그래서 tunable parameter가 0.01%에서 0.1-3%까지 증가하기에, 모델의 capa는 늘고, parameter-efficiency는 유지되면서 deeper layer까지 prompting이 들어가서 model prediction에 더 직접적인 영향을 끼칠수 있도록 된 겁니다.
추가 논문
📖 Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning (NeurIPS-2022-Main)
Few-shot ICL은 사전학습된 언어 모델이 새로운 작업에 대해 그래디언트 기반 훈련 없이도 수행할 수 있도록 설계된 기법입니다. Few-shot ICL과 PEFT를 정밀 비교하여 소수의 파라미터만 학습하여 모델이 새로운 작업을 수행할 수 있도록 하는 접근 방식인 PEFT가 정확도와 비용 효율성 측면에서 우월하다는 점을 입증했습니다.
📖 WARP: Word-level Adversarial ReProgramming(ACL-2021-Long)
✒️ WARP: Word-level Adversarial ReProgramming(⭐ACL-2021-Long)
WARP는 Prompt Engineering과 Adversarial Reprogramming을 결합하여 NLP 태스크를 해결하는 효율적인 방법입니다. 이 기법은 기존 Fine-Tuning보다 적은 파라미터로 높은 성능을 달성하며, 모델 본체(Transformer Layers)를 수정하지 않고 프롬프트와 Verbalizer를 학습하는 데 초점을 맞춥니다.
WARP의 학습 과정
1. 입력 시퀀스에[P_1], ..., [P_N]및[MASK]삽입
2. MLM 헤드를 통해[MASK]출력 벡터 생성
3. Verbalizer 임베딩과 비교하여 가장 가까운 클래스를 예측
4. 크로스 엔트로피 손실을 계산하여 프롬프트와 Verbalizer를 학습
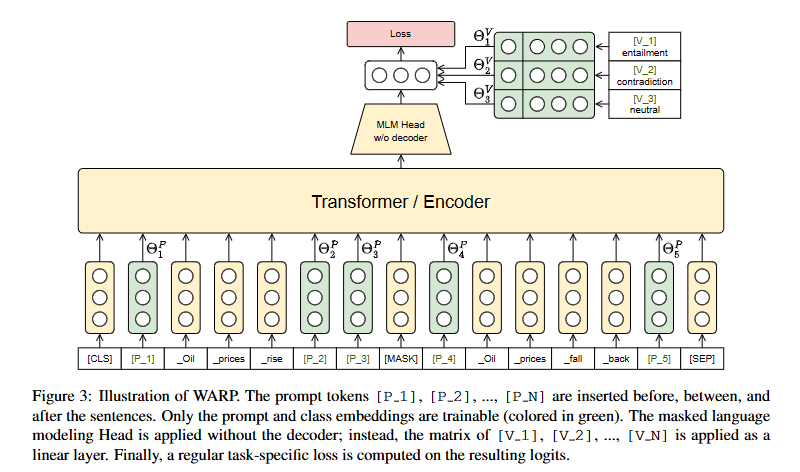
추가적인 디코더 없이, [MASK] 토큰의 출력 벡터를 활용합니다. Verbalizer [V_1], [V_2], ..., [V_C]는 클래스 레이블과 매핑된 워드 임베딩으로 구성됩니다.출력 벡터와 Verbalizer 임베딩 [V_1], [V_2], ..., [V_C] 간의 유사도를 계산해 클래스를 예측합니다. Verbalizer를 기반으로 생성된 로짓에 대해 크로스 엔트로피 손실을 계산하여 학습합니다.
예를 들어, 입력 문장 "Oil prices rise"에서 [MASK]에 대한 출력이 Verbalizer "entailment"에 가장 가깝다면, 해당 문장은 Entailment 클래스로 분류됩니다.
=> 학습 가능한 파라미터는 프롬프트와 Verbalizer 임베딩뿐이며, 기존 Fine-Tuning보다 훨씬 적은 수의 파라미터로 작업 수행 가능한다는 것을 보였습니다.
📖 Visual Prompt Tuning(ECCV-2022)
✒️ Visual Prompt Tuning(⭐ECCV-2022)
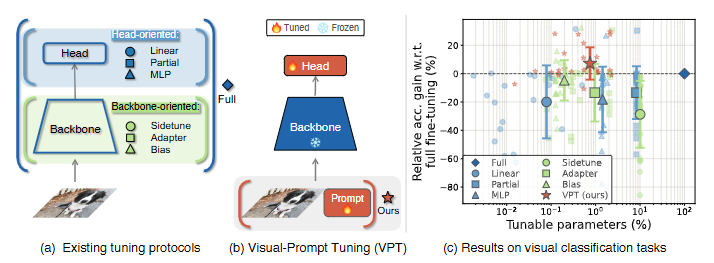
Visual Prompt Tuning(VPT)은 대규모 ViT 모델을 효율적으로 학습하기 위한 파라미터 효율적 튜닝 기법입니다. 기존의 Full Fine-Tuning 방식은 모델의 모든 백본 파라미터를 업데이트하는 데 반해, VPT는 입력 공간(Input Space)에 학습 가능한 파라미터를 추가하면서 백본 파라미터는 동결(Frozen) 상태로 유지합니다. 이렇게 추가되는 파라미터는 전체 모델 파라미터의 1% 미만으로, 매우 적은 자원을 사용하면서도 높은 성능을 제공합니다.
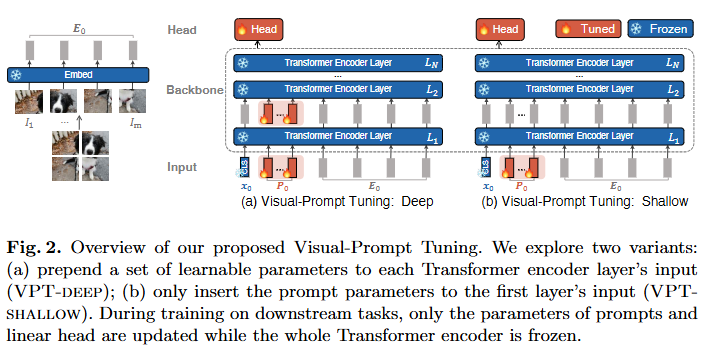
본 논문에서는 visual-prompt tuning을 하는 두 가지 방법을 제시했습니다.
1. VPT-Deep: Transformer Encoder를 거칠 때 마다 learnable한 visual prompt를 두고 학습
2. VPT-Shallow: 제일 처음 input 시에만 learnable한 visual prompt를 두고 학습
VPT는 다양한 다운스트림 태스크에서 기존의 파라미터 효율적 튜닝 기법보다 뛰어난 성능을 보여주며, 일부 태스크에서는 Full Fine-Tuning을 초과하는 결과를 기록합니다. 특히, 데이터 스케일과 모델 크기에 관계없이 안정적인 성능 향상을 제공하며, 태스크별 저장 비용을 크게 줄일 수 있습니다. 이는 적은 리소스로도 대규모 모델의 강력한 성능을 활용할 수 있는 혁신적인 접근법입니다. Computer Vision 분야에서 Prompt Tuning을 활용하는 최초의 연구 사레입니다.
참고한 블로그에 설명이 정말 잘 되어있습니다.
오늘도 끝~
