Semantic Text Similarity 프로젝트 (NLP 대회)를 진행하고 있다. 10일 간 진행을 하고 있고 Lv.1 팀원들과 함께하고 있다. 막내로서 모든 일을 하고 있다. 벨로그에 이번 일주일은 STS(Semantic Text Similarity)를 하면서 해본 실험과 여러 활동들을 정리하려고 한다.
Semantic Text Similarity(STS)란?
STS란 두 텍스트가 얼마나 유사한지 판단하는 NLP Task다. 일반적으로 두 개의 문장을 입력하고, 이러한 문장쌍이 얼마나 의미적으로 서로 유사한지를 판단한다.
STS는 N21, N2N, N2M Task 중 N21 Task에 해당
: 문장 1의 벡터, 문장 2의 벡터를 비교해서 유사도값(float 값, 0~5) 값을 뽑아내면 내기에 N21 task에 해당된다.
예를 들어 데이터는 이런 형식이다.
| id | sentence1 | sentence2 | label |
|---|---|---|---|
| 001 | 주택청약조건 변경해주세요. | 주택청약 무주택기준 변경해주세요. | 2.4 |
| 002 | 극의전개가너무느릿하여답답합니다 | 전개가 너무 느려서 속터진다 | 3.8 |
| 003 | 앞머리 새로 하셨습니다. ^^ | 가방에 넣어 다니면서 조금씩 먹습니다. | 0.0 |
문장 간 유사도(Similarity)를 측정하고자 생각해보았던 방법
[1] Sentence BERT로 문장을 임베딩해서 임베딩 벡터간의 거리를 제거나, 코사인 유사도 계산해보자!
문장이 주어졌다는 면에서 가장 먼저 떠올린 방법이다. 예전에 sBERT를 사용해 문장을 768 차원으로 임베딩 해본 적이 있었다.
그래서 실제로 Sentence Transformer (Hugging Face)를 참고해서 아래 처럼 문장을 임베딩(인코딩) 시켰다.
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
embeddings = model.encode(sentences)
print(embeddings)문장 A, B에 대해서 코사인 유사도(Cosine Similarity)를 통해 직접 계산해서 유사도를 따져보기도 했는데 결과는 참담했다....
🤔 실패 이유
1) 일단 target 값 즉 유사도 값이 0~5로 나와야 하지만 코사인 유사도 값은 (-1,1) 사이의 값으로 나온다
2) 모델 학습을 사용한 방법론이 아니기에, 실제 정답 label값(유사도 값)과의 차이가 컸다... 솔직히 말하자면 완전 말도 안되는 값이 나왔다.
3) pre-trained 모델을 너무 믿었다.
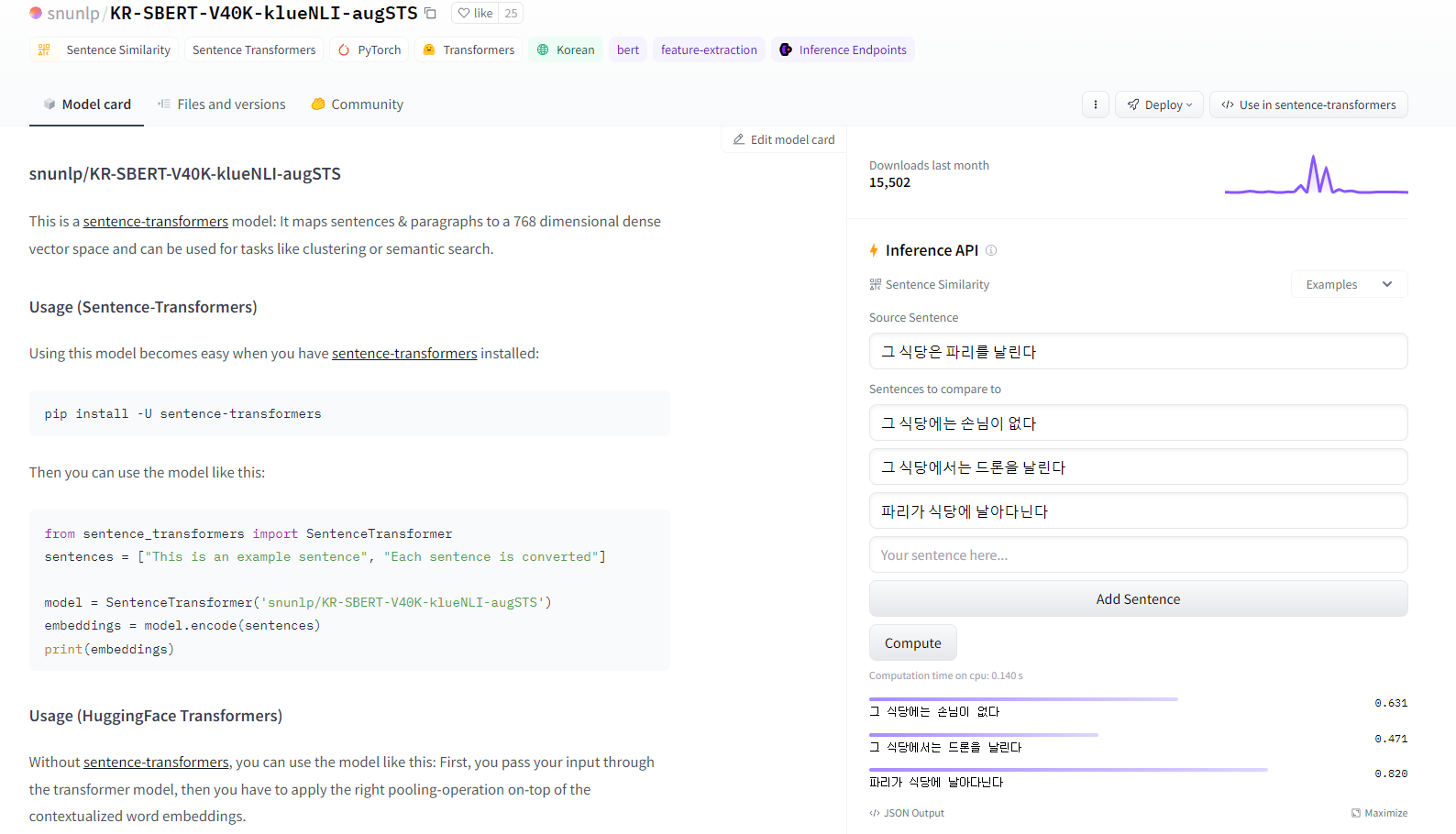
위의 사진이 실제로 사용한 'snunlp/KR-SBERT-V40K-klueNLI-augSTS'모델을 사용해서 문장 유사도를 따진 결과다. STS 용의로 사전 학습된 모델이기에 저 모델을 선택했고, 사진 속에서 실제 사이트에서 했을 때는 괜찮아 보였다. 하지만, 현재 가지고 있는 구어체가 많이 포함된 데이터에 있어서 뭔가 잘 작동을 안 하는 느낌이 들었다.
[2] sBERT 같은 모델로 문장들을 같은 차원으로 임베딩하고 그걸 Fully Connected Layer에 input으로 넣어줘서 output이 하나로 나오게 Sequential model를 만들자!
전에 sBERT를 가지고 문장을 임베딩했던 경험과 그 결과가 좋았어서 쉽게 sBERT를 놓아주지 못했다. 또한 2020년에 sBERT가 나왔길래 한 번 믿고 써보자라는 생각도 있었다.
그래서 아래와 같은 step을 구성해 봤다.
(STEP1) 문장 쌍 (a,b)를 <SEP> 토큰으로 붙여 한 문장으로 만든 후, 모두 sBERT를 사용해 768 차원으로 만든다.
| id | sentence1 | sentence2 | label |
|---|---|---|---|
| 001 | 주택청약조건 변경해주세요. | 주택청약 무주택기준 변경해주세요. | 2.4 |
위와 같이 데이터가 있다면,
"주택청약조건 변경해주세요.<SEP>주택청약 무주택기준 변경해주세요." 이렇게 붙여서 이걸 sBERT encoding을 통해 768차원 벡터로 만든다.
(STEP2) 일반적인 Dense, Fully Connected Layer을 구성해 마지막 output을 node1개로 나오게 한다.
데이터가 100개라면 (100,768)로 데이터가 임베딩 되어 있을 것이다.
이제 다층 hidden layer를 구성해서 (768, 384) -> (384, 192) -> (192, 128) -> (128, 64) -> (64, 16) -> (16, 1) 이런식으로 Sequential Layer 모델을 만들면 된다.
🤔 실패 이유
1) 성능이 그닥이다...
누가 봐도 LLM 시대에 Fully connected layer인가 싶다...
2) 이건언 자연어의 sequence, 순서라는 큰 데이터 특징을 반영한 모델링이 아니다.
솔직히,, task가 N21인 간단한 task이기에 이걸 굳이 이렇게까지 layer을 쌓을 필요가 있을까 했다.
그래서 좀 더 쉽게 진행하고자 pre-trained 모델에 head만 바꿔줘서 N21 task를 구현될 수 있도로 바꿔보는 시도를 하기 시작했다.
[3] pre-trained sBERT 모델을 사용해, AutoModelForSequenceClassification와 AutoTokenizer를 통해 head만들어서 N21 task 수행
아래 내용이 내가 실제로 작성한 코드이다. 시간이 없길에 baseline 코드와 매우 유사하게 chatGPT로 error를 해결하면서 만들어보았다.
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, EvalPrediction,EarlyStoppingCallback
import pandas as pd
from scipy.stats import pearsonr
import wandb
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class SimilarityDataset(Dataset):
def __init__(self, filename, tokenizer, max_length=128):
self.dataframe = pd.read_csv(filename)
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.dataframe)
def __getitem__(self, idx):
record = self.dataframe.iloc[idx]
inputs = self.tokenizer.encode_plus(
str(record['sentence_1']), str(record['sentence_2']),
add_special_tokens=True,
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
).to(device)
inputs = {key: val.squeeze(0).to('cpu') for key, val in inputs.items()} # Ensure tensors are on CPU
inputs["label"] = torch.tensor(record['label'], dtype=torch.float)
return inputs
class SimilarityDatasetWithoutLabels(Dataset):
def __init__(self, filename, tokenizer, max_length=128):
self.dataframe = pd.read_csv(filename)
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.dataframe)
def __getitem__(self, idx):
record = self.dataframe.iloc[idx]
inputs = self.tokenizer.encode_plus(
str(record['sentence_1']), str(record['sentence_2']),
add_special_tokens=True,
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
inputs = {key: val.squeeze(0).to('cpu') for key, val in inputs.items()}
return inputs
def compute_metrics(p: EvalPrediction):
predictions = p.predictions
if len(predictions.shape) == 2:
predictions = predictions[:, 0] # Extract the first column if predictions are 2D
return {"pearson": pearsonr(predictions, p.label_ids)[0]}
# snunlp/KR-SBERT-V40K-klueNLI-augSTS
print(f"Using device: {device}")
tokenizer = AutoTokenizer.from_pretrained("snunlp/KR-SBERT-V40K-klueNLI-augSTS")
train_dataset = SimilarityDataset("/data/ephemeral/home/becky/data/train.csv", tokenizer)
dev_dataset = SimilarityDataset("/data/ephemeral/home/becky/data/dev.csv", tokenizer)
test_dataset = SimilarityDatasetWithoutLabels('/data/ephemeral/home/becky/data/test.csv', tokenizer) # For prediction
# , hidden_dropout_prob=0.3
model = AutoModelForSequenceClassification.from_pretrained("snunlp/KR-SBERT-V40K-klueNLI-augSTS", num_labels=1)
model.to(device)
training_args = TrainingArguments(
output_dir='./lucid',
num_train_epochs=40,
per_device_train_batch_size=8,
per_device_eval_batch_size=64,
warmup_steps = 600,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=500,
do_eval=True,
save_total_limit=2,
report_to="wandb",
run_name="lucid",
save_strategy='steps',
evaluation_strategy='steps',
save_steps=500,
eval_steps=500,
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
trainer.train()학습은 너무나 잘되고 있다는 생각이 들었고, 문제가 없다고 생각했다.
하.
지.
만.
문제는 성능이다. 잘 돌아갈 뿐,,,
baseline 코드 속 klue/roberta-large 모델 보다 훨씬 성능이 안 나왔다. 평가지표가 pearson 값인데,,,

이런 말도안되는 성능이 나와버렸다...
이건 뭐 튜닝을 더 한다고 나아질 수준이 아니다..
🤔 실패 이유
1) baseline 속 모델인 roberta 모델보다 1,2년 전의 모델인 sBERT를 사용했기에 성능이 더 낫을 수밖에 없다고 생각한다.
2) 데이터 EDA를 아직 제대로 보지 않았지만, 일단 label 분포 값에서 불균형이 좀 있다는걸 확인했고, 팀원 중 한 명이 이로 인한 overfitting을 원인으로 보았다.
일단 이정도로 해서 sBERT 실험 실패기를 정리하겠다.
여기까지하면서 알게 된 점을 정리해보자면,
✅ sBERT를 사용하는 건 완벽히 익혔다.
✅ Hugging Face의 AutoTokenizer, AutoModelForSequenceClassification가 어떤 역할을 수행하는지 알 수 있었다.
✅ 다른 모델(pre-trained 모델)을 Hugging Face에서 실험해보면서 찾아보고 쉽게 사용하는 방법을 익혔다.
💡transformer의 AutoTokenizer
일단, AutoClass는 pretrained model을 이름이나 path를 이용해 불러올 수 있는 shortcut이라고 보면 된다. Pretrained model만 있다면, 수행하고자 하는 task에 적합한 AutoModel와 AutoTokenizer을 선택하기만 하면 된다.
AutoTokenizer은 입력을 Pretrained model의 tokenizer을 불러와 token으로 바꾸는 역할을 한다.
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
>>> {'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
>>> 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
>>> 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}- attention_mask는 일반 토큰이 자리한 곳(1)과 패딩 토큰이 자리한 곳(0)을 구분해 알려줌
- token_type_ids는 문장 id임
- input_id는 토큰이 모델 속 vocab.json에 정의된 인덱스 번호를 알려준다.
중요한 것은, AutoTokenizer을 초기화할 때 사용하는 model name을 AutoModel을 초기화할 때 사용한 것과 동일한 것으로 해야 한다는 것이다. 이는 model과 tokenizer이 동일한 tokenization 방법을 사용하도록 하기 위함이다.
tokenizer를 실행할때 알아야 하는 옵션!
batch_inputs = tokenizer(
sentences,
padding="max_length", # 문장의 최대 길이에 맞춰 패딩
max_length=12, # 문장의 토큰 기준 최대 길이
truncation=True, # 문장 잘림 허용 옵션
)- 만약 위의 경우 특정 문장이 12개의 토큰보다 많다면 잘려지고, 적다면 [pad] 에 해당되는 0으로 채워진다.
💡transformer의 AutoModelForSequenceClassification
AutoTokenizer와 마찬가지로, 사용하려는 task에 맞는 pretrained model을 다음과 같이 불러올 수 있다.
from transformers import AutoModelForSequenceClassification
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)앞에서 생성한 batch_inputs을 다음과 같이 모델에 입력으로 줄 수 있으며,
pt_outputs = pt_model(**batch_inputs)출력으로 얻은 logit을 softmax 함수에 통과시켜 확률값을 얻을 수 있다.
import torch.nn as nn
pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
print(pt_predictions)
>> tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)이렇게 불러온 모델들은 torch.nn.Module을 상속하는 객체들이다. 따라서 일반적인 training loop를 이용해 훈련시킬 수 있다. 혹은, HuggingFace에서 제공하는 Trainer class를 이용해 보다 편리하게 훈련시킬 수 있다.
Fine-tuning 된 모델은 다음과 같이 저장할 수 있다.
pt_save_directory = "./pt_save_pretrained"
tokenizer.save_pretrained(pt_save_directory)
pt_model.save_pretrained(pt_save_directory)이렇게 저장된 모델은 처음과 같이 불러오면 된다.
pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")💡 HuggingFace의 놀라운 점 중 하나는.. PyTorch로 모델을 저장했어도 TensorFlow로 불러오거나, 그 반대도 가능하다는 것이다.
🔖 Reference
sBERT 허깅페이스 배포 모델
[논문리뷰] SBERT(Sentence-BERT)와 SentenceTransformers
transfomer tokenizer
[HuggingFace] Pipeline & AutoClass
