Boostcamp
1.[부스트캠프 AI Tech] 첫 시작 후기 (D+1)
집 리모델링과 여러 일로 바빠서 부캠 6기 합격후기를 올리고 싶었는데 이제야 첫 시작 후기를 남기게 되었다.이러한 과정을 겪고 나름 코테도 열심히 준비해서 될지 안될지도 모르는 희망을 가지고 여기까지왔는데, 결과는 합격이었다.집 정리가 좀 마무리되어서 이 생활에 적응이
2.[부스트캠프 AI Tech] 공부 정리 (D+2)

위의 그림은 영국 코미디 쇼인 ‘몬티 파이썬의 날아다니는 서커스(Monty python's flying circus)’ 넷플릭스 포스터인데, 놀랍게도 이 포스터는 Python 이라는 프로그래밍 언어의 이름의 시작점이 되었다. 네덜란드 출신의 귀도 반 로섬(Guido v
3.[부스트캠프 AI Tech] 공부 정리 (D+3)

일주일 중 절반이 지나가는 느낌이 나는 수요일이다..부스트캠프 3일차인데,, 몸 컨디션이 너무 안 좋다.. 오랫동안 오래 앉아있고자 체력을 위해 시작하기도 했던 발레 수업이 지금 문제가 되고 있다. 화요일 발레 수업 후, 오늘 수요일의 아침부터 이 글을 포스팅하고 있는
4.[부스트캠프 AI Tech] 공부 정리 (D+4)
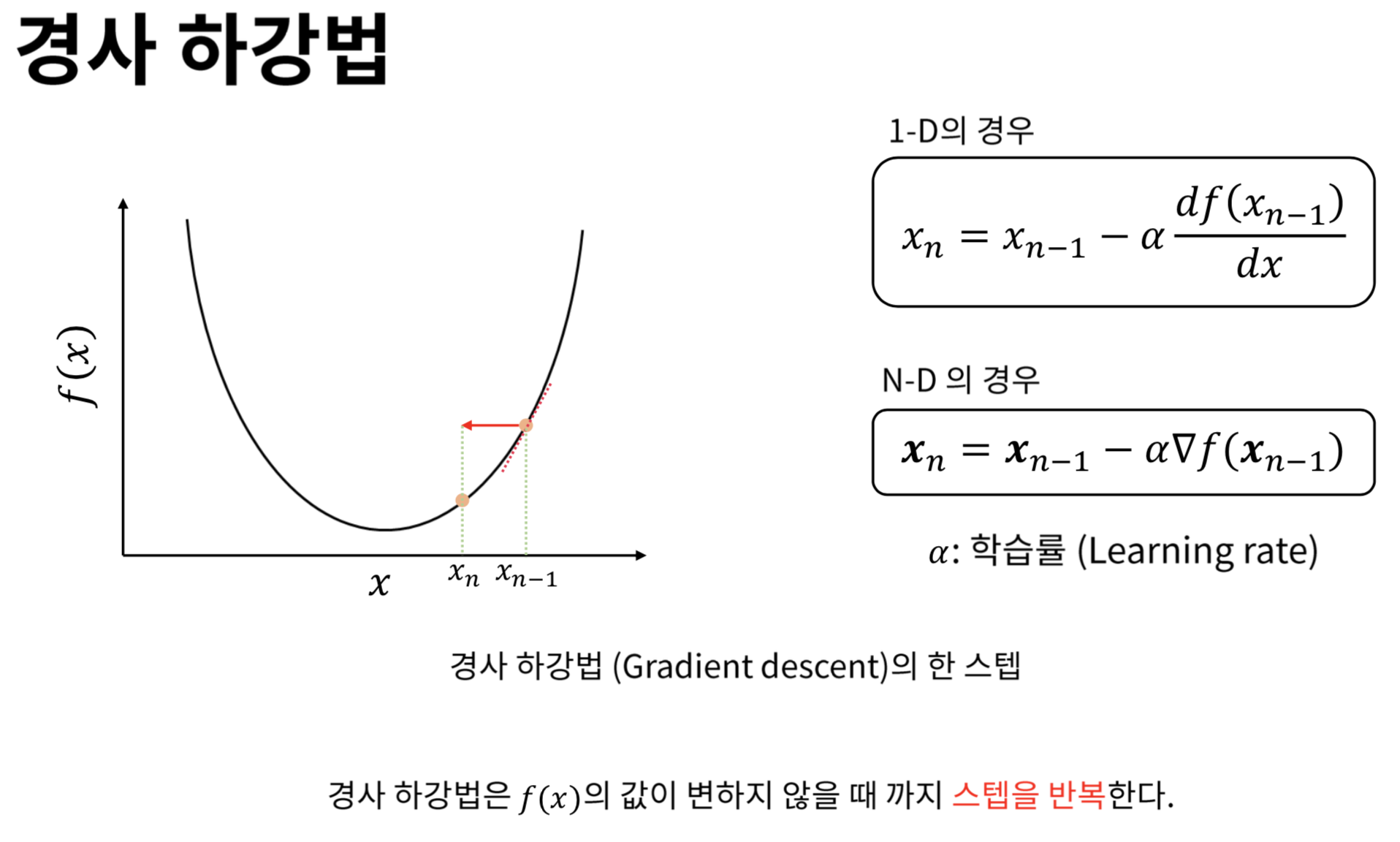
부캠 시작 4일차, AI를 위한 통계, 수학 강의들을 들었다. 원래 전공이 응용통계학이기에 전에 것들을 복습하는 관점에서 영상을 보았다.경사하강법, 딥러닝 학습 방법에 대해서 배웠는데 기억에 남기고 싶거나 중요한 내용들을 다시 한 번 정리해보려고 한다.경사상승법 : 기
5.[부스트캠프 AI Tech] 공부 정리 (D+5)

5일차의 하루도 끝이 났고, 기본적인 통계와 RNN, CNN에 대해서 간단하게 배울 수 있는 시간이었다.주말에는 사실 공부한 걸 정리하고 싶지만 너무 피곤해서 쉬어야 겠다는 생각부터 든다. 이 벨로그도 수정과 수정을 반복하면서 천천히 배운 내용을 채워 가려고 한다.
6.[부스트캠프 AI Tech] 공부 정리 (D+6)

일주일의 부캠을 끝냈다. 월요일을 맞았지만 날씨도 급격하게 추워지면서 피곤은 말할 수 없을 정도로 심해졌다. 다행인 점은 이번주 강의는 전보다 확연히 적다는 것이다. 6시간 정도면 모든 일주일치의 강의를 수강할 수 있기에, 저번주에 제대로 못 정리했던 강의를 하나하나
7.[부스트캠프 AI Tech] 공부 정리 (D+7)

PyTorch에 대한 강의를 듣고 있는 주이다. 생각보다 강의는 짧은데 하나하나 직접 정리하다보니 시간이 좀 걸리는 거 같다. 그 과정에서 궁금한 점이 몇개 있어서 찾아보다가 적게 되었다.7일차를 맞은 근황은 허리 통증이 생각보다 심하다는 점이다. 최근에 하던 일을 그
8.[부스트캠프 AI Tech] 공부 정리 (D+8)

수요일은 너무 나도 피곤하다. 팀 전체적으로 아침 인사할 때 보면 피곤해보인다.. 이번 주 우리 팀의 모더레이터는 나여서,,, 진행을 어떻게든 하려고 노력을 했다. 내용도 좀 어려운 부분이 있다보니까 좀 지친 면도 있지만 다들 열심히 하려고 노력한거 같다.
9.[부스트캠프 AI Tech] 공부 정리 (D+9)
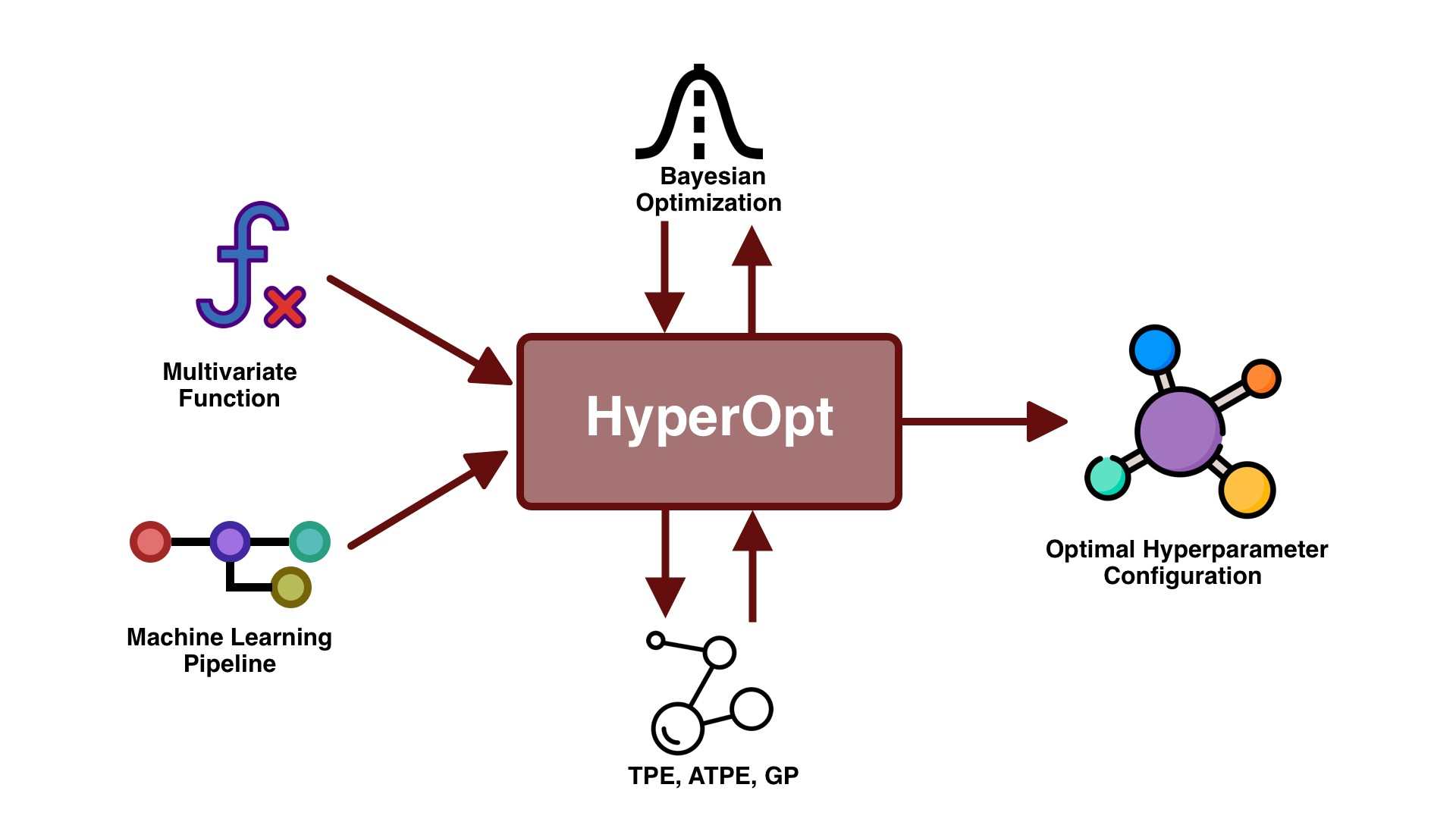
하이퍼 파라미터 튜닝으로 대단하게 성능을 끌어 올릴 수는 없지만, 마치 튜닝이라는 의미에서 알 수 있듯이 최고의 결과를 위해서 살짝 더 나은 결과를 얻고자 실행해보는 것이 하이퍼 파라미터 조정, 즉 하이퍼 파라미터 튜닝이다. 모델 스스로 학습하지 않는 값(learnin
10.[부스트캠프 AI Tech] 공부 정리 (D+10)

오늘날의 딥러닝 모델들의 천문학적인 파라미터 수를 보면, 결론적으로 연구 결과는 학습 시 필요한 컴퓨팅 파워와 관련이 있을 수 밖에 없다는 생각이 들었다. 그래서 "연구는 장비빨..."이라는 멘트가 강렬히 머리에 박혀있다. 수업 중에 배운 GPU에 대해서 알아보던 중
11.[부스트캠프 AI Tech] 공부 정리 (D+11)

지금 이 그림을 보는 사람들은 도대체 이건 뭐지? 싶을 수도 있는데,,,,사실 저건 이번주 월요일부터 사용하고 있는 목 디스크 소프트 칼라 즉, 목 보호대다...목이 왼쪽으로 뱡향은 오른쪽에 비해 돌리는데 자주 문제가 있었고, 꾸준히 목을 스트레칭과 필라테스 학원에서
12.[부스트캠프 AI Tech] 공부 정리 (D+12)

CNN 기초를 배우면서, 다시 한 번 번아웃이 오기 직전이다.어렵다는 느낌보다, 내가 이렇게 dimension 계산을 잘 못했었나? 라는 생각이 든다.
13.[부스트캠프 AI Tech] 공부 정리 (D+13)

내가 NLP 트랙을 선택한 이유는 시퀀스 자료형, 시계열 데이터에 대한 관심 때문이었다. 하지만, 공부를 하면서 점점 미궁으로 빠지는 것 같다. 기본적인 LSTM, RNN, GRU를 하나하나 다시 보면서 이게 이런 거..였구나..를 외치고 있다..
14.[부스트캠프 AI Tech] 공부 정리 (D+14)

Transformer에 대해서 집중적으로 배울 수 있는 시간이었다. 약간의 유머로 위의 사진은 영화 트랜스포머의 옵티머스 프라임이다..Transformer 구조에 대해서 항상 의문이 많았고, 제대로 파헤쳐서 보고 싶었는데 이제, 좀 정리를 해볼 수 있을 거 같다.🔖
15.[부스트캠프 AI Tech] 공부 정리 (D+15)

위의 사진은 2017년 워싱턴대학교 연구팀에서 영상 합성에 GAN을 적용하여 만든 ‘오바마 전 미국 대통령의 가짜 영상’ 속 사진이다. 이번주의 마지막 날에은 생성 모델(Generative model)에 대해서 배우는 시간이었다.
16.[부스트캠프 AI Tech] 공부 정리 (D+16)

NLP 이론 공부를 제대로 해볼 수 있는 도메인 별 기초 이론을 공부하는 주간이 시작되었다. 제대로 구현해보면서 이해할 수 있다는 점이 매우 좋다고 생각한다.이번 일주일을 정말 제대로 공부해서 기초를 제대로 쌓고 싶다!구체적으로는 1,2강 내용에 대해서 얘기하자면, c
17.[부스트캠프 AI Tech] 공부 정리 (D+17)

이고잉 님의 깃허브 특강이 있었다.오전 10시부터 오후 4시까지 5시간 동안 수업했다. 생각보다 길게 실시간 강의를 하다보니 지치지 않고 열심히 듣자고 다짐했다.원래 깃허브를 쓰지만 gui 환경인 웹상에서 쓰는데 익숙했기에, vscode 내부에서 git를 config
18.[부스트캠프 AI Tech] 공부 정리 (D+18)
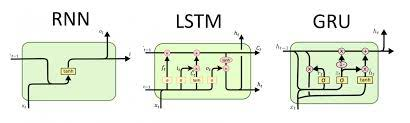
RNN에 대해서 제대로 공부할 수 있는 시간이었다. Basic RNN 이라고 볼 수 있는 (Vanilla) RNN 부터 LSTM, GRU에 대해서 배워 볼 수 있었다. 기존에 RNN를 공부하면서 가지고 있던 어떻게 모델 내부가 작동하고 forward를 하는지 등을 자세
19.[부스트캠프 AI Tech] 공부 정리 (D+19)

자연어 처리 과제 중 과제 1. "Data Preprocessing & Tokenization"를 하면서 의문이었고, 찾아본 내용을 정리하였다.파이썬 문법 적인 내용, 모듈에 대한 내용 등 여러 내용에 대해서 찾아보았고, 이렇게 기록하게 되었다.
20.[부스트캠프 AI Tech] 공부 정리 (D+20)

자연어 처리 과제 중 과제 2. "RNN_based_Language_Model"를 하면서 의문이었고, 찾아본 내용을 정리하였다.PyTorch 함수에 대해서 추가로 찾아보았고, 여기에 정리하려고 한다.기본적인 RNN, Vanilla RNN 구현을 했고, 그 과정에서 코드
21.[부스트캠프 AI Tech] 공부 정리 (D+21)
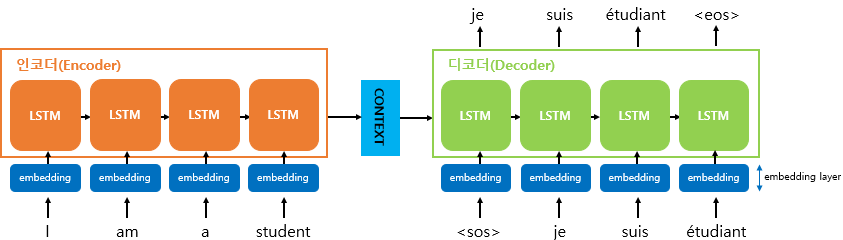
seq-seq, beamsearch, bleu score에 대해서 알아보았다.
22.[부스트캠프 AI Tech] 공부 정리 (D+22)
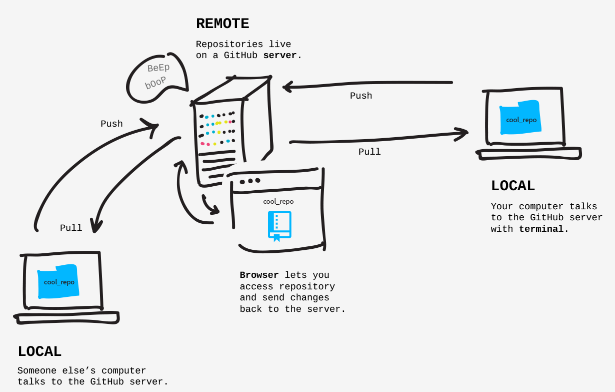
egoing님의 깃허브 특강을 들었다. 원격 저장소로 연결하는데 있어서 관련된 내용을 들었다. 이젠 나름 깃허브를 마스터 한 거 같다. 플젝하면서 본격적으로 깃허브 사용해보면 좋을 거 같다.일단 오늘 수업에 가장 중요한 내용은 pull/push/commit를 구분해서
23.[부스트캠프 AI Tech] 공부 정리 (D+23)
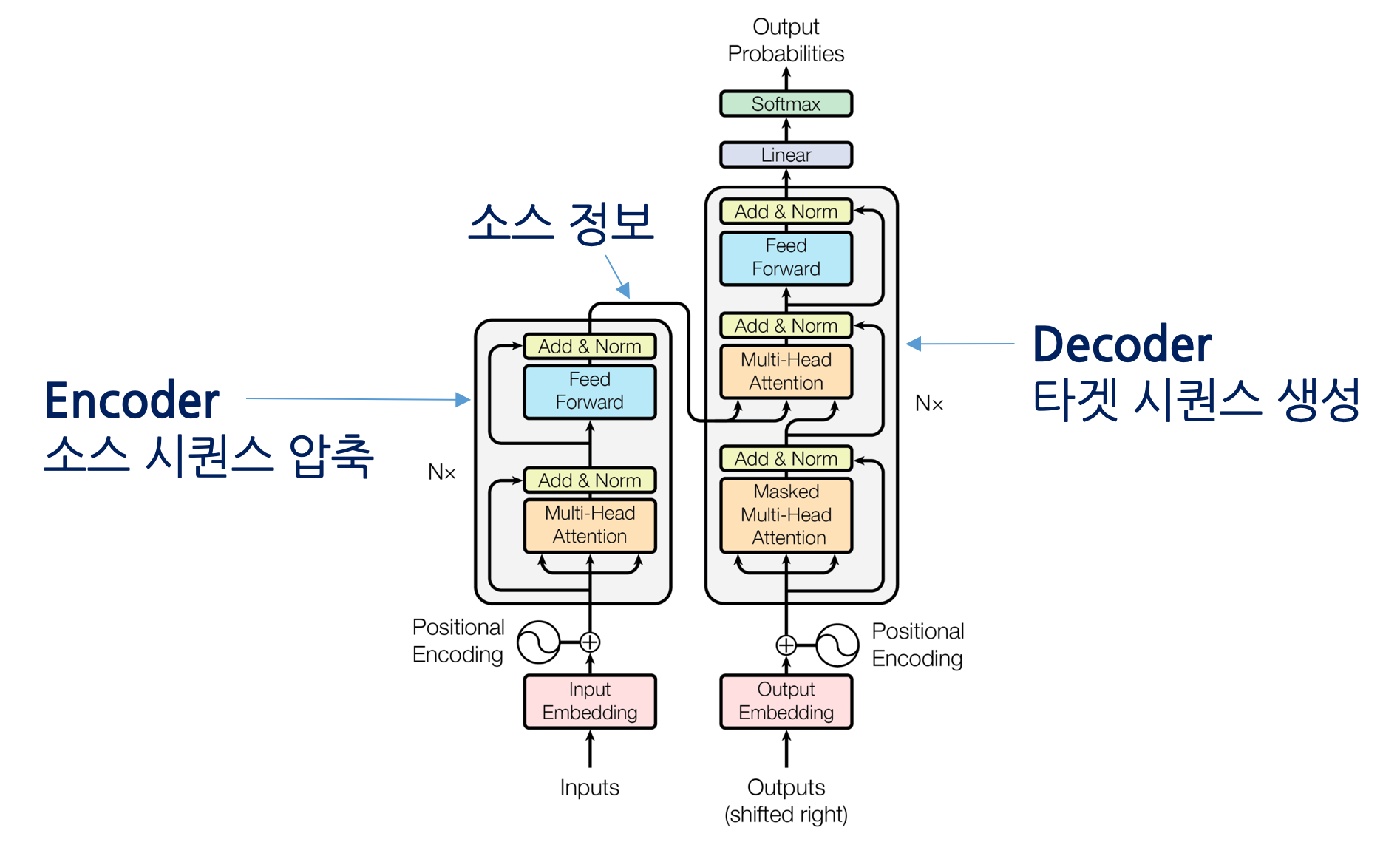
Transformer에 대해서 하나씩 뜯어보면서 그 내부를 자세히 알 수 있는 시간이었다. 내 벨로그 논문리뷰에 "Attention is All You Need(2017)"에도 transformer에 대해서 정리할 예정이기에. 현재 포스팅에서는 간단하게 정리 정도만하고
24.[부스트캠프 AI Tech] 공부 정리 (D+24)
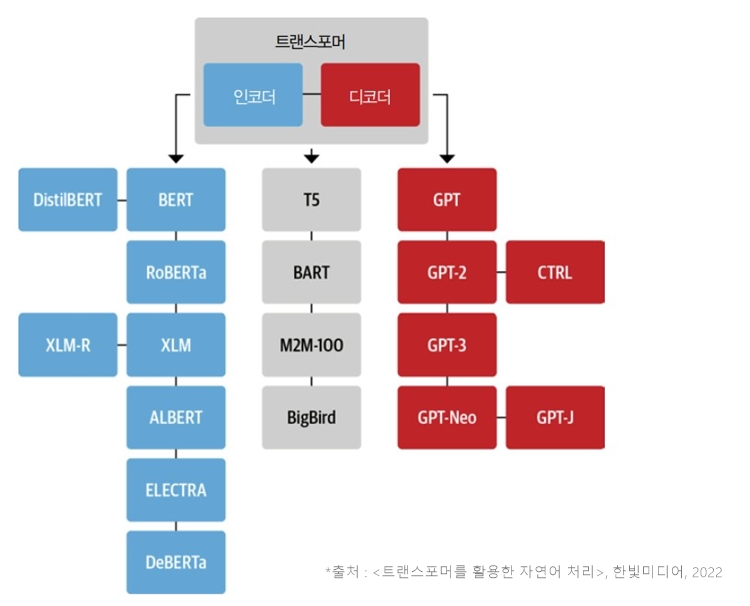
Self-supervised Pre-Training Model인 GPT, BERT의 차이를 이해하고 GPT의 발전사를 정리해볼 수 있는 시간이었다.
25.[부스트캠프 AI Tech] 공부 정리 (D+25)
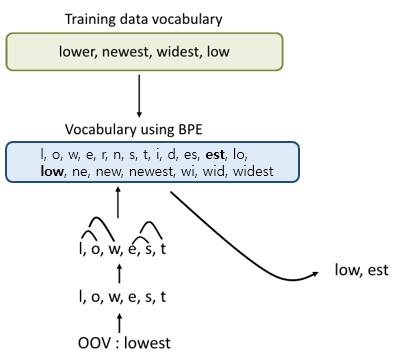
이번주 과제였던, Sub-Word Tokenization과 Byte Pair Encoding (BPE) 그리고 두번째 과제였던, 번역 모델 전처리 방법론인 Collating과 Bucketing에 대해서 다시 한 번 정리해보고 코드적인 부분에서 궁금했던 점을 정리하였다.
26.[부스트캠프 AI Tech] 공부 정리 (D+26)

Pytorch Lightning에 대해서 알아보고 실습 해보았다.
27.[부스트캠프 AI Tech] 공부 정리 (D+27)

Transformer 기반 모델들을 써본 사람들이라면 모를 수 없는 Hugging Face에 대한 수업을 들었다. 현재는 Transformer 기반 모델 말고도 다양한 pre-trained model를 확인할 수 있다.
28.[부스트캠프 AI Tech] 공부 정리 (D+28)
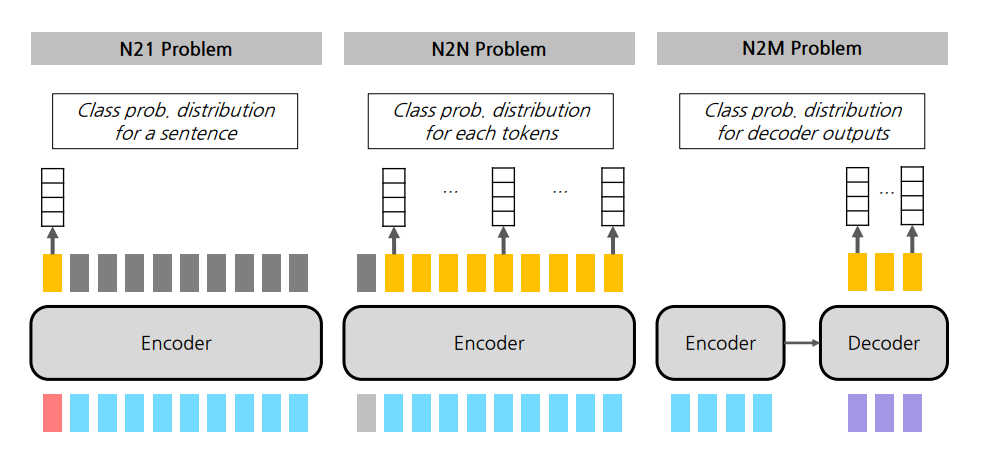
N21 Task에는 일반적으로 Encoder 파트만으로 구현할 수 있다. N21 Task 종류를 알아 보았고, 대표적인 N21 사례인 NMT를 PyTorch Lightning 실습을 통해 해보았다.
29.[부스트캠프 AI Tech] 공부 정리 (D+29)
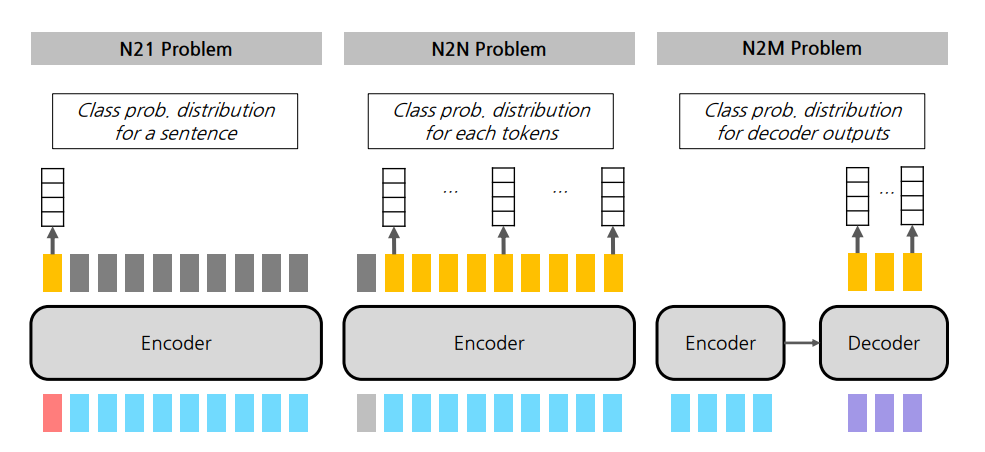
잎서 N21 task에 대해서 알아보았다면 이번에는 N2N의 사례를 알아보았다. 이번에도 똑같이 PyTorch Lightning을 통해 N2N Task를 실습해보았다.
30.[부스트캠프 AI Tech] 공부 정리 (D+30)
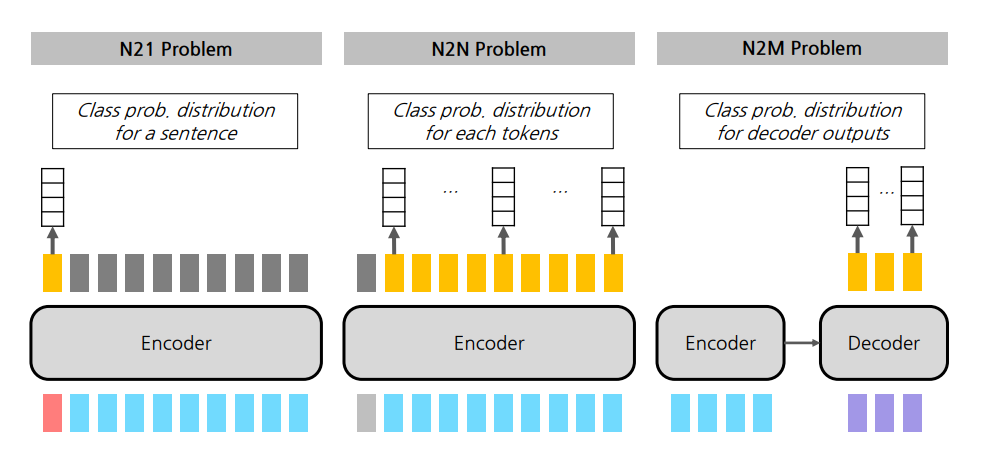
N21, N2N에 이어서 이번엔 N2M task를 알아보았다.
31.[부스트캠프 AI Tech] 공부 정리 (D+31)
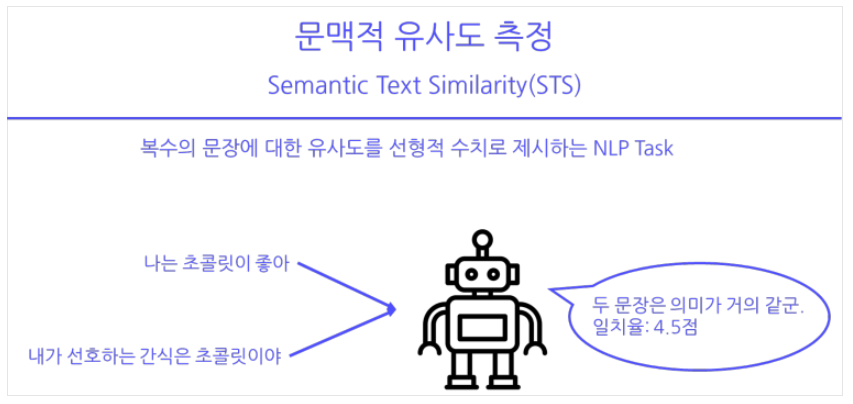
Semantic Text Similarity 프로젝트 (NLP 대회)를 진행하고 있다. 10일 간 진행을 하고 있고 Lv.1 팀원들과 함께하고 있다. 막내로서 모든 일을 하고 있다. 벨로그에 이번 일주일은 STS(Semantic Text Similarity)를 하면서
32.[부스트캠프 AI Tech] 공부 정리 (D+32)

SOTA (State of the Art)라는 표현을 아마 딥러닝 하는 분들은 엄청 많이 들었을거 같다. 특정 task에 대해서 현 시점 가장 좋은 성능을 보이는 모델을 찾으라고 하면 바로 SOTA를 찾으면 된다. Benchmark
33.[부스트캠프 AI Tech] 공부 정리 (D+33)

UNK 토큰...
34.[부스트캠프 AI Tech] 공부 정리 (D+34)
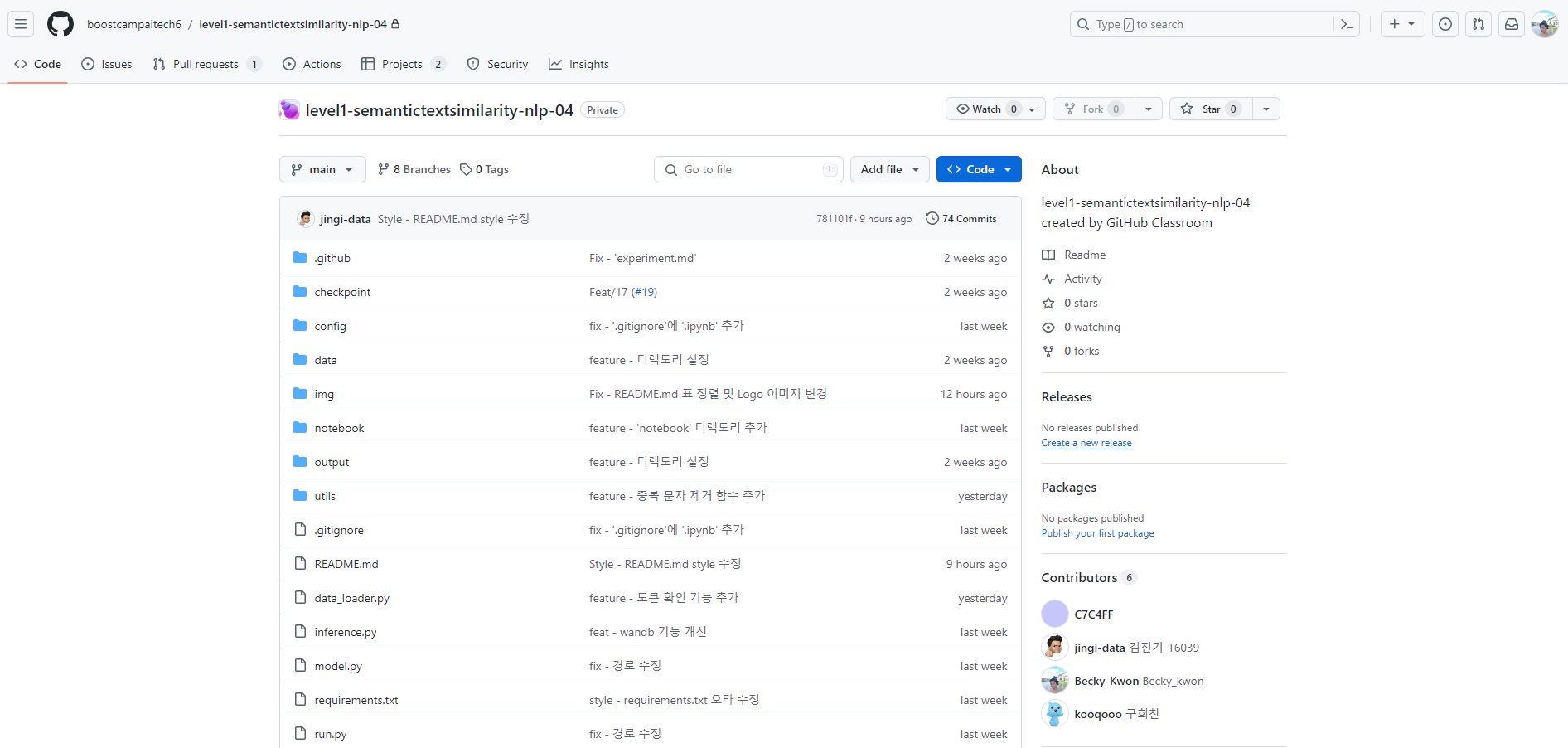
사실상 날밤을 새면서 하고 있다. 실험을 많이 하면서 성능을 체크하고 있다. 해봤던 실험을 몇개 정리해보려고 한다.
35.[부스트캠프 AI Tech] 공부 정리 (D+35)
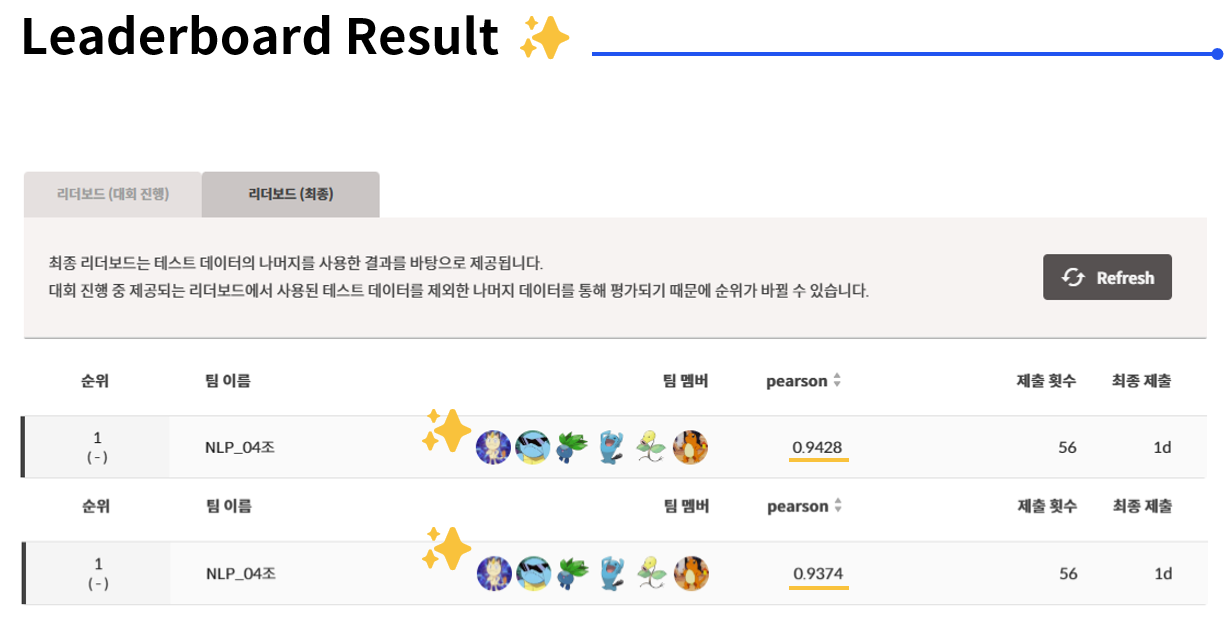
대회 기간 10일 중 4,5일은 거의 날 밤새듯이 모델을 돌렸다. tmux로 밤새 안 꺼지게 돌렸고, 그 결과 마지막에 기가 막히게 1등을 할 수 있었다. 그래서 tmux 사용법 같은 걸 좀 정리하면서 대회 마지막 회고를 해보려고 한다.
36.[부스트캠프 AI Tech] 공부 정리 (D+36, 37)

생각보다 한 해가 너무 일찍 끝나버렸다. 상반기에 몸이 많이 안 좋았고, 이를 회복하고 열심히 하반기에 달렸지만 생각보다 뭔가 많이 이룬게 없다는 생각이 들었다. 인턴도 다녀오고 이거저거 뭘 많이 했다고 생각했는데...크리스마스를 보내고 나니 뭔가 아쉽기도 하고 많은
37.[부스트캠프 AI Tech] 공부 정리 (D+38)
linux와 Docker에 대해서 알아보았다.
38.[부스트캠프 AI Tech] 공부 정리 (D+39)
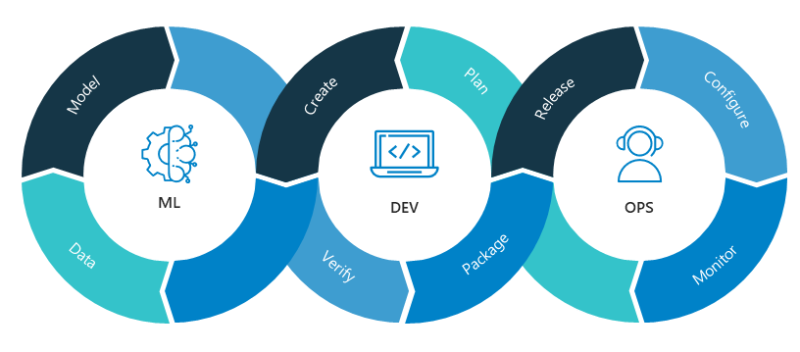
디버깅하는 방법과 그 흐름에 대해서 배울 수 있었다. 또한 항상 지향하고 있는 MLOps에 대해서 강의에서 다루고 있어서 그 내용또한 정리해 보았다.
39.[부스트캠프 AI Tech] 공부 정리 (D+40)

웹 프로그래밍에 대한 지식이 없어도, 웹서비스 형태로 프로토타이핑을 할 수 있는 Streamlit이라는 프레임워크에 대해서 학습해보는 시간을 가졌다. HuggingFce로 구현한 Sentiment Analysis모델을 Streamlit으로 만들어보았고, 이렇게 그 과정
40.[부스트캠프 AI Tech] 공부 정리 (D+41,42,43)
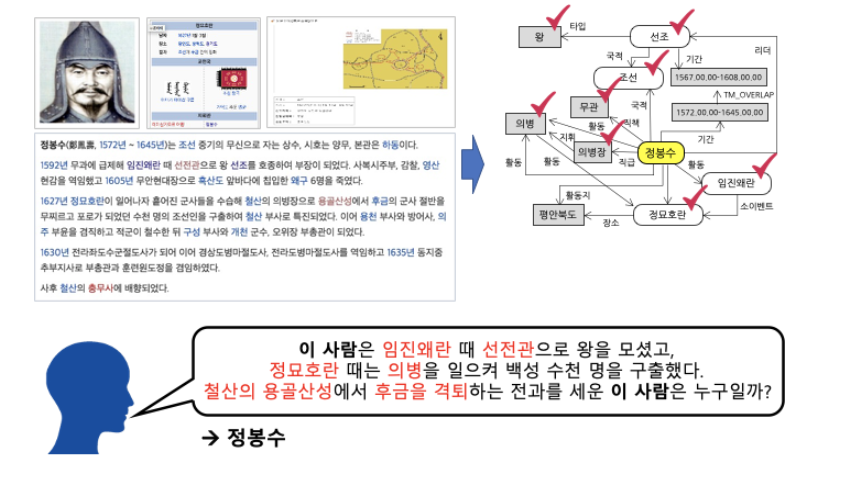
프로젝트로 하고 싶었던, Relation Extraction(RE) task project를 시작하게 되었다. Entity같의 Relation(관계)에 대한 label을 classification 하는 과제를 하게 되었다.
41.[부스트캠프 AI Tech] 공부 정리 (D+44)

인공지능과 자연어처리, 한국어 전처리, 한국어 토크나이징에 대해서 공부해보았습니다. 실제로 우리가 웹이나 메신저를 통해 사용하는 언어는 '정제 되지 않은 언어' 입니다. 해당 데이터가 적용되는 방향에 따라 정제가 필요할 수도, 필요하지 않을 수도 있습니다. 요즘에 많이
42.[부스트캠프 AI Tech] 공부 정리 (D+45)
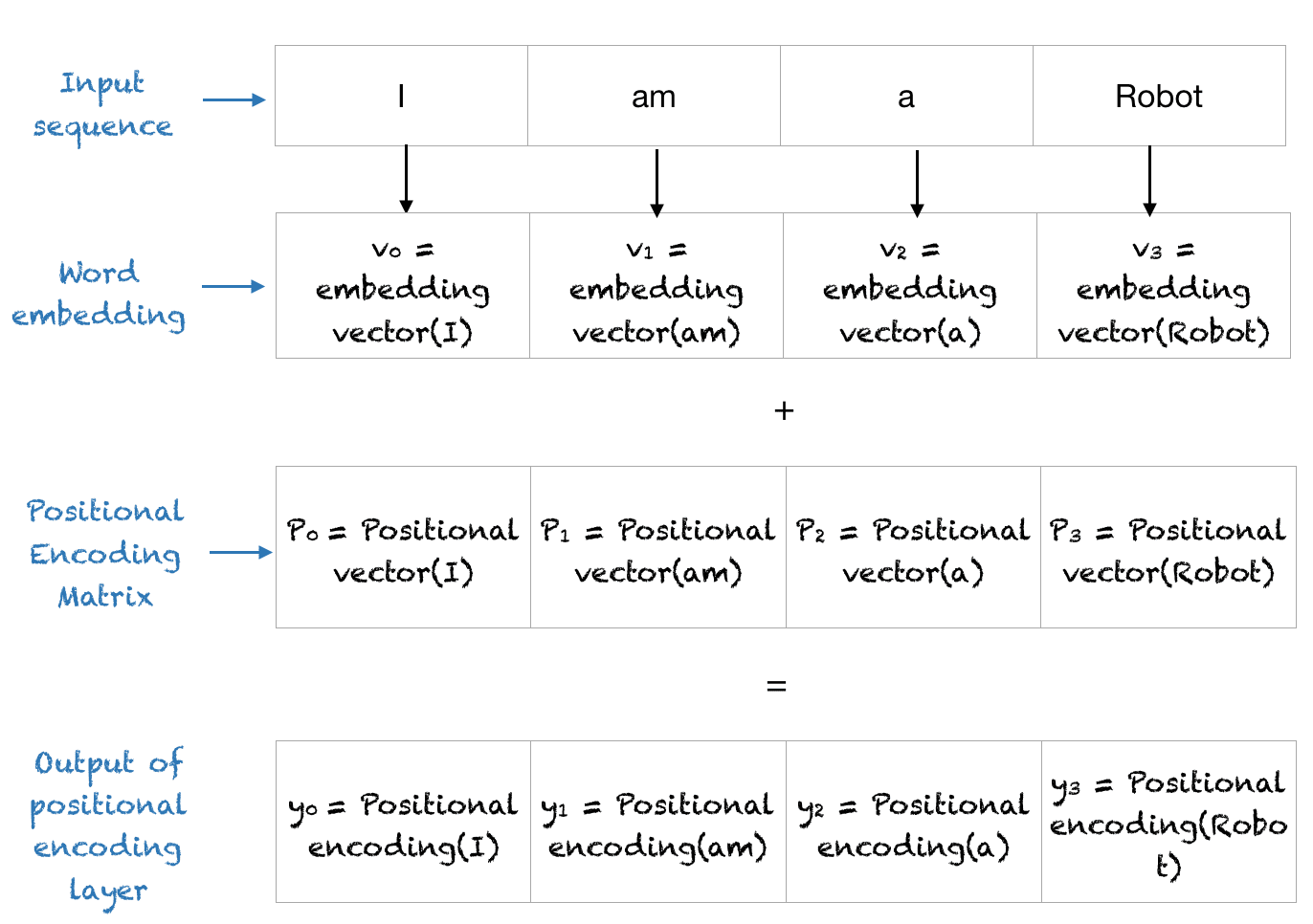
Positional Embedding은 현재 Transformer기반 모델들에서 token의 위치를 알려주는데 있어서 중요한 부분이 되었다고 생각합니다. 오늘은 김성현 마스터의 "LLM과 Position Encoding" 특강을 듣고 그 내용을 한 번 정리해보려고 합니