The post is personal notes I have taken while reading Computer Networking (James F. Kurose, Keith W. Ross) - 5th edition.
1. Introduction & Transport-layer services
Transport layer
- provides for logical commuication b/w application proceses running on different hosts
- Logical communication: communication as if the hosts running the processes were directly connected when the hosts are physically apart, connected via routers and a wide range of link types
- Application processes use logical communication provided by transport layer to send messages to each other
- free from physical constraints
- Transport layer protocols are implemented in the end systems
- not in network routers
- Sending side - transport leyar converts messages it receives from a sending application process into transport-layer packets by breaking the application messages into smaller chunks & adding a transport-layer header to each chunk
- Transport-layer segments: transport-layer packets
- Transport layer passes the segment to the network layer at the sending end system
- Segment is encapsulated w/i a network-layer packet (datagram) & sent to destination
- Receiving side - network layer extracts the transport-layer segment from datagram & passes the segment up to the transport layer
- transport layer processes received segment & makes the data in the segment available to the receiving application
Relationship b/w Transport & Network layers
Transport layer lies just above the network layer.
- Transport layer - provides logical communication b/w processes running on different hosts
- (an) mailing service b/w houses
- live in end systems
- moves messages from application processes to network layer (edge) but no involvement w/ messages moving within network core
- multiple transport protocols can exist in computer network, providing different service models
- constrained by services provided by network layer
- (ex) If network-layer protocol can't provide delay/bandwith guarantees for transport-layer segments b/w hosts, then transport-layer protocol can't provide delay/bandwith guarantees for application messages b/w processes
- exception: some services can be offered by transport protocol when network protocol does not offer corresponding service
- Network layer - provides logical communication b/w hosts
- (an) people who distribute/collect mails at each house
Overview of Transport Layer in the Internet
UDP, User Datagram Protocol - provides unreliable, connectionless service to the invoking application
TCP, Transmission Control Protocol - provides reliable, connection-oriented service to the invoking application
When designing a network application, the application developer must specify one of the two transport protocols.
Internet Protocol (IP) provides logical communication b/w hosts
- Best-effort delivery service:
- IP makes its best effort to deliver segments b/w communicating hosts
- but NO guarantees for:
- segment delivery, orderly delivery of segments, integrity of the data in the segments
- Unreliable service
- every host has at least one network-layer address (IP)
UDP & TCP
- responsibility: to extend IP's delivery service b/w two end systems to a delivery service b/w two processes running on end systems
- Transport-layer Multiplexing/Demultiplexing: extending host-to-host delivery to process-to-process delivery
- provide integrity checking
- error-detection fields in their segments' headers
- UDP - only provides process-to-process data delivery & error checking
- no guarantee for data integrity
- no congestion control
- applications can send at any rate it pleases
- TCP
- reliable data transfer
- flow control, sequence numbers, acknowledgements, timers
- orderly delivery, complete delivery
- converts IP's unreliable service b/w end systems into a reliable data transport service
- Congestion control
- prevents any one TCP connection from swamping links & routers b/w communicating hosts w/ an excessive amount of traffic
- TCP tries to give each connection traversing a congested link an equal share of link bandwith
- regulates the rate at which the sending sides of TCP connections can send traffic into network
- reliable data transfer
2. Multiplexing & Demultiplexing
Multiplexing & Demultiplexing: extending host-to-host delivery service (network layer) to a process-to-process delivery service for applications running on hosts
-
necessary for all computer networks
-
At destination host, transport layer receives segments from the network layer just below
-
Transport layer - delivers data in segmentes to appropriate application process running in host
-
A process can have one or more sockets
- socket: doors through which data passes from the network to the process & through which data passes from the process to network
-
Transport layer in the receiving host delivers data to an intermediary socket
- Since there can be more than one interemediary socket, each socket has a unique identifier
- format of identifier depends on whether socket is a UDP/TCP socket
- Since there can be more than one interemediary socket, each socket has a unique identifier
How receiving host directs an incoming transport-layer segment to the appropriate socket
-
Each transport-layer segment has a set of fields in the segment for this purpose
-
Transport-layer at receiving end examines the fields to identify receiving socket & directs segment to that socket
-
Demultiplexing: deliver data in a transport-layer segment to the correct socket
-
Multiplexing: gather data chunks at the source host from different sockets, encapsulate each data chunk w/ header information to create segments, and pass the segments to the network layer
- requires:
- sockets have unique identifiers
- each segment have special fields that indicate socket to which segment is to be delivered
- requires:
-
Source port number field, Destination port number field
- special fields in each segment that indicate sockets to which segment is to be delivered
- each port number:
- 16-bit number
- ranging from 0 to 65535
- Well-known port numbers: port numbers of 0~1023
- reserved for use by well-known application protocols (ex) HTTP (80), FTP (21)
Connectionless Multiplexing & Demultiplexing
- When a host creates a UDP socket, the transport layer automatically assigns a port number to the socket
DatagramSocket mySocket = new DatagramSocket();orDatagramSocket mySocket = new DatagramSocket(19157);- client - lets transport layer automatically assign the port number
- server - assigns a specific port number
- The transport layer assigns a port number of 1024~65535 (one that is not being used by any other UDP port in the host)
- (ex) Host A w/ UDP port 19157 wants to send a chunk of application data to a process w/ UDP port 46428 in Host B
- Transport layer in Host A creates a transport-layer segment that includes the application data, source port number (19157), destination portnumber (46428), and two other values & passes the resulting segment to network layer
- Network layer encapsulates the segment in an IP datagram & makes a best-effort attempt to deliver the segment to the receiving host
- If segment arrives at receiving Host B, the transport layer at receiving host examines the destination port number in the segment (46428) & delivers segment to its socket identifies by port 46428
- UDP socket is fully identified by a two-tuple: destination IP address & destination port number
- UDP segments w/ different source IP addresses/source port numbers but the same destination IP address & port number are sent to same destination process via same destination socket
- Source port number
- serves as part of return address
- in A-to-B, when B wants to send a segment back to A, the destination port in the B-to-A segment will take from source port value of the A-to-B segment
Connection-oriented Multiplexing & Demultiplexing
TCP socket is identified by a four-tuple: source IP address, source port number, destination IP address, destination port number
- When TCP segment arrives from the network to a host, the host uses all four values to direct (demultiplex) the segment to appropriate socket
- Arriving TCP segments w/ different source IP address/port numbers will be directed to different sockets
- exception: TCP segment carrying the original connection-establishment request
- Arriving TCP segments w/ different source IP address/port numbers will be directed to different sockets
Process
- TCP server application has "welcoming socket" waiting for connection-establishment requests from TCP clients on port 6789
- Connection-establishment request: a TCP segment w/ destination port number 6789 & special connection-establishment bit set in the TCP header
- includes source port number (chosen by client)
- Connection-establishment request: a TCP segment w/ destination port number 6789 & special connection-establishment bit set in the TCP header
- TCP client generates a connection-establishment segment w/:
Socket clientSocket = new Socket("serverHostName", 6789);- creates TCP socket for the client process through which data can enter & leave client process
- When the host operating system of the computer running the server process receives incoming connection-request segment w/ destination port 6789, it locates the server process that is waiting to accept a connection on port number 6789
- the server process then creates a new socket:
Socket connectionSocket = welcomeSocket.accept();
- the server process then creates a new socket:
- Transport layer at the server notes 4 values in the connection-request:
- source port number in the segment
- IP address of the source host
- destination port number in the segment
- server's IP address
- A newly created connection socket is identified by the 4 values
- Arriving segments whose four values match those of socket will be demultiplexed to the socket
Web servers & TCP
- all segments sent to the same server will have the same destination port
- including initial connection-establishment segments & segments carrying HTTP request messages
- server distinguishes segments from different clients by source IP addresses & source port numbers
- high-performing Web servers often use one process & create a new threat w/ a new connection socket for each new client connection
- If client & server use persistent HTTP, throughout the duration of the persistent connection the client & server exchange HTTP messages via same server socket
- If non-persistent HTTP, a new TCP conenction is created & closed for every request/response
- new socket created/closed for every request/response
3. Connectionless Transport: UDP
UDP
- only functions: multiplexing/demultiplexing, light error checking
- w/ UDP, the application is almost directly interacting w/ IP
- connectionliess: no handshaking b/w sending & receiving transport-layer entities before sending a segment
Process
- UDP takes messages from application process, attaches source/destination port number fields for multiplexing/demultiplexing, adds two other small fields, & passes resulting segment to network layer
- Network layer encapsulates transport-layer segment into an IP datagram & makes best-effort attempt to deliver segment to receiving host
- If segment arrives at receiving host, UDP uses destination port number to deliver the segment's data to the correct application process
Example: DNS
- DNS: an application-layer protocol that typically uses UDP
- when DNS application in a host wants to make a query, it constructs a DNS query message & passes the message to UDP
- no handshaking
- The host-side UDP adds header fields to the message & passes the resulting segment to the network layer
- The network layer encapsulates the UDP segment into a datagram & sends the datagram to a name server
- DNS application at querying host waits for a reply to its query
- If it does not receive a reply, it tries sending the query to another name server OR informs the invoking application that it can't get a reply
Strengths of UDP
1. Finer application level control over what data is sent & when
- UDP: As soon as an application process passes data to UDP, UDP will package the data inside a UDP segment & immediately pass the segment to the network layer
- TCP: congestion-control mechanism that throttles the transport-layer TCP sender when one or more links b/w the source & destination hosts become excessively congested
- continues to recsend a segment until the receipt of the segment is acknowledged by the destination, regardless of how long reliable delivery takes
- Real-time applications:
- require a minimum sending rate
- do not want to overlay delay segment transmission
- can tolerate some data loss
- Hence, UDP is more appropriate
- No connection establishment
- TCP: three-way handshake before transferring data
- UDP: no formal preliminaries
- does not introduce any delay to establish a connection
- DNS would be much slower if it ran over TCP
- HTTP uses TCP b/c reliability is critical for Web pages w/ text
- No connection state
- TCP: maintains connection state in end systems
- connection state: receive/send buffers, congestion-control parameters, sequence, acknowledgement number parameters
- these information is necessary to implement TCP's reliable data transfer service & provide congestion control
- connection state: receive/send buffers, congestion-control parameters, sequence, acknowledgement number parameters
- UDP:
- does NOT maintain connection state
- does NOT track any of the parameters
- Server devoted to a particular application can typically support many more active clients when the application runs over UDP rather than TCP
- Small packet header overhead
- TCP: 20 bytes of header overhead in every segment
- UDP: only 8 bytes of overhead
Examples
- TCP: email, remote terminal access, the Web, file transfer
- UDP:
- RIP routing table updates: RIP updates are sent periodically & lost updates will be replaced by more recent updates
- Network management (SNMP): network management applications must run when the network is in a stressed state
- In a stressed state, reliable, congestion-controlled data transfer is difficult to achieve
- DNS
Multimedia applications
- UDP is preferred b/c:
- Multimedia applications can tolerate small amounts of packet loss
- reliable data transfer is not absolutely critical
- real-time applications (Internet phone/video conferencing) react very poorly to TCP's congestion control
- TCP is preferred:
- for streaming media transport
- on-demand & live streaming
- UDP traffic is blocked for security reasons
- TCP's congestion control is necessary
- w/o congestion control > so much packet overflow at routers > very few UDP packets would successfully traverse the source-to-destination path
- high loss rates induced by uncontrolled UDP senders would cause TCP senders to dramatically decrease their rates
- lack of congestion control in UDP > high loss rates b/w UDP sender & receiver & crowding out of TCP sessions
How to make UDP reliable for data transfer
- when reliability is built into the application itself
- (ex) add acknowledgement & retransmission mechanisms
- allows application process to communicate reliably w/o bing subjected to the transmission-rate constraints imposed by TCP's congestion control mechanism
3.1 UDP Segment Structure
The UDP segment structure is defined in RFC 768
- 32 bits in total
- data field: either query or response message
- (ex) data field of streaming audio application: audio samples
- header: four fields, each consisting of 2 bytes
- port number (source & destination): allows destination host to pass application data to the correct process running on the destination end system
- checksum: receiving host uses checksum to check whether errors have been introduced into segment
- length: specifies length of the UDP segment in bytes
- includes header
3.2 UDP Checksum
UDP checksum - error detection
- determine whether bits within UDP segment have been altered as it moved from source to destination
- (ex) by noise in links, while stored in a router, etc.
- UDP at sender side: performs 1s complement of sum of all 16-bit words in the segment
- any overflow during the sum is wrapped around
- result -> checksum field of UDP segment
Why does UDP provide a checksum?
- many link-layer protocols also provide error checking
- BUT no guarantee that all the links b/w source & destination provide error checking & possible that bit errors can be introduced when a segment is stored in a router's memory
- Thus, UDP has to provide error detection at the transport layer on an end-end basis
- End-end basis: if the end-end data transfer service is to provide error detection
- example of End-end principle in system design: application-specific features are kept at communication end points
- End-end basis: if the end-end data transfer service is to provide error detection
UDP provides error checking but does nothing to recover from an error.
- either discard the damaged segment or pass the damaged segment to application w/ warning
4. Principles of Reliable Data Transfer
Implementing reliable data transfer relates to transport, link, and application layer.
Reliable data transfer protocol (rdt)
- responsible for implementing this service abstraction
- difficult b/c the layer below the reliable data transfer protocol may be unreliable
- (ex) TCP: reliable data transfer protocol implemented on top of an unreliable (IP) end-to-end network layer
- (ex) the layer beneath 2 reliably communicating end points might consist of a single physical link (link-level data transfer protocol) or global internetwork (transport-level protocol)
Unidireectional data transfer: Data transfer from the sending to receiving side
- Bidirectional data transfer: full-duplex
4.1 Building a Reliable Data Transfer Protocol
Reliable data transfer over a perfectly reliable channel: rdt 1.0
- Finite state machine (FSM): an abstraction machine that can be in exactly one of a finite number of states at any given time
- Common for both sending & receiving side
- separate FSMs for the sender & receiver
- each have only one state: transitions from the state and back to itself
- sending side: waits for call from above
- event causing transition:
rdt_send(data)- accepts data - actions taken when the event occurs:
packet=make_pkt(data)- creates a packet containing data,udt_send(packet)- sends packet thru unreliable data transfer
- event causing transition:
- receiving side: waits for call from below
- event causing transition:
rdt_rcv(packet)- receivs a packet - actions taken when the event occurs:
extract(packet, data)- removes data from packet,deliver_data(data)- passes data up to upper layer
- event causing transition:
RDT over a channel w/ bit errors: rdt 2.0 & 2.1
Bits in a packet may be corrupted typically in the physical components of a network as a packet is transmitted, propagates, or is buffered.
- Assume the packets arrive in order despite the errors
- Positive acknowledgement: "ok" every time message taker understands message
- Negative acknowledgement: "Please repeat that" every time message taker could not comprehend message
Automatic Repeat reQuest protocol (ARQ): reliable data transfer protocols based on retransmission (positive/negative acknowledgements)
- Error detection:
- allows receiver to detect/possibly correct packet bit errors
- requires that exttra bits be sent from the sender to receiver
- these bits will be gathered into the packet checksum field of the data packet
- Receiver feedback:
- since sender & receiver typically run on different end systems, the receiver has to provide explicit feedback to sender
- (ex) Positive (ACK) & negative (NAK) acknowledgement replies
- in principle, these packets need only be a one bit long
- since sender & receiver typically run on different end systems, the receiver has to provide explicit feedback to sender
- Retransmission:
- A packet that is received in error at the receiver will be retransmitted by the sender
Process
- sending side: 2 states
- waiting for data to be passed down from upper layer
- when the event
rdt_send(data)occurs, the sender creates a packetsndpktcontaining the data to be sent & a packet checksum and sends the packet viaudt_send(sndpkt)
- when the event
- waiting for an ACK/NAK packet from the receiver
- If ACK packet (
rdt_rcv(rcvpkt) && isACK(rcvpkt)), the sender knows that the most recently transmitted packet has been received correctly- protocol returns to state of waiting for data from upper layer
- If NAK, protocol retransmits the last packet & waits for an ACK/NAK to be returned by receiver
- When sender is waiting for ACK/NAK, it cannot get more data from upper layer
- sender does not send more data until it receives an ACK
- known as stop-and-wait protocols
- If ACK packet (
- waiting for data to be passed down from upper layer
- receiving side: 1 state
- on packet arrival, receiver replies w/ ACK/NAK depending on whether the received packet is corrupted
Problem
- the case of ACK/NAK packet being corrupted
- Thus, how would the sender know whether the receiver has correctly received the last piece of transmitted data?
Solution
- Add checksum bits to ACK/NAK packets
- How protocol should recover from errors in ACK/NAK packets
- Introduce a new type of sender-to-receiver packet to request for ACK/NAK packet again
- What if this new packet from sender is corrupted?
- Then would the receiver ask?
- Add enough checksum bits to allow sender to detect & recover from bit errors
- solves immediate problem for a channel that can corrupt packets but not lose them
- Sender resends current data packet when it receives a garbled ACK/NAK packet
- Introduces Duplicate pakcets into sender-to-receiver channel
- difficulty: receiver doesn't know whether ACK/NAK it last sent was received correctly at the sender
- receiver can't know whether an arriving packet contains new data or is a retransmission
- solution: add a new field to data packet for sequence number
- sender numbers its data packets w/ sequence numbers
- difficulty: receiver doesn't know whether ACK/NAK it last sent was received correctly at the sender
RDT 2.1
- sender & receiver have twice more states: protocol state must reflect whether packet currently being sent/expected should have a sequence number of 0 or 1
- out-of-order packet is received > receiver sends ACK
- corrupted packet is received > receiver sends NAK
- sender that receives two ACKS for the same packet (duplicate ACKs) knows that receiver did not correctly receive the packet
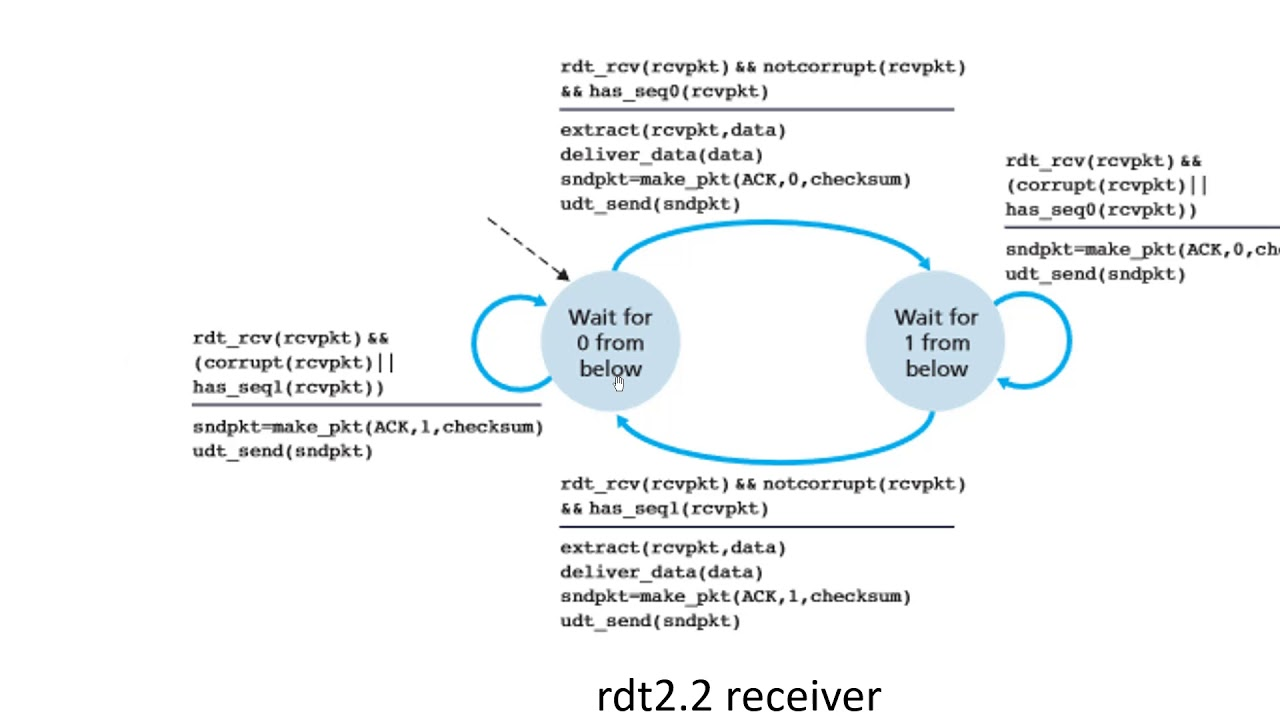
rdt 2.1 vs. rdt 2.2
- rdt2.2:
- receiver must include sequence number of packet being acknolwedged by an ACK message
- sender must check sequence number of packet being acknowledged by a received ACK message
RDT over a Lossy Channel w/ Bit errors: rdt3.0
The underlying channel can lose packets
- how to detect packet loss
- what to do when packet loss occurs
Solution 1: sender is responsible for detecting/receovering from lost packets on the sender
- situation: sender transmits a data packet. either sent data packet or receiver's ACK of that packet gets lost
- no reply at sender from receiver
- sender waits long enough and retransmit data packet
- How long must the sender wait to be certain that something has been lost?
- at least a round-trip delay b/w sender & receiver (may include buffering at intermediate routers) + time need to process packet ar receiver
- difficulty
- worst-case max delay is difficult to estimate
- protocol should ideally recover from packet loss ASAP
- solution: sender judiciously choose a time value such that packet loss is likely to have happened
- possibly introduces duplicate packets in sender-to-receiver channel
- requires a countdown timer that can interrupt sender after set time expired
- sender has to start timer each time a packet is sent, respond to a timer interrupt, and stop the timer
rdt3.0
- aka alternating-bit protocol
- packet sequence numbers alternate b/w 0 and 1
4.2 Pipelined Reliable Data Transfer Protocols
rdt3.0's performance is inappropriate for today's high-speed networks
Utilization: percentage of a network's bandwith that is currently being consumed by network traffic
- Under stop-and-wait protocol, the utilization of the sender channel is significantly low > inefficient use of resources
- lower-layer protocol-processing times at sender/receiver + processing/queuing delays at intermediate routers + etc. will delay the process even more
Solution: sender is allowed to send multiple packets w/o waiting for acknowledgements > Pipelining
- no stop-and-wait
Consequences of Pipelining
- range of sequence numbers increase
- each in-transit packet needs a unique sequence number
- there may be multiple, in-transit, unacknowledged packets
- sender & receiver sides of protocols may have to buffer more than one packet
- Buffer: region of memory used to temporarily hold data while being moved from one place to another
- used when moving data b/w processes
- minimally, sender will have to buffer packets that have been transmitted but not yet acknowledged
- buffering of correctly received packets may be needed at receiver
- Buffer: region of memory used to temporarily hold data while being moved from one place to another
- range of sequence numbers needed & buffering requirements will depend on the manner in which a data transfer protocol responds to lost, corrupted, overly delayed packets
- two basic approaches toward pipelined error recovery: Go-Back-N & selective repeat
4.3 Go-Back-N (GBN)
Go-Back-N (GBN) protocol:
- sender can transmit multiple pakcetes w/o waiting for acknowledgement
- w/ constraint on maximum allowable number (N) of acknowledged packets in the pipeline
Process
-
Base: sequence number of the oldest unacknwoledged packet
-
Next sequence number (
nextseqnum): smallest unused sequence number -
N: window size
- necessary for flow control
-
GBN protocol - sliding-window protocol
-
sequence numbers in interval [0, base-1] are packets that are already transmitted & acknowledged
-
sequence numbers in interval [base, nextseqnum - 1] are packets that are sent but not yet acknowledged
-
sequence numbers in interval [nextseqnum, base+N-1] can be used for packets that can be sent immediately when data arrive from upper layer
-
sequence numbers >= base + N: cannot be used until an unacknowledged packet in the pipeline w/ sequence number base has been acknowledged
-
the range of permissible sequence numbers for transmitted but not yet acknowledged packets is a window of size N over the range of sequence numbers
Process
- A packet's sequence number is carried in a fixed-length field
- k: the number of bits in the packet sequence number field
- the range of sequence numbers: [0, 2^k -1]
ACK-based, NAK-free, GBN protocol
sender:
receiver:
- extended FSM: added variables for base & nextseqnum, added operations/conditional actions
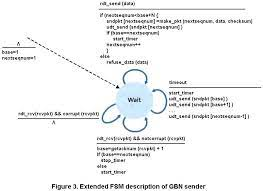
GBN sender must respond to 3 types of events:
- Invocation from above:
- When
rdt_send()is called from above, the sender first checks to see if the window is full- whether the window is full: whether there are N outstanding, unacknowledged packets
- If window is not full, a packet is created and sent & variables are appropriately updated
- If the window is full, the sender returns the data back to the upper layer
- this is an implicit indication that the window is full
- the upper layer presumably have to try again later
- (real implementation) Sender is likely to have either buffered this data or have synchronization mechanism that allow the upper layer to call
rdt_send()only when the window is not full
- When
- Receipt of an ACK
- In GBN protocol, acknowledgement for packet w/ sequence number n will be taken to be a cumulative acknowledgement
- Cumulative acknowledgement: all packets w/ a sequence number up to & including n have been correctly received at the receiver
- In GBN protocol, acknowledgement for packet w/ sequence number n will be taken to be a cumulative acknowledgement
- Timeout event
- "Go-Back-N" is derived from the sender's behavior in the presence of lost/overly delayed packets
- timer will again be used to recover from lost data or acknowledgement packets
- If timeout occurs, the sender resends all packets that have been previously sent but that have not yet been acknowledged
- If an ACK is received but there are still additional transmitted-but-yet-to-be-acknowledged packets, the timer is restarted
- If there are no outstanding unacknowledged packets, the timer is stopped.
- "Go-Back-N" is derived from the sender's behavior in the presence of lost/overly delayed packets
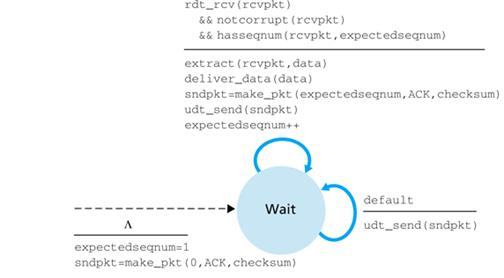
Receiver's actions:
- If a packet w/ sequence number n is received correctly & in-order, the receiver sends an ACK for packet n & delivers the data portion of the packet to the upper layer
- in-order: the data last delivered to the upper layer came from a packet w/ sequence number n-1
- All other cases: receiver discards packet & resends ACK for most recently received in-order packet
- Discards out-of-order packets
- If receiver saves (buffers) packet n+1 to send it after it receives packet n, according to GBN retransmission rule, packet n+1 will be eventually be retransmitted if packet n is lost
- advantage: simplicity of receiver buffering (does NOT need to buffer anything)
GBN protocol:
- use of sequence numbers
- cumulative acknowledgements
- checksums
- time-out/retransmit operation
TCP vs. GBN protocol
- TCP:
- buffers correctly-received but out-of-order segments
- selective acknowledgement: TCP receiver can selectively acknowledge a single out-of-order packet rather than cumulatively acknowledge the last correctly received packet
4.4 Selective Repeat (SR)
GBN protocol allows the sender to potentially fill the pipeline w/ packets
- thus avoids channel utilization problems that occur in stop-and-wait protocols
- Performance problems:
- when window size & bandwith-delay product are large: many packets can be in the pipeline
- a single packet error can cause GBN to unnecessarily retransmit a large # of packets
- as probability of channel errors increases, pipeline can become filled w/ these unnecessary retransmissions
- when window size & bandwith-delay product are large: many packets can be in the pipeline
Selective Repeat(SR) Protocols
SR avoids unnecessary retransmissions by having the sender retransmit only packets that it suspects were received in error(lost/corrupted) at the receiver
- This necessary retransmission will require that the receiver individually acknowledge correctly-received packets
- Window size of N will be used to limit the # of outsatnding & unacknowledged packets in the pipeline
- Unlike GBN, sender will have already received ACKs for some packets in the window
SR receiver acknowledges a correctly received packet regardless of order
- Out-of-order packets are buffered until any missing packets are received
- When packets up to sequence number of n are received, a batch of packets can be delivered in order to the upper layer
Selective Repeat sender actions
- Data is received from above
- When data is received, SR sender checks the next available sequence number for the packet
- If sequence number is within the sender's window, datais packetized & set
- Otherwise, it is buffered or returned to upper layer for later transmission
- Timeout
- Timers are used to protect against lost packets
- Each packet must have its own logical timer since only a single packet will be transmitted on timeout
- ACK received
- If an ACK is received, the SR sender marks the packet as having been received (if it's in the window)
- If packet's sequence number is equal to
sendbase, the window base is moved forward to the unacknowledged packet w/ the smallest sequence number - If the window moves & there are untransmitted packets w/ sequence numbers that now fall within the window, these packets are transmitted
Selective Repeat receiver actions
- Packet w/ sequence number in [rcvbase, rcvbase + N -1] is correctly received
- Received packet falls within the receiver's window
- A selective ACK packet is returned to the sender
- If the packet was not previously received, it is buffered
- If packet has a sequence number equal to the base of the receive window (rcvbase), then this packet & any previously buffered/consecutively numbered packets are delivered to upper layer
- Then, receive window is moved forward by the # of packets delivered to upper layer
- Received packet falls within the receiver's window
- Packet w/ sequence number in [rcvbase - N, rcvbase - 1] is received
- ACK must be genereated even tho this is a packet that receiver previously acknowledged
- If there is no ACK for packet sendbase propagating from receiver to sender, the sender will retransmit packet sendbase
- If the receiver were not to ACK this packet, the sender's window will never move forward
- Otherwise, ignore the packet
Lack of synchronization b/w sender & receiver windows
Ex 1) ACKs for the first three packets are lost & sender retransmits these packets
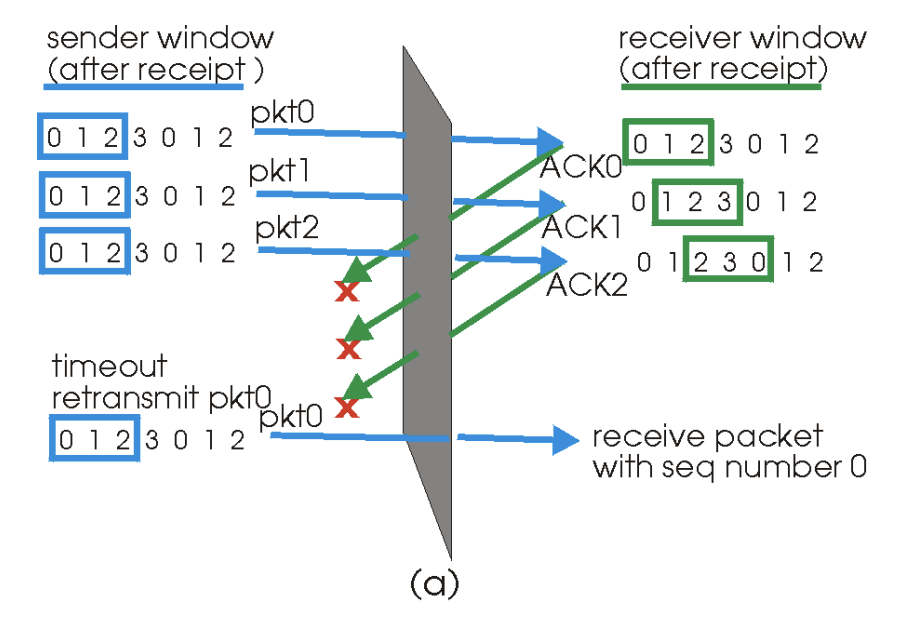
- Receiver thus next receives a packet w/ sequence number 0 (copy of first packet)
Ex 2) ACKs for the first three packets are delivered correctly
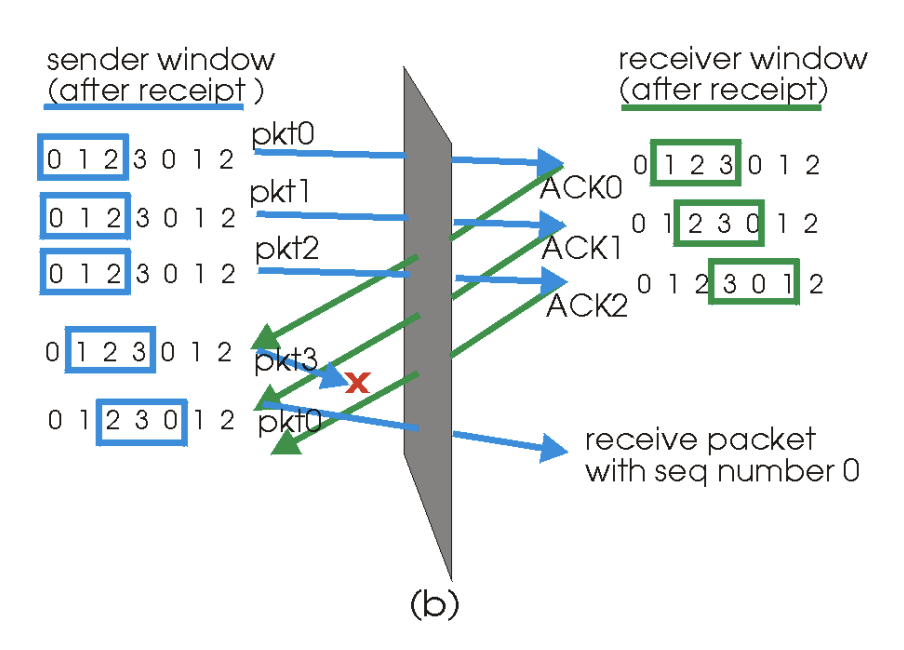
- Sender moves its window forward & sends the 4th, 5th, 6th packets w/ sequence numbers 3, 0, 1, respectively
- Packet w/ sequence number 3 (4th) is lost, but the packet w/ sequence number 0 arrives (a packet containing new data)
Conclusion: Receiver cannot see the actions taken by the sender
- Receiver can only see the sequence of messages it receives from the channel & sends into the channel
- To the receiver, (ex1) & (ex2) are identical scenarios
5. Connection-Oriented Transport: TCP
5.1. TCP Connection
TCP provides multiplexing, demultiplexing, and error detection (but not recovery) in exactly same manner as UDP.
TCP vs. UDP
Connection
- UDP: connectionless
- sends data w/o ever establishing a connection
- TCP: connection-oriented
- before one application process can begin to send data to another, two processes must first "handshake" with each other
- must send some preliminary segments to each other to establish the parameters of the ensuing data transfer
- As part of the TCP connection establishment, both sides of the connection will initialize many TCP state variables associated w/ the TCP connection
TCP Connection
- TCP connection provides for full duplex data transfer
- Application-level data can be transferred in both directions b/w two hosts
- If there is a TCP connection b/w process A on one host & process B on another host, then application-level data can flow from A to B at the same time as application-level data flows from B to A
- Application-level data can be transferred in both directions b/w two hosts
- TCP connection is always point-to-point
- point-to-point: b/w a single sender & single receiver
- multicasting is NOT possible
- multicasting: transfer of data from one sender to many receivers in a single send operation
Establishing a TCP connection
Client host initiates connection; Server host is the other host
- Client process informs client TCP that it wants to establish a connection to a process in the server
- TCP in the client proceeds to establish a TCP connection w/ the TCP in the server by sending a special TCP segment
- Server responds w/ a second special TCP segment
- Client responds again w/ a third special segment
- First two segments contain no "payload"
- payload: application-layer data
- Third segment may carry a payload
Since three segments are sent b/w two hosts, this connection establishment is referred to as three-way handshake
Process
After establishment of TCP connection, the application processes can send data to each other
- TCP is full-duplex: application processes can send data at the same time
- Client passes a stream of data through the socket (door of the process)
- Once data passes through the door, the data is now in the hands of TCP running in the client
- TCP directs this data to the connection's send buffer
- Send buffer: one of the buffers that is set aside during the initial three-way handshake
- From time to time, TCP grab chunks of data from the send buffer
- Maximum amount of data that can be grabbed & placed in a segment is limited by Maximum Segment Size (MSS)
- MSS depends on TCP implementation & can be configured
- common values: 1500 bytes, 536 bytes, 512 bytes
- only regards application-level data in the segment (not including headers)
- Maximum amount of data that can be grabbed & placed in a segment is limited by Maximum Segment Size (MSS)
- TCP encapsulates each chunk of client data w/ TCP header & forms TCP segments
- Segments are passed down to the network layer where they are separately encapsulated within network-layer IP datagrams
- IP datagrams are sent into the ntework
- When TCP receives a segment at the other end, the segment's data is placed in the TCP connection's receiver buffer
- Application reads the stream of data from this buffer
Each side of the connection has its own send & receiver buffer
5.2. TCP Segment Structure

TCP segment consists of header fields and a data field
- Data field: contains a chunk of application data
- maximum size limited by MSS
- If TCP sends a large file (i.e., image), it breaks the file into chunks of size MSS
- last chunk is most likely smaller than MSS
- Header fields: source & destination port numbers, checksum field, and ...
- 32-bit sequence number field & 32-bit acknowledgement number field: for TCP sender & receiver to implement a reliable data transfer service
- 16-bit window size: for flow control
- 4-bit length field: specifies length of TCP header in 32-bit words
- TCP header can have variable length due to TCP options field
- TCP options field is typically empty
- length of typical TCP header = 20 bytes
- TCP header can have variable length due to TCP options field
- optional & variable length options field:
- when a sender & receiver negotiate MSS
- as a window scaling factor for use in high-speed networks
- timestamping option exists
- 6-bit flag field
- ACK bit: indicates that the value carried in acknowledgement field is valid
- values: RST, SYN, FIN, PSH, URG
- RST, SYN, FIN: connection setup/teardown
- PSH: indicates that receiver should pass data to the upper layer immediately
- URG: indciates there is a data in this segment that the sending-side upper layer entity has marked as urgent
- location of last byte of urgent data is indicated by the 16-bit urgent data pointer
- TCP must inform receiving-side upper layer entity when urgent data exists & pass it a pointer to the end of the urgent data
5.3. Sequence numbers & Acknowledgement numbers
TCP views data as unstructured but ordered stream of bytes
- Hence, sequence numbers are over the stream of transmitted bytes (not segments)
Sequence number for a segment: byte-stream number of the first byte in the segment
- When host A wants to send data stream consisting of a file consisting of 500,000 bytes to host B, TCP in host A will implicity number each byte in the data stream
- TCP constructs 500 segments out of the data stream
- first segments is assigned sequence number 0
- second segment is assigned sequence number 1000
- Each sequence number is inserted in sequence number field in the header of appropriate TCP segment
- TCP constructs 500 segments out of the data stream
Acknowledgement number
- Each of the segments that arrive from host B have a sequence number for the data flowing from B to A
- The acknowledgement number that host A puts in its segment is sequence number of the next byte host A is expecting from host B
Cumulative acknowledgements
- If host A receives one segment containing bytes 0~535 and another segment containing bytes 900~1000
- Host A still waits for byte 536~899 in order to recreate B's data stream
- A's next segment to B will contain 536 in acknowledgement number field
Programmer decides what to do with the segments that arrived out of order
- Reciever immediately discards out-of-order bytes
- simplifies TCP code
- OR receiver keeps the out-of-order bytes & waits for the mssing bytes to fill in the gaps
- more efficient choice in terms of network bandwith
Both sides of TCP connection randomly choose an initial sequence number to minimize possibility a segment that is still present in the network from an earlier, already-terminated connection b/w two hosts is mistaken for a valid segment in later connection b/w same hosts
5.4. Telnet
Telnet: a popular application-layer protocol used for remote login
- runs over TCP
- designed to work b/w any pair of hosts
- interactive application: non-bulk-data transfer
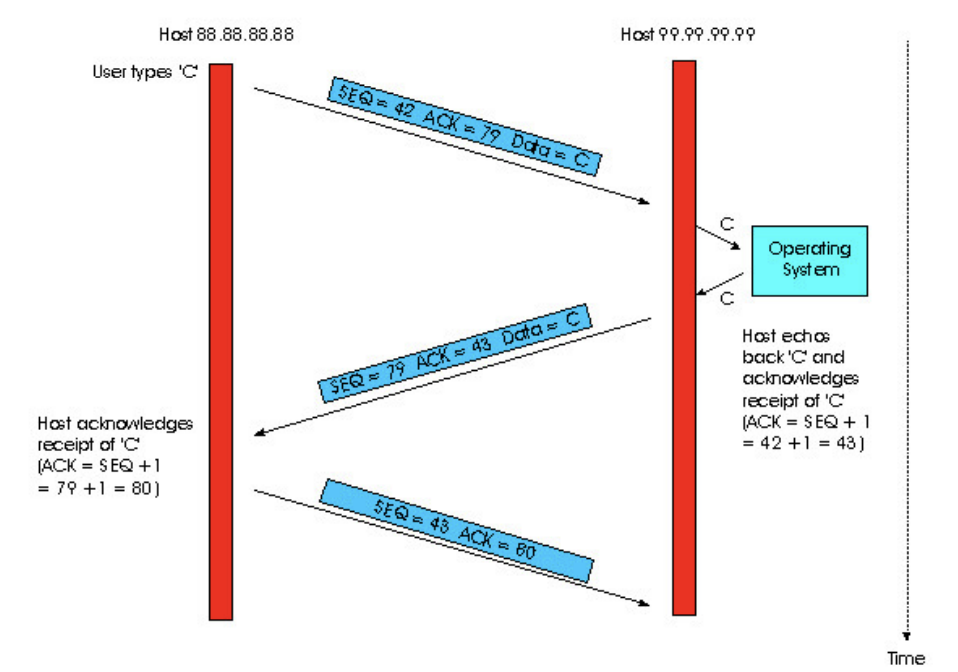
3 segments are sent
1. First segment is sent from client to server, containing one-byte ASCII representation of letter 'C' in data field
- has 42 in its sequence number field
- since client did not receive any data from server, acknowledgement number field is 79
2. Second segment is sent form server to client
- dual purpose:
- (1) provides acknowledgement for data the client has received
- 43 in acknowledgement field: server tells client that it successfully received everything up through 42 & waiting for bytes 43~
- (2) echoes back the letter 'C'
- sequence number 79 (initial sequence # of server-to-client data flow)
- Piggyback: acknowledgement for client-to-server data is carried in a segment carrying server-to-client data
3. Third segment is sent from client to server
- purpose: acknowledge the data it has received from server
- has empty data field: acknowledgement is not being piggybacked
- 80 in acknowledgement number field:
- client has received stream of bytes up through byte sequence # 79 & waiting for bytes 80~
- b/c TCP has a sequence number field, the segment needs to have some sequence number
5.5 Reliable Data Transfer
TCP creates reliable data transfer
- FTP, SMTP, NNTP, HTTP, Telnet uses TCP for this reason
- ensures that data stream that a process reads out of its TCP receive buffer is uncorrupted, w/o gaps, w/o duplication, and in sequence
- = byte stream is exactly the same byte stream that was sent by the end system on the other side
Retransmissions
Retransmission of lost & corrupted data: crucial for providing RDT
TCP provides RDT through positive acknowledgements & timers
- TCP acknowledges data that has been received correctly & retransmits segments when segments/corresponding acknowledgements are thought to be lost/corrupted
- TCP can't tell for certain if a segment/ACK is lsot/corrupted/overly delayed
- In all cases, TCP retransmits segment
- Pipelining: allows sender to have multiple transmitted but yet-to-be-acknowledged segments outstanding at any given time
- pipelining can improve throughput of TCP connection when ratio of segment size to round trip delay is small
- specific # of outstanding unacknowledged segments that a sender can have is determined by TCP's flow control & congestion control mechanisms
When host A sends data stream to host B:
1. At sending host, TCP is passed application-layer data, which it frames into segments & passes on to IP
2. Each time TCP releases a segment to IP, it starts a timer for that segment
- If this timer expires, an interrupt event is generated at host A
- TCP responds to the timeout event by retransmitting the segment that caused the timeout
5. When sender receives acknowledgement segment (ACK) from receiver, the sender's TCP must determine whether ACK is a first-time ACK for a segment
- first-time ACK: sender has yet to receive an acknowledgement for this segment
- duplicate ACK: reacknowledges a segment for which the sender has already received an earlier acknowledgement
6. In the case of first-time ACK, sender now knows that all data up to the byte being acknowledged has been received correctly at receiver.
- Sender thus updates its TCP state variable that tracks the sequence number of the last byte that is known to have been received correctly & in-order at receiver
TCP receiver's ACK generation policy
- Process 1
- Event:
- Arrival of in-order segment w/ expected sequence number
- all data up to expected sequence number already acknowledged
- no gaps in received data
- TCP receiver action: Delayed ACK
- wait up to 500 s for arrival of another in-order segment
- If next in-order segment does not arrive in this interval, send an ACK
- Event:
- Process 2
- Event:
- Arrival of in-order segment w/ expected sequence number
- One other in-order segment waiting for ACK transmission
- no gaps in received data
- TCP receiver action
- immediately send single cumulative ACK
- ACKing both in-order segments
- Event:
- Process 3
- Event:
- Arrival of out-of-order segment w/ sequence number higher than expected
- gap detected
- TCP receiver action
- immediately send duplicate ACK, indicating sequence number of next expected byte
- Event:
- Process 4
- Event:
- Arrival of segment that partially/completely fills in gap in received data
- TCP receiver action
- immediately send ACK, provided that segment starts at the lower end of gap
- Event:
Duplicate ACK
- When a TCP receiver receives a segment w/ sequence # larger than the next expected in-order sequence number, it detects a gap in the data stream (= missing segment)
- Since TCP does not use negative acknowledgements, the receiver cannot send an explicit negative acknowledgement back to sender
Instead, it reacknowledges the last in-order byte of data it received- reacknowledge: generates a duplicate ACK for the data
- If TCP sender receives 3 duplicate ACKs for same data, it takes this as an indication that the segment following the segment that has been ACKed three times has been lost
- Thus, TCP performs a fast retransmit: retransmitting the missing segment before the segment's timer expires
TCP vs. Go-Back-N protocol
TCP retransmits at most one segment, namely segment n, but if acknowledgement for segment n+1 arrives before timeout for segment n, then TCP won't even retransmit segment n
5.6 Flow Control
- When TCP connection receives bytes that are correct & in sequence, it places the data in the receive buffer
- Associated application process will read data from this buffer but not necessarily at the instant the data arrives
- If application is relatively slow at reading data, sender can easily overflow the connection's receive buffer
- Thus, TCP provides flow control service
- TCP elimiates the possibility of sender overflowing the receiver's buffer
- matches the rate at which sender is sending to the rate at which receiving application is reading
- If TCP sender is throttled due to congesting within the IP network: requires Congestion control
Receive window: gives sender an idea about how much free buffer space is available at receiver
- in full-duplex connection, sneder at each side of the connection maintains a distinct receive window
- receive window is dynamic: changes throughout connection's lifetime
- Implementation
LastByteRead: number of last byte in the data stream read from buffer by application process in BLastByteRcvd: number of last byte in the data stream that arrived from network & placed in receive buffer at B- TCP is not permitted to overflow allocated buffer:
LastByteRcvd - LastByteREad <= RcvBuffer
- Receive window is set to amount of spare room in the buffer:
RcvWindow = RcvBuffer - [LastByteRcvd - LastByteRead]- b/c spare room changes,
RcvWindowis dynamic
- Host B informs host A of how much spare room it has by placing current value of
RcvWindowin the window field of every segment it sends to A - Host A keeps track of
LastByteSent&LastByteAcked- ensures that
LastByteSent - LastByteAcked <= RcvWindow
- ensures that
- Problem:
- When host B's receive buffer is full &
RcvWindow = 0, and host B has nothing more to send to host A - As application process at B empties the buffer, TCP does not send new segments w/ new
RcvWindows to host A - Therefore, host A is never informed that some space opened in host B's receive buffer
- Host A is blocked & can't send any more data
- When host B's receive buffer is full &
- Solution
- TCP specification requires host A to continue to send segments w/ one data byte when B's receive window is 0
- these segments will be acknowledged by receiver
- Eventually buffer will begin to empty & acknowledgements will contain non-zero
RcvWindow
- TCP specification requires host A to continue to send segments w/ one data byte when B's receive window is 0
5.7. Round Trip Time and Timeout
When a host sends a segment into a TCP connection, it starts a timer.
- If timer expires before the host receives an acknowledgement for the data in the segment, the host retransmits the segment
- Timeout: time from when the timer is started until when it is expired
- should be larger than the connection's round-trip time
- round-trip time: time from when a segment is sent until it is acknowledged
- otherwise, unnecessary retransmissions occur
- should not be too larger than round-trip time
- TCP will not quickly respond when segment is lost > significant data transfer delays
- should be larger than the connection's round-trip time
Estimating average round-trip time
SampleRTT
- for a segment: the time from when the segment is sent until an acknowledgement for the segment is received
- each segment has its own
SampleRTT - fluctuates from segment to segment due to congestion in routers & varying load on end systems
TCP maintains an average of SampleRTT values: EstimatedRTT
- Upon receiving acknowledgement & obtaining new
SampleRTT, TCP updatesEstimatedRTTaccording to following formula
EstimatedRTT = (1-x) EstimatedRTT + x * SampleRTT
- new value of
EstimatedRTT: a weighted combination of previous value ofEstimatedRTT& new value forSampleRTT - typical value of
x= 0.1
Exponential weighted moving average (EWMA): an average in which more recent samples better reflect the current congestion in the network
- exponential: weight of given SampleRTT decays exponentially fast as updates proceed
Setting timeout
A timer should expire early only on rare occasions
- early: before delayed arrival of a segment's ACK
Set the timeout equal to (EstimatedRTT + margin)
- margin:
- should be large when there's a lot of fluctuation in
SampleRTTvalues - should be small when there is little fluctuation
- should be large when there's a lot of fluctuation in
Timeout = EstimatedRTT + 4 * Deviation
Deviation: estimate of how muchSampleRTTtypically deviates fromEstimatedRTTDeviation = (1-x) * Deviation + x * |SampleRTT - EstimatedRTT|- If
SampleRTTvalues have little fluctuation >Deviationis small >Timeoutis hardly more thanEstimatedRTT
5.8 TCP Connection Management
Client host: host that initiates connection
Server host: the other host
Establishment Process: Three-way handshake
- Client application process informs client TCP that it wants to establish connection to a process in the server
Socket clientSocket = new Socket("hostname", "port number"); - TCP in client proceeds to establish a TCP connection w/ TCP in server:
(1) Client-side TCP first sends a special TCP segment to the server-side TCP- This special segment:
- does not contain application-layer data
- contains SYN(one of the flag bits) set to 1
- thus called a SYN segment
- Client chooses an initial sequence number & places it in sequence number field of initial TCP SYN segment
- encapsulated within an IP datagram & sent to Internet
- This connection-granted segment:
- does not contain application-layer data
- contains 3 info in segment header
- SYN bit set to 1
- acknowledgement field of TCP segment header set to isn+1
- initial sequence number chosen by server in sequence number field
- sometimes referred to as SYNACK segment
- acknowledges the server's connection-granted segment
- SYN bit = 0 since conneciton is established
- This special segment:
Moving forward, client/server hosts can send segments containing data to each other (all of whose SYN bits = 0)
Ending the connection
Either participating process can end the connection
When a connection ends: resources (buffers/variables) in hosts are de-allocated
Ending process: if client decides to close connection
- Client process issues a close command
- Client TCP thus sends a special TCP segment(contains FIN bit=1) to server process
- When server receives this segment, it sends the client an acknowledgement segment in return
- The server then sends its own shut-down segment (FIN bit = 1)
- Client acknowledges the server's shut-down segment
TCP states
- Closed state: initial state
- SYN_SENT state: after initiating new TCP connection, client TCP waits for a segment from server TCP that includes an acknowledgement for client's previous segment & SYN bit = 1
- ESTABLISHED state
- after client received segment from server that includes acknowledgement for client's previous segment & SYN bit = 1
- during this state, TCP client can send/receive TCP segments
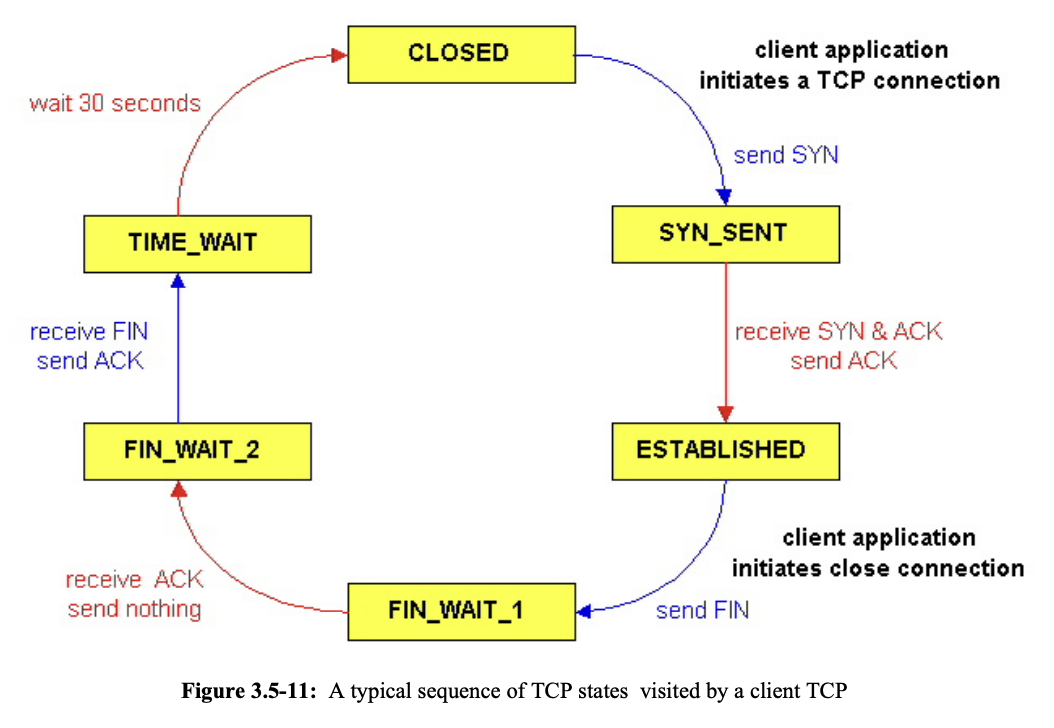
- FIN_WAIT_1 state: after client TCP sends TCP segment w/ FIN bit = 1
- client TCP waits for TCP segment from server w/ an acknowledgement
- FIN_WAIT_2 state: client TCP waits for another segment from server w/ FIN bit = 1
- TIME-WAIT state
- after receiving second segment from server w/ FIN bit = 1
- lets TCP client resend the final acknowledgement in the case the ACK is lost
- time spent here is implementation dependent
- typically 30 seconds, 1 min, or 2 min
- after the wait, connection formally closes & all resources(port numbers too) on client side are released
6. Principles of Congestion Control
6.1 Causes & Costs of Congestion
Scenario 1) Two senders & A router w/ infinite buffers
Two hosts (A & B) each have a connection that share a single hop b/w source & destination
Assumptions:
- Host A is sending data into connection at an average rate of x bytes/sec
- data are original in the sense that each unit of data is sent into socket only one
- underlying transport-level protocol:
- data is encapsulated & sent
- no error recovery (retransmission)
- no flow control
- no congestion control
- Host B operates similarly & sends data at rate of x bytes/sec
- Packets from hosts A & B pass through a router & over a shared outgoing link of capacity C
- Router has buffers that allow it to store incoming packets when the packet arrival rate exceeds the outgoing link's capacity
- assume the router has infinite amount of buffer space
Performance of Host A's connection:
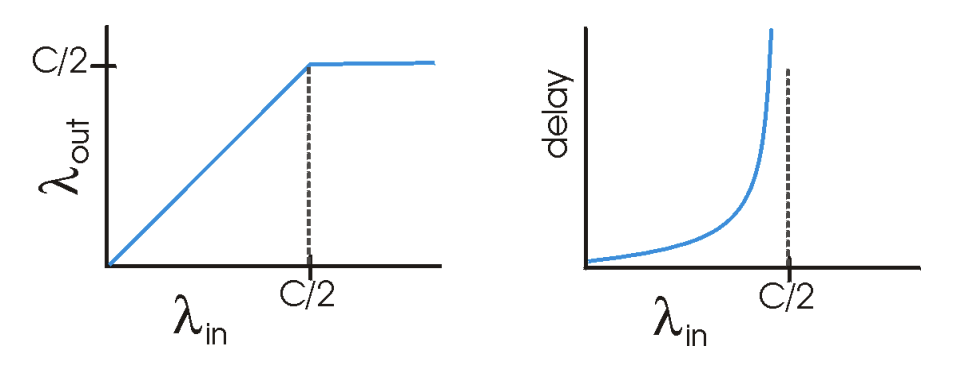
-
Left graph: per-connection throughput as a function of the connection sending rate
- Per-connection throughput: number of bytes per second at the receiver
- For sending rate in (0, C/2), the throughput at receiver == sender's sending rate
- everything sent by sender is received at receiver w/ a finite delay
- When sending rate exceeds C/2, the throughput is only C/2
- upper limit on throughput is a consequence of sharing of link capacity b/w two connections
- link can't deliver packets to a receiver at steady rate that exceeds C/2
- Both hosts A & B will each never see a throughput higher than C/2
-
Right graph: consequences of operating near link capacity
- achieving a per-connection throughput of C/2
- the link is fully utilized in delivering packets to their destination
- is not a good thing
- as sending rate approaches C/2, the average delay increases significantly
- when sending rate exceeds C/2, average number of queued packets in router is unbounded & average dely b/w source & destination becomes infinite
- while operating at an aggregate throughput of near C may be ideal from throughput standpoint, it's not ideal from delay standpoint
- congested network
- achieving a per-connection throughput of C/2
Scenario 2) Two senders & A router w/ finite buffers
Assumptions
- amount of router buffering is finite
- each connection is reliable
- If a packet containing tranpsort-level segment is dropped at router, it will eventually be retransmitted by sender
- Rate at which application sends original data into socket: x bytes/sec
- Rate at which tranpsort layer sends segments (containing original/retransmitted data): y bytes/sec
- aka offered load to the network
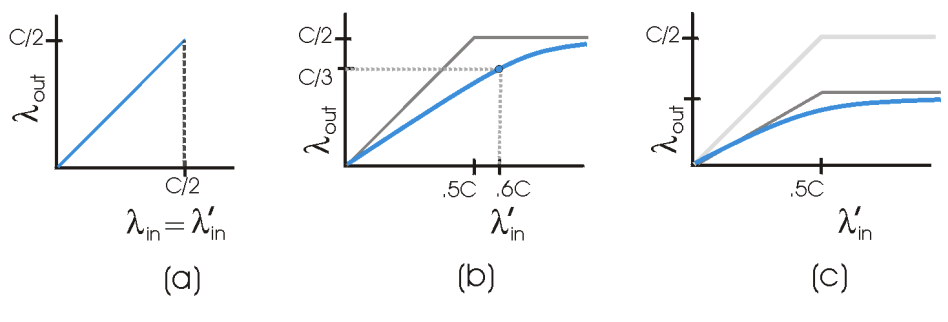
(a) No retransmissions
- Host A is able to somehow determine whether a buffer is free in router
- only sends a packet when a buffer is free
- no loss occurs
- x = y
- throughput of connection = x
- average host sending rate can't exceed C/2 since packet loss will not occur
- unrealistic
(b) only needed retransmissions
- sender retransmits only when a packet is known for certain to be lost
- when offered load (y) equals 0.6C, the rate at which data are delivered to receiver is C/3
- out of 0.6C units of data transmitted, 0.3333 ytes/sec are original data & 0.26666 bytes per second are retransmitted data
- cost of congested network: sender must perform retransmissions to compensate for lsot packets due to buffer overflow
- slightly more realistic than (a)
(c) extraneous & unneeded retransmissions
- sender may timeout prematurely & retransmit a packet that has been delayed but not yet lost
- both original data packet & retransmission may both reach the receiver
- receiver needs only one copy of this packet & discards retransmission
- router would have better used link transmission capacity on transmitting a different packet
- cost of congested network: unneeded retransmssions by sender in the face of large delays may cause router to use its link bandwith to forward unneeded copies of a packet
Scenario 3) 4 senders, routers w/ finite buffers, multihop paths
Assumptions
- 4 hosts transmit packets
- Each over overalpping two-hop paths
- Each host uses tiemout/retransmission mechanism to implement RDT
- All hosts have same value of x bytes/sec
- All router links have capacity C bytes/sec
Process
- For extremely small values of x, buffer overflows are rare
- Throughput approximately equals offered load
- For slightly larger values of x, throughput is also larger
- more original data is being transmitted
- For extremely large values of x, one of the hop paths will meet zero throughput
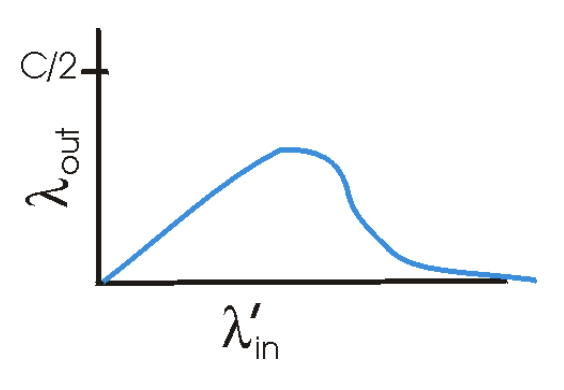
Eventual decrease in throughput w/ increasing offered load
- In high traffic scenario, whenever a packet is dropped at second-hop router, work done by first-hop router in forwarding a packet to second-hop router is wasted
- transmission capacity used at first router to forward the packet to second router could've been used profitably for another packet
- cost of congestion: when a packet is dropped along a path, the transmission capacity that was used at each of the upstream routers to forward that packet to the point at which it is dropped end sup having been wasted
6.2 Approaches Toward Congestion Control
End-end congestion control
- Network layer provides no explicit support to transport layer for congestion control purposes
- Presence of congestion in network: inferred by end systems based only on observed network behavior
- network behavior such as packet loss/delay indicates congestion
- TCP must necessarily take end-end approach towards congestion contril b/c IP layer provides no feedback to end systems regarding network congestion
- TCP segment loss is taken as indication of network congestion & TCP decreases its window size accordingly
- TCP segment loss is indicated by timeout/triple duplicate acknowledgement
Network-assisted congestion control
- Network-layer components(routers0 provide explicit feedback to sender regarding the congestion state in network
- feedback may be simple: single bit indicating congestion at link
- Congestion info is sent from network to sender in one of two ways:
- Choke packet: typical form the notification takes
- Marked packet: when a router marks/updates a field in a packet flowing from sender to receiver to indicate congestion
- takes up to a full round-trip time
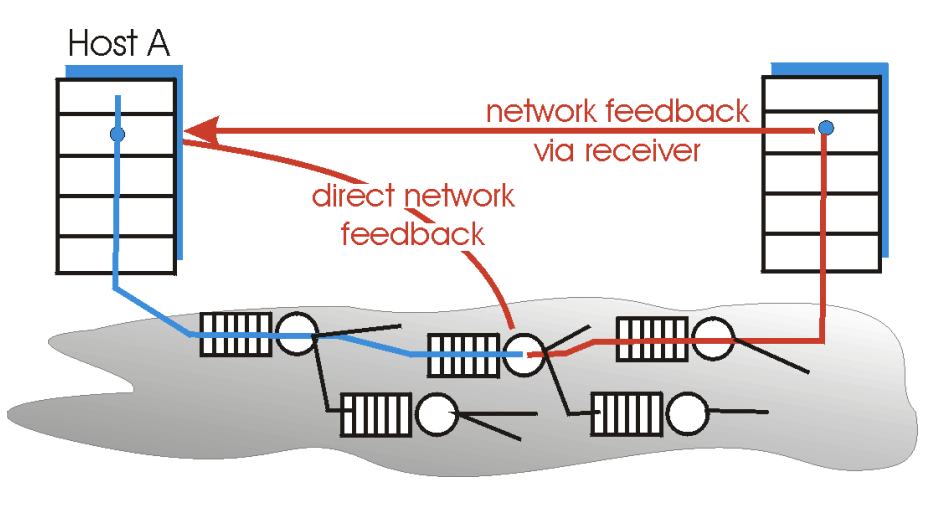
6.3 ATM ABR Congestion Control
switch: router, call: packet
Data cells are transmitted from a source to a destination through a series of intermediate switches
RM(Resource Management) cells: cells scattered b/w data cells
- used to convey congestion-related info among hosts & switches
- When an RM cell is at a destination, it will be turned around & sent back to the sender
- Switch can generate an RM cell & send this cell to a source
- can be used to provide both direct network feedback & network-feedback-via-receiver
ATM ABR congestion control
- a rate-based approach: sender explicitly computes max rate at which it can send & regulates itself accordingly
- provides 3 mechanisms for signaling congestion-related info from switches to receiver
- EFCI(Explicit Forward Congestion Indication) bit
- each data cell contains an EFCI
- a congested network switch can set the EFCI bit in a data cell to 1 to signal congestion to destination host
- destination must check EFCI bit in all received data cells
- when an RM cell arrives at destination, if the most recently-received data cell had EFCI bit = 1, then destination setes CI(Congestion Indication) bit of RM cell to 1 & sends RM cell back to sender
- sender is notified of congestion at network switch through EFCI in data cells & CI bit in RM cells
- CI and NI bits
- sender-to-receiver RM cells are interpersed w/ data cells
- rate of RM cell interpersion is a tunable parameter
- default: one RM cell every 32 data cells
- RM cells have CI bit & NI(No Increase) bit
- can be set by a congested network switch
- switch can set NI bit in a passing RM cell to 1 under mild congestion
- switch can set CI bit in a passing RM cell to 1 under sever congestion
- can be set by a congested network switch
- When destination host receives a RM cell, it will send the RM cell back to sender w/ its CI & NI bits intact
- except if destination has to set CI to 1 as result of EFCI
- Explicit Rate (ER) setting
- each RM cell contains a 2-byte ER(Explicit Rate) field
- a congested switch may lower the value contained in ER field in a passing RM cell
- ER field will be set to minimum supportable rate of all switches on the source-to-detsination path
- EFCI(Explicit Forward Congestion Indication) bit
7. TCP Congestion Control
TCP
- provides reliable transport service b/w 2 processes running on different hosts
- uses end-to-end control b/c IP layer provides no feedback to end systems regarding network congestion
TCP connection controls its transmission rate by limiting its number of transmitted-but-yet-to-be-acknowledged segments
- TCP window size: number of permissible unacknowledged segments
- TCP connections should be ideally allowed to transmit as fast as possible as long (to have a large # f outsatnding unacknolwedged segments as possible) as segments are not lost (dropped at router) due to congestion
- TCP starts w/ small value of window size & probes for existence of additional unused link bandwith at links by increasing window size
- continues to increase window size until a segment loss occurs
- detected by timeout or duplicate acknowledgements
- when loss occurs, TCP connection reduces window size to a safe level & repeats
- continues to increase window size until a segment loss occurs
Throughput: rate at which TCP connection transmits data from sender to receiver
- important measure of performance of a TCP connection
- depends on the value of window size(w)
- if a TCP sender transmits all w segments back-to-back, it must wait for a one roundt rip time until it receives acknowledgements for these segments, at which point it can send w additional segments
- if a conenciton transmits w segments of size MSS bytes every RTT seconds, the connection's throughput (=transmission rate) is
(w*MSS)/RTTbytes per sec
When K TCP connections are traversing a link of capacity R while no UDP packets are flowing, each TCP connection is transferring a very large amount of data, and none of these TCP connections traverse any other congested link:
- window sizes in TCp connections traversing this link should be in a way that each connection achieves a throughput of
R/K - if a connection passes through
Nlnks, with link n having transmission rate ofRn& supporting a total ofKnTCP connections, this connection should achieve a rate ofRn/Knon the n th link- this connection's end-to-end average rate can't exceed the min rate achived at all of links along end-to-end path
- = end-to-end transmission rate for this connection is
r= min{R1/K1, ..., Rn/Kn}
- = end-to-end transmission rate for this connection is
- this connection's end-to-end average rate can't exceed the min rate achived at all of links along end-to-end path
- goal of TCP: provide this connection with this end-to-end rate r
7. 1 Overview of TCP Congestion Control
Each side of TCP connection consists of receive buffer, send buffer, and variables (LastByteRead, RcvWin, etc.)
TCP congestion control mechanism has each side of connection keep track of 2 additional variables: Congestion window & Threshold
- Congestion window: imposes an additional constraint on how much traffic a host can send into a connection
- amount of unacknowledged data that a host can have wihtin a TCP connection may not exceed minimum of congestion window & receiving window
LastByteSent - LastByteAcked <= min{CongWin, RcvWin}
- amount of unacknowledged data that a host can have wihtin a TCP connection may not exceed minimum of congestion window & receiving window
- Threshold: affects how congestion window grows
Goal of TCP's congestion control: share a bottleneck link's bandwith evenly among the TCP connections traversing that link
Congestion window
Congestion window evolves throughout the lifetime of a TCP connection
Assumption
- TCP receive buffer is so large that the receive window constraint can be ignored
- amount of unacknowledged data that a host can have within a TCP connection is solely limited by congestion window (CongWin)
- a sender has a very large amount of data to send to receiver
Process
- Once a TCP connection is established b/w two end systems, the process at sender writes bytes to sender's TCP send buffer
- TCP grabs chunks of size MSS, encapsulates each chunk within a TCP segment, and passes segments to network layer for tarnsmission across network
- TCP congestion window regulates the times at which the segments are sent into network (passed to network layer)
- Initially, congestion window is equal to one MSS
- TCP sends first segment into network & waits for an acknowledgement
- If this segment is acknowledged before its timer times out, sender increases congestion window by one MSS & sends out two max size segments
- If these segments are acknowledged before their timeouts, the sender increases congestion window by one MSS for each of acknowledged segments
- gives congestion window of 4 MSS
- sends out 4 max sized segments
- Process continues as long as:
- (1) congestion window is below threshold
- & (2) acknowledgements arrive before their corresponding timeouts
Analysis
- Slow start: the phase the above process goes through
- process begins w/ a small congestion window equal to one MSS
- congestion window increases exponentially fast
- ends when window size exceeds value of threshold
- enters congestion avoidance
- Congestion avoidance
- at this point, congestion window grows linearly (not exponentially)
- if current window size is larger than threshold, then after w acknowledgements arrived, TCP replaces w w/ w+1
- continues as long as acknowledgements arrive before corresponding timeouts
- but window size cannot increase forever
- window size: rate at which TCP sender can send
- when timeout occurs, the value of threshold is set to half the value of current congestion window
- congestion window is reset to one MSS
- restarts slow start phase
(Except the slowstart phase) TCP increases its window size by 1 each RTT when its network path is not congested & decreases its window size by a factor of two each RTT when path is congested
-> TCP is called an additive-increase, multiplicative-decrease (AIMD) algorithm
TCP algorihtms; Tahoe, Reno, Vegas
Tahoe: when segment is lost, the sender size of the application may have to wait a long time for timeout
Reno: variant of Reno
- implemented by most operating systems
- (like Tahoe) sets its congestion window to one segment upon expiration of timer
- (unlike Tahoe) includes fast retransmit mechanism
- fast retransmit triggers transmission of a dropped segment if 3 duplicate ACKs for a segment are received before the occurrence of the segment's timeout
Vegas
- can improve Reno's performance
- attempts to avoid congestion while maintaining good throughput
- Tahoe & Reno reacts to congestion
- Process
- detect congestion in routers b/w source & destination before packet loss occurs
- lower rate linearly when this imminent packet loss is detected
- imment packet lossis predicted by observing RTT
- longer the RTT of the packets, the greater the congestion in routers
Use of TCP
TCP ensures reliable transport service & congestion control
- many multimedia applications do not run over TCP to avoid transmission rate being throttled even if network is very congested
- (ex) internet telephone/video conferencing applications
- prefer to pump their audio/video into network at constant rate & occasionally lose packets
- (ex) internet telephone/video conferencing applications
- TCP views these applications as not "fair"
- they don't cooperate w/ other connections nor adjust their transmission rates appropriately
Macroscopic Description of TCP dynamics
Sending a very large file over a TCP connection
- Connection is in the slow-start phase for a relatively short time b/c connection grows out of the phase exponentially fast
- When we ignore the slow-start phase, the congestion window grows linearly, halves when loss occurs, grows linearly, halves when loss occurs, etc.
Average throughput of TCP
- During a particular round-trip interval, the rate at which TCP sends data is a function of congestion window & current RTT
- when window size is
w*MSSand current RTT isRTT, then TCP's transmission rate is(w*MSS)/RTT
- when window size is
- During congestion avoidance phase, TCP probes for additional bandwith by increasing
wby one eachRTTuntil loss occursW: the value ofwat which loss occurs
- Assuming that
RTT&Ware approximately constant over the duration of connection, the TCP transmission rate ranges from(W*MSS)/(2*RTT)to(W*MSS)/RTT
The network drops a packet from connection when the window size increases to W*MSS.
Static Congestion Window
Many TCP connections transport relatively small files from one host to another
(ex) HTTP/1.0: each object in a Web page is transported over a separate TCP connection (many of which are small text files/icons)
- When transporting small files, TCP conenction establishment & slow-start my have a big impact on latency
Latency: time from when the client initiates a TCP conneciton until when the client receives the requested object in its entirety
Assumptions
- Network is uncongested: TCP connection transporting the object does not have to share link bandwith w/ other TCP/UDP traffic
- Simple one-link network from server to client
- Amount of data that the sender can transmit is solely limited by the sender's congestion window
- aka TCP receive buffers are large
- Packets are neither lost nor corrupted
- no retransmissions
- All protocol header overheads are negligible & ignored
- including TCP, IP and link-layer headers
- The object (aka file) to be transferred consists of an integer number of segments of size MSS
- The only packets that have non-negligible transmission times are packets that carry max size TCP segments
- other packets are small & have negligible transmission times
- (ex) request packets, acknowledgements, TCP connection establishment packets
- other packets are small & have negligible transmission times
- Initial threshold in TCP congestion control mechanism is a large value never attained by congestion window
Notations
- O bits: size of the object to be transferred
- S bits: maximum size segment (MSS)
- R bps: transmission rate of the link from server to cient (bytes per sec)
- RTT: round trip time
- time elapsed for a small packet to travel from client to server & back to client, excluding the transmission time of the packet
- includes two end-to-end propagation delays b/w two end systems & processing times at end systems
- equal to the roundtrip time of a packet beginning at the server
Static Congestion Window
- W: a positive integer, denotes a fixed-size static congestion window
- For a static congestion window, the server is not permitted to have more than W unacknowledged outstanding segments
Process
- When server receives request from client, server immediately sends W segments back-to-back to client
- The server sends one segment into network for each acknowledgement it receives from the client
- The server continues to send one segment for each acknowledgement until all of the segments of the object have been sent
Consider the following:
1. WS/R > RTT + S/R: server receives an acknowledgement for first segment in the first window before the server completes the transmission of the first window
2. WS/R < RTT + S/R: server transmits the first window's worth of segments before server receives an acknowledgement for the first segment in the window
1st Case: WS/R > RTT + S/R. W = 4 (window size: 4 segments)
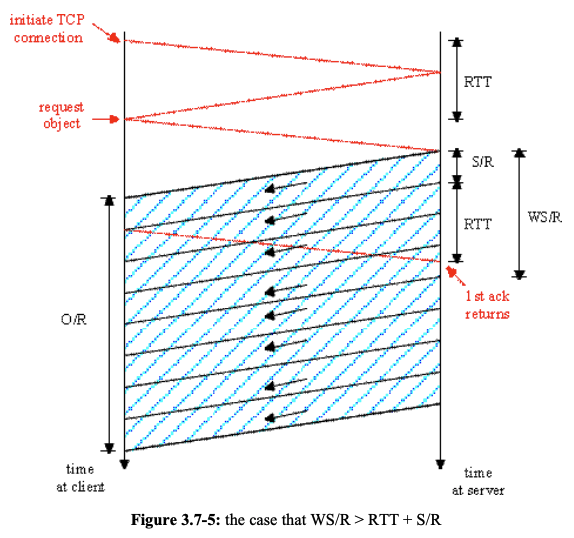
- TCP connection: requires 1 RTT
- After 1 RTT, client sends a request for the object
- This object is piggybacked onto the third segment in the three-way TCP handshake
- Client begins to receive data from the server after total of 2 RTT s
- Segments arrive periodically from the server every S/R seconds, and the client acknowledges every segment it receives from the server
- B/c server receives the first acknowledgement before it completes sending a window's worth of segments, the server continues to transmit segments after having transmitted the first window's worth of segments
- B/c acknowledgements arrive periodically at the server every S/R seconds from the time when first acknowledgement arrives, the server transmits segments continuously until it has transmitted the entire object
- Once the server starts to transmit the object at rate R , it continues to transmit the object at rate R until entire object is transmitted
- Latency:
2RTT + O/R
2nd Case: WS/R < RTT + S/R. W = 2 (window size: 2 segments)
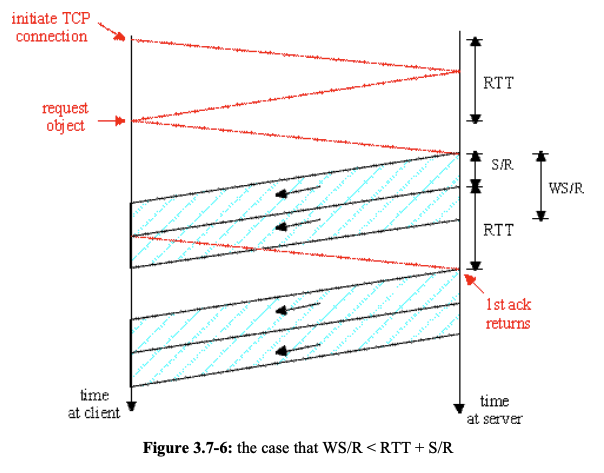
- After a total of 2 RTT s the client begins to receive segments from the server
- Segments arrive periodically every S/R seconds
- Client acknowledges every segment it receives from the server
- After sending a window, the server must stop & wait for an acknowledgement before resuming transmission
- When an acknowledgement finally arives, server sends a new segment to client
- Once first acknowledgement arrives, a window's worth of acknowledgements arrive, w/ each successive acknowledgement spaced by S/R seconds
- For each acknowledgement, server sends exactly one segment
- Thus, server alternates b/w: transmitting state, stalled state
- transmitting state: server transmits W segments
- stalled state: server transmits nothing & waits for an acknowledgement
- Latency =
2RTT + O/R +(K-1)[S/R + RTT - W*S/R](K-1)[S/R + RTT - W*S/R]: amount of time the srever is in the stalled state- K = O/WS
- if O/WS is not an integer, round K up to nearest integer
- K: number of windows of data there are in the object of size O
- K = O/WS
2 cases combined: Latency = 2RTT + O/R + (K-1)[S/R + RTT - W*S/R]+
[x]+ = max(x, 0)
7.3 Modeling Latency: Dynamic Congestion Window
- Server starts w/ a congestion window of one segment & sends one segment to the client
- When it receives an acknowledgement for the segment, it increases its congestion window to 2 segments & sends 2 segments to the client
- spaced apart by S/R seconds
- As server receives acknowledgements for two segments, it increases congestion window to 4 segments & sends 4 segments to the client
- spaced apart by S/R seconds
- Process continues w/ the congestion window doubling every RTT
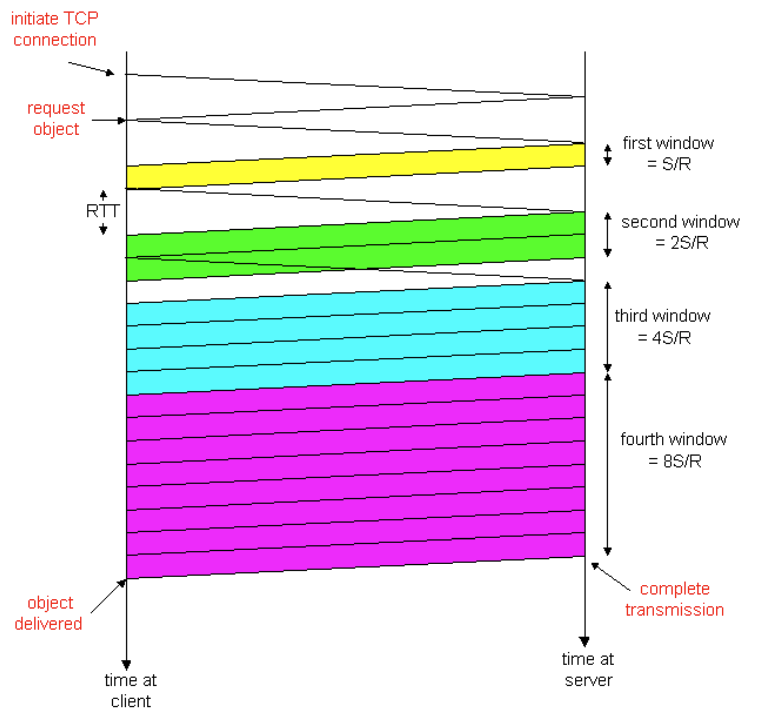
O/S: number of segments in the object
- 1st window: 1 segment
- 2nd window: 2 segments
- 3rd window: 4 segments
- k th window: 2^(k-1) segments
- When K is the number of windows that cover the object,
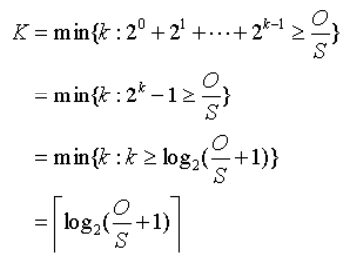
After transmitting a window's worth of data, server may stall while it waits for an acknowledgement
- Server stalls after transmitting the first & second windows but NOT after transmitting the third
- Time from when server begins to transmit the k th window until when server receives an acknowledgement for first segment in the window is S/R + RTT
- Transmission time of the k th window is (S/R)*2^(k-1)
- Stall time = difference of time from when server begins to transmit until it receives acknowledgement and transmission time of particular window
- Stall time =
[S/R + RTT - 2^(k-1)*(S/R)]+
- Stall time =
- Server can potentially stall after transmission of each of the first K-1 windows
- server is done after transmission of the K th window
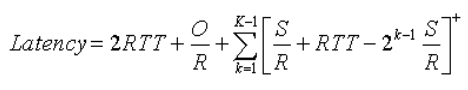
Compare latency equations for static & dynamic congestion windows
Static: Latency = 2RTT + O/R + (K-1)[S/R + RTT - W*S/R]+
-
[x]+ = max(x, 0)
Dynamic:
-
All terms are same
-
EXCEPT for the term WS/R for static windows replaced by 2^(k-1)*S/R for dynamic windows
8. Summary
Transport layer protocol
UDP protocol: provides only multiplexing/demultiplexing function for communicating processes
Other protocols: provide various guarantees (ex) reliable delivery of data, delay guarantees, bandwidth guarantees
Nevertheless, services a transport protocol can provide are often constrained by the service model of the underlying network-layer protocol
- If the network layer protocol can't provide delay/bandwidth guarantees to transport-layer segments, the transport-layer protocol can't provide delay/bandwidth guarantees for messages sent b/w processes
Transport layer protocol can provide reliable data transfer even if underlying network layer is unreliable.
Reliable data transfer can be provided by link, network, transport, application layer protocols
- Any of upper 4 layers of the protocol stack can implement acknowledgements, timers, retransmissions & sequence numbers and provide RDT to layer above.
TCP: Internet's connection-oriented reliable transport-layer protocol
- involves connection management, flow control, round-trip time estimation, reliable data transfer
