The post is personal notes I have taken while reading Computer Networking (James F. Kurose, Keith W. Ross) - 5th edition.
1. Principles of Network Applications
Network Application Architecture
Application Architecture
- designed by application developer
- about how the application is structured over end systems
- 2 categories: client-server architecture, peer-to-peer (P2P) architecture
Client-server architecture
- (ex) Web application
- server: an always-on host
- has a fixed, well-known address (IP address)
- clients: requests services to server
- can be sometimes-on or always-on
- can always contact server by sending a packet to the server's address
- Data center: large cluster of hosts
- necessary when too many requests
- Infrastructure intensive: require service providers to purchase/install/maintain server farms & pay recurring interconnection/bandwith costs
P2P architecture
- minimal reliance on always-on infrastructure servers
- Peers: pairs of intermittently connected hosts
- P2P exploits direct communication b/w peers
- not owned by service provider
- owned by laptops controlled by users
- does not pass a dedicated server
- Self-scalability
- cost-effective - no need for server
- challenges
- ISP Friendly
- most residential ISPs are dimensioned for asymmetrical bandwith usage
- much more downstream than upstream traffic
- P2P video streaming/file distribution shift upstream traffic from servers to residentail ISP
- more stress on ISPs
- Security
- b/c highly distributed & open
- hard to secure
- Incentives
- success of P2P depends on whether users are willing to volunteer bandwith, storage, computation resources
Process communicating
Process: a program that is running within an end system
- when processes are running on the same end system, they can communicate w/ interprocess communication
- under rules governed by the end system's OS
- processes on different end systems communicate thru *messages
- sending process creates & sends message into network
- receiving process receives messages & responds by sending messages back
Client and Server Processes
client process: process that initiates the communication
server process: the process that waits to be contacted to begin the session
- in P2P, a process can be both
- in Web, browser - client process, server - server process
Interface b/w the process and the computer network
A message sent from one process to another has to go through the underlying network.
Socket: a software interface through which processes send messages into & receive messages from the network
- interface b/w the application process & transport-layer protocol
- like a door to the house of process
Application Programming Interface (API): interface b/w application layer & transport layer within a host for the Internet
- application developer can control
- the choice of transport protoco
- fixing a few transport-level parameters (i.e., max buffer, max segment sizes)
Transport services available to applications
Reliable Data Transfer: data delivery serice that guarantees the data sent is delivered correctly & completely
- prevents packets loss
- unncessary for loss-tolerant applications (ex) multimedia applications like real-time audio/video having glitches
- Process-to-process reliable data transfer: the sending process can just pass its data into socket & know w/ complete confidence that the data will arrive w/o errors at the receiving process
Throughput: the rate at which the sending process can deliver bits to the receiving process
- other sessions will be sharing the bandwith along the network & these sesions will be coming/going
- the available throughput fluctuates
- service: guaranteed available throughput at a specificed rate
- Bandwith-sensitive applications: applications that have throughput requirements
- Elastic applications: can make use of available throughput
Timing
(ex) Every bit that the sender pumps into the socket arrives at the receiver's socket no more than 100 msec later
Security
(ex) transport protocol in sending host encrypts all data transmitted by the sending process & transport-layer protocol in receiving host decrypt data before deliver data to receiving process
Transport services provided by the Internet
Internet makes two transport protocols available to applications: UDP, TCP
TCP Services
- connection-oriented service: client & server exchange transport-layer control info before the application-level messages begin to flow
- alerts client & server > they can prepare for an onslaught of packets > TCP connection
- TCP connection: full-duplex connection: two processes can send messages to each other over the connection at the same time
- when application is done w/ messages, it must tear down connection
- reliable data transfer service: all data sent w/o error & in proper order
- congestion-control mechanism: throttles a sending process when network is congested b/w sender/receiver
- a service for general welfare of the Internet
- can be harmful on real time audio/video w/ minimum througput requirements
- (ex) email, remote terminal acess, the Web, file transfer
UDP services
- minimal services
- connectionless > no interaction b/w processes before communication
- unreliable data transfer service: no guarantee the message will be reached/in order
- no congestion-control mechanism: sender can freely pump data
- (ex) Internet telephony
Services not provided by Internet Transport Protocols
both TCP & UDP do NOT provide throughput/timing services
Addressing processes
To identify the receiving process: (1) the name/address of the host and (2) an identifier that specifies the receiving process in the destination host
IP address: address through which the host is identified in the Internet
Port number: identifier that specifies the receiving process in the destination host
Application-layer Protocols
Application-layer protocol: defines how an application's processes running on different end systems pass messages to each other
- defines:
- the types of messages exchanged (ex) request/response messages
- syntax of the various message types (ex) fields in the message & how the fields are delineated
- semantics of the fields > meaning of the info int he fields
- rules for determining when/how a process sends messages & responds to messages
- some application-layer protocols are specified in RFCs > in the public domain
- (ex) HTTP (the Web's application-layer protocol) is available as an RFC
Network applications vs. Application-layer protocol
- application-layer protocol: a piece of a network application
- network application includes an application layer protocol
2. The Web and HTTP
HyperText Transfer Protocol (HTTP): the Web's application-layer protocol
- implemented in two programs: client and server programs
- client & server programs execute on different end systems & exchange HTTP messages
- HTTP defines structure of these messages & how messages are exchanged
- uses TCP
- HTTP client initiates a TCP connection w/ the server
- once the connection is established, the browser/server processes access TCP through their socket interfaces
- Client sends HTTP request mesages into its socket interface & receives HTTP response message from its socket interface (same for server)
- reliabe data transfer service (TCP)
- Stateless protocol: server maintains no info about the clients
- server sends requested files to clients w/o storing any state info about the client
- if a particular client asks for the same object twice in a period of few seconds, the server resends the object twice > server forgets that it already sent the object
Web page (aka document)
- consists of objects
- object: a file (ex) HTML file, JPEG image, etc.
- base HTML file references the other objects in the page with the objects' URLS
- Each URL has two components: (1) hostanme of server that houses the object & (2) the object's path name
Web browser: implements the client side of HTTP
(ex) Internet Explorer, Firefox
Web server: implements the server side of HTTP, house Web objects, each addressable by a URL
- always on
- fixed IP address
- services requests from many different browsers
Non-persisent & Persistent connections
Non-persisent connections: request/response pair sent over a separate TCP connection
Persistent connections: all requests/responses sent over the same TCP connection
HTTP w/ Non-persistent Connections
Process
1. HTTP client initiates TCP connection
2. Client sends an HTTP request message to the server via socket
3. HTTP server process receives the request message via socket, receives the object from its storage (RAM/disk), encapsulates the object in an HTTP response message, and sends the response message to the client via its socket
4. HTTP server process tells TCP to close TCP connection (TCP doesn't actually terminate till the the client received the response message intact)
5. HTTP client receives the response message. TCP connection terminates
6. Repeated for each object (connection does not persist)
- user can decide whether connections will be parallel/serial by specifying the max # of parallel connections
Round-trip time (RTT): the time it takes for a small packet to travel from client to server and then back to client
- includes packet-propagation delays, packet-queuing delays in intermediate routers/switches, and packet-processing delays
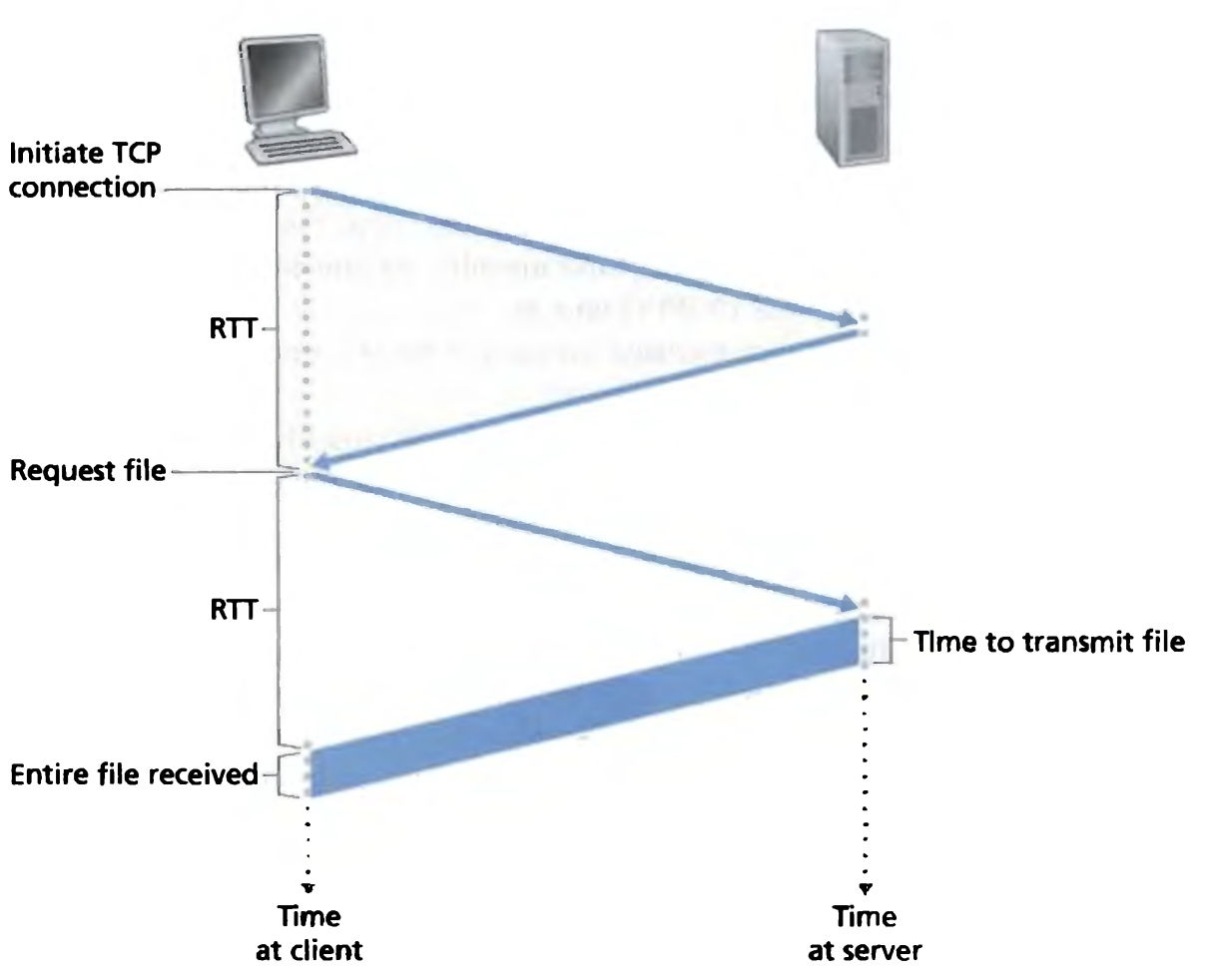
(ex) user clicks on hyperlink = 2 * RTT + transmission time at server
- Client initiates TCP conncetion b/w the browser and server
(client sends a small TCP segment to server) + (server acknowledges/responds w/ a small TCP segment) = 1 RTT - Client requests file (1/2 RTT)
- Server takes time to transmit file (1/2 RTT) and client takes time for the entire file to be received
Shortcomings of Non-persistent connections
- a new connection must be established/maintained for each requested object
- for each connection, TCP buffers must be allocated & TCP variables must be kept in both client & server
- significant burden on the Web server
- each object suffers a delivery delay of two RTTs
HTTP w/ Persistent Connections
Server leaves the TCP connection open after sending a response
- subsequent requests/responses b/w same client & server can be sent over same connection
- multiple Web pages residing on the same server can be sent from the server to the same client over a single persistent TCP connection
- requests for objects can be made back-to-back w/o waiting for replies to pending requests (pipelining)
- HTTP server closes a connection upon timeout (configurable)
- default mode of HTTP: persistent connectiosn w/ pipelining
HTTP Message Format
HTTP specifications include definitions of the HTTP message formats
2 types: request messages & response messages
HTTP Request message
GET /dir/page.html HTTP/1.1
Host: www.website.org
Connection: close
User-agent: Mozilla/4.0
Accept-language: fr- message is written in ordinary ASCII text
- message consists of 5 lines
- 1st line: request line
- 3 fields: method field, URL fields, HTTP version field
- method field: GET, POST, HEAD, PUT, DELETE
- 3 fields: method field, URL fields, HTTP version field
- subsequent lines: header lines
Host: www.website.org- specifies the host on which the object resides- required by Web proxy caches
Connection: close- the browser telling the server that it wants to close the connection after sending the requested objectUser-agent:- helps server to send different types of same objects to different clientsAccept language:- indicates the preferred language version of object
- 1st line: request line
HTTP Response message
HTTP/1.1 200 OK
Connection: close
Date: Sat, 08 March 2003 11:38:54 GMT
Server: Apache/1.3.0 (Unix)
Last-Modified: Fri, 07 March 2003 03:28:39 GMT
Content-Length: 483
Content-Type: text/html- status line: 3 fields - protocol version field, status code, corresponding status message
- status codes
- 200 OK - request succeeded & the info is returned in the response
- 301 Moved permanently - requested object permanently moved
- new URL is specified in
Location:header of the response - client software will automatically retrieve the new URL
- new URL is specified in
- 400 Bad request - generic error code, request could not be understood by server
- 404 Not found - the requested document does not exist on this server
- 505 HTTP Version not supported - requested HTTP protocol version is not supported by the server
- status codes
- header lines
Connection: close- server tells client that it'll close the TCP connection after sending the messageDate:- time & date when HTTP response was created/sentServer:- the message was generated by an Apache Web serverLast-Modified- time & date when the object was created/last modifiedContent-Length- # of bytes in the object being sent
- entity body: contains the requested object itself
User-Server Interaction: Cookies
HTTP server is stateless > simplified server design & high performance Web servers
Cookies allow sites to keep track of users
- 4 components
- A cookie header line in the HTTP response message
- A cookie header line in the HTTP request message
- A cookie file kept on the user's end system & managed by the user's browser
- A back-end database at the Web site
- Process
- already visited the Ebay
- access the Web using Internet Explorer on PC & contact Amazon.com
- when request comes into Amazon Web server, the server creates a unique identification number & creates an entry in its back-end database that is indexed by the identification number
- the server then responds to browser including
Set-cookie:header w/ the identification number in the HTTP response - When browser receives the HTTP response message, it sees the
Set-cookie:header & appends a line to the special cookie file it manages (hostname of server + identification number of header) - As user continues to browse the Amazon site, her browser consults her cookie file, extracts her identification number for this site, and puts a cookie header line that includes the identification number in the HTTP request
- Amazon server can track user's activity at Amazon site (visited pages, the order of visited pages, the time visited)
- When user returns to Amazon site after some time, the browser will continue to put the headerline
Cookie: (id number)in the request messages
- Cookies can be used to identify a user: user provides user identification > browser passes cookie header to server subsequently > identifies the user to server
- controversial > invasion of privacy?
Web Caching
Web cache (Proxy server): a network entity that satisfies HTTP requests on the behalf of an origin Web server
- has its own disk storage
- keeps copies of recently requested objects in storage
- a user's browser can be configured so that all of the user's HTTP requests are first directed to the Web cache
- is a server & client at the same time
- purchased/installed by an ISP
- Purpose
- substantially reduces the response time for a client request
- esp. if bottleneck bandwith b/w client & origin server is much less than bottleneck bandwith b/w client & cache
- substantially reduces traffic on an institution's access link to the Internet
- reduced traffic > institution does NOT have to upgrade bandwith as quickly
- substantially reduces the response time for a client request
- Process
- browser establishes TCP connection the Web cache & sends an HTTP request for the object to the Web cache
- Web cache checks to see if it has a copy of the object stored locally. If it does, the Web cache returns the object within a HTTP response message to the client browser
- If the Web cache does not have the object, the Web cache opens a TCP connection to the origin server & sends an HTTP request for the object into the cache-to-server TCP connection. After receiving this request, the origin server sends the object within an HTTP response to the Web cache.
- When the Web cache receives the object, it stores a copy in its local storage & sends a copy to the client browser within an HTTP response message (over the existing TCP connection b/w client and Web cache)
- total response time w/ cache = time from the broswer's request of object until its receipt of object = (LAN delay) + (access delay) + (Internet delay)
- solution 1) increase access rate > lower traffic intensity on access link
- costly upgrade of access rate
- solution 2) install Web cache > fraction of requests satisfied by cache > remaining requests will go through original servers > reduced traffic intensity > negligible Internet delay
- no costly upgrade needed
- lower response time than first solution
- solution 1) increase access rate > lower traffic intensity on access link
Conditional GET
Problem of caching - the copy of an object residing in the cache may be stale
- the object housed in the Web server may have been modified since the copy was cached at the client
- Conditional GET: HTTP mechanism that allows cache to verify that its objects are up to date
- (1) the request message uses the GET method
- (2) the request message includes an
If-Modified-Sinceheader line
- W/ conditional GET, the Web server will send a response message w/o requested object if the request object was updated
3. File Transfer: FTP
- FTP runs on TCP too
- Process
- User interacts w/ FTP through an FTP user agent
- User provides the hostname of the remote host
- Consequently, FTP client process in the local host establishes a TCP connection w/ the FTP server process in the remote host
- The user provides the user identification & password > sent over TCP connection as part of FTP commands
- Once the server authorizes the user, the user copies files stored in the local file system into remote file system (or vice versa)
- FTP vs. HTTP
- FTP uses 2 parallel TCP connections to transfer a file: control connection and data connection
- Control connection: to send control info b/w the two hosts
- info (ex) user identification, password, commands to change remote directory, commands to put/get files
- Data connection: to actually send a file
- Thus, FTP sends its control information out-of-band
- Control connection: to send control info b/w the two hosts
- HTTP is sends its control information in-band
- FTP uses 2 parallel TCP connections to transfer a file: control connection and data connection
- FTP session
- When user starts an FTP session w/ a remote host, the client side of FTP (user) first initiates a control TCP connection w/ the server side (remote host)
- the client sends user id & password & commands over control connection
- when the server receives command, the server initiates a TCP data connection to client side & sends file & closes the data connection
- If client wants to transfer another file, server opens another data connection
- control connection remains open throughout duration of user session
- FTP server must maintain state about the user throughout a session
- the server has to associate control connection w/ a specific user account & keep track of the user's current directory
- keeping track of state info for each ongoing user session > significant constraint on total number of sessions that FTP can maintain simultaneously
- HTTP is stateless - does not have to keep track of user states
FTP Commands and Replies
- commands: from client to server
- readable by people
- replies: from server to client
- 3 digiet number w/ optional message
- both sent across control connection in 7-bit ASCII format
- each command is followed by a reply
Commands
USER username- to send user identification to serverPASS password- to send user password to serverLIST- to ask the server to send back a list of all the files in the current remote directoryRETR filename- to retrieve (GET) a file from the current directory of the remote host- causes remote host to initiate a data connection & send the requested file over data connection
STOR filename- to store (PUT) a file into the current directory of the remote host
Response
- 331 Username OK, password required
- 125 Data connection already open; transfer starting
- 425 Can't open data connection
- 452 Error writing file
4. Electronic Mail in the Internet
E-mail - asynchronous communication medium: people send/read messages when it's convenient
- includes attachments, hyperlinks, HTML-formatted texts, photos
Internet mail system
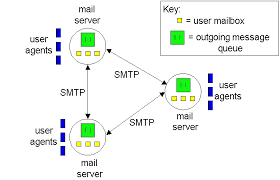
- User agent - allows users to read, reply to, forward, save, compose messages
- Mail server - each ecipient has a mailbox located in one of the mail servers
- message starts from sender's user agent > travels to sender's mail server > travels to recipient's mail server & deposited there
- if sender's server canNOT deliver mail to recipient's server, sender's server holds the message in a message queue & attempts to transfer the message later
- Simple Mail Transfer Protocol: principal application-layer protocol for Internet electronic mail
- uses reliable data service of TCP to transfer mail from the sender's mail server to recipient's mail server
- has two sides: client & server
- client executes on sender's mail server
- server executes on recipient's mail server
- thus, both sides of SMTP run on every server
SMTP
- transfers messages from senders' mail servers to recipients' mail servers
- much older than HTTP
- archaic characteristics
- restricts body of all mail messages to simple 7-bit ASCII
- requires binary multimedia data to be encoded to ASCII before being sent over SMTP & decoded back to binary after transport
- restricts body of all mail messages to simple 7-bit ASCII
- no intermediate servers
- summary
- client SMTP has TCP establish a connection at server SMTP
- if server is down, the client tries again later
- once connection established, server & client perform application-layer handshaking before transferring info
- SMTP client indicates email address of sender & email address of recipient
- SMTP counts on reliable data transfer service of TCP to get message to server w/o errors
- client SMTP has TCP establish a connection at server SMTP
- Client commands
HELO- abbreviation for HELLOMAIL FROMRCPT TODATAQUIT
- persistent connection > sending mail server can send several messages all over the same TCP connection
Comparison w/ HTTP
SMTP & HTTP both are used to transfer files from one host to another
- HTTP: transfers files from a Web server to a Web client
- SMTP: transfers files from one mail server to another
- both ues persistent connections
Differences
- Pull protocol vs. Push protocol
- HTML: mainly a pull protocol - someone loads info on a Web server & users use HTTP to pull info from server at their convenience
- TCP connection initiated by the machine that wants to receive the file
- SMTP: mainly a push protocol - sending mail server pushes the file to the receiving mail server
- TCP connection initiated by the machine that wants to send the file
- HTML: mainly a pull protocol - someone loads info on a Web server & users use HTTP to pull info from server at their convenience
- SMTP requires each message (including body) to be in 7-bit ASCII format
- How to handle document w/ text & image
- HTTP - encapsulates each object in its own HTTP response message
- SMTP - places all of the message's objects into one message
Mail Message Formats
Email message
- header contains peripheral info - precedes the message body
- header lines & body message separated by a blank line
- RFC 5322 specifies exact format for mail header lines & semantic interpretations
HTTP message
- each header line contains readable text (keyword, colon, value)
- required keywords:
From:,To: - optional:
Subject:, etc. - different from SMTP commands
- required keywords:
Mail Access Protocols
Today, mail access uses client-server architecture
- user reads email w/ a client executing on user's end system
- ability to view multimedia messages/attachments
- problem: recipient's mail server would have to remain always on & connected to Internet to receive new mail which can arrive at any time > impractical
- solution: user runs a user agent on the local PC & accesses its mailbox stored on always-on shared mail server
- mail server
- shared w/ other users
- maintained by user's ISP
Special mail access protocol that transfers messages from mail server to local PC: Post Office Protocol - Version 3 (POP3), Internet Mail Access Protocol (IMAP)
- solution: user runs a user agent on the local PC & accesses its mailbox stored on always-on shared mail server
POP3
- simple mail access protocol but limited functionality
- 3 phases
- authorization: user agent sends username & password to authenticate the user
- transaction: the user agent retrieves messages & mark messages for deletion, etc.
- update: the main server deletes the messages that were marked for deletion
- user agent issues commands; server responds to each command w/ a reply
- 2 possible responses:
+OK- previous command was fine-ERR- something was wrong w/ prev command
- 2 possible responses:
- commands
- authorization command =
user <username>pass <password>
- authorization command =
- During a POP3 session bw/a user agent & mail server, the POP3 server maintains some state info
- keeps track of which user messages have been marked deleted
- does NOT carry state info across POP3 sesions
- Drawback: POP3 does not provide any means for a user to create remote folders & assign messages to folders
IMAP
IMAP: a mail access protocol
- more complex than POP3 w/ more features
- IMAP server:
- associates each message w/ a folder
- when a message first arrives at the server, it's associated w/ the recipient's INBOX folder
- recipient can move the message into a new, user-created folder, read/delete message, etc.
- maintains user state info across IMAP sessions
- the names of folders & which messages are associated w/ which folders, etc.
- associates each message w/ a folder
- IMAP protocol provides commands:
- to allow users to create folders/move messages across folders
- to search remote folders for messages matching specific criteria
- to obtain components of messages
- useful for low bandwith connection
Web-based E-mail
Email using HTTP protocol
- not SMTP, not POP3/IMAP
5. DNS - The Internet's Directory Service
Identifiers for hosts
1. Hostname (ex) cnn.com, www.yahoo.com, etc.
- provide minimal info about location w/i the Internet of the host
- consist of variable-length alphanumeric characters > difficult to process by routers
- IP Address
- consists of 4 bytes (separated by periods)
- has a rigid hierarchical structure
Services provided by DNS
Domain name system (DNS): (1) a distributed database implemented in a hierarchy of DNS servers and (2) an application-layer protocol that allows hosts to query the distributed database
- provides directory service that translates hostnames to IP addresses
- commonly employed by other application-layer protocols to translate user-supplied hostnames to IP addresses
How the user's host send an HTTP request message to the Web server
1. The same user machien runs the client side of the DNS application
2. The browser extracts the hostname from the URL and passes the hostname to the client side of the DNS application.
3. The DNS client sends a query containing the hostname to a DNS server.
4. The DNS client eventually receives a reply, which includes the IP address for the hostname.
5. Once the browser receives the IP address from DNS, it can initiate a TCP connection to the HTTP server process located at port 80 at the IP address
Other services of DNS
- Host aliasing
- a host w/ a complicated hostname can have alias names
- canonical hostname: properly denoted hostname of ocmputers or a network server
- as opposed to mnemonic hostnames
- DNS can be invoked to obtain the canonical hostname for a supplied alias hostname/IP address of the host
- Mail server aliasing
- (ex) Even if Bob's email address is so simple (bob@hotmail.com), the hostname of the Hotmail mail server is more complicated/less mnemonic (relay1.west-coast.hotmail.com)
- DNS can obtain the canonical hostname for a supplied alias hostname/IP address of the host
- MX record permits a company's mail server & Web server to have identical hostnames
- Load distribution
- DNS can load disttribution among replicated servers (ex) replicated Web servers
- busy sites are replicated over multiple servers
- each server running on a different end system w/ different IP addresses
- for replicated Web servers, a set of IP addresses is associated w/ one canonical hostname
- How it works
- When clients make a DNS query for a name mapped to a set of addresses, the server responds w/ the entire set of IP addresses but rotates the ordering of the addresses within each reply
- client typically sends its HTTP request message to the IP address first in the set > DNS rotation distributes the traffic among replicated servers
Overview of How DNS Works
An application running in a user's host needs to translate a hostname to an IP address.
- Application invokes the client side of DNS, specifying the hostname to be translated
- DNS in the user's host takes over & sends a query message into the network
- ALL DNS query & replay messages are sent within UDP datagrams to port 53
- After a delay, DNS in the user's host receives a DNS reply message that provides desired mapping
- Mapping is passed to the invoking application
Centralized design of DNS:
- one DNS server that contains all mappings
- clients direct all queries to the single DNS
- DNS server responds directly to querying clients
- Problems:
- A single point of failure
- If the DNS server crashes, so does the entire Internet
- Traffic volume
- A single DNS server has to handle ALL DNS queries
- Distant centralized database
- A single DNS server cannot be close to all querying clients.
- (ex) If we put the server in NYC, then queries from Australia has to travel far over slow, congested links > significant delays
- Maintenance
- The single DNS server has to keep records for all Internet hosts
- The centralized database has to be huge & updated frequently
Distributed, Hierarchical Database

Mappings are distributed across DNS servers
-
DNS client wants to determine the IP address for a hostname:
www.amazon.com- The client contacts. one of the root servers
- Root server returns IP addresses for TDL servers for the top-level domain
com - The client contacts one of the TDL servers for
com - TLD server returns the IP address of an authoritative server for
amazon.com - The client contacts one of the authoritative server for
amazon.com - The authoritative server returns the IP address for hostname
www.amazon.com
-
3 classes of DNS servers: root, top-level domain, authoritative DNS servers
- Root DNS server
- There are 13 root DNS servers in the Internet
- labeled A~M
- each server is a cluster of replicated servers
- for security/reliability purposes
- Top-level domain (TLD) DNS server
- responsible for top-level domains (ex) com, org, net, edue, gov, and country top-level domains (uk, fr, ca)
- Network Solutions (company) maintains the TLD servers for the com top-level domain
- Educause (company) maintains TLD servers for the edue top-level domain
- TLD servers do not always know the authoritative DNS server for the hostname
- usually they only know the intermediate DNS server that knows the authoritative DNS server for the hostname
- Authoritative DNS server
- every organization w/ publicly accessible hosts (Web servers, mail servers) on the Internet must provide publicly accessible DNS records that map the names of those hosts to IP addresses
- An organization's authoritative DNS server houses these DNS records
- An organization can choose to implement its own authoritative DNS server to hold these records
- OR pay to have these records stored in an authoritative DNS server of a service provider
-
Local DNS server (aka default name server)
- does not strictly belong to the hierarchy of servers
- Each ISP has a local DNS server
- When a host connects to an ISP, the ISP provides the host w/ the IP address of one or more of its local DNS server
- You can determine the IP address of your local DNS server by accessing network status window
- A host's local DNS server is close to the host
- Institutional ISP) Local DNS server may be on the same LAN as host
- Residential ISP) Local DNS server is separated from host by a few routers
-
Recursive queries: one DNS server communicates w/ several other DNS servers to hunt down an IP address & return it to the client
-
Iterative queries: client communicates directly w/ each DNS server
DNS Caching
DNS caching: when a DNS server receives a DNS reply, it can cache the mapping in its local memory
(ex) if a hostname/IP address pair is cached in a DNS server & another query arrives to the DNS server for same hostname, the DNS server can provide the desired IP address
- improves delay performance
- reduces # of DNS messages ricocheting around the Internet
- Mapping b/w hostnames & IP addresses are NOT permanent > DNS servers discard cached information after some time
DNS Records & Messages
- DNS servers that implement the DNS distributed database store RRs, including RRs that provide hostname-to-IP address mappings
- Each DNS reply messages carries one or more resource records
Resource records: unit of information entry in DNS zone files
- four-tuple that contains: Name, Value, Type, TTL
- Type
- = A
- Name: hostname
- Value: IP address for the hostname
- provides the standard hostname-to-IP address mapping
- (ex) (relay1.bar.foo.com, 145.37.93.126, A)
- = NS
- Name: a domain
- Value: hostname of an authoritative DNS server that knows how to obtain the IP address for hosts in the domain
- used to route DNS queries further along in the query chain
- (ex) (foo.com, dns.foo.com, NS)
- = CNAME
- Value: canonical hostname for the alias hostname Name
- (ex) (foo.com, relay1.bar.foo.com, CNAME)
- = MX
- Value: canonical name of a mail server that has an alias hostname Name
- allows hostanmes of mail servers to have simple aliases
- to obtain the canonical name for the mail server, a DNS client queries for an MX record
- to obtain the canonical name for other servers, the DNS client queries for CNAME record
- = A
- TTL: time to live of the resource record
- determines when a resource should be removed from cache
- Type
DNS Messages
DNS query and reply messages have the same format
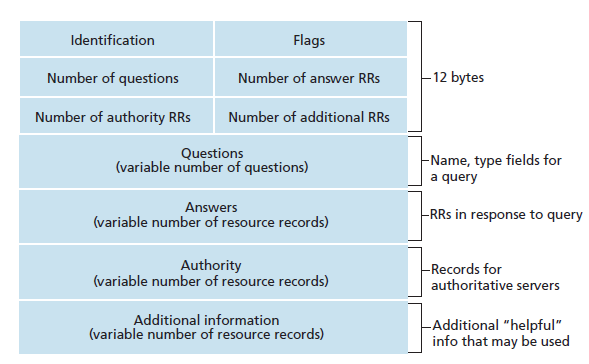
- Header section: first 12 bytes
- has a number of fields
- 1st field - a 16-bit number that identifies the query
- the identifier is copied into the reply message to a query & allows the client to match received replies w/ sent queries
- Flag field: contains a number of flags
- 1-bit query/reply flag: indicates whether the message is query (0) or reply (1)
- 1-bit authoritative flag: set in a reply message when a DNS server is an authoritative server for a queried name
- 1-bit recursion-desired flag: sent when a client (host/DNS server) desires that the DNS server perform recursion when it doesn't have the record
- 1-bit recursion-available field: set in a reply if the DNS server supports recursion
- 4 number-of fields: indicate the number of occurrences for the 4 types of data sections
- Questions section: info about the query that is being made
- a name field that contains the name that is being queried
- a type field that indicates the type of question being asked about the name
- (ex) a host address associated w/ a name (TypeA), mail server for a name (Type MX)
- Answer section: contains RRs for the name that was originally queried
- a reply can return multiple RRs in the answer
- since a hostname can have multiple IP addresses
- a reply can return multiple RRs in the answer
- Authority section: contains records of other authoritative servers
- Additional section: contains other helpful records
Nslookup program: you can send a DNS query message directly from the host to some DNS server
Inserting Records into the DNS Database
Register the domain name (network.com) at a registrar
- Registrar: a commercial entity that verifies the uniqueness of the domain name, enters the domain name into the DNS database, collects a small fee from you for its service
- When you register the domain name w/ some registrar, you have to provide the registrar w/ the names & IP addresses of your primary & secondary authoritative DNS servers (dns1.network.com, dns2.network.com, 212.212.212.21, 212.212.212.2)
- For each DNS server, the registrar will ensure that Type NS & Type A records are entered into the TDL com servers
- (network.com, dns1.network.com, NS)
- (dns1.network.com, 212.212.212.1, A)
- For each DNS server, the registrar will ensure that Type NS & Type A records are entered into the TDL com servers
- Make sure that Type A resource record for your Web server (network.com) & the Type MX resource record for mail server (mail.network.com) are entered into your authoritative DNS servers
DNS Vulnerabilities
How can DNS be attacked
- DDos bandwidth-flooding attack against DNS servers
- (ex) attacker attempts to send to each DNS root server a deluge of packets so many that the majority of legitimate DNS queries never get answered
- this case has been effectively protected against with packet filters
- A deluge of DNS queries to top-level domain servers
- harder to filter DNS queries directed to DNS servers
- top-level domain servers are not as easily bypassed as are root servers
- caching in local DNS servers will partially mitigate such attacks
- Man-in-the-middle attack
- attacker intercepts queries from hosts & returns bogus replies
- DNS poisoning attack
- attacker sends bogus replies to a DNS server, tricking the server into accepting bogus records into its cache
- Attacks manipulating DNS
- the attacker sends DNS queries to many authoritative DNS servers w/ eaech query having the spoofed source address of the targeted host
- DNS servers send their replies to the targeted host
- W/ queries that are crafted in a way that a reponse is larger than a query, attacker can potentially overwhelm the target w/o having to generate much of its own traffic
6. Peer-to-Peer Applications
P2P architecture
- minimal/no reliance on always-on infrastructure servers
- pairs of intermittently connected hosts (called peers) communicate directly w/ each other
- peers are not owned by a service provider
- are desktops/laptops controlled by users
- peers are not owned by a service provider
P2P File Distribution
P2P File distribution
- distributing a large file from a single server to a large number of hosts (called peers)
- each peer can redistribute any portion of the file it has received to any other peers
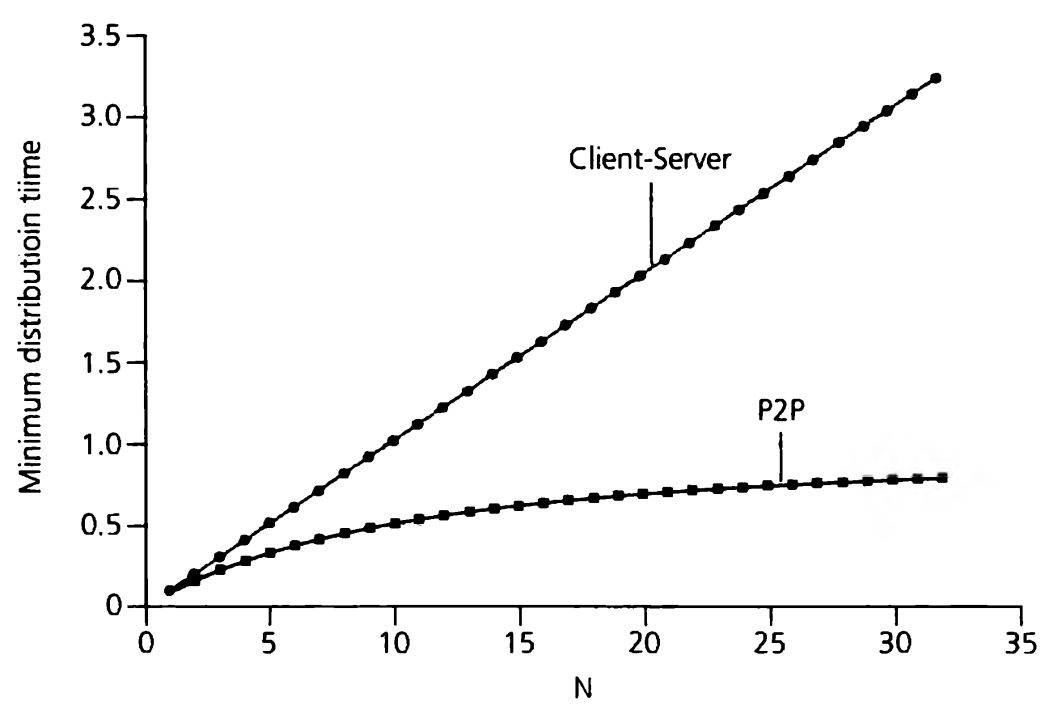
Scalability of P2P architectures
- distribution time: time it takes to get a copy of the file to all N peers
Assuming the Internet core has abundant bandwidth (all bottlenecks placed in network access), the distribution time for:
- client-server architecture
- the server transmits one copy of the file to each of the N peers
- server must transmit NF bits
- P2P architecture
- each peer can assist the server in distributing the file
- when a peer receives some file data, it can use its own upload capacity to redistribute the data to other peers
BitTorrent
BitTorrent: popular P2P protocol for file distribution
- torrent: collection of all peers participating in the distribution of a particular file
- peers in a torrent downlaod equal-size chunks of the file from one another
- while it download chunks it uploads chunks to other peers
- Each torrent has an infrastructure node called tracker
- When a peer joins a torrent, it registers itself w/ the tracker & inform the tracker that it is still in the torrent
- tracker keeps track of peers that participate in the torrent
- How participants determine which requests to make first: Rarest First
- among the chunks she does not have, determine the chunks that are the rarest among her neighbors (chunks that have the fewest repeated copies among neighbors) & request the rarest ones
- thus, rarest chunks get more quickly redistributed > equalize the number of copies of each chunk in the torrent
- among the chunks she does not have, determine the chunks that are the rarest among her neighbors (chunks that have the fewest repeated copies among neighbors) & request the rarest ones
- How participants determine to which neighbors to send first: a clever trading algorithm
- the participant gives priority to the neighbors that are currently supplying her data at the highest rate
- calculate the rate every 10 sec & modifies the set of 4 peers that are feeding her at highest rate
- Unchoked: the four peers
- every 30 sec, choose an additional neighbor at random & send chunks
- this neighbor > Optimistically unchoked
- calculate the rate every 10 sec & modifies the set of 4 peers that are feeding her at highest rate
- the participant gives priority to the neighbors that are currently supplying her data at the highest rate
Distributed Hash Tables (DHTs)
Index is critical to many P2P applications
- supports search/update operations
Distributed Hash Table: a popular indexing & searching technique
- b/c P2P systems are connected peers w/o no central authority, we want to distribute the (key, value) pairs across all the peers so that each peer only holds a small subset of the totality of the (key, value) pairs
- How to design a P2P database
- Assign an identifier to each peer
- each identifier is an integer in the range [0, 2^n -1] for some fixed n
- each identifier can be expressed by an n-bit representation
- Require each key to be an integer in the same range
- If current key can't be expressed in integers, use a hash function that maps each key to an integer in the range
- Hash function: a many-to-one function for which two different inputs can have the same output but the likelihood of the having the same output is extremely small
- assumed to be publicly availbale to all peers in the system
- Hash function: a many-to-one function for which two different inputs can have the same output but the likelihood of the having the same output is extremely small
- Thus, this distributed database is called a Distributed Hash Table (DHT)
Problem of storing (key, value) pairs in the DHT
- issue: defining a rule for assigning keys to peers
- Determine the peer whose identifier is closes to the key
- Send a message to that peer & instruct it to store the (key, value) pair
- However, you have to keep track of all the peers in the system to locally determine the closest peer
- impractical approach
Circular DHT
Arrange the peers into a circle
- Each peer only keeps track of its immediate successor
Overlay network: the peers form an abstract logical network which resides above the underlay computer network consisting of physical links, routers, hosts
- the links in an overlay network are virtual liaisons b/w pairs of peers
- not physical links
- a single overlay link typically uses many physical links & routers in the underlay network
How it works
- A peer requests for a particular key to successor
- If the successor does not have the key, he relays this message to his sucecssor
- Circular DHT reduces the amount of overlay information each peer must manage
Problem
- A tradeoff exists b/w the number of neighbors each peer has to track & the number of messages that the DHT needs to send to resolve a single query
- If each peer tracks all other peers, then only one message is sent per query but each peer has to keep track of N peers
- W/ circular DHT, each peer is only aware of two peers, but N/2 messages are sent on average for each query
Solution
- use the circular overlay as a foundation & add shortcuts so that each peer keeps track of its immediate successor & relatively small # of shortcut peers scattered about the circle
- shortcuts expedite the routing of query messages
- when a peer receives a message querying for a key, it forwards to the message to the neighbor (shortcut or successor) closest to the key
Peer Churn
In P2P systems, a peer can come/go w/o warning
How to maintain the DHT overlay in the presence of such peer churn
- require each peer to track (know the IP address of) its first & second successors
- require each peer to periodically verify that its two successors are alive
- send ping messages & asking for responses
Adding a sucecssor (Peer 13)
- Peer 13 sends a message to Peer 1
- message is forward through DHT until it reaches peer 12
- peer 12 realizes peer 12 will be successor of peer 13 and peer 15 will be peer 13's sucessor
- Peer 12 sends this info to peer 13
- Peer 13 can join DHT
Case study: P2P Internet telephony with Skype
Skype: PC-to-phone, PC-to-PC, phone-to-PC telephony service
- all packet transmissions (voice/control packets) are encrypted
- nodes in Skype are organized into hierarchical overlay network
- each peer classified as a super peer/ordinary peer
- includes an index that maps Skype usernames to current IP addresses
- index is distributed over super peers
- Skype relays: establish calls b/w hosts in home networks
- home newtork configurations provide access to the Internet through a router
- this router is called Network Address Translator (NAT)
- NAT - prevents a host from outside the home network from initiating a connection to ahost within the home network
- this router is called Network Address Translator (NAT)
- If both Skype callers have NATs, then neither can accept a call initiated by the other
- solution: User is assigned a non-NATed super peer so she can initiate a session to her super peer since her NAT only disallows sessions initiated from outside her home network
- If two NAT users want to call, their super peers select a third non-NATed super peer to relay data b/w users
- home newtork configurations provide access to the Internet through a router
7. Socket Programming w/ TCP
When client and server programs are executed, a client and a server process are created & communicate w/ each other by reading from and writing to sockets
When creating a network application, the developer's main task is to write the code for both the client & server programs
Two sorts of network applications:
- An implementation of a protocol standard defined in an RFC
- client & server programs must conform to the rules dictated by RFC
- programs will be able to interoperate as long as they are wirrten in accordance with rules of the RFC
- Proprietary network application
- the application-layer protocol used by the client & server programs do not necessarily conform to any existing RFC
- developer has complete control over the code
- b/c the code does NOT implement a public-domain protocol, other developers will not be able to develop code that interoperates with the application
- developer should not use one of the well-known port numbers defined in RFCs
Socket programmng w/ TCP
- client - initiates contact w/ the server
- server has to be ready to be able to react to client's initial contact
- server cannot be dormant > it must be running as a process before the client attempts to initiate contact
- server must have some sort of door (a socket) that welcomes some initial contact from a client process running on an arbitrary host
- The client process can initiate a TCP connection to the server when a server process is running
- by creating a socket
- when the client creates its socket, it specifies the address of the server process (IP address of the server host & port number of sever process)
- Once socket is created in cient program, TCP in the client initiates a three-way handshake & establishes a TCP connection w/ the server
- three-way handshake
- happens at transport layer
- completely transparent to the client & server programs
- three-way handshake
- During three-way handshake, the client process knocks on the door of server process
- If server hears the knocking, it creates a new socket dedicated to that particular client
- At the end of the handshake, a TCP connection exists b/w the client's socket & the server's new socket
- The server's new, dedicated socket is called the server's connection socket
The TCP connection is a direct virtual pipe b/w the client's socket & server's connection socket
- client process can send arbitrary bytes into its socket
- TCP guarantees that the server process will receive each byte in the order sent
- TCP provides a reliable byte-stream service b/w client & server processes
- TCP guarantees that the server process will receive each byte in the order sent
- cleint & server receives/sends bytes
Stream: a sequence of characters that flow into/out of a process
- Input stream: stream is attached to some input source for the process (i.e., standard input (keyboard), socket into which data flows from the Internet)
- Output stream: stream is attached to some output source for the process (i.e., standard output (monitor), socket out of which data flows into the Internet)
Implementation
TCPClient.java
import java.io.*;
import java.net.*;
class TCPClient {
public static void main(String argv[]) throws Exception {
String sentence;
String modifiedSentence;
BufferedReader inFromUser = new BufferedREader(new InputStreamReader(System.in));
Socket clientSocket = new Socket("hostname", 6789);
DataOutputStream outToServer = new DataOutputStream(clientSocket.getOutputStream());
BufferedReader inFromServer = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
sentence = inFromUser.readLine();
outToServer.writeBytes(sentence + '\n');
modifiedSentence = inFromServer.readLine();
System.out.println("FROM SERVER: " + modifiedSentence);
clientSocket.close();
}
}- creates 3 streams & one socket
inFromUser- input stream to program- attached to standard input
- characters user types
inFromServer- input stream to program- characters that arrive from the network flow into this stream
- attached to socket
outToServer- output stream from the program- attached to socket
- characters that client sends to network flow into stream
Socket clientSocket = new Socket("hostname", 6789);- initiates TCP connection b/w client & server
hostname- should be replaced w/ host name of server6789- port number
TCPServer.java
import java.io.*;
import java.net.*;
class TCPServer {
public static void main(String argv[]) throws Exception {
String clientSentence;
String capitalizedSentence;
ServerSocket welcomeSocket = new ServerSocket(6789);
while (true) {
Socket connectionSocket = welcomeSocket.accept();
BufferedReader inFromClient = new BufferedReader(new InputStreamReader(connectionSocket.getInputStream()));
DataOutputStream outToClient = new DataOutputStream(connectionSocket.getOutputStream());
clientSentence = inFromClient.readLine();
capitalizedSentence = clientSentence.toUpperCase() + '\n';
outToClient.writeBytes(capitalizedSentence);
}
}
}ServerSocket welcomeSocket = new ServerSocket(6789);- creates a server socket that listens for a knock from some client
Socket connectionSocket = welcomeSocket.accept();- when some client knocks on
welcomeSocket, this line creates a new socket - TCP establishes a virtual pipe
- when some client knocks on
8. Socket Programming w/ UDP
UDP allows two or more processes running on different hosts to communicate
- UDP vs. TCP
- UDP: connectionless service
- no initial handshaking phrase during which pipe is established
- when a process wanted to send a batch of bytes to another process, sending process must attach the destination process's address to the batch of bytes
- for each batch of bytes
- Packet: batch of information + IP destination address & port number
- provides unreliable message-oriented service model
- message-oriented: batches are bytes that are sent in a single zero operation at the sending side will be delivered as batch at the receiving side
- no guarantee that batch will be delivered
- TCP:
- byte-stream semantics
- reliable byte-stream service model
- UDP: connectionless service
- Difference in codes: In TCP, there is:
- no initial handshaking b/w processes
- no need for a welcoming socket
- no streams attached to the sockets
- the sending hosts create packets by attaching the IP destination address & port number to each batch of bytes it sends
- the receiving process must unravel each received packet to obtain the packet's info bytes
UDPClient.java
import java.io.*;
import java.net.*;
class UDPClient {
public static void main(String args[]) throws Exception {
BufferedReader inFromuser = new BufferedReader(new InputStreamReader(System.in));
DatagramSocket clientSocket = new DatagramSocket();
InetAddress IPAddress = InetAddress.getByName("hostname");
byte[] sendData = new byte[1024];
byte[] receiveData = new byte[1024];
String sentence = inFromuser.readLine();
sendData = sentence.getBytes();
DatagramPacket sendPacket = new DatagramPacket(sendData, sendData.length, IPAddress, 9876);
clientSocket.send(sendPacket);
DatagramPacket receivePacket = new DatagramPacket(receiveData, receiveData.length);
clientSocket.receive(receivePacket);
String modifiedSentence = new String(receivePacket.getData());
System.out.println("FROM SERVER: + modifiedSentence);
clientSocket.close();
}
}DatagramSocket clientSocket = new DatagramSocket();- this line does not initiate a TCP connection
- the client host does NOT contact the server host upon executin
- hence, this line does not take the server host name or port number as arguments
InetAddress IPAddress = InetAddress.getByName("hostname");- we need the address of the process to send bytes to a destination process
sendData = sentence.getBytes();- type conversion from string to an array of bytes
DatagramPacket sendPacket = new DatagramPacket(sendData, sendData.length, IPAddress, 9876);- constructs packet which the client will push into network through its socket
UDPServer.java
import java.io.*;
import java.net.*;
class UDPServer {
public static void main(String args[]) throws Exception {
DatagramSocket serverSocket = new DatagramSocket(9876);
byte[] receiveData = new byte[1024];
byte[] sendData = new byte[1024];
while (true) {
DatagramPacket receivePacket = new DatagramPacket(receiveData, receiveData.length);
serverSocket.receive(receivePacket);
String sentence = new String(receivePacket.getData());
InetAddress IPAddress = receivePacket.getAddress();
int port = receivePacket.getPort();
String capitalizedSentence = sentence.toUpperCase();
sendData = capitalizedSentence.getBytes();
DatagramPacket sendPacket = new DatagramPacket(sendData, sendData.length, IPAddress, port);
serverSocket.send(sendPacket);
}
}
}DatagramSocket serverSocket = new DatagramSocket(9876);- constructs datagram socket at port 9876
- all data sent & received will pass thru this socket
- if multiple clients access this application, they will all send their packets into this single door
- unravel packet that arrives from the client (extract data, IP address, port number)
