개요
- 워드 임베딩은 각 단어를 좌표공간에 최적의 벡터로 표현하는(임베딩하는) 기법을 말한다.
- text 데이터셋을 학습 데이터로 주고 좌표공간의 차원 수를 미리 정의해서 알고리즘에 주면 알고리즘이 각각의 단어에 대한 최적의 좌표값(벡터)을 준다.
- 유사한 단어는 가까이, 유사하지 않은 단어는 멀리 위치하는 것을 '최적의 좌표값'으로 표현할 수 있다.
1. Word2Vec
1. Word2Vec Idea
Word2Vec의 아이디어는 문장 내에서 비슷한 위치에 등장하는 단어는 유사한 의미를 가질 것이라는 가정에서 출발한다. 즉, 주변에 등장하는 단어들을 통해 중심 단어의 의미가 표현될 수 있다는 것으로 추정을 시작한다.

- 주변 단어를 기반으로 근처의 다른 단어의 확률 분포를 예측한다.
1) tokenization
2) unique한 단어만 모아서 사전(vocabulary) 구축
3) 사전의 각 단어는 이 사전만큼의 사이즈를 가지는 one-hot vector로 나타내어짐.
4) sliding window 라는 기법을 적용해서 어떤 한 단어를 중심으로 앞뒤로 나타나는 단어 각각과 입출력 단어 쌍을 구성.
ex) I study math.
중심단어가 I : (I, study)
슬라이딩 윈도우를 하나 옮겨서 중심단어가 study : (study, I), (study, math)
5) 이렇게 생긴 많은 단어 쌍들에 대해 예측 task를 수행하는 two-layer의 NN을 사용해 word embedding을 수행.
2. Word2Vec 계산 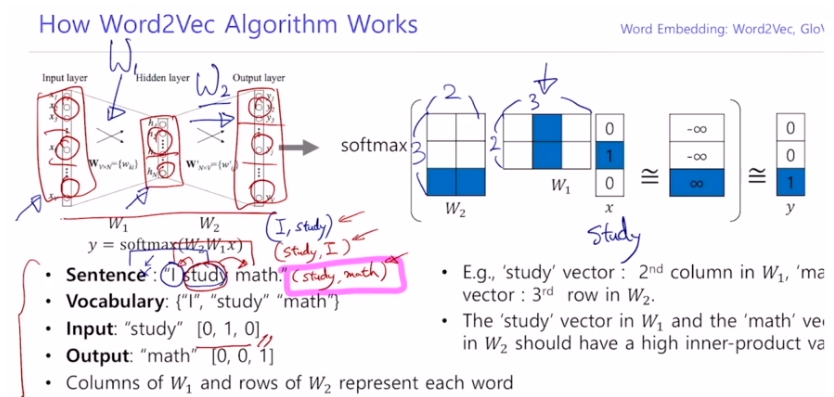
- 현재 각 단어가 vocabulary 사이즈만큼의 one-hot 벡터이므로 input layer와 output layer의 노드 수 또한 vocabulary 사이즈와 동일하다.
- hidden layer의 노드 수는 사용자가 설정하는 하이퍼 파라미터이다. word-embedding을 수행하는 좌표공간의 차원 수와 동일한 값으로 설정한다.
- ex) study가 input일 때
input layer 노드 수 : 3
output layer 노드 수 : 3
hidden layer 노드 수 : 2로 설정
: 2x3 행렬
: 3x2 행렬 - 행렬곱 연산 후에는 softmax를 non-linear 함수로 사용해줌으로써 3차원의 확률분포를 얻는다.
- 이 확률분포와 <ground truth 인 math에 100%를 부여한 3차원 확률분포 벡터> 와의 거리가 가장 가까워지도록 cross entropy loss를 감소시키는 방향으로 학습을 진행함으로써 이 neural net에 있는 과 를 업데이트한다.
3. Word2Vec에서의 행렬곱
- : 가 one-hot 벡터이므로
one-hot 벡터에서 1인 위치에 해당하는 그 인덱스의 column vector를 에서 뽑아오는 것이다.
이 원핫 벡터와 이 곱해지는 과정은 특별히 embedding layer라고 부른다. 실제로 Tensorflow나 Pytorch와 같은 프레임워크에서 임베딩 레이어와의 연산은 실제로 행렬곱을 수행하는 것이 아니라, one-hot 벡터에서 1에 해당하는 자리의 인덱스를 찾고 그 인덱스에 해당하는 column vector를 에서 뽑아오는 것이다. - 와, 와 의 곱으로 구해진 2-d 벡터의 곱: 의 각각의 row vector와 2-d 벡터의 내적으로 구해진다. 의 row vector의 수는 vocabulary에 포함된 단어 수만큼 존재한다. (예시에서 row vector의 차원은 2.)
- ground truth word 자리에 100% 확률이 부여된 ground truth label과, 의 각각의 row vector와 2-d vector의 내적으로 구해진 값이 최대한 가까우려면
ground truth 단어의 위치에 해당하는 내적 값은 +, 아닌 값은 –로 나와야 softmax를 적용했을 때 ground truth 확률값과 최대한 가까워진다.
이러한 내적 연산을 벡터들 간의 유사도를 나타내는 과정으로 생각한다면, 주어진 입력 단어의 상에서의 column vector와, 주어진 출력 단어의 상에서의 row vector 간의 내적의 유사도가 최대한 커지도록 하고
동시에 주어진 출력 단어가 아닌 단어들의 상에서의 row vector 들과의 내적의 유사도는 최대한 작도록
과 의 파라미터들을 조금씩 업데이트하는 것이 Word2Vec의 핵심 과정이다.
4. 예시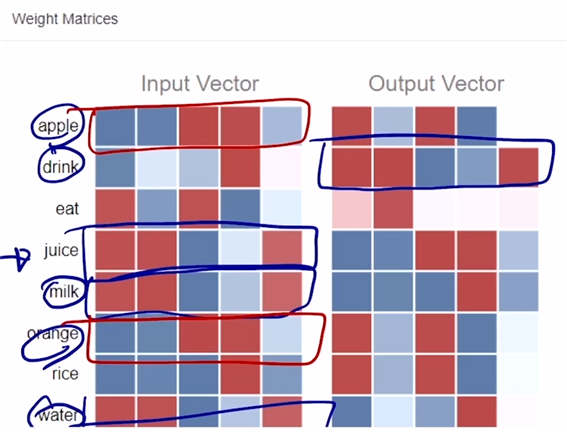
- 왼쪽 matrix가 , 오른쪽이 . 붉은색은 양수, 푸른색은 음수.
- 위의 matrix는 학습을 여러 번 진행하면서 gradient descent에 따라 파라미터를 업데이트한 상태로, drink, juice, milk, water 등 유사한 단어들은 벡터 형태가 비슷한 것을 확인할 수 있다. apple, orange 등도 벡터 형태가 비슷하다.
- 입력 단어 버전의 word embedding 벡터들과 출력 단어 버전의 word embedding 벡터들 둘 중에 어느 것을 최종적인 word embedding output으로 사용해도 크게 상관은 없음. 그러나 보통 통상적으로 (입력 버전)을 워드 임베딩 결과로 사용한다.
- 이렇게 학습된 Word2Vec 은 벡터들 간의 의미론적 결과를 잘 학습한 것으로 알려져 있다.
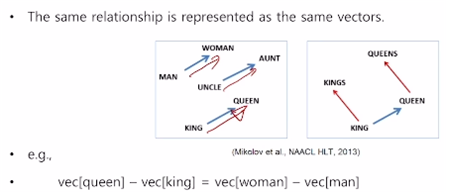 queen - king 그리고 woman - man , 마지막으로 aunt - uncle 의 벡터가 비슷한 것을 볼 수 있다. 해당 결과가 의미하는 것은 여성과 남성의 관계성을 잘 학습했다는 것을 의미한다.
queen - king 그리고 woman - man , 마지막으로 aunt - uncle 의 벡터가 비슷한 것을 볼 수 있다. 해당 결과가 의미하는 것은 여성과 남성의 관계성을 잘 학습했다는 것을 의미한다.
5. Word2Vec을 사용하는 다른 tasks
- intrusion detection : 여러 단어가 주어져있을 때 가장 의미가 다른 한 단어를 detect. 각 단어의 word embedding vector에 대해 다른 단어들의 벡터들과의 euclidean distance를 계산해 평균을 취한 후, 이 평균 거리가 가장 먼 단어를 고르게 되면 그 단어가 바로 주어진 단어들 중 가장 의미가 상이한 단어라고 할 수 있다.
- Word2Vec단어 자체의 의미를 파악하는 태스크 이외에도 자연어를 word 단위의 input으로 제공해주는 기능을 하고 있다. machine translation, PoS tagging, 감정분석 등에 쓰일 수 있다.
2. GloVE
- : 한 윈도우 내에서 두 단어가 동시에 나타나는 빈도
- : 입력 단어의 embedding vector
- : 출력 단어의 embedding vector
- Word2Vec 에서는 특정한 입출력 단어 쌍이 학습 데이터셋에서 빈번하게 등장했을 경우 데이터 아이템이 자연스럽게 여러 번에 걸쳐 학습됨으로써 학습이 진행될수록 두 워드 임베딩 벡터의 내적값이 커지도록 학습을 시켰다면 여기서는 동시 등장 횟수를 미리 계산하고, 이에 log를 취한 값을 두 단어 간의 내적값의 ground truth로 사용함으로써 반복계산을 줄일 수 있다.
- 따라서 Word2Vec보다 더 빠르게 동작하며, 더 적은 데이터에서도 잘 동작한다.
Reference
부스트코스 '자연어처리의 모든 것'
https://www.boostcourse.org/ai330/lecture/1455362?isDesc=false
https://www.boostcourse.org/ai330/lecture/1455363?isDesc=false
