NLP 기초
1.Word Embedding - Word2Vec, GloVe

워드 임베딩은 각 단어를 좌표공간에 최적의 벡터로 표현하는(임베딩하는) 기법을 말한다.text 데이터셋을 학습 데이터로 주고 좌표공간의 차원 수를 미리 정의해서 알고리즘에 주면 알고리즘이 각각의 단어에 대한 최적의 좌표값(벡터)을 준다. 유사한 단어는 가까이, 유사하지
2023년 9월 24일
2.RNN, LSTM, GRU
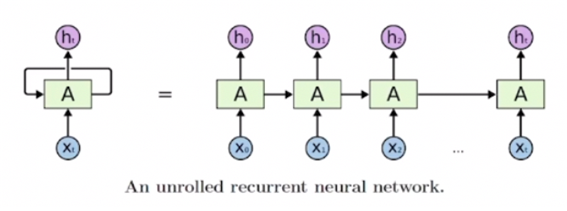
어떤 sequence data가 입력 또는 출력으로 들어오는 상황에서 각 타임스텝에서 들어오는 입력 $Xt$와 이전 타임스텝의 RNN 모듈에서 계산한 hidden state vector $h{t-1}$을 받아서 현재 타임스텝의 hidden state vector를 출력
2023년 10월 6일
3.Seq2seq & Attention

1. Seq2seq Model 1.1 Seq2seq 개요 RNN에서 many-to-many(입력 출력 둘다 sequence)에 해당되는 모델이다. 입력 문장을 읽어보는 부분을 'encoder', 출력 문장을 생성하는 부분을 'decoder'라고 한다. 인코더 디코더 둘
2023년 9월 23일
4.Transformer
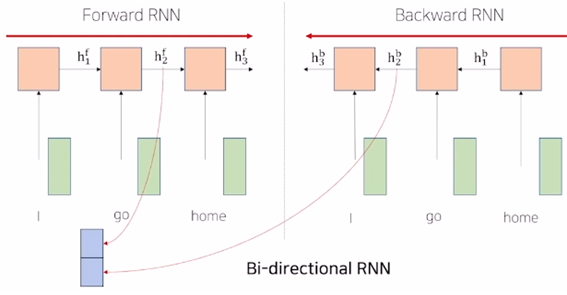
LSTM이나 GRU 기반의 Seq2seq 모델의 추가적인 add on 모듈로서 attention을 사용했었다면, 시퀀스 데이터를 입력/출력으로 처리할 때 사용할 때 사용하는 LSTM이나 GRU 혹은 전반적인 RNN 모델 자체를 이제는 attention 모듈만을 사용하는
2023년 10월 6일