[DB] 데이터베이스 객체
#데이터베이스 객체(Database Object)
: 데이터들을 저장하는 기능을 가진 가장 기본적인 테이블부터 뷰, 인덱스, 시퀀스, 저장 프로시저 등 그 용도에 따라 여러 가지가 존재한다.
| DataBase's Object | EXPLAIN |
|---|---|
| TABLE | 데이터 담고 있는 객체. |
| VIEW | 하나 이상의 테이블 연결해서 마치 테이블인 것처럼 사용하는 객체. |
| INDEX | 테이블에 있는 데이터를 바르게 찾기 위한 객체. |
| SYNONYM(동의어) | 데이터베이스 객체에 대한 별칭을 부여한 객체. |
| SEQUENCE | 일련번호 채번을 할 때 사용되는 객체. |
| FUNCTION | 특정 연산을 하고 값을 반환하는 객체. |
| PROCEDURE | 함수와 비슷하지만 값을 반환하지 않는 객체. |
| PACKAGE | 용도에 맞게 함수나 프로시저 하나로 묶어 놓은 객체. |
##인덱스(INDEX)
#ROWID
: ROWID는 데이터베이스 내 데이터 공유의 주소로, 이를 통해 데이터에 접근할 수 있다.
-
모든 테이블의 모든 데이터는 내부적으로 ROWID를 저장하고있음
-
해당 row(행)의 고유한 주소 값을 가리킨다.
DB에서 가장 빠르게 데이터를 찾아낼 수 있는 검색 방법
-
ROWID 구조
: AAASHOAAEAAAACXAAM
| AAASHO | AAE | AAAACX | AAM |
|---|---|---|---|
| 데이터 오브젝트 번호 | 파일 번호 | BLOCK 번호 | ROW 번호 |
[][]
#인덱스
-
인덱스란?
: 어떤 데이터가 어디에 있다는 위치 정보를 가진 주소록 >> ROWID는 주소이고 ROWID를 목록으로 정리하여 쉽게 테이블을 찾을수 있게 하는 역할
- 카테고리랑 ROWID만 인덱스에 넣어준다. -> ROWID값을 기준으로 데이터베이스에 조회(ROWID로 DB찾기가 쉽다)
인덱스를 만드는 이유
: ROWID를 기준으로 데이터를 탐색할 수 있도록 유도해서 쿼리의 성능을 향상시키기 위함이다.(인덱스가 없다면 테이블을 찾을때마다 Full Scan을 해야함)
인덱스 생성
실제 사용시 다음과 같이 인덱스를 생성해 놓으면 내부적으로 알아서 작동한다.
book_store 테이블의 category 컬럼에 index_category라는 인덱스를 생성
CREATE INDEX index_category ON book_store(category)book_store 테이블의 category 컬럼에 index_category라는 인덱스를 생성한 후, 기존과 똑같이 사용하면 된다.
SELECT name, location
FROM book_store
WHERE category = 'java'인덱스 생성원리
전체 테이블 스캔 (Table Full scan) -> PGA내의 Sort Area에서 정렬(Sort) -> Block 기록
-> 정렬 작업하기 때문에 시간이 많이 걸림.
인덱스는 데이터가 정렬되어 들어감
**PGA(Program Global Area)
오라클이 사용하는 메모리는 크게 두 가지가 존재한다.
- SGA(System Global Area) - 모든 사용자가 공유 가능하여 사용
- PGA(Program Global Area) - 사용자마다 공유하지 않고 개별적으로 사용
**Database Block
: 오라클 데이터베이스에서 데이터를 저장하는 최소 단위의 논리 단위 이다.
- 흔히 논리 블록(Logical Block), 페이지(Page)등으로 불림
- 이 Data Block의 사이즈는 입출력을 원활히 하기 위해 흔히 운영체제 블록의 정수배로 결정 된다.
- 오라클 데이터베이스에 데이터를 쓰고, 읽는 동작의 단위가 결국 Data Block 인 것이다.
인덱스 구조
-
테이블과 인덱스 비교
- 테이블 : 컬럼이 여러 개, 데이터가 정렬되지 않고 입력된 순서대로 들어감
- 인덱스 : 컬럼이 key 컬럼과 ROWID 컬럼 두 개로 이루어져 있음 ( 오름차순, 내림차순 정렬가능)
-
Key : 인덱스를 생성하라고 지정한 컬럼의 값
인덱스 작동원리
select *
from emp
where empno=7902;데이터 파일의 블록이 10만개 일 때, SQL을 수행시
1) 서버 프로세스가 파싱 과정을 마친 후 DB buffer cache에 empno 가 7902인 정보가 있는지 확인
2) 정보가 없으면 하드 디스크 파일에서 7902정보를 가진 블록을 복사해서 DB buffer cache로 가져온 후 7900 정보만 골라내서 사용자에게 보여줌
이 때
index 없는 경우 - 7902정보가 어떤 블록에 들어 있는지 모르므로 10만개 전부 db buffer cache로 복사한 후 하나하나 찾음
index 있는 경우 - where 절의 컬럼이 index가 만들어져 있는지 확인 후, 인덱스에 먼저 가서 7902정보가 어떤 ROWID를 가지고 있는지 확인한 후 해당 ROWID에 있는 블록만 찾아가서 db buffer cache에 복사함.
##시퀀스(Sequence)
-
시퀀스란?
- 시퀀스란 자동으로 순차적으로 증가하는 순번을 반환하는 데이터베이스 객체입니다.
- 보통 PK값에 중복값을 방지하기위해 사용합니다.
- 시퀀스를 사용하면 로직 필요없이 데이터베이스에 ROW가 추가될때마다 자동으로 +1을 시켜주어 매우 편리합니다.
-
시퀀스 생성
-
문법
--문법 CREATE SEQUENCE [시퀀스명] INCREMENT BY [증감숫자] --증감숫자가 양수면 증가 음수면 감소 디폴트는 1 START WITH [시작숫자] -- 시작숫자의 디폴트값은 증가일때 MINVALUE 감소일때 MAXVALUE NOMINVALUE OR MINVALUE [최솟값] -- NOMINVALUE : 디폴트값 설정, 증가일때 1, 감소일때 -1028 -- MINVALUE : 최소값 설정, 시작숫자와 작거나 같아야하고 MAXVALUE보다 작아야함 NOMAXVALUE OR MAXVALUE [최대값] -- NOMAXVALUE : 디폴트값 설정, 증가일때 1027, 감소일때 -1 -- MAXVALUE : 최대값 설정, 시작숫자와 같거나 커야하고 MINVALUE보다 커야함 CYCLE OR NOCYCLE --CYCLE 설정시 최대값에 도달하면 최소값부터 다시 시작 NOCYCLE 설정시 최대값 생성 시 시퀀스 생성중지 CACHE OR NOCACHE --CACHE 설정시 메모리에 시퀀스 값을 미리 할당하고 NOCACHE 설정시 시퀀스값을 메로리에 할당하지 않음 -
예제
--예제 CREATE SEQUENCE EX_SEQ --시퀀스이름 EX_SEQ INCREMENT BY 1 --증감숫자 1 START WITH 1 --시작숫자 1 MINVALUE 1 --최소값 1 MAXVALUE 1000 --최대값 1000 NOCYCLE --순한하지않음 CACHE; --메모리에 시퀀스값 미리할당결과 :
Sequence EX_SEQ이(가) 생성되었습니다. -
이 시퀀스는 EX_SEQ라는 시퀀스이고
1부터 시작해 1씩 증가하며 시작값은 1부터 1000까지 순번을 자동하는 시퀀스입니다. Cache를 사용하여 시퀀스값의 액세스 효율이 Cache를 사용하지 않았을때보다 증가합니다.
-
-
시퀀스 사용 예시
-
- 테스트 할 간단한 TEST 테이블을 만듭니다.
CREATE TABLE EX_TABLE (BOARD_NUM NUMBER(19,6) NOT NULL); -
- 위에서 만들었던 EX_SEQ 시퀀스로 TEST테이블에 데이터를 넣습니다.
INSERT INTO EX_TABLE(BOARD_NUM) VALUES(EX_SEQ.NEXTVAL); INSERT INTO EX_TABLE(BOARD_NUM) VALUES(EX_SEQ.NEXTVAL); INSERT INTO EX_TABLE(BOARD_NUM) VALUES(EX_SEQ.NEXTVAL); -
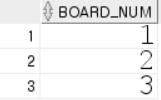
- 넣었던 데이터를 SELECT문으로 확인해봅니다.
SELECT * FROM EX_TABLE -
1, 2, 3이라는 값이 순차적으로 INSERT된것을 볼 수 있습니다. 시퀀스명.NEXTVAL을 사용하면 해당 시퀀스에서 다음 순번 값을 자동으로 가져옵니다.
-
-
시퀀스 조회
SELECT EX_SEQ.CURRVAL FROM DUAL --해당 시퀀스 값 조회 SELECT * FROM USER_SEQUENCES --전체 시퀀스 조회시퀀스 수정
-
문법
--문법 ALTER SEQUENCE [시퀀스명] INCREMENT BY [증가값] NOMINVALUE OR MINVALUE [최솟값] NOMAXVALUE OR MAXVALUE [최대값] CYCLE OR NOCYCLE [사이클 설정 여부] CACHE OR NOCACHE [캐시 설정 여부] -
예제
--예제 ALTER SEQUENCE EX_SEQ INCREMENT BY 2 MINVALUE 2 MAXVALUE 10000 CYCLE NOCACHE;결과 :
Sequence EX_SEQ이(가) 변경되었습니다. -
시퀀스는 DDL문이므로 ALTER문을 사용하여 수정이 가능
-
시퀀스 삭제
--문법 DROP SEQUENCE [시퀀스명] --예제 DROP SEQUENCE EX_SEQ결과 :
Sequence EX_SEQ이(가) 삭제되었습니다.
##PL/SQL
-
절차형 SQL
- SQL 언어에서도 일반적인 개발 언어처럼 절차 지향적인 프로그램이 가능하도록 함
- 종류 : DBMS 벤더별로 PL(Procedural Language) / SQL(Oracle), SQL/PL(DB2), T-SQL(SQL Server) 등의 절차형 SQL을 제공하고 있다.
- 이는 조건에 따른 분기처리를 이용해 특정 기능을 수행하는 저장 모듈을 생성할 수 있다
-
PL/SQL (Oracle’s Procedural Language extension to SQL) 란?
-
SQL의 확장된 개념으로 ORACLE에서 지원하는 프로그래밍 언어의 특성을 수용한 SQL의 확장
-
PL/SQL Block내에서 SQL의 DML(데이터 조작어)문과 Query(검색어)문, 절차형 언어(if, loop)등을 사용하여 절차적 프로그래밍을 가능하게 한 강력한 트랜잭션 언어이다.
-
PL/SQL 문은 블록구조로 이루어지며 PL/SQL 자신이 컴파일 엔진을 포함하고 있다
-
-
특징
-
블록 단위의 실행을 제공한다. 이를 위해 BEGIN과 END;를 사용한다. 그리고 마지막 라인에 /를 입력하면 해당 블록이 실행된다.
-
변수, 상수 등을 선언하여 SQL과 절차형 언어에서 사용
-
변수의 선언은 DECLARE절에서만 가능하다. 그리고 BEGIN 섹션에서 새 값이 할당될 수 있다.
-
IF문을 사용하여 조건에 따라 문장들을 분기 가능
-
LOOP문을 사용하여 일련의 문장을 반복 가능
-
커서를 사용하여 여러 행을 검색 및 처리
-
PL/SQL에서 사용 가능한 SQL은 Query, DML, TCL이다.
-
DDL (CREATE, DROP, ALTER, TRUNCATE …), DCL (GRANT, REVOKE) 명령어는 동적 SQL을 이용할 때만 사용 가능하다.
-
PL/SQL의 SELECT문은 해당 SELECT의 결과를 PL/SQL Engine으로 보낸다.
-
-
장점
-
1) 프로시저 생성자와 SQL의 통합
-
2) 성능 향상 : 잘 만들어진 PL/SQL 명령문이라는 가정하에 좋아진다.
-
3) *모듈식 프로그램 개발 : 논리적인 작업 을 진행하는 여러 명령어들을 하나의 블록을 만들 수 있다.
-
4) Oracle 툴과의 통합
-
5) 이식성
-
6) 예외 처리
-
PL/SQL은 다음 SQL의 단점들을 개선해준다.
1) 변수가 없다.
2) 단문 형식이다. (한번에 하나의 명령문만 사용 가능 => 트래픽 증가)
3) 제어문이 없다. (IF, LOOP)
4) 예외처리가 없다.
-
-
PL/SQL BLOCK 구조
PL/SQL은 논리적인 블록으로 이루어진 구조화된 블록언어로써 세개의 섹션으로 구성된다.
- 선언부
- 실행부
- 예외처리부
| 영역 | 설명 | 옵션/필수 |
|---|---|---|
| DECLARE (선언부) | PL/SQL에서 사용하는 모든 변수나 상수를 선언하는 부분으로서 DECLARE로 시작 => 변수/상수/커서 등 을 선언 | 옵션 |
| BEGIN (실행부) | 절차적 형식으로 SQL문을 실행할수있도록 절차적 언어의 요소인 제어문, 반복문, 함수 정의 등 로직을 기술할수있는 부분이며 BEGIN으로 시작 | 필수 |
| EXCEPTION (예외 처리부) | PL/SQL문이 실행되는 중에 에러가 발생할수있는데 이를 예외 사항이라고 한다. 이러한 예외 사항이 발생했을때 이를 해결하기 위한 문장을 기술할수있는 부분 | 옵션 |
| END (실행문 종료) |
-
PL/SQL Block종류
-
익명 블록 : 이름이 없는 PL/SQL Block을 말한다.
-
이름 있는 블록 : DB의 객체로 저장되는 블록이다.(Oracle *저장 모듈)
-
프로시저 : 함수와 비슷하지만 값을 반환하지 않는 객체.
-
함수 : 리턴 값을 반드시 반환해야 하는 프로그램을 말한다.
-
패키지 : 하나 이상의 프로시저, 함수, 변수, 예외 등의 묶음을 말한다.
-
트리거 : 지정된 이벤트가 발생하면 자동으로 실행되는 PL/SQL 블록이다.
-
-
**저장모듈
: PL / SQL 문장을 데이터베이스 서버에 저장하여 사용자와 애플리케이션 사이에 공유할 수 있도록 만든 일종의 SQL 컴포넌트 프로그램이며, 완전한 실행 프로그램이다.
/*
+변수선언 등 SQL문 추가
암시적 커서(Implicit Cursor)란?
암시적인 커서는 오라클이나 PL/SQL실행 메커니즘에 의해 처리되는 SQL문장이 처리되는 곳에 대한 익명의 주소이다.
오라클 데이터베이스에서 실행되는 모든 SQL문장은 암시적인 커서가 생성되며, 커서 속성을 사용 할 수 있다.
암시적 커서는 SQL 문이 실행되는 순간 자동으로 OPEN과 CLOSE를 실행 한다.
암시적 커서의 속성
- - SQL%ROWCOUNT : 해당 SQL 문에 영향을 받는 행의 수
- - SQL%FOUND : 해당 SQL 영향을 받는 행의 수가 한 개 이상일 경우 TRUE
- - SQL%NOTFOUND : 해당 SQL 문에 영향을 받는 행의 수가 없을 경우 TRUE
- - SQL%ISOPEN : 항상 FALSE, 암시적 커서가 열려 있는지의 여부 검색
*/
##프로시저(PROCEDURE)
-
프로시저란?
: 특정 작업을 수행 하는, 이름이 있는 *PL/SQL BLOCK 이다.
-
매개 변수를 받을 수 있고, 반복적으로 사용 할 수 있는 BLOCK 이다.
-
보통 연속 실행 또는 구현이 복잡한 트랜잭션을 수행하는 PL/SQL BLOCK을 데이터베이스에 저장하기 위해 생성 한다.
-
-
생성
CREATE OR REPLACE PROCEDURE 프로시저명 (매개변수명1 [IN | OUT | IN OUT] 데이터타입 [:= 디폴트값] ,매개변수명2 [IN | OUT | IN OUT] 데이터타입 [:= 디폴트값] ... ) IS[AS] 변수, 상수 등 선언부 BEGIN -->필수 실행부 [EXCEPTION -->선택 예외처리부] END [프로시저명]; -->필수-
IN은 입력, OUT은 출력, IN OUT은 입출력을 동시에 한다는 의미이다.(디폴트값은 IN이다.)
-
OUT매개변수는 프로시저 내에서 로직 처리 후, 해당 매개변수에 값을 할당해 프로시저 호출부분에서 이 값을 참조할 수 있다.
-
예시
CREATE OR REPLACE PROCEDURE MY_NEW_JOB_PROC ( P_JOB_ID IN JOBS.JOB_ID%TYPE, P_JOB_TITLE IN JOBS.JOB_TITLE%TYPE, P_MIN_SAL IN JOBS.MIN_SALARY%TYPE, P_MAX_SAL IN JOBS.MAX_SALARY%TYPE ) IS BEGIN INSERT INTO JOBS (JOB_ID, JOB_TITLE, MIN_SALARY, MAX_SALARY, CREATE_DATE, UPDATE_DATE) VALUES (P_JOB_ID, P_JOB_TITLE, P_MIN_SAL, P_MAX_SAL, SYSDATE, SYSDATE); COMMIT; END;실행결과 :
Procedure MY_NEW_JOB_PROC이(가) 컴파일되었습니다.
-
-
실행
-
프로시저는 반환값이 없으므로 함수처럼 SELECT절에는 사용할 수 없다.
-
EXEC(EXECUTE) 프로시저명(매개변수1값, 매개변수2값, ...); -
예시 :
EXEC MY_NEW_JOB_PROC('SM_JOB1', 'SAMPLE JOB1', 1000, 5000);결과 :
PL/SQL 프로시저가 성공적으로 완료되었습니다.
-
+추가
##함수(FUNCTION)
: 함수는 반환값이 있고, 프로시저는 반환 값이 없다.
-
함수작성
구성 :
- 함수명 선언
- 사용할 파라미터 선언
- 반환형 선언
- 함수 내에서 사용할 변수 선언
- 쿼리 수행
- 반환
- 예외처리
- END 함수명;
CREATE OR REPLACE FUNCTION test_func( -->함수명
PARAM_TEST IN NUMBER -->파라미터 선언
)
RETURN VARCHAR -->반환형 선언
IS
v_test VARCHAR2(100); -->함수 내에서 사용할 변수 선언
BEGIN
v_test := 'testFunction'; -->쿼리수행
RETURN v_test; -->반환
EXCEPTION -->예외처리
END test_func; -->END 함수명 예시 :
CREATE OR REPLACE FUNCTION SCOTT.GET_NAME ( -- 함수명
PARAM_EMPNO IN NUMBER -- 파라미터 선언
)
RETURN VARCHAR2 IS -- 반환형 선언
V_NM VARCHAR2(10); -- 변수 선언
BEGIN -- 쿼리 수행 부분
-- 파라미터로 NULL을 넣었을 경우 NULL 반환
IF PARAM_EMPNO IS NULL OR PARAM_EMPNO = NULL THEN
V_NM := NULL;
ELSE -- 파라미터를 넣었을 경우
SELECT ENAME -- 조회한 컬럼을
INTO V_NM -- V_NM에 넣는다
FROM EMP
WHERE EMPNO = PARAM_EMPNO;
END IF;
RETURN V_NM; -- 조회한 내용 반환
-- 예외처리
EXCEPTION
WHEN OTHERS THEN
RETURN '없는 번호'; -- 예외의 경우 NULL 반환
END GET_NAME;- 조회 시 INTO로 변수에 넣어준 값을 RETURN 변수명; 해서 반환시키면 된다
- END 함수명;은 해당 함수를 끝내는 것을 알려줌
- !오라클에서 대입하는 방식은 '='가 아니고 ':=' 이다.
##트리거(Trigger)
-
트리거란?
- 트리거(Trigger)란 영어로 방아쇠라는 뜻인데, 방아쇠를 당기면 그로 인해 총기 내부에서 알아서 일련의 작업을 실행하고 총알이 날아갑니다.
- 이처럼 데이터베이스에서도 트리거(Trigger)는 특정 테이블에 INSERT, DELETE, UPDATE 같은 *DML 문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램입니다.
- 즉! 사용자가 직접 호출하는 것이 아니라, 데이터베이스에서 자동적으로 호출하는 것이 가장 큰 특징입니다.
- 트리거(Trigger)는 테이블과 뷰 데이터베이스 작업을 대상으로 정의할 수 있으며, 전체 트랜잭션 작업에 대해 발생되는 트리거(Trigger)와 각행에 대해 발생되는 트리거(Trigger)가 있습니다.
-
트리거(Trigger)가 적용되는 예
-
쇼핑몰 일일 수만 건의 주문
- 주문데이터 : 주문일자, 주문상품, 수량, 가격이 있음
- 수천명의 임직원이 주문실적 조회(일자별, 상품별 총 판매수량과 총 판매가격으로 구성)
- 조회할 때마다 수만 건의 데이터를 읽고 계산해야한다. 만약 임직원이 수만명이고, 데이터가 수백만건이라면, 또 거의 동시다발적으로 실시간 조회가 요청된다면 시스템 퍼포먼스가 떨어질 것입니다.
-
따라서! 트리거(Trigger)를 사용하여 주문한 건이 입력될 때마다, 일자별 상품별로 판매수량과 판매금액을 집계하여 집계자료를 보관하도록 만들 수 있다.
-
**DML, DDL, DCL, TCL 이란?
| 명령어 종류 | 명령어 | 설명 |
| 데이터 조작어(DML : Data Manipulation Language | SELECT | 데이터베이스에 들어 있는 데이터를 조회하거나 검색하기 위한 명령어를 말하는 것으로 RETRIEVE 라고도 함 |
| INSERT UPDATE DELETE | 데이터베이스의 테이블에 들어 있는 데이터에 변형을 가하는 종류(데이터 삽입, 수정, 삭제)의 명령어들을 말함. | |
| 데이터 정의어(DDL : Data Definition Language) | CREATE ALTER DROP RENAME TRUNCATE | 테이블과 같은 데이터 구조를 정의하는데 사용되는 명령어들로 (생성, 변경, 삭제, 이름변경) 데이터 구조와 관련된 명령어들을 말함. |
| 데이터 제어어(DCL : Data Control Language) | GRANT REVOKE | 데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어들을 말함. |
| 트랜잭션 제어어(TCL : Transaction Control Language) | COMMIT ROLLBACK SAVEPOINT | 논리적인 작업의 단위를 묶어서 DML에 의해 조작된 결과를 작업단위(트랜잭션) 별로 제어하는 명령어를 말함. |
-
트리거 구현
1) 2개 테이블을 CREATE, DDL을 통해 만듬
CREATE TABLE ORDER_LIST(
ORDER_DATE CHAR(8) NOT NULL,
PRODUCT VARCHAR2(10) NOT NULL,
QTY NUMBER NOT NULL,
AMOUNT NUMBER NOT NULL
);CREATE TABLE SALES_PER_DATE(
SALE_DATE CHAR(8) NOT NULL,
PRODUCT VARCHAR2(10) NOT NULL,
QTY NUMBER NOT NULL,
AMOUNT NUMBER NOT NULL
);2)트리거 구현
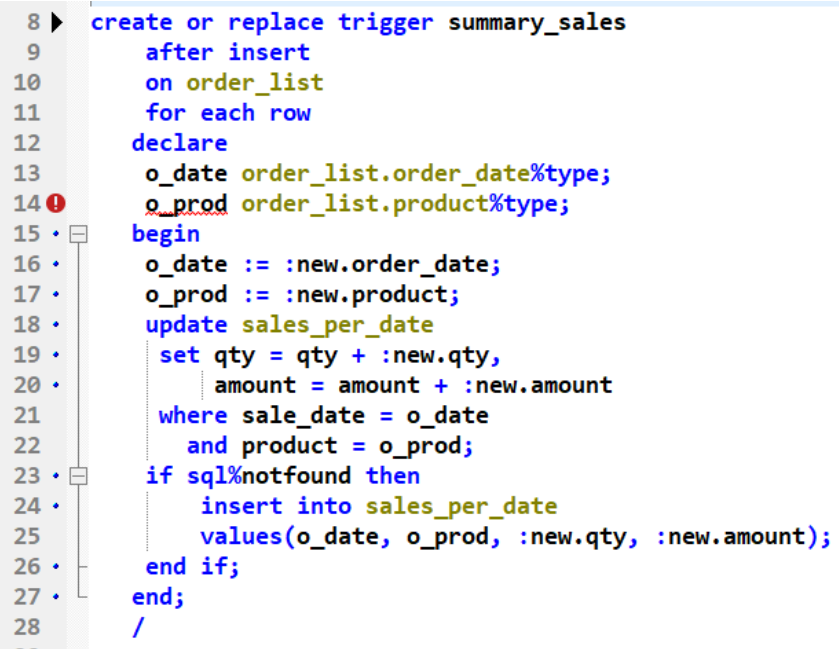
트리거(Trigger) 처리 절차를 설명하면 다음과 같습니다.
-
8 ~ 14 Line
: Trigger를 선언합니다.- order_list 테이블에 insert가 발생하면 그 이후 each row 즉 각 행에 해당 트리거(Trigger)를 적용한다라는 뜻입니다.
- declare 선언문에는 변수를 선언 : order_list 테이블에 있는 order_date, product Type에 맞게 o_date, o_prod 변수를 선언합니다.
-
15 ~17 Line
- new 는 트리거(Trigger)에서 사용하는 구조체 입니다. new는 새로 입력된 레코드 값을 담고 있습니다.
- o_date 에 새로 들어온 order_date 값을 , o_prod 에 새로 들어온 product 값을 저장합니다.
-
18 ~ 26 Line
- update > sales_per_date 테이블에 update 구문을 실행하는데
- set > 기존에 있는 qty, amount 를 누적합해서 다시 Set 합니다.
- while > 여기서 where문을 통해 현재 새로 들어온 날짜과 상품이 일치하는 데이터만 해당 update문을 실행하도록 조건을 걸었습니다.
- if > 만약 sql%notfound면(해당 조건에 모두 해당되지 않는다면), 기존에 있던 레코드 값이 아니고 전혀 새로운 레코드이기 때문에 insert 구문을 통해 새로 들어온 데이터를 새로 삽입합니다.
- SQL%NOTFOUND : 해당 SQL 문에 영향을 받는 행의 수가 없을 경우 TRUE
- end; / > / 부분은 트리거(Trigger)를 실행하는 실행명령어입니다.4
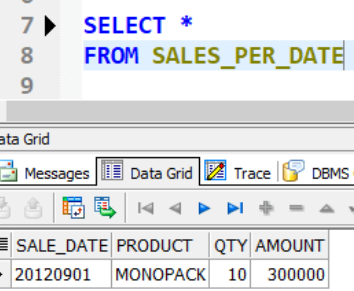
4) 결과
INSERT INTO ORDER_LIST VALUES('20120901','MONOPACK',10,300000)ORDER_LIST 정상적으로 값이 삽입되었습니다.
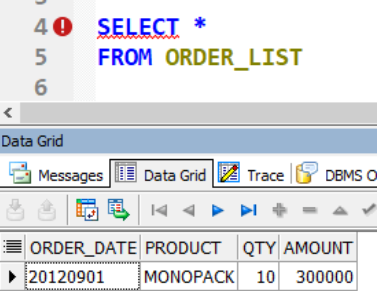
트리거에 의해서 SALES_PER_DATE 에도 정상적으로 값이 삽입되어있습니다.
-
트리거(Trigger)와 트랜잭션(**Transaction**)의 상관관계
판매 데이터 입력취소 동작 -> 주문 정보 테이블(ORDER_LIST)과 판매 집계테이블(SALES_PER_DATE )또한 입력(수정) 취소가 일어날까?
-
다른 상품으로 주문 데이터를 입력한 후 -> 트랜잭션을 ROLLBACK 해보겠습니다.
-
SALES_PER_DATE 테이블에도 똑같이 트리거로 입력된 데이터 정보까지 하나의 트랜잭션으로 인식하여 입력 취소가 되었습니다.
-
즉, 트리거는 데이터베이스에 의해 자동 호출되지만 결국 INSERT, UPDATE, DELETE 구문과 하나의 트랜잭션 안에서 일어나는 일련의 작업들이라 할 수 있습니다.
(추가로 트리거는 Begin ~ End 절에서 COMMIT , ROLLBACK 을 사용할 수 없습니다)
-
