
SQL 수행 시 비용이 많이 드는 것 중에 하나가 정렬 비용이다.
현업의 쿼리 중에 order by 없는 쿼리는 손에 꼽을 만하다.
그럼 정렬 비용을 줄이기 위해, 어떤 조건일 때 order by 가 인덱스를 사용하는지 정렬 비용이 많이드는지 알아보자
1) 인덱스를 이용한 정렬
order by 절의 테이블이 드라이빙 테이블이고, order by 순서대로 생성된 인덱스가 존재해야 한다.
< SQL_1 >
SELECT *
FROM employees
inner join salaries on salaries.emp_no = employees.emp_no
where employees.emp_no >= 10002 AND employees.emp_no < 10020
ORDER BY employees.emp_no
;-
인덱스 정보

-
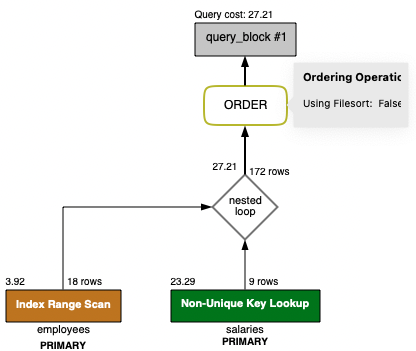
SQL_1 실행계획 분석
드라이빙 테이블 : employees
where 조건 : employees의 PK 컬럼 ( emp_no )
order by 컬럼 : employees의 PK 컬럼 ( emp_no )
Extra 항목에 정렬에 대한 내용이 없기 때문에 인덱스를 이용한 정렬을 확인할 수 있다.

-
정렬을 따로 하지 않았기 때문에 sort 관련 변수 모두 값이 0 .
mysql> show status like '%sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 0 |
| Sort_scan | 0 |
+-------------------+-------+
그럼 여기서 한번 더 생각해보자.
order by 절의 테이블을 드라이빙 -> 드리븐 테이블로 바꿔보자
< SQL_2 >
SELECT *
FROM employees
inner join salaries on salaries.emp_no = employees.emp_no
where employees.emp_no >= 10002 AND employees.emp_no < 10020
ORDER BY salaries.emp_no드라이빙 테이블과 정렬컬럼 (salaries.emp_no) 의 테이블이 다르기 때문에 인덱스를 활용할 수 없다.
- SQL_2 실행계획 분석
정렬시 인덱스를 활용하지 못하고, 임시테이블을 이용한 정렬 발생
Extra 항목에 "Using temporary; Using filesort"가 추가

! 튜닝 시 고려사항 : 정렬비용이 큰 경우, 인덱스를 사용할 수 있도록 개선 가능한지 검토
! 그럼 왜 employees 가 드라이빙 테이블이 되었는가 ? ( to be continue .. )
2) 조인의 드라이빙 테이블만 정렬
드라이빙 테이블을 정렬한 후 조인을 실행하는 경우에 사용된다.
이 경우 드라이빙 테이블만 정렬하면 된다.
< SQL_3 >
SELECT *
FROM employees
inner join salaries on salaries.emp_no = employees.emp_no
where employees.emp_no >= 10002 AND employees.emp_no < 10020
ORDER BY employees.last_name ;드라이빙 테이블을 PK로 검색했지만, 정렬 컬럼은 다르기 때문에 정렬 한 후 salaries 테이블과 조인한다.
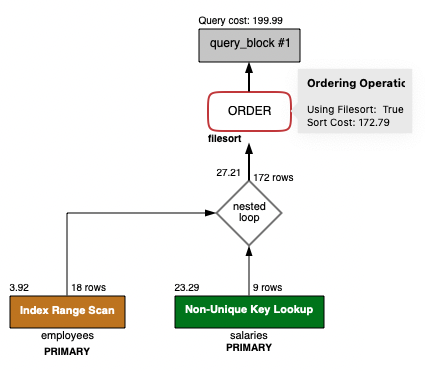
- SQL_3 실행계획 분석
* Extra 에 using filesort 로 정렬작업이 발생한 것을 알 수 있다.

- employees 조건만큼 sort_rows 가 18이 나옴 . ( 욕하는 거 아님 )
mysql> show status like '%sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 18 |
| Sort_scan | 1 |
+-------------------+-------+
3) 임시 테이블을 이용한 정렬
2개 이상의 테이블을 조인해서 결과를 다시 정렬 하는 경우 발생한다.
가장 느린 정렬방법이라, 이 경우 인덱스를 활용하는 방법을 고민해 봐야 한다.
< SQL_2 >
SELECT *
FROM employees
inner join salaries on salaries.emp_no = employees.emp_no
where employees.emp_no >= 10002 AND employees.emp_no < 10020
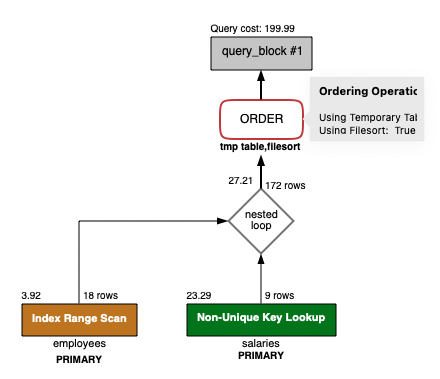
ORDER BY salaries.emp_no- SQL_2 실행계획 분석
* 드라이빙 테이블은 employees 인데, 정렬 기준은 salaries 테이블이라 조인결과를 다시 salaries.emp_no 기준으로 정렬해야한다.- 정렬시 인덱스를 활용하지 못하고, 임시테이블을 이용한 정렬 발생
- 결과 건 수 만큼 sort_rows가 나왔다.
mysql> show status like '%sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 174 |
| Sort_scan | 1 |
+-------------------+-------+
<SQL_4>
SELECT *
FROM employees
inner join salaries on salaries.emp_no = employees.emp_no
where employees.emp_no >= 10002 AND employees.emp_no < 10020
ORDER BY employees.emp_no, salaries.salary
;- SQL_4 실행계획 분석
정렬 컬럼이 여러 테이블이라 조인한 결과를 저장해서 다시 정렬해야한다.
정렬시 인덱스를 활용하지 못하고, 임시테이블을 이용한 정렬 발생

